【机器学习】无监督学习和自监督学习
1. 什么是机器学习
机器学习是一种使计算机系统能够从数据中学习并做出预测或决策的技术和科学领域。它不需要显式地编程来执行特定任务,而是通过使用算法来分析数据和识别模式,以此“学习”如何做出准确的预测或决策。
以下是机器学习的几个关键点:
1.1 核心概念
- 数据:机器学习模型的训练基于大量数据。
- 模型:模型是机器学习算法的核心,它从数据中学习并做出预测。
- 算法:算法是用于训练模型的步骤和规则。
- 学习:通过训练过程,模型从数据中学习模式和特征。
1.2 类型
- 监督学习:通过已标记的训练数据来训练模型,使其能够预测未标记数据的输出。
- 无监督学习:在没有任何标签的情况下,让模型自行发现数据中的结构和模式。
- 半监督学习:结合了少量标记数据和大量未标记数据来训练模型。
- 强化学习:模型通过与环境互动并接收奖励或惩罚来学习最优行为。
- 自监督学习:模型通过预测数据中的隐藏部分或上下文来学习,比如预测图像中的缺失像素、预测视频帧的未来状态或完成句子中的掩码单词。
1.3 应用方向
- 图像识别:如面部识别、物体检测。
- 语音识别:如语音到文本转换。
- 自然语言处理:如机器翻译、情感分析。
- 推荐系统:如电子商务网站上的个性化推荐。
1.4 训练过程
- 数据收集:收集大量相关数据。
- 数据预处理:清洗、标准化和转换数据,以便于模型处理。
- 模型选择:选择适当的算法和架构。
- 训练:使用训练数据来训练模型。
- 评估:使用验证集来评估模型的性能。
- 调优:调整模型参数以改善性能。
- 部署:将模型部署到实际应用中。
机器学习是人工智能的一个重要分支,并且在许多领域都显示出巨大的潜力和价值。
2. 无监督学习和自监督学习介绍
无监督学习和自监督学习是机器学习中的两种学习方式,它们在训练数据的需求和目标上有显著差异。
2.1 无监督学习特点
无监督学习是指在没有标签信息的情况下,让机器学习算法从数据中找出潜在的结构、模式或关联性。它的主要特点包括:
- 数据未标记:与监督学习不同,无监督学习不依赖于外部提供的标签信息。
- 发现模式:算法试图通过探索数据内在的规律和结构来发现模式或集群。
- 应用广泛:常用于数据预处理、降维、异常检测、关联规则学习等。
无监督学习的典型算法包括: - 聚类算法:如
K-means、DBSCAN等,用于将数据分成若干个群组。 - 降维技术:如主成分分析(
PCA)、t-SNE等,用于减少数据的维度,以便更容易理解和可视化。 - 关联规则学习:如
Apriori算法、Eclat算法等,用于发现数据中的频繁项集和关联规则。
2.2 自监督学习特点
自监督学习是近年来兴起的一种学习方式,它介于监督学习和无监督学习之间。自监督学习的核心是利用数据本身的信息生成标签,而不是依赖于人工标注的标签。其特点包括:
- 利用数据本身:通过设计预测任务,让算法预测数据中的一部分信息,这部分信息通常是从数据中移除或隐藏的。
- 标签自动生成:与监督学习相比,自监督学习的标签是从数据中自动生成的,不需要人工参与。
- 广泛应用:在计算机视觉、自然语言处理等领域表现出色。
自监督学习的典型应用包括: - 计算机视觉:通过预测图像中的像素值(如图像修复)、图像块位置(如拼图游戏)或图像标签(如对比学习)来学习图像表示。
- 自然语言处理:通过预测句子中的隐藏单词、下一个句子或语言模型中的单词掩码来自动学习语言表示。
2.3 异同点概括
无监督学习和自监督学习都旨在减少对大量标注数据的依赖,但自监督学习更侧重于通过设计任务来生成标签,而无监督学习更侧重于探索数据本身的内在结构。
3. 应用领域
无监督学习和自监督学习在多个领域都有广泛的应用,下面是一些主要的应用领域:
3.1 无监督学习的应用领域
- 数据挖掘:
- 客户细分:通过聚类分析来识别不同的客户群体。
- 关联规则学习:在零售业中,用于发现商品之间的购买关系。
- 推荐系统:
- 协同过滤:通过用户行为数据来发现潜在的相似性,从而进行个性化推荐。
- 文本分析:
- 主题建模:如使用隐含狄利克雷分配(LDA)来发现文档集合中的主题。
- 文本聚类:将相似的文档分组在一起,无需预先定义类别。
- 图像处理:
- 图像分割:将图像分割成多个区域,每个区域具有相似的特征。
- 图像聚类:将相似的图像分组在一起。
- 生物信息学:
- 基因表达分析:通过聚类来理解不同基因在不同条件下的表达模式。
- 网络分析:
- 社区检测:在社交网络分析中,用于发现紧密相连的节点群。
3.2 自监督学习的应用领域
- 计算机视觉:
- 图像分类:通过自监督预训练,可以学习到强大的图像特征表示,用于下游的分类任务。
- 目标检测:自监督学习可以用于预训练模型,以识别图像中的不同对象。
- 自然语言处理:
- 语言模型:如BERT(双向编码器表示从转换器)等模型,通过预测句子中的掩码单词来学习语言表示。
- 文本分类:自监督学习可以用于预训练文本表示,进而用于情感分析、主题分类等任务。
- 语音识别:
- 语音增强:通过自监督学习来提高语音信号的质量。
- 说话人识别:自监督学习可以用于提取说话人的特征。
- 时间序列分析:
- 异常检测:自监督学习可以用于学习正常的时间序列模式,从而检测出异常。
- 多模态学习:
- 跨模态检索:自监督学习可以用于学习如何将不同模态(如文本和图像)的数据映射到同一空间,以便进行检索。
这些应用领域展示了无监督学习和自监督学习在解决实际问题时的多样性和有效性。随着技术的进步,这两种学习方式的应用范围还在不断扩大。
4. 实例比较
4.1 无监督学习 - K-means聚类
以下是一个使用 Python 语言和scikit-learn库实现的无监督机器学习程序示例,这里我们使用K-means算法进行聚类。
from sklearn.cluster import KMeans
import numpy as np
# 示例数据,这里使用随机生成的数据
# 假设我们有10个数据点,每个数据点有2个特征
X = np.random.rand(10, 2)
# 使用KMeans进行聚类
# n_clusters: 聚类的数量,这里设置为3
kmeans = KMeans(n_clusters=3, random_state=0).fit(X)
# 输出聚类中心点
print("Cluster centers:", kmeans.cluster_centers_)
# 预测每个数据点的聚类标签
print("Labels:", kmeans.labels_)
# 预测新数据点的聚类标签
new_data = np.array([[0.5, 0.5], [1.0, 1.0]])
print("Predictions:", kmeans.predict(new_data))
这个程序首先导入了必要的库,然后创建了一组随机数据。接着,我们初始化KMeans对象并指定聚类的数量(这里是3个聚类)。通过调用fit方法,KMeans 算法会找到最佳的聚类中心,并将每个数据点分配到相应的聚类中。最后,我们打印出聚类中心、每个数据点的聚类标签以及新数据点的预测聚类标签。
4.2 自监督学习 - 预测图像块位置
以下是一个使用 Python 语言和PyTorch库实现的自监督机器学习程序示例。这里我们使用一个简单的自监督学习任务:预测图像块的位置。
在这个示例中,我们将使用一个预训练的卷积神经网络(CNN)来提取图像特征,并训练一个模型来预测图像块在原始图像中的位置。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 定义一个简单的卷积神经网络
class ConvNet(nn.Module):def __init__(self):super(ConvNet, self).__init__()self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1)self.pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)self.fc1 = nn.Linear(32 * 16 * 16, 128)self.fc2 = nn.Linear(128, 4) # 假设图像块的位置是4个分类def forward(self, x):x = self.pool(nn.functional.relu(self.conv1(x)))x = torch.flatten(x, 1)x = nn.functional.relu(self.fc1(x))x = self.fc2(x)return x
# 数据预处理
transform = transforms.Compose([transforms.RandomResizedCrop(32, scale=(0.2, 1.0)),transforms.RandomHorizontalFlip(),transforms.ToTensor(),
])
# 加载数据集
dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
dataloader = DataLoader(dataset, batch_size=64, shuffle=True)
# 初始化网络和优化器
net = ConvNet()
optimizer = optim.Adam(net.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
# 训练网络
for epoch in range(10): # 进行10个训练周期for i, (inputs, _) in enumerate(dataloader):# 创建图像块的位置标签# 这里简化处理,假设每个图像块的位置是一个整数positions = torch.randint(0, 4, (inputs.size(0),))# 前向传播outputs = net(inputs)loss = criterion(outputs, positions)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()if (i+1) % 100 == 0:print(f'Epoch [{epoch+1}/{10}], Step [{i+1}/{len(dataloader)}], Loss: {loss.item()}')
print("Training complete.")
这个示例中,我们定义了一个简单的卷积神经网络ConvNet,它有一个卷积层、一个池化层和两个全连接层。我们的目标是训练这个网络来预测图像块的位置。在这个简化的例子中,我们假设位置是一个4分类问题。
我们使用CIFAR-10数据集,并对图像进行随机裁剪和翻转来增加数据的多样性。然后,我们训练网络,通过比较网络输出和随机生成的位置标签来计算损失,并进行反向传播和优化。
请注意,这个示例是为了说明自监督学习的概念,并不是一个实用的自监督学习任务。在实际应用中,自监督学习任务会更加复杂,例如使用对比学习来预测图像块之间的相对位置。
相关文章:

【机器学习】无监督学习和自监督学习
1. 什么是机器学习 机器学习是一种使计算机系统能够从数据中学习并做出预测或决策的技术和科学领域。它不需要显式地编程来执行特定任务,而是通过使用算法来分析数据和识别模式,以此“学习”如何做出准确的预测或决策。 以下是机器学习的几个关键点&…...

蓝牙新篇章:WebKit的Web Bluetooth API深度解析
蓝牙新篇章:WebKit的Web Bluetooth API深度解析 在物联网(IoT)时代,Web应用与物理设备的交互变得越来越重要。WebKit的Web Bluetooth API开启了一个新时代,允许Web页面直接与蓝牙设备通信。这一API不仅提高了用户体验,还为创新的…...

2024可信数据库发展大会:TDengine CEO 陶建辉谈“做难而正确的事情”
在当前数字经济快速发展的背景下,可信数据库技术日益成为各行业信息化建设的关键支撑点。金融、电信、能源和政务等领域对数据处理和管理的需求不断增加,推动了数据库技术的创新与进步。与此同时,人工智能与数据库的深度融合、搜索与分析型数…...
Guns v7.3.0:基于 Vue3、Antdv 和 TypeScript 打造的开箱即用型前端框架
摘要 本文深入探讨了Guns v7.3.0前端项目,该项目是基于Vue3、Antdv和TypeScript的前端框架,以Vben Admin的脚手架为基础进行了改造。文章分析了Guns 7.3.0的技术特点,包括其使用Vue3、vite2和TypeScript等最新前端技术栈,以及提供…...
)
掌握构建艺术:在Gradle中配置自定义的源代码管理(SCM)
掌握构建艺术:在Gradle中配置自定义的源代码管理(SCM) 在软件开发过程中,源代码管理(Source Code Management,简称SCM)是不可或缺的一部分。它帮助开发者管理代码的变更历史,支持团…...

如何在 Mac 上下载安装植物大战僵尸杂交版? 最新版本 2.2 详细安装运行教程问题详解
植物大战僵尸杂交版已经更新至2.2了,但作者只支持 Windows、手机等版本并没有支持 MAC 版本,最近搞到了一个最新的杂交 2.2 版本的可以在 Macbook 上安装运行的移植安装包,试了一下非常完美能够正常在 MAC 上安装运行,看图&#x…...
前端Vue组件技术实践:打造自定义精美悬浮菜单按钮组件
随着前端技术的迅猛发展,复杂的应用场景和不断迭代的产品需求使得开发的复杂度日益提升。传统的整体式开发方式已经难以满足现代前端应用的灵活性和可维护性需求。在这样的背景下,组件化开发逐渐崭露头角,成为解决复杂前端应用问题的有效手段…...

数据仓库的一致性维度
一致性维度的定义: 一致性维度是指在数据仓库中,具有相同属性和含义的维度在不同的事实表中保持一致。它确保了通过不同事实表进行查询和分析时,维度数据的一致性和准确性。 一致性维度的作用: 数据一致性:一致性维度…...

【ffmpeg命令】RTMP推流
文章目录 前言推流是什么RTMP协议简介RTMP的基本概念RTMP的工作原理RTMP的优缺点 ffmpeg RTMP推流推流命令综合解释ffplay播放RTMP流 总结 前言 在现代的视频直播中,RTMP(Real-Time Messaging Protocol)是一种广泛使用的流媒体传输协议。它允…...

人工智能大模型发展的新形势及其省思
作者简介 肖仰华,复旦大学计算机科学技术学院教授、博导,上海市数据科学重点实验室主任。研究方向为知识图谱、知识工程、大数据管理与挖掘。主要著作有《图对称性理论及其在数据管理中的应用》、《知识图谱:概念与技术》(合著&a…...
Linux云计算 |【第一阶段】SERVICES-DAY4
主要内容: DHCP概述、PXE批量装机、配置PXE引导、Kickstart自动应答、Cobbler装机平台 一、DHCP服务概述及原理 DHCP动态主机配置协议(Dynamic Host Configuration Protocol),由IETF(Internet网络工程师任务小组&…...

微信小程序 button样式设置为图片的方法
微信小程序 button样式设置为图片的方法 background-image background-size与background-repeat与border:none;是button必须的 <view style" position: relative;"><button class"customer-service-btn" style"background-image: url(./st…...
2024 HNCTF PWN(hide_flag Rand_file_dockerfile Appetizers TTOCrv_)
文章目录 参考hide_flag思路exp Rand_file_dockerfile libc 2.31思路exp Appetizers glibc 2.35绕过关闭标准输出实例客户端 关闭标准输出服务端结果exp TTOCrv_🎲 glibc 2.35逆向DT_DEBUG获得各个库地址随机数思路exp 参考 https://docs.qq.com/doc/p/641e8742c39…...
《昇思25天学习打卡营第25天|第14天》
今天是打卡的第十四天,今天学习的是应用实践中的热门LLM及其他AI应用的K近邻算法实现红酒分类篇。这一片主要介绍使用MindSpore在部分wine数据集上进行KNN实验,对实验的步骤的介绍:K近邻算法原理介绍(分类问题、回归问题和距离的定…...
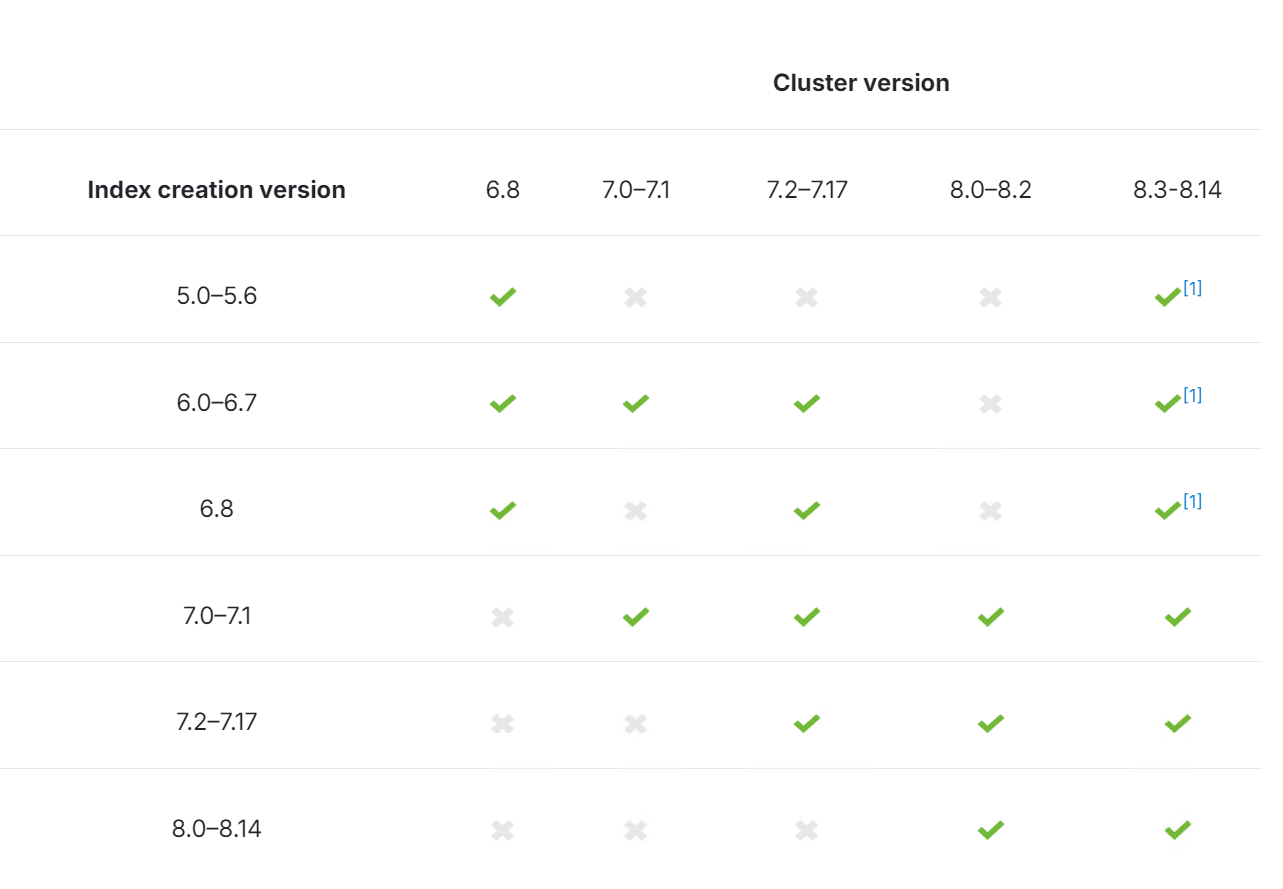
Easysearch、Elasticsearch、Amazon OpenSearch 快照兼容对比
在当今的数据驱动时代,搜索引擎的快照功能在数据保护和灾难恢复中至关重要。本文将对 EasySearch、Elasticsearch 和 Amazon OpenSearch 的快照兼容性进行比较,分析它们在快照创建、恢复、存储格式和跨平台兼容性等方面的特点,帮助大家更好地…...
数据分析入门指南:数据库入门(五)
本文将总结CDA认证考试中数据库中部分知识点,内容来源于《CDA模拟题库与备考资料PPT》 。 CDA认证,作为源自中国、面向全球的专业技能认证,覆盖金融、电信、零售、制造、能源、医疗医药、旅游、咨询等多个行业,旨在培养能够胜任数…...
Logback日志异步打印接入指南,输出自定义业务数据
背景 随着应用的请求量上升,日志输出量也会成线性比例的上升,给磁盘IO带来压力与性能瓶颈。应用也遇到了线程池满,是因为大量线程卡在输出日志。为了缓解日志同步打印,会采取异步打印日志。这样会引起日志中的追踪id丢失…...

将iPad 作为Windows电脑副屏的几种方法(二)
将iPad 作为Windows电脑副屏的几种方法(二) 1. 前言2. EV 扩展屏2.1 概述2.2 下载、安装、连接教程2.3 遇到的问题和解决方法2.3.1 平板连接不上电脑 3. Twomon SE3.1 概述3.2 下载安装教程 4. 多屏中心(GlideX)4.1 概述4.2 下载安…...
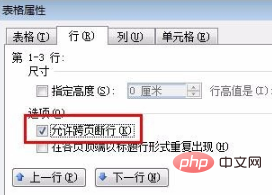
[word] word表格跨页断开实现教程 #职场发展#媒体
word表格跨页断开实现教程 选中整个word表格 单击鼠标右键,选择“表格属性”选项 切换至“行”标签,找到“允许跨页断行”选项 勾选上“允许跨页断行”,单击“确定”按钮,完成! word表格跨页断开实现教程的下载地址&a…...

《Linux运维总结:基于ARM64架构CPU使用docker-compose一键离线部署单机版tendis2.4.2》
总结:整理不易,如果对你有帮助,可否点赞关注一下? 更多详细内容请参考:《Linux运维篇:Linux系统运维指南》 一、部署背景 由于业务系统的特殊性,我们需要面对不同的客户部署业务系统࿰…...

SpringBoot-17-MyBatis动态SQL标签之常用标签
文章目录 1 代码1.1 实体User.java1.2 接口UserMapper.java1.3 映射UserMapper.xml1.3.1 标签if1.3.2 标签if和where1.3.3 标签choose和when和otherwise1.4 UserController.java2 常用动态SQL标签2.1 标签set2.1.1 UserMapper.java2.1.2 UserMapper.xml2.1.3 UserController.ja…...

DockerHub与私有镜像仓库在容器化中的应用与管理
哈喽,大家好,我是左手python! Docker Hub的应用与管理 Docker Hub的基本概念与使用方法 Docker Hub是Docker官方提供的一个公共镜像仓库,用户可以在其中找到各种操作系统、软件和应用的镜像。开发者可以通过Docker Hub轻松获取所…...
)
IGP(Interior Gateway Protocol,内部网关协议)
IGP(Interior Gateway Protocol,内部网关协议) 是一种用于在一个自治系统(AS)内部传递路由信息的路由协议,主要用于在一个组织或机构的内部网络中决定数据包的最佳路径。与用于自治系统之间通信的 EGP&…...

【大模型RAG】Docker 一键部署 Milvus 完整攻略
本文概要 Milvus 2.5 Stand-alone 版可通过 Docker 在几分钟内完成安装;只需暴露 19530(gRPC)与 9091(HTTP/WebUI)两个端口,即可让本地电脑通过 PyMilvus 或浏览器访问远程 Linux 服务器上的 Milvus。下面…...

【HTTP三个基础问题】
面试官您好!HTTP是超文本传输协议,是互联网上客户端和服务器之间传输超文本数据(比如文字、图片、音频、视频等)的核心协议,当前互联网应用最广泛的版本是HTTP1.1,它基于经典的C/S模型,也就是客…...

Android 之 kotlin 语言学习笔记三(Kotlin-Java 互操作)
参考官方文档:https://developer.android.google.cn/kotlin/interop?hlzh-cn 一、Java(供 Kotlin 使用) 1、不得使用硬关键字 不要使用 Kotlin 的任何硬关键字作为方法的名称 或字段。允许使用 Kotlin 的软关键字、修饰符关键字和特殊标识…...

从 GreenPlum 到镜舟数据库:杭银消费金融湖仓一体转型实践
作者:吴岐诗,杭银消费金融大数据应用开发工程师 本文整理自杭银消费金融大数据应用开发工程师在StarRocks Summit Asia 2024的分享 引言:融合数据湖与数仓的创新之路 在数字金融时代,数据已成为金融机构的核心竞争力。杭银消费金…...

Ubuntu系统复制(U盘-电脑硬盘)
所需环境 电脑自带硬盘:1块 (1T) U盘1:Ubuntu系统引导盘(用于“U盘2”复制到“电脑自带硬盘”) U盘2:Ubuntu系统盘(1T,用于被复制) !!!建议“电脑…...

【免费数据】2005-2019年我国272个地级市的旅游竞争力多指标数据(33个指标)
旅游业是一个城市的重要产业构成。旅游竞争力是一个城市竞争力的重要构成部分。一个城市的旅游竞争力反映了其在旅游市场竞争中的比较优势。 今日我们分享的是2005-2019年我国272个地级市的旅游竞争力多指标数据!该数据集源自2025年4月发表于《地理学报》的论文成果…...

webpack面试题
面试题:webpack介绍和简单使用 一、webpack(模块化打包工具)1. webpack是把项目当作一个整体,通过给定的一个主文件,webpack将从这个主文件开始找到你项目当中的所有依赖文件,使用loaders来处理它们&#x…...