大数据-学习实践-5企业级解决方案
大数据-学习实践-5企业级解决方案
(大数据系列)
文章目录
- 大数据-学习实践-5企业级解决方案
- 1知识点
- 2具体内容
- 2.1小文件问题
- 2.1.1 SequenceFile
- 2.1.2 MapFile
- 2.1.3 小文件存储计算
- 2.2数据倾斜
- 2.3 YARN
- 2.3.1 YARN架构
- 2.3.2 YARN调度器
- 2.3.2 YARN多资源队列配置和使用
- 2.4Hadoop官方文档
- 2.5总结
- 3待补充
- 4Q&A
- 5code
- 6参考
1知识点
- 小文件问题
- 小文件存储计算
- 数据倾斜
- YARN
- Hadoop官方
2具体内容
2.1小文件问题
MapReduce框架针对大数据文件设计,小文件处理效率低下,消耗内存资源
- 每个小文件在NameNode都会占用150字节的内存,每个小文件都是一个block
- 一个block产生一个inputsplit,产生一个Map任务
- 同时启动多个map任务消耗性能,影响MapReduce执行效率
2.1.1 SequenceFile
- SequenceFile是二进制文件,直接将<k,v>对序列化到文件
- 对小文件进行文件合并:文件名为k,文件内容为v,序列化到大文件
- 但需要合并文件的过程,文件大且合并后的文件不便查看,需要遍历查看每个小文件
- 读、写试验
- SequenceFile在hdfs上合并为一个文件
2.1.2 MapFile
- 排序后的MapFile,包括index和data
- index为文件的数据索引,记录每个record的key值,并保存该record在文件中的偏移位
- 访问MapFile时,索引文件被加载到内存,通过索引映射关系快速定位到指定Record所在文件位置
- 相对SequenceFile而言,MapFile的检索效率是高效的,缺点是会消耗一部分内存来存储index数据
- MapFile在hdfs上包括2个文件,index和data
2.1.3 小文件存储计算
使用SequenceFile实现小文件存储计算
- java开发,生成SequenceFile;(人工将一堆小文件处理成一个较大文件,进行MapReduce计算)
- 开发MapReduce(借助底层),读取Sequencefile,进行分布式计算
2.2数据倾斜
- 一般不对Map任务进行改动,但为了提高效率,可增加Reduce任务,需要对数据分区
- job.getPartitionerClass()实现分区
- 当MapReduce程序执行时,大部分Reduce节点执行完毕,但有一个或几个Reduce节点运行很慢,导致整个程序处理时间变长,表现为Reduce节点卡着不动
- 倾斜不严重,可增加Reduce任务个数
job.setNumReduceTasks(Integer.parseInt(args[2]));
- 倾斜严重,要把倾斜数据打散(抽样确定哪一类,打散)
String key = words[0];
if ("5".equals(key)) {//把倾斜的key打散,分成10份key = "5" + "_" + random.nextInt(10);
}
2.3 YARN
2.3.1 YARN架构
- 集群资源的管理和调度,支持主从架构,主节点最多2个,从节点可多个
- ResourceManager:主节点负责集群资源分配和管理
- NodeManager:从节点负责当前机器资源管理
- YARN主要管理内存和CPU两种资源
- NodeManager启动向ResourceManager注册,注册信息包含该节点可分配的CPU和内存总量
- 默认单节点:(yarn-site.xml文件中设置)
- yarn.nodemanager.resourece.memory-mb:单节点可分配物理内存总量,默认8Mb*1024,8G
- yarn.nodemanager.resource.cpu-vcores:单节点可分配的虚拟CPU个数,默认是8
2.3.2 YARN调度器
- FIFO Scheduler 先进先出
- Capacity Scheduler FIFO Scheduler 多队列版本(常用)
- Fair Scheduler 多队列,多用户共享资源
2.3.2 YARN多资源队列配置和使用
- 增加online队列和offline队列
- 修改 capacity-scheduler.xml 文件,并同步其他节点
<property><name>yarn.scheduler.capacity.root.queues</name><value>default,online,offline</value><description>The queues at the this level (root is the root queue).</description>
</property>
<property><name>yarn.scheduler.capacity.root.default.capacity</name><value>70</value><description>Default queue target capacity.</description>
</property>
<property><name>yarn.scheduler.capacity.root.online.capacity</name><value>10</value><description>Online queue target capacity.</description>
</property>
<property><name>yarn.scheduler.capacity.root.offline.capacity</name><value>20</value><description>Offline queue target capacity.</description>
</property>
<property><name>yarn.scheduler.capacity.root.default.maximum-capacity</name><value>70</value><description>The maximum capacity of the default queue.</description>
</property>
<property><name>yarn.scheduler.capacity.root.online.maximum-capacity</name><value>10</value><description>The maximum capacity of the online queue.</description>
</property>
<property><name>yarn.scheduler.capacity.root.offline.maximum-capacity</name><value>20</value><description>The maximum capacity of the offline queue.</description>
</property>
- 重新启动
stop-all.sh
start-all.sh
- 向offline队列提交MR任务
- online队列里面运行实时任务
- offline队列里面运行离线任务
#解析命令行通过-D传递参数,添加至conf;也可修改java程序解析各参数
String[] remainingArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
Job job = Job.getInstance(conf);
job.setJarByClass(WordCountJobQueue.class);#必须有,否则集群执行时找不到wordCountJob这个类
#重新编译上传执行
hadoop jar db_hadoop-1.0-SNAPSHOT-jar-with-dependencies.jar com.imooc.mr.WordCountJobQueue -Dmapreduce.job.queue=offline /test/hello.txt /outqueue
2.4Hadoop官方文档
- 官方文档
- 在CDH中的使用
- 在HDP中的使用
-(1080端口) Ambari组件,提供web界面
2.5总结
- MapReduce
- 原理
- 计算过程
- 执行步骤
- wordcount案例
- 日志查看:开启YARN日志聚合,启动historyServer进程
- 程序扩展:去掉Reduce
- Shuffle过程
- 序列化
- Writable实现类
- 特点
- 源码分析
- InputFormat
- OutputFormat
- 性能优化
- 小文件
- 数据倾斜
- YARN
- 资源管理:内存+CPU
- 调度器:常用CapacityScheduler
3待补充
无
4Q&A
无
5code
无
6参考
- 大数据课程资料
相关文章:

大数据-学习实践-5企业级解决方案
大数据-学习实践-5企业级解决方案 (大数据系列) 文章目录大数据-学习实践-5企业级解决方案1知识点2具体内容2.1小文件问题2.1.1 SequenceFile2.1.2 MapFile2.1.3 小文件存储计算2.2数据倾斜2.3 YARN2.3.1 YARN架构2.3.2 YARN调度器2.3.2 YARN多资源队列配置和使用2.4Hadoop官方…...

破解吲哚花菁素IR-808 N3,IR-808 azide,IR-808叠氮,酯溶性染料修饰叠氮基团,相关知识
基础产品数据(Basic Product Data):CAS号:N/A中文名:IR-808叠氮英文名:IR-808 N3,IR-808 azideIR-808结构式(Structural):详细产品数据(Detailed …...
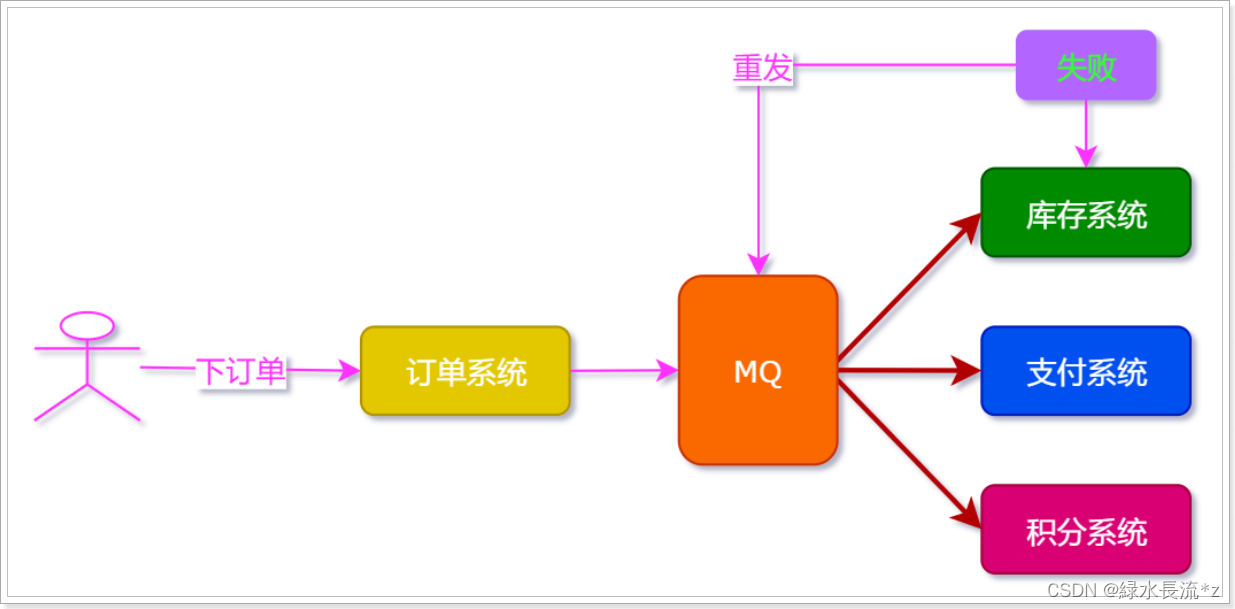
面试官:MQ的好处到底有哪些?
💗推荐阅读文章💗 🌸JavaSE系列🌸👉1️⃣《JavaSE系列教程》🌺MySQL系列🌺👉2️⃣《MySQL系列教程》🍀JavaWeb系列🍀👉3️⃣《JavaWeb系列教程》…...

事务机制:Redis能实现ACID属性吗?
ACID特性无需多言。我们知道关系数据库比如mysql可以实现事务的ACID特性,begin,commit,回滚实现。 那么redis可以实现ACID吗,结论是不能完全保证。 首先要知道redis通过MULTI关键字开启事务,中间一系列操作,加到操作队列中并不执…...
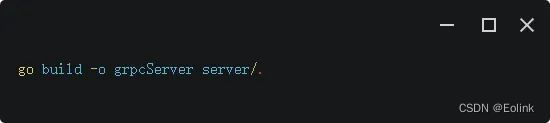
如何在 Apinto 实现 HTTP 与 gRPC 的协议转换(上)
什么是 gRPC 像 gRPC 是由 google 开发的一个高性能、通用的开源 RPC 框架,主要面向移动应用开发且基于 HTTP/2 协议标准而设计,同时支持大多数流行的编程语言。 gRPC 基于 HTTP/2 协议传输,而 HTTP/2 相比 HTTP1.x ,有以下优势:…...

3分钟看完-丄-Python自动化测试【项目实战解析】经验分享
目录:导读 引言 自动化测试 背景 测试团队 测试体系发展 测试平台 自动化测试现状 现状一: 现状二: 现状三: 现状四: 现状五: 现状六: 失败的背景 失败的经历 失败总结 引言 内…...

Web漏洞-命令执行和代码执行漏洞
命令执行原理就是指用户通过浏览器或其他辅助程序提交执行命令,由于服务器端没有针对执行函数做过滤,导致在没有指定绝对路径的情况下就执行命令。漏洞成因它所执行的命令会继承WebServer的权限,也就是说可以任意读取、修改、执行Web目录下的…...

Towards Unsupervised Text Classification Leveraging Experts and Word Embeddings
Towards Unsupervised Text Classification Leveraging Experts and Word Embeddings Abstract 该论文提出了一种无监督的方法,使用每个文档中相关单词之间的文本相似度以及每个类别的关键字字典将文档分为几类。所提出的方法通过人类专业知识和语言模型丰富了类别…...
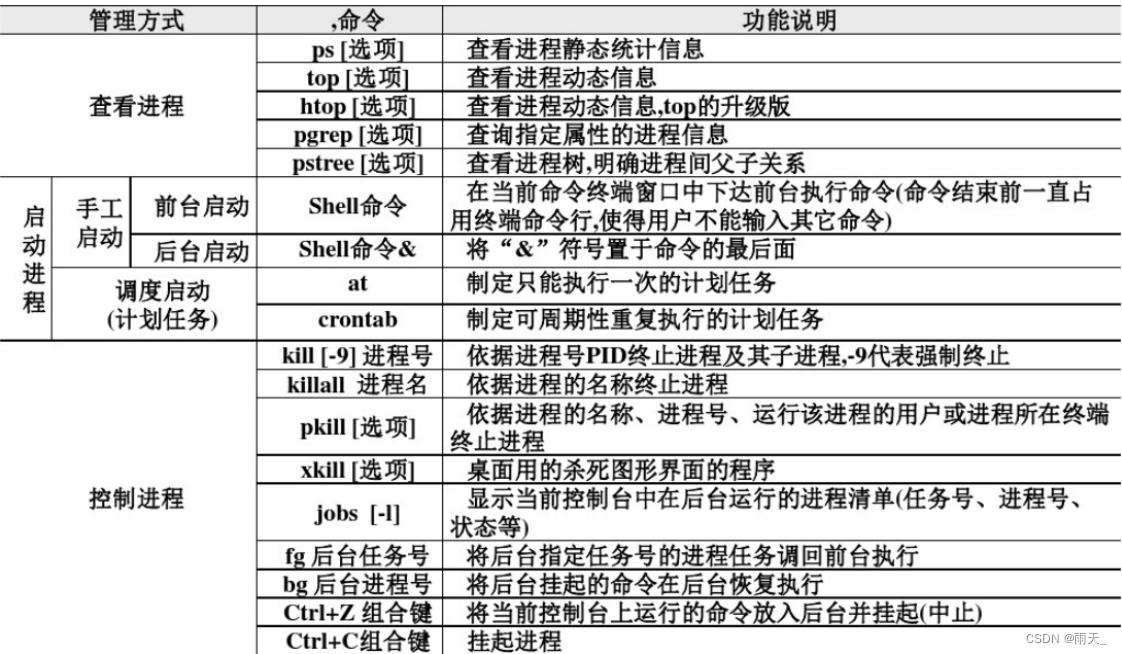
linux进程管理
进程管理 进程是启动的可执行程序的一个指令 1、进程简介 (1)进程的组成部分 已分配内存的地址空间安全属性,包括所有权凭据和特权程序代码的一个或多个执行线程进程状态 (2)程序和进程的区别 程序是一个静态的二进制…...
【深度强化学习】(6) PPO 模型解析,附Pytorch完整代码
大家好,今天和各位分享一下深度强化学习中的近端策略优化算法(proximal policy optimization,PPO),并借助 OpenAI 的 gym 环境完成一个小案例,完整代码可以从我的 GitHub 中获得: https://gith…...
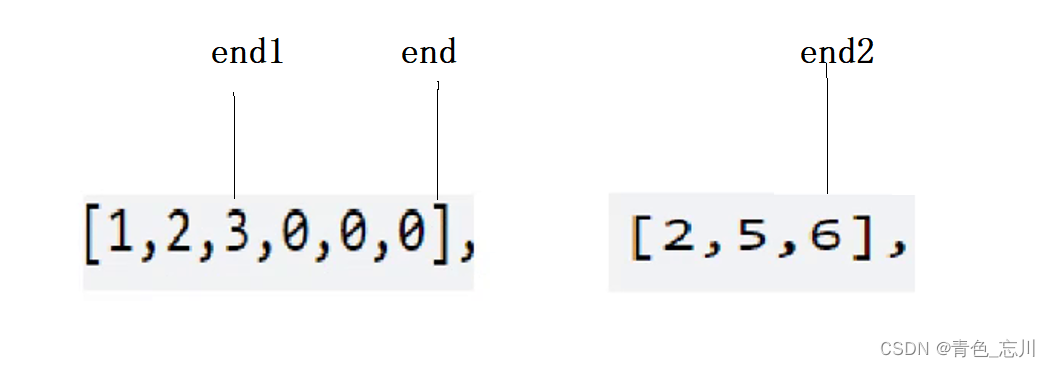
【数据结构】第二站:顺序表
目录 一、线性表 二、顺序表 1.顺序表的概念以及结构 2.顺序表的接口实现 3.顺序表完整代码 三、顺序表的经典题目 1.移除元素 2.删除有序数组中的重复项 3.合并两个有序数组 一、线性表 在了解顺序表前,我们得先了解线性表的概念 线性表(linear…...
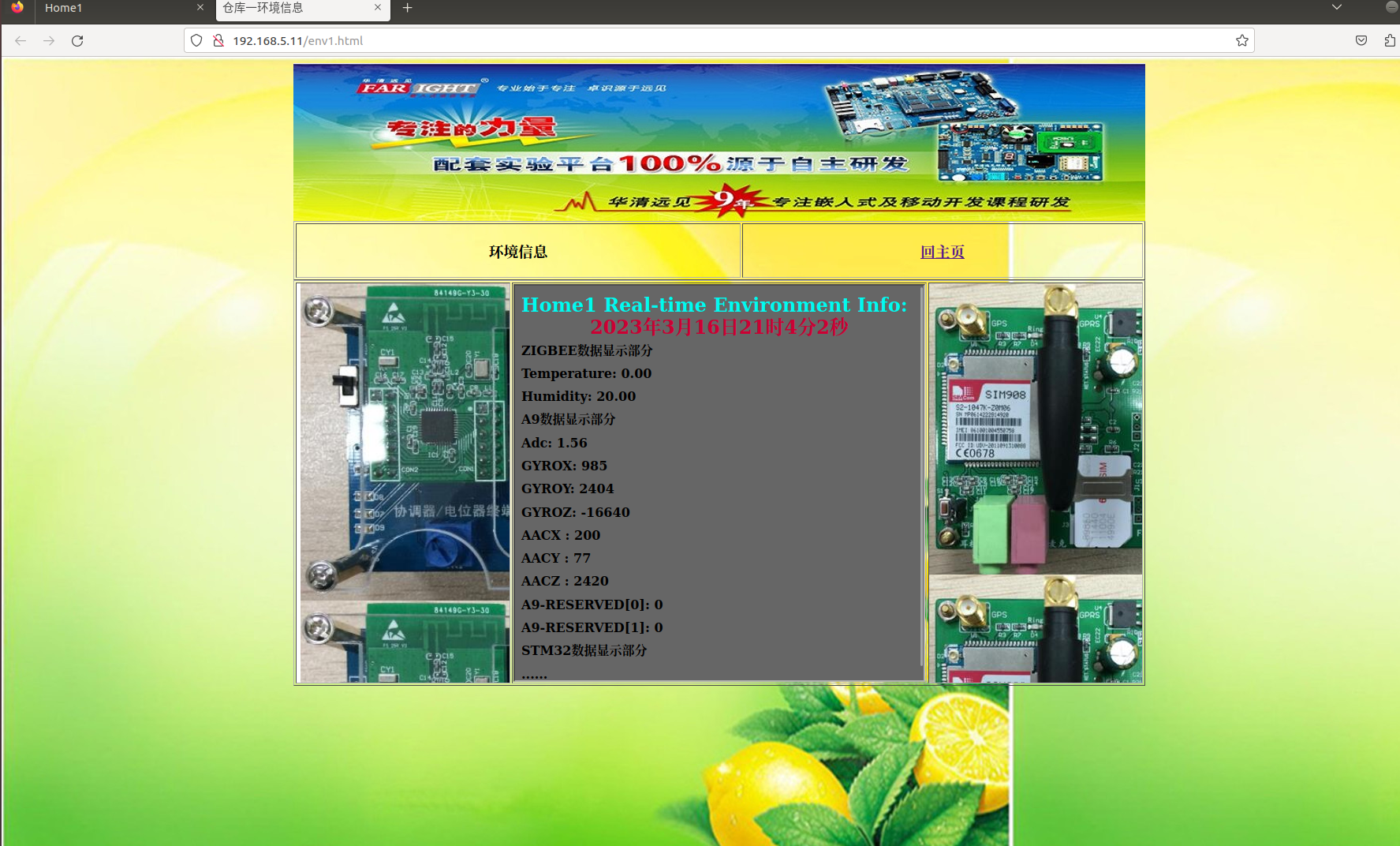
嵌入式安防监控项目——实现真实数据的上传
目录 一、相关驱动开发 二、A9主框架 三、脚本及数据上传实验 https://www.yuque.com/uh1h8r/dqrma0/tx0fq08mw1ar1sor?singleDoc# 《常见问题》 上个笔记的相关问题 一、相关驱动开发 /* mpu6050六轴传感器 */ i2c138B0000 { /* #address-cells <1>…...
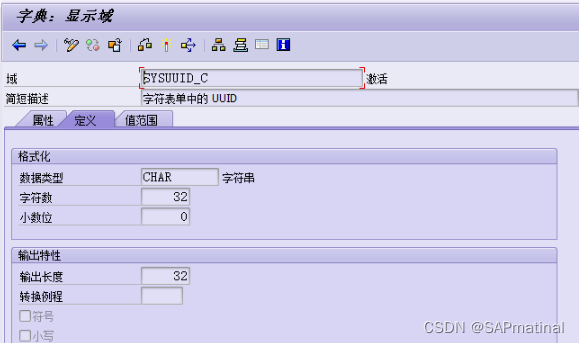
SAP 生成UUID
UUID含义是通用唯一识别码 (Universally Unique Identifier),这 是一个软件建构的标准,也是被开源软件基金会 (Open Software Foundation, OSF) 的组织应用在分布式计算环境 (Distributed Computing Environment, DCE) 领域的一部分。 UUID-Universally…...

DevOPs介绍,这一篇就足够了
一、什么是DevOps? DevOps是一种将软件开发和IT运维进行整合的文化和运动。它的目标是通过加强软件开发、测试和运维之间的协作和沟通,使整个软件开发和交付过程更加高效、快速、安全和可靠。DevOps涵盖了从计划和设计到开发、测试、交付和部署的全生命…...
libcurl库简介
一、libcurl简介libcurl是一个跨平台的网络协议库,支持http, https, ftp, gopher, telnet, dict, file, 和ldap 协议。libcurl同样支持HTTPS证书授权,HTTP POST, HTTP PUT, FTP 上传, HTTP基本表单上传,代理,cookies,和用户认证。…...
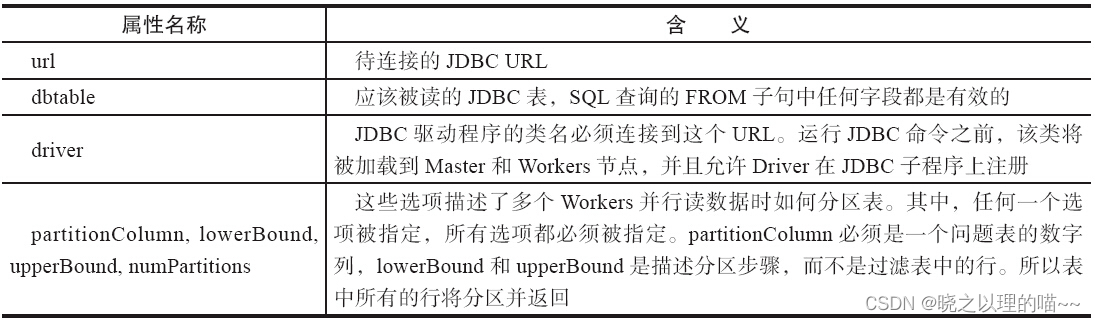
Spark SQL支持DataFrame操作的数据源
DataFrame提供统一接口加载和保存数据源中的数据,包括:结构化数据、Parquet文件、JSON文件、Hive表,以及通过JDBC连接外部数据源。一个DataFrame可以作为普通的RDD操作,也可以通过(registerTempTable)注册成…...
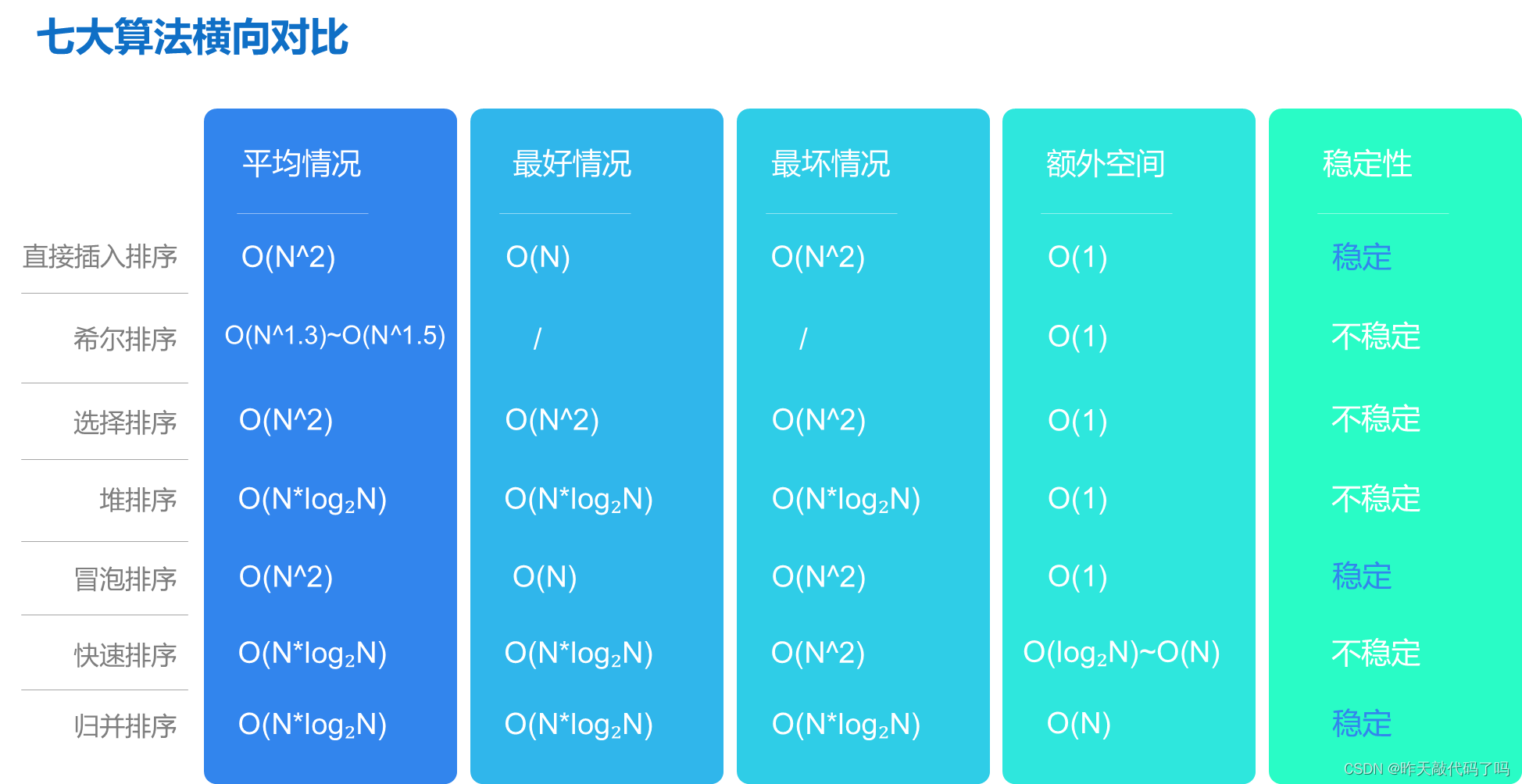
Java【归并排序】算法, 大白话式图文解析(附代码)
文章目录前言一、排序相关概念1, 什么是排序2, 什么是排序的稳定性3, 七大排序分类二、归并排序1, 图文解析2, 代码实现三、性能分析四、七大排序算法总体分析前言 各位读者好, 我是小陈, 这是我的个人主页 小陈还在持续努力学习编程, 努力通过博客输出所学知识 如果本篇对你有…...

【springboot】数据库访问
1、SQL 1、数据源的自动配置-HikariDataSource 1、导入JDBC场景 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jdbc</artifactId></dependency>数据库驱动? 为什么导入JD…...

普通和hive兼容模式下sql的差异
–odps sql –– –author:宋文理 –create time:2023-03-08 15:23:52 –– – 差异分为三块 – 1.运算符的差异 – 2.类型转换的差异 – 3.内建函数的差异 – 以下是运算符的差异: – BITAND(&) – 当输入参数是BIGINT类型的时候&…...
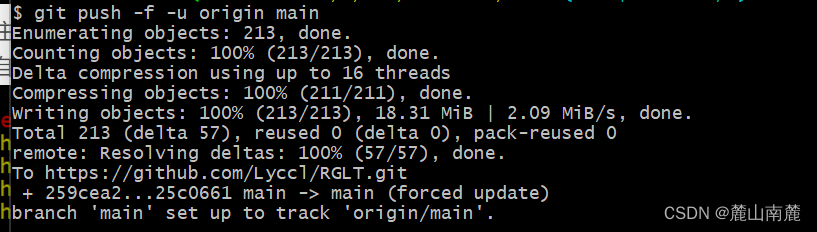
github开源自己代码
接下来,我们需要先下载Git,的网址:https://git-scm.com/downloads,安装时如果没有特殊需求,一直下一步就可以了,安装完成之后,双击打开Git Bash 出现以下界面: 第一步:…...

idea大量爆红问题解决
问题描述 在学习和工作中,idea是程序员不可缺少的一个工具,但是突然在有些时候就会出现大量爆红的问题,发现无法跳转,无论是关机重启或者是替换root都无法解决 就是如上所展示的问题,但是程序依然可以启动。 问题解决…...

Lombok 的 @Data 注解失效,未生成 getter/setter 方法引发的HTTP 406 错误
HTTP 状态码 406 (Not Acceptable) 和 500 (Internal Server Error) 是两类完全不同的错误,它们的含义、原因和解决方法都有显著区别。以下是详细对比: 1. HTTP 406 (Not Acceptable) 含义: 客户端请求的内容类型与服务器支持的内容类型不匹…...

EtherNet/IP转DeviceNet协议网关详解
一,设备主要功能 疆鸿智能JH-DVN-EIP本产品是自主研发的一款EtherNet/IP从站功能的通讯网关。该产品主要功能是连接DeviceNet总线和EtherNet/IP网络,本网关连接到EtherNet/IP总线中做为从站使用,连接到DeviceNet总线中做为从站使用。 在自动…...

代理篇12|深入理解 Vite中的Proxy接口代理配置
在前端开发中,常常会遇到 跨域请求接口 的情况。为了解决这个问题,Vite 和 Webpack 都提供了 proxy 代理功能,用于将本地开发请求转发到后端服务器。 什么是代理(proxy)? 代理是在开发过程中,前端项目通过开发服务器,将指定的请求“转发”到真实的后端服务器,从而绕…...

ABAP设计模式之---“简单设计原则(Simple Design)”
“Simple Design”(简单设计)是软件开发中的一个重要理念,倡导以最简单的方式实现软件功能,以确保代码清晰易懂、易维护,并在项目需求变化时能够快速适应。 其核心目标是避免复杂和过度设计,遵循“让事情保…...

Java + Spring Boot + Mybatis 实现批量插入
在 Java 中使用 Spring Boot 和 MyBatis 实现批量插入可以通过以下步骤完成。这里提供两种常用方法:使用 MyBatis 的 <foreach> 标签和批处理模式(ExecutorType.BATCH)。 方法一:使用 XML 的 <foreach> 标签ÿ…...

浪潮交换机配置track检测实现高速公路收费网络主备切换NQA
浪潮交换机track配置 项目背景高速网络拓扑网络情况分析通信线路收费网络路由 收费汇聚交换机相应配置收费汇聚track配置 项目背景 在实施省内一条高速公路时遇到的需求,本次涉及的主要是收费汇聚交换机的配置,浪潮网络设备在高速项目很少,通…...

NXP S32K146 T-Box 携手 SD NAND(贴片式TF卡):驱动汽车智能革新的黄金组合
在汽车智能化的汹涌浪潮中,车辆不再仅仅是传统的交通工具,而是逐步演变为高度智能的移动终端。这一转变的核心支撑,来自于车内关键技术的深度融合与协同创新。车载远程信息处理盒(T-Box)方案:NXP S32K146 与…...

AI+无人机如何守护濒危物种?YOLOv8实现95%精准识别
【导读】 野生动物监测在理解和保护生态系统中发挥着至关重要的作用。然而,传统的野生动物观察方法往往耗时耗力、成本高昂且范围有限。无人机的出现为野生动物监测提供了有前景的替代方案,能够实现大范围覆盖并远程采集数据。尽管具备这些优势…...

MySQL 8.0 事务全面讲解
以下是一个结合两次回答的 MySQL 8.0 事务全面讲解,涵盖了事务的核心概念、操作示例、失败回滚、隔离级别、事务性 DDL 和 XA 事务等内容,并修正了查看隔离级别的命令。 MySQL 8.0 事务全面讲解 一、事务的核心概念(ACID) 事务是…...