【Pytorch】RNN for Image Classification

文章目录
- 1 RNN 的定义
- 2 RNN 输入 input, h_0
- 3 RNN 输出 output, h_n
- 4 多层
- 5 小试牛刀
学习参考来自
- pytorch中nn.RNN()总结
- RNN for Image Classification(RNN图片分类–MNIST数据集)
- pytorch使用-nn.RNN
- Building RNNs is Fun with PyTorch and Google Colab
1 RNN 的定义

nn.RNN(input_size, hidden_size, num_layers=1, nonlinearity=tanh, bias=True, batch_first=False, dropout=0, bidirectional=False)
参数说明
- input_size输入特征的维度, 一般 rnn 中输入的是词向量,那么 input_size 就等于一个词向量的维度
- hidden_size隐藏层神经元个数,或者也叫输出的维度(因为rnn输出为各个时间步上的隐藏状态)
- num_layers网络的层数
- nonlinearity激活函数
- bias是否使用偏置
- batch_first输入数据的形式,默认是 False,就是这样形式,(seq(num_step), batch, input_dim),也就是将序列长度放在第一位,batch 放在第二位
- dropout是否应用dropout, 默认不使用,如若使用将其设置成一个0-1的数字即可
- birdirectional是否使用双向的 rnn,默认是 False
2 RNN 输入 input, h_0
input 形状: 当设置 batch_first = False 时, ( L , N , H i n ) (L , N , H_{ i n}) (L,N,Hin) —— [时间步数, 批量大小, 特征维度]
当设置 batch_first = True时, ( N , L , H i n ) (N , L , H_{ i n}) (N,L,Hin)
当输入只有两个维度且 batch_size 为 1 时 : ( L , H i n ) (L, H_{in}) (L,Hin) 时,需要调用 torch.unsqueeze() 增加维度。
h_0 形状: ( D ∗ n u m _ l a y e r s , N , H o u t ) ( D ∗ n u m \_ l a y e r s , N , H _{o u t} ) (D∗num_layers,N,Hout), D 代表单向 RNN 还是双向 RNN。

3 RNN 输出 output, h_n
output 形状:当设置 batch_first = False 时, ( L , N , D ∗ H o u t ) (L, N, D * H_{out}) (L,N,D∗Hout)—— [时间步数, 批量大小, 隐藏单元个数];
当设置 batch_first = True 时, ( N , L , D ∗ H o u t ) (N, L, D * H_{out}) (N,L,D∗Hout)。
h_n 形状: ( D ∗ num_layers , N , H o u t ) (D * \text{num\_layers}, N, H_{out}) (D∗num_layers,N,Hout)
4 多层

5 小试牛刀

如MNIST中28行看成28个序列, 每个序列有28个特征

x_0 到 x_27, 相当于依次输入图像的28行
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import numpy as np
import matplotlib.pyplot as plt# -------------
# MNIST dataset
# -------------
batch_size = 128
train_dataset = torchvision.datasets.MNIST(root='./',train=True,transform=transforms.ToTensor(),download=True)
test_dataset = torchvision.datasets.MNIST(root='./',train=False,transform=transforms.ToTensor())
# Data loader
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,batch_size=batch_size,shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,batch_size=batch_size,shuffle=False)# ---------------------
# Exploring the dataset
# ---------------------
# function to show an image
def imshow(img):npimg = img.numpy()plt.imshow(np.transpose(npimg, (1, 2, 0)))# get some random training images
dataiter = iter(train_loader)
images, labels = dataiter.next()if 1:# show imageimshow(torchvision.utils.make_grid(images, nrow=15))plt.show()# ----------
# parameters
# ----------
N_STEPS = 28
N_INPUTS = 28 # 输入数据的维度
N_NEURONS = 150 # RNN中间的特征的大小
N_OUTPUT = 10 # 输出数据的维度(分类的个数)
N_EPHOCS = 10 # epoch的大小
N_LAYERS = 3# ------
# models
# ------
class ImageRNN(nn.Module):def __init__(self, batch_size, n_inputs, n_neurons, n_outputs, n_layers):super(ImageRNN, self).__init__()self.batch_size = batch_size # 输入的时候batch_size, 128self.n_inputs = n_inputs # 输入的维度, 28self.n_outputs = n_outputs # 分类的大小 10self.n_neurons = n_neurons # RNN中输出的维度 150self.n_layers = n_layers # RNN中的层数 3self.basic_rnn = nn.RNN(self.n_inputs, self.n_neurons, num_layers=self.n_layers)self.FC = nn.Linear(self.n_neurons, self.n_outputs)def init_hidden(self):# (num_layers, batch_size, n_neurons)# initialize hidden weights with zero values# 这个是net的memory, 初始化memory为0return (torch.zeros(self.n_layers, self.batch_size, self.n_neurons).to(device))def forward(self, x): # torch.Size([128, 28, 28])# transforms x to dimensions : n_step × batch_size × n_inputsx = x.permute(1, 0, 2) # 需要把n_step放在第一个, torch.Size([28, 128, 28])self.batch_size = x.size(1) # 每次需要重新计算batch_size, 因为可能会出现不能完整方下一个batch的情况 128self.hidden = self.init_hidden() # 初始化hidden state torch.Size([3, 128, 150])rnn_out, self.hidden = self.basic_rnn(x, self.hidden) # 前向传播 torch.Size([28, 128, 150]), torch.Size([3, 128, 150])out = self.FC(rnn_out[-1]) # 求出每一类的概率 torch.Size([128, 150])->torch.Size([128, 10])return out.view(-1, self.n_outputs) # 最终输出大小 : batch_size X n_output torch.Size([128, 10])# --------------------
# Device configuration
# --------------------
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# ------------------------------------
# Test the model(输入一张图片查看输出)
# ------------------------------------
# 定义模型
model = ImageRNN(batch_size, N_INPUTS, N_NEURONS, N_OUTPUT, N_LAYERS).to(device)
print(model)
"""
ImageRNN((basic_rnn): RNN(28, 150, num_layers=3)(FC): Linear(in_features=150, out_features=10, bias=True)
)
"""# 初始化模型的weight
model.basic_rnn.weight_hh_l0.data = torch.eye(n=N_NEURONS, m=N_NEURONS, out=None).to(device)
model.basic_rnn.weight_hh_l1.data = torch.eye(n=N_NEURONS, m=N_NEURONS, out=None).to(device)
model.basic_rnn.weight_hh_l2.data = torch.eye(n=N_NEURONS, m=N_NEURONS, out=None).to(device)# 定义数据
dataiter = iter(train_loader)
images, labels = dataiter.next()
model.hidden = model.init_hidden()
logits = model(images.view(-1, 28, 28).to(device))
print(logits[0:2])
"""
tensor([[-0.2846, -0.1503, -0.1593, 0.5478, 0.6827, 0.3489, -0.2989, 0.4575,-0.2426, -0.0464],[-0.6708, -0.3025, -0.0205, 0.2242, 0.8470, 0.2654, -0.0381, 0.6646,-0.4479, 0.2523]], device='cuda:0', grad_fn=<SliceBackward>)
"""# 产生对角线是1的矩阵
torch.eye(n=5, m=5, out=None)
"""
tensor([[1., 0., 0., 0., 0.],[0., 1., 0., 0., 0.],[0., 0., 1., 0., 0.],[0., 0., 0., 1., 0.],[0., 0., 0., 0., 1.]])
"""# --------
# Training
# --------
model = ImageRNN(batch_size, N_INPUTS, N_NEURONS, N_OUTPUT, N_LAYERS).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 初始化模型的weight
model.basic_rnn.weight_hh_l0.data = torch.eye(n=N_NEURONS, m=N_NEURONS, out=None).to(device)
model.basic_rnn.weight_hh_l1.data = torch.eye(n=N_NEURONS, m=N_NEURONS, out=None).to(device)
model.basic_rnn.weight_hh_l2.data = torch.eye(n=N_NEURONS, m=N_NEURONS, out=None).to(device)def get_accuracy(logit, target, batch_size):"""最后用来计算模型的准确率"""corrects = (torch.max(logit, 1)[1].view(target.size()).data == target.data).sum()accuracy = 100.0 * corrects/batch_sizereturn accuracy.item()# ---------
# 开始训练
# ---------
for epoch in range(N_EPHOCS):train_running_loss = 0.0train_acc = 0.0model.train()# trainging roundfor i, data in enumerate(train_loader):optimizer.zero_grad()# reset hidden statesmodel.hidden = model.init_hidden()# get inputsinputs, labels = datainputs = inputs.view(-1, 28, 28).to(device)labels = labels.to(device)# forward+backward+optimizeoutputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()train_running_loss = train_running_loss + loss.detach().item()train_acc = train_acc + get_accuracy(outputs, labels, batch_size)model.eval()print('Epoch : {:0>2d} | Loss : {:<6.4f} | Train Accuracy : {:<6.2f}%'.format(epoch, train_running_loss/i, train_acc/i))# ----------------------------------------
# Computer accuracy on the testing dataset
# ----------------------------------------
test_acc = 0.0
for i,data in enumerate(test_loader,0):inputs, labels = datalabels = labels.to(device)inputs = inputs.view(-1,28,28).to(device)outputs = model(inputs)thisBatchAcc = get_accuracy(outputs, labels, batch_size)print("Batch:{:0>2d}, Accuracy : {:<6.4f}%".format(i,thisBatchAcc))test_acc = test_acc + thisBatchAcc
print('============平均准确率===========')
print('Test Accuracy : {:<6.4f}%'.format(test_acc/i))
"""
Epoch : 00 | Loss : 0.6336 | Train Accuracy : 79.32 %
Epoch : 01 | Loss : 0.2363 | Train Accuracy : 93.00 %
Epoch : 02 | Loss : 0.1852 | Train Accuracy : 94.63 %
Epoch : 03 | Loss : 0.1516 | Train Accuracy : 95.69 %
Epoch : 04 | Loss : 0.1338 | Train Accuracy : 96.13 %
Epoch : 05 | Loss : 0.1198 | Train Accuracy : 96.67 %
Epoch : 06 | Loss : 0.1254 | Train Accuracy : 96.46 %
Epoch : 07 | Loss : 0.1128 | Train Accuracy : 96.88 %
Epoch : 08 | Loss : 0.1059 | Train Accuracy : 97.09 %
Epoch : 09 | Loss : 0.1048 | Train Accuracy : 97.10 %
Batch:00, Accuracy : 98.4375%
Batch:01, Accuracy : 98.4375%
Batch:02, Accuracy : 95.3125%
Batch:03, Accuracy : 98.4375%
Batch:04, Accuracy : 96.8750%
Batch:05, Accuracy : 93.7500%
Batch:06, Accuracy : 97.6562%
Batch:07, Accuracy : 95.3125%
Batch:08, Accuracy : 94.5312%
Batch:09, Accuracy : 92.9688%
Batch:10, Accuracy : 96.0938%
Batch:11, Accuracy : 96.0938%
Batch:12, Accuracy : 97.6562%
Batch:13, Accuracy : 96.8750%
Batch:14, Accuracy : 96.0938%
Batch:15, Accuracy : 95.3125%
Batch:16, Accuracy : 95.3125%
Batch:17, Accuracy : 96.0938%
Batch:18, Accuracy : 96.0938%
Batch:19, Accuracy : 97.6562%
Batch:20, Accuracy : 97.6562%
Batch:21, Accuracy : 98.4375%
Batch:22, Accuracy : 96.0938%
Batch:23, Accuracy : 96.8750%
Batch:24, Accuracy : 97.6562%
Batch:25, Accuracy : 99.2188%
Batch:26, Accuracy : 96.0938%
Batch:27, Accuracy : 94.5312%
Batch:28, Accuracy : 98.4375%
Batch:29, Accuracy : 94.5312%
Batch:30, Accuracy : 96.0938%
Batch:31, Accuracy : 93.7500%
Batch:32, Accuracy : 96.8750%
Batch:33, Accuracy : 96.0938%
Batch:34, Accuracy : 95.3125%
Batch:35, Accuracy : 96.8750%
Batch:36, Accuracy : 97.6562%
Batch:37, Accuracy : 93.7500%
Batch:38, Accuracy : 94.5312%
Batch:39, Accuracy : 100.0000%
Batch:40, Accuracy : 99.2188%
Batch:41, Accuracy : 100.0000%
Batch:42, Accuracy : 98.4375%
Batch:43, Accuracy : 98.4375%
Batch:44, Accuracy : 96.8750%
Batch:45, Accuracy : 99.2188%
Batch:46, Accuracy : 96.0938%
Batch:47, Accuracy : 98.4375%
Batch:48, Accuracy : 97.6562%
Batch:49, Accuracy : 100.0000%
Batch:50, Accuracy : 99.2188%
Batch:51, Accuracy : 91.4062%
Batch:52, Accuracy : 96.8750%
Batch:53, Accuracy : 99.2188%
Batch:54, Accuracy : 99.2188%
Batch:55, Accuracy : 100.0000%
Batch:56, Accuracy : 98.4375%
Batch:57, Accuracy : 98.4375%
Batch:58, Accuracy : 97.6562%
Batch:59, Accuracy : 100.0000%
Batch:60, Accuracy : 99.2188%
Batch:61, Accuracy : 96.0938%
Batch:62, Accuracy : 100.0000%
Batch:63, Accuracy : 97.6562%
Batch:64, Accuracy : 97.6562%
Batch:65, Accuracy : 96.8750%
Batch:66, Accuracy : 98.4375%
Batch:67, Accuracy : 100.0000%
Batch:68, Accuracy : 100.0000%
Batch:69, Accuracy : 100.0000%
Batch:70, Accuracy : 96.8750%
Batch:71, Accuracy : 98.4375%
Batch:72, Accuracy : 100.0000%
Batch:73, Accuracy : 99.2188%
Batch:74, Accuracy : 100.0000%
Batch:75, Accuracy : 96.0938%
Batch:76, Accuracy : 95.3125%
Batch:77, Accuracy : 96.8750%
Batch:78, Accuracy : 12.5000%
============平均准确率===========
Test Accuracy : 97.4559%
# """# 定义hook
class SaveFeatures():"""注册hook和移除hook"""def __init__(self, module):self.hook = module.register_forward_hook(self.hook_fn)def hook_fn(self, module, input, output):self.features = outputdef close(self):self.hook.remove()# 绑定到model上
activations = SaveFeatures(model.basic_rnn)# 定义数据
dataiter = iter(train_loader)
images, labels = dataiter.next()# 前向传播
model.hidden = model.init_hidden()
logits = model(images.view(-1, 28, 28).to(device))
activations.close() # 移除hook# 这个是 28(step)*128(batch_size)*150(hidden_size)
print(activations.features[0].shape)
# torch.Size([28, 128, 150])
print(activations.features[0][-1].shape)
# torch.Size([128, 150])

相关文章:
【Pytorch】RNN for Image Classification
文章目录 1 RNN 的定义2 RNN 输入 input, h_03 RNN 输出 output, h_n4 多层5 小试牛刀 学习参考来自 pytorch中nn.RNN()总结RNN for Image Classification(RNN图片分类–MNIST数据集)pytorch使用-nn.RNNBuilding RNNs is Fun with PyTorch and Google Colab 1 RNN 的定义 nn.…...

基于Java的飞机大战游戏的设计与实现论文
点击下载源码 基于Java的飞机大战游戏的设计与实现 摘 要 现如今,随着智能手机的兴起与普及,加上4G(the 4th Generation mobile communication ,第四代移动通信技术)网络的深入,越来越多的IT行业开始向手机…...

初识影刀:EXCEL根据部门筛选低值易耗品
第一次知道这个办公自动化的软件还是在招聘网站上,了解之后发现对于办公中重复性的工作还是挺有帮助的,特别是那些操作非EXCEL的重复性工作,当然用在EXCEL上更加方便,有些操作比写VBA便捷。 下面就是一个了解基本操作后ÿ…...

nginx的四层负载均衡实战
目录 1 环境准备 1.1 mysql 部署 1.2 nginx 部署 1.3 关闭防火墙和selinux 2 nginx配置 2.1 修改nginx主配置文件 2.2 创建stream配置文件 2.3 重启nginx 3 测试四层代理是否轮循成功 3.1 远程链接通过代理服务器访问 3.2 动图演示 4 四层反向代理算法介绍 4.1 轮询࿰…...

中职网络安全B模块Cenots6.8数据库
任务环境说明: ✓ 服务器场景:CentOS6.8(开放链接) ✓ 用户名:root;密码:123456 进入虚拟机操作系统:CentOS 6.8,登陆数据库(用户名:root&#x…...

BGP笔记的基本概要
技术背景: 在只有IGP(诸如OSPF、IS-IS、RIP等协议,因为最初是被设计在一个单域中进行一个路由操纵,因此被统一称为Interior Gateway Protocol,内部网关协议)的时代,域间路由无法实现一个全局路由…...

【Redis】复制(Replica)
文章目录 一、复制是什么?二、 基本命令三、 配置(分为配置文件和命令配置)3.1 配置文件3.2 命令配置3.3 嵌套连接3.4 关闭从属关系 四、 复制原理五、 缺点 以下是本篇文章正文内容 一、复制是什么? 主从复制 masterÿ…...

封装了一个仿照抖音效果的iOS评论弹窗
需求背景 开发一个类似抖音评论弹窗交互效果的弹窗,支持滑动消失, 滑动查看评论 效果如下图 思路 创建一个视图,该视图上面放置一个tableView, 该视图上添加一个滑动手势,同时设置代理,实现代理方法 (BOOL)gestur…...

【JavaWeb程序设计】Servlet(二)
目录 一、改进上一篇博客Servlet(一)的第一题 1. 运行截图 2. 建表 3. 实体类 4. JSP页面 4.1 login.jsp 4.2 loginSuccess.jsp 4.3 loginFail.jsp 5. mybatis-config.xml 6. 工具类:创建SqlSessionFactory实例,进行 My…...

php探针
php探针是用来探测空间、服务器运行状况和PHP信息用的,探针可以实时查看服务器硬盘资源、内存占用、网卡流量、系统负载、服务器时间等信息。 下面就分享下我是怎样利用php探针来探测服务器网站空间速度、性能、安全功能等。 具体步骤如下: 1.从网上下…...

泰勒级数 (Taylor Series) 动画展示 包括源码
泰勒级数 (Taylor Series) 动画展示 包括源码 flyfish 泰勒级数(英语:Taylor series)用无限项连加式 - 级数来表示一个函数,这些相加的项由函数在某一点的导数求得。 定义了一个函数f(x)表示要近似的函数 sin ( x ) \sin(x) …...

蔚来汽车:拥抱TiDB,实现数据库性能与稳定性的飞跃
作者: Billdi表弟 原文来源: https://tidb.net/blog/449c3f5b 演讲嘉宾:吴记 蔚来汽车Tidb爱好者 整理编辑:黄漫绅(表妹)、李仲舒、吴记 本文来自 TiDB 社区合肥站走进蔚来汽车——来自吴记老师的演讲…...

【Django+Vue3 线上教育平台项目实战】构建高效线上教育平台之首页模块
文章目录 前言一、导航功能实现a.效果图:b.后端代码c.前端代码 二、轮播图功能实现a.效果图b.后端代码c.前端代码 三、标签栏功能实现a.效果图b.后端代码c.前端代码 四、侧边栏功能实现1.整体效果图2.侧边栏功能实现a.效果图b.后端代码c.前端代码 3.侧边栏展示分类及…...

对比 UUIDv1 和 UUIDv6
UUIDv6是UUIDv1的字段兼容版本,重新排序以改善数据库局部性。UUIDv6主要在使用UUIDv1的上下文中实现。不涉及遗留UUIDv1的系统应该改用UUIDv7。 与 UUIDv1 将时间戳分割成低、中、高三个部分不同,UUIDv6 改变了这一序列,使时间戳字节从最重要…...
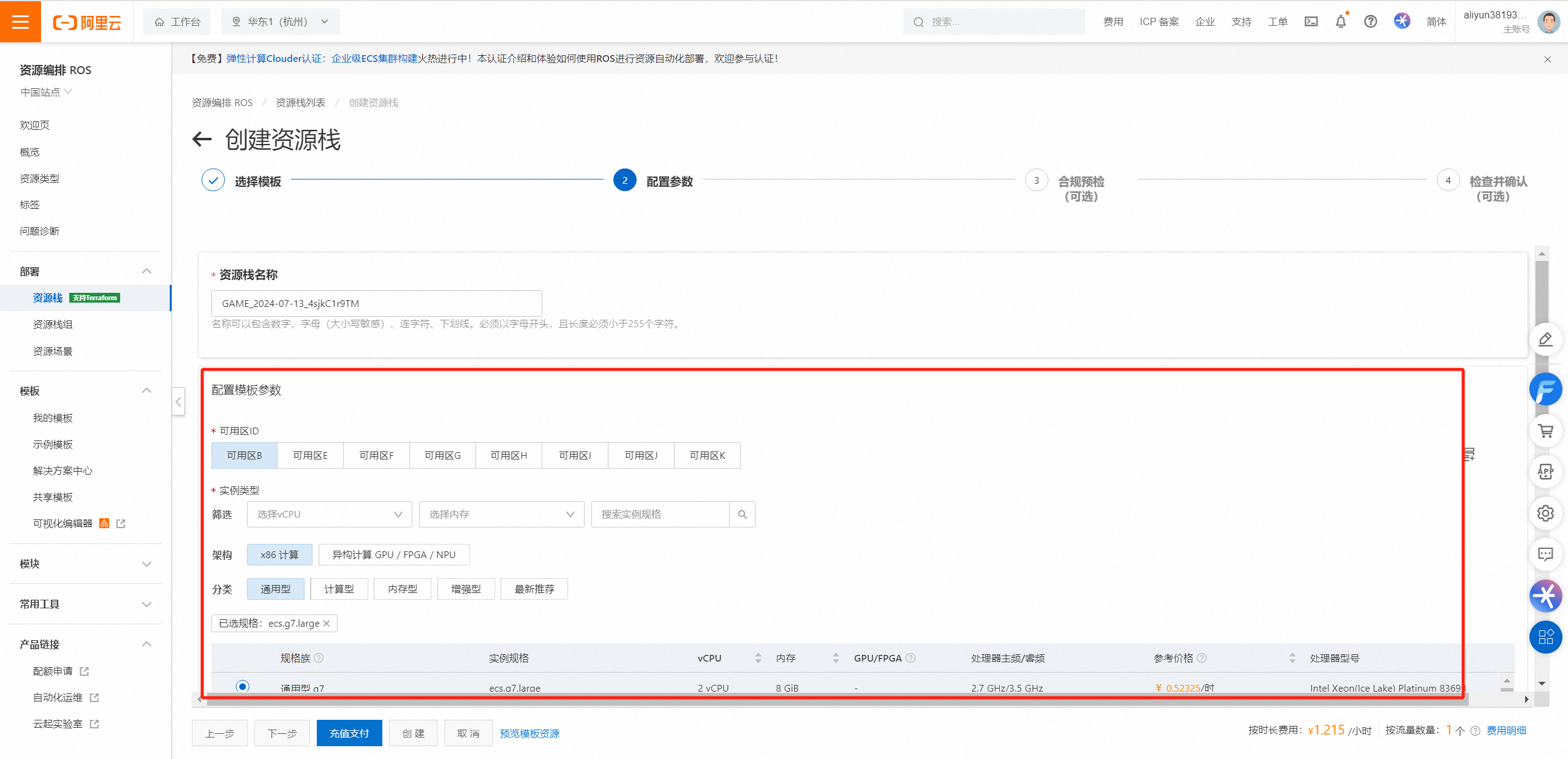
记一次饱经挫折的阿里云ROS部署经历
前言 最近在参加的几个项目测评里,我发现**“一键部署”这功能真心好用,省下了不少宝贵时间和力气,再加上看到阿里云现在有个开源上云**的活动。趁着这波热潮,今天就聊聊怎么从头开始,一步步搞定阿里云的资源编排服务…...

代码运行故障排除:PyCharm中的问题解决指南
代码运行故障排除:PyCharm中的问题解决指南 引言 PyCharm,作为一款流行的集成开发环境(IDE),提供了强大的工具来支持Python开发。然而,即使是最先进的IDE也可能遇到代码无法运行的问题。这些问题可能由多…...

css实现渐进中嵌套渐进的方法
这是我们想要的实现效果: 思路: 1.有一个底色的背景渐变 2.需要几个小的块级元素做绝对定位通过渐变filter模糊来实现 注意:这里的采用的定位方法,所以在内部的元素一律要使用绝对定位,否则会出现层级的问题&…...

JavaWeb后端学习
Web:全球局域网,万维网,能通过浏览器访问的网站 Maven Apache旗下的一个开源项目,是一款用于管理和构建Java项目的工具 作用: 依赖管理:方便快捷的管理项目以来的资源(jar包)&am…...

VUE_TypeError: Cannot convert a BigInt value to a number at Math.pow 解决方法
错误信息 TypeError: Cannot convert a BigInt value to a number at Math.pow vue 或 react package.json添加 "browserslist": {"production": ["chrome > 67","edge > 79","firefox > 68","opera >…...

Linux下mysql数据库的导入与导出以及查看端口
一:Linux下导出数据库 1、基础导出 要在Linux系统中将MySQL数据库导出,通常使用mysqldump命令行工具。以下是一个基本的命令示例,用于导出整个数据库: mysqldump -u username -p database_name > export_filename.sql 其中&a…...
)
uniapp 对接腾讯云IM群组成员管理(增删改查)
UniApp 实战:腾讯云IM群组成员管理(增删改查) 一、前言 在社交类App开发中,群组成员管理是核心功能之一。本文将基于UniApp框架,结合腾讯云IM SDK,详细讲解如何实现群组成员的增删改查全流程。 权限校验…...

JavaSec-RCE
简介 RCE(Remote Code Execution),可以分为:命令注入(Command Injection)、代码注入(Code Injection) 代码注入 1.漏洞场景:Groovy代码注入 Groovy是一种基于JVM的动态语言,语法简洁,支持闭包、动态类型和Java互操作性,…...

Spark 之 入门讲解详细版(1)
1、简介 1.1 Spark简介 Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,8个月后成为Apache顶级项目,速度之快足见过人之处&…...
:OpenBCI_GUI:从环境搭建到数据可视化(下))
脑机新手指南(八):OpenBCI_GUI:从环境搭建到数据可视化(下)
一、数据处理与分析实战 (一)实时滤波与参数调整 基础滤波操作 60Hz 工频滤波:勾选界面右侧 “60Hz” 复选框,可有效抑制电网干扰(适用于北美地区,欧洲用户可调整为 50Hz)。 平滑处理&…...

前端倒计时误差!
提示:记录工作中遇到的需求及解决办法 文章目录 前言一、误差从何而来?二、五大解决方案1. 动态校准法(基础版)2. Web Worker 计时3. 服务器时间同步4. Performance API 高精度计时5. 页面可见性API优化三、生产环境最佳实践四、终极解决方案架构前言 前几天听说公司某个项…...

uni-app学习笔记二十二---使用vite.config.js全局导入常用依赖
在前面的练习中,每个页面需要使用ref,onShow等生命周期钩子函数时都需要像下面这样导入 import {onMounted, ref} from "vue" 如果不想每个页面都导入,需要使用node.js命令npm安装unplugin-auto-import npm install unplugin-au…...

渗透实战PortSwigger靶场-XSS Lab 14:大多数标签和属性被阻止
<script>标签被拦截 我们需要把全部可用的 tag 和 event 进行暴力破解 XSS cheat sheet: https://portswigger.net/web-security/cross-site-scripting/cheat-sheet 通过爆破发现body可以用 再把全部 events 放进去爆破 这些 event 全部可用 <body onres…...

从零开始打造 OpenSTLinux 6.6 Yocto 系统(基于STM32CubeMX)(九)
设备树移植 和uboot设备树修改的内容同步到kernel将设备树stm32mp157d-stm32mp157daa1-mx.dts复制到内核源码目录下 源码修改及编译 修改arch/arm/boot/dts/st/Makefile,新增设备树编译 stm32mp157f-ev1-m4-examples.dtb \stm32mp157d-stm32mp157daa1-mx.dtb修改…...

汇编常见指令
汇编常见指令 一、数据传送指令 指令功能示例说明MOV数据传送MOV EAX, 10将立即数 10 送入 EAXMOV [EBX], EAX将 EAX 值存入 EBX 指向的内存LEA加载有效地址LEA EAX, [EBX4]将 EBX4 的地址存入 EAX(不访问内存)XCHG交换数据XCHG EAX, EBX交换 EAX 和 EB…...

C++八股 —— 单例模式
文章目录 1. 基本概念2. 设计要点3. 实现方式4. 详解懒汉模式 1. 基本概念 线程安全(Thread Safety) 线程安全是指在多线程环境下,某个函数、类或代码片段能够被多个线程同时调用时,仍能保证数据的一致性和逻辑的正确性…...