C++:哈希结构(内含unordered_set和unordered_map实现)
unordered系列关联式容器
在C++98中,STL提供了底层为红黑树结构的一系列关联式容器,在查询时效率可达到$log_2 N$,即最差情况下需要比较红黑树的高度次,当树中的节点非常多时,查询效率也不理想。最好 的查询是,进行很少的比较次数就能够将元素找到,因此在C++11中,STL又提供了4个 unordered系列的关联式容器,这四个容器与红黑树结构的关联式容器使用方式基本类似,只是 其底层结构不同,本文中只对unordered_map和unordered_set进行介绍。
unordered_map和unordered_set的文档介绍
1. unordered_map是存储键值对的关联式容器,其允许通过keys快速的索引到与 其对应的value。
2. 在unordered_map中,键值通常用于惟一地标识元素,而映射值是一个对象,其内容与此 键关联。键和映射值的类型可能不同。
3. 在内部,unordered_map没有对按照任何特定的顺序排序, 为了能在常数范围内 找到key所对应的value,unordered_map将相同哈希值的键值对放在相同的桶中。
4. unordered_map容器通过key访问单个元素要比map快,但它通常在遍历元素子集的范围迭 代方面效率较低。
5. unordered_maps实现了直接访问操作符(operator[]),它允许使用key作为参数直接访问 value。
6. 它的迭代器至少是前向迭代器。
详情可以参考文档:
https://cplusplus.com/reference/unordered_set/unordered_set/?kw=unordered_set
底层结构
unordered系列的关联式容器之所以效率比较高,是因为其底层使用了哈希结构。
哈希概念
顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系,因此在查找一个元素 时,必须要经过关键码的多次比较。顺序查找时间复杂度为O(N),平衡树中为树的高度,即 O($log_2 N$),搜索的效率取决于搜索过程中元素的比较次数。
理想的搜索方法:可以不经过任何比较,一次直接从表中得到要搜索的元素。 如果构造一种存储结构,通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立 一一映射的关系,那么在查找时通过该函数可以很快找到该元素。
当向该结构中:
插入元素
根据待插入元素的关键码,以此函数计算出该元素的存储位置并按此位置进行存放
搜索元素
对元素的关键码进行同样的计算,把求得的函数值当做元素的存储位置,在结构中按此位置 取元素比较,若关键码相等,则搜索成功
该方式即为哈希(散列)方法,哈希方法中使用的转换函数称为哈希(散列)函数,构造出来的结构称 为哈希表(Hash Table)(或者称散列表)
例如:数据集合{1,7,6,4,5,9};
哈希函数设置为:hash(key) = key % capacity;
capacity为存储元素底层空间总的大小。
常见哈希函数
1. 直接定址法--(常用)
取关键字的某个线性函数为散列地址:Hash(Key)= A*Key + B 优点:简单、均匀 缺点:需要事先知道关键字的分布情况 使用场景:适合查找比较小且连续的情况 面试题:字符串中第一个只出现一次字符
2. 除留余数法--(常用)
设散列表中允许的地址数为m,取一个不大于m,但最接近或者等于m的质数p作为除数, 按照哈希函数:Hash(key) = key% p(p<=m),将关键码转换成哈希地址
3. 平方取中法--(了解)
假设关键字为1234,对它平方就是1522756,抽取中间的3位227作为哈希地址; 再比如关键字为4321,对它平方就是18671041,抽取中间的3位671(或710)作为哈希地址 平方取中法比较适合:不知道关键字的分布,而位数又不是很大的情况
直接定址法,需要是整型,且范围需要高度集中,除留余数法正是为了突破直接定址法的局限才被提出来,但是也引入了新的问题——哈希冲突。
注意:哈希函数设计的越精妙,产生哈希冲突的可能性就越低,但是无法避免哈希冲突。
哈希冲突
解决哈希冲突两种常见的方法是:闭散列和开散列
1. 开放地址法(闭散列) ,节点中含状态, 不能满,插入时要计算负载因子
2. 哈希桶/拉链法(开散列)
如果不是整型,映射地址需要引入仿函数。
闭散列最大的缺陷就是空间利用率比较低,这也是哈希的缺陷。
闭散列实现
#pragma once
#include<iostream>
#include<vector>
#include<string>using namespace std;template<class K>
struct HashFunc
{size_t operator()(const K& k){return (size_t)k;}
};template<>
struct HashFunc<string>
{size_t operator()(const string& k){size_t ret = 0;for (const auto& e : k){ret *= 131;ret += e;}return ret;}
};namespace HashClose
{enum state{EXIST,DELETE,EMPTY,};template<class K, class V>struct HashNode{pair<K, V> _kv;state _sta = EMPTY;};template<class K, class V, class Hash = HashFunc<K>>class HashTable{public:typedef HashNode<K, V> Node;HashTable():_table(10),_n(0){}Node* find(const K& k){Hash hf;size_t hashi = hf(k) % _table.size();while (EMPTY != _table[hashi]._sta){if (EXIST == _table[hashi]._sta && k == _table[hashi]._kv.first){return &_table[hashi];}++hashi;hashi %= _table.size();}return nullptr;}bool insert(const pair<K, V>& kv){if (find(kv.first)){return false;}if (1.0 * _n / _table.size() >= 0.7){HashTable newtable;newtable._table.resize(2 * _table.size());for(const auto& e : _table){newtable.insert(e._kv);}_table.swap(newtable._table);}Hash hf;size_t hashi = hf(kv.first) % _table.size();while (EMPTY != _table[hashi]._sta){++hashi;hashi %= _table.size();}_table[hashi]._sta = EXIST;_table[hashi]._kv = kv;++ _n;}bool erase(const K& key){Node* ret = find(key);if (ret){ret->_sta = DELETE;--_n;return true;}else{return false;}}private:vector<HashNode<K, V>> _table;size_t _n;};void testht1(){HashTable<int, int> ht;int a[] = { 18, 8, 7, 27, 57, 3, 38, 18 };for (auto e : a){ht.insert(make_pair(e, e));}ht.insert(make_pair(17, 17));ht.insert(make_pair(5, 5));cout << ht.find(7) << endl;cout << ht.find(8) << endl;ht.erase(7);cout << ht.find(7) << endl;cout << ht.find(8) << endl;}void testht2(){string arr[] = { "苹果", "西瓜", "香蕉", "草莓", "苹果", "西瓜", "苹果", "苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" };//HashTable<string, int, HashFuncString> countHT;HashTable<string, int> countHT;for (auto& e : arr){HashNode<string, int>* ret = countHT.find(e);if (ret){ret->_kv.second++;}else{countHT.insert(make_pair(e, 1));}}HashFunc<string> hf;cout << hf("abc") << endl;cout << hf("bac") << endl;cout << hf("cba") << endl;cout << hf("aad") << endl;}}开散列
开散列法又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同地 址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链 接起来,各链表的头结点存储在哈希表中。
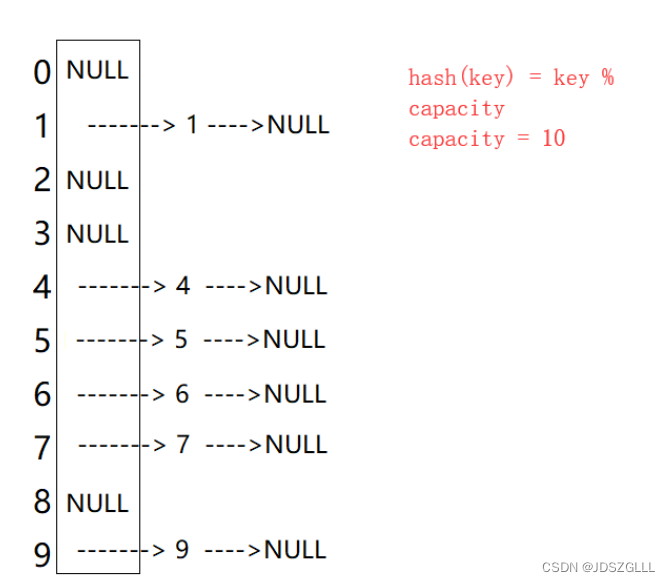
从上图可以看出,开散列中每个桶中放的都是发生哈希冲突的元素。
由于是一个数组下挂哈希桶,需要delete释放节点,需要写析构函数。
插入时头插。
扩容时旧节点重复利用
删除时与头节点交换,头删(也可以遍历直接删)
扩容时可以使容量为素数,以减少冲突
极端场景下,如果一个桶冲突过多,下面可以挂一个红黑树
开散列实现
namespace Hashbucket
{template<class T>struct HashNode{HashNode(const T& t):_date(t),_next(nullptr){}T _date;HashNode<T>* _next;};template<class K, class V, class Hash, class KeyOfV>class HashTable;template<class K, class V,class Ref, class Ptr, class Hash, class KeyOfV, class HTPTR, class HNPTR>struct HashIterator{typedef HashIterator<K, V, Ref, Ptr, Hash, KeyOfV, HTPTR, HNPTR> Self;typedef HashIterator<K, V, V&, V*, Hash, KeyOfV, HashTable<K, V, Hash, KeyOfV>*, HashNode<V>*> Iterator;HTPTR _ht;HNPTR _hn;HashIterator(HTPTR ht, HNPTR hn):_ht(ht),_hn(hn){}HashIterator(const Iterator& it):_ht(it._ht), _hn(it._hn){}Ref operator*(){return _hn->_date;}Ptr operator->(){return &(_hn->_date);}Self& operator++(){if (_hn->_next){_hn = _hn->_next;}else{KeyOfV kov;size_t hashi = Hash()(kov(_hn->_date)) % _ht->_table.size();while (++hashi < _ht->_table.size()){if (_ht->_table[hashi]){_hn = _ht->_table[hashi];return *this;}}_hn = nullptr;}return *this;}bool operator!=(const Self& it)const{return it._hn != _hn;}};template<class K, class V, class Hash, class KeyOfV>class HashTable{public:template<class K, class V, class Ref, class Ptr, class Hash, class KeyOfV, class HTPTR, class HNPTR>friend struct HashIterator;typedef HashTable<K, V, Hash, KeyOfV> Self;typedef HashNode<V> Node;typedef HashIterator<K, V, V&, V*, Hash, KeyOfV, Self*, Node*> iterator;typedef HashIterator<K, V, const V&, const V*, Hash, KeyOfV, const Self*, const Node*> const_iterator;//默认构造HashTable():_n(0){_table.resize(9, nullptr);}HashTable(const Self& ht):_n(0){_table.resize(9, nullptr);for (const auto& e : ht){insert(e);}}iterator begin(){for (int i = 0; i < _table.size(); ++i){if (_table[i]){return iterator(this, _table[i]);}}return iterator(this, nullptr);}iterator end(){return iterator(this, nullptr);}const_iterator begin()const{for (int i = 0; i < _table.size(); ++i){if (_table[i]){return const_iterator(this, _table[i]);}}return const_iterator(this, nullptr);}const_iterator end()const{return const_iterator(this, nullptr);}iterator find(const K& key){Hash hs;KeyOfV kot;size_t hashi = hs(key) % _table.size();Node* cur = _table[hashi];while (cur){if (key == kot(cur->_date)){return iterator(this, cur);}cur = cur->_next;}return end();}//找到下一个要扩容的尺寸inline unsigned long __stl_next_prime(unsigned long n){static const int __stl_num_primes = 28;static const unsigned long __stl_prime_list[__stl_num_primes] ={53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};for (int i = 0; i < __stl_num_primes; ++i){if (__stl_prime_list[i] > n){return __stl_prime_list[i];}}return __stl_prime_list[__stl_num_primes - 1];}pair<iterator, bool> insert(const V& v){KeyOfV kot;//已经存在,不需要插入iterator it = find(kot(v));if (end() != it){return make_pair(it, false);}Hash hs;//负载因子超过1 -> 扩容if(_n == _table.size()){vector<Node*> newtable;newtable.resize(__stl_next_prime(_table.size()), nullptr);for (int i = 0; i < _table.size(); ++i){Node* cur = _table[i];_table[i] = nullptr;Node* pre = nullptr;while (cur){size_t hashi = hs(kot(cur->_date)) % newtable.size();pre = cur;cur = cur->_next;pre-> _next = newtable[hashi];newtable[hashi] = pre;}}newtable.swap(_table);}//插入新节点size_t hashi = hs(kot(v)) % _table.size();Node* newnode = new Node(v);newnode->_next = _table[hashi];_table[hashi] = newnode;++_n;return make_pair(iterator(this, newnode), true);}private:vector<Node*> _table;size_t _n;};}unordered_set和unordered_map
#pragma once
#include"hash.h"namespace szg
{template<class K, class Hash = HashFunc<K>>class unordered_set{public:struct setKeyOfV{const K& operator()(const K& k){return k;}};typedef typename Hashbucket::HashTable<K, K, HashFunc<K>, setKeyOfV>::const_iterator iterator;typedef typename Hashbucket::HashTable<K, K, HashFunc<K>, setKeyOfV>::const_iterator const_iterator;iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}pair<iterator, bool> insert(const K& key){return _ht.insert(key);}private:Hashbucket::HashTable<K, K, HashFunc<K>, setKeyOfV> _ht;};}#pragma once
#include"hash.h"
namespace szg
{template<class K, class V, class Hash = HashFunc<K>>class unordered_map{public:struct mapKeyOfV{const K& operator()(const pair<const K, V>& v){return v.first;}};typedef typename Hashbucket::HashTable<K, pair<const K, V>, HashFunc<K>, mapKeyOfV>::iterator iterator;typedef typename Hashbucket::HashTable<K, pair<const K, V>, HashFunc<K>, mapKeyOfV>::const_iterator const_iterator;iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}pair<iterator, bool> insert(const K& key){return _ht.insert(key);}V& operator[](const K& key){pair<iterator, bool> ret = _ht.insert(make_pair(key, V()));return ret.first->second;}private:Hashbucket::HashTable<K, pair<const K, V>, HashFunc<K>, mapKeyOfV> _ht;};}相关文章:
C++:哈希结构(内含unordered_set和unordered_map实现)
unordered系列关联式容器 在C98中,STL提供了底层为红黑树结构的一系列关联式容器,在查询时效率可达到$log_2 N$,即最差情况下需要比较红黑树的高度次,当树中的节点非常多时,查询效率也不理想。最好 的查询是ÿ…...
Java实现调用第三方相关接口(附详细思路)
目录1.0.简单版2.0.升级版2-1.call.timeout()怎么传入新的超时值2-2.timeout(10, TimeUnit.SECONDS)两个参数的意思,具体含义3.0.进阶版3-1.java.net.SocketTimeoutException: 超时如何解决4.0.终极版1.0.简单版 以下是一个使用 Java 实际请求“第三方”的简单示例代…...

基础数据结构:单链表
今天懒洋洋学习了关于基础数据结构有关单链表的相关操作,懒洋洋来这温习一下。一:单链表的定义链表定义:用链式存储的线性表统称为链表,即逻辑结构上连续,物理结构上不连续。链表分类:单链表、双链表、循环链表、静态链…...
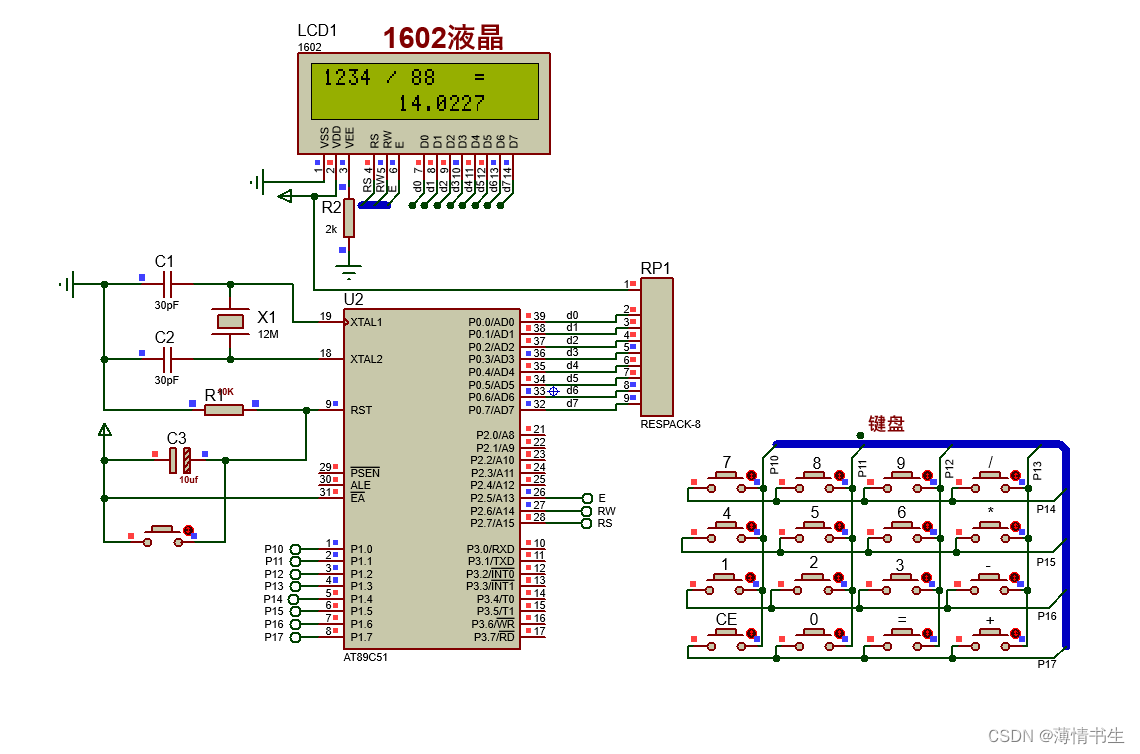
基于51单片机的智能计算器Protues仿真设计
目录 一、设计背景 二、实现功能 三、硬件设计 3.1 总体硬件设计 3.2 键盘电路的设计 3.3 显示电路的设计 四、仿真演示 五、源程序 一、设计背景 随着社会的发展,科学的进步,人们的生活水平在逐步的提高,尤其是微电子技术的发展&am…...

Pandas数据分析实战练习
Pandas数据分析实战练习 文章目录 Pandas数据分析实战练习一、读取Excel文件中的数据1、读取工号、姓名、时段、交易额这四列数据,使用默认索引,输出前10行数据2、读取第一个worksheet中所有列,跳过第1、3、5行,指定下标为1的列中数据为DataFrame的行索引标签二、筛选符合特…...
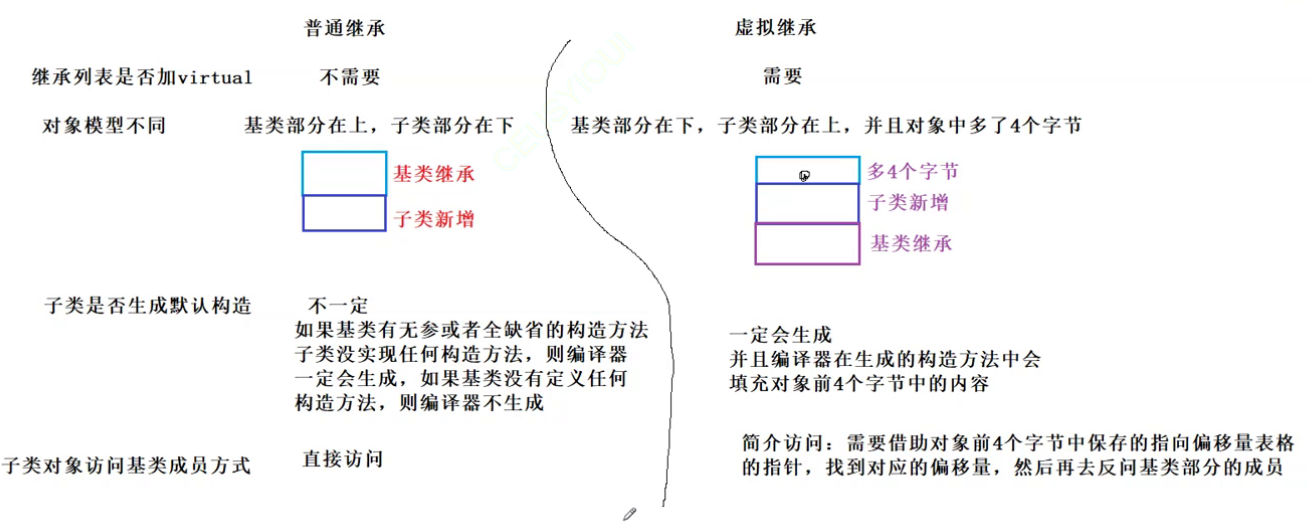
C++ 继承下(二篇文章学习继承所有知识点)
5.继承与友元友元关系不能继承,也就是说基类友元不能访问子类私有和保护成员 //验证友元不能继承 class B {friend void Print(); public:B(int b): _b(b){cout << "B()" << endl;}protected:int _b; };class D : public B { public:D(int b,…...
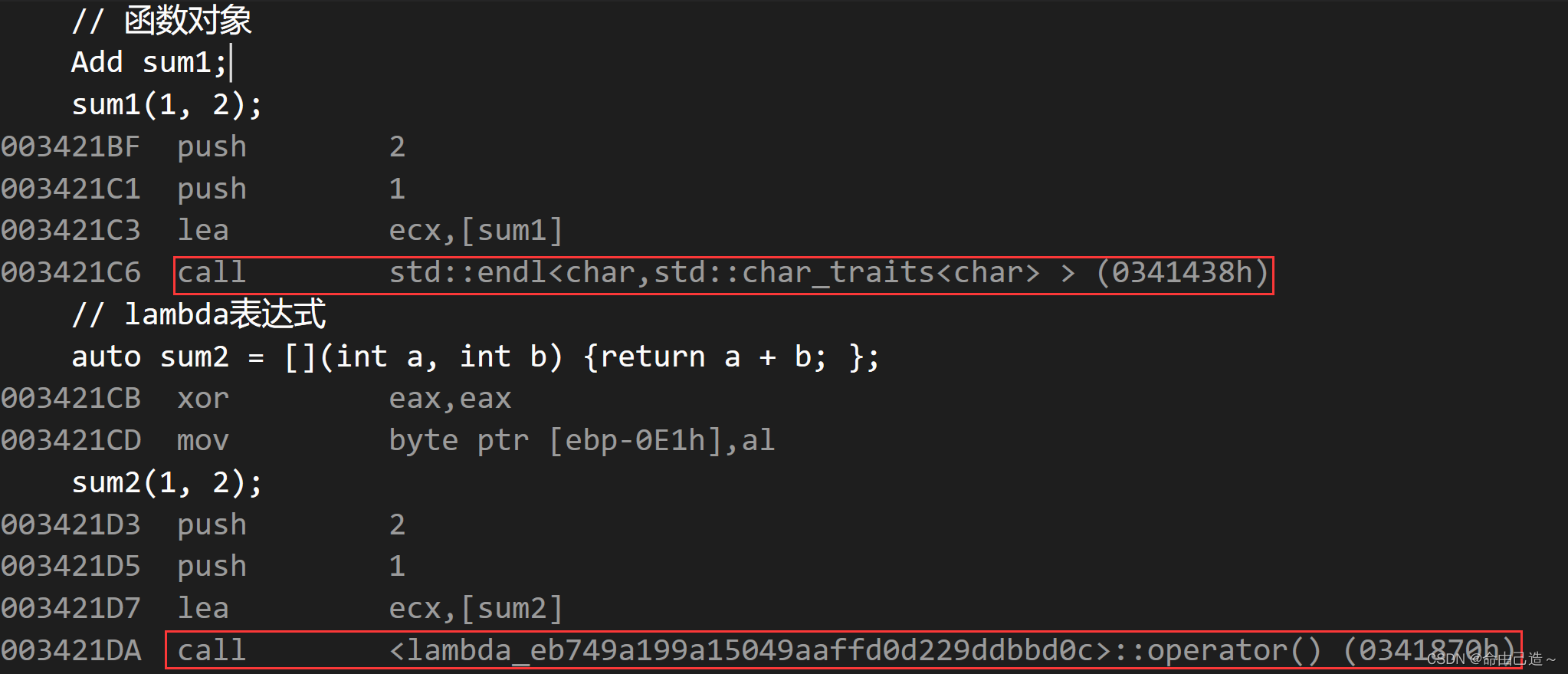
【C++】C++11新特性——类的改进|lambda表达式
文章目录一、类的改进1.1 默认生成1.2 移动构造函数1.3 移动赋值重载函数1.4 成员变量缺省值1.5 强制生成默认函数的关键字default1.6 禁止生成默认函数的关键字delete1.6.1 C98防拷贝1.6.1 C11防拷贝二、lambda表达式2.1 对比2.2 lambda表达式语法2.3 捕捉列表2.4 函数对象与l…...

C语言进阶(37) | 程序环境和预处理
目录 1.程序的翻译环境和执行环境 2.详解编译链接 2.1 翻译环境 2.2 编译本身也分为几个阶段: 2.3 运行环境 3.预处理详解 3.1预定符号 3.2 #define 3.3 #undef 3.4 命令行定义 3.5 条件编译 3.6 文件包含 了解重点: 程序的翻译环境程序的执行环境详解: C语言程…...

Golang每日一练(leetDay0005)
目录 13. 罗马数字转整数 Roman to Integer ★ 14. 最长公共前缀 Longest Common Prefix ★ 15. 三数之和 3Sum ★★★ 🌟 每日一练刷题专栏 🌟 Golang每日一练 专栏 Python每日一练 专栏 C/C每日一练 专栏 Java每日一练 专栏 13. 罗马数字转…...
occt_modeling_data(一)——拓扑
下面是我基于opencascade英文文档中关于occt_modeling_data中Topology部分进行的翻译,英文好的还是建议直接看文档,部分我不肯定的地方我会附上英文原句。如发现有错误欢迎评论区留言。 OCCT Topolog允许用户访问和操纵物体的数据,且不需要处…...
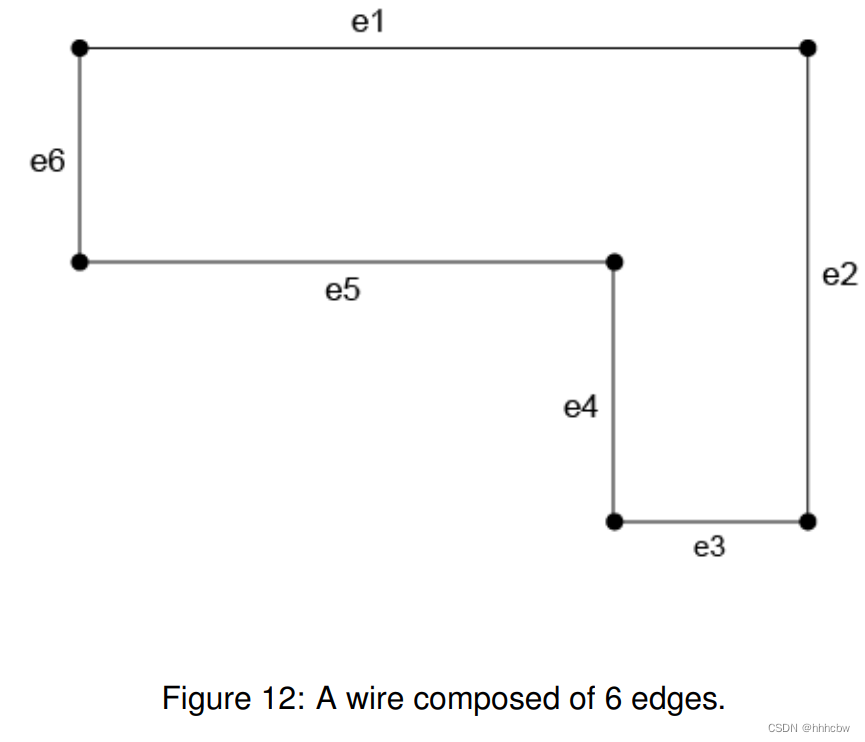
【AcWing】蓝桥杯备赛-深度优先搜索-dfs(3)
目录 写在前面: 题目:93. 递归实现组合型枚举 - AcWing题库 读题: 输入格式: 输出格式: 数据范围: 输入样例: 输出样例: 解题思路: 代码: AC &…...

宇宙最强-GPT-4 横空出世:最先进、更安全、更有用
文章目录前言一、准确性提升1.创造力2.视觉输入3.更长的上下文二、相比于ChatGPT有哪些提升1.GPT-4 的高级推理能力超越了 ChatGPT2.GPT-4 在多种测试考试中均优于 ChatGPT。三、研究团队在GPT-4模型都做了哪些改善1.遵循 GPT、GPT-2 和 GPT-3 的研究路径2.我们花了 6 个月的时…...
HashMap的实际开发使用
目 录 前言 一、HashMap是什么? 二、使用步骤 1.解析一下它实现的原理 编辑 2.实际开发使用 总结 前言 本章,只是大概记录一下hashMap的简单使用方法,以及理清一下hashMap的put方法的原理,以及get方法的原理。 一、Has…...

OpenCV入门(十三)快速学会OpenCV 12 图像梯度
OpenCV入门(十三)快速学会OpenCV 12 图像梯度1.Sobel算子1.1 计算x1.2 计算y1.3 计算xy2.Scharr算子2.1 计算x2.2 计算y2.3 计算xy3.Laplacian算子4.总结图像梯度计算的是图像变化的速度。对于图像的边缘部分,其灰度值变化较大,梯…...

软考:常见小题目计算题
01采购合同的类型采购合同主要包括总价类合同、成本补偿类合同、工料合同三大类合同。1、总价类合同此类合同为既定产品、服务或成果的采购设定一个总价。这种合同应在已明确定义需求,且不会出现重大范围变更的情况下使用。包括:(1࿰…...
【Linux】进程的程序替换
文章目录1. 程序替换1.创建子进程的目的是什么?2.了解程序是如何进行替换的3. 程序替换的基本原理当创建进程的时候,先有进程数据结构,还是先加载代码和数据?程序替换是整体替换,不是局部替换execl 返回值4. 替换函数1…...
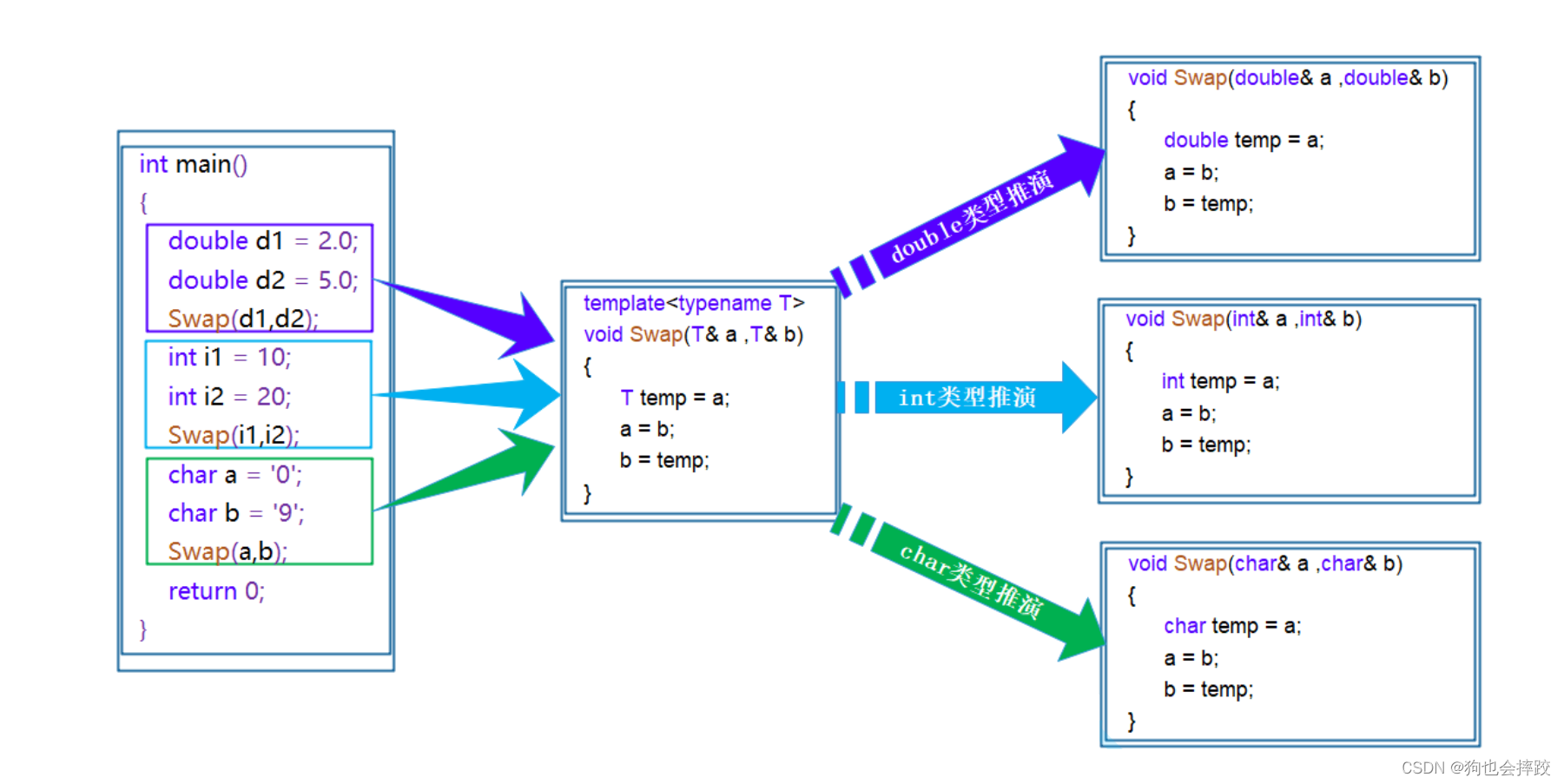
【C++】模板(上)
文章目录1、泛型编程2、函数模板函数模板的实例化模板参数的匹配原则3、 类模板类模板的实例化1、泛型编程 void Swap(int& left, int& right) {int temp left;left right;right temp; } void Swap(double& left, double& right) {double temp left;left …...
express框架利用formidable上传图片
express框架,在上传图片功能方面,用formidable里面的incomingform功能,很方便。很多功能都已经封装好了,非常好用,简单,不需要写更深层次的代码了。确实不错。 下面是我自己跟着黑马教程的博客系统的部分&…...
测试背锅侠?入职软件测试后大d佬给我丢了这个bug分类分析,至今受益匪浅......
目录:导读前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜)前言 刚成为入职…...
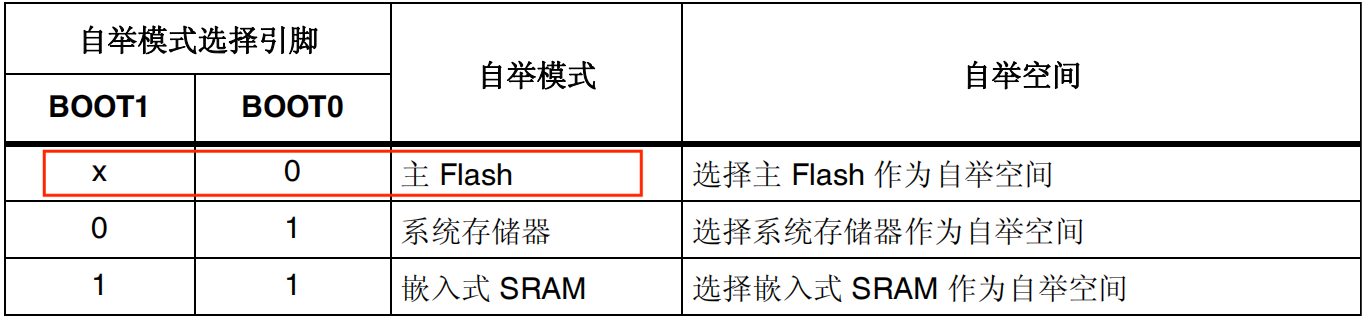
STM32 OTA应用开发——通过内置DFU实现USB升级(方式1)
STM32 OTA应用开发——通过内置DFU实现USB升级(方式1) 目录STM32 OTA应用开发——通过内置DFU实现USB升级(方式1)前言1 硬件介绍2 环境搭建2.1 Keil uVsion2.2 zadig2.3 STM32CubeProgrammer2.4 安装USB驱动3 OTA升级结束语前言 …...

ChatTTS最新模型解析:从架构设计到生产环境部署指南
最近在做一个需要语音合成的项目,之前用的一些开源TTS模型,要么音质不够自然,要么推理速度慢得让人着急。正好看到ChatTTS更新了,号称在自然度和效率上都有很大提升,就花时间深入研究了一下。这篇笔记就记录我从学习其…...

告别一刀切!SpringBoot Swagger未授权访问漏洞的优雅修复方案
1. 为什么不能直接禁用Swagger? 最近帮几个团队做安全审计时,发现90%的SpringBoot项目都存在Swagger未授权访问漏洞。安全团队通常会直接要求禁用Swagger,但开发团队往往叫苦连天——毕竟谁愿意放弃这个能自动生成文档的神器呢? 我…...

3步解锁硬件优化工具:华硕笔记本性能提升与温度控制完全指南
3步解锁硬件优化工具:华硕笔记本性能提升与温度控制完全指南 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops. Control tool for ROG Zephyrus G14, G15, G16, M16, Flow X13, Flow X16, TUF, Strix, Scar and other models 项…...

DeOldify图像上色结果导出:支持PNG/JPEG/WEBP多格式与DPI自定义设置
DeOldify图像上色结果导出:支持PNG/JPEG/WEBP多格式与DPI自定义设置 1. 引言:为什么需要关注导出设置? 当你用DeOldify给黑白照片上色后,最激动人心的时刻就是保存那张焕然一新的彩色照片。但你知道吗?不同的导出格式…...

Qwen3-VL-8B-Instruct-GGUF与VSCode的智能编程助手集成
Qwen3-VL-8B-Instruct-GGUF与VSCode的智能编程助手集成 1. 为什么要在VSCode中集成Qwen3-VL-8B-Instruct-GGUF 你是否经常在写代码时卡在某个函数的用法上,反复翻文档却找不到关键示例?或者调试时面对一堆报错信息,花半小时才定位到那个少写…...

人味护盾:软件测试工程师在AI时代的价值重构与晋升路径
一、AI重构测试生态:危机中的转机2026年的测试领域正经历三重颠覆:工具层:AI测试脚本生成覆盖率突破80%(Gartner 2025报告)流程层:DevOps流水线实现需求→用例→执行的秒级闭环决策层:缺陷预测模…...

MSPM0L1306开发四大高频问题与硬件级解决方案
1. MSPM0L1306开发常见问题深度解析与工程实践指南在基于TI MSPM0L1306微控制器的嵌入式开发实践中,工程师常遭遇一系列具有共性的构建、配置与调试障碍。这些问题虽不涉及核心算法或复杂外设驱动逻辑,却直接影响开发效率与项目进度。本文从工程落地角度…...

如何用dc.js打造震撼可再生能源数据可视化:能源转型分析指南
如何用dc.js打造震撼可再生能源数据可视化:能源转型分析指南 【免费下载链接】dc.js Multi-Dimensional charting built to work natively with crossfilter rendered with d3.js 项目地址: https://gitcode.com/gh_mirrors/dc/dc.js dc.js是一个基于d3.js和…...

ni命令重构指南:如何改进现有ni功能并提升开发者体验
ni命令重构指南:如何改进现有ni功能并提升开发者体验 【免费下载链接】ni 💡 Use the right package manager 项目地址: https://gitcode.com/gh_mirrors/ni1/ni ni是一个智能包管理器切换工具,能够自动检测项目使用的包管理器&#x…...

Llama-3.2-3B应用场景:Ollama部署后构建个人知识管理AI助理实战案例
Llama-3.2-3B应用场景:Ollama部署后构建个人知识管理AI助理实战案例 1. 引言:为什么需要个人知识管理AI助理 你有没有遇到过这样的情况:电脑里存了几百篇技术文档、学习笔记和研究资料,但当需要找某个特定信息时,却像…...