一、快速入门 MongoDB 数据库
文章目录
- 一、NoSQL 是什么
- 1.1 NoSQL 简史
- 1.2 NoSQL 的种类及其特性
- 1.3 NoSQL 特点
- 1.4 NoSQL 的优缺点
- 1.5 NoSQL 与 SQL 数据库的比较
- 二、MongoDB 基础知识
- 2.1 MongoDB 是什么
- 2.2 MongoDB 的体系结构
- 2.3 MongoDB 的特点
- 2.4 MongoDB 键特性
- 2.5 MongoDB 的核心服务和工具
- 2.6 MongoDB 应用场景
- 2.7 MongoDB 数据模型
- 2.7.1 数据模型
- 2.7.2 多态模式
- 三、MongoDB 的安装配置及可视化工具
- 四、MongoDB 数据库管理
- 4.1 MongoDB shell
- 4.2 MongoDB shell 命令
- 4.3 MongoDB shell 原生方法
- 4.4 MongoDB 的基本操作
- 4.4.1 MongoDB 数据库的连接
- 4.4.2 数据库
- 4.4.3 集合
- 4.4.4 文档
- 4.4.5 数据类型
- 4.4.6 索引
本文主要介绍
NoSQL 数据库的发展以及它其中最热门的
MongoDB 数据库基础知识。通过本文内容的学习,读者可以学习到
MongoDB 数据库安装方式以及
MongoDB 的基础使用等。
一、NoSQL 是什么
NoSQL,泛指非关系型数据库。 随着互联网 Web 2.0 网站的兴起,传统的关系型数据库在应付 Web 2.0 网站,特别是超大规模和高并发的 SNS 类型的 Web 2.0 纯动态网站时已经显得力不从心,暴露了很多难以克服的问题,而非关系型数据库则由于其自身的特点得到了非常迅速的发展。NoSQL 数据库的产生就是为了应对大规模数据集合以及多重数据种类带来的挑战,尤其是大数据应用难题。
1.1 NoSQL 简史
NoSQL 一词最早出现于 1998 年,是 Carlo Strozzi 开发的一个轻量、开源、不提供 SQL 功能的关系型数据库。2009年,Last.fm 的 Johan Oskarsson 发起了一次关于分布式开源数据库的讨论,来自 Rackspace 的 Eric Evans 再次提出了 NoSQL 的概念,这时的 NoSQL 主要指非关系型、分布式、不提供 ACID 的数据库设计模式。
2009年在亚特兰大举行的 no:sql(east) 讨论会是一个里程碑,其口号是 select fun, profit from real_world where relational=false;。 因此,对 NoSQL 最普遍的解释是 非关联型的,强调 Key-Value Stores 和文档数据库的优点,而不是单纯地反对 RDBMS。
1.2 NoSQL 的种类及其特性
NoSQL 数据库有多种类型,每种类型都有各自的特点,如下表所示:

下面介绍两种不同类型的数据库。面向列的数据库:
Cassandra、HBase、HyperTable属于这种类型。普通的关系型数据库都是以行为单位来存储数据的,擅长以行为单位读入数据,比如特定条件数据的获取。因此,关系型数据库也被称为面向行的数据库。相反,面向列的数据库是以列为单位来存储数据的,擅长以列为单位读入数据。面向列的数据库具有高扩展性,即使数据增加也不会降低相应的处理速度 (特别是写入速度),所以它主要应用于需要处理大量数据的情况。另外,把它作为批处理程序的存储器来对大量数据进行更新也是非常有用的。但由于面向列的数据库跟现行数据库存储的思维方式有很大不同,故应用起来十分困难。
面向文档的数据库:
MongoDB、CouchDB属于这种类型,它们属于NoSQL数据库,但与键值存储相异。1、不定义表结构。 即使是不定义表结构,也可以像定义表结构一样使用,还省去了变更表结构的麻烦。2、可以使用复杂的查询条件。 与键值存储不同的是,面向文档的数据库可以通过复杂的查询条件来获取数据,虽然不具备事务处理和Join这些关系型数据库所具有的处理能力,但除此以外的其他处理基本上都能实现。3、键值存储的数据库。 它的数据是以键值的形式存储的,虽然它的速度非常快,但基本上只能通过键的完全一致查询获取数据,根据数据的保存方式可以分为临时性、永久性和两者兼具三种。
补充:
1、临时性。 所谓临时性就是数据有可能丢失,memcached 把所有数据都保存在内存中,这样保存和读取的速度非常快,但是当 memcached 停止时,数据就不存在了。由于数据保存在内存中,所以无法操作超出内存容量的数据,旧数据会丢失。总体来说,在内存中保存数据、可以进行非常快速的保存和读取处理、数据有可能丢失。
2、永久性。 所谓永久性就是数据不会丢失,这里的键值存储是把数据保存在硬盘上,与临时性比起来,由于必然要发生对硬盘的 IO 操作,所以性能上还是有差距的,但数据不会丢失是它最大的优势。总体来说,在硬盘上保存数据、可以进行非常快速的保存和读取处理(但无法与 memcached 相比)、数据不会丢失。
3、两者兼具。 Redis 属于这种类型。Redis 有些特殊,临时性和永久性兼具。Redis 首先把数据保存在内存中,在满足特定条件(默认是15分钟一次以上,5分钟内10个以上,1分钟内10000个以上的键发生变更)的时候将数据写入到硬盘中,这样既确保了内存中数据的处理速度,又可以通过写入硬盘来保证数据的永久性,这种类型的数据库特别适合处理数组类型的数据。总体来说,同时在内存和硬盘上保存数据、可以进行非常快速的保存和读取处理、保存在硬盘上的数据不会消失(可以恢复)、适合于处理数组类型的数据。
1.3 NoSQL 特点
关系型数据库经过几十年的发展,各种优化工作已经做得很深了,而 NoSQL 系统也从中吸收了关系型数据库的技术,我们从系统设计的角度来了解一下 NoSQL 数据库的四大特点。
1、索引支持。 关系型数据库创立之初没有想到今天的互联网应用对可扩展性提出如此高的要求,因此,设计时主要考虑的是简化用户的工作,SQL 语言的产生促成数据库接口的标准化,从而形成了 Oracle 这样的数据库公司并带动了上下游产业链的发展。关系型数据库的单机存储引擎支持索引,比如 MySQL 的 InnoDB 存储引擎需要支持索引,而 NoSQL 系统的单机存储引擎是纯粹的,只需要支持基于主键的随机读取和范围查询。NoSQL 系统在系统层面提供对索引的支持,比如有一个用户表,主键为 user_id,每个用户有很多属性,包括用户名,照片 ID(photo_id),照片 URL,在 NoSQL 系统中如果需要对 photo_id 建立索引,可以维护一张分布式表,表的主键为形成的二元组。关系型数据库由于需要在单机存储引擎层面支持索引,大大降低了系统的可扩展性,使得单机存储引擎的设计变得很复杂。
2、并发事务处理。 关系型数据库有一整套的关于事务并发处理的理论,比如锁的粒度是表级、页级还是行级,多版本并发控制机制 MVCC,事务的隔离级别,死锁检测,回滚,等等。然而,互联网应用大多数的特点都是多读少写,比如读和写的比例是 10:1,并且很少有复杂事务需求,因此,一般可以采用更为简单的 copy-on-write 技术:单线程写,多线程读,写的时候执行 copy-on-write,写不影响读服务。NoSQL 系统这样的假设简化了系统的设计,减少了很多操作的 overhead,提高了性能。
3、数据结构。 关系型数据库的存储引擎的数据结构是一棵磁盘 B+ 树,为了提高性能,可能需要有 Insert Buffer 聚合写,Query Cache 缓存读,经常需要实现类似 Linux page cache 的缓存管理机制。数据库中的读和写是互相影响的,写操作也因为时不时需要将数据输出到磁盘而性能不高。简而言之,关系型数据库存储引擎的数据结构是通用的动态更新的 B+ 树。然而,在 NoSQL 系统中,比如 Bigtable 中采用 SSTable+MemTable 的数据结构,数据先写入到内存的 MemTable,达到一定大小或者超过一定时间才会备份到磁盘生成 SSTable 文件, SSTable 是只读的。如果说关系型数据库存储引擎的数据结构是一棵动态的 B+ 树,那么 SSTable 就是一个排好序的有序数组。很明显,实现一个有序数组比实现一棵动态 B+ 树且包含复杂的并发控制机制要简单高效得多。
4、Join操作。 关系型数据库需要在存储引擎层面支持 Join,而 NoSQL 系统一般根据应用来决定 Join 实现的方式。举个例子,有两张表:用户表和商品表,每个用户下可能有若干个商品,用户表的主键为 user_id,用户和商品的关联属性存放在用户表中,商品表的主键为 item_id,商品属性包括商品名和商品 URL,等等。假设应用需要查询一个用户的所有商品并显示商品的详细信息,普通的做法是先从用户表查找指定用户的所有 item_id,然后对每个 item_id 去商品表查询详细信息,即执行一次数据库 Join 操作,这必然带来了很多的磁盘随机读,并且由于 Join 带来的随机读的局部性不好,缓存的效果往往也是有限的。在 NoSQL 系统中,我们往往可以将用户表和商品表集成到一张宽表中,这样虽然存储了额外的信息,但却换来了查询的高效。
1.4 NoSQL 的优缺点
业界为了解决更多用户的需求,推出了多款新类型的数据库,并且由于它们在设计上和传统的 NoSQL 数据库相比有很大的不同,所以被统称为 NoSQL 系列数据库。总的来说,在设计上,它们非常关注对数据高并发读写和对海量数据的存储等,与关系型数据库相比,它们在架构和数据模型方面做了 减法,而在扩展和并发等方面做了 加法。现在主流的 NoSQL 数据库有 BigTable、HBase、Cassandra、SimpleDB、CouchDB、MongoDB 和 Redis 等。接下来,我们了解一下 NoSQL 数据库到底存在哪些优缺点。在优势方面,主要体现在下面这三点:
1、简单的扩展。 典型例子是 Cassandra,由于其架构是类似于经典的 P2P,所以能通过轻松地添加新的节点来扩展这个集群。
2、快速的读写。 主要例子有 Redis,由于其逻辑简单,而且纯内存操作,使得其性能非常出色,单节点每秒可以处理超过 10万次 读写操作。
3、低廉的成本。 这是大多数分布式数据库共有的特点,因为主要都是开源软件,没有昂贵的许可证成本。虽然有以上优势,但 NoSQL 数据库还存在着很多的不足,常见的主要有下面这几个:
1、不提供对 SQL 的支持。 如果不支持 SQL 这样的工业标准,将会对用户产生一定的学习和应用迁移成本。
2、支持的特性不够丰富。 现有产品所提供的功能都比较有限,大多数 NoSQL 数据库都不支持事务,也不像 SQL Server 和 Oracle 那样能提供各种附加功能,比如 BI 和报表等。
3、现有产品的不够成熟。 大多数产品都还处于初创期,和关系型数据库几十年的完善不可相提并论。上面 NoSQL 产品的优缺点都是共通的,在实际情况下,每个产品都会根据自己所遵从的数据模型和 CAP 理念而有所不同。
1.5 NoSQL 与 SQL 数据库的比较
在日常的编码中,我们常用的是 SQL(结构化的查询语言) 数据库,SQL 是过去几十年间存储数据的主要方式。现在主流的 SQL 主要有 MySQL、SQL Server、Oracle 等数据库。NoSQL 数据库自从 20世纪60年代 就已经存在了,现在主流的 NoSQL 有 MongoDB、CouchDB、Redis 和 Memcache 等数据库。SQL 和 NoSQL 有着相同的目标:存储数据。 但是它们存储数据的方式不同,这可能会影响到你开发的项目,一种会简化你的开发,一种会阻碍你的开发。尽管目前 NoSQL 数据库非常火爆,但是 NoSQL 尚不能取代 SQL ——它仅仅是 SQL 的一种替代品。SQL 和 NoSQL 没有明显的区别。一些 SQL 数据库也采用了 NoSQL 数据库的特性,反之亦然。在选择数据库方面的界限变得越来越模糊了,并且一些新的混合型数据库将会在不久的将来提供更多的选择。SQL 和 NoSQL 的区别:
- SQL 数据库提供关系型的表来存储数据,NoSQL 数据库采用类 JSON 的键值对来存储文档。SQL 中的表结构具有严格的数据模式约束,因此存储数据很难出错。NoSQL 存储数据更加灵活自由,但是也会导致数据不一致性问题的发生。
- 在 SQL 数据库中,除非你事先定义了表和字段的模式否则你无法向其中添加数据。在 NoSQL 数据库中,数据在任何时候都可以进行添加,不需要事先去定义文档和集合。SQL 在进行数据的逻辑操作之前我们必须要定义数据模式,数据模式可以在后期进行更改,但是对于模式的大改将会是非常复杂的。因此 NoSQL 数据库更适合于那些不能够确定数据需求的工程项目(MongoDB 会在集合中为每一个文档添加一个独一无二的id。如果你仍然想要定义索引,你也可以自己在之后定义)。模式中包含了许多的信息:主键——独一无二的标志就像 ISBN 唯一确定一个书号。索引——通常设置索引字段加快搜索的速度。关系——字段之间的逻辑连接。
- SQL 具有数据库的规范化。NoSQL 虽然可以同样使用规范化,但是更倾向于非规范化。在 SQL 中我们需要增加一张新表 tableB,一张旧表 tableA 关联新表只需使用外键 B_id,用于引用 tableB 中的信息,这样的设计能够最小化数据的冗余,我们不需要为 tableA 重复添加 tableB 的所有信息——只需要去引用就可以了。这项技术叫作数据库的规范化,具有实际的意义。我们可以更改 tableB 的信息而不用修改 tableA 中的数据。而 NoSQL 更多的是在 tableA 中为每项数据添加 tableB 的信息,这样会使查询更快,但是在更新信息的记录变多时效率将会显著下降。
- SQL 具有 Join 操作,NoSQL 则没有。SQL 语言为查询提供了强大的 Join 操作。我们可以使用单个 SQL 语句在多个表中获取相关数据。而在 NoSQL 中没有与 Join 相同的操作,对于具有 SQL 语言经验的人来说是非常令人震惊的,这也是非规范化存在的原因之一。
- SQL 具有数据完整性,NoSQL 则不具备数据完整性。大多数的数据库允许通过定义外键来进行数据库的完整性约束。在 NoSQL 数据库中则没有数据完整性的约束选项,你可以存储任何你想要存储的数据。理想情况下,单个文档将是项目所有信息的唯一来源。
- SQL 需要自定义事务。NoSQL 操作单个文档时具备事务性,而操作多个文档时则不具备事务性。在 SQL 数据库中,两条或者多条更新操作可以结合成一个 事务(或者全部执行成功否则失败) 执行。将两条更新操作绑定为一个事务确保了它们要么全部成功要么全部失败。在 NoSQL 数据库中,对于一个文档的更新操作是原子性的。换句话说,如果你要更新一个文档中的三个值,要么三个值都更新成功要么它们保持不变。然而,对于操作多个文档时没有与事务相对应的操作。在 MongoDB 中有一个操作是 transaction-like options,但是,需要我们手动地加入到代码中。
- SQL 使用 SQL 语言,NoSQL 使用类 JSON。SQL 是一种声明性语言。SQL 语言的功能强大,并且已经成为了一种国际的通用标准,尽管大多数系统在语法上有一些细微的差别。NoSQL 数据库使用类似 JSON 为参数的 JavaScript 来进行查询,基本操作是相同的,但是嵌套的 JSON 将会产生复杂的查询。
- NoSQL 比 SQL 更快。通常情况下,NoSQL 比 SQL 语言更快。这并没有什么好震惊的,NoSQL 中更加简单的非规范化存储允许我们在一次查询中得到特定项的所有信息,不需要使用 SQL 中复杂的 Join 操作。也就是说,你的项目的设计和数据的需求会有很大的影响。一个好的 SQL 数据库一定会比一个不好的 NoSQL 数据库性能好很多,反之亦然。
二、MongoDB 基础知识
MongoDB 是一个跨平台的、面向文档的数据库,是当前 NoSQL 数据库产品中最热门的一种。下面我们来认识一下 MongoDB。
2.1 MongoDB 是什么
MongoDB 是一个基于分布式文件存储的数据库。由 C++ 语言编写。旨在为 Web 应用提供可扩展的高性能数据存储解决方案。MongoDB 是一个介于关系型数据库和非关系型数据库之间的产品,是非关系型数据库当中功能最丰富、最像关系型数据库的。它支持的数据结构非常松散,是类似 JSON 的 BSON 格式,因此可以存储比较复杂的数据类型。MongoDB 最大的特点是它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
2.2 MongoDB 的体系结构
MongoDB 的逻辑结构是一种层次结构,主要由 文档(document)、集合(collection)、数据库(database) 这三部分组成。逻辑结构是面向用户的,用户使用 MongoDB 开发应用程序使用的就是逻辑结构:
- MongoDB 的文档,相当于关系数据库中的一行记录。
- 多个文档组成一个集合,相当于关系数据库的表。
- 多个集合逻辑上组织在一起,就是数据库。
- 一个 MongoDB 实例支持多个数据库。
文档、集合、数据库的层次结构如下图所示:

2.3 MongoDB 的特点
MongoDB 最大的特点是它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。它是一个面向集合的,模式自由的文档型数据库。具体特点总结如下:
- 面向集合存储,易于存储对象类型的数据。
- 模式自由。
- 支持动态查询。
- 支持完全索引,包含内部对象。
- 支持复制和故障恢复。
- 使用高效的二进制数据存储,包括大型对象(如视频等)。
- 自动处理碎片,以支持云计算层次的扩展性。
- 支持 Python、PHP、Ruby、Java、C、C#、JavaScript、Perl 及 C++ 语言的驱动程序,社区中也提供了对 Erlang 及
.NET等平台的驱动程序。 - 文件存储格式为 BSON(一种JSON的扩展)。
2.4 MongoDB 键特性
MongoDB 的设计目标是高性能、可扩展、易部署、易使用,存储数据非常方便,其主要功能特性如下:
1、文档数据类型。 SQL 类型的数据库是正规化的,可以通过主键或者外键的约束保证数据的完整性与唯一性,所以 SQL 类型的数据库常用于对数据完整性要求较高的系统。MongoDB 在这一方面是不如 SQL 类型的数据库的,且 MongoDB 没有固定的 Schema,正因为 MongoDB 少了一些这样的约束条件,可以让数据的存储数据结构更灵活,存储速度更快。
2、即时查询能力。 MongoDB 保留了关系型数据库即时查询的能力,保留了索引(底层是基于B树)的能力。这一点汲取了关系型数据库的优点,同类型的 NoSQL Redis 则没有上述的能力。
3、复制能力。 MongoDB 自身提供了副本集能将数据分布在多台机器上实现冗余,目的是可以提供自动故障转移、扩展读能力。
4、速度与持久性。 MongoDB 的驱动实现一个写入语义 fire and forget,即通过驱动调用写入时,可以立即得到返回成功的结果(即使是报错),这样让写入的速度更快,当然会有一定的不安全性,完全依赖网络。
5、数据扩展。 MongoDB 使用分片技术对数据进行扩展,MongoDB 能自动分片、自动转移分片里面的数据块,让每一个服务器里面存储的数据都是一样大小。
2.5 MongoDB 的核心服务和工具
MongoDB 是用 C++ 编写的,由 10gen 积极维护。该项目能在所有主流操作系统上编译,包括 Mac OS X、Windows 和大多数 Linux。MongoDB.org 上提供了这些平台的预编译二进制包。MongoDB 是开源的,遵循 GNU-AGPL 许可,GitHub 上可以免费获取到源代码,而且经常会接受来自社区的贡献,但这一项目主要还是由 10gen 的核心服务器团队来领导的,绝大多数提交亦来自该团队。
1、核心服务器。 通过可执行文件 mongod(Windows 上是 MongoDB.exe)可以运行核心服务器。mongod 服务器进程使用一个自定义的二进制协议从网络套接字上接收命令。mongod 进程的所有数据文件默认都存储在 /data/db 里。mongod 有多种运行模式,最常见的是作为副本集中的一员。因为推荐使用复制,通常副本集由两个副本组成,再加一个部署在第三台服务器上的仲裁进程。对于 MongoDB 的自动分片架构而言,其组件包含配置为预先分片的副本集的 mongod 进程,以及特殊的元数据服务器,称为配置服务器。另外还有单独的名为 mongos 的路由服务器向适当的分片发送请求。相比其他的数据库系统,例如 MySQL,配置一个 mongod 进程相对比较简单。虽然可以指定标准端口和数据目录,但没有什么调优数据库的选项。在大多数 RDBMS 中,数据库调优意味着通过一大堆参数来控制内存分配等内容,这已经变成了一门黑魔法。MongoDB 的设计哲学指出,内存管理最好是由操作系统而非 DBA 或应用程序开发者来处理。如此一来,数据文件通过 mmap() 系统调用被映射成了系统的虚拟内存。这一举措行之有效地将内存管理的重任交给了操作系统内核。后续还会更多地阐述与 mmap() 相关的内容,不过目前只需要知道缺少配置参数是系统设计亮点,而非缺陷。
2、JavaScript Shell。 MongoDB 命令行 Shell 是一个基于 JavaScript 的工具,用于管理数据库和操作数据。可执行文件 mongod 会加载 Shell 并连接到指定的 mongod 进程。MongoDB Shell 的功能和 MySQL Shell 差不多,主要的区别在于不使用 SQL,大多数命令使用的是 JavaScript 表达式。除了可以插入和查询数据,Shell 还可以用于运行管理命令。例如,查看当前数据库操作、检查到从节点的复制状态,以及配置一个用于分片的集合。
3.数据库驱动。 MongoDB 的驱动很容易使用,MongoDB 团队竭尽全力提供符合特定语言风格的 API,并同时保持跨语言、相对统一的接口。例如,所有驱动都实现了向集合保存文档的方法,但不同语言里文档本身的表述通常会有所不同,驱动尽量会对特定语言表现得更自然一些。例如,在 Ruby 中就是使用一个 Ruby 散列,在 Python 中字典更合适一点,Java 中缺少类似的语言原语,需要使用 LinkedHashMap 类实现的特殊文档来表示文档。由于驱动程序为数据库开发人员提供了一个标准的 API,因此可以构建更高级的工具和接口。数据库开发人员使用 Java API 编写的数据库应用程序,不但可以跨平台运行,而且还不受数据库供应商的限制。这与使用 RDBMS 的应用程序设计截然不同,在数据库的关系型数据模型和大多数现代编程语言的面向对象模型之间几乎都需要有一个库来做中介。虽然不需要 对象关系映射器(object-relational mapper),但很多开发者都喜欢在驱动上做一层薄薄的封装,用它来处理关联、验证和类型检查。
4、命令行工具。 MongoDB 自带了很多命令行工具。mongodump 和 mongorestore:备份和恢复数据库的标准工具。mongodump 用原生的 BSON 格式将数据库的数据保存下来,因此最好只是用来做备份,其优势是热备时非常有用,备份后能方便地用 mongorestore 恢复。mongoexport 和 mongoimport:用来导入导出 JSON、CSV 和 TSV 数据,数据需要支持多种格式时很有用。mongoimport 还能用于大数据集的初始导入,但是在导入前顺便还要注意一下,为了能充分利用好 MongoDB 通常需要对数据模型做些调整。在这种情况下,通过使用驱动的自定义脚本来导入数据会更方便一些。mongosniff:这是一个网络嗅探工具,用来观察发送到数据库的操作。基本就是把网络上传输的 BSON 转换为易于人们阅读的 Shell 语句。mongostat:它与 iostat 类似,持续轮询 MongoDB 和系统以便提供有帮助的统计信息,包括每秒操作数(插入、查询、更新、删除等)、分配的虚拟内存数量以及服务器的连接数。
2.6 MongoDB 应用场景
MongoDB 的主要目标是在键值存储方式(提供了高性能和高度伸缩性)和传统的 RDBMS 系统(具有丰富的功能)之间架起一座桥梁,它集两者的优势于一身。根据官方网站的描述,MongoDB 适用于以下场景:
- 网站数据:MongoDB 非常适合实时的插入、更新与查询,并具备网站实时数据存储所需的复制及高度伸缩性。
- 缓存:由于性能很高,MongoDB 也适合作为信息基础设施的缓存层。在系统重启之后,由 MongoDB 搭建的持久化缓存层可以避免下层的数据源过载。
- 大尺寸、低价值的数据:使用传统的关系型数据库存储一些数据时可能会比较昂贵,在此之前,很多时候程序员往往会选择传统的文件进行存储。
- 高伸缩性的场景:MongoDB 非常适合由数十或数百台服务器组成的数据库,MongoDB 的路线图中已经包含对 MapReduce 引擎的内置支持。
- 用于对象及 JSON 数据的存储:MongoDB 的 BSON 数据格式非常适合文档化格式的存储及查询。MongoDB 的使用也会有一些限制,例如,它不适合于以下几个地方:
高度事务性的系统:例如,银行或会计系统。传统的关系型数据库目前还是更适用于需要大量原子性复杂事务的应用程序。 传统的商业智能应用:针对特定问题的BI数据库会产生高度优化的查询方式。对于此类应用,数据仓库可能是更合适的选择。
2.7 MongoDB 数据模型
对于 MongoDB 而言,本身数据格式非常灵活,即在同一个 Collection 中,不同的 Document 的格式也无需一致。但是,在实际使用中,我们首先也会对数据结构进行一些基本的设计。同时,MongoDB 本身也提供了一些与数据模型相关的功能,可以用于验证数据格式等信息,下面将会讲解 MongoDB 的数据模型。
2.7.1 数据模型
MongoDB 的数据模式是一种灵活模式。关系型数据库要求你在插入数据之前必须先定义好一个表的模式结构,而 MongoDB 的集合则并不限制 document 结构。这种灵活性让对象和数据库文档之间的映射变得很容易。即使数据记录之间有很大的变化,每个文档也可以很好地映射到各条不同的记录。当然在实际使用中,同一个集合中的文档往往都有一个比较类似的结构。
1、文档结构。 MongoDB 是面向集合存储的文档型数据库,其涉及到的基本概念与关系型数据库有所不同,如下表所示:
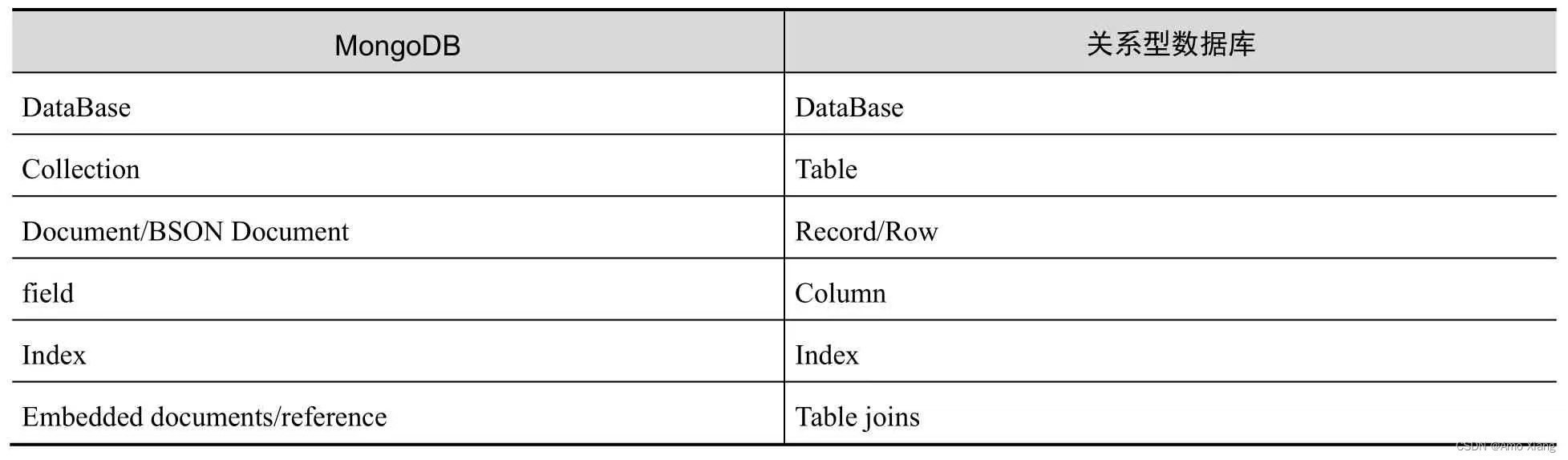
文档是 MongoDB 最核心的概念,本质上是一种类 JSON 的 BSON 格式的数据。BSON 是一种类 JSON 的二进制格式的数据,它可以理解为在 JSON 基础上添加了一些新的数据类型,包括 日期、int32、int64 等。BSON 是由一组组键值对组成,它具有轻量性、可遍历性和高效性三个特征。
2、嵌套与引用。 文档的数据模型代表了数据的组织结构,一个好的数据模型能更好地支持应用程序。在 MongoDB 中,文档有两种数据模型,内嵌(embed) 和 引用(references)。
内嵌: 内嵌方式指的是把相关联的数据保存在同一个文档结构之内。MongoDB 的文档结构允许一个字段或者一个数组内的值为一个嵌套的文档。这种冗余的数据模型可以让应用程序在一个数据库操作内完成对相关数据的读取或修改。嵌套型的使用方式如下图所示:
内嵌类型支持一组相关的数据存储在一个文档中,这样的好处就是,应用程序可以通过比较少的查询和更新操作来完成一些常规的数据的查询和更新工作。通常,对于一对一关系或者简单的一对多的关系,我们会使用嵌套型数据。
引用: 引用方式通过存储链接或者引用信息来实现两个不同文档之间的关联。应用程序可以通过解析这些数据库引用来访问相关数据。简单来讲,这就是规范化的数据模型。引用型的使用方式如下图所示:
在这个模型中,把 contact 和 access从user 中移出,并通过 user_id 作为索引来表示它们之间的联系。对于引用型关系而言,不同 Collection 之间通过 _id 进行关联,从而最终组合获得整体的数据。

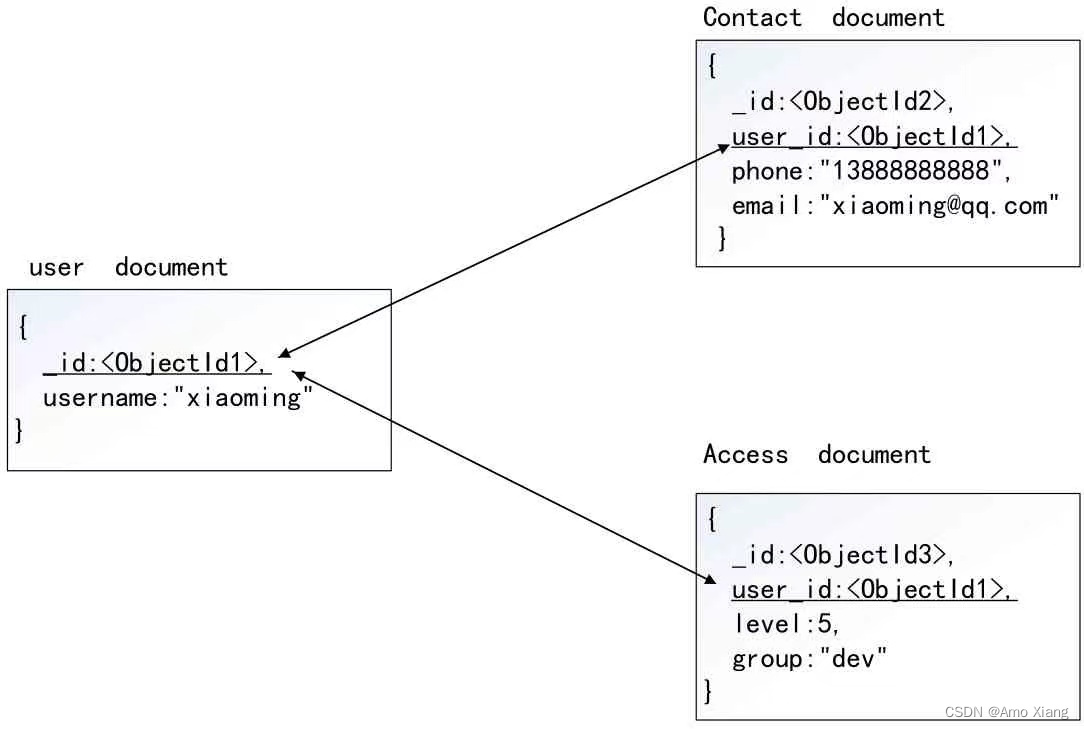
通常,对于多对多关系或者复杂的一对多的关系,我们会使用引用型数据,因为随着单条数据量的增加,性能将会有所下降。
3、原子写操作。 在 MongoDB 中,写操作在文档级别上是原执行的,没有一个单一的写操作可以对原子的影响多于一个文档或者是集合。一个包含嵌入式数据非标准化的数据模型和相关的数据代表了一个单一的文档。这些有利于原子写操作,因为对一个实体一个单一的写操作可以插入或者更新数据,标准化数据将把数据分散在多个集合中,这样就会要求多个写操作,也就是说不是集体原子执行。但是,有利于原子写的模式或许会限制应用程序可以使用的数据或者限制修改应用的方法,原子性地考虑文档描述了设计模式平衡灵活性和原子性的挑战。
4、文档增长。 一些更新,例如一些增加域或者在数组中增加元素,都会加大文档的大小。对于 MMAPv1 存储引擎,如果文档的大小超过为文档分配的空间的大小,MongoDB 将会在文档上迁移文档,当我们使用 MMAPv1 存储引擎时,文档的大小可以影响标准化与非标准化数据的决策。
2.7.2 多态模式
MongoDB 又被称为 无模式 的数据库,它不强制要求集合的文档拥有特定的结构。不考虑应用的结构,将应用中每个对象存储在相同的集合是合法的,尽管效率上存在问题。然而优秀的应用中常见的情景是集合会包含完全相关或密切关联的文档结构。当集合中所有文档结构都是类似的,但不是完全相同的称之为多态模式。
1、多态模式支持面向对象编程。 面向对象编程中,习惯通过继承使得不同对象共享数据和行为。面向对象语言允许函数像操作父类一样操作子类,调用在父类中定义的方法。
2、多态模式使得模式进化成为可能。 开发数据库驱动应用时,程序员有一个需要考虑的事情就是模式进化。典型的是使用迁移脚本将数据库从一个模式升级为另一个。在应用配置在线数据前,迁移操作可能包含删除数据库并使用新的模式重新创建数据库。然而,一旦应用是在线时,模式更改需通过复杂的迁移脚本来实现在保存内容的同时更改格式。关系型数据库通过 ALTER TABLE 语句来支持迁移,可使用它添加或删除列。ALTER TABLE 语句最大的缺陷在于处理大量行数据的表时会十分耗时,而且在迁移的时候应用需下线,因为 ALTER TABLE 需锁定数据表文档来执行迁移。
3、BSON 的存储效率。 MongoDB 有一个主要的特点是缺乏强制模式(存储效率),RDBMS 中列名和类型格式在表级定义,因此无须在行级重复该信息。对比 MongoDB 来说,不知道在集合级别每个文档有哪些字段,也不知道这些字段的类型,因此每个文档都需要存储字段名和类型。特别是在文档中存储一个较小的值(整型、日期、短字符、…),并使用很长的属性名时,MongoDB 将造成使用比 RDBMS 更多的存储空间存储相同的数据。一种减轻影响的方法是在 MongoDB 中的文档上使用短字段名,但该方法会导致很难在 Shell 中直接查看数据库。
三、MongoDB 的安装配置及可视化工具
https://blog.csdn.net/xw1680/article/details/127626145
https://blog.csdn.net/xw1680/article/details/126659241
四、MongoDB 数据库管理
本小节主要讲解 MongoDB shell 的基础知识以及可视化工具如何使用它们来管理数据库。在深入探究创建与数据库交互的应用程序之前,理解 MongoDB shell 如何工作是很重要的。通过本小节的学习,我们可以学习到怎么使用 shell 命令去操作使用数据库。
4.1 MongoDB shell
MongoDB shell 是 MongoDB 自带的 JavaScript shell,随 MongoDB 一同发布,它是 MongoDB 客户端工具,可以在 shell 中使用命令与 MongoDB 进行交互,对数据库的管理操作(CURD、集群配置、状态查看等)都可以通过 MongoDB shell 来完成。
MongoDB shell 是 MongoDB 自带的一个交互式的 JavaScript shell,可以使用 MongoDB shell 访问、配置、管理 MongoDB 数据库。可以说使用 MongoDB shell,就可以管理 MongoDB 的一切。一旦开启了数据库服务,就可以启动 MongoDB shell 并且开始使用 MongoDB。想要使用 MongoDB shell,首先需要启动 MongoDB。然后进入到 MongoDB 安装目录的bin目录,输入 MongoDB shell 的连接命令,其命令格式如下所示:
# ip是要连接的数据库所在的ip地址,若不填,则默认localhost即127.0.0.1。
mongo [ip][:port][/database] [--username "username" --password "password"]
# port是要连接的数据库的端口号,若不填,则默认27017。
# /database是要连接的MongoDB的哪一个数据库,如果不填,则默认连接test数据库。
#[--username "username" --password "password"],则是如果数据库在启动时使用--auth开启了身份验证,则需要输入用户名和密码
注意:不要把这个命令和启动 MongoDB 的命令混淆了,一个是 mongod 命令,一个是 mongo 命令。接下来连接 MongoDB shell,如下图所示:
另外的写法:
D:\DevelopSoftware\MongoDB\bin>mongo localhost:27017/test
4.2 MongoDB shell 命令
- help 命令: 如果想知道某个对象下都有哪些函数可以使用 help 命令,直接使用 help 会列举出 MongoDB 支持操作,使用 db.help() 会列举所有 db 对象所支持的操作,使用 db.mycoll.help() 可以列举所有集合对象对应的操作。
db.help() # 查看所有数据级别的操作 db.mycoll.help() # 查看集合级别的操作 db.listCommands() # 列举数据库命令 - 可以通过输入函数名查看函数方法的实现或者查看方法的定义(比如忘记函数的参数了),不带小括号,代码如下:
4.3 MongoDB shell 原生方法
MongoDB shell 提供了很多用于执行管理的原生方法,我们可以在 MongoDB shell 中直接调用,也可以在 js 文件中直接调用,然后使用 shell 执行 js 文件即可。下面我们看一些常用的原生方法:
Date()方法。若直接使用Date()方法,则直接返回当前日期字符串
UUID(hex_string)方法。将32B的十六进制字符串转换成BSON子类型的UUID格式。
ObjectId.valueOf()方法。将一个ObjectId的属性str显示为十六进制字符串。
Mongo.getDB(DataBase)方法。返回一个数据库对象,它标识指定的数据库。
Mongo(host:port)方法。创建一个连接对象,它连接到指定的主机和端口。
connect(string)方法。连接到指定MongoDB实例中的指定数据库,返回一个数据库对象,string的格式为:
host:port/database,如db=connect("localhost:27017/test"),该语法等同于Mongo(host:port).getDB(database)。cat(path)方法。与Linux差不多,返回指定路径的文件的内容。
version()方法。返回当前MongoDB shell的版本。
cd(path)方法。将工作目录切换到指定路径。
getMemInfo()方法。返回当前shell占用的内存量。
hostname()方法。返回运行当前MongoDB shell的系统的主机名。
load(path)方法。在shell中加载并运行参数path指定的js文件。
_rand()方法。返回一个0~1的随机数。
4.4 MongoDB 的基本操作
MongoDB 是一个介于关系数据库和非关系数据库之间的产品,也是非关系型数据库当中功能最丰富,最像关系型数据库的。MongoDB 的操作和 MySQL 中的操作很相像,使用过 MySQL 的人群也能很快适应 MongoDB 中的操作。
4.4.1 MongoDB 数据库的连接
见 4.1 小节
4.4.2 数据库
数据库是以一定方式储存在一起、能与多个用户共享、具有尽可能小的冗余度、与应用程序彼此独立的数据集合,可视为电子化的文件柜——存储电子文件的处所,用户可以对文件中的数据进行新增、查询、更新、删除等操作。数据库是集合和索引的命名空间和物理分组。MongoDB 没有显式地创建数据库的方式,而是会在第一次写入数据时创建数据库。创建数据库时,MongoDB 会在磁盘上分配一系列数据库文件集合,包括所有的集合、索引以及其他元数据。数据库文件存储在 mongod 启动时的 dbpath 参数指定的目录文件夹中,如果不指定 dbpath,则会默认在 /data/db 文件夹下存储。
首先查看所有数据库:> show dbs;
创建/切换数据库newdb:use newdb; 有数据才会真正的创建
获取当前正在操作的数据库:db
删除数据库:db.dropDatabase()
4.4.3 集合
集合是结构或者概念上相似的文档的容器。MongoDB 创建集合是隐式的,在插入文档的时候才会创建。但因为有多重集合类型的存在,所以也提供了创建集合的命令:
db.createCollection("users")
从 MongoDB 内部来讲,集合名字是通过其命名空间名字来区分的,包含所属的数据库的名字。在 MongoDB 中使用 createCollection() 方法来创建集合。语法格式如下:
db.createCollection(name, options)
name:要创建的集合名称。options:可选参数,指定有关内存大小及索引的选项,其中 options 参数可以是下表所示的类型:
示例:
> use test
switched to db test
> db.createCollection("newdb") 当插入数据时会自动创建
{ "ok" : 1 }
> show collections 查看已有集合
newdb
> db.createCollection("newdb2",{capped : true, autoIndexId : true, size :5000000, max : 1000})
{"note" : "The autoIndexId option is deprecated and will be removed in a future release","ok" : 1
}
> db.newdb2.drop()
true
> show collections
newdb
> db.newdb.renameCollection("temp")
{ "ok" : 1 }
> show collections
temp
4.4.4 文档
文档是一组键值(key-value)对。MongoDB 的文档不需要设置相同的字段,并且相同的字段不需要相同的数据类型,这与关系型数据库有很大的区别,也是 MongoDB 非常突出的特点。文档是 MongoDB 的核心概念,是数据的基本单元,非常类似于关系型数据库中的行。在 MongoDB 中,文档表示为键值对的一个有序集。MongoDB 使用 JavaScript shell,文档的表示一般使用 JavaScript 里面的对象的样式来标记,代码如下:
{"title":"hello!"}
{"title":"hello!","recommend":5}
{"title":"hello!","recommend":5,"author":{"firstname":"张三","lastname":"李四"}}
创建文档的时候需要注意:
- 文档中的键值对是有序的。
- 文档中的值不仅可以是在双引号里面的字符串,还可以是其他几种数据类型(甚至可以是整个嵌入的文档)。
- MongoDB 区分类型和大小写。
- MongoDB 的文档不能有重复的键。
- 文档的键是字符串。除了少数例外情况,键可以使用任意 UTF-8 字符。
4.4.5 数据类型
在 MongoDB 中有几种重要的数据类型,分别如下:
1、ObjectId: ObjectId 文档自动生成的 _id,类似于唯一主键,可以很快地生成和排序,它包含24B。例如:
{"_id" : ObjectId("5d69cf296693871a67f19983")}
含义分别如下:
0~8B(5d69cf29)表示时间戳,即这条数据产生的时间。
9~14B(669387)表示机器标识符,即存储这条数据时的机器编码。
15~18B(1a67)表示进程id。
19~24B(f19983)表示计数器。
MongoDB 中存储的文档必须有一个 _id 键。这个键的值可以是任何类型的,默认是 ObjectId 对象。
2、String: UTF-8 字符串都可表示为字符串类型的数据。
3、Boolean: 布尔值只有两个值 true 和 false(注意 true 和 false 首字母小写)。
4、Integer: 整数,一般有 32 位和 64 位。
32位整数:shell中这个类型不可用,JavaScript仅支持64位浮点数,所以32位整数会被自动转换。
64位整数:shell中这个类型不可用,shell会使用一个特殊的内嵌文档来显示64位整数。
5、Double: 浮点数,MongoDB 中没有 Float 类型,所有小数都是 Double 类型。
6、Arrays: 数组,值的集合或者列表可以表示成数组,数组中的元素可以是不同类型的数据,例如:
{"x" : ["a", "b", "c", 20]}
7、Null: 空数据类型,表示不存在的字段。例如:
{"x" : null}
8、Date: 日期类型存储的是从标准纪元开始的毫秒数,不存储时区,例如:
{"x" : new Date()}
JavaScript 中 Date 对象用作 MongoDB 的日期类型,创建日期对象要使用 new Date() 而不是 Date(),返回的是对日期的字符串表示,而不是真正的 Date 对象。
4.4.6 索引
索引通常能够极大地提高查询的效率,如果没有索引,MongoDB 在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询要花费几十秒甚至几分钟,这对网站的性能是非常致命的。索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构。createIndex() 方法:MongoDB 使用 createIndex() 方法来创建索引。createIndex() 方法基本语法格式如下所示:
>db.collection.createIndex(keys, options)
语法中 key 值为要创建的索引字段,1为指定按升序创建索引,-1为指定按降序创建索引。
至此今天的学习就到此结束了,笔者在这里声明,笔者写文章只是为了学习交流,以及让更多学习数据库的读者少走一些弯路,节省时间,并不用做其他用途,如有侵权,联系博主删除即可。感谢您阅读本篇博文,希望本文能成为您编程路上的领航者。祝您阅读愉快!

好书不厌读百回,熟读课思子自知。而我想要成为全场最靓的仔,就必须坚持通过学习来获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请点赞、评论、收藏一键三连哦!听说点赞的人运气不会太差,每一天都会元气满满呦!如果实在要白嫖的话,那祝你开心每一天,欢迎常来我博客看看。
编码不易,大家的支持就是我坚持下去的动力。点赞后不要忘了关注我哦!
相关文章:
一、快速入门 MongoDB 数据库
文章目录一、NoSQL 是什么1.1 NoSQL 简史1.2 NoSQL 的种类及其特性1.3 NoSQL 特点1.4 NoSQL 的优缺点1.5 NoSQL 与 SQL 数据库的比较二、MongoDB 基础知识2.1 MongoDB 是什么2.2 MongoDB 的体系结构2.3 MongoDB 的特点2.4 MongoDB 键特性2.5 MongoDB 的核心服务和工具2.6 Mongo…...
PMP第一章到第三章重要知识点
第1章引论 1.1指南概述和目的 PMBOK指南收录项目管理知识体系中被普遍认可为“良好实践”的那一部分: “普遍认可”:大多数时候适用于大多数项目,获得一致认可。 “良好实践”:能提高很多项目成功的可能性。 全球项目管理业界…...

【事务与锁】当Transactional遇上synchronized
事务与锁 - Transactional与Synchronize🥰前言问题回放问题一1、代码与结果复现2、原因分析3、解决方法问题二1、问题复现2、原因分析事务Transactional与锁synchronized1、synchronized与Transactional区别2、可能带来的问题3、针对问题二的解决前言 最近工作中遇…...
Pytorch模型转TensorRT步骤
Pytorch模型转TensorRT步骤 yolov5转TRT 流程 当前项目基于yolov5-6.0版本,如果使用其他版本代码请参考 https://github.com/wang-xinyu/tensorrtx/tree/master/yolov5 获取转换项目: git clone https://github.com/wang-xinyu/tensorrtx.git git …...
产品经理入门——必备技能之【产品运营】
文章目录一、基础介绍1.1 用户生命周期 & 产品生命周期1.2 运营的目的1.3 运营的阶段1.4 运营的主要工作(海盗模型)二、AARRR模型2.1 Acquisition 拉新2.2 Activision 促活2.3 Retention 留存2.4 Revenue 转化2.5 Referral 传播总结产品运营技能是产…...

【Java实现文件上传】java后端+vue前端实现文件上传全过程详解(附源码)
【写在前面】其实这篇文章我早就想写了,只是一直被需求开发耽搁,这不晚上刚好下班后有点时间,记录一下。需求是excel表格的上传,这个是很多业务系统不可或缺的功能点,再此也希望您能够读完我这篇文章对文件上传不再困惑…...

什么是SSD?SSD简述
什么是SSD?SSD简述前言一. SSD组成二. SSD存储介质存储介质按材料不同可分为三大类:光学存储介质、半导体存储介质和磁性存储介质三. SSD接口形态固态硬盘有SATA 3.0接口、MSATA接口、M.2接口、PCI-E接口、U.2接口五种类型。三. SSD闪存颗粒分类闪存颗粒…...

MySQL基础------sql指令1.0(查询操作->select)
目录 前言: 单表查询 1.查询当前所在数据库 2.查询整个表数据 3.查询某字段 4.条件查询 5.单行处理函数(聚合函数) 6.查询时给字段取别名 7.模糊查询 8.查询结果去除重复项 9.排序(升序和降序) 10. 分组查询 1…...

Python数据分析处理报告--实训小案例
目录 1、实验一 1.1、题目总览 1.2、代码解析 2、实现二 2.1、题目总览 2.2、代码解析 3、实验三 3.1、题目总览 3.2、代码解析 4、实验四 3.1、题目总览 3.2、代码解析 哈喽~今天学习记录的是数据分析实训小案例。 就用这个案例来好好巩固一下 python 数据分析三…...
OpenCV入门(十二)快速学会OpenCV 11几何变换
OpenCV入门(十二)快速学会OpenCV 11几何变换1.图像平移2.图像旋转3.仿射变换4.图像缩放我们在处理图像时,往往会遇到需要对图像进行几何变换的问题。图像的几何变换是图像处理和图像分析的基础内容之一,不仅提供了产生某些图像的可…...
小菜鸟Python历险记:(第二集)
今天写的文章是记录我从零开始学习Python的全过程。Python基础语法学习:Python中的数值运算一共有7种,分别是加法()、减法(-)、除法(/)得到的结果是一个浮点数、乘法(*&a…...
ContentProvider程序之间数据的相互调用
1权限的获取和调用 权限分为普通权限和危险权限,除了日历信息,电话,通话记录,相机,通讯录,定位,麦克风,电话,传感器,界面识别(Activity-Recognit…...

金三银四最近一次面试,被阿里P8测开虐惨了...
都说金三银四涨薪季,我是着急忙慌的准备简历——5年软件测试经验,可独立测试大型产品项目,熟悉项目测试流程...薪资要求?5年测试经验起码能要个20K吧 我加班肝了一页半简历,投出去一周,面试电话倒是不少&a…...

算法题——给定一个字符串 s ,请你找出其中不含有重复字符的最长子串 的长度
给定一个字符串 s ,请你找出其中不含有重复字符的最长子串 的长度 示例 1: 输入: s “abcabcbb” 输出: 3 解释: 因为无重复字符的最长子串是 “abc”,所以其长度为 3。 示例 2: 输入: s “bbbbb” 输出: 1 解释: 因为无重复字符的最长子串是 “b”&am…...
机器学习中的数学原理——F值与交叉验证
通过这篇博客,你将清晰的明白什么是F值、交叉验证。这个专栏名为白话机器学习中数学学习笔记,主要是用来分享一下我在 机器学习中的学习笔记及一些感悟,也希望对你的学习有帮助哦!感兴趣的小伙伴欢迎私信或者评论区留言࿰…...

vue.js介绍
个人名片: 😊作者简介:一名大一在校生,web前端开发专业 🤡 个人主页:python学不会123 🐼座右铭:懒惰受到的惩罚不仅仅是自己的失败,还有别人的成功。 🎅**学习…...
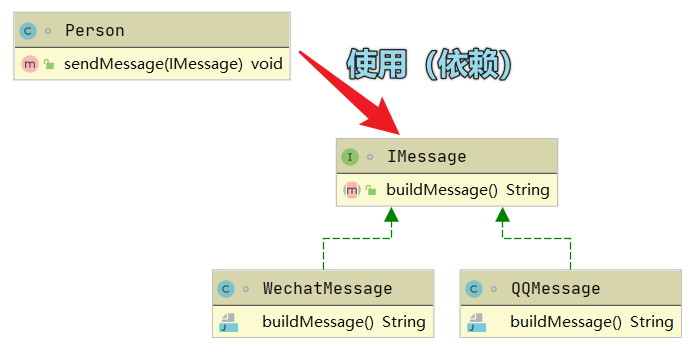
【设计模式】1、设计模式七大原则
目录一、单一职责二、接口隔离三、依赖倒置(倒转)四、里氏替换五、迪米特法则(Law of Demeter)六、开闭七、合成复用一、单一职责 类(或方法)功能的专一性。一个类(或方法)不应该承担…...

【前端老赵的CSS简明教程】10-1 CSS预处理器和使用方法
大家好,欢迎来到本期前端课程。我是前端老赵,今天的课程将讲解CSS预处理器的概念和使用方法,希望能够帮助大家更好地进行前端开发。 CSS预处理器是什么? CSS预处理器是一种将类似CSS的语言转换为CSS的工具。它们提供了许多额外的功能,如变量、嵌套、混入、函数等等。这些…...

BFC详解
1. 引言 在前端的布局手段中,一直有这么一个知识点,很多前端开发者都知道有它的存在,但是很多人也仅仅是知道它的存在而已,对它的作用也只是将将说得出来,可是却没办法说得非常的清晰。这个知识点,就是BFC…...
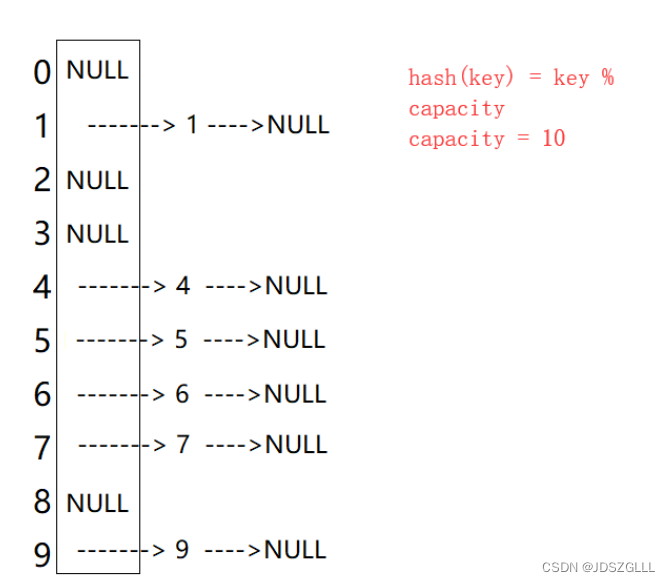
C++:哈希结构(内含unordered_set和unordered_map实现)
unordered系列关联式容器 在C98中,STL提供了底层为红黑树结构的一系列关联式容器,在查询时效率可达到$log_2 N$,即最差情况下需要比较红黑树的高度次,当树中的节点非常多时,查询效率也不理想。最好 的查询是ÿ…...

SpringBoot-17-MyBatis动态SQL标签之常用标签
文章目录 1 代码1.1 实体User.java1.2 接口UserMapper.java1.3 映射UserMapper.xml1.3.1 标签if1.3.2 标签if和where1.3.3 标签choose和when和otherwise1.4 UserController.java2 常用动态SQL标签2.1 标签set2.1.1 UserMapper.java2.1.2 UserMapper.xml2.1.3 UserController.ja…...

华为云AI开发平台ModelArts
华为云ModelArts:重塑AI开发流程的“智能引擎”与“创新加速器”! 在人工智能浪潮席卷全球的2025年,企业拥抱AI的意愿空前高涨,但技术门槛高、流程复杂、资源投入巨大的现实,却让许多创新构想止步于实验室。数据科学家…...

微信小程序 - 手机震动
一、界面 <button type"primary" bindtap"shortVibrate">短震动</button> <button type"primary" bindtap"longVibrate">长震动</button> 二、js逻辑代码 注:文档 https://developers.weixin.qq…...

【android bluetooth 框架分析 04】【bt-framework 层详解 1】【BluetoothProperties介绍】
1. BluetoothProperties介绍 libsysprop/srcs/android/sysprop/BluetoothProperties.sysprop BluetoothProperties.sysprop 是 Android AOSP 中的一种 系统属性定义文件(System Property Definition File),用于声明和管理 Bluetooth 模块相…...

C# 类和继承(抽象类)
抽象类 抽象类是指设计为被继承的类。抽象类只能被用作其他类的基类。 不能创建抽象类的实例。抽象类使用abstract修饰符声明。 抽象类可以包含抽象成员或普通的非抽象成员。抽象类的成员可以是抽象成员和普通带 实现的成员的任意组合。抽象类自己可以派生自另一个抽象类。例…...

涂鸦T5AI手搓语音、emoji、otto机器人从入门到实战
“🤖手搓TuyaAI语音指令 😍秒变表情包大师,让萌系Otto机器人🔥玩出智能新花样!开整!” 🤖 Otto机器人 → 直接点明主体 手搓TuyaAI语音 → 强调 自主编程/自定义 语音控制(TuyaAI…...

基于TurtleBot3在Gazebo地图实现机器人远程控制
1. TurtleBot3环境配置 # 下载TurtleBot3核心包 mkdir -p ~/catkin_ws/src cd ~/catkin_ws/src git clone -b noetic-devel https://github.com/ROBOTIS-GIT/turtlebot3.git git clone -b noetic https://github.com/ROBOTIS-GIT/turtlebot3_msgs.git git clone -b noetic-dev…...
高考志愿填报管理系统---开发介绍
高考志愿填报管理系统是一款专为教育机构、学校和教师设计的学生信息管理和志愿填报辅助平台。系统基于Django框架开发,采用现代化的Web技术,为教育工作者提供高效、安全、便捷的学生管理解决方案。 ## 📋 系统概述 ### 🎯 系统定…...

【Linux】Linux安装并配置RabbitMQ
目录 1. 安装 Erlang 2. 安装 RabbitMQ 2.1.添加 RabbitMQ 仓库 2.2.安装 RabbitMQ 3.配置 3.1.启动和管理服务 4. 访问管理界面 5.安装问题 6.修改密码 7.修改端口 7.1.找到文件 7.2.修改文件 1. 安装 Erlang 由于 RabbitMQ 是用 Erlang 编写的,需要先安…...
CSS3相关知识点
CSS3相关知识点 CSS3私有前缀私有前缀私有前缀存在的意义常见浏览器的私有前缀 CSS3基本语法CSS3 新增长度单位CSS3 新增颜色设置方式CSS3 新增选择器CSS3 新增盒模型相关属性box-sizing 怪异盒模型resize调整盒子大小box-shadow 盒子阴影opacity 不透明度 CSS3 新增背景属性ba…...