SDG,ADAM,LookAhead,Lion等优化器的对比介绍
本文将介绍了最先进的深度学习优化方法,帮助神经网络训练得更快,表现得更好。有很多个不同形式的优化器,这里我们只找最基础、最常用、最有效和最新的来介绍。
优化器
首先,让我们定义优化。当我们训练我们的模型以使其表现更好时,首先使用损失函数,训练时损失的减少表明我们的模型运行良好。而优化是用来描述这种减少损失技术的术语。
“损失函数”是什么意思?
多个变量的值被映射成一个实数,该实数直观地表示使用损失函数与事件相关的一些“成本”。
实际值与模型预测值之间的差值被加起来被称作损失,而计算这种差值的函数被称作损失函数。
Σ (y_actual — y_predicted)/n (from i=1 to n {n = Number of samples})
这是一种衡量算法对它所使用的数据建模的好坏的方法。如果你的预测不准确,你的损失函数将产生更大的值。数字越低,说明模型越好。

实际的Y值由上面例子中的绿色点表示,拟合的直线由蓝色线表示(由我们的模型预测的值)。
让我们开始介绍优化技术来增强我们模型并尽可能减少前面提到的损失函数
梯度下降法 Gradient Descent
术语“梯度”指的是当函数的输入发生轻微变化时,函数的输出会发生多大的变化。
使用微积分,梯度下降迭代调整参数值,以在定义初始参数值后最小化所提供的成本函数。这是根据重复直到收敛方法完成的。
1、通过计算函数的一阶导数(y = mX + c {m =斜率,c =截距)来确定函数的梯度或斜率
2、斜率将从当前位置提升一个等于eta(学习率)倍的量到局部最小值,这是通过与梯度方向相反的方向移动来进行的

学习率:梯度下降向局部最小值下降所采取的步骤的大小,较大的步长是由高学习率产生的,但也有超过最小值的风险。低学习率还表明步长较小,这降低了操作效率,但提供了更高的准确性,并且有时无法逃出局部最小值,所以学习率是一个很重要的超参数。
随机梯度下降
通过一次加载n点的整个数据集来计算损失函数的导数,SGD方法不是在每次迭代中使用整个数据集,而是通过随机选择少量样本来计算导数,从而降低了计算强度。
SGD的缺点是,一旦它接近最小值,它就不会稳定下来,而是四处反弹,给我们一个很好的模型性能值,但不是最好的值。这可以通过改变模型参数来解决。
使用SGD是大型数据集的理想选择。但是当数据集较小或中等时,最好应用GD来获得更优的解决方案
小批量的梯度下降
小批量梯度将大数据集划分为小批量,并分别更新每个批量,这样既解决了GD的计算消耗问题,也解决了SGD到达最小值的路径问题,这也就是我们在训练时设置batch size参数的作用。
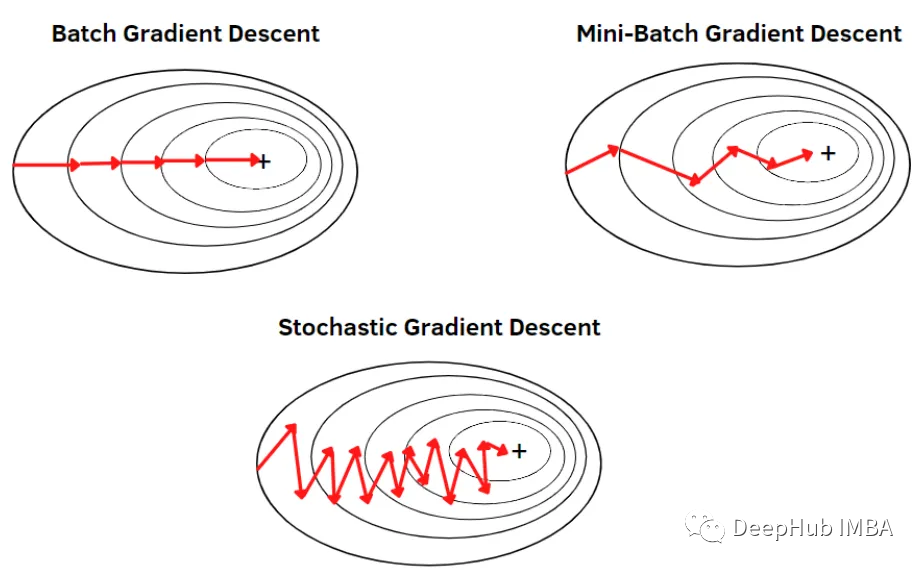
也就是说:
- 梯度下降(GD):在整个训练集之后,训练的参数会被修改
- 随机梯度下降(SGD):在每一个样本训练之后更新参数
- 小批量的梯度下降 (Mini Batch Gradient Descent): 每批完成后,更新参数
带动量的梯度下降 Momentum Stochastic Gradient
为了平滑更新,考虑到以前的梯度。它不是更新权重,而是计算前几次迭代的梯度平均值。
比传统的梯度下降方法更快。动量通过用指数加权平均去噪梯度来解决这个噪声问题,加快了在正确方向上的收敛,减缓了在错误方向上的波动。这个动量超参数用符号“γ”表示。

权重由θ = θ−γ(t)更新,动量项通常设置为0.9或类似的值,所有以前的更新,计算t时刻的动量,给予最近的更改比旧的更新更多的权重。这导致收敛加速并更快地达到最小值。
如果你使用pytorch,有一个momentum 参数,就是这个了。
Adaptive Gradient Descent (AdaGrad)
AdaGrad消除了手动调整学习率的需要,在迭代过程中不断调整学习率,并让目标函数中的每个参数都分别拥有自己的学习率。利用低学习率的参数链接到频繁发生的特征,并使用高学习率的参数链接到很少发生的特征。它适合用于稀疏数据。
每个权重以不同的速率(η)学习。
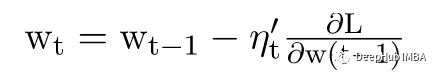
在每次迭代中,每个权重的不同学习率用alpha(t)表示,η =常数,Epsilon =正整数(以避免除0误差)
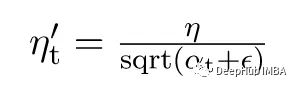
Adagrad的一个优点是不需要手动调优速率,大多数将其保持在默认值0.01。随着重复次数的增加,alpha(t)会变得相当大,结果ηt’会更快地变化。因此以前的权重将几乎等于新的权重,这可能导致收敛速度较慢。
Adagrad也一些缺点,由于每一个额外的项都是正的,梯度的平方的累积和,分母中的alpha(t)在训练过程中不断扩大,导致学习率下降,最终变得无限小,会导致梯度消失的问题另外就是它是单调下降的学习速率。必须使用初始全局学习率来设置它。
AdaDelta
Adadelta 是 Adagrad 的更可靠的增强,它根据梯度更新的移动窗口来调整学习率,而不是通过取指数衰减平均值来累加所有先前的梯度(累积和)。在时间步 t 影响 E[g2]t 的运行平均值的唯一因素是先前的平均值和当前梯度。

这有助于在迭代次数非常大时防止低收敛率并导致更快的收敛。即使在进行了多次升级之后,Adadelta 仍以这种方式学习。与 Adagrad 不同,我们不需要为 Adadelta 选择初始学习率。
Adaptive Moment Estimation (ADAM)
Adam 的优化方法结合了偏差校正、RMSprop 和 带动量SGD。
所以我们没有单独介绍RMSprop
1、RMSProp:通过使用“指数移动平均值”来提高性能,这是平方梯度的平均值。
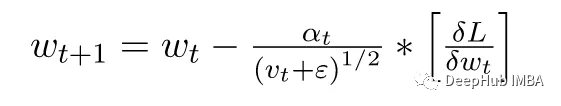
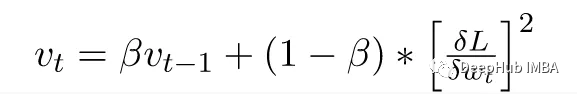
在 mt & vt 计算中,添加的表达式 (1-β)[∂L/∂Wt] 和 (1-β)[∂L/∂Wt]² 分别用于偏差校正,m 和 v 初始化为 0
用于 mt 和 vt 的超参数 β(分别为 β1 和 β2)在 mt 的情况下默认为 0.9,在 vt 的情况下默认为 0.999。它们的唯一作用是控制这些移动平均线的指数率。因为这里的α 为 0.001,ε 为 10⁻⁷。
还记得ADAM的默认值吗,就是这俩了,对吧。
2、Momentum:与上面的带动量的梯度下降一样,对梯度进行“指数加权平均”,以加速梯度下降算法的收敛到最小值。它是对第一个矩(均值)的估计。
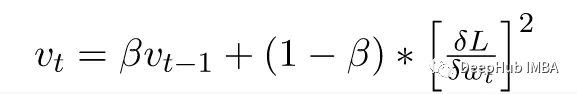
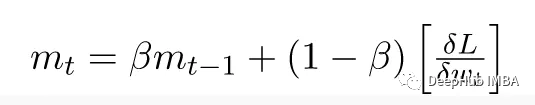
下面的截图是来自研究论文“ADAM: A METHOD FOR STOCHASTIC OPTIMIZATION”的图表显示了实验支持的理由,为什么ADAM是训练成本最低的最佳优化技术
在Adam的基础上还出现了Nadam,AdamW,RAdam等变体,这里就不详细介绍了
ADAM自从发布以来就变为了我们最常用的默认优化器,在没有选择的时候我们直接使用它就可以了,当然上面的变体可以试试,这里推荐试试RAdam,我自测效果不错。
Lookahead
Lookahead是Adam的作者在19年发布的一个方法,虽然它不能算做一个优化器,但是它可以和任何优化器组合使用,所以我们这里要着重的介绍一下。
Lookahead 算法与已有的方法完全不同,它迭代地更新两组权重。直观来说,Lookahead 算法通过提前观察另一个优化器生成的「fast weights」序列,来选择搜索方向。
它可以提高基于梯度的优化方法(如随机梯度下降(SGD)及其变体)的收敛速度和泛化性能。
Lookahead背后的思想是在当前梯度更新的方向上迈出一步,然后使用一组额外的权重(称为“慢权重”)在同一方向上迈出一步,但时间范围更长。与原始权重相比,这些慢权重更新的频率更低,有效地创建了对优化过程未来的“展望”。
在训练期间,Lookahead计算两个权重更新:快速权重更新,它基于当前的梯度并应用于原始权重,以及慢速权重更新,它基于之前的慢速权重并应用于新的权重集。这两个更新的组合给出了最终的权重更新,用于更新原始权重。使用慢权重提供了一种正则化效果,有助于防止过拟合并提高泛化性能。此外,这种前瞻机制有助于优化器更有效地逃避局部最小值和鞍点,从而导致更快的收敛。
Lookahead已被证明在一系列深度学习任务(包括图像分类、语言建模和强化学习)上优于Adam和SGD等其他优化算法。他的使用方式也很简单,我们可以将它与任何优化器相结合:
base_optim=RAdam(model.parameters(),lr=0.001) optimizer= Lookahead(base_optim, k=5, alpha=0.5)
然后获得的这个optimizer就像以前的优化器一样使用就可以了
LION
最后我们再介绍一个google在2月最新发布的 自动搜索优化器 论文的名字是《Symbolic Discovery of Optimization Algorithms》,作者说通过数千 TPU 小时的算力搜索并结合人工干预,得到了一个更省显存的优化器 Lion(EvoLved Sign Momentum),能看的出来,为了凑LION这个名字作者也是煞费苦心。
所以这里我们不介绍Lion的具体算法,因为作者说了数千 TPU 小时的算力搜索 这个我们没法评判,这里只介绍一些性能的对比。
作者在论文中与 AdamW进行对比:

并且在imagenet上训练了各种模型来获得
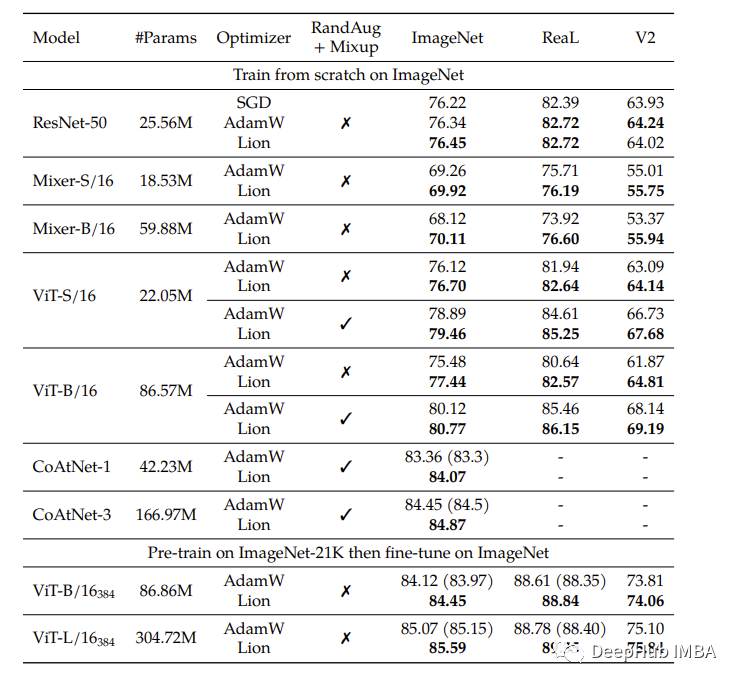
从上图看出Lion还是有所提高的。但是从下图可以看到,大批次的lion表现得更好
总结
优化器是深度学习训练的基础,有很多的优化器可以选择,但是我们可以看到,最基础的SGD为我们提供了优化器工作的理论基础,而Adam的出现使得我们得到了一个在训练时默认的选择(或者可以直接试试RAdam)。在这之上,如果你只想通过设置优化器的方式来进一步提高模型性能的话,可以使用Lookahead。如果想试试最新的那么Lion应该还好,但是具体的效果还需要实地的测试。
https://avoid.overfit.cn/post/f7ed65f0a24a41ba942df18598f17e5c
还是那句话:“没有银弹”,先做个baseline,再进行测试,选择适合项目的优化器来使用才是最佳的方案。
作者:Tavleen Bajwa
相关文章:
SDG,ADAM,LookAhead,Lion等优化器的对比介绍
本文将介绍了最先进的深度学习优化方法,帮助神经网络训练得更快,表现得更好。有很多个不同形式的优化器,这里我们只找最基础、最常用、最有效和最新的来介绍。 优化器 首先,让我们定义优化。当我们训练我们的模型以使其表现更好…...
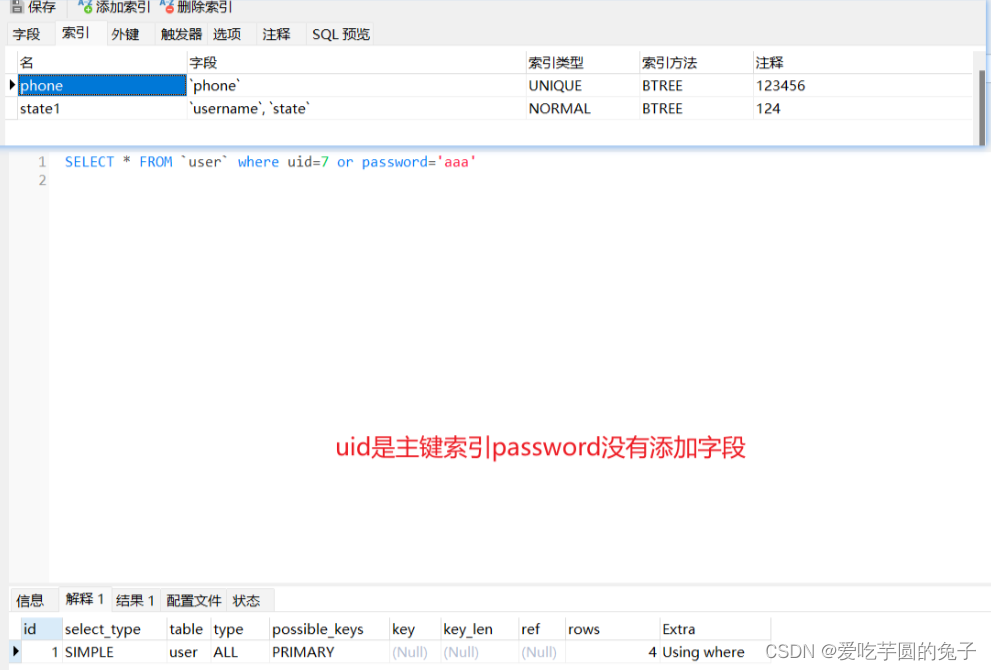
【项目实现典型案例】12.数据库数据类型不一致导致查询慢
目录一:背景介绍二:索引失效复现四:索引实现的六种情况1、类型转换,函数2、ISNULL3、通配符开头4、范围查询5、组合索引,不符合最左匹配原则6、WHERE子句中的OR四:总结一:背景介绍 MySql数据库…...

【大数据开发】报错汇总
目录 Hadoop Attempting to operate on hdfs namenode as root jps后没有namenode Hive Exception in thread "main" java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V Caused by:o…...

HTTPS的加密原理(工作机制)
现在很多网站使用的都是HTTPS协议,比如CSDN他们为什么要使用HTTPS协议而不是继续使用HTTP协议呢?以及HTTPS都做了些什么?HTTP协议与HTTPS有哪些区别? 下面我来 讲解这些问题?(篇幅可能有些长,请求耐心观看,我以0基础的角度去讲解这些东西, 如果你有一定的基础前面的跳过就好…...

Git仓库迁移
背景 由于公司原来的gitee地址需要改完新的gitlab仓库,大量的服务模块已再本地进行开发,且存在大量分支进行维护,迁移要求历史提交记录也得同步,需要简单快捷一并完成各服务已经分支迁移。 一、在新的目标git中创建新代码仓 新…...

用CHATGPT生成C++面试题及答案
以下是C的面试题及其答案: 什么是C?C与C语言有什么区别? C是一种高级编程语言,是对C语言的扩展。C具有更强大的面向对象编程能力,支持类、继承、多态等特性。 什么是面向对象编程? 面向对象编程是一种编程…...

二进制,八进制,十进制,十六进制的相互转换【简单易懂】(含代码模板)
目录 二进制转十进制 十进制原理: 二进制转十进制计算: 八、十六进制转十进制 八、十六进制转十进制计算: 十进制转其他进制 十进制转二进制: 十进制转八进制: 十进制转十六进制: 不同进制之间的相互转…...
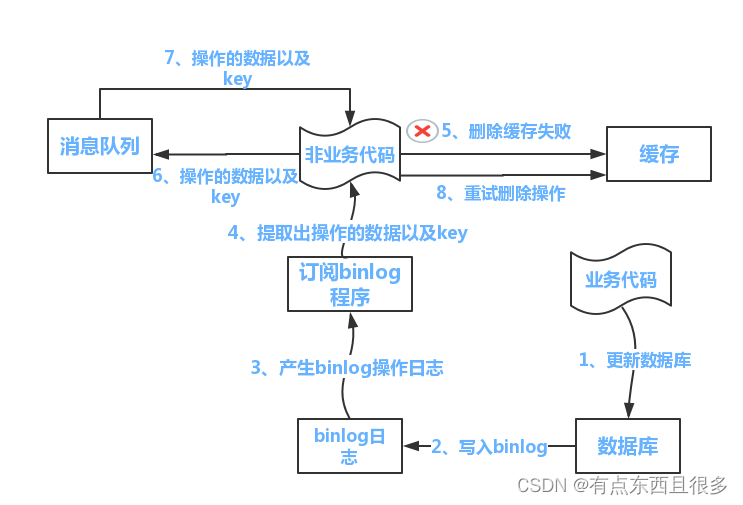
Redis技术详解
Redis技术详解 Redis是一种支持key-value等多种数据结构的存储系统。可用于缓存,事件发布或订阅,高速队列等场景。支持网络,提供字符串,哈希,列表,队列,集合结构直接存取,基于内存&…...
解决mybatis-plus updateById方法不能set null
原因 因为 MyBatis-Plus 自带的更新方法,都有对对象空值进行判空。只有不为空的字段才会进行数据更新 所以像updateById等方法,在更新时会自动忽略为null的字段,只更新非null字段值 但在某些情况下,我们的需求就是将数据库中的值…...

Linux的mysql 数据库及开发包安装
注意:以下操作都以 root 用户进行操作 直接按照下列步骤在命令行输入即可 下载 1: sudo yum install -y mariadb 2: sudo yum install -y mariadb-server 3: sudo yum install -y mariadb-devel 接下来配置文件:在相应…...

π-Day快乐:Python可视化π
π-Day快乐:Python可视化π 今天是3.14,正好是圆周率 π\piπ 的前3位,因此数学界将这一天定为π\bold{\pi}π day。 π\piπ 可能是最著名的无理数了,人类对 π\piπ 的研究从未停止。目前人类借助计算机已经计算到 π\piπ 小数…...

【论文速递】ACM MM 2022 - 基于统一对比学习框架的新闻多媒体事件抽取
【论文速递】ACM MM 2022 - 基于统一对比学习框架的新闻多媒体事件抽取 【论文原文】:Multimedia Event Extraction From News With a Unified Contrastive Learning Framework 【作者信息】:Liu, Jian and Chen, Yufeng and Xu, Jinan 论文ÿ…...

数据库分库分表
一、为什么要分库分表 如果一个网站业务快速发展,那这个网站流量也会增加,数据的压力也会随之而来,比如电商系统来说双十一大促对订单数据压力很大,Tps十几万并发量,如果传统的架构(一主多从),主库容量肯定无法满足这么高的Tps,业务越来越大,单表数据超出了数据库支持…...

【C缺陷与陷阱】----语义“陷阱”
💯💯💯 本篇处理的是有关语义误解的问题:即程序员的本意是希望表示某种事物,而实际表示的却是另外一种事物。在本篇我们假定程序员对词法细节和语法细节的理解没有问题,因此着重讨论语义细节。导言…...

JavaWeb--VUE
VUE1 概述2 快速入门3 Vue 指令3.1 v-bind & v-model 指令3.2 v-on 指令3.3 条件判断指令3.4 v-for 指令4 生命周期5 案例5.1 需求5.2 查询所有功能5.3 添加功能目标 能够使用VUE中常用指令和插值表达式能够使用VUE生命周期函数 mounted 1 概述 接下来我们学习一款前端的框…...

2分钟彻底搞懂“高内聚,低耦合”
💗推荐阅读文章💗 🌸JavaSE系列🌸👉1️⃣《JavaSE系列教程》🌺MySQL系列🌺👉2️⃣《MySQL系列教程》🍀JavaWeb系列🍀👉3️⃣《JavaWeb系列教程》…...

网络编程UDP TCP
定义:关注底层数据的传输 区分网页编程:关注上层应用 端口号:区分软件 2个字节 0~65535表示端口号 同一协议下端口号不能冲突 8000以下称为预留端口号,建议之间设置端口号为8000以上 常见的端口号: 80:http 8080:tomcat 3306:mysql 1521:oracle InetSocketAddress:此类实现IP套…...
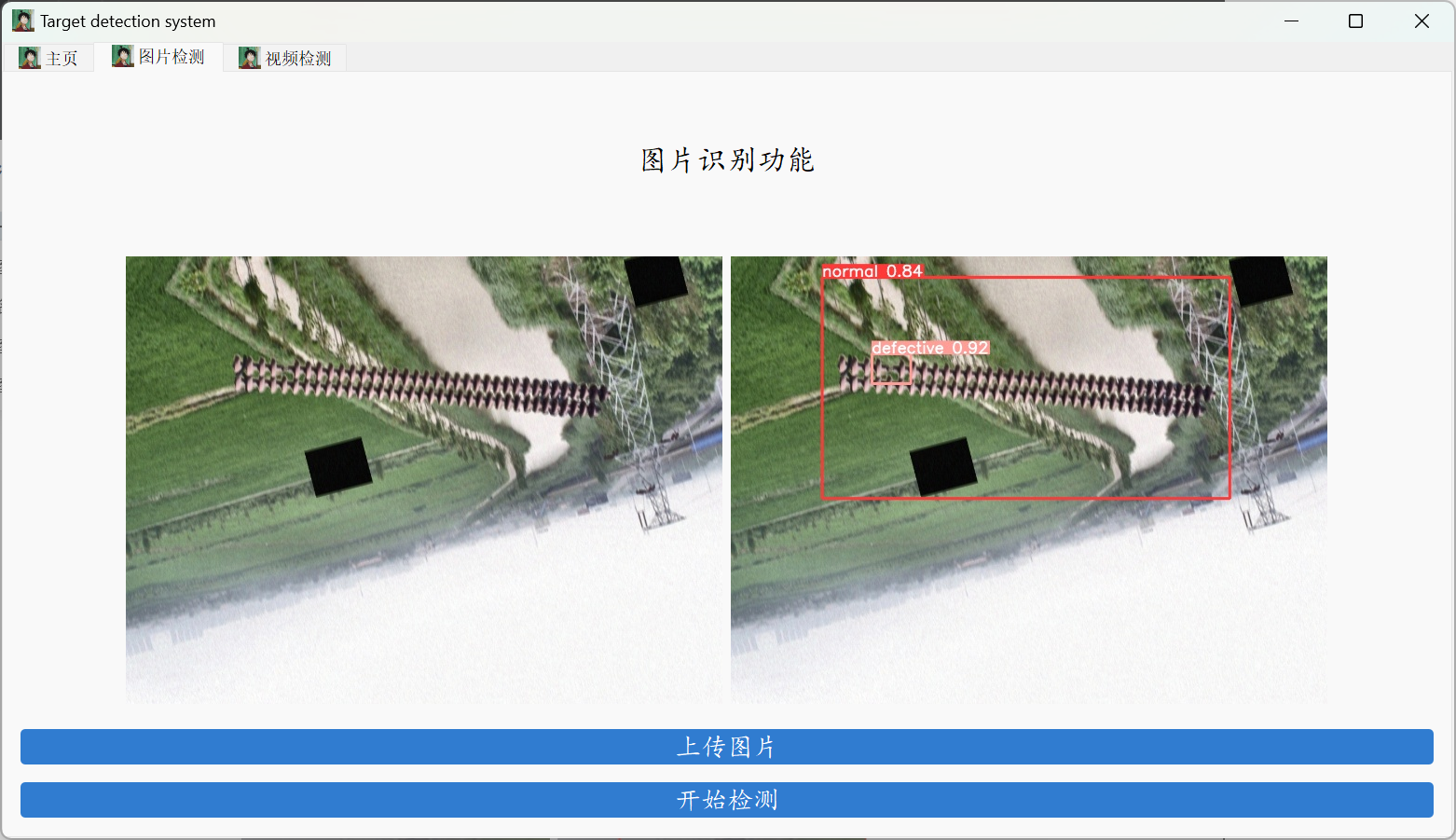
【2023-Pytorch-检测教程】手把手教你使用YOLOV5做电线绝缘子缺陷检测
随着社会和经济的持续发展,电力系统的投资与建设也日益加速。在电力系统中,输电线路作为电能传输的载体,是最为关键的环节之一。而绝缘子作为输电环节中的重要设备,在支撑固定导线,保障绝缘距离的方面有着重要作用。大…...
)
交叉编译(NDK)
文章目录前言Android-NDK使用NDK目录结构主流的Android NDK交叉编译前言 交叉编译是指在一种计算机体系结构上编译和构建应用程序,但是生成的可执行文件和库是针对另一种不同的体系结构,比如ARM、MIPS、PowerPC、x86 等。 常见的交叉编译工具集&#x…...

【数据库】MySQL 解读事务的意义及原则
目录 1.事务的概念 2.为什么要用事物 3.使用 4.事务的原则(ACID) 4.1原子性(Atomicity) 4.2一致性(Consistency) 4.3持久性(Durability) 4.4隔离性(Isolation…...

从格式混乱到工作流重构:Cloud Document Converter如何重塑飞书文档迁移体验
从格式混乱到工作流重构:Cloud Document Converter如何重塑飞书文档迁移体验 【免费下载链接】cloud-document-converter Convert Lark Doc to Markdown 项目地址: https://gitcode.com/gh_mirrors/cl/cloud-document-converter 你是否曾花费数小时手动复制飞…...

从零搭建短剧生成AI
当AI遇上短剧创作,会产生怎样的火花?从抖音的1分钟小剧场到YouTube的3分钟微电影,短剧已成为最受欢迎的内容形式之一。而AI,正在让这种创作变得触手可及。AI时代的内容创作革命在数字内容爆炸式增长的时代,短剧以其紧凑…...

物理网卡down了?虚拟机还能通信吗?看teaming策略就够了
在ESXi虚拟化运维中,物理网卡(vmnic)故障、网线松动、网卡损坏导致网卡down(宕机),是常见的硬件故障场景。很多新手遇到这种情况,会下意识认为所有虚拟机都会断网,但实际并非如此。核…...

2026终极指南:如何一键重置JetBrains IDE试用期,享受无限期免费开发体验
2026终极指南:如何一键重置JetBrains IDE试用期,享受无限期免费开发体验 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 你是否曾因JetBrains IDE试用期到期而中断开发工作?每次…...

量子计算威胁下的密码安全:从后量子密码到密码敏捷性实战解析
1. 量子计算:从实验室概念到国家安全的“灰犀牛”最近几年,每当我和业内的同行、安全专家,甚至是投资圈的朋友聊起前沿技术风险,话题总会在某个时刻滑向量子计算。这感觉很像十几年前大家第一次严肃讨论“云计算安全”时一样——一…...

RK3368安卓9.0固件烧录后开机卡Recovery?手把手教你调整分区表解决4GB闪存空间不足
RK3368安卓9.0固件烧录实战:4GB闪存分区优化全解析 当你满怀期待地将Android 9.0固件烧录到RK3368开发板,却发现设备直接进入了Recovery模式,屏幕上躺着那个令人沮丧的红色感叹号机器人——这可能是每个嵌入式开发者都经历过的"入门仪式…...

5分钟搞定Mac Boot Camp驱动:告别繁琐手动安装的智能工具
5分钟搞定Mac Boot Camp驱动:告别繁琐手动安装的智能工具 【免费下载链接】brigadier Fetch and install Boot Camp ESDs with ease. 项目地址: https://gitcode.com/gh_mirrors/bri/brigadier 还在为Mac电脑安装Windows驱动而头疼吗?Brigadier是…...

从找石油到防灾害:地震勘探技术如何跨界守护城市安全?
地震勘探技术的跨界革命:从油气勘探到城市安全守护者 上世纪20年代,当第一批地球物理学家尝试用炸药激发地震波来寻找石油时,他们或许不会想到,这项技术会在百年后成为保护现代城市安全的"透视眼"。传统的地震勘探技术…...

第七部分-容器安全与监控——33. 镜像安全
33. 镜像安全 1. 镜像安全概述 镜像是容器的基石,镜像安全问题直接影响容器运行时安全。镜像安全涵盖基础镜像选择、镜像构建过程、镜像存储和分发等环节。 ┌─────────────────────────────────────────────────…...

QProcess::FailedToStart “No program defined“。qtcreator用的好好的,然后就不能调试了
点击 项目-》运行-》执行档根本原因:执行档:路径为空 解决办法:添加这样执行档 就有路径了。就可以用了...