数学建模-Topsis(优劣解距离法)
介绍
TOPSIS法(Technique for Order Preference by Similarity to Ideal Solution) 可翻译为逼近理想解排序法,国内常简称为优劣解距离法 TOPSIS 法是一种常用的综合评价方法,其能充分利用原始数据的信息, 其结果能精确地反映各评价方案之间的差距。
C.L.Hwang 和 K.Yoon 于1981年首次提出TOPSIS (Technique for Order Preference by Similarity to an Ideal Solution),可翻译为逼近理 想解排序法,国内常简称为优劣解距离法。 TOPSIS 法是一种常用的综合评价方法,能充分利用原始数据的 信息,其结果能精确地反映各评价方案之间的差距。 基本过程为先将原始数据矩阵统一指标类型(一般正向化处理) 得到正向化的矩阵,再对正向化的矩阵进行标准化处理以消除各指 标量纲的影响,并找到有限方案中的最优方案和最劣方案,然后分 别计算各评价对象与最优方案和最劣方案间的距离,获得各评价对 象与最优方案的相对接近程度,以此作为评价优劣的依据。该方法 对数据分布及样本含量没有严格限制,数据计算简单易行
为什么要用这个东西?
当给出一组数据时,比如一个宿舍有小明、小红、小刚、小智四个人,他们的高数分别考了60、72、66、99,那么对应的排名就是4、2、3、1,修正后的排名就是:1,3,2,4,则排名的权重就是(4 + 2 + 3 + 1 = 10):1 / 10 = 0.4、3 / 10 = 0.3、2 / 10 = 0.2、4 / 10 = 0.4,虽然说小智的权重确实是最高的,但是你能通过这个权重看出差距吗?很明显不行,明明小智同学考了99分非常优秀远远超过的小明同学的60分,但是权重就是0.4和0.1,无论最后一名考多少分都是这个权重,无法得出他们之前的真实的差距,咦,这时候Topsis就有用了,请继续往下看
量纲
极大型:
如果是上述成绩或者GDP这类的例子,得分越高越好,那么就称其为极大型指标
极小型:
如果是某个工厂产生的污染,那么就是污染越少越好,称这样的指标为极小型指标
中间型:
大家可以回忆一下初高中学的化学知识,就比如中和反应,是不是ph越接近7越好啊,这时候的ph值就是中间型指标
区间型:
还是以化学实验为例子,中等氧水体:溶解氧浓度在4-8毫克/升之间。这个区间内,水体中的大多数生物仍然可以正常进行呼吸活动,但可能在高温或其它压力下会有些许限制。这时候含氧量就是一个区间型指标了
如何计算得分?
x - min / (x - min) + (x + max)
就是x与最小值之间的距离 / x与最小值之间的距离 + x与最大值之间的距离
那么到此对这个模型的基本介绍就结束了,下面给出py的模板
Topsis的python代码模板:
import numpy as np # 导入numpy包并将其命名为np##定义正向化的函数
def positivization(x,type,i):
# x:需要正向化处理的指标对应的原始向量
# typ:指标类型(1:极小型,2:中间型,3:区间型)
# i:正在处理的是原始矩阵的哪一列if type == 1: #极小型print("第",i,"列是极小型,正向化中...")posit_x = x.max(0)-xprint("第",i,"列极小型处理完成")print("--------------------------分隔--------------------------")return posit_xelif type == 2: #中间型print("第",i,"列是中间型")best = int(input("请输入最佳值:"))m = (abs(x-best)).max()posit_x = 1-abs(x-best)/mprint("第",i,"列中间型处理完成")print("--------------------------分隔--------------------------")return posit_xelif type == 3: #区间型print("第",i,"列是区间型")a,b = [int(l) for l in input("按顺序输入最佳区间的左右界,并用逗号隔开:").split(",")]m = (np.append(a-x.min(),x.max()-b)).max()x_row = x.shape[0] #获取x的行数posit_x = np.zeros((x_row,1),dtype=float)for r in range(x_row):if x[r] < a:posit_x[r] = 1-(a-x[r])/melif x[r] > b:posit_x[r] = 1-(x[r]-b)/melse:posit_x[r] = 1print("第",i,"列区间型处理完成")print("--------------------------分隔--------------------------")return posit_x.reshape(x_row)## 第一步:从外部导入数据
#注:保证表格不包含除数字以外的内容
x_mat = np.loadtxt('20条河流的水质情况数据.csv', encoding='UTF-8-sig', delimiter=',') # 推荐使用csv格式文件## 第二步:判断是否需要正向化
n, m = x_mat.shape
print("共有", n, "个评价对象", m, "个评价指标")
judge = int(input("指标是否需要正向化处理,需要请输入1,不需要则输入0:"))
if judge == 1:position = np.array([int(i) for i in input("请输入需要正向化处理的指标所在的列,例如第1、3、4列需要处理,则输入1,3,4").split(',')])position = position-1typ = np.array([int(j) for j in input("请按照顺序输入这些列的指标类型(1:极小型,2:中间型,3:区间型)格式同上").split(',')])for k in range(position.shape[0]):x_mat[:, position[k]] = positivization(x_mat[:, position[k]], typ[k], position[k])print("正向化后的矩阵:", x_mat)## 第三步:对正向化后的矩阵进行标准化
tep_x1 = (x_mat * x_mat).sum(axis=0) # 每个元素平方后按列相加
tep_x2 = np.tile(tep_x1, (n, 1)) # 将矩阵tep_x1平铺n行
Z = x_mat / ((tep_x2) ** 0.5) # Z为标准化矩阵
print("标准化后的矩阵为:", Z)## 第四步:计算与最大值和最小值的距离,并算出得分
tep_max = Z.max(0) # 得到Z中每列的最大值
tep_min = Z.min(0) # 每列的最小值
tep_a = Z - np.tile(tep_max, (n, 1)) # 将tep_max向下平铺n行,并与Z中的每个对应元素做差
tep_i = Z - np.tile(tep_min, (n, 1)) # 将tep_max向下平铺n行,并与Z中的每个对应元素做差
D_P = ((tep_a ** 2).sum(axis=1)) ** 0.5 # D+与最大值的距离向量
D_N = ((tep_i ** 2).sum(axis=1)) ** 0.5
S = D_N / (D_P + D_N) # 未归一化的得分
std_S = S / S.sum(axis=0)
sorted_S = np.sort(std_S, axis=0)提示:此代码是适用于csv文件的如果是xlsx的话需要转csv的,请参考一下代码
import pandas as pd# 1. 从Excel文件读取数据
excel_file = '20条河流的水质情况数据.xlsx' # 输入的Excel文件名
sheet_name = 'Sheet1' # Excel文件中的工作表名称try:df = pd.read_excel(excel_file, sheet_name=sheet_name)print(f"成功从 '{excel_file}' 中读取数据。")
except FileNotFoundError:print(f"文件 '{excel_file}' 未找到。请检查文件路径和文件名是否正确。")exit(1)
except Exception as e:print(f"读取文件 '{excel_file}' 发生错误:{e}")exit(1)# 2. 将数据保存为CSV文件
csv_file = '20条河流的水质情况数据.csv' # 输出的CSV文件名try:df.to_csv(csv_file, index=False, encoding='utf-8-sig') # 使用utf-8-sig编码格式print(f"成功将数据保存到 '{csv_file}'。")
except Exception as e:print(f"保存文件 '{csv_file}' 发生错误:{e}")exit(1)print("转换完成。")
加油
相关文章:
)
数学建模-Topsis(优劣解距离法)
介绍 TOPSIS法(Technique for Order Preference by Similarity to Ideal Solution) 可翻译为逼近理想解排序法,国内常简称为优劣解距离法 TOPSIS 法是一种常用的综合评价方法,其能充分利用原始数据的信息, 其结果能精…...

嵌入式linux相机 转换模块
convert_manager.c #include <config.h> #include <convert_manager.h> #include <string.h>static PT_VideoConvert g_ptVideoConvertHead NULL;/*********************************************************************** 函数名称: Register…...

【自学安全防御】二、防火墙NAT智能选路综合实验
任务要求: (衔接上一个实验所以从第七点开始,但与上一个实验关系不大) 7,办公区设备可以通过电信链路和移动链路上网(多对多的NAT,并且需要保留一个公网IP不能用来转换) 8,分公司设备可以通过总…...

【Android】传给后端的Url地址被转码问题处理
一、问题 为什么使用Gson().toJson的时候,字符串中的会被转成\u003d 在 Gson 中,默认情况下会对某些特殊字符进行 HTML 转义,以确保生成的 JSON 字符串在 HTML 中是安全的。因此,字符 会被转义为 \u003d。你可以通过禁用 HTML 转…...

1.厦门面试
1.Vue的生命周期阶段 vue生命周期分为四个阶段 第一阶段(创建阶段):beforeCreate,created 第二阶段(挂载阶段):beforeMount(render),mounted 第三阶段&#…...
)
设计模式使用场景实现示例及优缺点(行为型模式——状态模式)
在一个遥远的国度中,有一个被称为“变幻之城”的神奇城堡。这座城堡有一种特殊的魔法,能够随着王国的需求改变自己的形态和功能。这种神奇的变化是由一个古老的机制控制的,那就是传说中的“状态宝石”。 在变幻之城中,有四颗宝石&…...

抖音短视频seo矩阵系统源码(搭建技术开发分享)
#抖音矩阵系统源码开发 #短视频矩阵系统源码开发 #短视频seo源码开发 一、 抖音短视频seo矩阵系统源码开发,需要掌握以下技术: 网络编程:能够使用Python、Java或其他编程语言进行网络编程,比如使用爬虫技术从抖音平台获取数据。…...

基于 asp.net家庭财务管理系统设计与实现
博主介绍:专注于Java .net php phython 小程序 等诸多技术领域和毕业项目实战、企业信息化系统建设,从业十五余年开发设计教学工作 ☆☆☆ 精彩专栏推荐订阅☆☆☆☆☆不然下次找不到哟 我的博客空间发布了1000毕设题目 方便大家学习使用感兴趣的可以先…...

allure_pytest:AttributeError: ‘str‘ object has no attribute ‘iter_parents‘
踩坑记录 问题描述: 接口自动化测试时出现报错,报错文件是allure_pytest库 问题分析: 自动化测试框架是比较成熟的代码,报错也不是自己写的文件,而是第三方库,首先推测是allure_pytest和某些库有版本不兼…...

C语言 反转链表
题目链接:https://leetcode.cn/problems/reverse-linked-list/description/?envTypestudy-plan-v2&envIdselected-coding-interview 完整代码: /*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/// 反转链表…...

MFC CRectTracker 类用法详解
CRectTracker 类并非 Microsoft Foundation Class (MFC) 库中应用很广泛的一个类,一般教科书中很少有提到。在编程中如果需编写选择框绘制以及选择框大小调整、移动等程序时,用CRectTracker 类就会做到事半而功倍。下面详细介绍MFC CRectTracker 类。 M…...

好玩的调度技术-场景编辑器
好玩的调度技术-场景编辑器 文章目录 好玩的调度技术-场景编辑器前言一、演示一、代码总结好玩系列 前言 这两天写前端写上瘾了,顺手做了个好玩的东西,好玩系列也好久没更新,正好作为素材写一篇文章,我真的觉得蛮好玩的ÿ…...
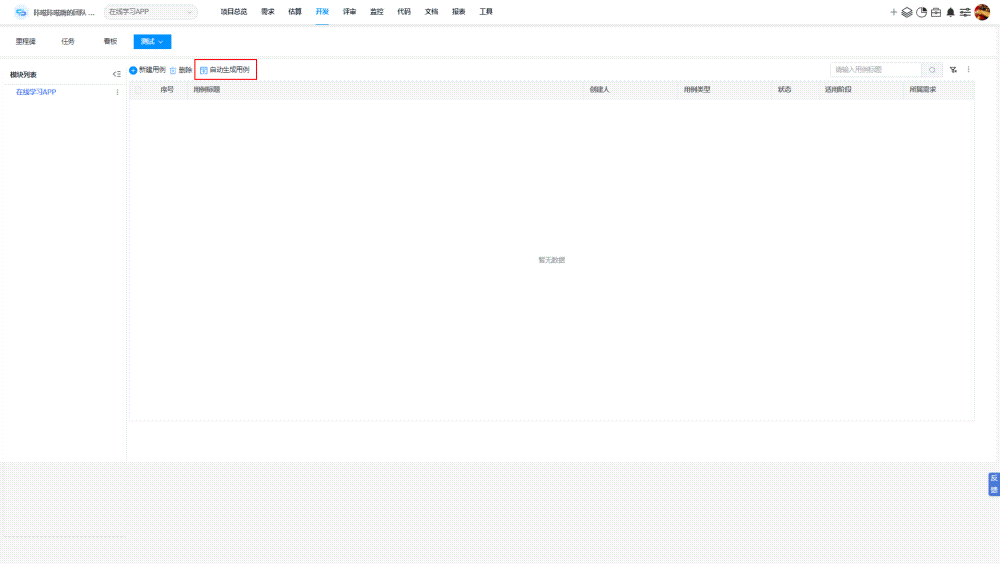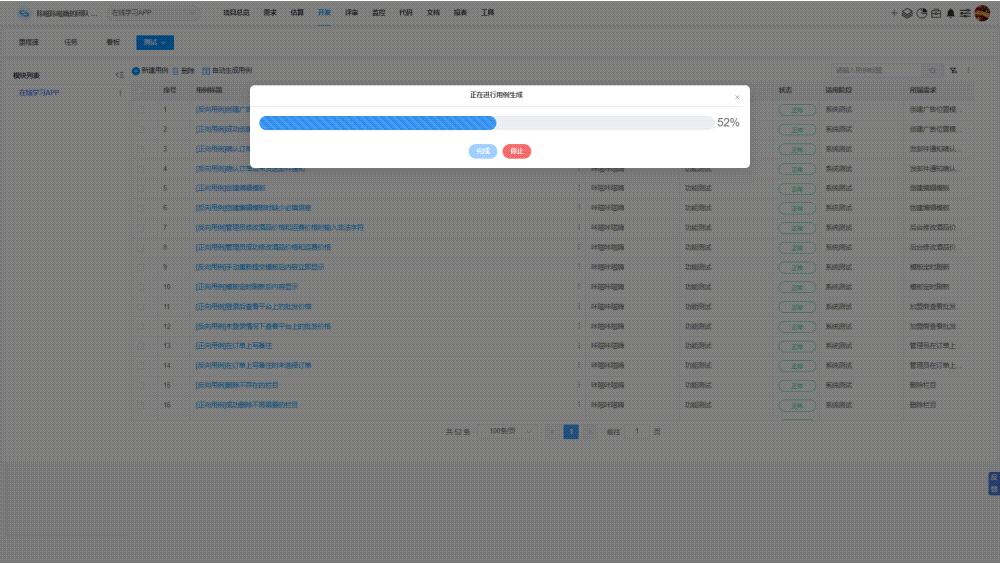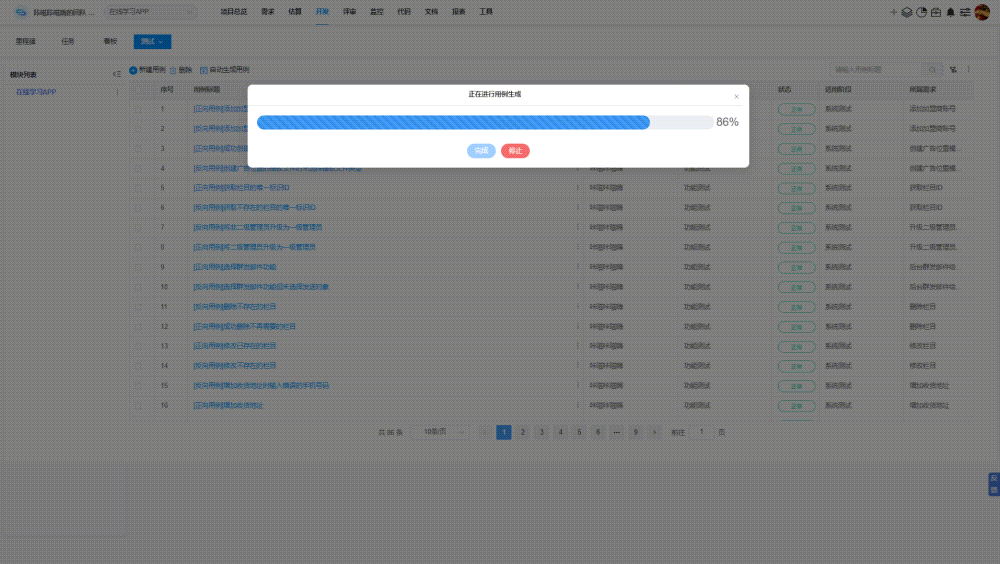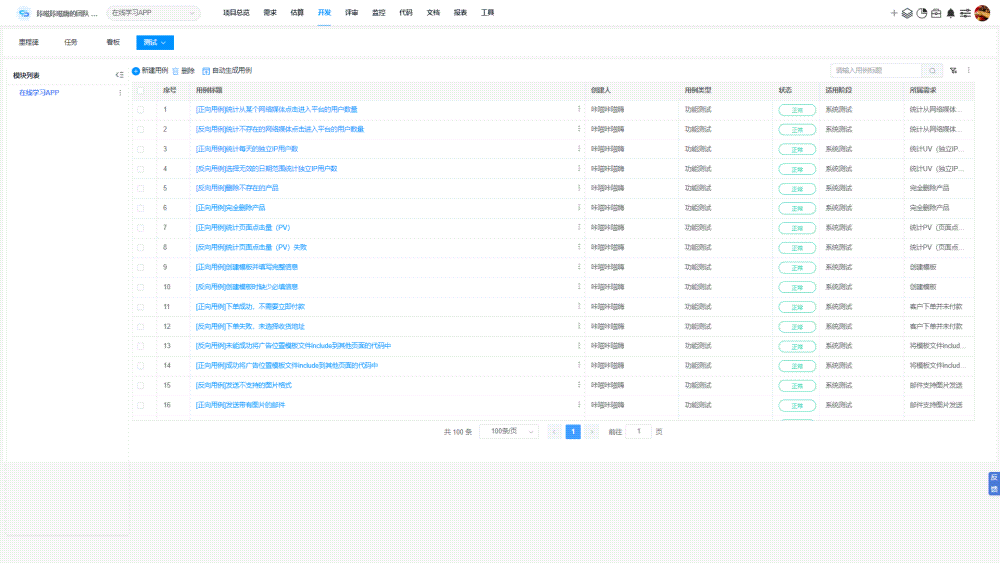
提高自动化测试脚本编写效率 5大关键注意事项
提高自动化测试脚本编写效率能加速测试周期,减少人工错误,提升软件质量,促进项目按时交付,增强团队生产力和项目成功率。而自动化测试脚本编写效率低下,往往会导致测试周期延长,增加项目成本,延…...

护眼落地灯哪个更护眼?2024年度最值得入手的5款护眼大路灯推荐
落地灯和台灯哪个更护眼?之所以我们眼睛经常酸痛,很大部分的原因是因为我们长时间在不良光线下,将注意力集中在屏幕或书本上会导致眼睛肌肉过度使用,引发疲劳和酸痛。但也不排除不正确的坐姿或者工作环境缺乏适当的照明引起的&…...

DP讨论——适配器、桥接、代理、装饰器模式通用理解
学而时习之,温故而知新。 共性 适配器、桥接、代理和装饰器模式,实现上基本没啥区别,怎么区分?只能从上下文理解,看目的是啥。 它们,我左看上看下看右看,发现理解可以这么简单:都是A类调用B/…...

Apache AGE的MATCH子句
MATCH子句允许您在数据库中指定查询将搜索的模式。这是检索数据以在查询中使用的主要方法。 通常在MATCH子句之后会跟随一个WHERE子句,以添加用户定义的限制条件到匹配的模式中,以操纵返回的数据集。谓词是模式描述的一部分,不应被视为仅在匹…...

Netty Websocket
一、WebSocket 协议概述 WebSocket 是一种在单个 TCP 连接上进行全双工通信的协议。它允许服务端主动向客户端推送数据,从而实现了实时通信。WebSocket 建立在 HTTP 之上,但与 HTTP 的轮询(Polling)和长轮询(Long Pol…...

用户注册业务逻辑、接口设计和实现、前端逻辑
一、用户注册业务逻辑分析 二、用户注册接口设计和定义 2.1. 设计接口基本思路 对于接口的设计,我们要根据具体的业务逻辑,设计出适合业务逻辑的接口。设计接口的思路: 分析要实现的业务逻辑: 明确在这个业务中涉及到几个相关子…...

ubuntu搭建harbor私仓
1、环境准备 链接: https://pan.baidu.com/s/1q4XBWPd8WdyEn4l253mpUw 提取码: 7ekx --来自百度网盘超级会员v2的分享 准备一台Ubuntu 机器:192.168.124.165 将上面两个文件考入Ubuntu上面 2、安装harbor 安装Docker Harbor仓库以容器方式运行,需要先安装好docker,参考:…...
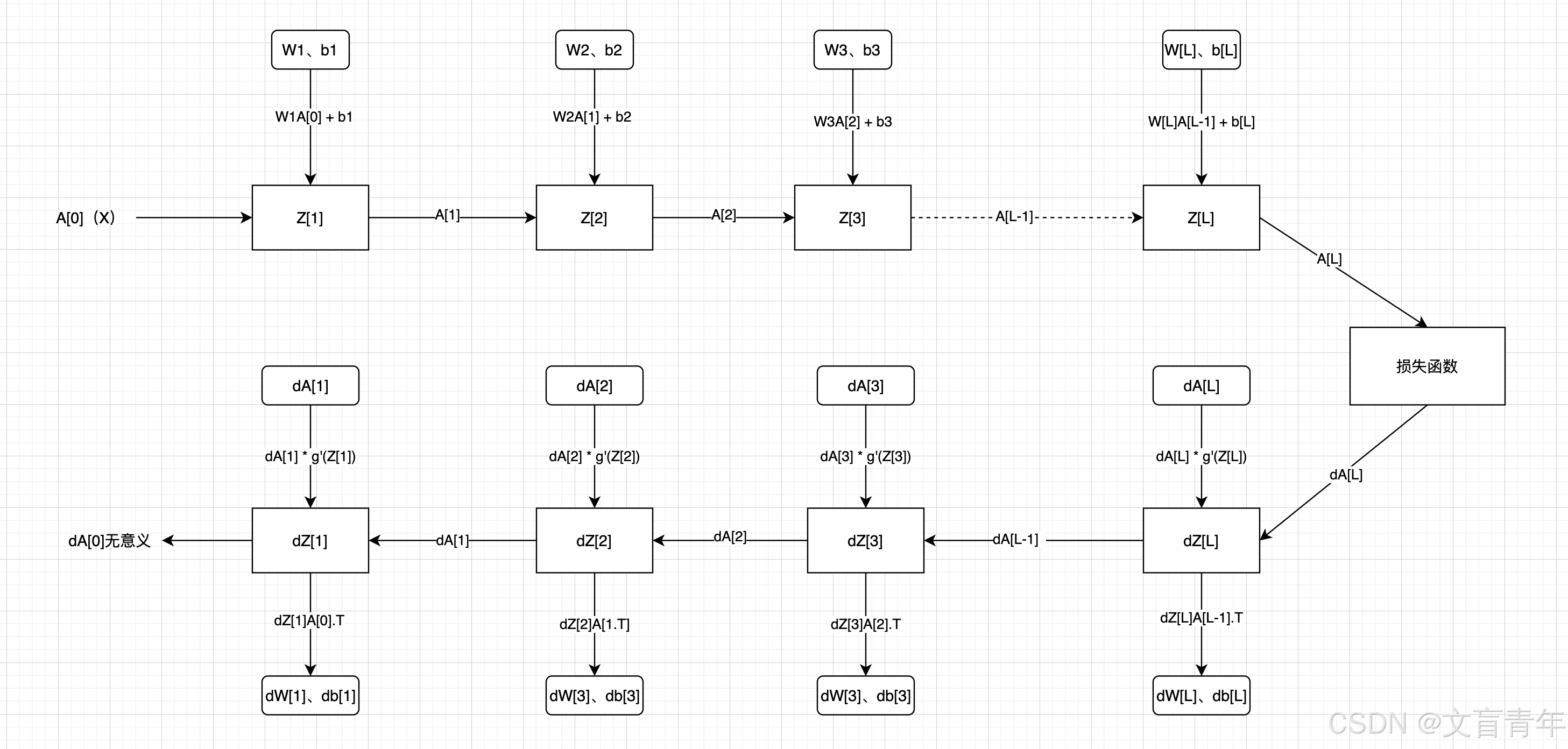
深层神经网络示例
维度说明: A[L]、Z[L]:(本层神经元个数、样本数) W[L]:(本层神经元个数、上层神经元个数) b[L]:(本层神经元个数、1) dZ[L]:dA[L] * g’A…...

Chapter03-Authentication vulnerabilities
文章目录 1. 身份验证简介1.1 What is authentication1.2 difference between authentication and authorization1.3 身份验证机制失效的原因1.4 身份验证机制失效的影响 2. 基于登录功能的漏洞2.1 密码爆破2.2 用户名枚举2.3 有缺陷的暴力破解防护2.3.1 如果用户登录尝试失败次…...

应用升级/灾备测试时使用guarantee 闪回点迅速回退
1.场景 应用要升级,当升级失败时,数据库回退到升级前. 要测试系统,测试完成后,数据库要回退到测试前。 相对于RMAN恢复需要很长时间, 数据库闪回只需要几分钟。 2.技术实现 数据库设置 2个db_recovery参数 创建guarantee闪回点,不需要开启数据库闪回。…...
Cesium相机控制)
三维GIS开发cesium智慧地铁教程(5)Cesium相机控制
一、环境搭建 <script src"../cesium1.99/Build/Cesium/Cesium.js"></script> <link rel"stylesheet" href"../cesium1.99/Build/Cesium/Widgets/widgets.css"> 关键配置点: 路径验证:确保相对路径.…...

连锁超市冷库节能解决方案:如何实现超市降本增效
在连锁超市冷库运营中,高能耗、设备损耗快、人工管理低效等问题长期困扰企业。御控冷库节能解决方案通过智能控制化霜、按需化霜、实时监控、故障诊断、自动预警、远程控制开关六大核心技术,实现年省电费15%-60%,且不改动原有装备、安装快捷、…...

vue3 字体颜色设置的多种方式
在Vue 3中设置字体颜色可以通过多种方式实现,这取决于你是想在组件内部直接设置,还是在CSS/SCSS/LESS等样式文件中定义。以下是几种常见的方法: 1. 内联样式 你可以直接在模板中使用style绑定来设置字体颜色。 <template><div :s…...

macOS多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用
文章目录 问题现象问题原因解决办法 问题现象 macOS启动台(Launchpad)多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用。 问题原因 很明显,都是Google家的办公全家桶。这些应用并不是通过独立安装的…...

Robots.txt 文件
什么是robots.txt? robots.txt 是一个位于网站根目录下的文本文件(如:https://example.com/robots.txt),它用于指导网络爬虫(如搜索引擎的蜘蛛程序)如何抓取该网站的内容。这个文件遵循 Robots…...
与常用工具深度洞察App瓶颈)
iOS性能调优实战:借助克魔(KeyMob)与常用工具深度洞察App瓶颈
在日常iOS开发过程中,性能问题往往是最令人头疼的一类Bug。尤其是在App上线前的压测阶段或是处理用户反馈的高发期,开发者往往需要面对卡顿、崩溃、能耗异常、日志混乱等一系列问题。这些问题表面上看似偶发,但背后往往隐藏着系统资源调度不当…...

云原生安全实战:API网关Kong的鉴权与限流详解
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、基础概念 1. API网关(API Gateway) API网关是微服务架构中的核心组件,负责统一管理所有API的流量入口。它像一座…...

在Mathematica中实现Newton-Raphson迭代的收敛时间算法(一般三次多项式)
考察一般的三次多项式,以r为参数: p[z_, r_] : z^3 (r - 1) z - r; roots[r_] : z /. Solve[p[z, r] 0, z]; 此多项式的根为: 尽管看起来这个多项式是特殊的,其实一般的三次多项式都是可以通过线性变换化为这个形式…...