[论文笔记]RAPTOR: RECURSIVE ABSTRACTIVE PROCESSING FOR TREE-ORGANIZED RETRIEVAL
引言
今天带来又一篇RAG论文笔记:RAPTOR: RECURSIVE ABSTRACTIVE PROCESSING FOR TREE-ORGANIZED RETRIEVAL。
检索增强语言模型能够更好地适应世界状态的变化并融入长尾知识。然而,大多数现有方法只能从检索语料库中检索到短的连续文本片段,限制了对整个文档上下文的完整理解。作者引入了一种新颖的方法,即递归嵌入、聚类和总结文本片段,从底部开始构建具有不同摘要级别的树。在推理期间,RAPTOR模型从这棵树中检索,将跨不同抽象级别的庞大文档中的信息整合起来。
源码发布在: https://github.com/parthsarthi03/raptor 。
1. 总体介绍
大语言模型已经成为具有深远影响的变革性工具,在许多任务上表现出令人印象深刻的性能。然而,即使是一个大型语言模型也不包含特定任务所需的足够领域特定知识,并且世界持续变化,使LLM中的事实失效。通过额外的微调或编辑来更新这些模型的知识是困难的,特别是在处理庞大文本语料库时。在开放领域问答系统中开创性的另一种方法是将大量文本进行分块(段落)后在单独的信息检索系统中建立索引。所检索的信息随后与问题一起作为上下文呈现给LLM(RAG检索增强),这使得为系统提供特定领域当前知识变得容易,并且能够轻松解释和追溯来源。
然而,现有的检索增强方法也存在缺陷。大多数现有方法只检索到几个短小的相邻文本片段,这限制了它们表示和利用大规模话语结构的能力。这在需要整合来自文本多个部分知识的主题性问题中尤为重要,比如理解整本书的情况,就像NarrativeQA数据集中以灰姑娘的童话故事为例,针对问题“灰姑娘如何走向幸福结局?”,检索到的前K个相邻短文本不包含足够的上下文来回答问题。
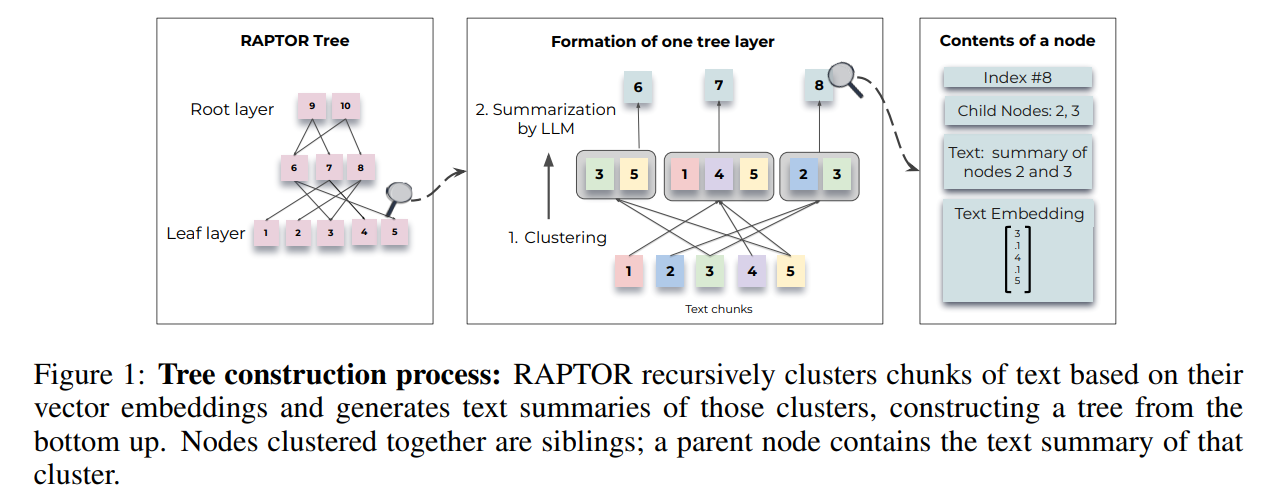
为了解决这个问题,作者设计了一个索引和检索系统,使用树结构捕捉文本的高级和低级细节。如图1所示,RAPTOR对文本片段进行聚类,生成这些聚类的文本摘要,然后重复此过程,从底部生成树。这种结构使得RAPTOR能够加载不同级别代表文本的片段到LLM的上下文中,从而能够有效地回答不同级别的问题。
作者的主要贡献是利用文本摘要的想法,允许在不同尺度上进行检索增强上下文,并在长文集合的实验中展示其有效性。
2. 相关工作
为什么使用检索? 硬件和算法的最新进展确实扩展了模型可以处理的上下文长度,引发了关于检索系统必要性的讨论。然而,模型往往未充分利用长距离上下文,并在上下文长度增加时性能下降,特别是当相关信息嵌入在冗长上下文中时。此外,在实际应用中,使用长上下文既昂贵又缓慢。这表明,为知识密集型任务选择最相关的信息仍然至关重要。
检索方法 检索增强语言模型(Retrieval-augmented language models, RALMs)在各个组成部分中取得了改进:检索器(retriever)、阅读器(reader)和端到端系统训练。检索方法已经从传统的基于单词(term)的技术(如TF-IDF和BM25)转变为基于深度学习的策略。一些最近的工作提出使用大型语言模型作为检索器,因为它们能够记忆大量知识。关于阅读器组件的研究包括Fusion-in-Decoder,它同时使用DPR和BM25进行检索,并在编码器中独立处理段落,以及RETRO,它利用跨块关注和分块检索生成基于检索上下文的文本。
端到端系统训练工作包括Atlas,它在与检索器一起微调编码器-解码器模型;REALM,一种为开放域问答微调的双向掩码语言模型;以及RAG,将预训练的序列到序列模型与神经网络检索器集成。尽管方法多样,模型的检索组件主要依赖于标准方法,即对语料库进行分块并使用基于BERT的检索器进行编码。
尽管这种方法被广泛采用,但Nair等强调了一个潜在的缺点:连续分割可能无法捕获文本的完整语义深度。从技术或科学文档中提取的片段阅读可能缺乏重要上下文,使其难以阅读甚至具有误导性。
递归摘要作为上下文 摘要(Summarization,总结)技术提供了对文档的简洁视图,使内容更加集中。Gao等人的摘要模型使用段落(passage)的摘要和片段,提高了大多数数据集的正确性,但有时可能是一种高失真的压缩手段。Wu等人的递归摘要生成模型采用任务分解来总结较小的文本块,然后将其集成以形成较大部分的摘要。虽然这种方法对捕获更广泛主题很有效,但可能会忽略细节。LlamaIndex通过类似摘要相邻文本块的方式来缓解这一问题,但同时保留中间节点,因此存储着不同层次的细节,保留了细粒度的详情。然而,由于这两种方法依赖于相邻节点的分组或摘要,可能仍会忽视文本内的远程相互依赖关系,而RAPTOR可以找到并组合这些关系。
3. Method
RAPTOR概览 建立在长文本通常呈现子主题和分层结构的思想基础上,RAPTOR通过构建一个递归树结构来解决阅读中的语义深度和连接问题,该结构平衡了更广泛的主题理解和细粒度细节,允许根据语义相似性而不仅仅是文本顺序对节点进行分组。
RAPTOR树的构建始于将检索语料库分割成长度为100的短连续文本,类似于传统的检索增强技术。如果一句话超过100个标记的限制,我们将整个句子移至下一个块(chunk),而不是在句子中途截断。这保留了每个块内文本的上下文和语义连贯性。然后使用SBERT嵌入这些文本。这些块及其对应的SBERT嵌入形成了树结构的叶节点。
为了将相似的文本块分组,采用了聚类算法。一旦分组,将使用语言模型对分组文本进行总结。然后重新嵌入这些总结文本,并继续嵌入、聚类和总结循环,直到进一步聚类变得不可行为止,最终形成原始文档的结构化、多层树表示。RAPTOR的一个重要特点是其计算效率。该系统在构建时间和标记消耗方面呈线性缩放,适用于处理庞大和复杂的语料库。
对于在该树内查询,引入了两种不同的策略:树遍历和折叠树。树遍历方法逐层遍历树,在每个级别修剪和选择最相关的节点。折叠树方法评估所有级别上的节点,以找到最相关的节点。
聚类算法 聚类在构建RAPTOR树、将文本段组织成连贯簇(Group)方面发挥着关键作用。这一步将相关内容组合在一起,有助于后续的检索过程。
作者聚类方法的一个独特之处在于使用软聚类,其中节点可以属于多个簇,而不需要固定数量的簇。这种灵活性是必不可少的,因为单个文本段通常包含与各种主题相关的信息,因此需要将其纳入多个摘要中。
聚类算法基于高斯混合模型(GMMs),这种方法提供了灵活性和概率框架。GMMs假设数据点是从多个高斯分布混合中生成的。
给定一个包含N个文本片段的集合,每个表示为一个d维稠密向量嵌入,假设文本向量 x x x属于第k个高斯分布的概率表示为 p ( x ∣ k ) = N ( x ; μ k , Σ k ) p(x|k) = \mathscr N(x;\mu_k,\Sigma_k) p(x∣k)=N(x;μk,Σk)。整体概率分布是加权和 P ( x ) = ∑ k = 1 K π k N ( x ; μ k , Σ k ) P(x) = \sum_{k=1}^K \pi_k \mathscr N(x;\mu_k,\Sigma_k) P(x)=∑k=1KπkN(x;μk,Σk),其中 π k \pi_k πk表示第k个高斯分布的混合权重。
向量嵌入的高维度对传统GMMs构成挑战,因为在高维空间中使用距离度量可能表现不佳。为了缓解这一问题,作者采用均匀流形近似和投影(Uniform Manifold Approximation and Projection,UMAP),一种用于降维的流形学习技术。UMAP中的最近邻参数n_neighbors决定了保留局部结构和全局结构之间的平衡。作者的算法通过变化n_neighbors来创建层次聚类结构:首先识别全局聚类,然后在这些全局聚类中执行局部聚类。这种两步聚类过程捕捉了文本数据之间的广泛关系,从广泛主题到具体细节。
如果局部聚类的组合上下文超过了总结模型的标记阈值,作者的算法会在该聚类内递归应用聚类,确保上下文保持在标记阈值内。
为了确定最佳聚类数,使用贝叶斯信息准则(Bayesian Information Criterion,BIC)进行模型选择。BIC不仅惩罚模型复杂性,还奖励拟合优度。对于给定的GMM,BIC为 B I C = ln ( N ) k − 2 ln ( L ^ ) BIC = \ln(N)k - 2\ln(\hat L) BIC=ln(N)k−2ln(L^),其中 N N N为文本片段(或数据点)的数量, k k k为模型参数的数量, L ^ \hat L L^为模型似然函数的最大化值。在GMM的情境中,参数数量 k k k是输入向量的维度和聚类数量的函数。
得到由BIC确定的最佳聚类数量后,使用EM算法来估计GMM参数,即均值、协方差和混合权重。虽然GMM中的高斯假设可能与文本数据的性质不完全符合,后者通常表现出稀疏和偏斜的分布,但实证观察表明,它是一种有效的模型。
基于模型的摘要 在使用高斯混合模型对节点进行聚类后,将每个聚类中的节点发送到语言模型进行总结。这一步允许模型将大块文本转化为所选节点的简明、连贯摘要。作者使用gpt-3.5-turbo生成摘要。总结步骤将检索到的大量信息压缩为可管理的大小。
查询 下面详细阐述了RAPTOR所采用的两种查询机制:树遍历和折叠树(collapsed tree,坍塌树)。这些方法提供了在多层RAPTOR树中获取相关信息的独特方式,每种方法都有其各自的优势和权衡。在附录F中提供了这两种方法的伪代码。使用SBERT对所有节点进行嵌入。
树遍历方法首先基于查询嵌入与根节点的余弦相似性选择top-k个最相关的根节点。这些所选节点的子节点在下一层被考虑,然后再次基于它们的子节点与查询向量的余弦相似性选择top-k个节点。该过程重复进行,直到达到叶节点。最后,将从所有选定节点中提取的文本连接起来形成检索到的上下文。算法步骤如下:
- 在RAPTOR树的根层开始。计算查询嵌入与该初始层中所有节点的嵌入之间的余弦相似性。
- 基于最高余弦相似性得分选择前k个节点,形成集合 S 1 S_1 S1。
- 继续处理集合 S 1 S_1 S1中元素的子节点。计算查询向量与这些子节点的向量嵌入之间的余弦相似性。
- 根据与查询的最高余弦相似性得分选择top-k个子节点,形成集合 S 2 S_2 S2。
- 递归地继续这个过程达到d层,生成集合 S 1 、 S 2 . . . S d S_1、S_2...S_d S1、S2...Sd。
- 将集合 S 1 S_1 S1至 S d S_d Sd连接起来组装成与查询相关的上下文。
通过调整深度 d d d和每层选择的节点数 k k k,树遍历方法提供了对检索到的信息的特定性和广度的控制。该算法从树的顶层开始具有宽泛的视野,并随着向下穿越到较低层而逐渐聚焦于更细节的内容。
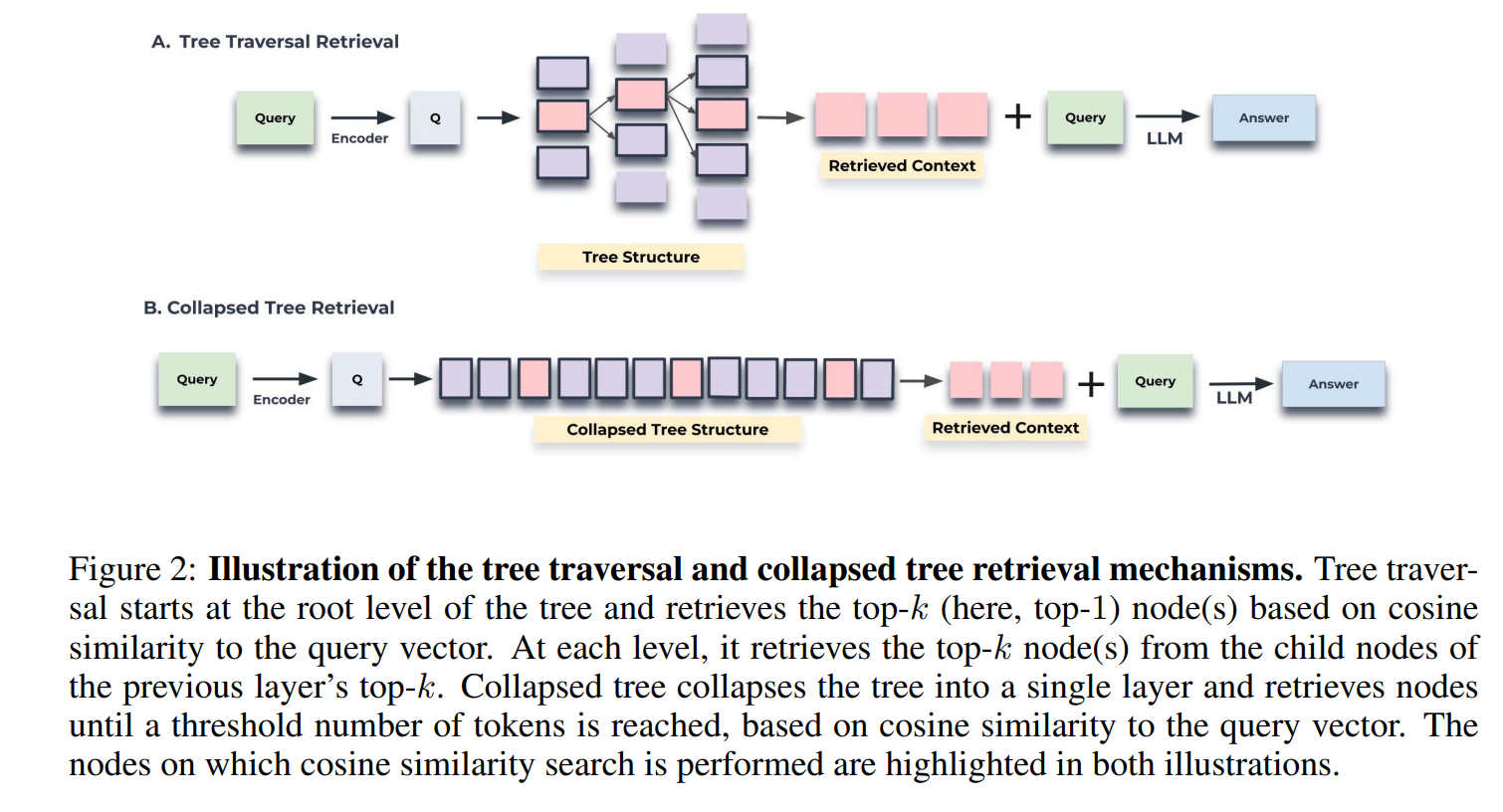
图2:树遍历和折叠树检索机制的示意图。树遍历从树的根层开始,并基于余弦相似性与查询向量检索top-k个(在此处为top-1个节点)。在每层,它从前一层top-k的子节点中检索top-k的节点。折叠树将树折叠成单层,并基于与查询向量的余弦相似性检索节点,直到达到标记数的阈值。这两种示意图中都突出显示了进行余弦相似性搜索的节点。
折叠树方法提供了一种更简单的搜索相关信息的方式,通过同时考虑树中的所有节点,如图2所示。这种方法不是逐层进行,而是将多层树折叠成单层,实质上将所有节点置于同一水平进行比较。该方法的步骤如下所述:
- 首先将整个RAPTOR树折叠为单层。这个新的节点集合,表示为 C C C,包含原始树的每一层中的节点。
- 接下来,计算查询嵌入与折叠集合 C C C中所有节点的嵌入之间的余弦相似性。
- 最后,选择与查询具有最高余弦相似性得分的top-k个节点。继续将节点添加到结果集,直到达到预定义的最大标记数,确保不超出模型的输入限制。
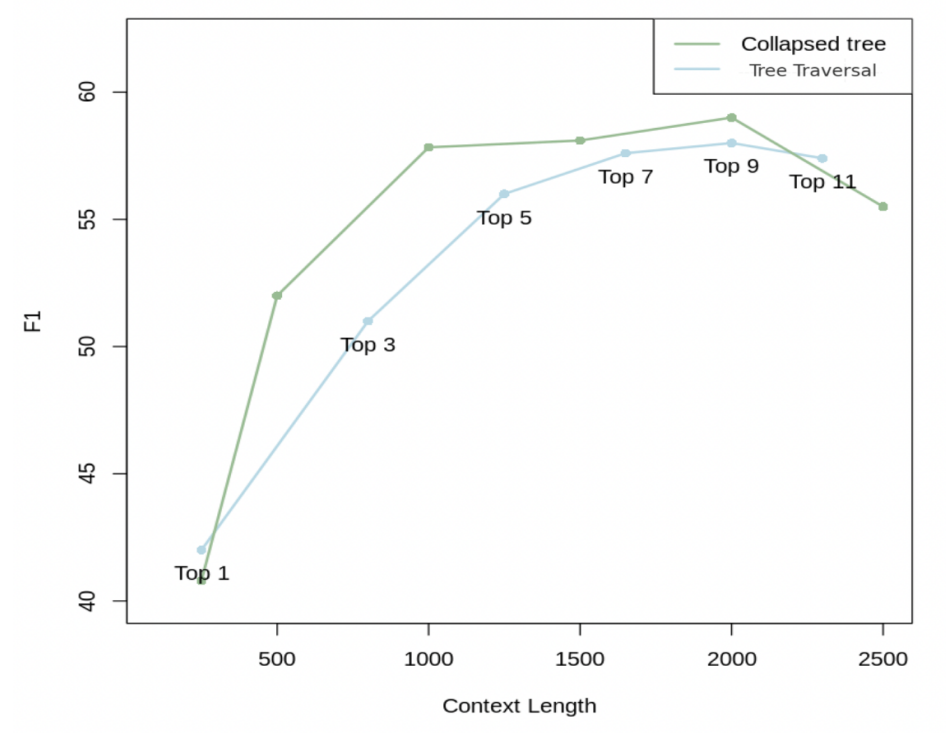
作者在QASPER数据集的20个故事上对这两种方法进行了测试。图3显示了树遍历在不同top-大小和折叠树在不同最大标记数下的性能。折叠树方法始终表现更好。因为它提供了比树遍历更大的灵活性;即,通过同时搜索所有节点,它检索出针对特定问题正确粒度的信息。相比之下,使用相同值的 d d d和 k k k进行树遍历时,树的每个级别的节点比例将保持恒定。因此,无论问题是什么,高阶主题信息与细节信息的比例将保持不变。
然而,折叠树方法的一个缺点是需要对树中的所有节点执行余弦相似性搜索。然而,使用诸如FAISS等快速k近邻库可以使这一过程更加高效。
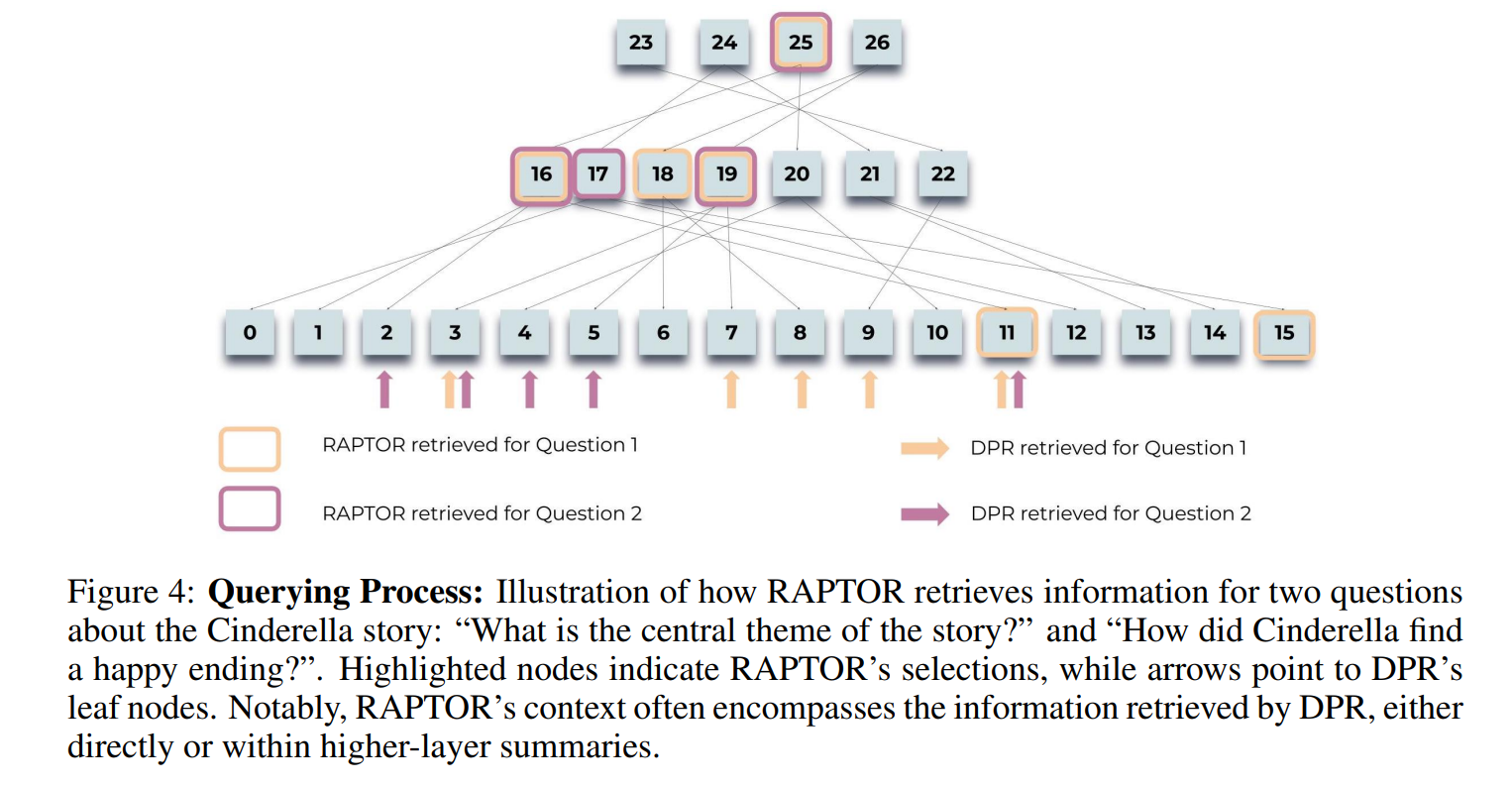
定性研究 作者进行了定性研究,以比较RAPTOR的检索过程与Dense Passage Retrieval(DPR)方法的优劣。研究专注于使用一个1500字的灰姑娘童话故事的主题性、多跳问题。如图4所示,RAPTOR基于树的检索使其能够选择来自不同树层的节点,与问题的细节级别相匹配。这种方法通常比DPR为下游任务提供更相关和全面的信息。
4. 实验
在三个问答数据集:NarrativeQA、QASPER和QuALITY上评估。
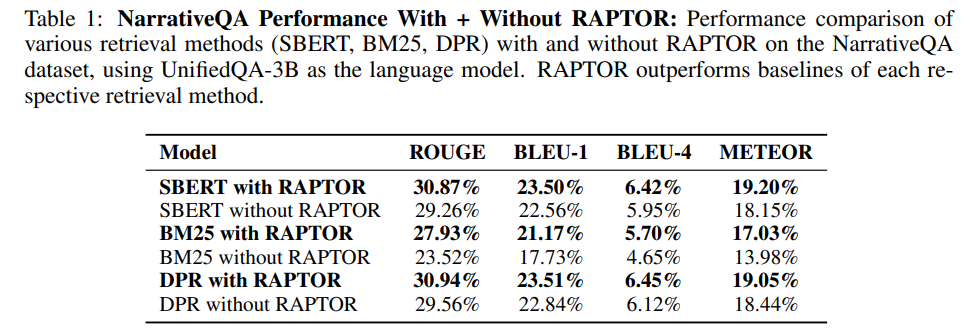
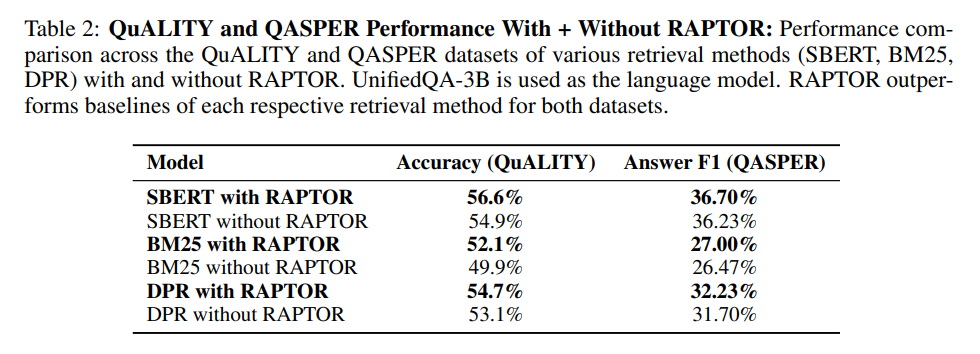
使用UnifiedQA 3B作为阅读器,SBERT、BM25和DPR作为嵌入模型,在QASPER、NarrativeQA和QuALITY三个数据集上进行受控对比。如表1和表2所示,结果表明,当RAPTOR与任何检索器结合时,在所有数据集上均表现出优于各自检索器的一致性。RAPTOR与SBERT结合具有最佳性能。
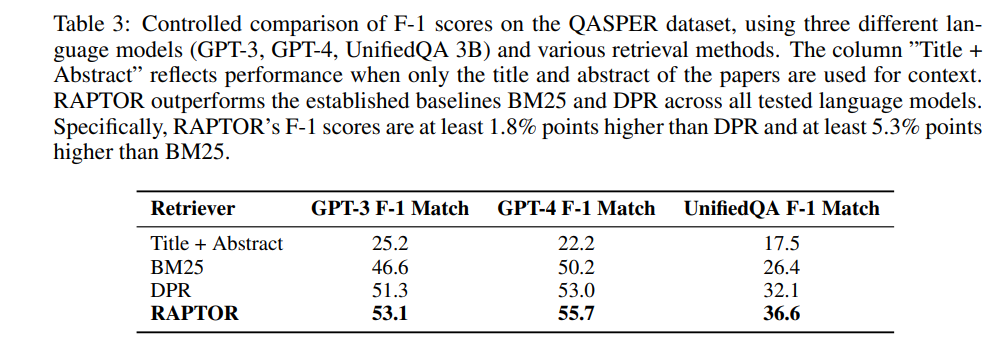
比较了RAPTOR与BM25和DPR,在三种不同的LLM上的表现。如表3所示,在QASPER数据集上,RAPTOR始终优于BM25和DPR。
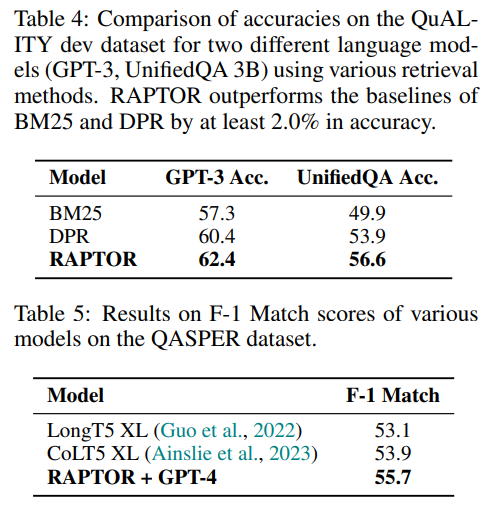
在QuALITY数据集中,如表4所示,RAPTOR的准确率达到62.4%,比DPR和BM25分别提高了2%和5.1%。当使用UnifiedQA时也观察到类似的趋势。
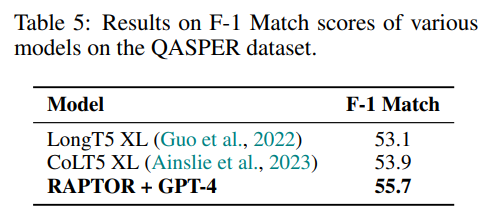
最后,在NarrativeQA数据集中,如表6所示,RAPTOR在多个指标上表现出色。
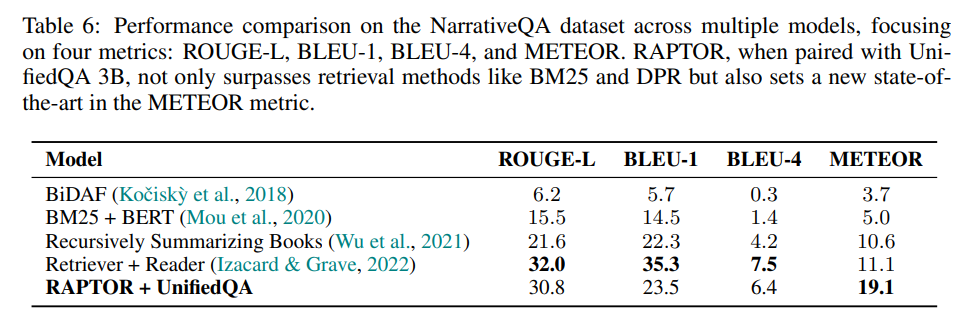
**与最先进系统的比较 **
在受控比较的基础上,研究了RAPTOR相对于其他最先进模型的性能。如表5所示,搭配GPT-4的RAPTOR在QASPER上创造了一个新的基准,获得了55.7%的F-1分数,超过了CoLT5 XL的53.9%。
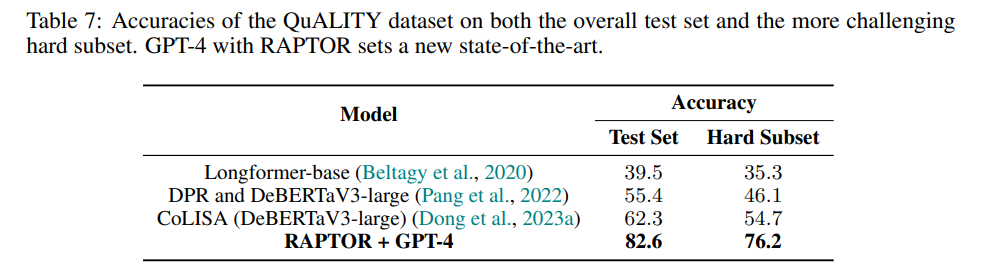
在QuALITY数据集中,如表7所示,搭配GPT-4的RAPTOR创造了一个新的最先进,准确率达到82.6%,超过了之前62.3%的最佳结果。
在NarrativeQA数据集中,如表6所示,与UnifiedQA搭配的RAPTOR创造了一个新的最先进的METEOR分数。
4.1 树结构的贡献
研究了每一层节点对RAPTOR检索能力的贡献。假设上层节点在处理需要对文本进行更广泛理解的主题性或多跳查询中起着至关重要的作用。作者定性和定量验证了这一假设。

在表8中展示了一个故事的具体发现,表明全树搜索,利用所有层,优于仅专注于特定层级的检索策略。这些发现凸显了RAPTOR中完整树结构的重要性。通过为检索提供原始文本和更高级别的摘要,RAPTOR可以有效处理更广泛范围的问题,从高阶主题性查询到细节导向问题。
B 在RAPTOR中聚类机制的消融研究
在QuALITY数据集上进行了一项消融研究。该研究将RAPTOR的表现与一种平衡的树状编码和摘要相邻块进行了对比。
B.1 方法论
对于RAPTOR,采用了典型的聚类和摘要过程。相比之下,另一种设置涉及通过递归编码和总结相邻文本块来创建平衡树。选择了7个节点的窗口大小,折叠树方法应用于两种模型的检索。

B.2 结果与讨论
消融研究的结果见表9。该消融研究的结果明确显示在利用RAPTOR的聚类机制时,准确性有所提高。
5. 结论
介绍了RAPTOR,一种新颖的基于树结构的检索系统,它通过在各种抽象级别上的上下文信息增强了大型语言模型的参数化知识。通过采用递归聚类和总结技术,RAPTOR创建了一个能够在检索语料库的各个部分之间综合信息的分层树结构。在查询阶段,RAPTOR利用这个树结构进行更有效的检索。
F 检索方法伪代码
遍历方法:

折叠方法:

总结
⭐ 作者引入了一种新颖的方法,递归嵌入、聚类和总结文本片段,从底部开始构建具有不同摘要级别的树。在推理期间,首先将这棵树拉平,然后从拉平的树节点中检索,将跨不同抽象级别的庞大文档中的信息整合起来。
相关文章:
[论文笔记]RAPTOR: RECURSIVE ABSTRACTIVE PROCESSING FOR TREE-ORGANIZED RETRIEVAL
引言 今天带来又一篇RAG论文笔记:RAPTOR: RECURSIVE ABSTRACTIVE PROCESSING FOR TREE-ORGANIZED RETRIEVAL。 检索增强语言模型能够更好地适应世界状态的变化并融入长尾知识。然而,大多数现有方法只能从检索语料库中检索到短的连续文本片段࿰…...

python 端口的转发
实现端口的转发 tcpsocket.py 对基础的socket进行了封装 import socketclass baseSocket:def service(host:str,port:int,maxSuspend:int)->socket: service_socket socket.socket(socket.AF_INET,socket.SOCK_STREAM) # 创建 socket 对象service_socket.setso…...

opencv 中如何通过欧式距离估算实际距离(厘米)
1:这个方法个人测试觉得是正确的,误差较小,目前满足我当前的需求,如果方法不对,请大家评论,完善。 2:确保拍摄的参照物是垂直的,如果不垂直,就会有误差,不垂…...

Flask+Layui开发案例教程
基于 Python 语言的敏捷开发框架_DjangoAdmin敏捷开发框架FlaskLayui版本_开发文档 软件产品基于 Python 语言,采用 Flask2.x、Layui、MySQL 等技术栈精心打造的一款集模块化、高性能、组件化于一体的企业级敏捷开发框架,本着简化开发、提升开发效率的初…...

复现ORB3-YOLO8项目记录
文章目录 1.编译错误1.1 错误11.2 错误21.3 错误31.4 错误4 1.编译错误 首先ORB-SLAM相关项目已经写过很多篇博客了,从ORB-SLAM2怎么运行,再到现在的项目。关于环境已经不想多说了 1.1 错误1 – DEPENDENCY_LIBS : /home/lvslam/ORB3-YOLO8/Thirdparty…...

【jvm】字符串常量池问题
目录 一、基本概念1.1 说明1.2 特点 二、存放位置2.1 JDK1.6及以前2.2 JDK1.72.3 JDK1.8及以后 三、工作原理3.1 创建字符串常量3.2 使用new关键字创建字符串 四、intern()方法4.1 作用 五、优点六、字节码分析6.1 示例16.1.1 代码示例6.1.2 字节码6.1.3 解析 6.2 示例26.2.1 代…...
:I2C EEPROM实验)
STM32学习和实践笔记(39):I2C EEPROM实验
1.I2C总线介绍 I2C(Inter-Integrated Circuit)总线是由PHILIPS公司开发的两线式串行总线,用于连接微控制器及其外围设备,是微电子通信控制领域广泛采用的一种总线标准。 它是同步通信的一种特殊形式,具有接口线少,控制方式简单,器件封装形式小,通信速率较高等优点。I…...

【Js】导出 HTML 为 Word 文档
在 Web 开发中,有时我们希望用户能够将网页上的 HTML 内容保存为 Word 文档,以便更方便地分享和打印。 html样式 word文档 工具准备 1、 html-docx-js - npm html-docx-js是一个 JavaScript 库,用于将 HTML 内容转换为 Word 文档的格式。它…...

c++入门基础篇(上)
目录 前言: 1.c++的第一个程序 2.命名空间 2.1 namespace的定义 2.2 命名空间使用 3.c++输入&输出 4.缺省参数 5.函数重载 前言: 我们在之前学完了c语言的大部分语法知识,是不是意…...

Java实现数据结构——双链表
目录 一、前言 二、实现 2.1 类的创建 三、对链表操作实现 3.1 打印链表 3.2 插入数据 3.2.1 申请新节点 3.2.2 头插 编辑 3.2.3 尾插 3.2.4 链表长度 3.2.5 任意位置插入 3.3 删除数据 3.3.1 头删 3.3.2 尾删 3.3.3 删除指定位置数据 3.3.4 删除指定数据 3…...
Python应用爬虫下载QQ音乐歌曲!
目录: 1.简介怎样实现下载QQ音乐的过程; 2.代码 1.下载QQ音乐的过程 首先我们先来到QQ音乐的官网: https://y.qq.com/,在搜索栏上输入一首歌曲的名称; 如我在上输入最美的期待,按回车来到这个画面 我们首…...

AWS-WAF-Log S3存放,通过Athena查看
1.创建好waf-cdn 并且设置好规则和log存储方式为s3 2. Amazon Athena 服务 使用 (注意s3桶位置相同得区域) https://docs.aws.amazon.com/zh_cn/athena/latest/ug/waf-logs.html#waf-example-count-matched-ip-addresses 官方文档参考,建一个分区查询表…...

无法解析主机:mirrorlist.centos.org Centos 7
从 2024 年 7 月 1 日起,在 CentOS 7 上,请切换到 Vault 存档存储库: vi /etc/yum.repos.d/CentOS-Base.repo 复制/粘贴以下内容并注意您的操作系统版本。如果需要,请更改。此配置中的版本为 7.9.2009: [base] name…...

自动驾驶论文总结
1.预测 1.1光栅化 代表性论文 Motion Prediction of Traffic Actors for Autonomous Driving using Deep Convolutional Networks (Uber)MultiPath (Waymo) 问题 渲染信息丢失感受野有限高计算复杂度 1.2图神经网络 1.2.1 图卷积 LaneGCN (uber 2020) 1.2.2 边卷积 V…...

【uniapp微信小程序】uniapp微信小程序——页面通信
uniapp微信小程序——页面通信 在开发微信小程序过程中,页面之间的通信是一个常见需求。在使用 uniapp 开发微信小程序时,我们可以采用多种方式实现页面之间的数据传递和状态共享。本文将详细介绍几种常见的实现方式,以供开发者参考。 1. 页…...

【笔记】从零开始做一个精灵龙女-画贴图阶段(上)
此文只是我的笔记,不包全看懂,有问题可评论 PS贴图加工 1.打开ps 拖入uv图,新建图层,设置背景色为灰色,改一下图层名字 2.按z缩小一下uv图层,拖入实体uv图片(目的是更好上色,比如…...

线性代数|机器学习-P22逐步最小化一个函数
文章目录 1. 概述2. 泰勒公式3. 雅可比矩阵4. 经典牛顿法4.1 经典牛顿法理论4.2 牛顿迭代法解求方程根4.3 牛顿迭代法解求方程根 Python 5. 梯度下降和经典牛顿法5.1 线搜索方法5.2 经典牛顿法 6. 凸优化问题6.1 约束问题6.1 凸集组合 Mit麻省理工教授视频如下:逐步…...

SpringCloudAlibaba Nacos配置中心与服务发现
目录 1.配置 1.1配置的特点 只读 伴随应用的整个生命周期 多种加载方式 配置需要治理 1.2配置中心 2.Nacos简介 2.1特性 服务发现与服务健康检查 动态配置管理 动态DNS服务 服务和元数据管理 3.服务发现 1.配置 应用程序在启动和运行的时候往往需要读取一些配置信…...

.NET 一款获取内网共享机器的工具
01阅读须知 此文所提供的信息只为网络安全人员对自己所负责的网站、服务器等(包括但不限于)进行检测或维护参考,未经授权请勿利用文章中的技术资料对任何计算机系统进行入侵操作。利用此文所提供的信息而造成的直接或间接后果和损失…...
备考美国数学竞赛AMC8和AMC10:吃透1850道真题和知识点(持续)
距离接下来的AMC8、AMC10美国数学竞赛还有几个月的时间,实践证明,做真题,吃透真题和背后的知识点是备考AMC8、AMC10有效的方法之一。 通过做真题,可以帮助孩子找到真实竞赛的感觉,而且更加贴近比赛的内容,…...

【项目实战】通过多模态+LangGraph实现PPT生成助手
PPT自动生成系统 基于LangGraph的PPT自动生成系统,可以将Markdown文档自动转换为PPT演示文稿。 功能特点 Markdown解析:自动解析Markdown文档结构PPT模板分析:分析PPT模板的布局和风格智能布局决策:匹配内容与合适的PPT布局自动…...
可以参考以下方法:)
根据万维钢·精英日课6的内容,使用AI(2025)可以参考以下方法:
根据万维钢精英日课6的内容,使用AI(2025)可以参考以下方法: 四个洞见 模型已经比人聪明:以ChatGPT o3为代表的AI非常强大,能运用高级理论解释道理、引用最新学术论文,生成对顶尖科学家都有用的…...

R语言速释制剂QBD解决方案之三
本文是《Quality by Design for ANDAs: An Example for Immediate-Release Dosage Forms》第一个处方的R语言解决方案。 第一个处方研究评估原料药粒径分布、MCC/Lactose比例、崩解剂用量对制剂CQAs的影响。 第二处方研究用于理解颗粒外加硬脂酸镁和滑石粉对片剂质量和可生产…...
的使用)
Go 并发编程基础:通道(Channel)的使用
在 Go 中,Channel 是 Goroutine 之间通信的核心机制。它提供了一个线程安全的通信方式,用于在多个 Goroutine 之间传递数据,从而实现高效的并发编程。 本章将介绍 Channel 的基本概念、用法、缓冲、关闭机制以及 select 的使用。 一、Channel…...

Go语言多线程问题
打印零与奇偶数(leetcode 1116) 方法1:使用互斥锁和条件变量 package mainimport ("fmt""sync" )type ZeroEvenOdd struct {n intzeroMutex sync.MutexevenMutex sync.MutexoddMutex sync.Mutexcurrent int…...

掌握 HTTP 请求:理解 cURL GET 语法
cURL 是一个强大的命令行工具,用于发送 HTTP 请求和与 Web 服务器交互。在 Web 开发和测试中,cURL 经常用于发送 GET 请求来获取服务器资源。本文将详细介绍 cURL GET 请求的语法和使用方法。 一、cURL 基本概念 cURL 是 "Client URL" 的缩写…...
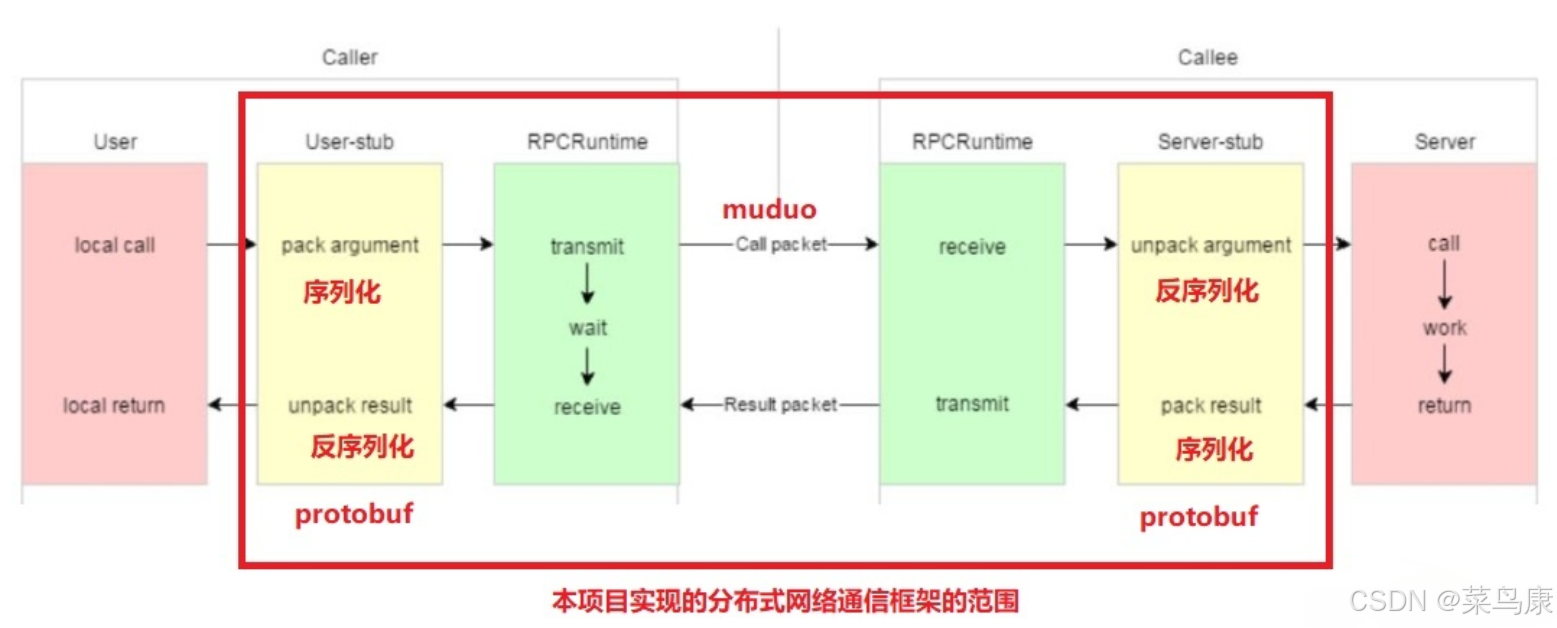
C++实现分布式网络通信框架RPC(2)——rpc发布端
有了上篇文章的项目的基本知识的了解,现在我们就开始构建项目。 目录 一、构建工程目录 二、本地服务发布成RPC服务 2.1理解RPC发布 2.2实现 三、Mprpc框架的基础类设计 3.1框架的初始化类 MprpcApplication 代码实现 3.2读取配置文件类 MprpcConfig 代码实现…...

加密通信 + 行为分析:运营商行业安全防御体系重构
在数字经济蓬勃发展的时代,运营商作为信息通信网络的核心枢纽,承载着海量用户数据与关键业务传输,其安全防御体系的可靠性直接关乎国家安全、社会稳定与企业发展。随着网络攻击手段的不断升级,传统安全防护体系逐渐暴露出局限性&a…...

从零开始了解数据采集(二十八)——制造业数字孪生
近年来,我国的工业领域正经历一场前所未有的数字化变革,从“双碳目标”到工业互联网平台的推广,国家政策和市场需求共同推动了制造业的升级。在这场变革中,数字孪生技术成为备受关注的关键工具,它不仅让企业“看见”设…...

Easy Excel
Easy Excel 一、依赖引入二、基本使用1. 定义实体类(导入/导出共用)2. 写 Excel3. 读 Excel 三、常用注解说明(完整列表)四、进阶:自定义转换器(Converter) 其它自定义转换器没生效 Easy Excel在…...