深度学习 Day26——使用Pytorch实现猴痘病识别
深度学习 Day26——使用Pytorch实现猴痘病识别
文章目录
- 深度学习 Day26——使用Pytorch实现猴痘病识别
- 一、前言
- 二、我的环境
- 三、前期工作
- 1、设置GPU导入依赖项
- 2、导入猴痘病数据集
- 3、划分数据集
- 四、构建CNN网络
- 五、训练模型
- 1、设置超参数
- 2、编写训练函数
- 3、编写测试函数
- 4、正式训练
- 六、结果可视化
- 七、图片预测
- 八、保存模型
- 九、模型优化
一、前言
🍨 本文为🔗365天深度学习训练营 中的学习记录博客
🍦 参考文章:Pytorch实战 | 第P4周:猴痘病识别
🍖 原作者:K同学啊|接辅导、项目定制

这期博客在之前的猴痘病识别的基础上添加了指定图片预测与保存并加载模型这两个模块,将来我们训练后的模型是需要部署到真实环境中去测试的。
二、我的环境
- 电脑系统:Windows 11
- 语言环境:Python 3.8.5
- 编译器:Datalore
- 深度学习环境:
- torch 1.12.1+cu113
- torchvision 0.13.1+cu113
- 显卡及显存:RTX 3070 8G
三、前期工作
1、设置GPU导入依赖项
如果设备支持GPU就使用GPU,否则就是用CPU,但推荐深度学习使用GPU,如果设备不行,可以去网上云平台跑模型。
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasets
import os,PIL,pathlibdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")device
device(type='cuda')
2、导入猴痘病数据集
import os,PIL,random,pathlibdata_dir = 'E:\\深度学习\\data\\Day13'
data_dir = pathlib.Path(data_dir)data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("\\")[4] for path in data_paths]
classeNames
['Monkeypox', 'Others']
total_datadir = 'E:\\深度学习\\data\\Day13'train_transforms = transforms.Compose([transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])total_data = datasets.ImageFolder(total_datadir,transform=train_transforms)
total_data
Dataset ImageFolderNumber of datapoints: 2142Root location: E:\深度学习\data\Day13StandardTransform
Transform: Compose(Resize(size=[224, 224], interpolation=bilinear, max_size=None, antialias=None)ToTensor()Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]))
total_data.class_to_idx
{'Monkeypox': 0, 'Others': 1}
3、划分数据集
将总数据集分为训练集和测试集,其中训练集占总数据集的80%,测试集占20%
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
train_size, test_size
(1713, 429)
将训练集和测试集分别封装成 DataLoader 对象,方便对数据进行批量处理,batch_size 表示每个 batch 的大小,shuffle 表示是否随机打乱数据,num_workers 表示使用多少个线程来读取数据
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=32, shuffle=True, num_workers=1)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=32, shuffle=True, num_workers=1)
for X, y in test_loader:print(X.shape, y.shape)break
torch.Size([32, 3, 224, 224]) torch.Size([32])
四、构建CNN网络
接下来我们定义一个简单的CNN网络结构。
import torch.nn.functional as F# 定义一个带有Batch Normalization的卷积神经网络
class Network_bn(nn.Module):def __init__(self):super(Network_bn, self).__init__()"""nn.Conv2d()函数:第一个参数(in_channels)是输入的channel数量第二个参数(out_channels)是输出的channel数量第三个参数(kernel_size)是卷积核大小第四个参数(stride)是步长,默认为1第五个参数(padding)是填充大小,默认为0"""# 第一个卷积层,输入的channel数量是3,输出的channel数量是12,卷积核大小为5,步长为1,填充大小为0self.conv1 = nn.Conv2d(in_channels=3, out_channels=12, kernel_size=5, stride=1, padding=0)self.bn1 = nn.BatchNorm2d(12) # Batch Normalization层,输入的channel数量是12# 第二个卷积层,输入的channel数量是12,输出的channel数量是12,卷积核大小为5,步长为1,填充大小为0self.conv2 = nn.Conv2d(in_channels=12, out_channels=12, kernel_size=5, stride=1, padding=0)self.bn2 = nn.BatchNorm2d(12) # Batch Normalization层,输入的channel数量是12# 最大池化层,池化核大小为2,步长为2self.pool = nn.MaxPool2d(2,2)# 第三个卷积层,输入的channel数量是12,输出的channel数量是24,卷积核大小为5,步长为1,填充大小为0self.conv4 = nn.Conv2d(in_channels=12, out_channels=24, kernel_size=5, stride=1, padding=0)self.bn4 = nn.BatchNorm2d(24) # Batch Normalization层,输入的channel数量是24# 第四个卷积层,输入的channel数量是24,输出的channel数量是24,卷积核大小为5,步长为1,填充大小为0self.conv5 = nn.Conv2d(in_channels=24, out_channels=24, kernel_size=5, stride=1, padding=0)self.bn5 = nn.BatchNorm2d(24) # Batch Normalization层,输入的channel数量是24# 全连接层,输入的大小是24*50*50,输出的大小是类别数self.fc1 = nn.Linear(24*50*50, len(classeNames))# 定义网络的前向传播过程def forward(self, x):x = F.relu(self.bn1(self.conv1(x))) # 第一层卷积、Batch Normalization和ReLU激活函数x = F.relu(self.bn2(self.conv2(x))) # 第二层卷积、Batch Normalization和ReLU激活函数x = self.pool(x) # 最大池化层x = F.relu(self.bn4(self.conv4(x))) x = F.relu(self.bn5(self.conv5(x))) # 第五层卷积、Batch Normalization和ReLU激活函数x = self.pool(x) # 最大池化层x = x.view(-1, 24*50*50) # 将卷积层的输出展平成一维向量x = self.fc1(x) # 全连接层return xdevice = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))model = Network_bn().to(device)
model
Using cuda device
Network_bn((conv1): Conv2d(3, 12, kernel_size=(5, 5), stride=(1, 1))(bn1): BatchNorm2d(12, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(12, 12, kernel_size=(5, 5), stride=(1, 1))(bn2): BatchNorm2d(12, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(conv4): Conv2d(12, 24, kernel_size=(5, 5), stride=(1, 1))(bn4): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv5): Conv2d(24, 24, kernel_size=(5, 5), stride=(1, 1))(bn5): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(fc1): Linear(in_features=60000, out_features=2, bias=True)
)
五、训练模型
1、设置超参数
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
2、编写训练函数
我们自己定义一个训练函数train,该函数接受四个参数:dataloader,model,loss_fn和optimizer。其中,dataloader是一个PyTorch的数据加载器,用于加载训练数据;model是一个PyTorch的神经网络模型;loss_fn是一个损失函数,用于计算模型的预测误差;optimizer是一个优化器,用于更新模型的参数。函数的返回值是训练误差和训练精度。
在函数中,首先初始化训练误差和训练精度为0,然后遍历训练数据集中的每个批次。对于每个批次,首先将输入数据和标签数据转换为指定的设备(如GPU)上的张量,然后将输入数据输入模型,得到模型的预测结果。接着,使用损失函数计算模型的预测误差,并根据误差进行反向传播和参数更新。最后,累计训练误差和训练精度,并在每训练100个批次时输出当前的训练误差。最后,计算训练误差和训练精度的平均值,并输出训练误差和训练精度。该函数的作用是完成深度学习模型的训练过程,将输入数据经过模型计算得到输出结果,并根据损失函数计算输出结果与标签之间的差异,从而优化模型的参数,使模型能够更好地拟合数据。
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset)num_batches = len(dataloader)train_loss, train_acc = 0, 0for batch, (X, y) in enumerate(dataloader):X, y = X.to(device), y.to(device)# 计算预测误差pred = model(X)loss = loss_fn(pred, y)# 反向传播optimizer.zero_grad()loss.backward()optimizer.step()train_loss += loss.item()train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()if batch % 100 == 0:loss, current = loss.item(), batch * len(X)print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")train_loss /= num_batchestrain_acc /= sizeprint(f"Train Error: \n Accuracy: {(100*train_acc):>0.1f}%, Avg loss: {train_loss:>8f} \n")return train_loss, train_acc
3、编写测试函数
测试函数和训练函数大致相同,但是由于不进行梯度下降对网络权重进行更新,所以不需要传入优化器。
我们自己定义一个训练函数test函数,模型在测试集上的评估,包括计算测试集上的损失和准确率。
具体来说,test函数接受一个数据集迭代器、一个模型、一个损失函数作为输入,并返回模型在测试集上的平均损失和准确率。
函数的具体实现如下:
- 首先获取数据集大小和批次数量,并将模型设为评估模式;
- 然后遍历测试集迭代器,将每个batch的数据送入模型计算预测值;
- 用预测值和实际标签计算损失,并将损失值和准确率累加到test_loss和test_acc变量中;
- 最后除以批次数得到平均损失和准确率,并打印输出结果。
需要注意的是,由于在测试集上不需要反向传播计算梯度,因此需要使用torch.no_grad()上下文管理器来禁用梯度计算,从而提高计算效率。
def test(dataloader, model, loss_fn):size = len(dataloader.dataset)num_batches = len(dataloader)model.eval()test_loss, test_acc = 0, 0with torch.no_grad():for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model(X)test_loss += loss_fn(pred, y).item()test_acc += (pred.argmax(1) == y).type(torch.float).sum().item()test_loss /= num_batchestest_acc /= sizeprint(f"Test Error: \n Accuracy: {(100*test_acc):>0.1f}%, Avg loss: {test_loss:>8f} \n")return test_loss, test_acc
4、正式训练
epochs = 20
train_loss, train_acc = [], []
test_loss, test_acc = [], []
for t in range(epochs):model.train()epoch_train_acc, epoch_train_loss = train(train_loader, model, loss_fn, optimizer)train_loss.append(epoch_train_loss)train_acc.append(epoch_train_acc)model.eval()epoch_test_acc, epoch_test_loss = test(test_loader, model, loss_fn)test_loss.append(epoch_test_loss)test_acc.append(epoch_test_acc)print(f"Epoch {t+1}\n-------------------------------")train(train_loader, model, loss_fn, optimizer)test(test_loader, model, loss_fn)
print("Done!")
训练结果为:
loss: 1.199974 [ 0/ 1713]
Train Error: Accuracy: 83.9%, Avg loss: 0.503470 Test Error: Accuracy: 86.2%, Avg loss: 0.487529 Epoch 1
-------------------------------
loss: 0.062999 [ 0/ 1713]
Train Error: Accuracy: 81.9%, Avg loss: 0.463360 Test Error: Accuracy: 79.7%, Avg loss: 0.457709 loss: 0.708710 [ 0/ 1713]
Train Error: Accuracy: 85.9%, Avg loss: 0.406817 Test Error: Accuracy: 85.3%, Avg loss: 0.506047 Epoch 2
-------------------------------
loss: 0.270929 [ 0/ 1713]
Train Error: Accuracy: 87.2%, Avg loss: 0.338913 Test Error: Accuracy: 82.8%, Avg loss: 0.500975 loss: 0.657500 [ 0/ 1713]
Train Error: Accuracy: 87.1%, Avg loss: 0.405702 Test Error: Accuracy: 80.4%, Avg loss: 0.691268 Epoch 3
-------------------------------
loss: 0.149799 [ 0/ 1713]
Train Error: Accuracy: 87.9%, Avg loss: 0.310380 Test Error: Accuracy: 79.7%, Avg loss: 0.514998 loss: 0.230001 [ 0/ 1713]
Train Error: Accuracy: 85.9%, Avg loss: 0.478800 Test Error: Accuracy: 76.9%, Avg loss: 1.450183 Epoch 4
-------------------------------
loss: 0.731624 [ 0/ 1713]
Train Error: Accuracy: 84.7%, Avg loss: 0.388541 Test Error: Accuracy: 83.2%, Avg loss: 0.551030 loss: 0.425535 [ 0/ 1713]
Train Error: Accuracy: 87.9%, Avg loss: 0.339442 Test Error: Accuracy: 84.6%, Avg loss: 0.762711 Epoch 5
-------------------------------
loss: 0.261778 [ 0/ 1713]
Train Error: Accuracy: 91.4%, Avg loss: 0.251970 Test Error: Accuracy: 84.1%, Avg loss: 0.550993 loss: 0.120489 [ 0/ 1713]
Train Error: Accuracy: 92.3%, Avg loss: 0.267334 Test Error: Accuracy: 82.1%, Avg loss: 0.732856 Epoch 6
-------------------------------
loss: 0.545078 [ 0/ 1713]
Train Error: Accuracy: 93.5%, Avg loss: 0.190953 Test Error: Accuracy: 81.4%, Avg loss: 0.654517 loss: 0.242050 [ 0/ 1713]
Train Error: Accuracy: 93.9%, Avg loss: 0.166487 Test Error: Accuracy: 86.5%, Avg loss: 0.520211 Epoch 7
-------------------------------
loss: 0.032337 [ 0/ 1713]
Train Error: Accuracy: 94.4%, Avg loss: 0.139460 Test Error: Accuracy: 81.8%, Avg loss: 0.571910 loss: 0.111919 [ 0/ 1713]
Train Error: Accuracy: 95.3%, Avg loss: 0.133110 Test Error: Accuracy: 87.9%, Avg loss: 0.581790 Epoch 8
-------------------------------
loss: 0.011513 [ 0/ 1713]
Train Error: Accuracy: 93.2%, Avg loss: 0.168966 Test Error: Accuracy: 84.6%, Avg loss: 0.612067 loss: 0.138732 [ 0/ 1713]
Train Error: Accuracy: 95.9%, Avg loss: 0.131339 Test Error: Accuracy: 85.5%, Avg loss: 0.658192 Epoch 9
-------------------------------
loss: 0.098304 [ 0/ 1713]
Train Error: Accuracy: 97.5%, Avg loss: 0.073731 Test Error: Accuracy: 86.2%, Avg loss: 0.648000 loss: 0.041354 [ 0/ 1713]
Train Error: Accuracy: 98.2%, Avg loss: 0.054499 Test Error: Accuracy: 85.1%, Avg loss: 0.804457 Epoch 10
-------------------------------
loss: 0.111462 [ 0/ 1713]
Train Error: Accuracy: 97.4%, Avg loss: 0.069474 Test Error: Accuracy: 86.9%, Avg loss: 0.575027 loss: 0.039980 [ 0/ 1713]
Train Error: Accuracy: 97.8%, Avg loss: 0.069207 Test Error: Accuracy: 86.5%, Avg loss: 0.715076 Epoch 11
-------------------------------
loss: 0.030235 [ 0/ 1713]
Train Error: Accuracy: 97.5%, Avg loss: 0.078401 Test Error: Accuracy: 87.2%, Avg loss: 0.594295 loss: 0.055335 [ 0/ 1713]
Train Error: Accuracy: 97.5%, Avg loss: 0.059249 Test Error: Accuracy: 87.4%, Avg loss: 0.696577 Epoch 12
-------------------------------
loss: 0.040502 [ 0/ 1713]
Train Error: Accuracy: 96.5%, Avg loss: 0.100692 Test Error: Accuracy: 82.1%, Avg loss: 0.793313 loss: 0.044457 [ 0/ 1713]
Train Error: Accuracy: 95.9%, Avg loss: 0.108039 Test Error: Accuracy: 84.6%, Avg loss: 0.848924 Epoch 13
-------------------------------
loss: 0.022895 [ 0/ 1713]
Train Error: Accuracy: 98.2%, Avg loss: 0.055400 Test Error: Accuracy: 86.2%, Avg loss: 0.881824 loss: 0.058409 [ 0/ 1713]
Train Error: Accuracy: 97.5%, Avg loss: 0.066015 Test Error: Accuracy: 86.5%, Avg loss: 0.834848 Epoch 14
-------------------------------
loss: 0.037372 [ 0/ 1713]
Train Error: Accuracy: 99.2%, Avg loss: 0.029454 Test Error: Accuracy: 86.5%, Avg loss: 0.886635 loss: 0.126379 [ 0/ 1713]
Train Error: Accuracy: 98.9%, Avg loss: 0.036465 Test Error: Accuracy: 86.7%, Avg loss: 0.926361 Epoch 15
-------------------------------
loss: 0.022206 [ 0/ 1713]
Train Error: Accuracy: 96.1%, Avg loss: 0.134624 Test Error: Accuracy: 83.0%, Avg loss: 0.761580 loss: 0.109468 [ 0/ 1713]
Train Error: Accuracy: 95.0%, Avg loss: 0.145105 Test Error: Accuracy: 86.2%, Avg loss: 0.864981 Epoch 16
-------------------------------
loss: 0.116144 [ 0/ 1713]
Train Error: Accuracy: 97.8%, Avg loss: 0.056436 Test Error: Accuracy: 85.5%, Avg loss: 0.808745 loss: 0.148035 [ 0/ 1713]
Train Error: Accuracy: 98.2%, Avg loss: 0.056249 Test Error: Accuracy: 87.2%, Avg loss: 0.805620 Epoch 17
-------------------------------
loss: 0.107752 [ 0/ 1713]
Train Error: Accuracy: 98.9%, Avg loss: 0.028704 Test Error: Accuracy: 85.3%, Avg loss: 0.989487 loss: 0.005748 [ 0/ 1713]
Train Error: Accuracy: 99.2%, Avg loss: 0.027402 Test Error: Accuracy: 86.0%, Avg loss: 0.791777 Epoch 18
-------------------------------
loss: 0.005322 [ 0/ 1713]
Train Error: Accuracy: 99.5%, Avg loss: 0.015000 Test Error: Accuracy: 86.2%, Avg loss: 0.807837 loss: 0.003800 [ 0/ 1713]
Train Error: Accuracy: 99.4%, Avg loss: 0.020819 Test Error: Accuracy: 84.4%, Avg loss: 1.052223 Epoch 19
-------------------------------
loss: 0.001303 [ 0/ 1713]
Train Error: Accuracy: 99.4%, Avg loss: 0.015747 Test Error: Accuracy: 85.8%, Avg loss: 1.024608 loss: 0.007683 [ 0/ 1713]
Train Error: Accuracy: 98.5%, Avg loss: 0.067711 Test Error: Accuracy: 85.3%, Avg loss: 1.076210 Epoch 20
-------------------------------
loss: 0.001310 [ 0/ 1713]
Train Error: Accuracy: 94.2%, Avg loss: 0.196802 Test Error: Accuracy: 84.8%, Avg loss: 0.813763 Done!
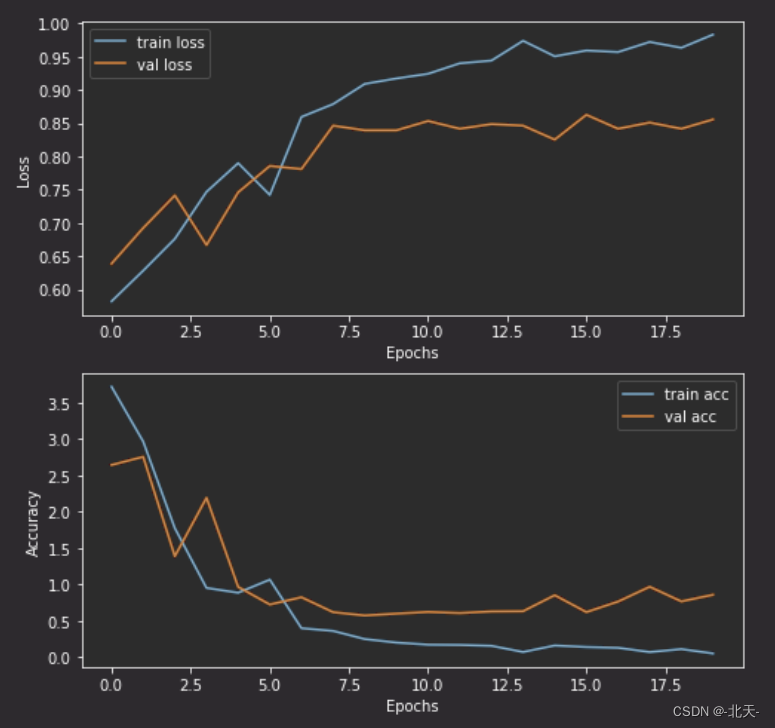
六、结果可视化
# 可视化上述训练结果
import matplotlib.pyplot as pltdef plot_curve(train_loss, val_loss, train_acc, val_acc):plt.figure(figsize=(8, 8))plt.subplot(2, 1, 1)plt.plot(train_loss, label='train loss')plt.plot(val_loss, label='val loss')plt.legend(loc='best')plt.xlabel('Epochs')plt.ylabel('Loss')plt.subplot(2, 1, 2)plt.plot(train_acc, label='train acc')plt.plot(val_acc, label='val acc')plt.legend(loc='best')plt.xlabel('Epochs')plt.ylabel('Accuracy')plt.show()
plot_curve(train_loss, test_loss, train_acc, test_acc)

七、图片预测
from PIL import Image
classes = list(total_data.class_to_idx)def predict_one_image(image_path, model, transform, classes):test_img = Image.open(image_path).convert('RGB')# plt.imshow(test_img) # 展示预测的图片test_img = transform(test_img)img = test_img.to(device).unsqueeze(0)model.eval()output = model(img)_,pred = torch.max(output,1)pred_class = classes[pred]print(f'预测结果是:{pred_class}')
predict_one_image('E:\\深度学习\\data\\Day13\\Monkeypox\\M01_01_00.jpg', model, train_transforms, classes)
预测结果是:Monkeypox
预测结果是正确的,但是准确率没有到88%。
八、保存模型
# 模型保存
torch.save(model.state_dict(), "model.pth")# 将参数加载到model当中
model.load_state_dict(torch.load(PATH, map_location=device))
print("Saved PyTorch Model State to model.pth")
Saved PyTorch Model State to model.pth
九、模型优化
我添加了一层Dropout层,但是最后训练的准确率并没有提升。
...
Epoch 20
-------------------------------
loss: 0.019593 [ 0/ 1713]
Train Error: Accuracy: 99.1%, Avg loss: 0.023408 Test Error: Accuracy: 84.6%, Avg loss: 0.888081
相关文章:
深度学习 Day26——使用Pytorch实现猴痘病识别
深度学习 Day26——使用Pytorch实现猴痘病识别 文章目录深度学习 Day26——使用Pytorch实现猴痘病识别一、前言二、我的环境三、前期工作1、设置GPU导入依赖项2、导入猴痘病数据集3、划分数据集四、构建CNN网络五、训练模型1、设置超参数2、编写训练函数3、编写测试函数4、正式…...

redis简单介绍
对于一名前端工程师,想要进阶成为全栈工程师,redis技术是我们一定需要掌握的。作为当前非关系型数据库Nosql中比较热门的key-value存储系统,了解redis的原理和开发是极其重要的。本文我会循序渐进的带领大家一步步认识redis,使用r…...

Understanding services:理解服务(Service)
文章目录背景1. 准备工作2. ros2 service list 命令3. ros2 service type 命令3.1 ros2 service list -t 命令4. ros2 service find 命令5. ros2 interface show 命令6. ros2 service call 命令参考官方文档: Understanding services背景 服务(Service&…...

【链表OJ题(五)】合并两个有序链表
📝个人主页:Sherry的成长之路 🏠学习社区:Sherry的成长之路(个人社区) 📖专栏链接:数据结构 🎯长路漫漫浩浩,万事皆有期待 文章目录链表OJ题(五)1. 合并…...
)
C++ Primer第五版_第三章习题答案(1~10)
文章目录练习3.1练习3.2一次读入一行一次读入一个词练习3.3练习3.4大的字符串长度大的字符串练习3.5未隔开的隔开的练习3.6练习3.7练习3.8练习3.9练习3.10练习3.1 使用恰当的using 声明重做 1.4.1节和2.6.2节的练习。 // 1.4.1 #include <iostream>using std::cin; using…...

小样本学习
机器学习就是从数据中学习,从而使完成任务的表现越来越好。小样本学习是具有有限监督数据的机器学习。类似的,其他的机器学习定义也都是在机器学习定义的基础上加上不同的限制条件衍生出来。例如,弱监督学习是强调在不完整、不准确、有噪声、…...
python打包成apk界面设计,python打包成安装文件
大家好,给大家分享一下如何将python程序打包成apk文件,很多人还不知道这一点。下面详细解释一下。现在让我们来看看! 1、如何用python制作十分秒加减的apk 如何用python制作十分秒加减的apk?用法:. apk包放入apk文件目录,然后输入…...

pytorch转onnx踩坑日记
在深度学习模型部署时,从pytorch转换onnx的过程中,踩了一些坑。本文总结了这些踩坑记录,希望可以帮助其他人。 首先,简单说明一下pytorch转onnx的意义。在pytorch训练出一个深度学习模型后,需要在TensorRT或者openvin…...

极智AI | GPT4来了,ChatGPT又该升级了
欢迎关注我,获取我的更多经验分享 大家好,我是极智视界,本文介绍一下 GPT4来了,ChatGPT又该升级了,更多的是个人思考。 邀您加入我的知识星球「极智视界」,星球内有超多好玩的项目实战源码下载,链接:https://t.zsxq.com/0aiNxERDq 从 ChatGPT 发布 (2022年11月30日) 到…...

智能优化算法之灰狼优化算法(GWO)的实现(Python附源码)
文章目录一、灰狼优化算法的实现思路1、社会等级结构分级2、包围猎物3、攻击猎物4、搜索猎物二、算法步骤三、实例一、灰狼优化算法的实现思路 灰狼优化算法(Grey Wolf Optimizer,简称GWO)是由Seyedali Mirjalili等人于2014年提出的一种群智…...

leetCode热题10-15 解题代码,思路
前言 计划做一系列算法题的文章,因为自己这块确实比较薄弱,但又很重要!写这篇文章前,我已经刷了一本剑指offer,leetcode top150道,牛客某题库106道 这个样子吧,感觉题量算是入门了吧࿱…...

同步辐射GISAXS和GIWAXS的原理及应用领域
同步辐射GISAXS和GIWAXS是两种常用的同步辐射X射线衍射技术,它们在材料科学、化学、生物学、物理学等领域中广泛应用。本文将从原理、实验方法和应用三个方面,对同步辐射GISAXS和GIWAXS进行描述和比较。 一、原理 GISAXS和GIWAXS都是利用X射线与样品相互…...

OpManager 进行网络性能管理
计算机网络构成了任何组织的 IT 基础架构的支柱。由于企业严重依赖基于互联网的应用程序,由于网络相关问题,最终用户不受影响非常重要。因此,借助网络管理解决方案监控和提高网络性能对于保持企业始终正常运行至关重要。这将确保维护服务级别…...

面试被问到向上转型和向下转型时,怎么回答?
目录 前置小知识 1、向上转型 补充:向上转型的三种情况 2、向下转型 使用关键字:instanceof 3、转型带来了什么好处 前置小知识 java中的继承,我们简单回顾一下 通过java中的继承机制,可以实现一个类继承另一个类ÿ…...

加密月解密:概述,基础篇
加密月解密:概述,基础篇 2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开 测开的话,你就得学数据库,sql,oracle&…...
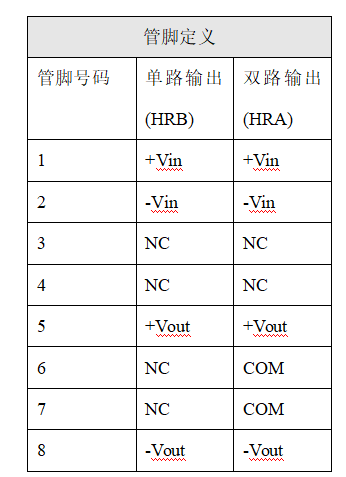
DC-DC升压模块隔离高压稳压电源直流变换器12v24v48v转600V1000V1100V1500V2000V3000V
特点● 效率高达 80%● 2*2英寸标准封装● 单双电压输出● 价格低● 大于600V高压,稳压输出● 工作温度: -40℃~85℃● 阻燃封装,满足UL94-V0 要求● 温度特性好● 可直接焊在PCB 上应用HRB W1~25W 系列模块电源是一种DC-DC升压变换器。该模块电源的输入电压分为&am…...
pandas数据分析(三)
书接pandas数据分析(二) 文章目录DataFrame数据处理与分析处理超市交易数据中的异常值处理超市交易数据中的缺失值处理超市交易数据中的重复值使用数据差分查看员工业绩波动情况使用透视表与交叉表查看业绩汇总数据使用重采样技术按时间段查看员工业绩Da…...

cpu performance profiling
精彩文章分享1. android performanceAndroid 性能分析工具介绍 (qq.com)手机Android存储性能优化架构分析 (qq.com)抖音 Android 性能优化系列:启动优化之理论和工具篇 (qq.com)那些年,我们一起经历过的 Android 系统性能优化 (qq.com)Android卡顿&#…...

vue2启动项目npm run dev报错 Error: Cannot find module ‘babel-preset-es2015‘ 修改以及问题原因
报错内容如下图: 说找不到模块 babel-preset-es2015。 在报错之前,我正在修改代码,使用 ElementUI 的按需引入方式,修改了 babel.config.js 。 注意:vue/cli 脚手架4版本已经使用了 babel7 ,所以项目中…...
*9 set up 注意点
1、set up 执行的时机:beforeCreate 之前执行一次,this 是 undefined 2、set up 的参数: props:值为对象,组件外传递属性,内部声明并且接收属性 context:上下文对象,其内部包含三个…...

电脑插入多块移动硬盘后经常出现卡顿和蓝屏
当电脑在插入多块移动硬盘后频繁出现卡顿和蓝屏问题时,可能涉及硬件资源冲突、驱动兼容性、供电不足或系统设置等多方面原因。以下是逐步排查和解决方案: 1. 检查电源供电问题 问题原因:多块移动硬盘同时运行可能导致USB接口供电不足&#x…...

《基于Apache Flink的流处理》笔记
思维导图 1-3 章 4-7章 8-11 章 参考资料 源码: https://github.com/streaming-with-flink 博客 https://flink.apache.org/bloghttps://www.ververica.com/blog 聚会及会议 https://flink-forward.orghttps://www.meetup.com/topics/apache-flink https://n…...

AspectJ 在 Android 中的完整使用指南
一、环境配置(Gradle 7.0 适配) 1. 项目级 build.gradle // 注意:沪江插件已停更,推荐官方兼容方案 buildscript {dependencies {classpath org.aspectj:aspectjtools:1.9.9.1 // AspectJ 工具} } 2. 模块级 build.gradle plu…...
关于easyexcel动态下拉选问题处理
前些日子突然碰到一个问题,说是客户的导入文件模版想支持部分导入内容的下拉选,于是我就找了easyexcel官网寻找解决方案,并没有找到合适的方案,没办法只能自己动手并分享出来,针对Java生成Excel下拉菜单时因选项过多导…...

Qt 事件处理中 return 的深入解析
Qt 事件处理中 return 的深入解析 在 Qt 事件处理中,return 语句的使用是另一个关键概念,它与 event->accept()/event->ignore() 密切相关但作用不同。让我们详细分析一下它们之间的关系和工作原理。 核心区别:不同层级的事件处理 方…...
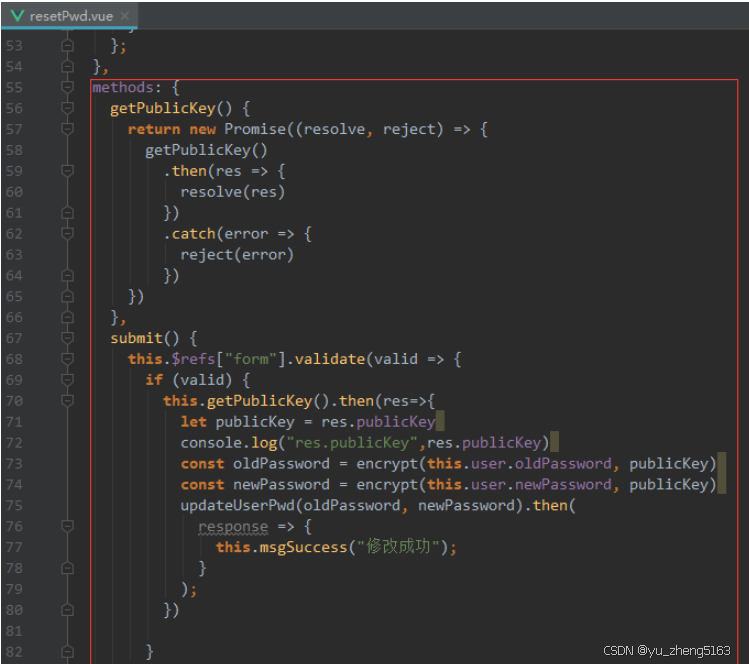
若依登录用户名和密码加密
/*** 获取公钥:前端用来密码加密* return*/GetMapping("/getPublicKey")public RSAUtil.RSAKeyPair getPublicKey() {return RSAUtil.rsaKeyPair();}新建RSAUti.Java package com.ruoyi.common.utils;import org.apache.commons.codec.binary.Base64; im…...

用 Rust 重写 Linux 内核模块实战:迈向安全内核的新篇章
用 Rust 重写 Linux 内核模块实战:迈向安全内核的新篇章 摘要: 操作系统内核的安全性、稳定性至关重要。传统 Linux 内核模块开发长期依赖于 C 语言,受限于 C 语言本身的内存安全和并发安全问题,开发复杂模块极易引入难以…...

数据分析六部曲?
引言 上一章我们说到了数据分析六部曲,何谓六部曲呢? 其实啊,数据分析没那么难,只要掌握了下面这六个步骤,也就是数据分析六部曲,就算你是个啥都不懂的小白,也能慢慢上手做数据分析啦。 第一…...

【java】【服务器】线程上下文丢失 是指什么
目录 ■前言 ■正文开始 线程上下文的核心组成部分 为什么会出现上下文丢失? 直观示例说明 为什么上下文如此重要? 解决上下文丢失的关键 总结 ■如果我想在servlet中使用线程,代码应该如何实现 推荐方案:使用 ManagedE…...

手动给中文分词和 直接用神经网络RNN做有什么区别
手动分词和基于神经网络(如 RNN)的自动分词在原理、实现方式和效果上有显著差异,以下是核心对比: 1. 实现原理对比 对比维度手动分词(规则 / 词典驱动)神经网络 RNN 分词(数据驱动)…...