SpringBoot集成Sharding-JDBC-5.3.0实现按月动态建表分表
Sharding-JDBC系列
1、Sharding-JDBC分库分表的基本使用
2、Sharding-JDBC分库分表之SpringBoot分片策略
3、Sharding-JDBC分库分表之SpringBoot主从配置
4、SpringBoot集成Sharding-JDBC-5.3.0分库分表
5、SpringBoot集成Sharding-JDBC-5.3.0实现按月动态建表分表
前言
随着业务量的递增,项目产生海量的数据,在某些场景中,需要将数据按月存储。本篇基于Sharding-JDBC 5.3.0,分享一下按月自动建表以及分表的实现。
准备工作
创建一个数据库,创建一张表,表名为tb_order。该表作为基准表。
引入依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.7.1</version><relativePath/> <!-- lookup parent from repository --></parent><modelVersion>4.0.0</modelVersion><artifactId>Sharding-JDBC-demo2</artifactId><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.4.1</version></dependency><dependency><groupId>org.apache.shardingsphere</groupId><artifactId>shardingsphere-jdbc-core</artifactId><version>5.3.0</version></dependency><dependency><groupId>org.yaml</groupId><artifactId>snakeyaml</artifactId><version>1.33</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.28</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.2.6</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.22</version><scope>compile</scope></dependency><!--<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><optional>true</optional><scope>runtime</scope></dependency>--></dependencies></project>1)引入shardingsphere-jdbc-core 5.3.0 的版本;
2)项目中不要引入spring-boot-devtools,否则在调试启动时,会报错;
spring-boot-devtools 会在类路径上的文件发生更改时自动重启,方便开发调试。在项目部署时,通过 java -jar 启动项目时,会自动禁用开发工具。报错的原因下面说明。
分片规则配置
4.1 application.yml
server:port: 8080
spring:main:# 处理连接池冲突allow-bean-definition-overriding: truedatasource:# shardingsphere5.3.0引入ShardingSphereDriver数据库驱动driver-class-name: org.apache.shardingsphere.driver.ShardingSphereDriverurl: jdbc:shardingsphere:classpath:sharding.yml指定分片规则的文件为sharding.yml。
4.2 sharding.yml
dataSources:order_ds:dataSourceClassName: com.zaxxer.hikari.HikariDataSourcedriverClassName: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3306/shardingjdbctest?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=falseusername: rootpassword: 123456rules:
- !SHARDINGtables:tb_order: #逻辑表actualDataNodes: order_ds.tb_order #表是自动创建keyGenerateStrategy: # 指定主键生成策略column: order_idkeyGeneratorName: snowflaketableStrategy:standard: shardingColumn: order_time #分片键shardingAlgorithmName: custom-time-shardingshardingAlgorithms: #分片算法custom-time-sharding:type: CLASS_BASED #自定义类props:strategy: standardalgorithmClassName: com.jingai.sharding.jdbc.algorithm.OrderTimeShardingAlgorithm #分片算法keyGenerators: # 主键生成器snowflake:type: SNOWFLAKE
props:sql-show: true # 是否打印sql1)配置真实表为tb_order,作为分表的表前缀;
2)配置分表策略为standard标准策略,以订单创建日期为分片键;
3)配置分表算法为自定义类OrderTimeShardingAlgorithm;
分片算法OrderTimeShardingAlgorithm
package com.jingai.sharding.jdbc.algorithm;@Slf4j
public class OrderTimeShardingAlgorithm implements StandardShardingAlgorithm<Date> {private static final DateFormat TABLE_SHARD_TIME_FORMAT = new SimpleDateFormat("yyyyMM");// 表分片符号。如:tb_order_202407private static final String TABLE_SPLIT_SYMBOL = "_";private Properties props;@Overridepublic String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Date> shardingValue) {String logicTableName = shardingValue.getLogicTableName();log.info("精准分片,逻辑表名:{},节点表名:{}", logicTableName, availableTargetNames);Date time = shardingValue.getValue();String result = logicTableName + TABLE_SPLIT_SYMBOL + TABLE_SHARD_TIME_FORMAT.format(time);// 在配置中,只配置了逻辑表名。如果只有一个,且是逻辑表名,说明需要获取所有表名initAvailableTargetNames(availableTargetNames, logicTableName);return getAndCreateShardingTable(logicTableName, result, availableTargetNames);}@Overridepublic Collection<String> doSharding(Collection<String> availableTargetNames, RangeShardingValue<Date> shardingValue) {String logicTableName = shardingValue.getLogicTableName();log.info("精准分片,逻辑表名:{},节点表名:{}", logicTableName, availableTargetNames);// 在配置中,只配置了逻辑表名。如果只有一个,且是逻辑表名,说明需要获取所有表名initAvailableTargetNames(availableTargetNames, logicTableName);Range<Date> valueRange = shardingValue.getValueRange();// 如果没有最大值或最小值,则全库扫描if(!valueRange.hasLowerBound() || !valueRange.hasUpperBound()) {return availableTargetNames;}Date min = valueRange.lowerEndpoint();Date max = valueRange.upperEndpoint();Set<String> rs = new HashSet<>();while (min.compareTo(max) <= 0) {String tableName = logicTableName + "_" + TABLE_SHARD_TIME_FORMAT.format(min);rs.add(tableName);min = DateUtils.addMonths(min, 1);}return getAndCreateShardingTable(logicTableName, rs, availableTargetNames);}private void initAvailableTargetNames(Collection<String> availableTargetNames, String logicTableName) {if(availableTargetNames.size() == 1 && availableTargetNames.contains(logicTableName)) {Set<String> allTableNameBySchema = ShardingAlgorithmUtil.getAllTableNameBySchema(logicTableName);availableTargetNames.clear();availableTargetNames.addAll(allTableNameBySchema);}}/*** 检查可用的真实表,如果表名不存在,则创建新表* @param logicTableName 逻辑表* @param resultTableNames 操作需要的真实表* @param availableTargetNames 可用的真实表* @return 分片的真实表*/private List<String> getAndCreateShardingTable(String logicTableName, Set<String> resultTableNames, Collection<String> availableTargetNames) {return resultTableNames.stream().map(name -> getAndCreateShardingTable(logicTableName, name, availableTargetNames)).collect(Collectors.toList());}/*** 检查可用的真实表,如果表名不存在,则创建新表* @param logicTableName* @param resultTableName* @param availableTargetNames* @return*/private String getAndCreateShardingTable(String logicTableName, String resultTableName, Collection<String> availableTargetNames) {if(availableTargetNames.contains(resultTableName)) {return resultTableName;}boolean rs = ShardingAlgorithmUtil.createShardingTable(logicTableName, resultTableName);if(rs) {availableTargetNames.add(resultTableName);return resultTableName;}return null;}@Overridepublic Properties getProps() {return props;}@Overridepublic void init(Properties properties) {this.props = properties;}
}
1)实现StandardShardingAlgorithm接口,重写doSharding()方法;
2)根据传入的时间分片值,解析出年月,和逻辑表组合,为实际操作的真实表;
3)如果当前的真实表不存在,则调用工具类ShardingAlgorithmUtil创建一个真实表;
工具类ShardingAlgorithmUtil
package com.jingai.sharding.jdbc.util;@Slf4j
public class ShardingAlgorithmUtil {// 表分片符号。如:tb_order_202407private static final String TABLE_SPLIT_SYMBOL = "_";// 配置的数据库源private volatile static Map<String, Map<String, Object>> dataSources = null;public static void init(String url) {Assert.hasText(url, "分片策略不能为空");log.info("数据源获取...");byte[] bytes = new ShardingSphereDriverURL(url).toConfigurationBytes();try {YamlRootConfiguration yamlRootConfiguration = YamlEngine.unmarshal(bytes, YamlRootConfiguration.class);dataSources = yamlRootConfiguration.getDataSources();} catch(Exception e) {e.printStackTrace();log.error("分片策略配置解析失败");throw new IllegalArgumentException("分片策略解析失败");}}/*** 获取所有真实表名*/public static Set<String> getAllTableNameBySchema(String logicTableName) {Assert.notNull(dataSources, "分片策略配置未初始化");Set<String> rs = new HashSet<>();// 获取配置的数据源String startTable = logicTableName + TABLE_SPLIT_SYMBOL;for (Map<String, Object> dataSource : dataSources.values()) {try (Connection conn = DriverManager.getConnection(dataSource.get("url").toString(),dataSource.get("username").toString(), dataSource.get("password").toString())){Statement statement = conn.createStatement();ResultSet resultSet = statement.executeQuery("show tables like '" + startTable + "%'");while (resultSet.next()) {String tableName = resultSet.getString(1);if(StringUtils.hasText(tableName) && tableName.replaceFirst(startTable, "").matches("\\d{6}")) {rs.add(tableName);}}} catch(Exception e) {e.printStackTrace();throw new IllegalArgumentException("数据库连接失败");}}return rs;}/*** 创建分表* @param logicTableName* @param resultTableName* @return*/public static boolean createShardingTable(String logicTableName, String resultTableName) {synchronized (logicTableName.intern()) {for (Map<String, Object> dataSource : dataSources.values()) {try (Connection conn = DriverManager.getConnection(dataSource.get("url").toString(),dataSource.get("username").toString(), dataSource.get("password").toString())){Statement statement = conn.createStatement();log.info("创建{}表", resultTableName);statement.execute("create table if not exists `" + resultTableName + "` like `" + logicTableName + "`;");} catch(Exception e) {e.printStackTrace();throw new IllegalArgumentException("数据库连接失败");}}return true;}}}
1)init(String url) 初始化方法,通过传入的url(application.yml中配置的spring.datasource.url),解析分片配置文件,得到配置的datasources信息;
2)getAllTableNameBySchema(String logicTableName),通过传入的逻辑表(配置中的tb_order),结合配置的datasources信息,创建连接,从数据库中获取表名以tb_order为前缀的表。即数据库中的真实表;
真实表只需从主库中获取即可,此处可以完善。
3)createShardingTable(),结合配置的datasources信息,创建连接,创建真实表;
初始化类
package com.jingai.sharding.jdbc.listener;@Component
@Slf4j
public class ShardingInitRunner implements InitializingBean {@Value("${spring.datasource.url}")private String url;@Overridepublic void afterPropertiesSet() throws Exception {log.info("sharding初始化...");ShardingAlgorithmUtil.init(url);}}
该类获取spring.datasource.url的配置值,在初始化方法中,调用ShardingAlgorithmUtil.init(url),初始化ShardingAlgorithmUtil中的datasource值。
1)如果引入了spring-boot-devtools依赖,开启开发工具。项目启动的时候,ShardingAlgorithmUtil类的类加载器为devtools包下的RestartClassLoader,并执行了初始化,获取了datasources;
2)在分片算法OrderTimeShardingAlgorithm的类加载器为AppClassLoader,OrderTimeShardingAlgorithm中调用ShardingAlgorithmUtil时,会用AppClassLoader重新加载一次ShardingAlgorithmUtil,此时的datasources为null;
3)此时执行ShardingAlgorithmUtil操作数据库时,会报空指针;
如果一定要引入spring-boot-devtools依赖,可以在项目的resources目录下增加一个文件META-INF/spring-devtools.properties,在文件下添加RestartClassLoader额外要加载的包的信息。代码如下:
restart.include.shardingsphere=/shardingsphere-[\\w\\d-\.]+\.jarOrderTimeShardingAlgorithm是在shardingsphere中使用AppClassLoader加载的,所以设置shardingsphere使用RestartClassLoader加载。
实体类
package com.jingai.sharing.jdbc.entity;@Data
@ToString
@TableName("tb_order")
public class OrderEntity {private long orderId;private long memberId;private float totalPrice;private String status;private Date orderTime;}在实体类中,@TableName指定配置中的逻辑表。
Mapper类
package com.jingai.sharing.jdbc.dao;public interface OrderMapper extends BaseMapper<OrderEntity> {@Insert("insert into tb_order(member_id, total_price, status, order_time) values " +"(#{memberId}, #{totalPrice}, #{status}, #{orderTime})")@Options(useGeneratedKeys = true, keyProperty = "orderId")int insert2(OrderEntity order);
}
在4.2的配置中,通过key-generator设置了逻辑表的主键生成策略为雪花算法。当进行数据插入时,需要编写新的插入接口,不能直接使用Mybatis-plus中的insert()接口。因为在默认的insert()接口中,实体对象的orderId为0,不会走配置的雪花算法。
Service类
package com.jingai.sharing.jdbc.service;@Service
public class OrderService extends ServiceImpl<OrderMapper, OrderEntity> {@Resourceprivate OrderMapper orderMapper;public long insert2(OrderEntity order) {int rs = orderMapper.insert2(order);return rs > 0 ? order.getOrderId() : 0;}}
为了便于测试,此处省略了Service的接口类。
Controller类
@RestController
public class OrderController {@Resourceprivate OrderService orderService;@RequestMapping("order")public String order(OrderEntity order) {order.setOrderTime(new Date());long insert = orderService.insert2(order);return insert > 0 ? "success" : "fail";}@RequestMapping("list")public List<OrderEntity> list() {return orderService.list();}}小结
以上为本篇分享的全部内容。以下做一个小结:
1)创建一个基准表tb_order;
2)配置分片规则:标准策略、以订单时间为分片键、自定义分片算法;
3)在分片算法中,根据分片键的值日期值,找到对应月份的表。如果真实表不存在,则创建;
关于本篇内容你有什么自己的想法或独到见解,欢迎在评论区一起交流探讨下吧。
相关文章:

SpringBoot集成Sharding-JDBC-5.3.0实现按月动态建表分表
Sharding-JDBC系列 1、Sharding-JDBC分库分表的基本使用 2、Sharding-JDBC分库分表之SpringBoot分片策略 3、Sharding-JDBC分库分表之SpringBoot主从配置 4、SpringBoot集成Sharding-JDBC-5.3.0分库分表 5、SpringBoot集成Sharding-JDBC-5.3.0实现按月动态建表分表 前言 …...

ubuntu 上安装中文输入法
在Ubuntu上安装中文输入法,通常有以下几种方法: 方法一:使用Fcitx输入法框架和搜狗输入法 安装Fcitx: sudo apt update sudo apt install fcitx fcitx-bin fcitx-table-all 安装搜狗输入法: 首先,从搜狗…...

Postman导出excel文件
0 写在前面 在我们后端写接口的时候,前端页面还没有出来,我们就得先接口测试,在此记录下如何使用postman测试导出excel接口。 如果不会使用接口传参可以看我这篇博客如何使用Postman 1 方法一 2 方法二 3 写在末尾 虽然在代码中写入文件名…...

你还在手动构建Python项目吗?PyBuilder让一切自动化!
在 Python 项目开发中,构建和管理项目是一项繁琐但必不可少的工作。你可能需要处理依赖项、运行测试、生成文档等。这时候,PyBuilder 出场了。它是一个强大的构建自动化工具,可以帮助你简化项目管理,让你更专注于编写代码。 什么…...

WebRTC音视频-前言介绍
目录 效果预期 1:WebRTC相关简介 1.1:WebRTC和RTC 1.2:WebRTC前景和应用 2:WebRTC通话原理 2.1:媒体协商 2.2:网络协商 2.3:信令服务器 效果预期 1:WebRTC相关简介 1.1&…...

centos/rocky容器中安装xfce、xrdp记录
最近需要一台机器来测试rdp连接,使用容器linuxxfcexrdp来实现,在此记录下主要步骤 启动rockylinux容器(其他linux发行版步骤应该相似) docker run -it -p 33891:3389 rockylinux:9.3 bash容器内操作 # 省略替换软件源步骤 ...# …...
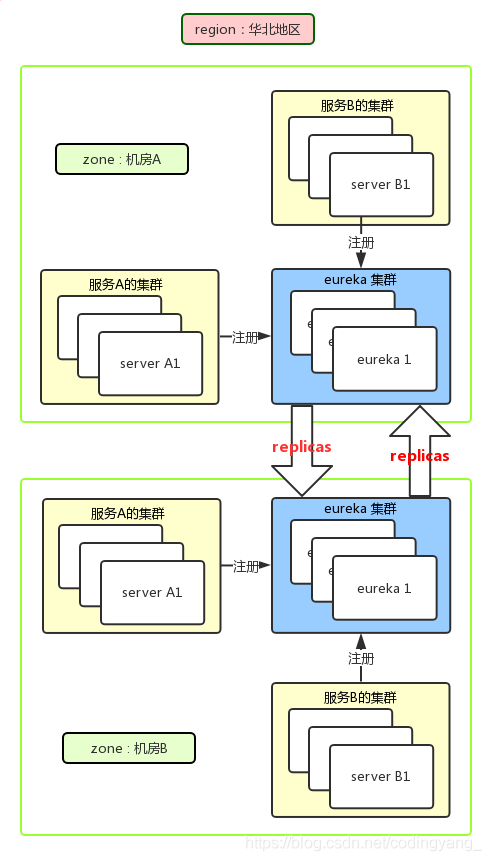
实战:Eureka的概念作用以及用法详解
概叙 什么是Eureka? Netflix Eureka 是一款由 Netflix 开源的基于 REST 服务的注册中心,用于提供服务发现功能。Spring Cloud Eureka 是 Spring Cloud Netflix 微服务套件的一部分,基于 Netflix Eureka 进行了二次封装,主要负责…...

jupyter_contrib_nbextensions安装失败问题
目录 1.文件路径长度问题 2.jupyter不出现Nbextensions选项 1.文件路径长度问题 问题: could not create build\bdist.win-amd64\wheel\.\jupyter_contrib_nbextensions\nbextensions\contrib_nbextensions_help_item\contrib_nbextensions_help_item.yaml: No su…...
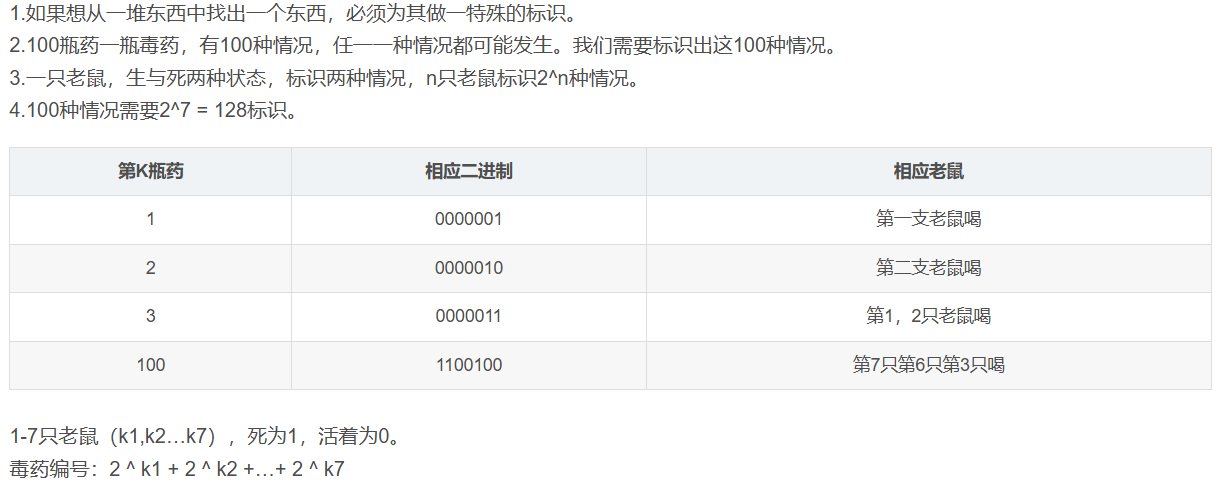
设计模式-Git-其他
目录 设计模式? 创建型模式 单例模式? 啥情况需要单例模式 实现单例模式的关键点? 常见的单例模式实现? 01、饿汉式如何实现单例? 02、懒汉式如何实现单例? 03、双重检查锁定如何实现单例ÿ…...

【C#】计算两条直线的交点坐标
问题描述 计算两条直线的交点坐标,可以理解为给定坐标P1、P2、P3、P4,形成两条线,返回这两条直线的交点坐标? 注意区分:这两条线是否垂直、是否平行。 代码实现 斜率解释 斜率是数学中的一个概念,特别是…...

在项目服务器部署git 并实现自动提交
以下场景适合在服务器当中使用git 方便提交代码,同时不需要外部的git仓库(码云gitee或者github作为管理平台)。依靠服务器本身ssh 连接协议做为git提交的地址,同时利用钩子自动同步项目代码 首先下载git sudo apt update sudo a…...

前缀匹配工具之IP-Prefix
目录 基本概念: 技术背景: 用户需求: 安全需求: 企业内部的访问控制需求: IP-Prefix的配置与语句分析: 调用方式: 尾声 基本概念: IP-Prefix,即IP前缀,相比传统ACL,它能…...

等级保护测评案例分享及合规建议
一、黑龙江省等级保护测评概述 黑龙江省等级保护测评(简称“等保测评”)是依据国家网络安全等级保护制度的要求,对信息系统进行安全等级划分和安全保护能力的评估。等保测评不仅能够帮助企业和组织发现潜在的安全风险,还能够指导…...

GOLLIE : ANNOTATION GUIDELINES IMPROVE ZERO-SHOT INFORMATION-EXTRACTION
文章目录 题目摘要引言方法实验消融研究 题目 Techgpt-2.0:解决知识图谱构建任务的大型语言模型项目 论文地址:https://arxiv.org/abs/2310.03668 摘要 大型语言模型 (LLM) 与指令调优相结合,在泛化到未见过的任务时取得了重大进展。然而,它…...
2024-07-19 Unity插件 Odin Inspector9 —— Validation Attributes
文章目录 1 说明2 验证特性2.1 AssetsOnly / SceneObjectsOnly2.2 ChildGameObjectsOnly2.3 DisallowModificationsIn2.4 FilePath2.5 FolderPath2.6 MaxValue / MinValue2.7 MinMaxSlider2.8 PropertyRange2.9 Required2.10 RequiredIn2.11 RequiredListLength2.12 ValidateIn…...

跨平台WPF音乐商店应用程序
目录 一 简介 二 设计思路 三 源码 一 简介 支持在线检索音乐,支持实时浏览当前收藏的音乐及音乐数据的持久化。 二 设计思路 采用MVVM架构,前后端分离,子界面弹出始终位于主界面的中心。 三 源码 视窗引导启动源码: namesp…...
)
设计模式简述(一)
定义:设计模式指的是在软件开发过程中,经过验证的,用于解决在特定环境下,重复出现的,特定问题的解决方案。创建型设计模式关注对象的创建过程,提供了更灵活、可扩展的对象创建机制。结构型设计模式用于解决…...

OSI参考模型:解析网络通信的七层框架
引言 在现代计算机网络中,OSI(开放式系统互联)参考模型是理解和设计网络通信协议的基础。1978年由国际标准化组织(ISO)提出,OSI模型定义了网络通信的七层结构,每一层都承担着特定的功能&#x…...

QT通用配置文件库(QPreferences)
QT通用配置文件库(QPreferences) QPreferences项目是基于nlohmann/json的qt可视化配置文件库,将配置保存成json格式,并提供UI查看与修改,可通过cmake可快速添加进项目。默认支持基本类型、stl常用容器、基本类型与stl容器组成的结构体&#…...

如何搭建一个RADIUS服务器?
1. 系统环境 1.1.操作系统 Ubuntu-20.04.1 (kernel: 5.15.0-58-generic) 1.2.所需软件 FreeRADIUS MariaDB 1.3.注意事项 本文提到的所有操作,都是以root 身份执行; 2. FreeRADIUS的安装 2.1. 安装FreeRADIUS服务器程序 以…...

C++中显示与隐式加载dll的使用与区别
一、什么是 DLL?DLL(Dynamic Link Library) 是 Windows 下的动态链接库,包含可被多个程序共享的函数、资源或类。使用 DLL 可以实现代码复用、模块化设计和插件机制。在 C 中,调用 DLL 中的函数有两种主要方式…...

告别命令行!用Python脚本批量管理Docker容器,效率提升不止一点点
告别命令行!用Python脚本批量管理Docker容器,效率提升不止一点点每次在终端敲入docker ps、docker stop、docker rm时,你是否想过——当容器数量超过两位数,这种重复劳动是否在消耗你的生命?去年我们团队在迁移微服务架…...

基于Arduino的模块化DIY智能时钟:从RTC到RGB LED的完整实现
1. 项目概述:打造一台高度可定制的DIY RGB LED时钟如果你和我一样,对市面上千篇一律的电子钟感到审美疲劳,同时又对Arduino和电子DIY充满热情,那么这个项目可能就是为你准备的。我们不是在简单地组装一个套件,而是在亲…...
)
告别外部中断!用EnableInterrupt库轻松搞定Arduino Nano多通道PWM读取(附完整代码)
Arduino Nano多通道PWM读取实战:用EnableInterrupt突破硬件限制当你用Arduino Nano开发四轴飞行器或机器人项目时,是否遇到过这样的尴尬:遥控器的四个通道PWM信号需要同时读取,但Nano只有两个外部中断引脚?这个问题困扰…...

孤舟笔记 互联网常用框架篇二 Dubbo服务请求失败怎么处理?集群容错策略你用过几种
文章目录先说结论Failover:换家店试试Failfast:不行就算了Failsafe:忘了这事Failback:回头再说Forking:同时点几家Broadcast:通知所有人怎么选择回答技巧与点评加分回答面试官点评个人网站分布式系统中&…...

Godot4 2D游戏开发避坑指南:TileMap绘制、节点顺序与相机设置的三个常见问题
Godot4 2D游戏开发避坑指南:TileMap绘制、节点顺序与相机设置的三个常见问题当你第一次用Godot4完成一个2D场景搭建时,那种成就感往往会被几个突如其来的bug瞬间击碎——角色神秘消失、背景纹丝不动、屏幕边缘出现诡异黑边。这些问题看似简单,…...

Arcmap实操:如何用‘渔网’给你的地图做一次‘CT扫描’——以韶关市路网密度可视化为例
Arcmap实操:如何用‘渔网’给你的地图做一次‘CT扫描’——以韶关市路网密度可视化为例 想象一下,医生通过CT扫描将人体内部结构分层呈现,而GIS中的"渔网"工具同样能对城市路网进行"切片式"分析。这种空间离散化技术&…...

2026数据治理平台选型:五款产品如何赋能数据中台建设?
一、引言:数据中台的成败,关键在治理在数字化浪潮的席卷下,“数据中台”已成为当代企业信息化架构中的核心战略组件。然而,一个悖论正困扰着大量企业:数据中台的基础设施搭建日趋完善,但真正将数据转化为业…...

中小企无需重型数据中台:轻量化数据体系搭建完整方案
过去几年,“数据中台”一度成为企业数字化的标配热词。大量中小企业盲目跟风搭建重型数据中台,投入高额成本、耗费数月甚至数年周期,最终落地效果极差:功能冗余、运维复杂、使用率低、投入产出比失衡。大量项目最终沦为“摆设式中…...

终极STL到STEP转换指南:如何实现3D打印模型到CAD设计的无缝衔接
终极STL到STEP转换指南:如何实现3D打印模型到CAD设计的无缝衔接 【免费下载链接】stltostp Convert stl files to STEP brep files 项目地址: https://gitcode.com/gh_mirrors/st/stltostp 在数字化制造和工程设计领域,STL到STEP转换已成为连接3D…...