NLP教程:1 词袋模型和TFIDF模型
文章目录
- 词袋模型
- TF-IDF模型
- 词汇表模型
词袋模型
文本特征提取有两个非常重要的模型:
-
词集模型:单词构成的集合,集合自然每个元素都只有一个,也即词集中的每个单词都只有一个。
-
词袋模型:在词集的基础上如果一个单词在文档中出现不止一次,统计其出现的次数(频数)。
两者本质上的区别,词袋是在词集的基础上增加了频率的维度,词集只关注有和没有,词袋还要关注有几个。
假设我们要对一篇文章进行特征化,最常见的方式就是词袋。
导入相关的函数库:
from sklearn.feature_extraction.text import CountVectorizer
实例化分词对象:
vectorizer = CountVectorizer(min_df=1)
>>> vectorizer CountVectorizer(analyzer=...'word', binary=False, decode_error=...'strict',dtype=<... 'numpy.int64'>, encoding=...'utf-8', input=...'content',lowercase=True, max_df=1.0, max_features=None, min_df=1,ngram_range=(1, 1), preprocessor=None, stop_words=None,strip_accents=None, token_pattern=...'(?u)\\b\\w\\w+\\b',tokenizer=None, vocabulary=None)
将文本进行词袋处理:
import jieba
from sklearn.feature_extraction.text import CountVectorizertxt="""
变压器停、送电操作时,应先将该变压器中性点接地,对于调度要求不接地的变压器,在投入系统后应拉开中性点接地刀闸。在中性点直接接地系统中,运行中的变压器中性点接地闸刀需倒换时,应先合上另一台主变压器的中性点接地闸刀,再拉开原来变压器的中性点接地闸刀。运行中的变压器中性点接地方式、中性点倒换操作的原则是保证该网络不失去接地点,采用先合后拉的操作方法。
变压器中性点的接地方式变化后其保护应相应调整,即是变压器中性点接地运行时,投入中性点零序过流保护,停用中性点零序过压保护及间隔零序过流保护;变压器中性点不接地运行时,投入中性点零序过压保护及间隔零序保护,停用中性点零序过流保护,否则有可能造成保护误动作。
"""
words = jieba.lcut(txt) # 使用精确模式对文本进行分词
vectorizer = CountVectorizer(min_df=1)#min_df 默认为1(int),表示“忽略少于1个文档中出现的术语”,因此,默认设置不会忽略任何术语,该参数不起作用X = vectorizer.fit_transform(words)#获取对应的特征名称:
print(vectorizer.get_feature_names())#feature_names可能不等于words
#词袋化
print(X.toarray())
词袋类似array([[0, 1, 1, 1, 0, 0, 1, 0, 1],
[0, 1, 0, 1, 0, 2, 1, 0, 1],
[1, 0, 0, 0, 1, 0, 1, 1, 0],
[0, 1, 1, 1, 0, 0, 1, 0, 1]]…)
但是如何可以使用现有的词袋的特征,对其他文本进行特征提取呢?我们定义词袋的特征空间叫做词汇表vocabulary:
vocabulary=vectorizer.vocabulary_
针对其他文本进行词袋处理时,可以直接使用现有的词汇表:
new_vectorizer = CountVectorizer(min_df=1, vocabulary=vocabulary)
CountVectorize函数比较重要的几个参数为:
- decode_error,处理解码失败的方式,分为‘strict’、‘ignore’、‘replace’三种方式。
- strip_accents,在预处理步骤中移除重音的方式。
- max_features,词袋特征个数的最大值。
- stop_words,判断word结束的方式。
- max_df,df最大值。
- min_df,df最小值 。
- binary,默认为False,当与TF-IDF结合使用时需要设置为True。
本例中处理的数据集均为英文,所以针对解码失败直接忽略,使用ignore方式,stop_words的方式使用english,strip_accents方式为ascii方式。
TF-IDF模型
文本处理领域还有一种特征提取方法,叫做TF-IDF模型(term frequency–inverse document frequency,词频与逆向文件频率)。TF-IDF是一种统计方法,用以评估某一字词对于一个文件集或一个语料库的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。
TF-IDF的主要思想是,如果某个词或短语在一篇文章中出现的频率TF(Term Frequency,词频),词频高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TF-IDF实际上是:TF * IDF。TF表示词条在文档d中出现的频率。IDF(inverse document frequency,逆向文件频率)的主要思想是:如果包含词条t的文档越少,也就是n越小,IDF越大,则说明词条t具有很好的类别区分能力。如果某一类文档C中包含词条t的文档数为m,而其他类包含t的文档总数为k,显然所有包含t的文档数n=m+k,当m大的时候,n也大,按照IDF公式得到的IDF的值会小,就说明该词条t类别区分能力不强。但是实际上,如果一个词条在一个类的文档中频繁出现,则说明该词条能够很好代表这个类的文本的特征,这样的词条应该给它们赋予较高的权重,并选来作为该类文本的特征词以区别与其他类文档。
示例
文档

中文停用词见
停用词
import jieba
import pandas as pd
import re
from sklearn.feature_extraction.text import CountVectorizer#词袋
from sklearn.feature_extraction.text import TfidfTransformer#tfidffile=pd.read_excel("文档.xls")# 定义删除除字母,数字,汉字以外的所有符号的函数
def remove_punctuation(line):line = str(line)if line.strip() == '':return ''rule = re.compile(u"[^a-zA-Z0-9\u4E00-\u9FA5]")line = rule.sub('', line)return line#停用词
def stopwordslist(filepath):try:stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]except:stopwords = [line.strip() for line in open(filepath, 'r', encoding='gbk').readlines()]return stopwords# 加载停用词
stopwords = stopwordslist("停用词.txt")#去除标点符号
file['clean_review']=file['文档'].apply(remove_punctuation)
# 去除停用词
file['cut_review'] = file['clean_review'].apply(lambda x: " ".join([w for w in list(jieba.cut(x)) if w not in stopwords]))#词袋计数
count_vect = CountVectorizer()
X_train_counts = count_vect.fit_transform(file['cut_review'])#tf-idf
tfidf_transformer = TfidfTransformer()
X_train_tfidf = tfidf_transformer.fit_transform(X_train_counts)
X_train_tfidf
(0, 123) 0.08779682150216786 表示第1篇文档词袋中第123个单词的tdidf为0.087

X_train_tfidf.toarray()

词汇表模型
词袋模型可以很好的表现文本由哪些单词组成,但是却无法表达出单词之间的前后关系,于是人们借鉴了词袋模型的思想,使用生成的词汇表对原有句子按照单词逐个进行编码。TensorFlow默认支持了这种模型:
tf.contrib.learn.preprocessing.VocabularyProcessor (max_document_length, min_frequency=0,vocabulary=None,tokenizer_fn=None)
其中各个参数的含义为:
- max_document_length:,文档的最大长度。如果文本的长度大于最大长度,那么它会被剪切,反之则用0填充。
- min_frequency,词频的最小值,出现次数小于最小词频则不会被收录到词表中。
- vocabulary,CategoricalVocabulary 对象。
- tokenizer_fn,分词函数。
假设有如下句子需要处理:
x_text =['i love you','me too'
]
基于以上句子生成词汇表,并对’i me too’这句话进行编码:
vocab_processor = learn.preprocessing.VocabularyProcessor(max_document_length)vocab_processor.fit(x_text)print next(vocab_processor.transform(['i me too'])).tolist()x = np.array(list(vocab_processor.fit_transform(x_text)))print x
运行程序,x_text使用词汇表编码后的数据为:
[[1 2 3 0]
[4 5 0 0]]
'i me too’这句话编码的结果为:
[1, 4, 5, 0]
相关文章:
NLP教程:1 词袋模型和TFIDF模型
文章目录 词袋模型TF-IDF模型词汇表模型 词袋模型 文本特征提取有两个非常重要的模型: 词集模型:单词构成的集合,集合自然每个元素都只有一个,也即词集中的每个单词都只有一个。 词袋模型:在词集的基础上如果一个单词…...

【开源 Mac 工具推荐之 2】洛雪音乐(lx-music-desktop):免费良心的音乐平台
旧版文章:【macOS免费软件推荐】第6期:洛雪音乐 Note:本文在旧版文章的基础上,新更新展示了一些洛雪音乐的新功能,并且描述更为详细。 简介 洛雪音乐(GitHub 名:lx-music-desktop )…...

AMEYA360:思瑞浦推出汽车级理想二极管ORing控制器TPS65R01Q
聚焦高性能模拟芯片和嵌入式处理器的半导体供应商思瑞浦3PEAK(股票代码:688536)发布汽车级理想二极管ORing控制器TPS65R01Q。 TPS65R01Q拥有20mV正向调节功能,降低系统损耗。快速反向关断(Typ:0.39μs),在电池反向和各种汽车电气瞬…...

简约的悬浮动态特效404单页源HTML码
源码介绍 简约的悬浮动态特效404单页源HTML码,页面简约美观,可以做网站错误页或者丢失页面,将下面的代码放到空白的HTML里面,然后上传到服务器里面,设置好重定向即可 效果预览 完整源码 <!DOCTYPE html> <html><head><meta charset="utf-8&q…...

Golang 创建 Excel 文件
经常会遇到需要导出数据报表的需求,除了可以通过 encoding/csv 导出 CSV 以外,还可以使用 https://github.com/qax-os/excelize 导出 xlsx 等格式的 excel,下面封装了一个方法,支持多 sheet 的 excel 数据生成,导出按需…...

探索GitHub上的两个革命性开源项目
在数字世界中,总有一些项目能够以其创新性和实用性脱颖而出,吸引全球开发者的目光。今天,我们将深入探索GitHub上的两个令人惊叹的开源项目:Comic Translate和GPTPDF,它们不仅改变了我们处理信息的方式,还极…...

SpringBoot框架学习笔记(三):Lombok 和 Spring Initailizr
1 Lombok 1.1 Lombok 介绍 (1)Lombok 作用 简化JavaBean开发,可以使用Lombok的注解让代码更加简洁Java项目中,很多没有技术含量又必须存在的代码:POJO的getter/setter/toString;异常处理;I/O…...

【ASP.NET网站传值问题】“object”不包含“GetEnumerator”的公共定义,因此 foreach 语句不能作用于“object”类型的变量等
问题一:不允许遍历 原因:实体未强制转化 后端: ViewData["CateGroupList"] grouplist; 前端加上:var catelist ViewData["CateGroupList"] as List<Catelogue>; 这样就可以遍历catelist了 问题二:…...

Stateflow中的状态转换表
状态转换表是表达顺序模态逻辑的另一种方式。不要在Stateflow图表中以图形方式绘制状态和转换,而是使用状态转换表以表格格式表示模态逻辑。 使用状态转换表的好处包括: 易于对类列车状态机进行建模,其中模态逻辑涉及从一个状态到其邻居的转换…...

结合Redis解决接口幂等性问题
结合Redis解决接口幂等性问题 引言正文收获 引言 该问题产生背景是根据需求描述,要求对已发布的课程能进行编辑修改,并且要求能进行回滚。 幂等性问题描述:对同一个接口并发请求产生的结果是不变的。 Get 请求以及 Delete 请求天然保证幂等…...

2024算力基础设施安全架构设计与思考(免费下载)
算网安全体系是将数据中心集群、算力枢纽、一体化大数据中心三个层级的安全需求进行工程化解耦,从国家安全角度统筹设计,通过安全 服务化方式,依托威胁情报和指挥协同通道将三层四级安全体系串联贯通,达成一体化大数据安全目标。 …...
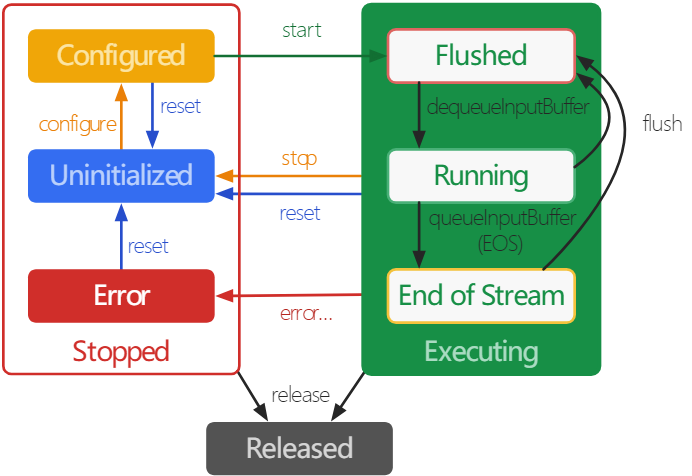
ExoPlayer架构详解与源码分析(15)——Renderer
系列文章目录 ExoPlayer架构详解与源码分析(1)——前言 ExoPlayer架构详解与源码分析(2)——Player ExoPlayer架构详解与源码分析(3)——Timeline ExoPlayer架构详解与源码分析(4)—…...

网络安全-等级保护制度介绍
一、等保发展历程 (1)1994国务院147号令 第一次提出等级保护概念,要求对信息系统分等级进行保护 (2)1999年GB17859 国家强制标准发布,信息系统等级保护必须遵循的法规 (3)2005年公安…...

【介绍下大数据组件之Storm】
🎥博主:程序员不想YY啊 💫CSDN优质创作者,CSDN实力新星,CSDN博客专家 🤗点赞🎈收藏⭐再看💫养成习惯 ✨希望本文对您有所裨益,如有不足之处,欢迎在评论区提出…...
)
React Hook 总结(React 萌新升级打怪中...)
1 useCallback useMemo 和 useCallback 接收的参数都是一样,都是在其依赖项发生变化后才执行,都是返回缓存的值,区别在于 useMemo 返回的是函数运行的结果,useCallback 返回的是函数。 当需要使用 useCallback 的情况通常包括以…...
Typora 1.5.8 版本安装下载教程 (轻量级 Markdown 编辑器),图文步骤详解,免费领取
文章目录 软件介绍软件下载安装步骤激活步骤 软件介绍 Typora是一款基于Markdown语法的轻量级文本编辑器,它的主要目标是为用户提供一个简洁、高效的写作环境。以下是Typora的一些主要特点和功能: 实时预览:Typora支持实时预览功能࿰…...

mac docker no space left on device
mac 上 docker 拉取镜像报错 Error response from daemon: write /var/lib/docker/tmp/docker-export-3995807640/b8464f52498789c4ebbc063d508f04e8d2586567fbffa475e3cd9afd3c5a7cf2/layer.tar: no space left on device解决: 增加 docker 虚拟磁盘大小。如下图...

单片机主控的基本电路
论文 1.复位电路 2.启动模式设置接口 3.VBAT供电接口 4.MCU 基本电路 5.参考电压选择端口...
)
【19】读感 - 架构整洁之道(一)
概述 《架构整洁之道》一书中有提到设计和架构的感念,它们究竟是什么?书是这么说的,它们的层次不一样,架构更“高层级”的说法,这类讨论一般都把“底层”的实现细节排除在外。而设计往往指代的具体的系统底层组织结构…...

多层全连接神经网络(三)---分类问题
问题介绍 机器学习中的监督学习主要分为回归问题和分类问题,我们之前已经讲过回归问题了,它希望预测的结果是连续的,那么分类问题所预测的结果就是离散的类别。这时输入变量可以是离散的,也可以是连续的,而监督学习从数…...

web vue 项目 Docker化部署
Web 项目 Docker 化部署详细教程 目录 Web 项目 Docker 化部署概述Dockerfile 详解 构建阶段生产阶段 构建和运行 Docker 镜像 1. Web 项目 Docker 化部署概述 Docker 化部署的主要步骤分为以下几个阶段: 构建阶段(Build Stage):…...

基于距离变化能量开销动态调整的WSN低功耗拓扑控制开销算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.算法仿真参数 5.算法理论概述 6.参考文献 7.完整程序 1.程序功能描述 通过动态调整节点通信的能量开销,平衡网络负载,延长WSN生命周期。具体通过建立基于距离的能量消耗模型&am…...

Oracle查询表空间大小
1 查询数据库中所有的表空间以及表空间所占空间的大小 SELECTtablespace_name,sum( bytes ) / 1024 / 1024 FROMdba_data_files GROUP BYtablespace_name; 2 Oracle查询表空间大小及每个表所占空间的大小 SELECTtablespace_name,file_id,file_name,round( bytes / ( 1024 …...

转转集团旗下首家二手多品类循环仓店“超级转转”开业
6月9日,国内领先的循环经济企业转转集团旗下首家二手多品类循环仓店“超级转转”正式开业。 转转集团创始人兼CEO黄炜、转转循环时尚发起人朱珠、转转集团COO兼红布林CEO胡伟琨、王府井集团副总裁祝捷等出席了开业剪彩仪式。 据「TMT星球」了解,“超级…...

大模型多显卡多服务器并行计算方法与实践指南
一、分布式训练概述 大规模语言模型的训练通常需要分布式计算技术,以解决单机资源不足的问题。分布式训练主要分为两种模式: 数据并行:将数据分片到不同设备,每个设备拥有完整的模型副本 模型并行:将模型分割到不同设备,每个设备处理部分模型计算 现代大模型训练通常结合…...
多光源(Multiple Lights))
C++.OpenGL (14/64)多光源(Multiple Lights)
多光源(Multiple Lights) 多光源渲染技术概览 #mermaid-svg-3L5e5gGn76TNh7Lq {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-3L5e5gGn76TNh7Lq .error-icon{fill:#552222;}#mermaid-svg-3L5e5gGn76TNh7Lq .erro…...

华为OD机考-机房布局
import java.util.*;public class DemoTest5 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseSystem.out.println(solve(in.nextLine()));}}priv…...

MySQL:分区的基本使用
目录 一、什么是分区二、有什么作用三、分类四、创建分区五、删除分区 一、什么是分区 MySQL 分区(Partitioning)是一种将单张表的数据逻辑上拆分成多个物理部分的技术。这些物理部分(分区)可以独立存储、管理和优化,…...
)
Leetcode33( 搜索旋转排序数组)
题目表述 整数数组 nums 按升序排列,数组中的值 互不相同 。 在传递给函数之前,nums 在预先未知的某个下标 k(0 < k < nums.length)上进行了 旋转,使数组变为 [nums[k], nums[k1], …, nums[n-1], nums[0], nu…...

第八部分:阶段项目 6:构建 React 前端应用
现在,是时候将你学到的 React 基础知识付诸实践,构建一个简单的前端应用来模拟与后端 API 的交互了。在这个阶段,你可以先使用模拟数据,或者如果你的后端 API(阶段项目 5)已经搭建好,可以直接连…...