C++复习的长文指南
C++复习的长文指南
- 一、入门语法知识
- 1.预备
- 1.1 main函数
- 1.2 注释
- 1.3 变量
- 1.3 常量
- 1.4 关键字
- 1.5 标识符明明规则
- 2. 数据类型
- 2.1 整型
- 2.1.1 sizeof关键字
- 2.2 实型(浮点型)
- 2.3 字符型
- 2.4 转义字符
- 2.5 字符串型
- 2.6 布尔类型bool
- 2.7 数据的输入
- 3. 运算符
- 3.1 算数运算符
- 3.2 赋值运算符
- 3.3 比较运算符
- 3.4 逻辑运算符
- 4. 程序流程结构
- 4.1 选择结构
- 4.1.1 if语句
- 4.1.2 三目运算符
- 4.1.3 switch语句
- 4.2 循环结构
- 4.2.1 while语句
- 4.2.2 do while语句
- 4.2.3 for循环语句
- 4.2.4 嵌套循环
- 4.3 跳转结构
- 4.3.1 break语句
- 4.3.2 continue语句
- 4.3.3 go to语句
- 5. 数组
- 5.1 概述
- 5.2 一维数组
- 5.2.1 一维数组定义方式
- 5.2.2 一维数组数组名
- 5.2.3 冒泡排序
- 5.3 二维数组
- 5.3.1 二维数组定义方式
- 5.3.2 二维数组数组名
- 6. 函数
- 6.1 概述
- 6.2 函数的定义
- 6.3 函数的调用
- 6.4 值传递
- 6.5 函数的常见样式
- 6.6 函数的申明
- 6.7 函数的分文件编写
- 7. 指针
- 7.1 指针的基本概念
- 7.2 指针变量的定义和使用
- 7.3 指针所占内存空间
- 7.4 空指针和野指针
- 7.4.1 空指针
- 7.4.2 野指针
- 7.5 const修饰指针
- 7.5.1 常量指针
- 7.5.2 指针常量
- 7.5.3 既修饰指针,又修饰常量
- 7.6 指针和数组
- 7.7 指针和函数
- 7.8 指针、数组、函数的综合案例
- 8.结构体
- 8.1 结构体的基本概念
- 8.2 结构体定义和使用
- 8.3 结构体数组
- 8.4 结构体指针
- 8.5 结构体嵌套结构体
- 8.6 结构体做函数参数
- 8.7 结构体中的const使用场景
- 二、C++核心编程
- 1.内存分区模型
- 1.1 程序运行前
- 1.2 程序运行后
- 1.3 new操作符
- 2. 引用
- 2.1 引用的基本使用
- 2.2 引用的注意事项
- 2.3 引用做函数参数
- 2.4 引用做函数返回值
- 2.5 引用的本质
- 2.6 常量引用
- 3. 函数提高
- 3.1 函数默认参数
- 3.2 函数占位参数
- 3.3 函数重载
- 3.3.1 函数重载概述
- 3.3.2 函数重载的注意事项
- 4. 面向对象
- 4.1 封装
- 4.1.1 封装的意义
- 4.1.2 struct和class区别
- 4.1.3 成员属性设置为私有
- 4.1.4 类的分文件编写
一、入门语法知识
1.预备
1.1 main函数
任何c++程序都有的 main。
#include<iostream>
using namespace std;
int main() {cout << "hello world" << endl;system("pause");return 0;
}
1.2 注释
// 单行注释
//cout << "hello world" << endl;
// 多行注释
/*cout << "hello world" << endl;cout << "hello world" << endl;
*/
1.3 变量
变量的作用:给内存起个名字,方便操作这块内存。
数据类型 变量名称 = 变量初始值;
int a = 10;
1.3 常量
常量的作用:用于记录程序中不可更改的数据。
// 1.第一种#define 宏常量
#define Day 7
// 2.第二种const 修饰一个变量
const int a = 10;
1.4 关键字
关键字的作用:c++中预先保留的单词(标识符),定义变量、常量名时不能再使用。
比如:int、double、bool、long、sizeof…
1.5 标识符明明规则
1、 标识符不能为关键字;
2、 标识符只能是字母、数字、下划线;
3、 第1个标识符必须只能字母或下划线;
4、标识符字母区分大小写。
建议:尽量做到“见名知意”。
int num1 = 10;
int num2 = 20;
int sum = num1 + num2;
cout << "和为:" << sum << endl;
2. 数据类型
2.1 整型
C++规定在创建一个变量或者常量时,必须要指定出相应的数据类型,否则无法给变量分配合适的内存。
比如,int a = 10;在内存中找一个空间存放数据10,并且给这块内存空间命名为a,想要操纵管理这个空间,用a就行。
那数据类型存在的意义?
存放一个数据10,可以用小内存,或者更大的内存空间存放,而加上数据类型,就不会造成下图的内存空间浪费。

除了int,还有别的常用的整型,区别在于占用的内存空间不同。

2.1.1 sizeof关键字
作用:利用sizeof关键字可以统计数据类型所占内存大小。
#include<iostream>
using namespace std;
int main(){cout << "short 类型所占内存空间:" << sizeof(short) << endl;cout << "int 类型所占内存空间:" << sizeof(int) << endl;cout << "long 类型所占内存空间:" << sizeof(long) << endl;cout << "long long 类型所占内存空间:" << sizeof(long long) << endl;system("pause");return 0;
}
整型结论:short<int<= long<= long long(区分操作系统)
2.2 实型(浮点型)
作用:用于表示小数
浮点型变量分为:
1.单精度float;
2.双精度double。
float f1 = 3.14f;
double d1 = 3.14;
// 4
cout << "float所占内存空间" << sizeof(float) << endl;
// 8
cout << "double所占内存空间" << sizeof(double) << endl;
// 科学计数法
float f2 = 3e2; // 3 * 10 ~ 2
float f3 = 3e-2; // 3 * 0.1 ~ 2

2.3 字符型
语法 :char ch = ‘a’;
注意1:在显示字符型变量时,用单引号将字符括起来,不要用双引号;
注意2:单引号内只能有一个字符,不可以是字符串。
结论:
1.c和c++中字符型只占1个字节的内存空间;
2.字符型变量并不是把字符本身放到内存中存储,而是将对应的ASCIl编码放入
到存储单元。
2.4 转义字符
作用:用于显示一些不能显示出来的ASCII字符。

2.5 字符串型
作用:用于表示一串字符
两种风格:
1.C风格字符串:char 变量名[] = “字符串值”
char str1[] = "hello world";
2.C++风格字符串:string 变量名 = “字符串值”
#include<string> // 使用c++风格时,需要包含这个头文件。string str1 = "hello world";
2.6 布尔类型bool
作用:用于表示真或假
布尔类型bool只占1个字节的内存空间;
bool flag = true;
cout << flag << endl; // 输出为1
2.7 数据的输入
作用:用于从键盘获取数据
关键字:cin
语法:cin >> 变量
int a = 0;
cout << "请输入数据:" << endl;
cin >> a;
cout << "输入数据为:" << a << endl;
3. 运算符
作用:用于执行代码的运算
3.1 算数运算符
作用:用于处理四则运算
结论:
1.两数相除(取模),除数不可以为0;
2.只有整型变量之间可以做取余运算;
3.++a,前置递增先让变量+1,然后进行表达式运算
4.a++,后置递增先进行表达式运算,后让变量+1

int a1 = 10;
int a2 = 3;
cout << a1 / a2 << endl; // 输出结果为3,取决于a1和a2的数据类型
float b1 = 0.55;
float b2 = 0.22;
cout << b1 / b2 << endl; // 输出结果为小数,取决于b1和b2的数据类型int a1 = 10;
3.2 赋值运算符
作用:用于将表达式的值赋值给变量

3.3 比较运算符
作用:用于表达式的比较,返回一个真值或假值

3.4 逻辑运算符
作用:用于根据表达式的值返回真值或假值

4. 程序流程结构
作用:用于执行代码的运算
C/C++支持最基本的三种程序运行结构:
顺序结构、选择结构、循环结构
1.顺序结构:程序按顺序执行,不发生跳转;
2.选择结构:依据条件是否满足,有选择的执行相应功能;
3.循环结构:依据条件是否满足,循环多次执行某段代码;
4.1 选择结构
4.1.1 if语句
作用:执行满足条件的语句
if语句的三种形式:
1.单行格式if语句

int score = 70;
if (score > 60) //注意事项,if条件后面不要加分号
{cout << "分数及格" << endl;
}
2.多行格式if语句

int score = 70;
if (score > 60) //注意事项,if条件后面不要加分号
{cout << "分数及格" << endl;
}
else
{cout << "分数不及格" << endl;
}
3.多条件的if语句

int score = 70;
if (score > 90) //注意事项,if条件后面不要加分号
{cout << "分数优秀" << endl;
}
else if (score > 80)
{cout << "分数良好" << endl;
}
else
{cout << "分数及格" << endl;
}
4.多嵌套if语句
在if语句中,可以嵌套使用if语句,达到更精确的条件判断
int score = 70;
if (score > 90) //注意事项,if条件后面不要加分号
{cout << "分数优秀" << endl;// 嵌套if语句if (score > 95){cout << "分数特别优秀" << endl;}
}
else if (score > 80)
{cout << "分数良好" << endl;
}
else
{cout << "分数及格" << endl;
}
4.1.2 三目运算符
作用:通过三目运算符实现简单的判断
语法:表达式1 ? 表达式2 : 表达式3
解释:
如果表达式1的值为真,执行表达式2,并返回表达式2的结果;
如果表达式1的值为假,执行表达式3,并返回表达式3的结果。
int a = 10;
int b = 20;
int c = 0;
c = (a > b ? a : b);
cout << c << endl;
// 在C++中三目运算符返回的是变量,可以继续赋值
(a > b ? a : b) = 30;
4.1.3 switch语句
作用:执行多条件分支语句
语法:
switch (表达式){case 结果1: 执行语句; break;case 结果2: 执行语句; break;......default: 执行语句; break;}
示例:
int score = 90;
switch (score)
{
case 90:cout << "成绩优秀" << endl;break; // 退出当前分支
case 80:cout << "成绩良好" << endl;break; // 退出当前分支
case 70:cout << "成绩及格" << endl;break; // 退出当前分支
default:cout << "成绩不及格" << endl;break;}
if和 switch 区别?
switch缺点:判断时候只能是整型或者字符型,不可以是一个区间
switch优点:结构清晰,执行效率高
4.2 循环结构
4.2.1 while语句
作用:满足循环条件,执行循环语句
语法:while(循环条件){循环语句}
解释:只要循环条件的结果为真,就执行循环语句

int num = 0;
while (num < 10)
{cout << num << endl;num++;
}
注意事项:在写循环一定要避免死循环的出现
4.2.2 do while语句
作用:满足循环条件,执行循环语句;
语法:do{循环语句 } while(循环条件);
注意:与while的区别在于do…while会先执行一次循环语句,再判断循环条件

int num = 0;
do
{cout << num << endl;num++;
} while (num < 10);
4.2.3 for循环语句
作用:满足循环条件,执行循环语句;
语法:for(起始表达式;条件表达式;末尾循环体){循环语句;};
for (int i = 0; i < 10; i++){cout << i << endl;}
4.2.4 嵌套循环
作用:在循环体中再嵌套—层循环,解决—些实际问题
// 外层循环执行一次
for (int i = 0; i < 10; i++)
{// 内层循环执行一周for (int j = 0; j < 10; j++){cout << "* ";}cout << endl;
}
4.3 跳转结构
4.3.1 break语句
作用:用于跳出选择结构或者循环结构
break使用的时机:
1.出现在switch条件语句中,作用是终止case并跳出switch
2.出现在循环语句中,作用是跳出当前的循环语句
3.出现在嵌套循环中,跳出最近的内层循环语句
4.3.2 continue语句
作用:在循环语句中,跳过本次循环中余下尚未执行的语句,继续执行下一次循环
4.3.3 go to语句
作用:可以无条件跳转语句;
语法:goto标记;
解释:如果标记的名称存在,执行到goto语句时,会跳转到标记的位置
cout << "1" << endl;
cout << "2" << endl;
goto FLAG;
cout << "3" << endl;
cout << "4" << endl;
FLAG:
cout << "5" << endl;
注意:在程序中不建议使用goto语句,以免造成程序流程混乱
5. 数组
5.1 概述
所谓数组,就是—个集合,里面存放了“相同类型”的数据元素
特点1:数组中的每个数据元素都是相同的数据类型
特点2:数组是由连续的内存位置组成的
好比,一个盒子放着同样的电池。

5.2 一维数组
5.2.1 一维数组定义方式
—维数组定义的三种方式:
1.数据类型 数组名[数组长度];
2.数据类型 数组名[数组长度] = { 值1,值2 …];
3.数据类型 数组名[ ] ={ 值1,值2 …};
数组特点:
1.放在一块连续的内存空间中
2.数组中每个元素都是相同数据类型
// 定义方式1
int score[10];
// 定义方式2
// 如果{}内不足10个数据,剩余数据用0补全
int score[10] = {10, 20, 30, 40};
// 定义方式3
// 如果{}有了初始长度,[]内也可以不用显式化数组长度
int score[] = { 10, 20, 30, 40 };
总结1:数组名的命名规范与变量名命名规范—致,不要和变量重名;
总结2:数组中下标是从0开始索引。
5.2.2 一维数组数组名
一维数组名称的用途:
1.可以统计整个数组在内存中的长度;
2.可以获取数组在内存中的首地址。

// 1.可以通过数组名统计整个数组占用内存大小
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
cout << "整个数组占用的内存空间为:" << sizeof(arr) << endl;
cout << "每个元素占用的内存空间为:" << sizeof(arr[0]) << endl;
cout << "数组中元素的个数为:" << sizeof(arr) / sizeof(arr[0]) << endl;
// 2.可以通过数组名查看数组首地址,加(int)将16进制地址强转成10进制数
cout << "数组首地址为:" << (int)arr<< endl;
cout << "数组中第一个元素的地址为:" << (int)&(arr[0])<< endl;
// 数组中存放的是整型,每个整型占用4个字节,所以每个元素地址差4
cout << "数组中第二个元素的地址为:" << (int)&(arr[1])<< endl;
// 数组名是常量,它已经指向了首地址,不可以进行赋值操作
// arr = 100;
示例,实现一个一维数组的逆置
// 1.创建数组
int arr[5] = { 1,3,2,5,4 };
cout << "数组逆置前:" << endl;
for (int i = 0; i < 5; i++)
{cout << arr[i] << endl;
}
// 2、实现逆置
// 2.1记录起始下标位置
int start = 0;
// 2.2记录结束下标位置
int end = sizeof(arr) / sizeof(arr[0]) - 1;
// 2.3起始下标与结束下标的元素互换
// 2.4起始位置++ 结束位置--
// 2.5循环执行2.1操作,直到起始位置>=结束位置
while (start < end)
{int temp = arr[start];arr[start] = arr[end];arr[end] = temp;start++;end--;}
cout << "数组逆置后:" << endl;
for (int i = 0; i < 5; i++)
{cout << arr[i] << endl;
}
5.2.3 冒泡排序
作用:最常用的排序算法,对数组内元素进行排序
1.比较相邻的元素。如果第一个比第二个大,就交换他们两个。
2.对每一对相邻元素做同样的工作,执行完毕后,找到第一个最大值。
3.重复以上的步骤,每次比较次数-1,直到不需要比较
首先看比几轮,每1轮比几次,比如第1轮, 就比8次;
其实第1轮的作用就是,两两比较,直到选到最大的数放在最后位置;
第2轮时候,因为第1轮已经找到最大数,所以比较次数-1,其作用就是第2大的数放在倒数第2位置。

int arr[9] = { 4,2,8,0,5,7,1,3,9 };
int arr_num = sizeof(arr) / sizeof(arr[0]);
for (int i = 0; i < arr_num - 1; i++)
{for (int j = 0; j < arr_num - i - 1; j++){if (arr[j] > arr[j + 1]){int temp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = temp;}}
}
cout << "排序后的结果:" << endl;
for (int i = 0; i < arr_num; i++)
{cout << arr[i] << endl;
}
5.3 二维数组
二维数组就是在一维数组上,多加一个维度。通常以矩阵的形式进行体现。

5.3.1 二维数组定义方式
二维数组定义的四种方式:
1.数据类型 数组名[行数] [列数];
2.数据类型 数组名[行数] [列数] = { (值1,值2), (值3,值4) …];
3.数据类型 数组名[行数] [列数] ={ 值1,值2, 值3,值4…};
4.数据类型 数组名[ ] [列数] ={ 值1,值2, 值3,值4…};
建议:以上4种定义方式,利用第二种更加直观,提高代码的可读性
// 1.数据类型 数组名[行数] [列数];
int arr1[2][3];
// 2.数据类型 数组名[行数] [列数] = { (值1,值2), (值3,值4) ...];
int arr2[2][3] =
{{1,2,3},{4,5,6}
};
// 3.数据类型 数组名[行数] [列数] ={ 值1,值2,值3,值4...};
int arr3[2][3] = { 1,2,3,4,5,6 };
// 4.数据类型 数组名[ ] [列数] ={ 值1,值2,值3,值4...};
int arr4[][3] = { 1,2,3,4,5,6 };
总结:在定义二维数组时,如果初始化了数据,可以省略行数
5.3.2 二维数组数组名
作用:
1.查看二维数组所占内存空间
2.获取二维数组首地址
int arr[2][3] ={{1,2,3},{4,5,6}};
// 1.查看二维数组所占内存空间
cout << "二维数组所占内存空间为:" << sizeof(arr) << endl;
cout << "二维数组第一行所占内存空间为:" << sizeof(arr[0]) << endl;
cout << "二维数组第1个元素所占内存空间为:" << sizeof(arr[0][0]) << endl;
cout << "二维数组行数为:" << sizeof(arr) / sizeof(arr[0]) << endl;
cout << "二维数组列数为:" << sizeof(arr[0]) / sizeof(arr[0][0]) << endl;
// 2.获取二维数组首地址
cout << "二维数组首地址为:" << (int)arr << endl;
cout << "二维数组第1行首地址为:" << (int)arr[0] << endl;
// 第1行和第2行首地址差了12, 3x4
cout << "二维数组第2行首地址为:" << (int)arr[1] << endl;
// 第1个和第2个元素首地址差了4
cout << "二维数组第1个元素首地址为:" << (int)&arr[0][0] << endl;
cout << "二维数组第2个元素首地址为:" << (int)&arr[0][1] << endl;
6. 函数
6.1 概述
作用:将一段经常使用的代码封装起来,减少重复代码
一个较大的程序,一般分为若干个程序块,每个模块实现特定的功能。
6.2 函数的定义
函数的定义一般主要有5个步骤:
1、返回值类型
2、函数名
3、参数表列
4、函数体语句
5、return表达式
// 函数定义的时候,num1和num2并没有真实数据,他只是一个形式上的参数,简称形参
int add(int num1, int num2)
{int sum = num1 + num2;return sum;
}
6.3 函数的调用
功能:使用定义好的函数
语法:函数名(参数)
int a = 10;
int b = 10;
// a和b称为实际参数,简称实参
// 当调用函数时候,实参的值会传递给形参
int sum = add(a, b);
6.4 值传递
1.所谓值传递,就是函数调用时实参将数值传入给形参
2.值传递时,如果形参发生,并不会影响实参

6.5 函数的常见样式
1.无参无返
2.有参无返
3.无参有返
4.有参有返
6.6 函数的申明
作用:告诉编译器函数名称及如何调用函数。函数的实际主体可以单独定义。
注意:函数的声明可以多次,但是函数的定义只能有—次。
#include<iostream>
using namespace std;
// 提前告诉编译器函数的存在,可以利用函数的声明
int max(int a, int b);
// 声明可以多次,但是函数的定义只能有—次。
int max(int a, int b);
int main()
{system("pause");return 0;
}
int max(int a, int b)
{return a > b ? a : b;
}
6.7 函数的分文件编写
作用:让代码结构更加清晰
函数分文件编写一般有4个步骤:
1.创建后缀名为.h的头文件

2.创建后缀名为.cpp的源文件

3.在头文件中写函数的声明
#include<iostream>
using namespace std;
void swap(int a, int b);
4.在源文件中写函数的定义
#include"swap.h"
void swap(int a, int b)
{int temp = a;a = b;b = temp;cout << "a=" << a << endl;cout << "b=" << b << endl;
}
主函数中进行调用
#include<iostream>
using namespace std;
#include"swap.h"
int main()
{int a = 10;int b = 20;swap(a, b);system("pause");return 0;
}7. 指针
7.1 指针的基本概念
作用:可以通过指针间接访问内存
1.内存编号是从0开始记录的,一般用“十六进制数字”麦示
2.可以利用指针变量保存地址
7.2 指针变量的定义和使用
指针变量定义语法:数据类型 * 变量名

// 1、定义指针,语法: 数据类型 * 变量名;
int a = 10;
int* p;
// 让指针记录变量a的地址
p = &a;
cout << "a的地址为:" << &a << endl;
cout << "指针p为:" << p << endl;
// 2、使用指针
// 可以通过解引用的方式来找到指针指向的内存
// 指针前加 *
*p = 1000;
cout << "a=" << a << endl;
cout << "*p=" << *p << endl;
7.3 指针所占内存空间
提问:指针也是种数据类型,那么这种数据类型占用多少内存空间?

// 1、定义指针,语法: 数据类型 * 变量名;
int a = 10;
int* p = &a; // 让指针记录变量a的地址// 在32位操作系统下,指针是占4个字节空间大小,不管是什么数据类型
// 在64位操作系统下,指针是占8个字节空间大小,不管是什么数据类型
cout << "int*所占内存空间为:" << sizeof(int*) << endl;
cout << "int*所占内存空间为:" << sizeof(p) << endl;
cout << "float*所占内存空间为:" << sizeof(float*) << endl;cout << "double*所占内存空间为:" << sizeof(double*) << endl;cout << "char* 所占内存空间为:" << sizeof(char*) << endl;
7.4 空指针和野指针
7.4.1 空指针
空指针:指针变量指向内存中编号为0的空间

用途:初始化指针变量
注意:空指针指向的内存是不可以访问的
//空指针
// 1.初始化指针变量
int* p = NULL;
// 2.空指针指向的内存是不可以访问的
// 0-255之间的内存编号是系统占用的,因此不可以访问
//*p = 100;
7.4.2 野指针
野指针:指针变量指向非法的内存空间
// 野指针
// 1.初始化指针变量
// 0x1100这个内存空间并不我们是申请的,没有权利操纵这块内存
// 在程序中,尽量避免出现野指针
int* p = (int*)0x1100;
cout << *p << endl;
总结:空指针和野指针都不是我们申请的空间,因此不要访问。
7.5 const修饰指针
const修饰指针有三种情况;
7.5.1 常量指针
const修饰指针—常量指针
记忆技巧:const修饰的是int *,所以 * 的操纵就不能了。
// 1.const修饰指针 常量指针
int a = 10;
int b = 10;
const int* p = &a;
// 指针指向的值不可以改,指针的指向可以改
// *p = 20;
p = &b;

7.5.2 指针常量
const修饰常量—指针常量
记忆技巧:const修饰的是指针p,所以指针p就不能操纵了。
// 2.const修饰常量 指针常量
int* const p2 = &a;
// 指针指向不可以改,指针指向的值可以改
*p2 = 2;
// p2 = &b;

7.5.3 既修饰指针,又修饰常量
cons既修饰指针,又修饰常量
// 3.const既修饰指针,又修饰常量
const int* const p3 = &a;
// *p3 = 20;
// p3 = &b;

总结:看const右侧紧跟着的是指针还是常量,是指针就是常量指针,是常量就是指针常量。
7.6 指针和数组
作用:利用指针访问数组中元素。

// 指针和数组
// 利用指针访问数组中的元素
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
cout << "数组种第一个元素为:" << arr[0] << endl; //普通下标访问
int* p = arr; // 数组名就是数组的首地址
// 当使用指针指向数组首地址时,也可以通过p[0]这样下标的形式进行元素的访问。
cout << "利用指针访问的第一个元素为:" <<* p << endl;
p++; //将指针向后偏移4个字节
cout << "利用指针访问的第二个元素为:" << *p << endl;// 利用循环
int* p2 = arr;
for (int i = 0; i < 10; i++)
{cout << *p2 << endl;p2++;
}
7.7 指针和函数
作用:利用指针作函数参数,可以修改实参的值。

// 指针和函数
int a = 10;
int b = 20;
// 1.值传递
// 值传递不会改变实参
swap(a, b);
cout << "a=" << a << endl;
cout << "b=" << b << endl;
// 2.地址传递
// 如果是地址传递,可以修饰实参
swap02(&a, &b);
cout << "a=" << a << endl;
cout << "b=" << b << endl;
总结:如果不想修改实参,就用值传递,如果想修改实参,就用地址传递
7.8 指针、数组、函数的综合案例
案例:封装一个函数,利用冒泡排序,实现对整型数组的升序排
#include<iostream>
using namespace std;// 冒泡排序函数 参数1:数组的首地址 参数2:数组长度
void bubbleSort(int* arr, int len)
{for (int i = 0; i < len - 1; i++){for (int j = 0; j < len - i -1; j++){// 如果j > j+1 的值,就进行交换// 当使用指针指向数组首地址时,也可以通过p[0]这样下标的形式进行元素的访问。if (arr[j] > arr[j+1]){int temp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = temp;}}}
}
int main()
{// 1.创建数组int arr[10] = { 4,3,6,9,1,2,10,8,7,5 };// 数组长度int len = sizeof(arr) / sizeof(arr[0]);// 2.创建函数,实现冒泡排序bubbleSort(arr, len); //一般,我们函数传数组,会连着数组的长度一起传// 3.打印结果for (int i = 0; i < len; i++){cout << arr[i] << endl;}system("pause");return 0;
}
8.结构体
8.1 结构体的基本概念
结构体属于用户自定义的数据类型,允许用户存储不同的数据类型
8.2 结构体定义和使用
语法:struct结构体名{结构体成员列表};
通过结构体创建变量的方式有三种:
1.struct 结构体名 变量名
2.struct 结构体名 变量名 = {成员1值,成员2值…}
3.定义结构体时顺便创建变量
#include<iostream>
using namespace std;
#include<string>
// 1.创建学生数据类型(3个属性)
// 自定义数据类型,其实就是一些内置数据类型的集合
struct Student
{// 成员列表string name; //姓名int age; //年龄int score; //分数
}s3; //顺便创建结构体变量s3int main()
{// 2.通过学生数据类型创建具体学生// 2.1 struct Student s1;// Student s1; struct关键字可以省略// 给属性进行赋值s1.name = "张三";s1.age = 18;s1.score = 100;// 2.2 struct Student s2 = { ...}struct Student s2 = { "李四", 19, 80 };// 2.3 在定义结构体时顺便创建结构体变量s3.name = "王五";s3.age = 20;s3.score = 60;system("pause");return 0;
}
总结1:定义结构体时的关键字是struct,不可省略
总结2:创建结构体变量时,关键字struct可以省略
总结3:结构体变量利用操作符"."访问成员
8.3 结构体数组
作用:将自定义的结构体放入到数组中方便维护
语法:struct 结构体名 数组名[元素个数] = { {} , {}, … {}}
#include<iostream>
using namespace std;
#include<string>// 结构体数组
// 1.定义结构体数组
struct Student
{string name; // 姓名int age; // 年龄int score; // 分数
};
int main()
{// 2.创建结构体数组并赋值struct Student stuArray[3] ={{"张三", 18, 100},{"李四", 28, 99},{"王五", 38, 95},};// 3.修改结构体数组中的值stuArray[2].name = "哈哈";// 4.遍历结构体数组for (int i = 0; i < 3; i++){cout << "姓名:" << stuArray[i].name << endl;cout << "年龄:" << stuArray[i].age << endl;cout << "分数:" << stuArray[i].score << endl;}system("pause");return 0;
}
8.4 结构体指针
作用:通过指针访问结构体中的成员
利用操作符->可以通过结构体指针访问结构体属性
#include<iostream>
using namespace std;
#include<string>
// 结构体指针
// 定义学术结构体
struct student
{string name; // 姓名int age; // 年龄int score; // 分数
};
int main()
{// 创建学生结构体变量struct student s = { "张三",18, 100 };// 通过指针指向结构体变量struct student* p = &s;// 通过指针访问结构体变量中的数据cout << "姓名:" << p->name << "年龄:" << p->age << "分数:" << p->score << endl;system("pause");return 0;
}
总结:结构体指针可以通过->操作符来访问结构体中的成员
8.5 结构体嵌套结构体
作用:结构体中的成员可以是另一个结构体
例如:每个老师辅导一个学员,一个老师的结构体中,记录一个学生的结构体

#include<iostream>
using namespace std;
#include<string>
// 定义学生结构体
struct student
{string name; // 学生姓名int age; // 学生年龄int score; //考试分数
};
// 定义老师结构体
struct teacher
{int id; // 教师编号string name; // 教师姓名int age; // 年龄struct student stu;
};
int main()
{// 创建老师结构体变量struct teacher t;t.id = 1000;t.name = "老王";t.age = 50;t.stu.name = "小王";t.stu.age = 20;t.stu.score = 60;cout << "教师姓名:" << t.name << "编号:" << t.id << "年龄:" << t.age << endl;cout << "学生姓名:" << t.stu.name << "年龄:" << t.stu.age << "分数:" << t.stu.score << endl;system("pause");return 0;
}
8.6 结构体做函数参数
作用:将结构体作为参数向函数中传递
传递方式有两种:
1.值传递
2.地址传递
#include<iostream>
using namespace std;
#include<string>
// 定义学生结构体
struct student
{string name; // 学生姓名int age; // 学生年龄int score; //考试分数
};
// 1.值传递
void printStudentInfo(struct student s)
{s.name = "哈哈";cout << "子函数中:" << "学生姓名:" << s.name << "年龄:" << s.age << "分数:" << s.score << endl;}
// 2.地址传递
void printStudentInfo2(struct student* s)
{ s->name = "哈哈";cout << "子函数中:" << "学生姓名:" << s->name << "年龄:" << s->age << "分数:" << s->score << endl;}int main()
{// 创建学生结构体变量struct student s;s.name = "张三";s.age = 20;s.score = 85;printStudentInfo(s);printStudentInfo2(&s);cout << "main函数中:" << "学生姓名:" << s.name << "年龄:" << s.age << "分数:" << s.score << endl;system("pause");return 0;
}
总结:如果不想修改主函数中的数据,用值传递,反之用地址传递
8.7 结构体中的const使用场景
作用:用const来防止误操作
当进行值传递时,实参和形参不是同一份数据,而当函数为结构体时,结构体内有多个成员变量,就会拷贝多少份数据,加大了内存负担。
因此,使用指针进行地址传递就减少了内存占用, 指针只占4个字节,但是为了更改的误操作,对结构体指针进行const修饰,防止误操作。
#include<iostream>
using namespace std;
#include<string>
// const使用场景
// 定义学生结构体
struct student
{string name; // 学生姓名int age; // 学生年龄int score; //考试分数
};
// 将函数中的形参改为指针,可以减少内存空间,并且不会复制出新的副本
void printStudentInfo(const struct student* s)
{//s->name = "哈哈"; //加入const后,就可以防止更改操作cout << "学生姓名:" << s->name << "年龄:" << s->age << "分数:" << s->score << endl;}
int main()
{// 创建学生结构体变量struct student s = { "张三",20, 85 };printStudentInfo(&s);system("pause");return 0;
}
二、C++核心编程
本阶段主要针对C++面向对象的编程技术
1.内存分区模型
C++程序在执行时,将内存大方向划分为4个区域:
1.代码区:存放函数体的二进制代码,由操作系统进行管理的
2.全局区:存放全局变量和静态变量以及常量
3.栈区︰由编译器自动分配释放,存放函数的参数值,局部变量等
4.堆区:由程序员分配和释放,若程序员不释放,程序结束时由操作系统回收
内存四区意义
不同区域存放的数据,赋予不同的生命周期,给我们更大的灵活编程
1.1 程序运行前
在程序编译后,生成了exe可执行程序,未执行该程序前分为两个区域
代码区:
存放CPU执行的机器指令
代码区是共享的,共享的目的是对于频繁被执行的程序,只需要在内存中有一份代码即可
代码区是只读的,使其只读的原因是防止程序意外地修改了它的指令
全局区:
全局变量和静态变量存放在此.
全局区还包含了常量区,字符串常量和其他常量(比如const修饰的)也存放在此.
该区域的数据在程序结束后由操作系统释放
只要带“局部”的,哪怕加了const进行修饰,也不在全局区。
#include<iostream>
using namespace std;
// 全局变量
int g_a = 10;
int g_b = 10;
const int c_g_a = 10;
const int c_g_b = 10;
int main()
{// 全局区// 全局变量、静态变量、常量// 创建普通局部变量int a = 10;int b = 10;cout << "局部变量a的地址为:" << (int)&a << endl;cout << "局部变量b的地址为:" << (int)&b << endl;/*局部变量a的地址为:9829476局部变量b的地址为:9829476*/cout << "全局变量g_a的地址为:" << (int)&g_a << endl;cout << "全局变量g_b的地址为:" << (int)&g_b << endl;/*全局变量g_a的地址为:11976756全局变量g_b的地址为:11976760*/// 静态变量 在普通变量前面加static,属于静态变量static int s_a = 10;static int s_b = 10;cout << "静态变量s_a的地址为:" << (int)&s_a << endl;cout << "静态变量s_b的地址为:" << (int)&s_b << endl;/*静态变量s_a的地址为:11976764静态变量s_b的地址为:11976768*/// 常量// 字符串常量cout << "字符串常量的地址为:" << (int)&"hello world" << endl;// 字符串常量的地址为:11967324// const修饰的变量// const修饰的全局变量cout << "全局常量c_g_a的地址为:" << (int)&c_g_a << endl;cout << "全局常量c_g_b的地址为:" << (int)&c_g_b << endl;/*全局常量c_g_a的地址为:11968136全局常量c_g_b的地址为:11968140*/// const修饰的局部变量const int c_1_a = 10;const int c_1_b = 10;cout << "局部常量c_g_a的地址为:" << (int)&c_1_a << endl;cout << "局部常量c_g_b的地址为:" << (int)&c_1_b << endl;/*局部常量c_g_a的地址为:9829452局部常量c_g_b的地址为:9829440*/system("pause");return 0;
}

总结:
1.C++中在程序运行前分为全局区和代码区
2.代码区特点是共篡和只读
3.全局区中存放全局变量、静态变量、常量
4.常量区中存放const修饰的全局常量和字符串常量
1.2 程序运行后
栈区:
由编译器自动分配释放,存放函数的参数值,局部变量等
注意事项:不要返回局部娈量的地址,栈区开辟的数据由编译器自动释放
#include<iostream>
using namespace std;
int* func(int b) // 形参也是放在栈区的
{b = 100;int a = 10; //局部变量 存放在栈区,栈区的数据在函数执行完后自动释放return &a; // 返回局部变量的地址
}
int main()
{// 注意事项:不要返回局部娈量的地址,栈区开辟的数据由编译器自动释放int* p = func(1);// 第一次正确输出,是因为编译器做了保留cout << *p << endl;// 第二次不再保留了,输出产生乱码cout << *p << endl; system("pause");return 0;
}
堆区:
曲程序员分配释放,若程序员不释放,程序结束时由操作系统回收
在C++中主要利用new在堆区开辟内存
newint (10)创建的数据,并不是把数据本身返回出来,而是把数据的地址返回出来,所以用指针接受/
#include<iostream>
using namespace std;
int* func()
{// 利用new关键字,可以将数据开辟到堆区// 指针本质也是变量,放在栈上,只是指针保存的数据放在堆区int* p = new int(10);return p;
}
int main()
{// 在堆区开辟数据int* p = func();cout << *p << endl;system("pause");return 0;
}

总结:
堆区数据由程序员管理开辟和释放堆区
数据利用new关键字进行开辟内存
1.3 new操作符
C++中利用new操作符在堆区开辟数据
堆区开辟的数据,由程序员手动开辟,手动释放,释放利用操作符delete
语法:new 数据类型
利用new创建的数据,会返回该数据对应的数据类型的指针
#include<iostream>
using namespace std;
int* func()
{// 在堆区创建整型数据// new返回的是该数据类型的指针int* p = new int(10);return p;
}
void test01()
{int* p = func();cout << *p << endl;cout << *p << endl;cout << *p << endl;// 堆区的数据 由程序员管理开发,管理释放// 如果想释放, 利用关键字deletedelete p;//cout << *p << endl; // 内存已经被释放,再次访问就是非法操作,会报错
}
// 2、在堆区利用new开辟数组
void test02()
{// 创建10个整型数据的数组int* arr = new int[10]; // []时,10代表数组有10个元素for (int i = 0; i < 10; i++){arr[i] = i + 100;}for (int i = 0; i < 10; i++){cout << arr[i] << endl;}// 释放堆区数组// 释放数组的时候,要加[]才可以delete[] arr;
}
int main()
{//test01();test02();system("pause");return 0;
}
2. 引用
2.1 引用的基本使用
作用:给变量起别名
语法:数据类型 &别名 = 原名

// 引用基本语法
// 数据类型 &别名 = 原名
int a = 10;
// 创建引用
int& b = a;
b = 20;
cout << "a = " << a << endl;
cout << "b = " << b << endl;
2.2 引用的注意事项
1.引用必须初始化
2.引用在初始化后,不可以改变

int a = 10;
// 引用必须初始化
// int& b;
int& b = a;// 引用在初始化后,不可以改变
// 创建引用
int c = 20;
b = c; //这是赋值操作,而不是更改引用
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl;
2.3 引用做函数参数
作用:函数传参时,可以利用引用的技术让形参修饰实参
优点:可以简化指针修改实参
#include<iostream>
using namespace std;
// 交换函数
// 1.值传递
void mySwap01(int a, int b)
{int temp = a;a = b;b = temp;
}// 2.地址传递
void mySwap02(int* a, int* b)
{int temp = *a;*a = *b;*b = temp;
}
// 3.引用传递
void mySwap03(int& a, int& b)
{int temp = a;a = b;b = temp;
}
int main()
{int a = 10;int b = 20;//mySwap01(a, b); // 值传递,形参并不会修饰实参//mySwap02(&a, &b); // 地址传递,形参可以修饰实参mySwap03(a, b); // 引用传递,形参可以修饰实参cout << "a = " << a << endl;cout << "b = " << b << endl;system("pause");return 0;
}
总结:通过引用参数产生的效果同按地址传递是—样的。引用的语法更清楚简单
2.4 引用做函数返回值
作用:引用是可以作为函数的返回值存在的
注意:不要返回局部变量引用
用法:函数调用作为左值
#include<iostream>
using namespace std;// 1.不返回局部变量的引用
int& test01()
{int a = 10; //局部变量存在在四区中的栈区return a;
}int& test02()
{static int a = 10; //静态变量存在在四区中的全局区,由系统管理释放return a;
}int main()
{//int& ref = test01();int& ref = test02();cout << "ref = " << ref << endl; //第一次结果正确,是因为编译器做了保留cout << "ref = " << ref << endl; //第二次结果正确,是因为a的内存已经做了释放// 2.如果函数的调用返回值是引用,函数的调用可以作为左值test02() = 1000;cout << "ref = " << ref << endl; cout << "ref = " << ref << endl; system("pause");return 0;
}
2.5 引用的本质
本质:引用的本质在c++内部实现是一个指针常量

总结:C++推荐用引用技术,因为语法方便,引用本质是指针常量,但是所有的指针操作编译器都帮我们做了
2.6 常量引用
本质:常量引用主要用来修饰形参,防止误操作
在函数形参列表中,可以加const修饰形参,防止形参改变实参
#include<iostream>
using namespace std;void showValue(const int& val)
{//val = 1; // 为了防止误操作,在形参之前加上const进行修饰cout << "val = " << val << endl;
}int main()
{// 常量引用// 使用场景:用来修饰形参,防止误操作int a = 10;//int& ref = 10; // 引用必须引一块合法的内存空间// 加上const后,编译器将代码修改为 int temp 10; const int& ref = temp;const int& ref = 10;//ref = 20; // 加入const之后变为只读,不可以修改int b = 100;showValue(b);system("pause");return 0;
}
3. 函数提高
3.1 函数默认参数
在C++中,函数的形参列表中的形参是可以有默认值的。
语法:返回值类型 函数名 (参数=默认值) {}
#include<iostream>
using namespace std;// 函数默认参数
// 如果我们自己传入数据,就用自己的数据,如果没有,那么用默认值
// 语法:返回值类型 函数名(形参=默认值){}// 注意事项
// 1.如果某个位置已经有了默认参数,那么从这个位置往后,从左到右都必须有默认值
int func(int a, int b = 20, int c = 30)
{return a + b + c;
}// 2.如果函数声明有默认参数,函数实现就不能有默认参数
// 声明和实现只能有一个有默认参数
int func2(int a = 10, int b = 10);int func2(int a = 10, int b = 10)
{return a + b;
}
int main()
{//cout << func(10) << endl;//cout << func(10, 30) << endl;cout << func2(10, 30) << endl;system("pause");return 0;
}
3.2 函数占位参数
C++中函数的形参列表里可以有占位参数,用来做占位,调用函数时必须填补该位置
语法:返回值类型 函数名(数据类型){}
#include<iostream>
using namespace std;// 占位参数
// 返回值类型 函数名(数据类型){}
// 占位参数还可以有默认参数 void func(int a, int = 10)void func(int a, int)
{cout << "this is func" << endl;
}int main()
{func(10, 10); // 占位参数必须要补system("pause");return 0;
}
3.3 函数重载
3.3.1 函数重载概述
作用:函数名可以相同,提高复用性
函数重载满足条件:
1.同一个作用域下
2.函数名称相同
3.函数参数类型不同,或者个数不同,或者顺序不同
注意:函数的返回值不可以作为函数重载的条件
#include<iostream>
using namespace std;// 函数重载
// 可以让函数名相同,提高复用性// 函数重载满足条件:
// 1.同一个作用域下
// 2.函数名称相同
// 3.函数参数类型不同,或者个数不同,或者顺序不同void func()
{cout << "func 的调用" << endl;
}void func(int a)
{cout << "func(int a) 的调用" << endl;
}void func(double a)
{cout << "func(double a) 的调用" << endl;
}void func(int a, double b)
{cout << "func(int a, double b) 的调用" << endl;
}void func(double b, int a)
{cout << "func(double b, int a) 的调用" << endl;
}// 注意事项:函数的返回值不可以作为函数重载的条件
// // 因为不管是void func还是int func,函数调用都是func(),就会产生歧义。
//int func(double b, int a)
//{
// cout << "void func(double b, int a) 的调用" << endl;
//}int main()
{func();func(10);func(3.14);func(10, 3.14);func(3.14, 10);system("pause");return 0;
}
3.3.2 函数重载的注意事项
函数重载满足条件:
1.引用作为重载条件
2.函数重载碰到函数默认参数
#include<iostream>
using namespace std;// 函数重载满足条件:
// 1.引用作为重载条件
void func(int& a) // int& =10 不合法
{cout << "func(int& a) 的调用" << endl;
}void func(const int& a) // const int& =10 会创建一个temp临时空间,合法
{cout << "func(const int& a) 的调用" << endl;
}// 2.函数重载碰到函数默认参数
void func2(int a, int b = 10)
{cout << "func2(int a, int b) 的调用" << endl;
}void func2(int a)
{cout << "func2(int a) 的调用" << endl;
}int main()
{// a是一个变量,可读可写,所以当引用作为重载条件时,编译器默认走void func(int& a)的版本int a = 10;// func(a); // 调用无const// 相当于 int& =10,这个没有引用一个合法空间,编译器不会通过的,编译器默认走void func(const int& a)的版本// func(10); // 调用有const// func2(10); // 两种都能调,因为默认参数b可以不传形参,出现了歧义system("pause");return 0;
}
4. 面向对象
C++面向对象的三大特性为:封装、继承、多态
C++认为万事万物都皆为对象,对象上有其属性和行为
例如:
人可以作为对象,属性有姓名、年龄、身高、体重…,行为有走、跑、跳、吃饭、唱歌…
车也可以作为对象,属性有轮胎、方向盘、车灯…行为有载人、放音乐、放空调…
具有相同性质的对象,我们可以抽象称为类,人属于人类,车属于车类
4.1 封装
4.1.1 封装的意义
封装是C++面向对象三大特性之一
封装的意义:
1.将属性和行为作为一个整体,表现生活中的事物
2.将属性和行为加以权限控制
封装意义一:
在设计类的时候,属性和行为写在一起,表现事物
语法:class 类名 { 访问权限 : 属性 / 行为 };
#include<iostream>
using namespace std;
// 设计一个圆类,求圆的周长
const double PI = 3.14;// class代表设计一个类
class Circle
{// 访问权限// 公共权限
public:// 类中的属性和行为我们统一称为:成员// 属性 成员属性、成员变量// 行为 成员函数、成员方法// 属性// 半径int m_r;// 行为// 获取圆的周长double calculateZC(){return 2 * PI * m_r;}// 也可设置一个给属性赋值的行为void setR(int r){m_r = r;}
};
int main()
{// 通过圆类 创建具体的圆(对象)// 实例化 (通过一个类创建一个对象的过程)Circle c1;// 给圆对象的属性进行赋值c1.m_r = 10;cout << "圆的周长为:" << c1.calculateZC() << endl;Circle c2;c2.setR(20); // 通过定义好的属性给行为直接赋值cout << "圆的周长为:" << c2.calculateZC() << endl;system("pause");return 0;
}
封装意义二:
类在设计时,可以把属性和行为放在不同的权限下,加以控制
访问权限有三种:
1.public公共权限
2.protected保护权限
3.private私有权限
#include<iostream>
using namespace std;// 访问权限, 三种:
// public 公共权限 成员, 类内可以访问,类外也可以访问
// protected 保护权限 成员, 类内可以访问,类外不可以访问 儿子可以访问父亲中的保护内容
// private 私有权限 成员, 类内可以访问,类外也可以访问 儿子不可以访问父亲中的保护内容class Person
{// 访问权限
public:// 公共权限string m_Name; // 姓名protected:// 保护权限string m_Car; //汽车
private:// 私有权限int m_Password; //银行卡密码public:// 行为void func(){m_Name = "张三";m_Car = "拖拉机";m_Password = 12346;}
};
int main()
{// 实例化具体对象Person p1;p1.m_Name = "李四";//p1.m_Car = "奔驰"; //m_Car是保护权限,类外不可以访问//p1.m_Password = 123; //m_Car是私有权限,类外不可以访问system("pause");return 0;
}
4.1.2 struct和class区别
在C++中struct和class唯一的区别就在于:
默认的访问权限不同
区别:
1.struct 默认权限为公共
2.class默认权限为私有
#include<iostream>
using namespace std;// struct和class唯一的区别就在于默认的访问权限不同// 1.struct 默认权限为公共
// 2.class 默认权限为私有class C1
{int m_A; // 默认权限为私有
};struct C2
{int m_A; // 默认权限为公共
};int main()
{C1 c1;//c1.m_A = 100; // 私有权限,类外不可以访问C2 c2;c2.m_A = 100; // 公共权限,类外可以访问system("pause");return 0;
}
4.1.3 成员属性设置为私有
在C++中struct和class唯一的区别就在于:
优点1:将所有成员属性设置为私有,可以自己控制读写权限
优点2:对于写权限,我们可以检测数据的有效性
其实,就是将属性设置私有后,设置public接口函数来控制对属性的读与写的状态。
#include<iostream>
using namespace std;// 成员属性设置为私有// 1、将所有成员属性设置为私有,可以自己控制读写权限
// 2、对于写权限,我们可以检测数据的有效性// 定义一个人类
class Person
{
public:// 设置姓名void setName(string name){m_Name = name;}// 获取姓名string getName(){return m_Name;}// 获取年龄int getAge(){return m_Age;}// 设置年龄 用于2,检测数据有效性时,设置为可写,但是年龄必须在0-150之间void setAge(int age){if (age < 0 || age > 150){cout << "年龄输入有误,赋值失败" << endl;return;}m_Age = age;}// 设置偶像void setIdol(string idol){m_Idol = idol;}private:string m_Name; // 姓名 可读可写int m_Age =18; // 年龄 只读 用于2,检测数据有效性时,设置为可写,但是年龄必须在0-150之间string m_Idol; // 偶像 只写
};int main()
{Person p;// 姓名的设置//p.m_Name = "张三";p.setName("张三");cout << "姓名为:" << p.getName() << endl; // 设置了可读可写状态// 年龄的设置//p.m_Age = 20; // 只设置了可读状态,不可写cout << "年龄为:" << p.getAge() << endl;// 偶像的设置p.setIdol("小明");//cout << "偶像为:" << p.m_Idol << endl; // 只设置了写的状态,不可读// 用于2,检测数据有效性时,设置为可写,但是年龄必须在0-150之间p.setAge(160);cout << "年龄为:" << p.getAge() << endl; //输出仍为18system("pause");return 0;
}
补充:和结构体类似,类里面还可以让另一个类来作为本类中的成员!!!
4.1.4 类的分文件编写
1.首先,先在头文件中进行类的申明,将所有成员函数的函数体去掉,只留下申明就行。
其实,类的分文间编写和上面的函数分文件编写类似,只要管函数就行。

#pragma once //防止头文件重复申明
#include<iostream>
using namespace std;class Circle
{
public:// 成员行为只留下函数的申明就行// 设置半径void setR(int r);// 获取半径int getR();
private:int m_R; //半径
};
2.接着,进行函数体的实现,新建.cpp文件
进行头文件的导入,类的申明中成员属性也不用管,只要实现成员函数的实现就行,在每个函数名之前加上函数的作用域(不然就是全局函数,是不对的),最后进行一个缩进就完成了。
#include"circle.h"// 设置半径
void Circle::setR(int r)
{m_R = r;
}
// 获取半径
int Circle::getR()
{return m_R;
}相关文章:
C++复习的长文指南
C复习的长文指南 一、入门语法知识1.预备1.1 main函数1.2 注释1.3 变量1.3 常量1.4 关键字1.5 标识符明明规则 2. 数据类型2.1 整型2.1.1 sizeof关键字 2.2 实型(浮点型)2.3 字符型2.4 转义字符2.5 字符串型2.6 布尔类型bool2.7 数据的输入 3. 运算符3.1…...

深入了解MySQL文件排序
数据准备 CREATE TABLE user_info (id bigint(20) NOT NULL AUTO_INCREMENT COMMENT ID,name varchar(20) NOT NULL COMMENT 用户名,age tinyint(4) NOT NULL DEFAULT 0 COMMENT 年龄,sex tinyint(2) NOT NULL DEFAULT 0 COMMENT 状态 0:男 1: 女,creat…...

【JAVA基础】反射
编译期和运行期 首先大家应该先了解两个概念,编译期和运行期,编译期就是编译器帮你把源代码翻译成机器能识别的代码,比如编译器把java代码编译成jvm识别的字节码文件,而运行期指的是将可执行文件交给操作系统去执行, …...
贪心算法(2024/7/16)
1合并区间 以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] [starti, endi] 。请你合并所有重叠的区间,并返回 一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间 。 示例 1: 输入:inter…...

Python 在Word表格中插入、删除行或列
Word文档中的表格可以用于组织和展示数据。在实际应用过程中,有时为了调整表格的结构或适应不同的数据展示需求,我们可能会需要插入、删除行或列。以下提供了几种使用Python在Word表格中插入或删除行、列的方法供参考: 文章目录 Python 在Wo…...

Java二十三种设计模式-单例模式(1/23)
引言 在软件开发中,设计模式是一套被反复使用的、大家公认的、经过分类编目的代码设计经验的总结。单例模式作为其中一种创建型模式,确保一个类只有一个实例,并提供一个全局访问点。本文将深入探讨单例模式的概念、实现方式、使用场景以及潜…...

Unity动画系统(3)---融合树
6.1 动画系统基础2-6_哔哩哔哩_bilibili Animator类 using System.Collections; using System.Collections.Generic; using UnityEngine; public class EthanController : MonoBehaviour { private Animator ani; private void Awake() { ani GetComponen…...

sqlalchemy.orm中validates对两个字段进行联合校验
版本 sqlalchemy1.4.37 需求说明 有个场景,需要在orm中对两个字段进行联合校验,当 col1 xxx’时,对 col2的长度进行检查,超过限制(500)时,进行截断。 网上找了很久,没找到类似的…...
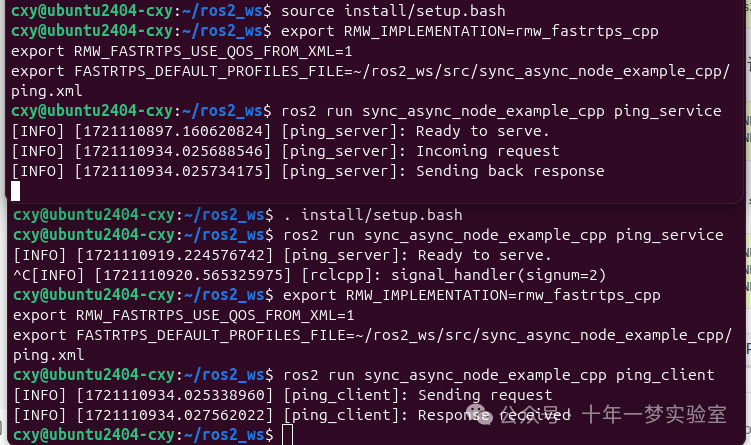
【ROS2】高级:解锁 Fast DDS 中间件的潜力 [社区贡献]
目标:本教程将展示如何在 ROS 2 中使用 Fast DDS 的扩展配置功能。 教程级别:高级 时间:20 分钟 目录 背景 先决条件在同一个节点中混合同步和异步发布 创建具有发布者的节点创建包含配置文件的 XML 文件执行发布者节点创建一个包含订阅者的节…...

VirtualBox虚拟机与主机互传文件的方法
建立共享文件夹 1.点击设置,点击共享文件夹,添加共享文件夹路径,保存 2.启动虚拟机,点击设备,点击安装增强功能,界面会出现一个光碟图标,点击光碟图标 3.打开光碟图标,出现一个目…...

访问控制系列
目录 一、基本概念 1.客体与主体 2.引用监控器与引用验证机制 3.安全策略与安全模型 4.安全内核 5.可信计算基 二、访问矩阵 三、访问控制策略 1.主体属性 2.客体属性 3.授权者组成 4.访问控制粒度 5.主体、客体状态 6.历史记录和上下文环境 7.数据内容 8.决策…...

【BUG】已解决:ModuleNotFoundError: No module named ‘cv2’
已解决:ModuleNotFoundError: No module named ‘cv2’ 欢迎来到英杰社区https://bbs.csdn.net/topics/617804998 欢迎来到我的主页,我是博主英杰,211科班出身,就职于医疗科技公司,热衷分享知识,武汉城市开…...

成都亚恒丰创教育科技有限公司 【插画猴子:笔尖下的灵动世界】
在浩瀚的艺术海洋中,每一种创作形式都是人类情感与想象力的独特表达。而插画,作为这一广阔领域中的璀璨明珠,以其独特的视觉语言和丰富的叙事能力,构建了一个又一个令人遐想连篇的梦幻空间。成都亚恒丰创教育科技有限公司 在众多插…...
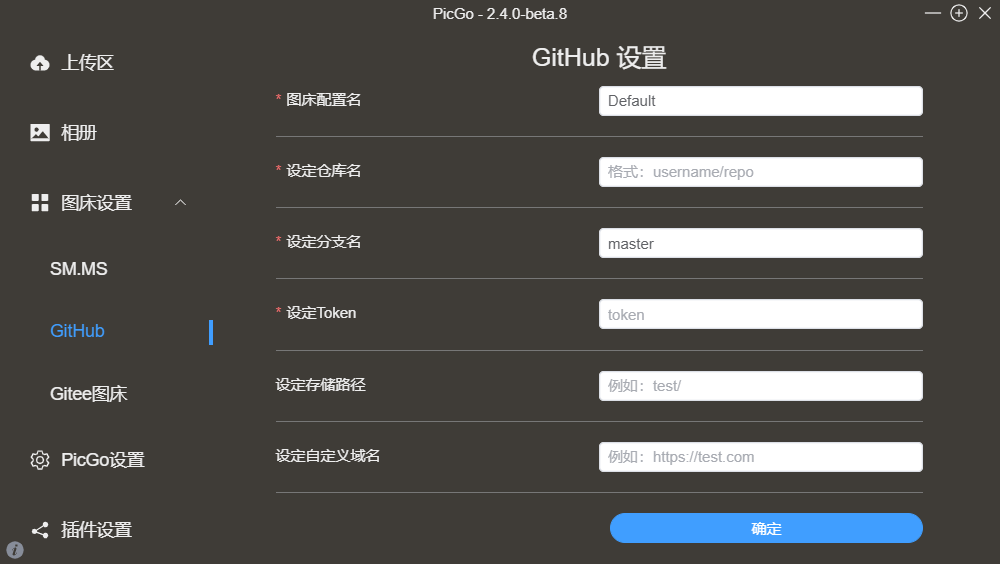
gite+picgo+typora打造个人免费笔记软件
文章目录 1️⃣个人笔记软件2️⃣ 配置教程2.1 使用软件2.2 node 环境配置2.3 软件安装2.4 gite仓库设置2.5 配置picgo2.6 测试检验2.7 github教程 🎡 完结撒花 1️⃣个人笔记软件 最近换了环境,没有之前的生产环境舒适,写笔记也没有劲头&…...

只用 CSS 能玩出什么花样?
在前端开发领域,CSS 不仅仅是一种样式语言,它更像是一位多才多艺的艺术家,能够创造出令人惊叹的视觉效果。本文将带你探索 CSS 的无限可能,从基本形状到动态动画,从几何艺术到仿生设计,只用 CSS 就能玩出令…...

Linux C++ 056-设计模式之迭代器模式
Linux C 056-设计模式之迭代器模式 本节关键字:Linux、C、设计模式、迭代器模式 相关库函数: 概念 迭代器模式(Iterator Pattern)是一种常用的设计模式。迭代器模式提供一种方法顺序访问一个聚合对象中的各个元素,而…...

【Elasticsearch7.11】reindex问题
参考博文链接 问题:reindex 时出现如下问题 原因:数据量大,kibana的问题 解决方法: 将DSL命令转化成CURL命令在服务上执行 CURL命令 自动转化 curl -XPOST "http://IP:PORT/_reindex" -H Content-Type: application…...

nginx代理缓存
在服务器架构中,反向代理服务器除了能够起到反向代理的作用之外,还可以缓存一些资源,加速客户端访问,nginx的ngx_http_proxy_module模块不仅包含了反向代理的功能还包含了缓存功能。 1、定义代理缓存规则 参数详解: p…...

[React 进阶系列] useSyncExternalStore hook
[React 进阶系列] useSyncExternalStore hook 前情提要,包括 yup 的实现在这里:yup 基础使用以及 jest 测试 简单的提一下,需要实现的功能是: yup schema 需要访问外部的 storage外部的 storage 是可变的React 内部也需要访问同…...

Linux C++ 055-设计模式之状态模式
Linux C 055-设计模式之状态模式 本节关键字:Linux、C、设计模式、状态模式 相关库函数: 概念 状态模式(State Pattern)是设计模式的一种,属于行为模式。允许一个对象在其内部状态改变时改变它的行为。对象看起来似…...

SpringBoot-17-MyBatis动态SQL标签之常用标签
文章目录 1 代码1.1 实体User.java1.2 接口UserMapper.java1.3 映射UserMapper.xml1.3.1 标签if1.3.2 标签if和where1.3.3 标签choose和when和otherwise1.4 UserController.java2 常用动态SQL标签2.1 标签set2.1.1 UserMapper.java2.1.2 UserMapper.xml2.1.3 UserController.ja…...

铭豹扩展坞 USB转网口 突然无法识别解决方法
当 USB 转网口扩展坞在一台笔记本上无法识别,但在其他电脑上正常工作时,问题通常出在笔记本自身或其与扩展坞的兼容性上。以下是系统化的定位思路和排查步骤,帮助你快速找到故障原因: 背景: 一个M-pard(铭豹)扩展坞的网卡突然无法识别了,扩展出来的三个USB接口正常。…...

CTF show Web 红包题第六弹
提示 1.不是SQL注入 2.需要找关键源码 思路 进入页面发现是一个登录框,很难让人不联想到SQL注入,但提示都说了不是SQL注入,所以就不往这方面想了 先查看一下网页源码,发现一段JavaScript代码,有一个关键类ctfs…...

什么是库存周转?如何用进销存系统提高库存周转率?
你可能听说过这样一句话: “利润不是赚出来的,是管出来的。” 尤其是在制造业、批发零售、电商这类“货堆成山”的行业,很多企业看着销售不错,账上却没钱、利润也不见了,一翻库存才发现: 一堆卖不动的旧货…...

【AI学习】三、AI算法中的向量
在人工智能(AI)算法中,向量(Vector)是一种将现实世界中的数据(如图像、文本、音频等)转化为计算机可处理的数值型特征表示的工具。它是连接人类认知(如语义、视觉特征)与…...

UR 协作机器人「三剑客」:精密轻量担当(UR7e)、全能协作主力(UR12e)、重型任务专家(UR15)
UR协作机器人正以其卓越性能在现代制造业自动化中扮演重要角色。UR7e、UR12e和UR15通过创新技术和精准设计满足了不同行业的多样化需求。其中,UR15以其速度、精度及人工智能准备能力成为自动化领域的重要突破。UR7e和UR12e则在负载规格和市场定位上不断优化…...

TSN交换机正在重构工业网络,PROFINET和EtherCAT会被取代吗?
在工业自动化持续演进的今天,通信网络的角色正变得愈发关键。 2025年6月6日,为期三天的华南国际工业博览会在深圳国际会展中心(宝安)圆满落幕。作为国内工业通信领域的技术型企业,光路科技(Fiberroad&…...

android RelativeLayout布局
<?xml version"1.0" encoding"utf-8"?> <RelativeLayout xmlns:android"http://schemas.android.com/apk/res/android"android:layout_width"match_parent"android:layout_height"match_parent"android:gravity&…...

从零开始了解数据采集(二十八)——制造业数字孪生
近年来,我国的工业领域正经历一场前所未有的数字化变革,从“双碳目标”到工业互联网平台的推广,国家政策和市场需求共同推动了制造业的升级。在这场变革中,数字孪生技术成为备受关注的关键工具,它不仅让企业“看见”设…...
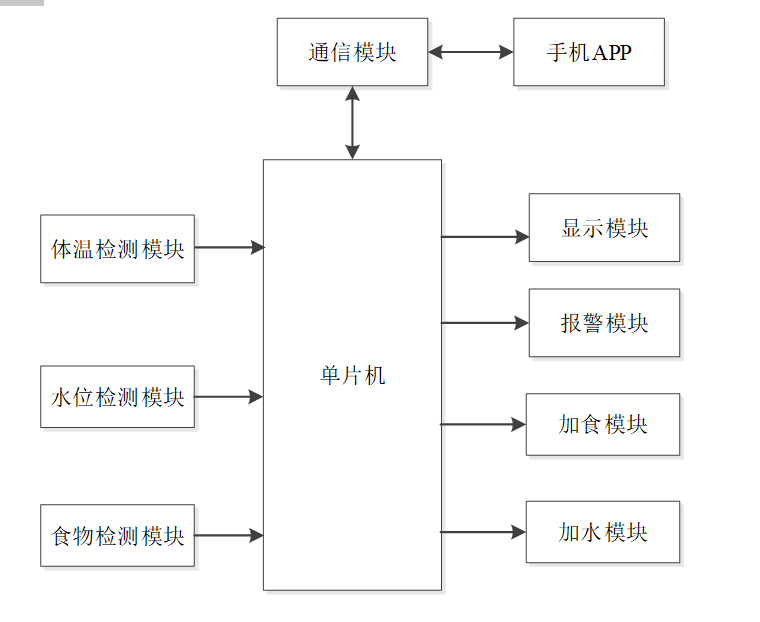
基于单片机的宠物屋智能系统设计与实现(论文+源码)
本设计基于单片机的宠物屋智能系统核心是实现对宠物生活环境及状态的智能管理。系统以单片机为中枢,连接红外测温传感器,可实时精准捕捉宠物体温变化,以便及时发现健康异常;水位检测传感器时刻监测饮用水余量,防止宠物…...