昇思25天学习打卡营第15天|两个分类实验
打卡


目录
打卡
实验1:K近邻算法实现红酒聚类
数据准备
模型构建--计算距离
计算演示
模型预测
实验2:基于MobileNetv2的垃圾分类
任务说明
数据集
参数配置(训练/验证/推理)
数据预处理
MobileNetV2模型搭建
MobileNetV2模型的训练与测试
模型训练与测试
训练过程
模型推理
导出AIR/GEIR/ONNX模型文件
此次两个分类实验中,一个是经典的knn聚类算法,一种是轻量级cnn网络,都是基于较轻资源可以实现的任务。
可以在任务简单、逻辑清晰的任务中使用。
实验1:K近邻算法实现红酒聚类
K近邻算法(K-Nearest-Neighbor, KNN)是一种用于分类和回归的非参数统计方法,于1968年提出(Cover等人,1967)。
- 思想:如何确定某个样本的类别?计算 & 找出该样本与所有样本的中距离最近的K个样本;统计这K个样本的类别并投票,投票最多的类别即确定为该样本的类别。
- knn的3个要素:
K值,一个样本的分类是由K个邻居的“多数表决”确定的。K值越小,容易受噪声影响,反之,会使类别之间的界限变得模糊。k的取值可以根据问题和数据特点来确定。在具体实现时,可以考虑样本的权重,即每个样本有不同的投票权重,这种方法称为带权重的k近邻算法,它是一种变种的k近邻算法。如,带样本权重的回归预测函数为:
,其中𝑤𝑖 为第个 𝑖 样本的权重。
距离度量,反映了特征空间中两个样本间的相似度,距离越小,越相似。常用的有Lp距离(p=2时,即为欧式距离)、曼哈顿距离、海明距离、切比雪夫距离等。
分类决策规则,通常是多数表决,或者基于距离加权的多数表决(权值与距离成反比)。
数据准备
Wine数据集是模式识别最著名的数据集之一,Wine数据集的官网:Wine Data Set。这些数据是对来自意大利同一地区但来自三个不同品种的葡萄酒进行化学分析的结果。数据集分析了三种葡萄酒中每种所含13种成分的量。这些13种属性是
- Alcohol,酒精
- Malic acid,苹果酸
- Ash,灰
- Alcalinity of ash,灰的碱度
- Magnesium,镁
- Total phenols,总酚
- Flavanoids,类黄酮
- Nonflavanoid phenols,非黄酮酚
- Proanthocyanins,原花青素
- Color intensity,色彩强度
- Hue,色调
- OD280/OD315 of diluted wines,稀释酒的OD280/OD315
- Proline,脯氨酸
- 方式一,从Wine数据集官网下载wine.data文件。
- 方式二,从华为云OBS中下载wine.data文件。
部分数据如下图:第1列为类别,2~14列为13种化学成分数据。

共178条数据,其中1类是1-59,行,2类是60-130行,3类是131-178行。取两个属性观察样本分布情况和可区分性,如下图。


共178条数据,按照128:50划分为训练集和验证集样本。
import numpy as nptrain_idx = np.random.choice(178, 128, replace=False)
test_idx = np.array(list(set(range(178)) - set(train_idx)))
X_train, Y_train = X[train_idx], Y[train_idx]
X_test, Y_test = X[test_idx], Y[test_idx]print(np.shape(X_train)) ### (128, 13)
print(np.shape(X_test)) ### (50, 13)
print(np.shape(Y_train)) ## (128,)
print(np.shape(Y_test))模型构建--计算距离
同样地,继承 nn.Cell 类构建模型,使用 ops.tile, square, ReduceSum, sqrt, TopK等算子,通过矩阵运算的方式同时计算输入样本x和已明确分类的其他样本X_train的距离(欧式距离),并计算出top k 近邻。
class KnnNet(nn.Cell):def __init__(self, k):super(KnnNet, self).__init__()self.k = kdef construct(self, x, X_train):#平铺输入x以匹配X_train中的样本数,即复制x到128份与X_train一样的维度,方便计算。x_tile = ops.tile(x, (128, 1))square_diff = ops.square(x_tile - X_train)square_dist = ops.sum(square_diff, 1)dist = ops.sqrt(square_dist)#-dist表示值越大,样本就越接近: 沿给定维度查找k个最大或最小元素和对应的索引,需要排序的维度dims=None,因为是1维。默认 sorted=True 按值降序排序。### 负最大,即正距离最小即最近邻的K个值values, indices = ops.topk(-dist, self.k)return indicesdef knn(knn_net, x, X_train, Y_train):x, X_train = ms.Tensor(x), ms.Tensor(X_train)indices = knn_net(x, X_train)topk_cls = [0]*len(indices.asnumpy())for idx in indices.asnumpy():topk_cls[Y_train[idx]] += 1cls = np.argmax(topk_cls)return cls计算演示



如上图,是针对一个验证样本,筛选出来13个特征中计算knn 算法的5个距离最小的样本后,拿到对应的分类类别 Y_train[idx],为k=5个样本对应的类别进行统计,取统计值最大的类别np.argmax(topk_cls)即为分类结果。
模型预测
下面是所有验证样本的统计,计算验证精度。
acc = 0
knn_net = KnnNet(5)
for x, y in zip(X_test, Y_test):pred = knn(knn_net, x, X_train, Y_train)acc += (pred == y)print('label: %d, prediction: %s' % (y, pred))print('Validation accuracy is %f' % (acc/len(Y_test)))根据下图演示,说明KNN算法在该3分类任务上有效,能根据酒的13种属性判断出酒的品种。多次改变k测试,效果一般,验证精度不超过80%。

实验2:基于MobileNetv2的垃圾分类
MobileNet网络是由Google团队于2017年提出的专注于移动端、嵌入式或IoT设备的轻量级CNN网络,相比于传统的卷积神经网络,MobileNet网络使用深度可分离卷积(Depthwise Separable Convolution)的思想在准确率小幅度降低的前提下,大大减小了模型参数与运算量。并引入宽度系数 α和分辨率系数 β使模型满足不同应用场景的需求。
由于MobileNet网络中Relu激活函数处理低维特征信息时会存在大量的丢失,所以MobileNetV2网络提出使用倒残差结构(Inverted residual block)和 Linear Bottlenecks来设计网络,以提高模型的准确率,且优化后的模型更小。
如下图,Inverted residual block结构是先使用1x1卷积进行升维,然后使用3x3的DepthWise卷积,最后使用1x1的卷积进行降维,与Residual block结构相反。Residual block是先使用1x1的卷积进行降维,然后使用3x3的卷积,最后使用1x1的卷积进行升维。

- 说明: 详细内容可参见MobileNetV2论文
任务说明
通过读取本地图像数据作为输入,对图像中的垃圾物体进行检测,并且将检测结果图片保存到文件中。
数据集
- 权重文件:
- https://ascend-professional-construction-dataset.obs.cn-north-4.myhuaweicloud.com:443/ComputerVision/mobilenetV2-200_1067.zip
- 数据文件:
- https://ascend-professional-construction-dataset.obs.cn-north-4.myhuaweicloud.com:443/MindStudio-pc/data_en.zip
- 环境添加:`pip install easydict`
import math
import numpy as np
import os
import random
from download import downloadfrom matplotlib import pyplot as plt
from easydict import EasyDict
from PIL import Image
import numpy as np
import mindspore.nn as nn
from mindspore import ops as P
from mindspore.ops import add
from mindspore import Tensor
import mindspore.common.dtype as mstype
import mindspore.dataset as de
import mindspore.dataset.vision as C
import mindspore.dataset.transforms as C2
import mindspore as ms
from mindspore import set_context, nn, Tensor, load_checkpoint, save_checkpoint, export
from mindspore.train import Model
from mindspore.train import Callback, LossMonitor, ModelCheckpoint, CheckpointConfigos.environ['GLOG_v'] = '3' # Log level includes 3(ERROR), 2(WARNING), 1(INFO), 0(DEBUG).
os.environ['GLOG_logtostderr'] = '0' # 0:输出到文件,1:输出到屏幕
os.environ['GLOG_log_dir'] = '../../log' # 日志目录
os.environ['GLOG_stderrthreshold'] = '2' # 输出到目录也输出到屏幕:3(ERROR), 2(WARNING), 1(INFO), 0(DEBUG).
set_context(mode=ms.GRAPH_MODE, device_target="CPU", device_id=0) # 设置采用图模式执行,设备为Ascend## 下载预训练权重文件
url = "https://ascend-professional-construction-dataset.obs.cn-north-4.myhuaweicloud.com:443/ComputerVision/mobilenetV2-200_1067.zip"
path = download(url, "./", kind="zip", replace=True)https://ascend-professional-construction-dataset.obs.cn-north-4.myhuaweicloud.com:443/MindStudio-pc/data_en.zip

参数配置(训练/验证/推理)
# 垃圾分类数据集标签,以及用于标签映射的字典。
garbage_classes = {'干垃圾': ['贝壳', '打火机', '旧镜子', '扫把', '陶瓷碗', '牙刷', '一次性筷子', '脏污衣服'],'可回收物': ['报纸', '玻璃制品', '篮球', '塑料瓶', '硬纸板', '玻璃瓶', '金属制品', '帽子', '易拉罐', '纸张'],'湿垃圾': ['菜叶', '橙皮', '蛋壳', '香蕉皮'],'有害垃圾': ['电池', '药片胶囊', '荧光灯', '油漆桶']
}class_cn = ['贝壳', '打火机', '旧镜子', '扫把', '陶瓷碗', '牙刷', '一次性筷子', '脏污衣服','报纸', '玻璃制品', '篮球', '塑料瓶', '硬纸板', '玻璃瓶', '金属制品', '帽子', '易拉罐', '纸张','菜叶', '橙皮', '蛋壳', '香蕉皮','电池', '药片胶囊', '荧光灯', '油漆桶']
class_en = ['Seashell', 'Lighter','Old Mirror', 'Broom','Ceramic Bowl', 'Toothbrush','Disposable Chopsticks','Dirty Cloth','Newspaper', 'Glassware', 'Basketball', 'Plastic Bottle', 'Cardboard','Glass Bottle', 'Metalware', 'Hats', 'Cans', 'Paper','Vegetable Leaf','Orange Peel', 'Eggshell','Banana Peel','Battery', 'Tablet capsules','Fluorescent lamp', 'Paint bucket']index_en = {'Seashell': 0, 'Lighter': 1, 'Old Mirror': 2, 'Broom': 3, 'Ceramic Bowl': 4, 'Toothbrush': 5, 'Disposable Chopsticks': 6, 'Dirty Cloth': 7,'Newspaper': 8, 'Glassware': 9, 'Basketball': 10, 'Plastic Bottle': 11, 'Cardboard': 12, 'Glass Bottle': 13, 'Metalware': 14, 'Hats': 15, 'Cans': 16, 'Paper': 17,'Vegetable Leaf': 18, 'Orange Peel': 19, 'Eggshell': 20, 'Banana Peel': 21,'Battery': 22, 'Tablet capsules': 23, 'Fluorescent lamp': 24, 'Paint bucket': 25}# 训练超参
config = EasyDict({"num_classes": 26,"image_height": 224,"image_width": 224,#"data_split": [0.9, 0.1],"backbone_out_channels":1280,"batch_size": 16,"eval_batch_size": 8,"epochs": 10,"lr_max": 0.05,"momentum": 0.9,"weight_decay": 1e-4,"save_ckpt_epochs": 1,"dataset_path": "./data_en","class_index": index_en,"pretrained_ckpt": "./mobilenetV2-200_1067.ckpt" # mobilenetV2-200_1067.ckpt
})
数据预处理
用ImageFolderDataset方法读取垃圾分类数据集,并整体对数据集进行处理。
读取数据集时指定训练集和测试集,首先对整个数据集进行归一化,修改图像频道等预处理操作。然后对训练集的数据依次进行RandomCropDecodeResize、RandomHorizontalFlip、RandomColorAdjust、shuffle操作,以增加训练数据的丰富度;对测试集进行Decode、Resize、CenterCrop等预处理操作;最后返回处理后的数据集。
def create_dataset(dataset_path, config, training=True, buffer_size=1000):"""create a train or eval datasetArgs:dataset_path(string): the path of dataset.config(struct): the config of train and eval in diffirent platform.Returns:train_dataset, val_dataset"""data_path = os.path.join(dataset_path, 'train' if training else 'test')ds = de.ImageFolderDataset(data_path, num_parallel_workers=4, class_indexing=config.class_index)resize_height = config.image_heightresize_width = config.image_widthnormalize_op = C.Normalize(mean=[0.485*255, 0.456*255, 0.406*255], std=[0.229*255, 0.224*255, 0.225*255])change_swap_op = C.HWC2CHW()type_cast_op = C2.TypeCast(mstype.int32)if training:crop_decode_resize = C.RandomCropDecodeResize(resize_height, scale=(0.08, 1.0), ratio=(0.75, 1.333))horizontal_flip_op = C.RandomHorizontalFlip(prob=0.5)color_adjust = C.RandomColorAdjust(brightness=0.4, contrast=0.4, saturation=0.4)train_trans = [crop_decode_resize, horizontal_flip_op, color_adjust, normalize_op, change_swap_op]train_ds = ds.map(input_columns="image", operations=train_trans, num_parallel_workers=4)train_ds = train_ds.map(input_columns="label", operations=type_cast_op, num_parallel_workers=4)train_ds = train_ds.shuffle(buffer_size=buffer_size)ds = train_ds.batch(config.batch_size, drop_remainder=True)else:decode_op = C.Decode()resize_op = C.Resize((int(resize_width/0.875), int(resize_width/0.875)))center_crop = C.CenterCrop(resize_width)eval_trans = [decode_op, resize_op, center_crop, normalize_op, change_swap_op]eval_ds = ds.map(input_columns="image", operations=eval_trans, num_parallel_workers=4)eval_ds = eval_ds.map(input_columns="label", operations=type_cast_op, num_parallel_workers=4)ds = eval_ds.batch(config.eval_batch_size, drop_remainder=True)return dsds = create_dataset(dataset_path=config.dataset_path, config=config, training=False)
print(ds.get_dataset_size())
data = ds.create_dict_iterator(output_numpy=True)._get_next()
images = data['image']
labels = data['label']for i in range(1, 5):plt.subplot(2, 2, i)plt.imshow(np.transpose(images[i], (1,2,0)))plt.title('label: %s' % class_en[labels[i]])plt.xticks([])
plt.show()处理后的数据展示

MobileNetV2模型搭建
继承mindspore.nn.Cell基类搭建网络。
1)各层需要预先在__init__方法中定义
2)通过定义construct方法来完成神经网络的前向构造。原始模型激活函数为ReLU6,池化模块采用是全局平均池化层。
__all__ = ['MobileNetV2', 'MobileNetV2Backbone', 'MobileNetV2Head', 'mobilenet_v2']def _make_divisible(v, divisor, min_value=None):if min_value is None:min_value = divisornew_v = max(min_value, int(v + divisor / 2) // divisor * divisor)if new_v < 0.9 * v:new_v += divisorreturn new_vclass GlobalAvgPooling(nn.Cell):"""Global avg pooling definition.Args:Returns:Tensor, output tensor.Examples:>>> GlobalAvgPooling()"""def __init__(self):super(GlobalAvgPooling, self).__init__()def construct(self, x):x = P.mean(x, (2, 3))return xclass ConvBNReLU(nn.Cell):"""Convolution/Depthwise fused with Batchnorm and ReLU block definition.Args:in_planes (int): Input channel.out_planes (int): Output channel.kernel_size (int): Input kernel size.stride (int): Stride size for the first convolutional layer. Default: 1.groups (int): channel group. Convolution is 1 while Depthiwse is input channel. Default: 1.Returns:Tensor, output tensor.Examples:>>> ConvBNReLU(16, 256, kernel_size=1, stride=1, groups=1)"""def __init__(self, in_planes, out_planes, kernel_size=3, stride=1, groups=1):super(ConvBNReLU, self).__init__()padding = (kernel_size - 1) // 2in_channels = in_planesout_channels = out_planesif groups == 1:conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, pad_mode='pad', padding=padding)else:out_channels = in_planesconv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, pad_mode='pad',padding=padding, group=in_channels)layers = [conv, nn.BatchNorm2d(out_planes), nn.ReLU6()]self.features = nn.SequentialCell(layers)def construct(self, x):output = self.features(x)return outputclass InvertedResidual(nn.Cell):"""Mobilenetv2 residual block definition.Args:inp (int): Input channel.oup (int): Output channel.stride (int): Stride size for the first convolutional layer. Default: 1.expand_ratio (int): expand ration of input channelReturns:Tensor, output tensor.Examples:>>> ResidualBlock(3, 256, 1, 1)"""def __init__(self, inp, oup, stride, expand_ratio):super(InvertedResidual, self).__init__()assert stride in [1, 2]hidden_dim = int(round(inp * expand_ratio))self.use_res_connect = stride == 1 and inp == ouplayers = []if expand_ratio != 1:layers.append(ConvBNReLU(inp, hidden_dim, kernel_size=1))layers.extend([ConvBNReLU(hidden_dim, hidden_dim,stride=stride, groups=hidden_dim),nn.Conv2d(hidden_dim, oup, kernel_size=1,stride=1, has_bias=False),nn.BatchNorm2d(oup),])self.conv = nn.SequentialCell(layers)self.cast = P.Cast()def construct(self, x):identity = xx = self.conv(x)if self.use_res_connect:return P.add(identity, x)return xclass MobileNetV2Backbone(nn.Cell):"""MobileNetV2 architecture.Args:class_num (int): number of classes.width_mult (int): Channels multiplier for round to 8/16 and others. Default is 1.has_dropout (bool): Is dropout used. Default is falseinverted_residual_setting (list): Inverted residual settings. Default is Noneround_nearest (list): Channel round to . Default is 8Returns:Tensor, output tensor.Examples:>>> MobileNetV2(num_classes=1000)"""def __init__(self, width_mult=1., inverted_residual_setting=None, round_nearest=8,input_channel=32, last_channel=1280):super(MobileNetV2Backbone, self).__init__()block = InvertedResidual# setting of inverted residual blocksself.cfgs = inverted_residual_settingif inverted_residual_setting is None:self.cfgs = [# t, c, n, s[1, 16, 1, 1],[6, 24, 2, 2],[6, 32, 3, 2],[6, 64, 4, 2],[6, 96, 3, 1],[6, 160, 3, 2],[6, 320, 1, 1],]# building first layerinput_channel = _make_divisible(input_channel * width_mult, round_nearest)self.out_channels = _make_divisible(last_channel * max(1.0, width_mult), round_nearest)features = [ConvBNReLU(3, input_channel, stride=2)]# building inverted residual blocksfor t, c, n, s in self.cfgs:output_channel = _make_divisible(c * width_mult, round_nearest)for i in range(n):stride = s if i == 0 else 1features.append(block(input_channel, output_channel, stride, expand_ratio=t))input_channel = output_channelfeatures.append(ConvBNReLU(input_channel, self.out_channels, kernel_size=1))self.features = nn.SequentialCell(features)self._initialize_weights()def construct(self, x):x = self.features(x)return xdef _initialize_weights(self):"""Initialize weights.Args:Returns:None.Examples:>>> _initialize_weights()"""self.init_parameters_data()for _, m in self.cells_and_names():if isinstance(m, nn.Conv2d):n = m.kernel_size[0] * m.kernel_size[1] * m.out_channelsm.weight.set_data(Tensor(np.random.normal(0, np.sqrt(2. / n),m.weight.data.shape).astype("float32")))if m.bias is not None:m.bias.set_data(Tensor(np.zeros(m.bias.data.shape, dtype="float32")))elif isinstance(m, nn.BatchNorm2d):m.gamma.set_data(Tensor(np.ones(m.gamma.data.shape, dtype="float32")))m.beta.set_data(Tensor(np.zeros(m.beta.data.shape, dtype="float32")))@propertydef get_features(self):return self.featuresclass MobileNetV2Head(nn.Cell):"""MobileNetV2 architecture.Args:class_num (int): Number of classes. Default is 1000.has_dropout (bool): Is dropout used. Default is falseReturns:Tensor, output tensor.Examples:>>> MobileNetV2(num_classes=1000)"""def __init__(self, input_channel=1280, num_classes=1000, has_dropout=False, activation="None"):super(MobileNetV2Head, self).__init__()# mobilenet headhead = ([GlobalAvgPooling(), nn.Dense(input_channel, num_classes, has_bias=True)] if not has_dropout else[GlobalAvgPooling(), nn.Dropout(0.2), nn.Dense(input_channel, num_classes, has_bias=True)])self.head = nn.SequentialCell(head)self.need_activation = Trueif activation == "Sigmoid":self.activation = nn.Sigmoid()elif activation == "Softmax":self.activation = nn.Softmax()else:self.need_activation = Falseself._initialize_weights()def construct(self, x):x = self.head(x)if self.need_activation:x = self.activation(x)return xdef _initialize_weights(self):"""Initialize weights.Args:Returns:None.Examples:>>> _initialize_weights()"""self.init_parameters_data()for _, m in self.cells_and_names():if isinstance(m, nn.Dense):m.weight.set_data(Tensor(np.random.normal(0, 0.01, m.weight.data.shape).astype("float32")))if m.bias is not None:m.bias.set_data(Tensor(np.zeros(m.bias.data.shape, dtype="float32")))@propertydef get_head(self):return self.headclass MobileNetV2(nn.Cell):"""MobileNetV2 architecture.Args:class_num (int): number of classes.width_mult (int): Channels multiplier for round to 8/16 and others. Default is 1.has_dropout (bool): Is dropout used. Default is falseinverted_residual_setting (list): Inverted residual settings. Default is Noneround_nearest (list): Channel round to . Default is 8Returns:Tensor, output tensor.Examples:>>> MobileNetV2(backbone, head)"""def __init__(self, num_classes=1000, width_mult=1., has_dropout=False, inverted_residual_setting=None, \round_nearest=8, input_channel=32, last_channel=1280):super(MobileNetV2, self).__init__()self.backbone = MobileNetV2Backbone(width_mult=width_mult, \inverted_residual_setting=inverted_residual_setting, \round_nearest=round_nearest, input_channel=input_channel, last_channel=last_channel).get_featuresself.head = MobileNetV2Head(input_channel=self.backbone.out_channel, num_classes=num_classes, \has_dropout=has_dropout).get_headdef construct(self, x):x = self.backbone(x)x = self.head(x)return xclass MobileNetV2Combine(nn.Cell):"""MobileNetV2Combine architecture.Args:backbone (Cell): the features extract layers.head (Cell): the fully connected layers.Returns:Tensor, output tensor.Examples:>>> MobileNetV2(num_classes=1000)"""def __init__(self, backbone, head):super(MobileNetV2Combine, self).__init__(auto_prefix=False)self.backbone = backboneself.head = headdef construct(self, x):x = self.backbone(x)x = self.head(x)return xdef mobilenet_v2(backbone, head):return MobileNetV2Combine(backbone, head)MobileNetV2模型的训练与测试
一般情况下,模型训练时采用静态学习率,如0.01。随着训练步数的增加,模型逐渐趋于收敛,对权重参数的更新幅度应该逐渐降低,以减小模型训练后期的抖动。所以,模型训练时可以采用动态下降的学习率,常见的学习率下降策略有:
- polynomial decay/square decay;
- cosine decay;
- exponential decay;
- stage decay.
本次使用cosine decay下降策略,如下代码:
def cosine_decay(total_steps, lr_init=0.0, lr_end=0.0, lr_max=0.1, warmup_steps=0):"""Applies cosine decay to generate learning rate array.Args:total_steps(int): all steps in training.lr_init(float): init learning rate.lr_end(float): end learning ratelr_max(float): max learning rate.warmup_steps(int): all steps in warmup epochs.Returns:list, learning rate array."""lr_init, lr_end, lr_max = float(lr_init), float(lr_end), float(lr_max)decay_steps = total_steps - warmup_stepslr_all_steps = []inc_per_step = (lr_max - lr_init) / warmup_steps if warmup_steps else 0for i in range(total_steps):if i < warmup_steps:lr = lr_init + inc_per_step * (i + 1)else:cosine_decay = 0.5 * (1 + math.cos(math.pi * (i - warmup_steps) / decay_steps))lr = (lr_max - lr_end) * cosine_decay + lr_endlr_all_steps.append(lr)return lr_all_steps模型训练过程中,可以添加检查点(Checkpoint)用于保存模型的参数,以便进行推理及中断后再训练使用。使用场景如下:
- 训练后推理场景
- 再训练场景(防止长时间的训练任务异常退出; 微调场景)
这里加载ImageNet数据上预训练的MobileNetv2进行Fine-tuning,只训练最后修改的FC层,并在训练过程中保存Checkpoint。
def switch_precision(net, data_type):if ms.get_context('device_target') == "Ascend":net.to_float(data_type)for _, cell in net.cells_and_names():if isinstance(cell, nn.Dense):cell.to_float(ms.float32)模型训练与测试
训练之前,定义训练函数,读取数据并对模型进行实例化,定义优化器和损失函数。
在训练MobileNetV2之前对MobileNetV2Backbone层的参数进行了固定,使其在训练过程中对该模块的权重参数不进行更新;只对MobileNetV2Head模块的参数进行更新。
from mindspore.amp import FixedLossScaleManager
import time
LOSS_SCALE = 1024train_dataset = create_dataset(dataset_path=config.dataset_path, config=config)
eval_dataset = create_dataset(dataset_path=config.dataset_path, config=config)
step_size = train_dataset.get_dataset_size()backbone = MobileNetV2Backbone() #last_channel=config.backbone_out_channels
# Freeze parameters of backbone. You can comment these two lines.
for param in backbone.get_parameters():param.requires_grad = False
# load parameters from pretrained model
load_checkpoint(config.pretrained_ckpt, backbone)head = MobileNetV2Head(input_channel=backbone.out_channels, num_classes=config.num_classes)
network = mobilenet_v2(backbone, head)# define loss, optimizer, and model
loss = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean')
loss_scale = FixedLossScaleManager(LOSS_SCALE, drop_overflow_update=False)
lrs = cosine_decay(config.epochs * step_size, lr_max=config.lr_max)
opt = nn.Momentum(network.trainable_params(), lrs, config.momentum, config.weight_decay, loss_scale=LOSS_SCALE)# 定义用于训练的train_loop函数。
def train_loop(model, dataset, loss_fn, optimizer):# 定义正向计算函数def forward_fn(data, label):logits = model(data)loss = loss_fn(logits, label)return loss# 定义微分函数,使用mindspore.value_and_grad获得微分函数grad_fn,输出loss和梯度。# 由于是对模型参数求导,grad_position 配置为None,传入可训练参数。grad_fn = ms.value_and_grad(forward_fn, None, optimizer.parameters)# 定义 one-step training函数def train_step(data, label):loss, grads = grad_fn(data, label)optimizer(grads)return losssize = dataset.get_dataset_size()model.set_train()for batch, (data, label) in enumerate(dataset.create_tuple_iterator()):loss = train_step(data, label)if batch % 10 == 0:loss, current = loss.asnumpy(), batchprint(f"loss: {loss:>7f} [{current:>3d}/{size:>3d}]")# 定义用于测试的test_loop函数。
def test_loop(model, dataset, loss_fn):num_batches = dataset.get_dataset_size()model.set_train(False)total, test_loss, correct = 0, 0, 0for data, label in dataset.create_tuple_iterator():pred = model(data)total += len(data)test_loss += loss_fn(pred, label).asnumpy()correct += (pred.argmax(1) == label).asnumpy().sum()test_loss /= num_batchescorrect /= totalprint(f"Test: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")print("============== Starting Training ==============")
# 由于时间问题,训练过程只进行了2个epoch ,可以根据需求调整。
epoch_begin_time = time.time()
epochs = 2
for t in range(epochs):begin_time = time.time()print(f"Epoch {t+1}\n-------------------------------")train_loop(network, train_dataset, loss, opt)ms.save_checkpoint(network, "save_mobilenetV2_model.ckpt")end_time = time.time()times = end_time - begin_timeprint(f"per epoch time: {times}s")test_loop(network, eval_dataset, loss)
epoch_end_time = time.time()
times = epoch_end_time - epoch_begin_time
print(f"total time: {times}s")
print("============== Training Success ==============")训练过程
没有占用gpu显存(是英伟达的4090).


模型推理
加载模型Checkpoint进行推理,使用load_checkpoint接口加载数据时,需要把数据传入给原始网络,而不能传递给带有优化器和损失函数的训练网络。
CKPT="save_mobilenetV2_model.ckpt"def image_process(image):"""Precess one image per time.Args:image: shape (H, W, C)"""mean=[0.485*255, 0.456*255, 0.406*255]std=[0.229*255, 0.224*255, 0.225*255]image = (np.array(image) - mean) / stdimage = image.transpose((2,0,1))img_tensor = Tensor(np.array([image], np.float32))return img_tensordef infer_one(network, image_path):image = Image.open(image_path).resize((config.image_height, config.image_width))logits = network(image_process(image))pred = np.argmax(logits.asnumpy(), axis=1)[0]print(image_path, class_en[pred])def infer():backbone = MobileNetV2Backbone(last_channel=config.backbone_out_channels)head = MobileNetV2Head(input_channel=backbone.out_channels, num_classes=config.num_classes)network = mobilenet_v2(backbone, head)load_checkpoint(CKPT, network)for i in range(91, 100):infer_one(network, f'data_en/test/Cardboard/000{i}.jpg')
infer()导出AIR/GEIR/ONNX模型文件
导出AIR模型文件,用于后续Atlas 200 DK上的模型转换与推理。当前仅支持MindSpore+Ascend环境。
backbone = MobileNetV2Backbone(last_channel=config.backbone_out_channels)
head = MobileNetV2Head(input_channel=backbone.out_channels, num_classes=config.num_classes)
network = mobilenet_v2(backbone, head)
load_checkpoint(CKPT, network)input = np.random.uniform(0.0, 1.0, size=[1, 3, 224, 224]).astype(np.float32)
# export(network, Tensor(input), file_name='mobilenetv2.air', file_format='AIR')
# export(network, Tensor(input), file_name='mobilenetv2.pb', file_format='GEIR')
export(network, Tensor(input), file_name='mobilenetv2.onnx', file_format='ONNX')
相关文章:
昇思25天学习打卡营第15天|两个分类实验
打卡 目录 打卡 实验1:K近邻算法实现红酒聚类 数据准备 模型构建--计算距离 计算演示 模型预测 实验2:基于MobileNetv2的垃圾分类 任务说明 数据集 参数配置(训练/验证/推理) 数据预处理 MobileNetV2模型搭建 Mobile…...

实践:Redis6.0配置文件解读
详细解读redis配置文件 https://raw.githubusercontent.com/redis/redis/6.2/redis.conf Units 配置数据单位换算关系配置大小单位:当需要内存大小时,可以指定。开头定义了一些基本的度量单位,只支持bytes,不支持bit࿰…...

【Go系列】Go语言的网络服务
承上启下 我们既然知道了Go语言的语法,也了解到了Go语言如何协同工作机制。那么对于这样一款天生支持高并发的语言,它的用武之地自然而然的就是网络服务了。我们今天学学如何使用网络服务。 开始学习 Go语言使用网络服务 在Go语言中,使用网…...

CS110L(Rust)
1.Rust 语法总结 数值类型 有符号整数: i8, i16, i32, i64无符号整数: u8, u16, u32, u64 变量声明 声明变量: let i 0; // 类型推断let n: i32 1; // 显式类型声明 可变变量: let mut n 0; n n 1; 字符串 注意,let s: str "Hello world";…...
免费恢复软件有哪些?电脑免费使用的 5 大数据恢复软件
您是否在发现需要的文件时不小心删除了回收站中的文件?您一定对误操作感到后悔。文件永远消失了吗?还有机会找回它们吗?当然有!您可以查看这篇文章,挑选 5 款功能强大的免费数据恢复软件,用于 Windows 和 M…...

Flink History Server配置
目录 问题复现 History Server配置 HADOOP_CLASSPATH配置 History Server配置 问题修复 启动flink集群 启动Histroty Server 问题复现 在bigdata111上执行如下命令开启socket: nc -lk 9999 如图: 在bigdata111上执行如下命令运行flink应用程序 …...

ASPICE过程改进原则:确保汽车软件开发的卓越性能
"在汽车行业中,软件已经成为驱动创新和增强产品功能的核心要素。然而,随着软件复杂性的增加,确保软件质量、可靠性和性能成为了一项严峻的挑战。ASPICE标准的引入,为汽车软件开发提供了一套全面的过程改进框架,以…...

HDU1005——Number Sequence,HDU1006——Tick and Tick,HDU1007——Quoit Design
目录 HDU1005——Number Sequence 题目描述 超时代码 代码思路 正确代码 代码思路 HDU1006——Tick and Tick 题目描述 运行代码 代码思路 HDU1007——Quoit Design 题目描述 运行代码 代码思路 HDU1005——Number Sequence 题目描述 Problem - 1005 超时代码…...

uniapp form表单校验
公司的一个老项目,又要重新上架,uniapp一套代码,打包生成iOS端发布到App Store,安卓端发布到腾讯应用宝、OPPO、小米、华为、vivo,安卓各大应用市场上架要求不一样,可真麻烦啊 光一个表单校验,…...

构建RSS订阅机器人:观察者模式的实践与创新
在信息爆炸的时代,如何高效地获取和处理信息成为了一个重要的问题。RSS订阅机器人作为一种自动化工具,能够帮助我们从海量信息中筛选出我们感兴趣的内容。 一、RSS 是什么?观察者模式又是什么? RSS订阅机器人是一种能够自动订阅…...

芯片基础 | `wire`类型引发的学习
在Verilog中,wire类型是一种用于连接模块内部或模块之间的信号的数据类型。wire类型用于表示硬件中的物理连线,它可以传输任何类型的值(如0、1、高阻态z等),但它在任何给定的时间点上只能有一个确定的值。 wire类型通…...
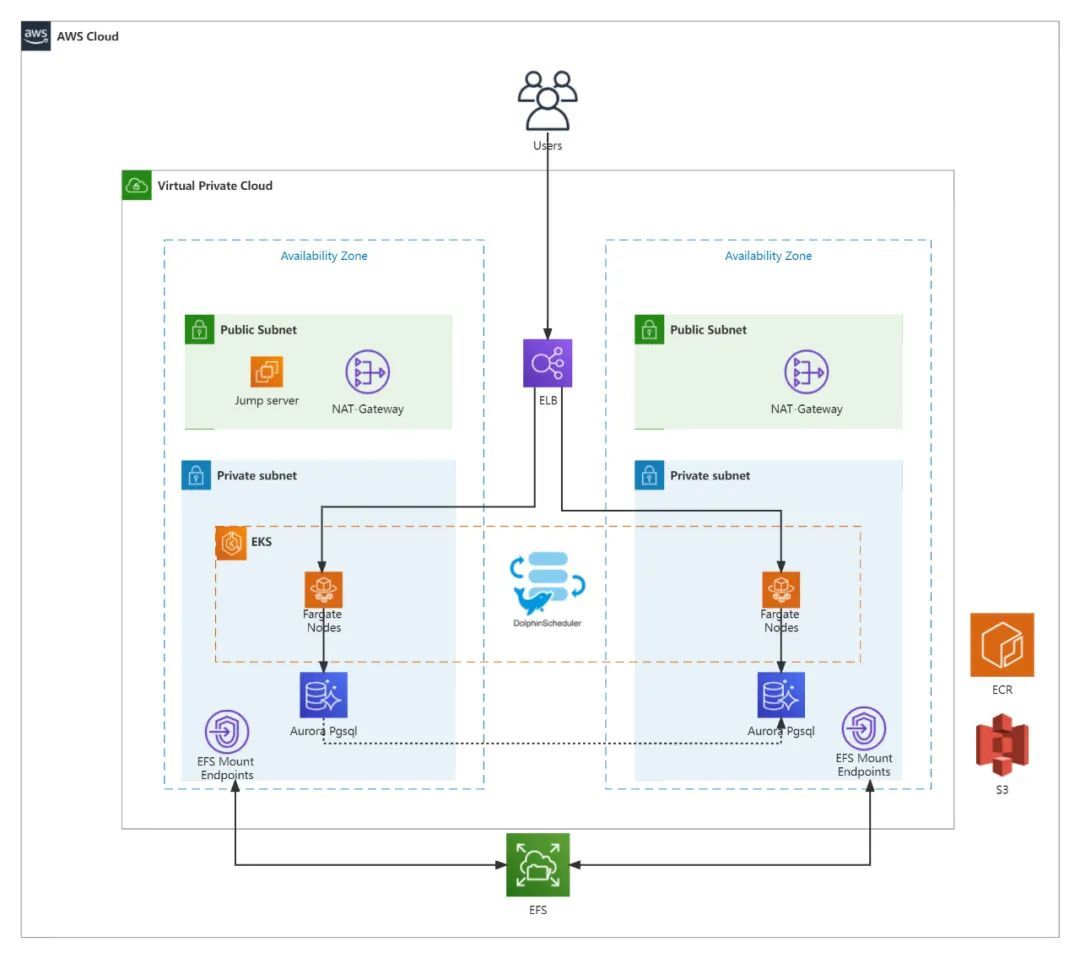
如何在AWS上构建Apache DolphinScheduler
引言 随着云计算技术的发展,Amazon Web Services (AWS) 作为一个开放的平台,一直在帮助开发者更好的在云上构建和使用开源软件,同时也与开源社区紧密合作,推动开源项目的发展。 本文主要探讨2024年值得关注的一些开源软件及其在…...

Quartus II 13.1添加新的FPGA器件库
最近需要用到Altera的一款MAX II 系列EPM240的FPGA芯片,所以需要给我的Quartus II 13.1添加新的器件库,在此记录一下过程。 1 下载所需的期间库 进入Inter官网,(Altera已经被Inter收购)https://www.intel.cn/content…...
)
【html】html的基础知识(面试重点)
一、如何理解HTML语义化 1、思考 A、在没有任何样式的前提下,将代码在浏览器打开,也能够结构清晰的展示出来。标题是标题、段落是段落、列表是列表。 B、便于搜索引擎优化。 2、参考答案 A、让人更容易读懂(增加代码可读性)。 B、…...

Java 网络编程(TCP编程 和 UDP编程)
1. Java 网络编程(TCP编程 和 UDP编程) 文章目录 1. Java 网络编程(TCP编程 和 UDP编程)2. 网络编程的概念3. IP 地址3.1 IP地址相关的:域名与DNS 4. 端口号(port)5. 通信协议5.1 通信协议相关的…...

STM32 | 看门狗+RTC源码解析
点击上方"蓝字"关注我们 作业 1、使用基本定时7,完成一个定时喂狗的程序 01、上节回顾 STM32 | 独立看门狗+RTC时间(第八天)02、定时器头文件 #ifndef __TIM_H#define __TIM_H#include "stm32f4xx.h"void Tim3_Init(void);void Tim7_Init(void);…...

filebeat,kafka,clickhouse,ClickVisual搭建轻量级日志平台
springboot集成链路追踪 springboot版本 <parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.6.3</version><relativePath/> <!-- lookup parent from…...

Django实战项目之进销存数据分析报表——第一天:Anaconda 环境搭建
引言 Anaconda是一个流行的Python和R语言的发行版,它包含了大量预安装的数据科学、机器学习库和科学计算工具。使用Anaconda可以轻松地创建隔离的环境,每个环境都可以有自己的一套库和Python版本,非常适合多项目开发。本文将指导你如何安装A…...

Linux部署Prometheus+Grafana
【Linux】PrometheusGrafana 一、Prometheus(普罗米修斯)1、Prometheus简述2、Prometheus特点3、Prometheus生态组件4、Prometheus工作原理 二、部署Prometheus1、系统架构2、部署Prometheus3、修改配置文件4、配置系统启动文件 三、部署 Node Exporter …...

【视频讲解】神经网络、Lasso回归、线性回归、随机森林、ARIMA股票价格时间序列预测|附代码数据
全文链接:https://tecdat.cn/?p37019 分析师:Haopeng Li 随着我国股票市场规模的不断扩大、制度的不断完善,它在金融市场中也成为了越来越不可或缺的一部分。 【视频讲解】神经网络、Lasso回归、线性回归、随机森林、ARIMA股票价格时间序列…...

测试微信模版消息推送
进入“开发接口管理”--“公众平台测试账号”,无需申请公众账号、可在测试账号中体验并测试微信公众平台所有高级接口。 获取access_token: 自定义模版消息: 关注测试号:扫二维码关注测试号。 发送模版消息: import requests da…...

Chapter03-Authentication vulnerabilities
文章目录 1. 身份验证简介1.1 What is authentication1.2 difference between authentication and authorization1.3 身份验证机制失效的原因1.4 身份验证机制失效的影响 2. 基于登录功能的漏洞2.1 密码爆破2.2 用户名枚举2.3 有缺陷的暴力破解防护2.3.1 如果用户登录尝试失败次…...
)
rknn优化教程(二)
文章目录 1. 前述2. 三方库的封装2.1 xrepo中的库2.2 xrepo之外的库2.2.1 opencv2.2.2 rknnrt2.2.3 spdlog 3. rknn_engine库 1. 前述 OK,开始写第二篇的内容了。这篇博客主要能写一下: 如何给一些三方库按照xmake方式进行封装,供调用如何按…...

Docker 运行 Kafka 带 SASL 认证教程
Docker 运行 Kafka 带 SASL 认证教程 Docker 运行 Kafka 带 SASL 认证教程一、说明二、环境准备三、编写 Docker Compose 和 jaas文件docker-compose.yml代码说明:server_jaas.conf 四、启动服务五、验证服务六、连接kafka服务七、总结 Docker 运行 Kafka 带 SASL 认…...

Qt Widget类解析与代码注释
#include "widget.h" #include "ui_widget.h"Widget::Widget(QWidget *parent): QWidget(parent), ui(new Ui::Widget) {ui->setupUi(this); }Widget::~Widget() {delete ui; }//解释这串代码,写上注释 当然可以!这段代码是 Qt …...

AtCoder 第409场初级竞赛 A~E题解
A Conflict 【题目链接】 原题链接:A - Conflict 【考点】 枚举 【题目大意】 找到是否有两人都想要的物品。 【解析】 遍历两端字符串,只有在同时为 o 时输出 Yes 并结束程序,否则输出 No。 【难度】 GESP三级 【代码参考】 #i…...

《通信之道——从微积分到 5G》读书总结
第1章 绪 论 1.1 这是一本什么样的书 通信技术,说到底就是数学。 那些最基础、最本质的部分。 1.2 什么是通信 通信 发送方 接收方 承载信息的信号 解调出其中承载的信息 信息在发送方那里被加工成信号(调制) 把信息从信号中抽取出来&am…...

【HTML-16】深入理解HTML中的块元素与行内元素
HTML元素根据其显示特性可以分为两大类:块元素(Block-level Elements)和行内元素(Inline Elements)。理解这两者的区别对于构建良好的网页布局至关重要。本文将全面解析这两种元素的特性、区别以及实际应用场景。 1. 块元素(Block-level Elements) 1.1 基本特性 …...

高防服务器能够抵御哪些网络攻击呢?
高防服务器作为一种有着高度防御能力的服务器,可以帮助网站应对分布式拒绝服务攻击,有效识别和清理一些恶意的网络流量,为用户提供安全且稳定的网络环境,那么,高防服务器一般都可以抵御哪些网络攻击呢?下面…...

AI书签管理工具开发全记录(十九):嵌入资源处理
1.前言 📝 在上一篇文章中,我们完成了书签的导入导出功能。本篇文章我们研究如何处理嵌入资源,方便后续将资源打包到一个可执行文件中。 2.embed介绍 🎯 Go 1.16 引入了革命性的 embed 包,彻底改变了静态资源管理的…...