<Linux>进程概念

文章目录
- 一、什么是进程
- 1.进程概念
- 2.进程描述 – PCB
- 3.task_struct内容分类
- 二、进程的基本操作
- 1.查看进程
- 2.结束进程
- 3.通过系统调用获取进程标示符
- 4.通过系统调用创建子进程(fork)
- 三、进程状态
- 1.普遍的操作系统状态
- 2.Linux操作系统状态
- 四、两种特殊的进程
- 1.僵尸进程
- 2.孤儿进程
- 五、进程优先级
- 1.基本概念
- 2.查看系统进程
- 3.PRI and NI
- 4.查看进程优先级信息
- 5.通过top命令修改进程优先级(ni)
- 六、进程的其他概念
- 七、进程切换
一、什么是进程
1.进程概念
课本概念:程序的一个执行实例,正在执行的程序等,或者进程就是被加载到内存中的程序,或者被运行起来的程序就叫做进程
内核观点:担当分配系统资源(CPU时间,内存)的实体。
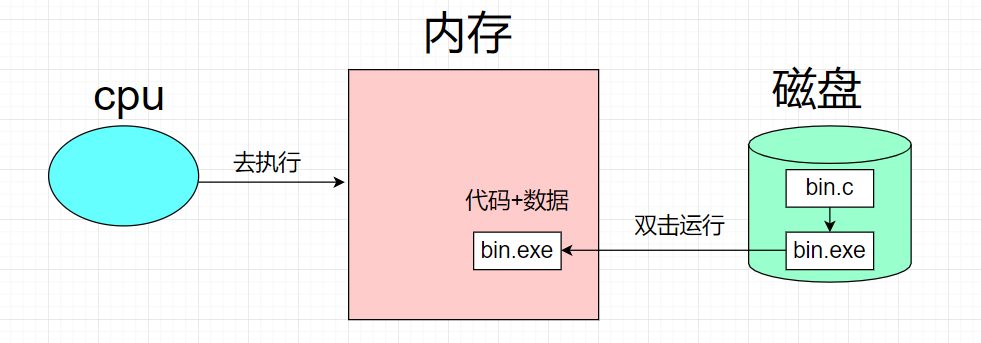
严格意义上的进程 = 进程对应的磁盘代码(可执行程序代码) + 该进程对应的内核数据结构(task_struct)
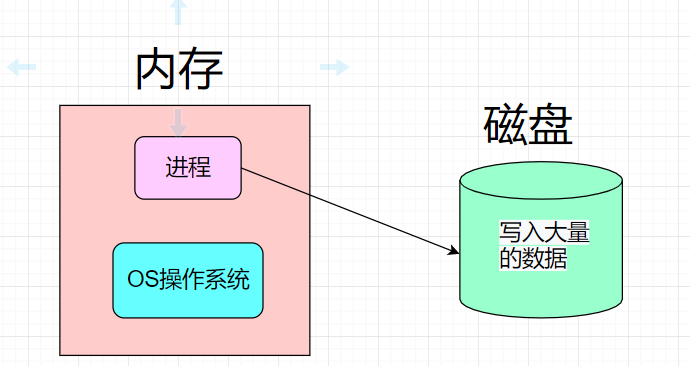
假设你在磁盘上写了一个名为bin.c的文件代码,最终经过编译链接形成bin.exe可执行程序。这个可执行程序是一个文件,当前存放在磁盘中,根据冯诺依曼体系得知,磁盘就是一个外设,你的程序最终要被CPU运行,要先从外设(磁盘)加载到内存中,而加载的过程就叫做此程序运行起来了,但是这不能说是进程,这个程序只是搬到内存,依旧是个程序。
2.进程描述 – PCB
操作系统里面可能同时存在大量被加载的进程 ,**操作系统要将所有的进程管理起来,而对进程的管理,本质就是对进程数据的管理,依旧是先描述,再组织。**下面分开讨论:
先描述:
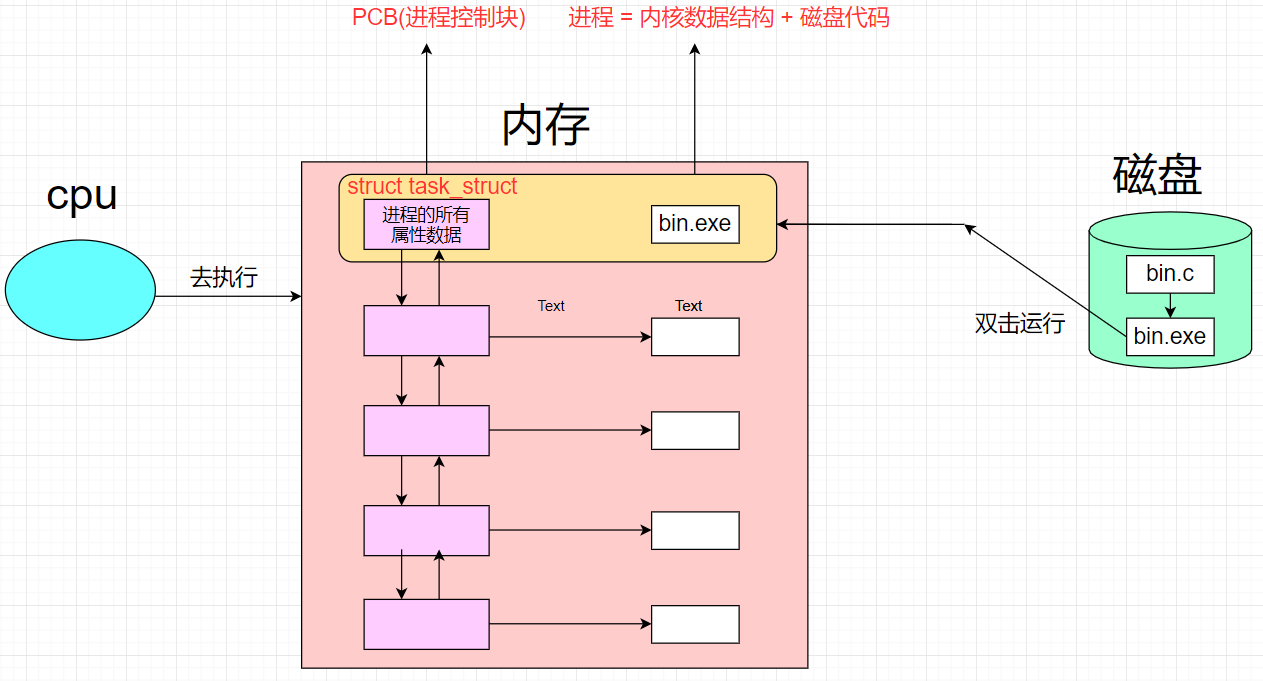
所以当一个程序加载到内存时,除了加载了代码和相关数据,操作系统还要为了管理该进程创建了对应的数据结构。而Linux操作系统描述进程是用一个叫task_struct的结构体,进程的所有属性数据全部放在这个结构体中(task_struct),每一个结构体指向对应的磁盘代码,当我们有多个进程的时候,也相应的要匹配多个task_struct结构体。此时描述好后还需要再组织起来:
再组织:
这里我们把所有的task_struct用双链表链接起来即可,此时对进程的管理就变成了对内核数据结构(PCB)的相关管理,也就是对链表进行增删查改转化成了对进程的管理。
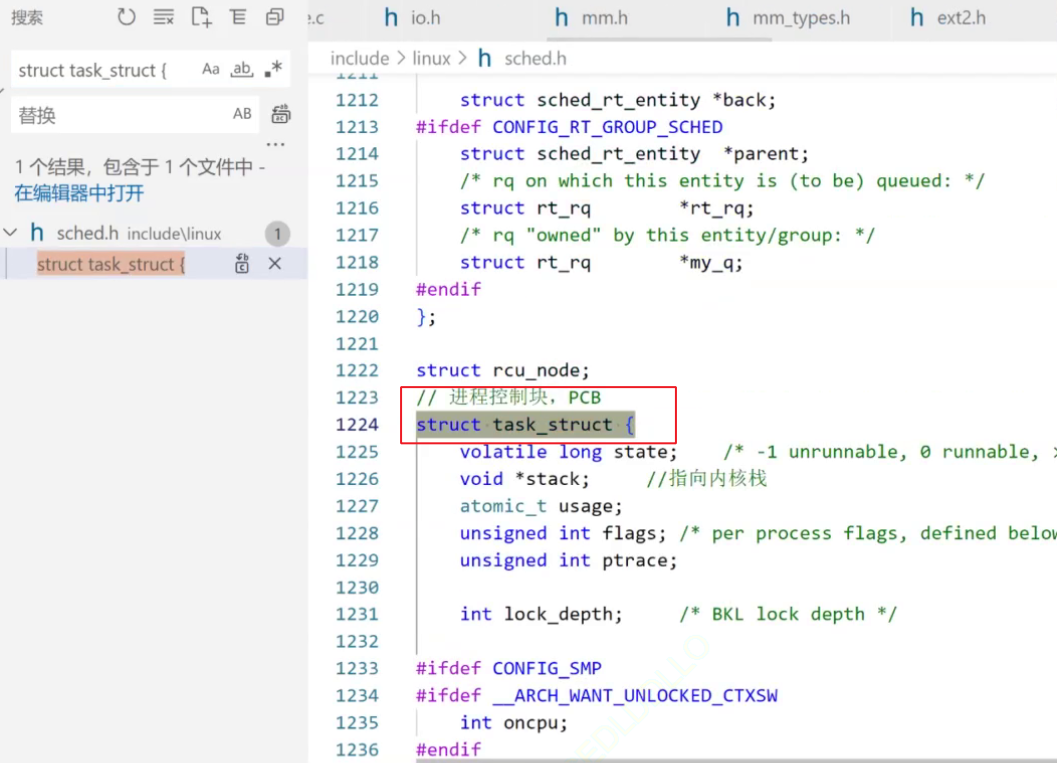
而在操作系统里我们把描述进程的结构体叫做PCB(process control block 进程控制块),而Linux下的进程控制块叫做struct task_struct,以此来描述进程结构体。task_struct是Linux内核的一种数据结构,它会被装载到RAM(内存)里并且包含进程的信息。通过内核结构体,我们能够创建出内核对象,将该结构和我们的代码和数据相关联起来,就完成了先描述,在组织的工作。
抽象出来可以用如下结构体来表示 (假设task_struct使用链表进行组织):
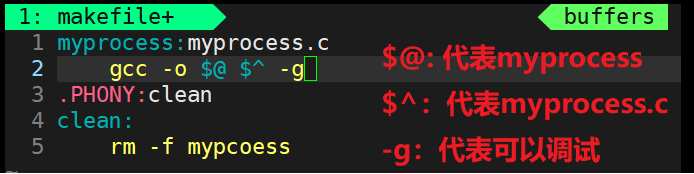
struct task_struct { //进程的所有属性... ...//进程对应的代码和数据的地址... ...//下一个进程的地址struct task_struct* next; };Linux系统中task_struct的代码:
注:关于 task_struct 的详细介绍,即其中包含了那些具体的进程属性,可以参考下面这篇文章:Linux中进程控制块PCB-------task_struct结构体结构 。
综上,我们就从操作系统内核的观点来理解进程:进程 = 内核数据结构 (task_struct) + 进程对应的磁盘代码。
3.task_struct内容分类
task_struct就是Linux当中的进程控制块,task_struct当中主要包含以下信息:
- 标示符: 描述本进程的唯一标示符,用来区别其他进程。
- 状态: 任务状态,退出代码,退出信号等。
- 优先级: 相对于其他进程的优先级。
- 程序计数器(pc): 程序中即将被执行的下一条指令的地址。
- 内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针。
- 上下文数据: 进程执行时处理器的寄存器中的数据。
- I/O状态信息: 包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表。
- 记账信息: 可能包括处理器时间总和,使用的时钟总和,时间限制,记账号等。
- 其他信息
二、进程的基本操作
1.查看进程
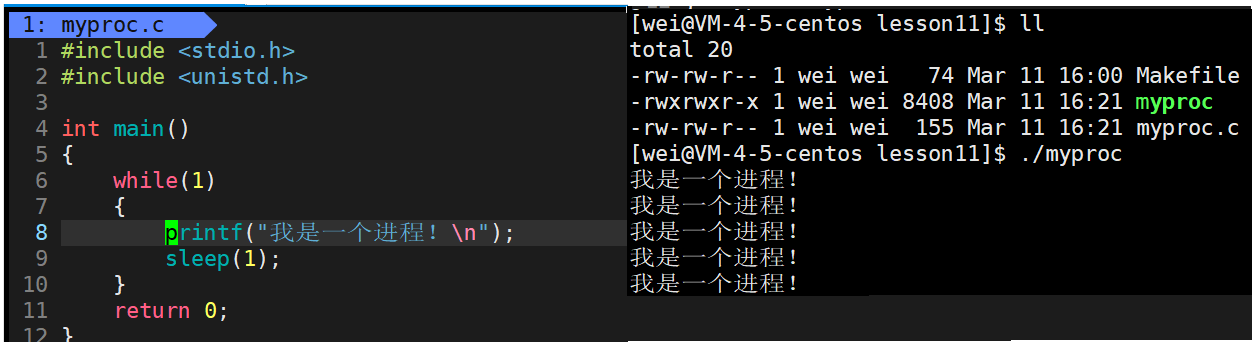
假设我现在生成了一个可执行程序myproc,它现在位于磁盘上,现在我们将程序运行起来,此时这个程序就变成了一个进程。
我们该如何查看现在的进程呢,主要有下列几种办法:
- 通过ps命令查看进程
- 通过proc查看
下面逐个分析:
通过ps命令查看进程
ps ajx | grep 'myproc'ps ajx命令会把你系统中所有的进程显示出来,随后我们使用管道命令组合grep为的是把名为myproc的进程显示出来,如下:
明明要的是myproc进程,为什么会出现grep的进程呢?
- 我们自己写的代码,编译成为可执行程序,启动之后就是一个进程,同样别人写的代码,启动之后也是一个进程。例如先前学到的ls、pwd、touch、grep、chgrp……指令,这些指令就是别人写的,存在目录/usr/bin/中, 这些指令在执行后也会成为进程,这也就是为什么上面会把grep显示出来。
如何只显示mytest进程呢?
- 输入下面的命令:
ps ajx | grep 'myproc' | grep -v grep此命令就是把带有grep字符的进程屏蔽掉,此时展现出来的就是我mytest进程。
通过proc查看
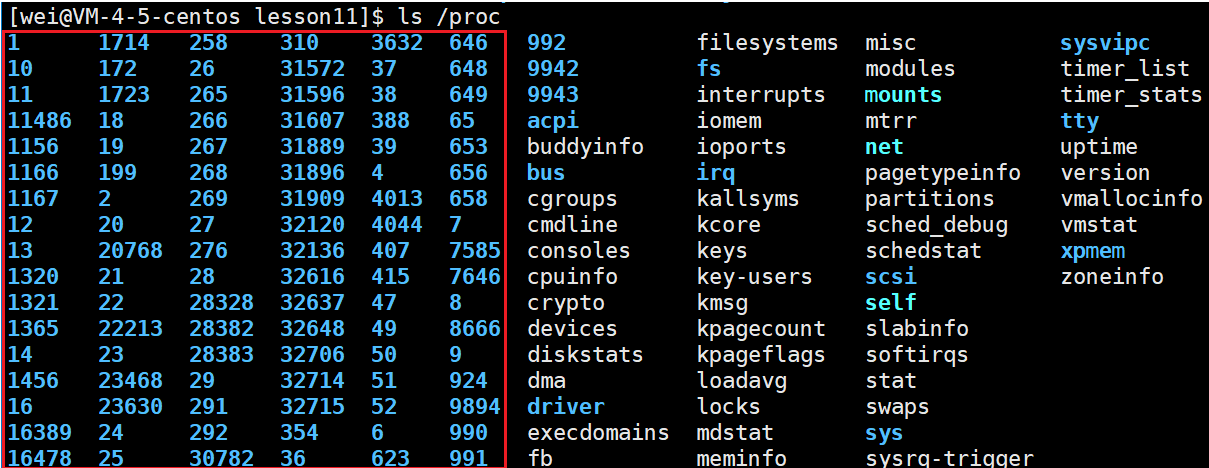
我们都清楚根目录下有很多的路径:
注意上面的proc目录,它是一个内存文件系统,里面放的是当前系统实时的进程信息。我们进入此目录看看:
每一个进程在系统中,都会存在一个唯一的标识符,就如同每个学生都有学号一样,而这个唯一标识符在linux称为pid(全称process id),而上面蓝色的数字即为进程的pid。
我们可以查看你显示出来的所有的title列名称,输入下面的指令:
ps ajx | head -1
这一行显示的就是所有的属性名,提取好了属性,下面继续往后显示mytest的进程,直接使用&&逻辑与操作:
ps ajx | head -1 && ps ajx | grep 'mytest' | grep -v grep
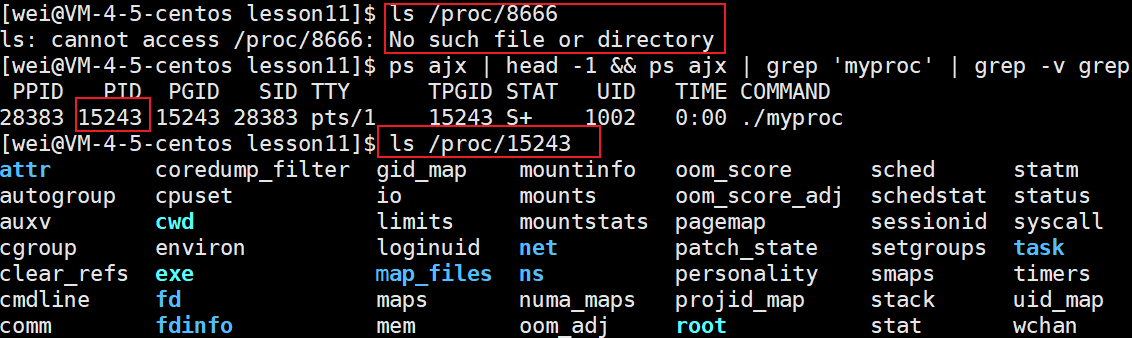
前面又得知proc存放的是当前系统实时的进程信息,现如今我们已然得知进程mytest的pid(8666),下面就在proc目录里面查询一下:
而如果我们 [Ctrl+C] 停止myproc的运行,根据proc是实时显示进程的性质,它此时就不会再显示进程myproc了:
而当我们再次运行起myproc程序时,再使用刚才的命令,结果如下:
此时会发现,先前的pid失效了,由此得知,重新启动程序就叫做一个新的进程,会给你重新分配一个pid。
补充1:如何理解当前路径?
下面输入这条指令:并从中截取这块内容。
ls /proc/15243 -al
- cwd表示进程当前的工作路径。
- exe表示进程对应的可执行程序的磁盘文件。
先前我们学习文件操作时知道,如果我用fopen创建一个文件,它默认是在当前路径,而当前路径指的就是当前进程所在路径,进程自己会维护。
补充2:pid,当前路径,这些都是进程的内部属性。都在进程的进程控制块PCB(task_struct)结构体中!!!








2.结束进程
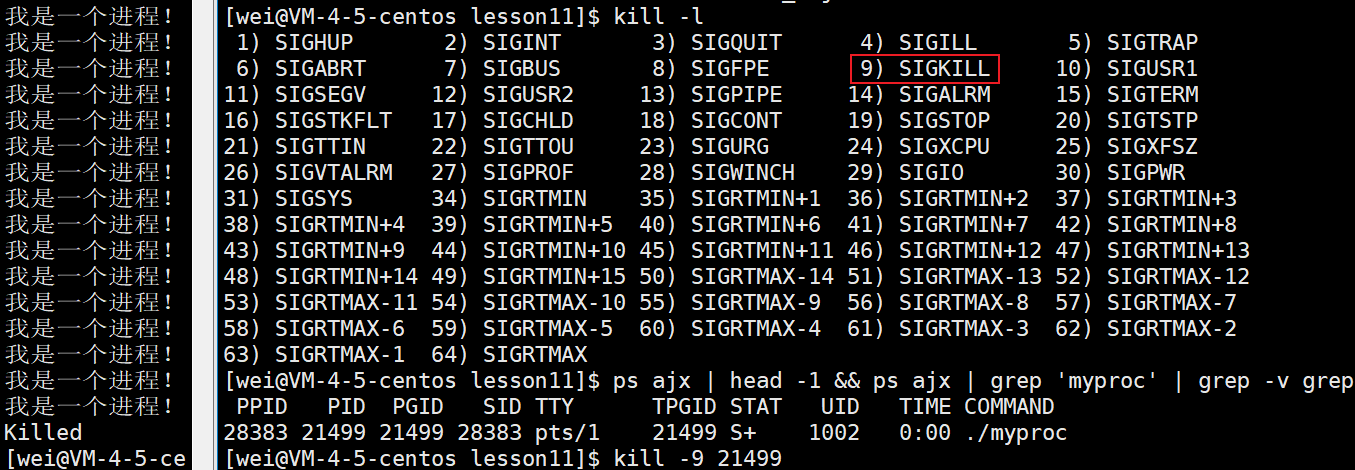
对于一个进程来说,我们可以使用 [Ctrl + c] 来结束进程,也可以使用 kill 命名,指定 -9 选项来结束。
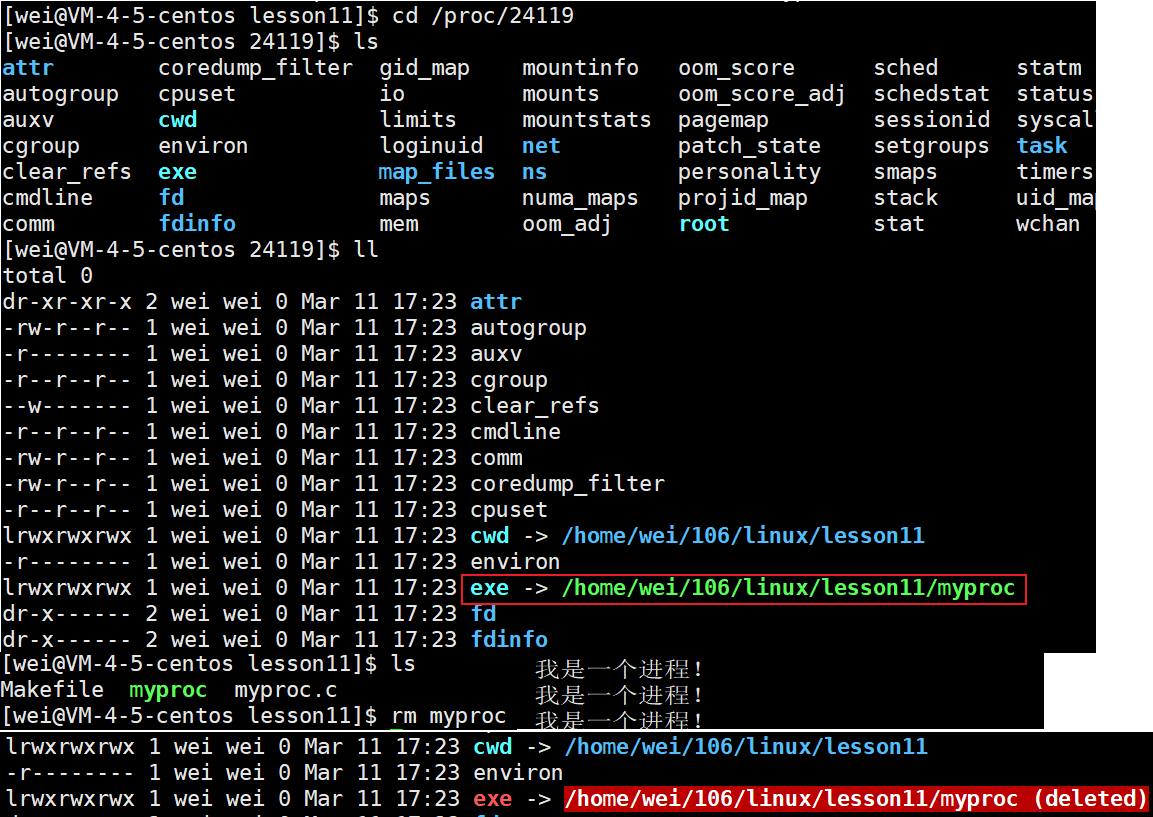
这里我们可以进入进程PID,我们这里思考一个问题:当我们删掉正在执行进程对应的可执行文件的时候,进程是否会停止/退出?
答案是不会,我们知道可执行文件被加载到内存中,CPU会执行相应的代码,形成进程。进程形成时,不会被对应的可执行文件所影响。但是如果我们【Ctrl + c】停止进程,这时进程的PID已经消失了。
3.通过系统调用获取进程标示符
我们可以通过使用操作系统给我们提供的系统调用接口 getpid() 与 getppid() 来获取进程id和父进程id (进程ID是一个进程的唯一标识)。这里的返回值pid_t,大家把它当做int就行,打印的时候使用%d即可。
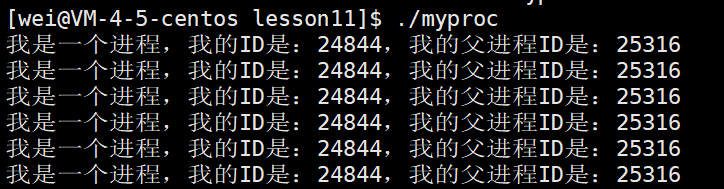
我们通过如下程序打印进程和父进程ID:
#include <stdio.h> #include <unistd.h> #include <sys/types.h>int main() {while(1){printf("我是一个进程,我的ID是:%d,我的父进程ID是:%d\n", getpid(), getppid());sleep(1);}return 0; }运行该程序,即可获得该进程的pid和ppid:
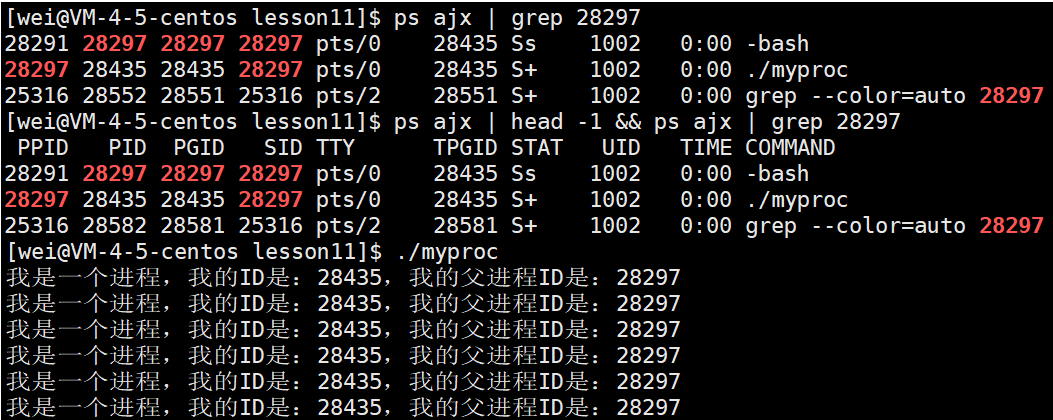
我们下面可以通过ps命令查看该进程的相关信息
补充1:如何杀掉进程?
- 1、按下【Ctrl + c】
- 2、使用命令:【kill -9 pid】
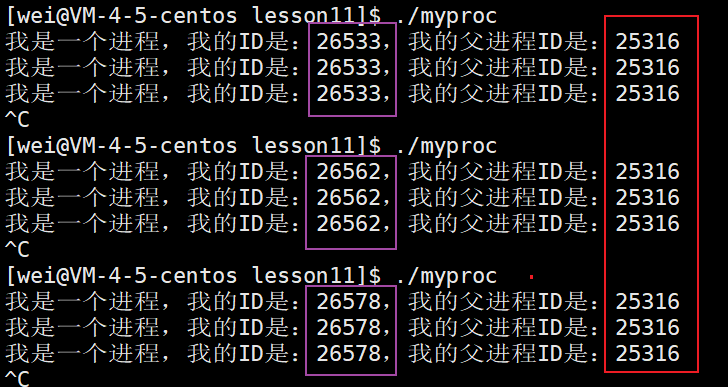
补充2:父进程ppid是不会变的
前面我们得知,我们每次重新运行一个进程,其pid是会不断变化的,可是父进程ppid是不会变的。这是因为进程的代码和数据需要重新从磁盘中加载;但是它的父进程id是通过 bash 来执行。bash是shell外壳,并不会变化。
我们可以输入下面的指令来查看这个父进程到底是什么:
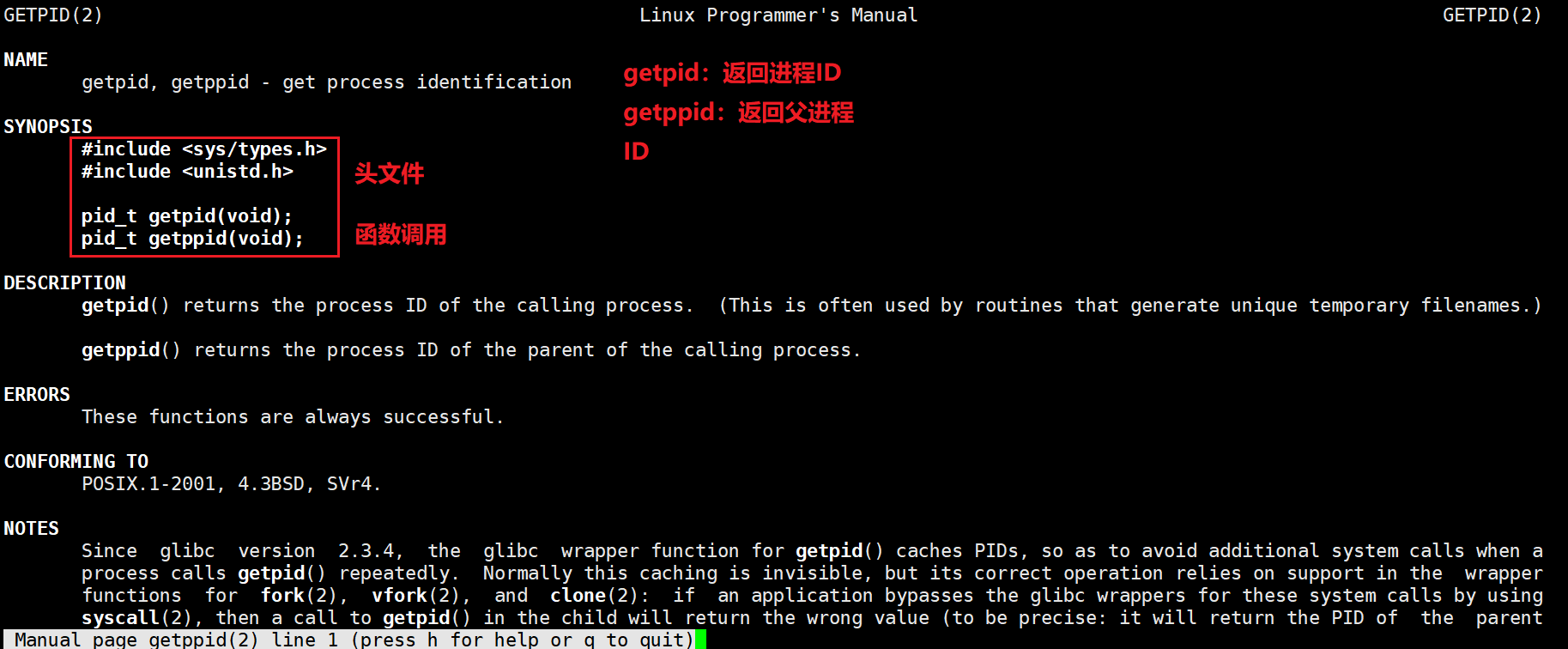
ps ajx | head -1 && ps ajx | grep 28297
图中可以看出父进程28297就是一个bash,即 shell 外壳,这也侧面证实了我们在 Linux权限管理 中提到的结论:shell 为了防止自身崩溃,并不会自己去执行指令,而是会派生子进程去执行。几乎我们在命令行上所执行的所有的指令,都是bash进程的子进程!

4.通过系统调用创建子进程(fork)
fork函数是用来创建子进程的,它有两个返回值:
- 返回成功的话,把子进程的pid返回给父进程,给子进程返回0
- 失败的话,-1返回给父进程。不创建子进程
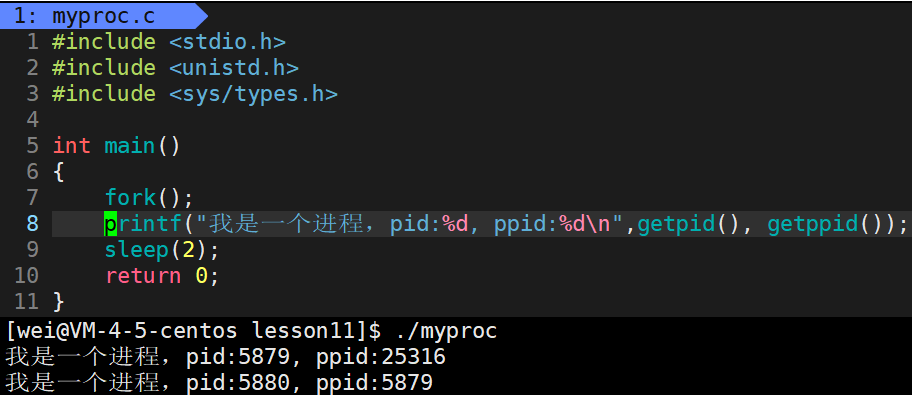
因为其有两个返回值,这导致我一个printf语句运行后,会输出两个,并且返回的值一个为子进程的pid给父进程,一个0给子进程。
根据上面得知,既然父进程和子进程获取到fork函数的返回值不同,那么我们就可以据此来让父子进程执行不同的代码,从而做不同的事。示例:
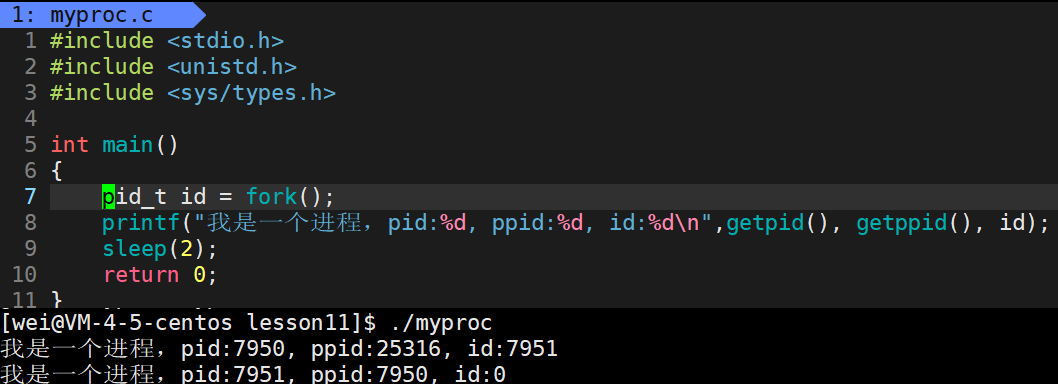
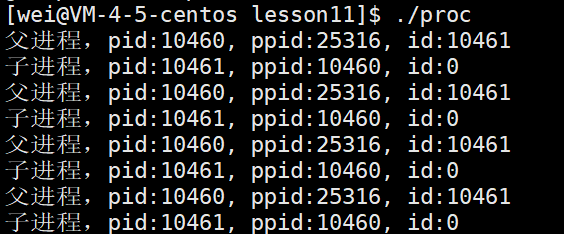
#include <stdio.h> #include <unistd.h> #include <sys/types.h>int main() {pid_t id = fork();if(id == 0){while(1){printf("子进程,pid:%d, ppid:%d, id:%d\n", getpid(), getppid(), id);sleep(1);}}else if(id > 0){while(1){printf("父进程,pid:%d, ppid:%d, id:%d\n", getpid(), getppid(), id);sleep(1);}}else {printf("子进程创建失败!\n");}return 0; }
- 由上图得知,子进程为10461,父进程为10460,父进程的父进程为25316,此外,我们还可以发现这里的if 和 else语句竟然可以同时执行。
总结:
- fork之后,父进程和子进程会共享代码,一般都会执行后续的代码,这就是为什么printf会打印两次的原因。
- fork之后,父进程和子进程返回值不同,可以通过不同的返回值,判断,让父子执行不同的代码块。
补充1:fork()为什么给父进程返回子进程的pid,给子进程返回0?
- 父进程必须有标识子进程的方案,这个方案就是fork之后给父进程返回子进程的pid!
- 子进程最重要的是要知道自己被创建成功了,因为子进程找父进程成本非常低,只需要getppid()即可,所以只需要给子进程返回0即可。
补充2:为什么fork会返回两次?
- fork是用来创建子进程,则会导致系统多了一个进程(task_struct+子进程的代码和数据),子进程的task_struct对象内部的数据大部分从父进程继承下来的。子进程和父进程执行同样的代码,fork之后,父子进程代码共享,而数据要各自独立。虽然代码共享,但是可以让不同的返回值执行不同的代码。
- 调用一个函数,当这个函数准备return的时候,这个函数的核心功能已经完成,子进程已经被创建了,并将子进程放入运行队列,现在父进程和子进程既然都存在,并且代码共享,那么当然return要返回两次。自然就有两个返回值。
三、进程状态
1、 什么是进程状态?
我们知道,一个程序被加载到内存变成进程之后,操作系统要对该进程进行管理,即为其创建对应的PCB对象。而进程状态,本质上就是PCB内部的一个整形变量,不同的整形值就对应不同的进程状态。
2、进程有什么状态?
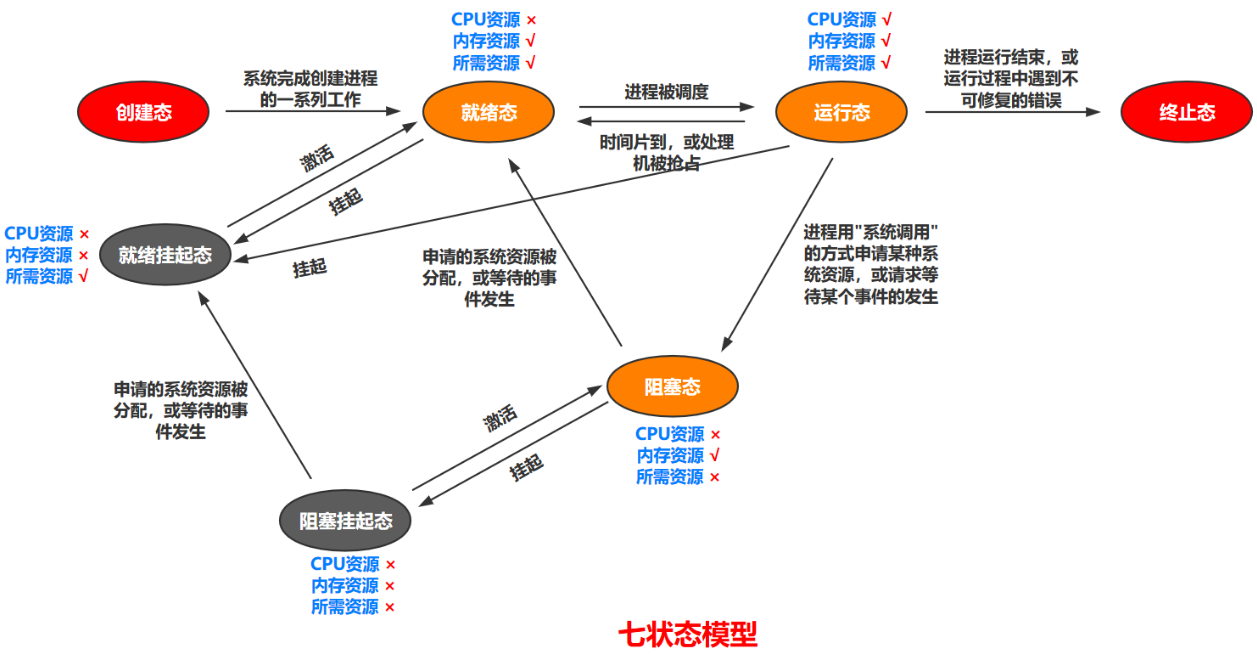
状态反映进程执行过程的变化。这些状态随着进程的执行和外界条件的变化而转换。在三态模型中,进程状态分为三个基本状态,即运行态,就绪态,阻塞态。在五态模型中,进程分为新建态、终止态,运行态,就绪态,阻塞态,在七态模型中,进程分为新建态、终止态,运行态,就绪态,阻塞态,就绪挂起态,阻塞挂起态
但是在普遍的操作系统层面,即站在操作系统学科的角度来说,进程状态远远不止上面几种状态,大致可能有:运行、挂起、阻塞、新建、就绪、等待、挂机、死亡。其中最重要也是最难理解的几种状态分别是:运行、阻塞、挂起。
下面我将从操作系统层面上的进程状态以及细化到Linux层面上的进程状态来综合讲解这三种状态:
1.普遍的操作系统状态
下面我将针对运行、终止、堵塞、挂起这四个状态来进行讲解,之后我们就能对这幅图有个清晰的认知。
1、进程运行:
如果我们申请CPU资源,暂时无法得到满足,因为资源永远是少数的,CPU只有一个,你在申请这块资源,可是其它进程可能也在申请这块资源,如果给了A,那么B和C该怎么办呢?所以我们在申请的时候是需要排队的,我们把此队列称为运行队列。因此我们申请其它慢设备资源也是需要排队的。
因为内存的容量有限,而需要运行的程序非常多,操作系统为了更好分配CPU和各种硬件资源,并且更好地调度进程。操作系统为了合理分配CPU以及各种硬件资源,也为了更好的调度各个进程,会为CPU创建一个进程队列,为每一个硬件都创建一个等待队列;而让某一个进程处于运行状态本质上就是将该进程对应的PCB放入CPU的运行队列中,然后再将PCB中维护进程状态的变量修改为相应的值,比如0。因为进程PCB里面有进程的各种属性,以及进程对应的代码和数据的地址,所以CPU从运行队列中取出PCB后,可以根据该PCB来得到进程的各种数据和指令,然后执行相应运算。
- 总结:所以进程处于运行状态并不一定意味着该进程此刻正在被运行,只要该进程处于CPU的运行队列中即可。(注:CPU是纳秒级的芯片,运算速度非常快,所以只要进程处于CPU的运行队列中,我们就可以认为该进程正在被运行)
2、进程终止:
这个进程还在,只不过永远不运行了,随时等待被释放!进程都终止了,为什么不立马释放对应的资源,而要维护一个终止状态?因为即使进程终止了,但是你操作系统并不能立马就来释放这个进程,就好比如你在一家餐厅的某个位置吃饭,当你吃饭走人后,这个位置能再次被别人使用吗,当然不能,因为服务员还没来得及收拾你的残渣。所以既然你已经终止了,那么就需要一直维持着终止状态,以此告诉操作系统等你不忙了赶紧来把我释放掉,这就是随时等待被释放。
3、进程阻塞:
和CPU一样,我们计算机中的各种硬件也是十分有限的,但是需要使用这些硬件资源的进程却有很多,比如很多进程都需要向磁盘中写入数据,又或者要通过网卡发送数据,但是一个磁盘或者一个网卡在同一个时刻只能为一个进程提供服务,那么如果此时有其他运行中的进程需要使用该硬件资源,操作系统就会将该进程的PCB放入硬件的等待队列中,等待硬件来为我提供服务。
上面这种由于访问某种硬件需要进行等待的状态就被称为阻塞状态,阻塞状态本质上就是将进程的PCB从CPU的运行队列中剥离出来,放入硬件的等待队列中,然后将PCB中维护进程状态的变量修改为相应的值,比如1;待该进程获得对应的对应的硬件资源以后,再将该进程放入CPU的运行队列中。
总结:
并不是只有等待硬件资源进程才会处于阻塞状态,一个进程等待另一个进程就绪、一个进程等待某种软件资源就绪等都会处于阻塞状态。
当进程访问某些资源(磁盘、网卡……)时,如果该资源暂时没有准备好,或者正在给其它进程提供服务,这时,当前进程要从runqueue移除,并且将当前进程放入对应设备的描述结构体中的等待队列。而这件工作是由操作系统完成的。
当我们的进程在等待外部资源的时候,该进程的代码,就不会被执行,此时我们作为用户看到的现象就是我的进程卡住了(类似于你下载大型软件,看视频会卡一样),我们把这样的状态就称之为进程堵塞。
通俗说就是进程等待某种资源(非CPU),资源没有就绪的时候,进程需要在该资源的等待队列中进行排队,此时进程的代码并没有运行,进程所处的状态就叫堵塞。
4、进程挂起:
上面我们学习了阻塞状态,处于阻塞状态的进程由于需要等待某种资源,所以它对应的代码和数据在短期内并不会被执行,此时它们仍存在在内存中就相当于浪费了内存资源;而如果当前操作系统处于高IO的情况下,内存空间不足,操作系统就会选择将这些处于阻塞状态的进程对应的代码和数据拷贝一份存放到磁盘中,然后释放内存中那一份,从而节省出内存空间。
上面这种由于内存空间不足,操作系统将在等待资源的进程对应的代码数据放到磁盘中以节省内存空间的状态就被称为挂起状态;挂起状态不会移动进程的PCB,只会移动进程对应的代码和数据。
- 总结:如上,当把该进程的代码和数据置换到磁盘中后,释放掉这块空间,此时内存就多出来了这块空间的容量,可以短期内让其它进程使用,因此操作系统通过这样的方式可以短暂的让进程只残留PCB,剩下的代码和数据全部置换到磁盘上(swap分区),此时这样的进程就叫做进程挂起!!!
- 注意:挂起进程并不是释放进程,因为该进程对应的PCB仍然处于某硬件的等待队列中,当该进程获得对应的资源以后,操作系统仍然可以将该进程对应的代码和数据从磁盘加载到内存中来继续运行,其本质是对内存数据的唤入唤出,同时阻塞不一定挂起,挂起也不一定阻塞,也可能是新建挂起、就绪挂起,甚至是运行挂起。
2.Linux操作系统状态
上面我们谈到的都是理论上的操作系统中进程的状态,下面我们来学习具体Linux操作系统中进程的状态。
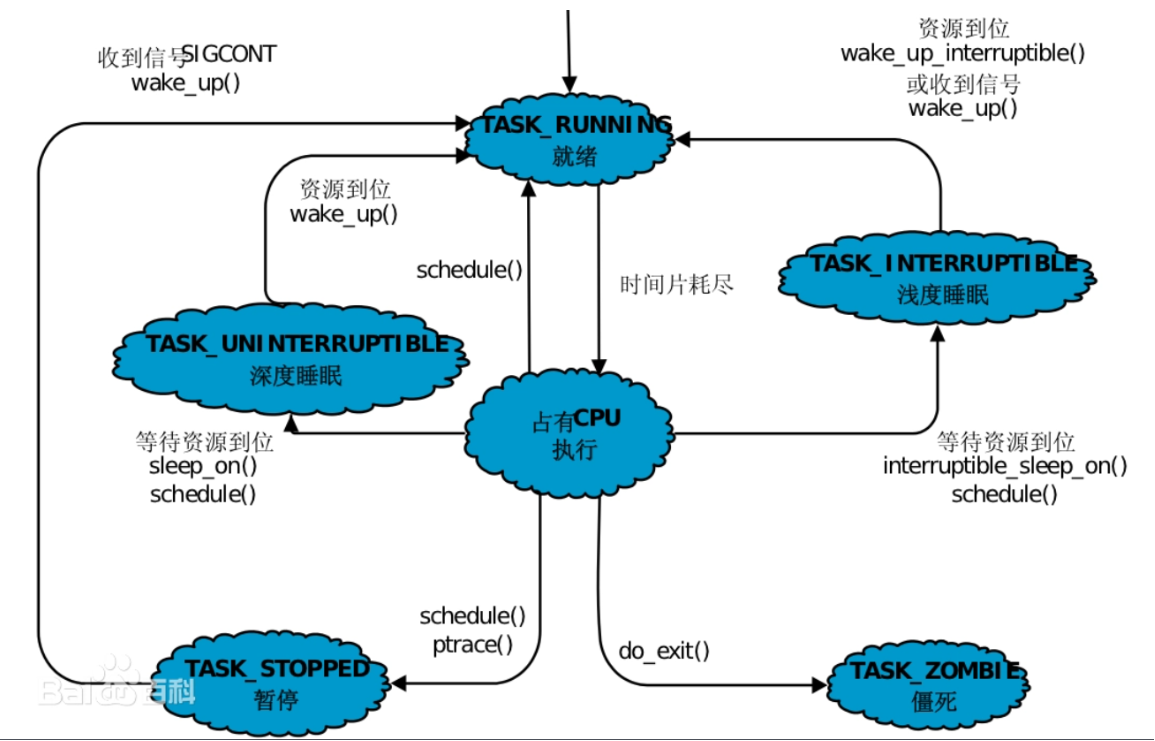
Linux内核源代码中对进程状态的定义如下:
/*
* The task state array is a strange "bitmap" of
* reasons to sleep. Thus "running" is zero, and
* you can test for combinations of others with
* simple bit tests.
*/
static const char * const task_state_array[] = {"R (running)", /* 0 */"S (sleeping)", /* 1 */"D (disk sleep)", /* 2 */"T (stopped)", /* 4 */"t (tracing stop)", /* 8 */"X (dead)", /* 16 */"Z (zombie)", /* 32 */
};
可以看到,Linux中进程一共有七种状态,分别是运行、睡眠、深度睡眠 (磁盘休眠)、暂停、追踪暂停、死亡、僵尸。
1、运行状态 ®
- 一个进程处于运行状态(running),并不意味着进程一定在运行中,它表明进程要么是在运行中要么在运行队列里。
示例:
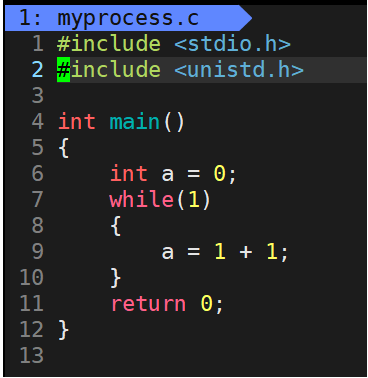
当我们编译运行此程序后,进入死循环,此程序没有访问其它外设资源(读文件、读磁盘……)此进程一直在cpu的队列里,下面来查看此进程的状态:
- 综上,只要你的代码不访问外设,只访问cpu资源,只要能跑起来,那么就是R状态。
2、(浅度)睡眠状态 (S)
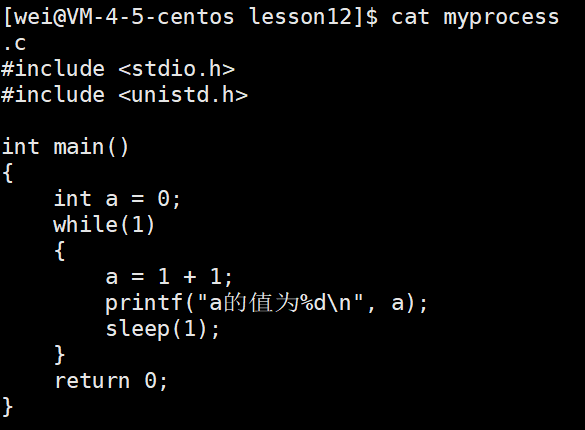
示例:
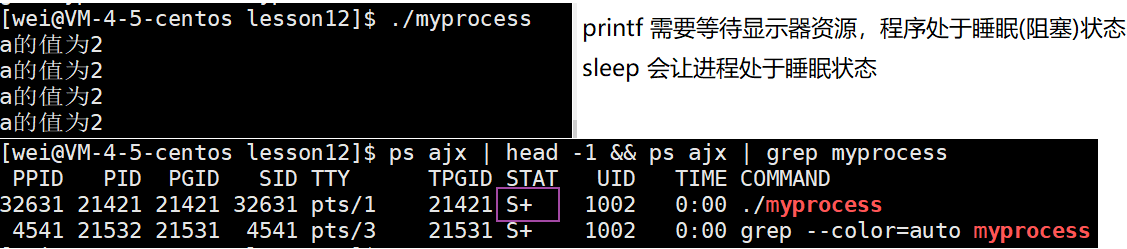
我们运行此代码,并查看此进程的状态:
我明明已经运行了此进程,可为什么显示的会是S睡眠状态呢?
- 这里执行了printf语句,想要打印信息,这就需要访问外设(显示器),但是想占用显示器的不止你一个,其它进程可能正在使用,操作系统就会把你的进程PCB放到显示器的等待队列里面,当轮到你访问的时候,操作系统再把你唤醒,此时你就可以打印了,这就是S睡眠状态,对应的就是上文操作系统层面上的阻塞状态。
- 总结:外设的速度是要远远低于CPU的,所以我们可以发现,虽然 process 也在执行加法运算,但是我们每次查询时进程基本都处于阻塞状态,因为进程99%的时间都在等待硬件资源就绪,只有1%的时间在进行加法运算以及执行打印代码。
S睡眠状态又叫做浅度睡眠和可中断睡眠。
- 浅度睡眠:当进程处于S状态,它可以随时被操作系统唤醒。
- 可中断睡眠:当进程处于S状态,它可以被你随时kill杀掉。
3、深度睡眠状态 (D)
- D状态也是一种阻塞状态,它也是要让进程去等待某种资源,资源不就绪,那么此进程就处于某种等待状态。一般而言,Linux中,如果我们等待的是磁盘资源,我们进程阻塞所处的状态就是D。
下面对D状态进行深度剖析:
- 假设我内存上一个500MB大小的进程,要写到磁盘上,我们假设磁盘写入这500MB的数据耗费时间很长(实际非常快),此时该进程只能处在内存里默默等待磁盘完工,此时的进程就是S状态,不会被运行,等待磁盘资源就绪,可是在进程等待的过程中,内存中的进程越来越多,操作系统也越来越忙,假设操作系统在扫描所有进程的时候路过此S状态的进程,见此进程啥事不干,于是把它kill杀掉(一般服务器压力过大,OS是会终止用户进程的!!),可是当磁盘写完数据回来(无论写入成功与否)呼叫此进程的时候发现进程竟然不见了。
我们假设上述磁盘读取的500MB数据很重要,可是无论磁盘读取成功与否,此数据都失效了,因为对应的进程被OS杀掉了,那么这个锅到底谁来背呢?
- 对于操作系统:OS本身的权限就是管理好系统,如果内存不够,挂起进程也无济于事,为了防止操作系统崩溃,OS有权利去自主的杀掉任何进程,尤其是处于等待队列的进程。
- 对于被kill的进程:此进程就是把数据给磁盘,进程也确实需要等待磁盘反馈结果,可是等待的过程中莫名其妙被OS杀掉了,所以与进程也无关。
- 对于磁盘:磁盘在这里扮演的角色就是一个跑腿的,进程需要把数据写到磁盘上,那磁盘听从指令慢慢写入,这就需要进程在内存等待磁盘的反馈结果,结果数据写入失败,最后发现进程无响应,磁盘也需要写入其他数据,既然无响应,磁盘就把数据丢弃了。
综上,OS、进程、磁盘这三者好像都没有错误,为了防止这种情况的发生,Linux设计出了深度睡眠 (D) 状态,处于深度睡眠状态的进程既不能被用户杀掉,也不能被操作系统杀掉,只能通过断电,或者等待进程自己醒来,也就是不可被中断睡眠。此时进程在等待磁盘的过程中,就由浅度睡眠S演化为深度睡眠D,具有了不可被中断属性,自然就不会被OS误杀了。而要彻底解决掉D状态,唯有关机重启和拔电源能够解决。
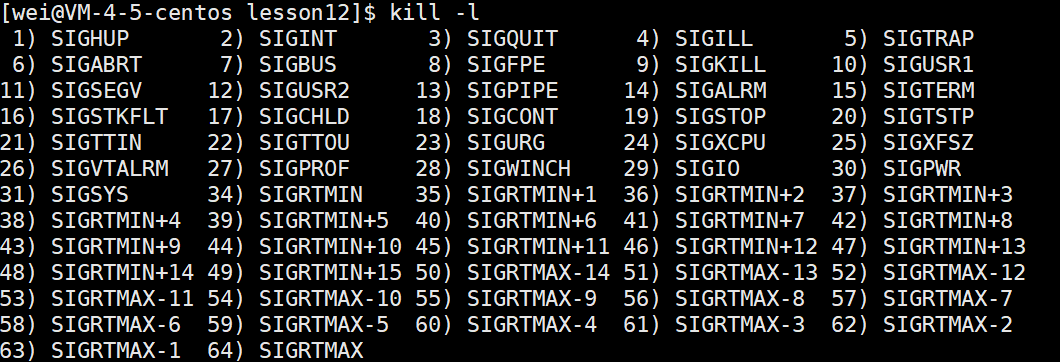
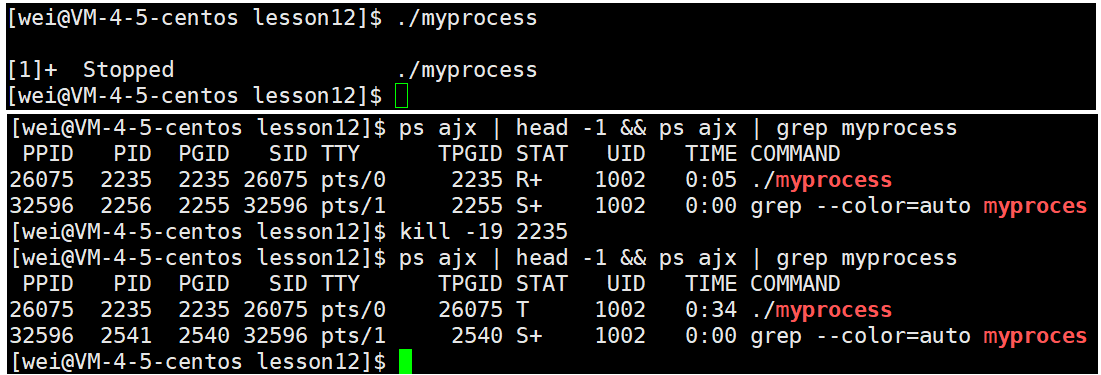
4、追踪暂停状态 (T/t)
- 在Linux中,我们可以通过发送 SIGSTOP 信号给进程来停止(T)进程。这个被暂停的进程可以通过发送 SIGCONT 信号让进程继续运行。
我们可以通过如下命令去查看 SIGSTOP 信号:
kill -l
暂停的意思是你本来是运行的,后来让你暂停了,假设现在有一个正在运行且不断循环的进程,我们对此进程发送SIGSTOP也就是第19个信号,该进程就进入到了暂停状态。
kill -19 pid
我们再对该进程发送SIGCONT也就是第18个信号,该进程就继续运行。
kill -18 pid
我们将 process 暂停或者 continue 之后,进程状态前面的 + 号消失了;其实,进程状态后面的 + 号代表着一个进程是前台进程,没有 + 号就代表是后台进程;对于前台进程,我们可以使用【Ctrl + c】将其终止,也可以用 kill 命令杀死它,但是对于后台进程来说,我们只能通过 kill 命令来杀死它。
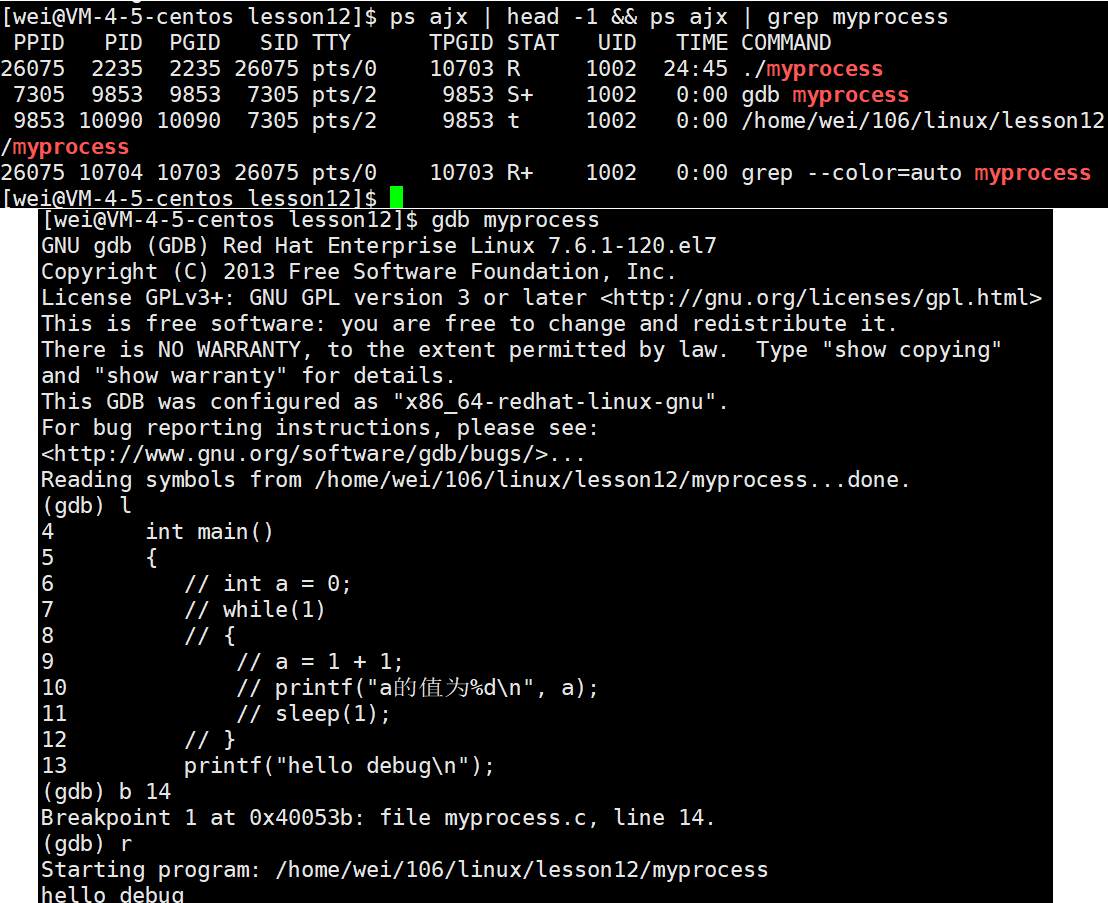
假设现在对我的一串代码进行调试,并打了一个断点,仔细观察我进程的状态:
- 小t也是暂停,不过它代表的是进程被调试的时候,遇到断定所处的状态,追踪状态。
- 补充:
5、死亡状态 (X)
这个状态只是一个返回状态,当一个进程的退出信息被读取后,该进程所申请的资源就会立即被释放,该进程也就不存在了,你不会在任务列表里看到这个状态。
6、僵尸状态 (Z)
假设程序员张三在外出跑步时,看到前面原先跑的程序员李四好好的突然倒下了,此时张三叫来了医生和警察,首先医生检查了一下,判断李四已经“嘠了”,此时医生的任务已经完成并回去了,接着警察派出法医去检测李四的死因,当法医检测好死因后,此时警察的事也完成了,往后就是查案,在走之前,通知了李四的家属,告知其具体情况并让他们来认领“李四”,从李四的倒下一直到被抬走,整个过程李四已无生命迹象,但是并没有立刻抬走,因为警察要确定死因,在警察所排查的过程中,李四所处的状态就是僵尸状态。
**总结:**当一个进程将要退出的时候,在系统层面,该进程曾经申请的资源并不是立即被释放(直接进入X死亡状态),而是要暂时存储一段时间,以供操作系统或是其父进程进行读取,如果退出信息一直未被读取,则相关数据是不会被释放掉的,一个进程若是正在等待其退出信息被读取,那么我们称该进程处于僵尸状态(zombie)。僵尸状态就是进程在退出时等待父进程或者操作系统来读取退出状态代码,然后释放PCB的一种状态。
- 为什么进程要进入Z状态呢?
1、进程被创建出来,一定是因为有任务让这个进程执行,当进程退出的时候,不能立即释放该进程对应的资源,需要保存一段时间,一般需要把进程的执行结果告知给父进程或OS以此让我们得知任务的完成结果。
2、进程进入Z状态,就是为了维护退出信息,可以让父进程或os读取的。最后才能进入X状态。



四、两种特殊的进程
1.僵尸进程
什么是僵尸进程?
回顾一下,前面说到,一个进程若是正在等待其退出信息被读取,那么我们称该进程处于僵尸状态。而处于僵尸状态的进程,我们就称之为僵尸进程。再来回顾下:
- 僵死状态(Zombies)是一个比较特殊的状态。当进程退出并且父进程(使用wait()系统调用,后面讲)没有读取到子进程退出的返回代码时就会产生僵死(尸)进程
- 僵尸进程会以终止状态保持在进程表中,并且会一直在等待父进程读取退出状态代码。
- 所以,只要子进程退出,父进程还在运行,但父进程没有读取子进程状态,子进程进入Z状态。
示例:创建一个5s的僵尸进程
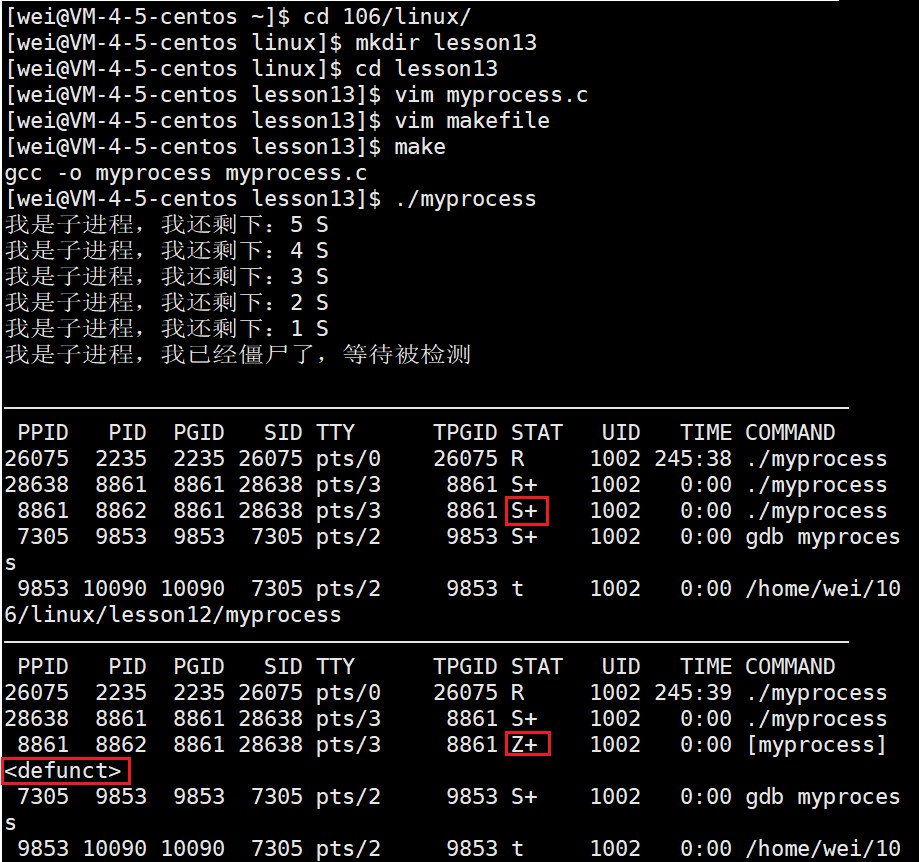
#include<stdio.h> #include<stdlib.h> #include<unistd.h> int main() {pid_t id = fork();if (id == 0){//child int cnt = 5;while (cnt){printf("我是子进程,我还剩下:%d S\n", cnt--);sleep(1);}printf("我是子进程,我已经僵尸了,等待被检测\n");exit(0);}else{//father while (1){sleep(1);}}return 0; }运行该代码后,我们可以通过以下监控脚本,每隔一秒对该进程的信息进行检测:
while :; do ps ajx | head -1 && ps ajx | grep process | grep -v grep; sleep 1; echo "—————————————————————————————————————————————————————————————————"; done
通过对上述pid和ppid的观察,我们得知,8862是父进程,8861是子进程,此时运行了5秒钟,8862退出了,状态变成了Z状态。并且子进程后面还提示了 defunct (失效的,不再使用的)。
僵尸进程的危害
- 进程的退出状态必须被维持下去,因为他要告诉关心它的进程(父进程),你交给我的任务,我办的怎么样了。可父进程如果一直不读取,那子进程就一直处于Z状态
- 维护退出状态本身就是要用数据维护,也属于进程基本信息,所以保存在task_struct(PCB)中,换句话说, Z状态一直不退出, PCB一直都要维护?是的!
- 那一个父进程创建了很多子进程,就是不回收,是不是就会造成内存资源的浪费?是的!因为数据结构对象本身就要占用内存,想想C中定义一个结构体变量(对象),是要在内存的某个位置进行开辟空间!
- 最终会导致内存泄漏
2.孤儿进程
我们针对上面的代码进行修改:
#include <stdio.h> #include <unistd.h> #include <stdlib.h> #include <sys/types.h>int main() {int id = fork();if(id > 0){while(1){printf("我是父进程,pid: %d, ppid: %d\n", getpid(), getppid());sleep(1);}}else if(id == 0){while(1){printf("我是子进程,pid: %d, ppid: %d\n", getpid(), getppid());sleep(1);}}else {perror("fork fail");exit(-1);}return 0; }我们运行此程序并查看其进程的相关信息:
图中我们可以看出子进程是7968,父进程是7967,当父进程7067退出的时候,父进程为什么没有变成僵尸状态Z呢?
- 因为父进程的父进程是bash,bash会自动回收它的子进程,也就是这里的父进程,换言之这里没有看到僵尸是因为父进程被它的父进程bash回收了。
先前我们说过,子进程退出的时候,父进程要通过某种方式回收子进程,但是这里很明显父进程先走了,子进程还没退出,可如果我子进程退出了,那谁来回收我呢?
- 总结:这里操作系统就扮演了干爹的角色,也就是如果父进程提前退出,子进程就会被1号进程(就是操作系统)领养,我们把这种被领养的进程称为孤儿进程。
补充:
- 这里注意当父进程退出后,由S+变成S,带加号的是前台进程,不带加号的是后台进程,并且这里使用ctrl+c并不能结束进程,需要手动kill进程:



五、进程优先级
1.基本概念
1、什么是优先级 vs 权限(是什么?)
- 优先级是进程获取资源的先后顺序,比如你去医院看病,但是看病的人很多,这就需要排队挂号,假设你在队尾,虽然是队尾,但是你也能打到饭,只不过是先后的问题。
- 权限是能和不能的问题,好比如你听QQ音乐,周董的歌只有vip用户才能看,普通用户不能看,因为你没有这个权限。
2、为什么会存在优先级?
- 就好比如我去医院挂号,这就是最典型的排队,而排队的本质叫做确认优先级,而排队的原因在于资源有限,你挂号来晚了就没你的号了
- 系统里面永远是进程占大多数,而资源是少数,cpu只有一个,可是进程有n个,这就导致竞争资源是常态,所以一定要确认前后,因此必须存在优先级来确定谁先谁后。
总结:
- cpu资源分配的先后顺序,就是指进程的优先权(priority)。
- 优先权高的进程有优先执行权利。配置进程优先权对多任务环境的linux很有用,可以改善系统性能。还可以把进程运行到指定的CPU上,这样一来,把不重要的进程安排到某个CPU,可以大大改善系统整体性能。
2.查看系统进程
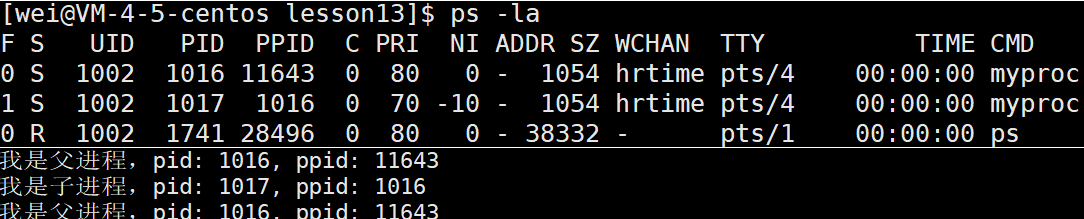
在linux或者unix系统中,我们运行一个无限循环的process文件,并用ps –l命令则会类似输出以下几个内容:
ps -al
我们很容易注意到其中的几个重要信息,如下:
- UID : 代表执行者的身份
- PID : 代表这个进程的代号
- PPID :代表这个进程是由哪个进程发展衍生而来的,亦即父进程的代号
- PRI :代表这个进程可被执行的优先级,其值越小越早被执行
- NI :代表这个进程的nice值

3.PRI and NI
Linux下用PRI(priority)和NI(nice)来确认优先级
- PRI也还是比较好理解的,即进程的优先级,或者通俗点说就是程序被CPU执行的先后顺序,此值越小进程的优先级别越高,越大代表进程优先级越低。
- Linux下默认进程的优先级是80
- 那NI呢?就是我们所要说的nice值了,其表示进程可被执行的优先级的修正数值,只能通过修改ni值来更改优先级
- PRI值越小越快被执行,那么加入nice值后,将会使得PRI变为: PRI(new)=PRI(old)+nice,注意每次设置优先级,这个old优先级都会被恢复成80。
- 这样,当nice值为负值的时候,那么该程序将会优先级值将变小,即其优先级会变高,则其越快被执行
- 所以,调整进程优先级,在Linux下,就是调整进程nice值
- nice其取值范围是-20至19,所以pri的取值范围是60至99。表示我们能调整40个级别
4.查看进程优先级信息
当我们创建一个进程后,我们可以使用ps -al命令查看该进程优先级的信息。
ps -al

5.通过top命令修改进程优先级(ni)
修改进程优先级就是在修改ni值,这里有两种方法:
- 1、通过top命令更改进程的nice值
- 2、通过renice命令更改进程的nice值
- 注意优先级不能随便修改,它会打破调度器平衡的,如果你非得修改,就要用超级用户修改。
这里我们只讨论第一种方法:
- 通过top命令更改进程的nice值
输入**sudo top**命令:
top命令就相当于Windows操作系统中的任务管理器,它能够动态实时的显示系统当中进程的资源占用情况。
按下‘ r ’键:此时会要求你输入待调整nice值的进程的PID。
输入后按下回车,此时会要求你输入调整后的nice值。
使用【q】命令退出。修改号后,再ps -la查看是否已经修改:
根据先前的性质不难得知,ni的值设置为-10,而PRI = PRI(old)+nice = 80 - 10 = 70。假设我后续把ni的值设置为10,最后ni的值为10,PRI的值为80 + 10 = 90,因为每次设置优先级,这个old优先级都会被恢复成80,所以是从80开始。


六、进程的其他概念
- 竞争性:系统进程数目众多,而CPU资源只有少量,甚至1个,所以进程之间是具有竞争属性的。为了高效完成任务,更合理竞争相关资源,便具有了优先级
- 独立性:多进程运行,需要独享各种资源,多进程运行期间互不干扰
- 并行:多个进程在多个CPU下分别,同时进行运行,这称之为并行
- 并发:多个进程在一个CPU下采用进程切换的方式,在一段时间之内,让多个进程都得以推进,称之为并发
下面具体解释并发:
- 多个进程在你的系统中运行 != 多个进程在你的系统中同时运行
- 进程不是占用了cpu,就会一直执行到结束然后释放cpu资源,我们遇到的大部分操作系统都是分时的!所谓的分时就是操作系统会给每一个进程,在以此调度周期中,赋予一个时间片的概念。
- 如图:假设进程1进入cpu运行,假设操作系统给它分配10ms的时间,如果10ms到了,无论结果如何都不会再让你进程1继续运行了,操作系统会把你进程1从cpu上剥离下来,然后再调度进程2……假设往后每个进程都是分配10ms,1s = 1000ms,那么在1s内,这5个进程平均每个都要调度20次。
总结:在一个时间段内,多个进程都会通过切换交叉的方式,让多个进程代码,在一段时间内都得到推进,这种现象,我们叫并发。
补充1:抢占式内核
- 我们的操作系统内部支持抢占式内核,正在运行的低优先级进程,但如果来个优先级更高的进程,我们的调度器会直接把进程从cpu上玻璃,放上优先级更高的进程,这就是进程抢占。
补充2:进程的 优先级 | 队列
- 操作系统内是允许不同的优先级的存在的,且相同优先级的进程,是可以存在多个的。但是进程是一个先进先出的队列,如果在原有稳定的进程基础上,突然来了一个优先级更高的进程,那它就会随便插队吗,这不就不符合队列的性质了。这里就可以借用指针数组、hash来解决:
总结:linux内核是根据不同的优先级,将特定的进程放入不同的队列中,而cpu就很自然的从数组的优先级最高的地方开始寻找进程。
七、进程切换
进程间是如何进行切换的。
- CPU内部存在各种各样的寄存器,可以临时的保存数据。而寄存器又分可见寄存器和不可见寄存器。当进程在被执行的时候,一定会存在大量的临时数据,会暂存在CPU内的寄存器中。当你要把下一个进程放上来的时候,除了要把上一个进程拿走,还要把你的历史数据拿走,CPU同一时刻只能运行一个进程,但是CPU的运算速度非常快,所以位于CPU运行队列中的每一个进程都只运行一个时间片,每个进程运行完一个时间片后被都被放到运行队列尾部,等待下次运行,这样使得在一个时间段中多个进程都能被运行。示例:
- 假如小王刚上大一,还没开学,随即填报了大学生征兵入伍,为了保留学籍,小王向学校申请了保留学籍,此时学校要留存小王的数据(个人信息,学籍……)。小王两年义务兵退伍后,随即又向学校申请恢复学籍,此时小王就可以从先前被切走的地方(大一)继续运行(上学)。此时学校扮演的角色就是cpu,小王在学校产生的所有临时数据就是上下文数据,小王就是一个进程,小王当兵被招走就相等于被操作系统切换下去,前提是在cpu内把临时数据保存好,为了的是后续的恢复。
总结:我们把进程在运行中产生的各种寄存器数据,我们叫做进程的上下文
- 当进程被剥离:需要保存上下文数据(task_struct)。
- 当进程恢复的时候:需要将曾经保存的上下文数据恢复到寄存器中。
参考文章:进程概念和进程状态
相关文章:

<Linux>进程概念
文章目录一、什么是进程1.进程概念2.进程描述 – PCB3.task_struct内容分类二、进程的基本操作1.查看进程2.结束进程3.通过系统调用获取进程标示符4.通过系统调用创建子进程(fork)三、进程状态1.普遍的操作系统状态2.Linux操作系统状态四、两种特殊的进程1.僵尸进程2.孤儿进程五…...
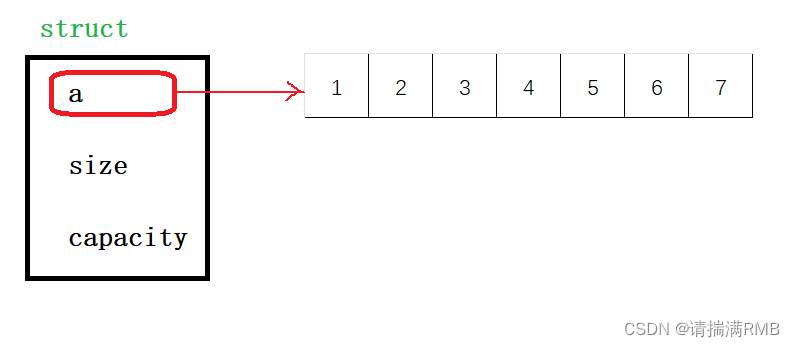
数据结构——顺序表
文章目录🐨0. 前言🎈1. 顺序表的概念及定义🪁2. 接口的声明🪄3. 接口的实现🍅3.1 为何使用断言?🍒3.2 初始化与销毁🍓3.3 尾插与尾删🍉3.4 头插与头删🍹3.5 指…...

闪存系统性能优化方向集锦?AC timing? Cache? 多路并发?
1. 从Flash系统的性能提升说起从消费级产品到数据中心企业级场景,NAND Flash凭借其高性能、大容量、低功耗以及低成本等特性大受欢迎,是目前应用最为广泛的半导体非易失存储介质。为了满足业务场景越来越严苛的性能要求,人们想了许多方法来提…...

【每日一题】——网购
🌏博客主页:PH_modest的博客主页 🚩当前专栏:每日一题 💌其他专栏: 🔴 每日反刍 🟢 读书笔记 🟡 C语言跬步积累 🌈座右铭:广积粮,缓称…...
百度终于要出手了?文心一言
文心一言 百度全新一代知识增强大语言模型,文心大模型家族的新成员,能够与人对话互动,回答问题,协助创作,高效便捷地帮助人们获取信息、知识和灵感。 前几天炒的风风火火的ChatGPT,虽然 ChatGPT 很强大&a…...
8年Java架构师面试官教你正确的面试姿势,10W字面试题带你成功上岸大厂
从最开始的面试者变成现在的面试官,工作多年以及在面试中,我经常能体会到,有些面试者确实是认真努力工作,但坦白说表现出的能力水平却不足以通过面试,通常是两方面原因: 1、“知其然不知其所以然”。做了多…...

Mybatis-Plus详解
简介MyBatis-Plus (opens new window)(简称 MP)是一个 MyBatis (opens new window)的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。特性(官网提供)无侵入:只做增强…...

购物清单(蓝桥杯C/C++省赛)
目录 1 问题描述 2 文件的读取格式 3 代码实现 1 问题描述 小明刚刚找到工作,老板人很好,只是老板夫人很爱购物。老板忙的时候经常让小明帮忙到商场代为购物。小明很厌烦,但又不好推辞。 这不,XX大促销又来了!老板…...

【蓝桥杯集训·每日一题】AcWing 4496. 吃水果
文章目录一、题目1、原题链接2、题目描述二、解题报告1、思路分析2、时间复杂度3、代码详解三、知识风暴求组合数一、题目 1、原题链接 4496. 吃水果 2、题目描述 n 个小朋友站成一排,等着吃水果。 一共有 m 种水果,每种水果的数量都足够多。 现在&…...
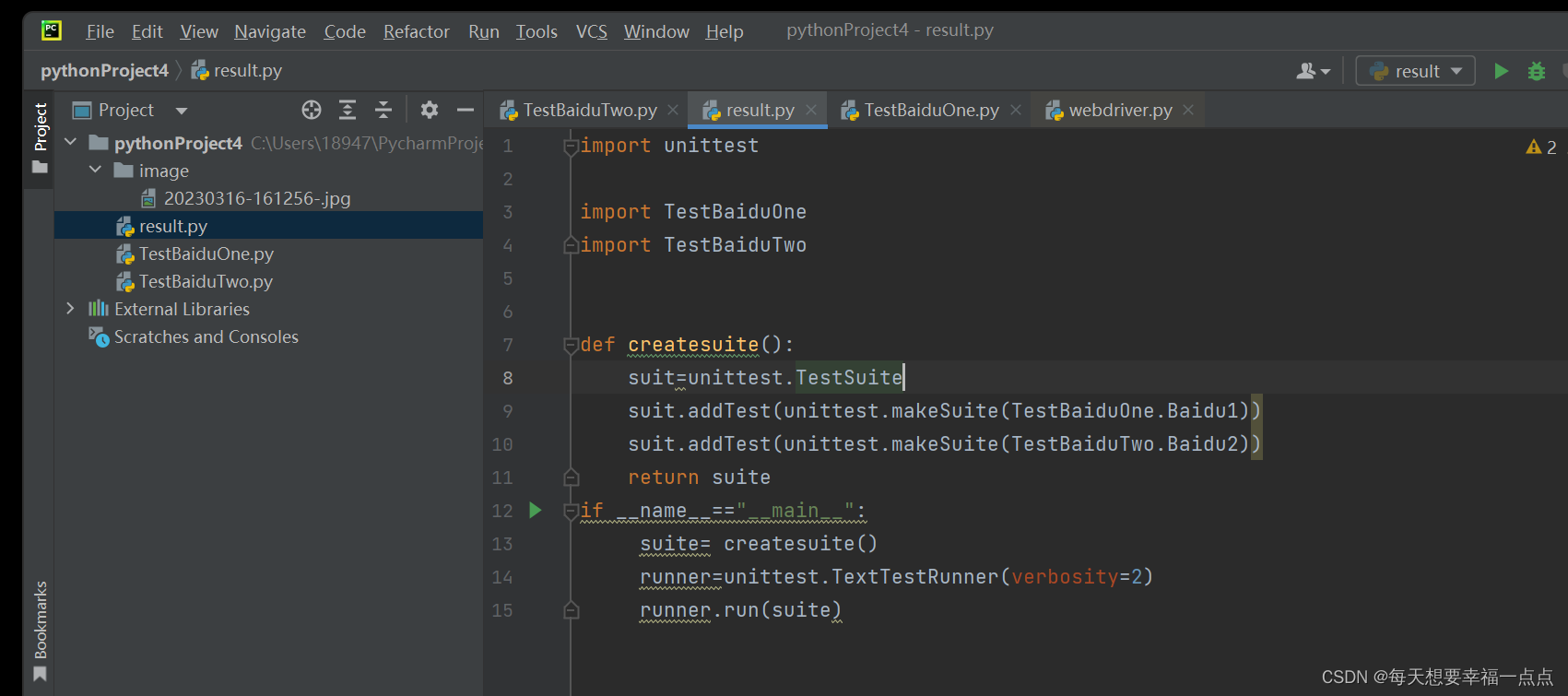
selenium(6)-----unittest框架
unittest框架 1)测试固件 1)setUp()是用来初始化测试环境所做的工作 2)tearDown()是用来清理环境所做的工作 2)测试套件 把不同的测试脚本,不同类中的测试用例给组织起来放到一个测试套中执行 3)测试用例的要以test_开头 4)如何使用unittest框架 只需要在脚本中定义…...
统计软件与数据分析--Lesson3
dataframe数据常用python操作dataframe数据常用知识点1.创建dataframe1.1使用字典创建DataFrame:1.2使用列表创建DataFrame:1.3使用numpy数组创建DataFrame:1.4从TXT文件中创建DataFrame:1.5从CSV文件中创建DataFrame:…...

竞赛无人机搭积木式编程——以2022年TI电赛送货无人机一等奖复现为例学习(7月B题)
在学习本教程前,请确保已经学习了前4讲中无人机相关坐标系知识、基础飞行控制函数、激光雷达SLAM定位条件下的室内定点控制、自动飞行支持函数、导航控制函数等入门阶段的先导教程。 同时用户在做二次开发自定义的飞行任务时,可以参照第5讲中2021年国赛植…...

oracle基础操作
oracle基础操作语法: 1、查询会话 SQL> select count(*) from v$session;2、增大连接数 SQL> alter system set processes5000 scope spfile;3、增大会话数 SQL> alter system set sessions7552 scopespfile;4、查询 参数: SQL> sho…...

python爬虫数据写入excel
在Jmeter118中描述了如何将接口请求的响应数据写入到csv中,同样的接口如果采用python写法,会简便很多,主要是用到了python中的pandas库#爬取展台数据import requestsimport pandas as pdurlhttps://ficonline.cfaa.cn/Exhibition/searchExhib…...
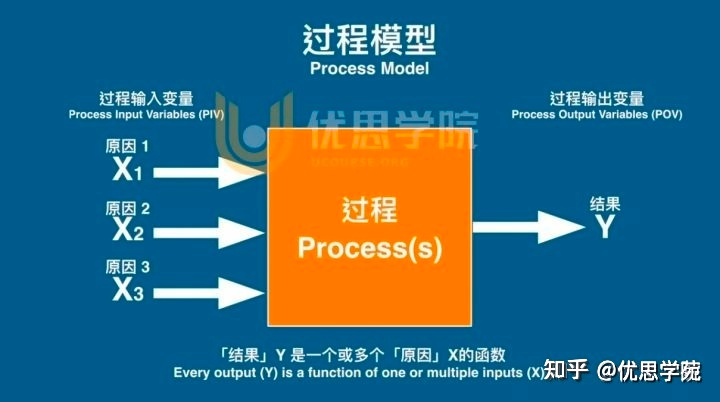
优思学院|六西格玛DMAIC,傻傻搞不清?
DMAIC还是搞不清? DMAIC是一个用于过程改进和六西格玛的问题解决方法论。它是以下五个步骤的缩写: 定义(Define):明确问题,设定项目的目标和目的。绘制流程图,并收集数据,以建立未来…...
【Linux】网络编程套接字(下)
🎇Linux: 博客主页:一起去看日落吗分享博主的在Linux中学习到的知识和遇到的问题博主的能力有限,出现错误希望大家不吝赐教分享给大家一句我很喜欢的话: 看似不起波澜的日复一日,一定会在某一天让你看见坚持…...

【Linux网络】网络编程套接字(上)
🎇Linux: 博客主页:一起去看日落吗分享博主的在Linux中学习到的知识和遇到的问题博主的能力有限,出现错误希望大家不吝赐教分享给大家一句我很喜欢的话: 看似不起波澜的日复一日,一定会在某一天让你看见坚持…...
十二、51单片机之DS1302
1、DS1302简介 (1)详情查看数据手册。 (2)管角描述 管教名称功能1Vcc2双供电配置中的主电源供电引脚2X1与标准的32.768kHz晶振相连。用于ds1302记时。3X24GND电源地5CE输入信号,CE信号在读写时必须保持高电平6I/O输入/推挽输出I/O,是三线接口的双向数…...
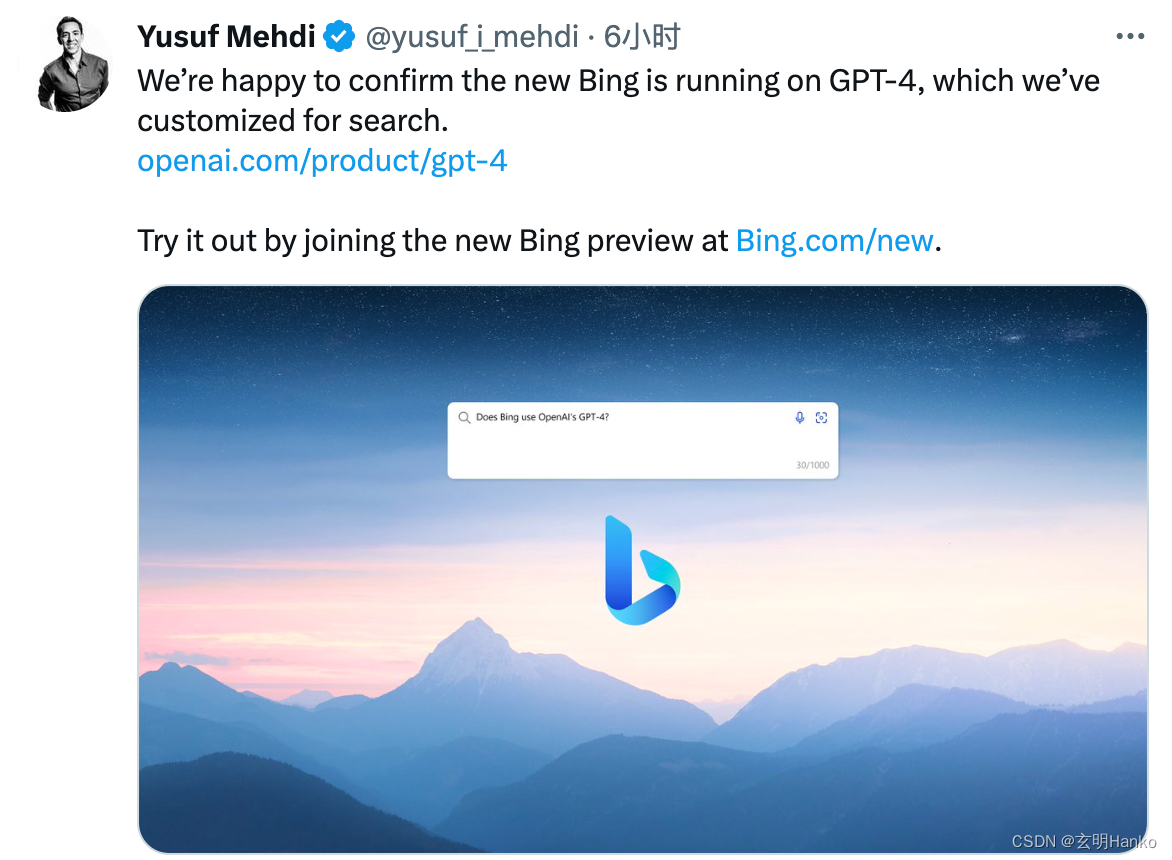
ChatGPT-4震撼发布
3月15日消息,美国当地时间周二,人工智能研究公司OpenAI发布了其下一代大型语言模型GPT-4,这是其支持ChatGPT和新必应等应用程序的最新AI大型语言模型。该公司表示,该模型在许多专业测试中的表现超出了“人类水平”。GPT-4, 相较于…...
HTML樱花飘落
樱花效果 FOR YOU GIRL 以梦为马,不负韶华 LOVE YOU FOREVER 实现代码 <!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"> <html><head><meta http-equiv"…...

【RK3588】UBoot环境变量持久化存储实战:从MMC到TF卡的全配置指南
1. 为什么需要持久化存储UBoot环境变量 第一次用RK3588开发板调试时,我就被环境变量丢失的问题坑过。当时花了两天时间配置好的bootargs参数,一次断电重启后就全没了——这种酸爽相信很多嵌入式开发者都体验过。UBoot默认将环境变量存放在内存中…...

如何用OpCore-Simplify工具3步完成黑苹果系统自动化配置
如何用OpCore-Simplify工具3步完成黑苹果系统自动化配置 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 你是否曾经被黑苹果系统复杂的OpenCore配置搞…...
)
从iPhone面捕到3D动画:手把手教你用ARKit 52个BlendShape驱动DAZ角色(含MetaHuman插件设置)
iPhone面捕驱动3D角色全流程:ARKit与DAZ的52个BlendShape深度适配指南 当iPhone的前置摄像头能够实时捕捉你的微笑、挑眉甚至微妙的面部抽搐,并将这些数据无缝转化为3D角色的生动表情时,数字内容创作的边界被彻底打破。本文将带你深入探索如何…...

Real-ESRGAN-GUI:5分钟掌握AI图像修复神器,让模糊图片秒变高清
Real-ESRGAN-GUI:5分钟掌握AI图像修复神器,让模糊图片秒变高清 【免费下载链接】Real-ESRGAN-GUI Lovely Real-ESRGAN / Real-CUGAN GUI Wrapper 项目地址: https://gitcode.com/gh_mirrors/re/Real-ESRGAN-GUI 还在为模糊不清的老照片、低分辨率…...

避坑指南:RM65-B机械臂拓展轴MoveIt配置中最容易忽略的5个参数设置
RM65-B机械臂拓展轴MoveIt配置中最容易忽略的5个参数设置 当工程师第一次尝试为RM65-B机械臂配置拓展轴时,往往会遇到机械臂与拓展轴运动不同步的问题。这种不同步不仅影响工作效率,还可能造成安全隐患。本文将深入剖析5个最容易被忽视的关键参数设置&am…...

实战分享:如何将通义千问3-Embedding-4B集成到现有业务系统中
实战分享:如何将通义千问3-Embedding-4B集成到现有业务系统中 1. 为什么选择Qwen3-Embedding-4B 在构建现代知识库和语义搜索系统时,文本向量化模型的选择至关重要。Qwen3-Embedding-4B作为阿里通义千问系列的最新成员,凭借其平衡的性能和资…...

HTTPS RSA 握手解析
HTTPS 的 RSA 握手过程是建立安全通信通道的核心机制之一。虽然在现代互联网中,为了提供前向安全性(Forward Secrecy),基于 Diffie-Hellman(如 ECDHE)的密钥交换算法已逐渐成为主流,但理解经典的…...

Neeshck-Z-lmage_LYX_v2精彩案例:‘水墨+3D渲染’混合风格LoRA生成实录
Neeshck-Z-lmage_LYX_v2精彩案例:‘水墨3D渲染’混合风格LoRA生成实录 1. 引言:当传统水墨遇上现代3D 想象一下,一幅画既有中国水墨画的飘逸意境,又有3D渲染的立体质感,会是什么样子?这听起来像是两个不同…...

快速恢复误删的Anaconda环境
问题确认与初步处理检查回收站或垃圾箱,确认文件是否被彻底删除。若存在回收站中,直接恢复即可。停止对系统盘的一切写入操作,避免数据被覆盖。立即关闭不必要的程序,减少磁盘活动。使用数据恢复工具推荐工具:Recuva、…...

SEO_资深专家揭秘长期稳定的SEO操作秘诀
SEO操作的长期稳定之道:资深专家揭秘 在当今数字化时代,搜索引擎优化(SEO)已经成为了企业在网络上获得流量和知名度的关键手段。无论是小型企业还是大型公司,都在竞争着在搜索结果中的高排名。很多人在进行SEO操作时&a…...