Kaggle实战入门:泰坦尼克号生生还预测
Kaggle实战入门:泰坦尼克号生生还预测
- 1. 加载数据
- 2. 特征工程
- 3. 模型训练
- 4. 模型部署
泰坦尼克号(Titanic),又称铁达尼号,是当时世界上体积最庞大、内部设施最豪华的客运轮船,有“永不沉没”的美誉,被称为“世界工业史上的奇迹”。1912年4月10日,她在从英国南安普敦出发,驶往美国纽约的首次处女航行中,不幸与一座冰山相撞,1912年4月15日凌晨2时20分左右,船体断裂成两截,永久沉入大西洋底3700米处,2224名船员及乘客中,逾1500人丧生。
而以此事件为背景的《泰坦尼克号》则是成为了电影史上的传奇,该片由詹姆斯•卡梅隆执导,莱昂纳多•迪卡普里奥、凯特•温斯莱特领衔主演。在中国大陆上映的时间是1998年4月,虽然时隔25年,泰坦尼克号也已沉没111年,但每当影片主题曲my heart will go on中悠扬的苏格兰风笛声响起时,每个人都会再次被带回那艘奥林匹克级的豪华邮轮。
机器学习领域,著名的数据科学竞赛平台kaggle的入门经典也是以泰坦尼克号事件为背景。该问题通过训练数据(train.csv)给出891名乘客的基本信息以及生还情况,通过训练数据生成合适的模型,并根据另外418名乘客的基本信息(test.csv)预测其生还情况,并将生还情况以要求的格式(gender_submission.csv)提交,kaggle会根据你的提交情况给出评分与排名。
1. 加载数据
import pandas as pd
file = r'datasets/train.csv'
data = pd.read_csv(file)
加载数据完成后,可使用内置方法对数据进行探查,初步认识数据。
data.head(5) #查看前5行数据:data.iloc[:5] 或者 data.loc[:5]
输出

data.info() #查看整体信息
输出
<class ‘pandas.core.frame.DataFrame’>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
可以看出,数据共有11个字段,其中Age有714个非空值,而Cabin仅有204个非空值。每个字段含义如下:
| 字段名 | 字段含义 |
|---|---|
| PassengerId | 乘客ID |
| Pclass | 客舱等级 |
| Name | 乘客姓名 |
| Sex | 性别 |
| Age | 年龄 |
| SibSp | 兄弟姐妹、配偶 |
| Parch | 父母与子女 |
| Ticket | 船票编号 |
| Fare | 票价 |
| Cabin | 客舱号 |
| Embarked | 登船港口 |
data.Pclass.unique() #查看字段的取值情况
输出
array([3, 1, 2])
data.Pclass.value_counts() #查看字段取值的统计值
输出
3 491
1 216
2 184
Name: Pclass, dtype: int64
2. 特征工程
特征工程(Feature Engineering)极其重要,特征的选择与处理直接影响到模型效果。实际中,特征工程很多时候是依赖业务经验的。
通过数据探查,可以发现该数据包含以下几类属性
- 标称属性(Nominal attribute):Sex(性别)、Embarked(登船港口)
- 标称属性(Ordinal attribute):Pclass(客舱等级)
- 数值属性(Numeric attribute):Age(年龄)、SibSp(兄弟姐妹、配偶)、Parch(父母与子女)、Fare(票价)
- 其他:Name(乘客姓名)、Ticket(船票编号)、Cabin(客舱号)
(1)统计分析各属性与生还结果的相关性
针对Sex、Pclass、Embarkd与Survived的关系,可使用crosstab函数(或groupby函数)分别进行聚合统计,计算相应的百分比以实现归一化,并做图。
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS'] #Mac系统设置中文显示
plt.rcParams['axes.unicode_minus'] = Falsefig = plt.figure()
fig.set(alpha=0.65) # 设置图像透明度
ax1=fig.add_subplot(131)
ax2=fig.add_subplot(132)
ax3=fig.add_subplot(133)cou_Sex = pd.crosstab(data.Sex,data.Survived)
#或者用counts_Sex = data.groupby(['Sex','Survived']).size().unstack
cou_Sex.rename({0:'未生还',1:'生还'},axis=1,inplace=True)
cou_Sex.rename({'female':'F','male':'M'},inplace=True)
pct_Sex = cou_Sex.div(cou_Sex.sum(1).astype(float),axis=0) #归一化
pct_Sex.plot(kind='bar',stacked=True,title=u'不同性别的生还情况',ax=ax1)cou_Pclass = pd.crosstab(data.Pclass,data.Survived)
cou_Pclass.rename({0:'未生还',1:'生还'},axis=1,inplace=True)
pct_Pclass = cou_Pclass.div(cou_Pclass.sum(1).astype(float),axis=0)
pct_Pclass.plot(kind='bar',stacked=True,title=u'不同等级的生还情况',ax=ax2,sharey=ax1)cou_Embarked = pd.crosstab(data.Embarked,data.Survived)
cou_Embarked.rename({0:'未生还',1:'生还'},axis=1,inplace=True)
pct_Embarked = cou_Embarked.div(cou_Embarked.sum(1).astype(float),axis=0)
pct_Embarked.plot(kind='bar',stacked=True,title=u'不同登录点生还情况',ax=ax3,sharey=ax1)
输出

可直观的看出生还情况受性别(女性乘客生还概率较高)、客舱等级(一等舱乘客生还概率较高)、登船港口(C港口登船乘客生还概率较高)的影响。
针对数值属性的Age、Fare,可使用cut函数将其离散化后,再进行统计分析。
fig = plt.figure()
fig.set(alpha=0.65) # 设置图像透明度
ax1=fig.add_subplot(121)
ax2=fig.add_subplot(122)bins=[0,14,30,45,60,80]
cats=pd.cut(data.Age.as_matrix(),bins) #Age离散化
data.Age=cats.codescou_Age = pd.crosstab(data.Age,data.Survived)
cou_Age.rename({0:'未生还',1:'生还'},axis=1,inplace=True)
pct_Age = cou_Age.div(cou_Age.sum(1).astype(float),axis=0)
pct_Age.plot(kind='bar',stacked=True,title=u'不同年龄的生还情况',ax=ax1)bins=[0,15,30,45,60,300]
cats=pd.cut(data.Fare.as_matrix(),bins) #Fare离散化
data.Fare=cats.codescou_Fare = pd.crosstab(data.Fare,data.Survived)
cou_Fare.rename({0:'未生还',1:'生还'},axis=1,inplace=True)
pct_Fare = cou_Fare.div(cou_Fare.sum(1).astype(float),axis=0)
pct_Fare.plot(kind='bar',stacked=True,title=u'不同票价的生还情况',ax=ax2,sharey=ax1)

可直观的看出年龄越小生还概率越高、票价越高生活概率越高(-1表示缺失值)。
(2)计算相关系数分析各属性与生还结果的相关性
使用corr函数计算属性aaa和bbb之间的相关性r(a,b)r(a,b)r(a,b),corr函数默认使用Person系数,取值在[−1,1][-1,1][−1,1]之间。
- r(a,b)>0r(a,b)>0r(a,b)>0表示属性aaa和bbb正相关
- r(a,b)<0r(a,b)<0r(a,b)<0表示属性aaa和bbb负相关
- r(a,b)=0r(a,b)=0r(a,b)=0表示属性aaa和bbb相互独立。
def dataProcess(data):mapTrans={'female':0,'male':1,'S':0,'C':1,'Q':2} #属性值转换data.Sex=data.Sex.map(mapTrans)data.Embarked=data.Embarked.map(mapTrans)data.Embarked=data.Embarked.fillna(data.Embarked.mode()[0]) #使用众数填充data.Age=data.Age.fillna(data.Age.mean()) #均值填充缺失年龄data.Fare=data.Fare.fillna(data.Fare.mean()) #均值填充缺失Farereturn datadata = data = pd.read_csv(file)#重新载入数据
data = dataProcess(data)
data.iloc[:,1:].corr()['Survived']
输出
Survived 1.000000
Pclass -0.338481
Sex -0.543351
Age -0.069809
SibSp -0.035322
Parch 0.081629
Fare 0.257307
Embarked 0.106811
Name: Survived, dtype: float64
可以看出Survived与Pclass、Sex、Fare、Embarked相关性较大。
使用seaborn库的热力图可视化展示:
import seaborn as sns #导入seaborn绘图库
sns.set(style='white', context='notebook', palette='deep')
sns.heatmap(data.iloc[:,1:].corr(),annot=True, fmt = ".2f", cmap = "coolwarm")
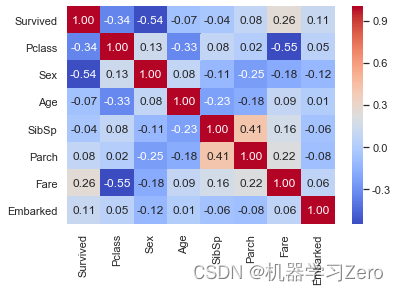
通过上述分析,选择[‘Pclass’, ‘Sex’, ‘Age’, ‘Fare’, ‘Embarked’]作为特征,其中使用map方法将Sex、Embarked映射为数值,并用fillna方法填充Embark、Age、Fare的缺失值。
3. 模型训练
构建决策树模型,并使用fit方法完成模型的训练。
feature =['Pclass','Sex','Age','Fare','Embarked']
X = data[feature] #选择特征
y = data.Survived #标签from sklearn.tree import DecisionTreeClassifier as DT
clf = DT() #建立模型
clf.fit(X,y) #训练模型
可使用准确率(score方法)和混淆矩阵(metrics.confusion_matrix方法)对模型进行评估。
print('%.3f' %(clf.score(X,y))) #准确率
输出
0.980
from sklearn import metrics
metrics.confusion_matrix(y, clf.predict(X)) #混淆矩阵
输出
array([[546, 3],
[ 15, 327]])
4. 模型部署
加载test.csv文件的数据,进行处理,并使用predict方法预测,将生成的结果文件在Kaggle页面点击Submit Predictions进行提交,Kaggle会给出准确率和排名。
data_sub = pd.read_csv(r'datasets/test.csv') #加载测试数据
data_sub = dataProcess(data_sub) #处理测试数据
X_sub = data_sub[feature] #提取测试数据特征
y_sub = clf.predict(X_sub) #使用模型预测数据标签
result = pd.DataFrame({'PassengerId':data_sub['PassengerId'].as_matrix(), 'Survived':y_sub}) #形成要求格式
result.to_csv(r'D:\[DataSet]\1_Titanic\submission.csv', index=False) #输出至文件
相关文章:
Kaggle实战入门:泰坦尼克号生生还预测
Kaggle实战入门:泰坦尼克号生生还预测1. 加载数据2. 特征工程3. 模型训练4. 模型部署泰坦尼克号(Titanic),又称铁达尼号,是当时世界上体积最庞大、内部设施最豪华的客运轮船,有“永不沉没”的美誉ÿ…...
)
【大汇总】11个Python开发经典错误(1)
“但是太阳,他每时每刻都是夕阳也都是旭日。当他熄灭着走下山去收尽苍凉残照之际,正是他在另一面燃烧着爬上山巅散烈烈朝晖之时。” --------史铁生《我与地坛》 🎯作者主页:追光者♂🔥 🌸个人简介:计算机专业硕士研究生💖、2022年CSDN博客之星人工智能领…...
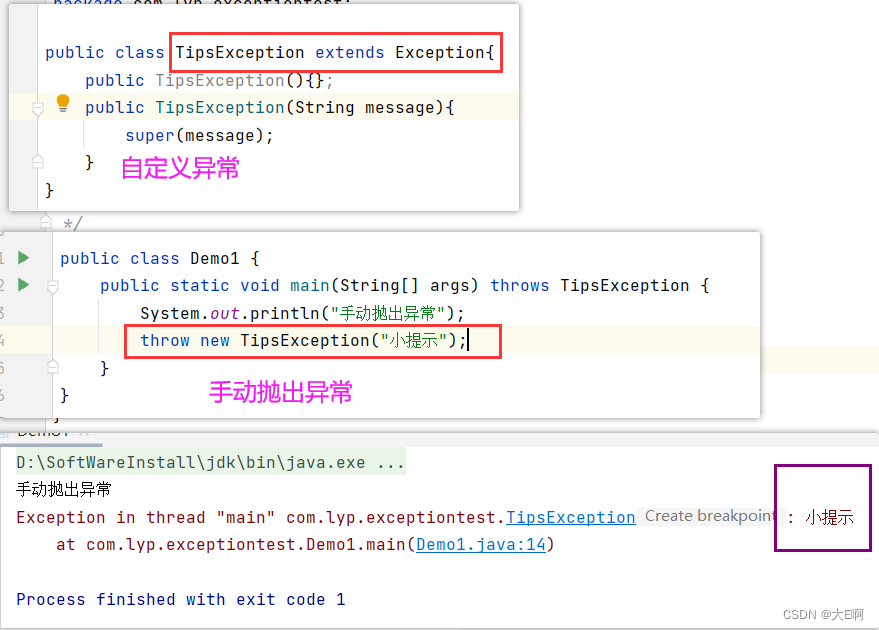
Java中的异常
程序错误一般分为三种:编译错误: 编写程序时没有遵循语法规则,编译程序能够自己发现错误并提示位置和原因。运行错误:程序在执行的时候运行环境发现了不能执行的操作。比如,JVM出错了,内存溢出等。逻辑错误…...

L2-022 重排链表 L2-002 链表去重
给定一个单链表 L1 →L2→⋯→L n−1 →L n ,请编写程序将链表重新排列为 L n →L 1 →L n−1 →L 2 →⋯。例如:给定L为1→2→3→4→5→6,则输出应该为6→1→5→2→4→3。 输入格式: 每个输入包含1个测试用例。每个测试用例第1行…...
【手撕八大排序】——插入排序
文章目录插入排序概念插入排序分为2种一 .直接插入排序直接插入排序时间复杂度二.希尔排序希尔排序时间复杂度效率比较插入排序概念 直接插入排序是从一个有序的序列中选择一个合适的位置进行插入,这个合适的位置取决于是要升序排序还是降序排序。 每一次进行排序…...
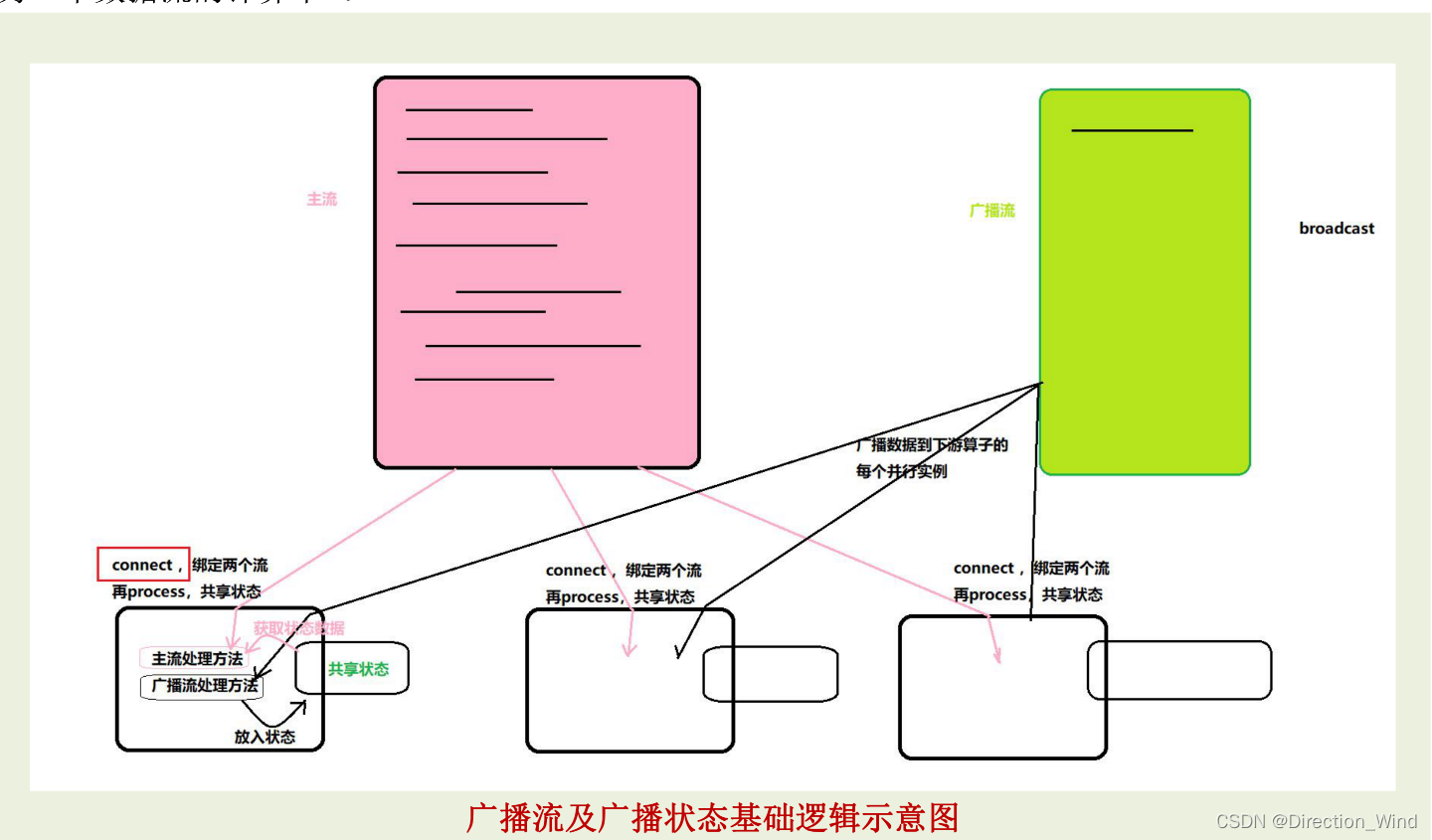
flink多流操作(connect cogroup union broadcast)
flink多流操作1 分流操作2 connect连接操作2.1 connect 连接(DataStream,DataStream→ConnectedStreams)2.2 coMap(ConnectedStreams → DataStream)2.3 coFlatMap(ConnectedStreams → DataStream)3 union操作3.1 uni…...

漫画:什么是快速排序算法?
这篇文章,以对话的方式,详细着讲解了快速排序以及排序排序的一些优化。 一禅:归并排序是一种基于分治思想的排序,处理的时候可以采取递归的方式来处理子问题。我弄个例子吧,好理解点。例如对于这个数组arr[] { 4&…...

vue 3.0组件(下)
文章目录前言:一,透传属性和事件1. 如何“透传属性和事件”2.如何禁止“透传属性和事件”3.多根元素的“透传属性和事件”4. 访问“透传属性和事件”二,插槽1. 什么是插槽2. 具名插槽3. 作用域插槽三,单文件组件CSS功能1. 组件作用…...
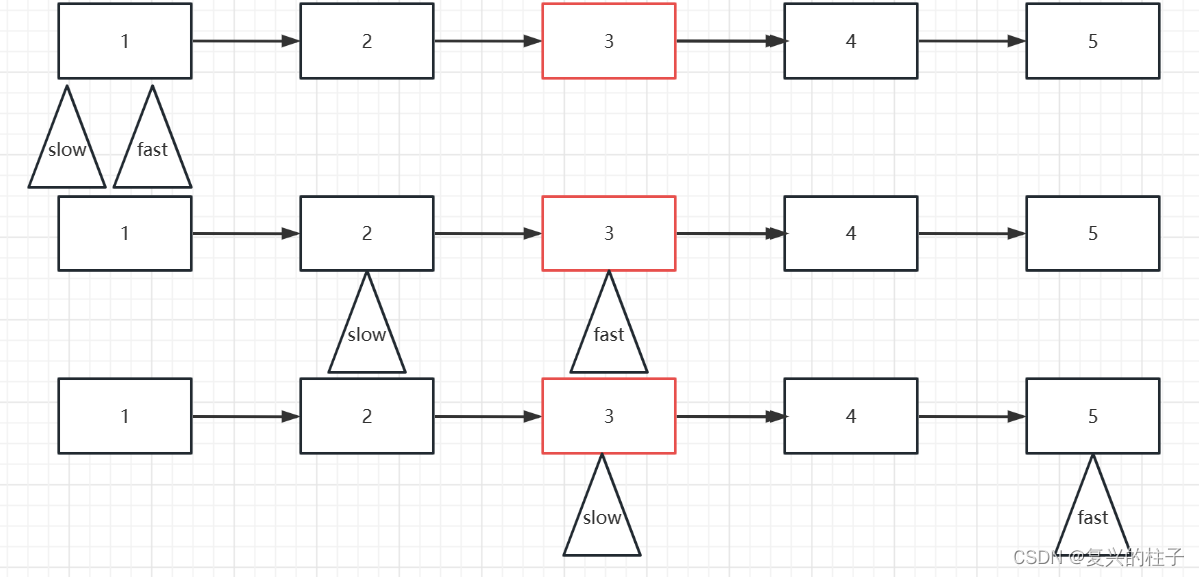
双指针 -876. 链表的中间结点-leetcode
开始一个专栏,写自己的博客 双指针,也算是作为自己的笔记吧! 双指针从广义上来说,是指用两个变量在线性结构上遍历而解决的问题。狭义上说, 对于数组,指两个变量在数组上相向移动解决的问题;对…...

Linux之运行级别
文章目录一、指定运行级别基本介绍CentOS7后运行级别说明一、指定运行级别 基本介绍 运行级别说明: 0:关机 1:单用户【找回丢失密码】 2:多用户状态没有网络服务 3:多用户状态有网络服务 4:系统未使用保留给用户 5:图形界面 6:系统重启 常用运行级别是3和5,也可以…...

python搭建web服务器
前言:相信看到这篇文章的小伙伴都或多或少有一些编程基础,懂得一些linux的基本命令了吧,本篇文章将带领大家服务器如何部署一个使用django框架开发的一个网站进行云服务器端的部署。 文章使用到的的工具 Python:一种编程语言&…...
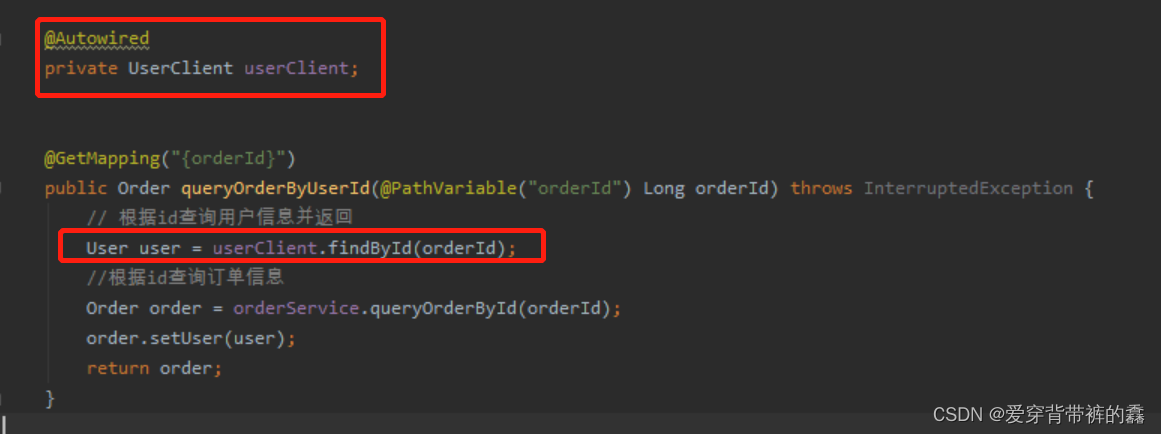
【SpringCloud】SpringCloud Feign详解
目录前言SpringCloud Feign远程服务调用一.远程调用逻辑图二.两个服务的yml配置和访问路径三.使用RestTemplate远程调用四.构建Feign五.自定义Feign配置六.Feign配置日志七.Feign调优八.抽离Feign前言 微服务分解成多个不同的服务,那么多个服务之间怎么调用呢&…...

更改Hive元数据发生的生产事故
今天同事想在hive里用中文做为分区字段。如果用中文做分区字段的话,就需要更改Hive元 数据库。结果发生了生产事故。导致无法删除表和删除分区。记一下。 修改hive元数据库的编码方式为utf后可以支持中文,执行以下语句: alter table PARTITI…...
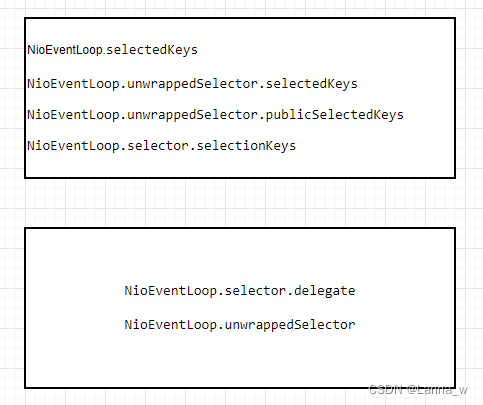
《Netty》从零开始学netty源码(八)之NioEventLoop.selector
目录java原生的WEPollSelectorImplnetty的SelectionKey容器SelectedSelectionKeySetnetty的SelectedSelectionKeySetSelectorSelectorTupleopenSelector每一个NioEventLoop配一个选择器Selector,在创建NioEventLoop的构造函数中会调用其自身方法openSelector获取sel…...
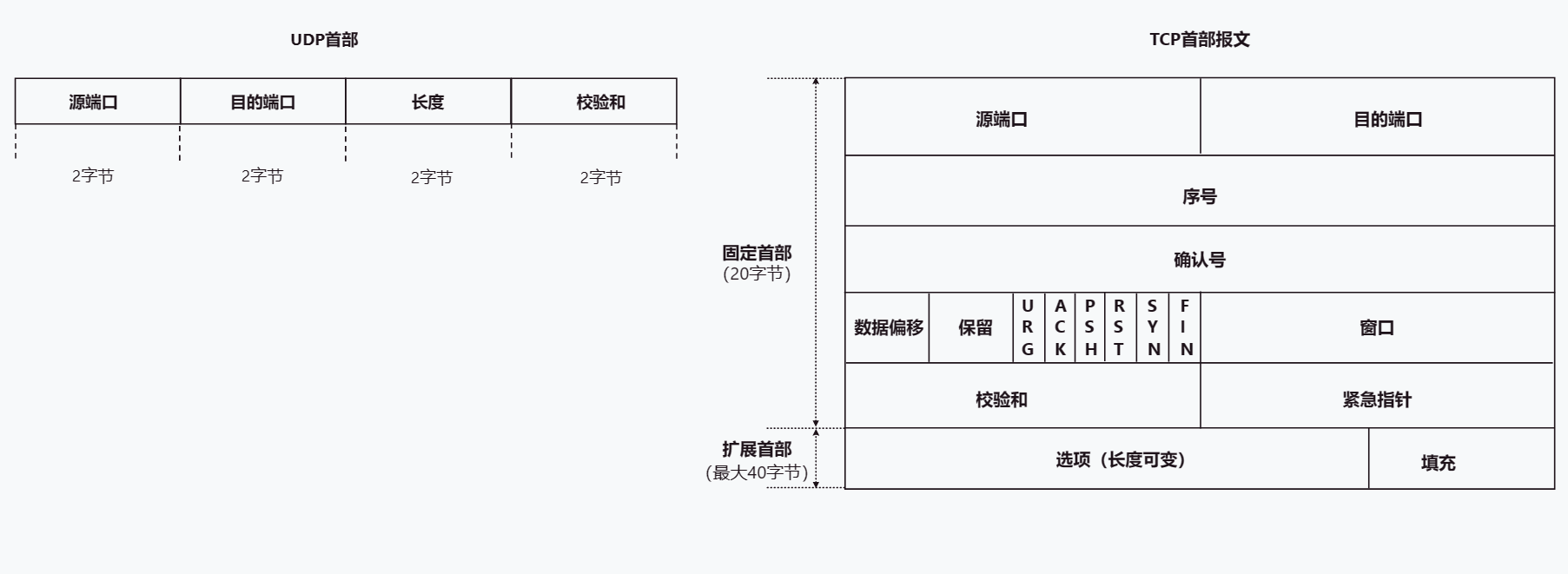
TCP UDP详解
文章目录TCP UDP协议1. 概述2. 端口号 复用 分用3. TCP3.1 TCP首部格式3.2 建立连接-三次握手3.3 释放连接-四次挥手3.4 TCP流量控制3.5 TCP拥塞控制3.6 TCP可靠传输的实现3.7 TCP超时重传4. UDP5.TCP与UDP的区别TCP UDP协议 1. 概述 TCP、UDP协议是TCP/IP体系结构传输层中的…...
超详细淘宝小程序的接入开发步骤
本文是向大家介绍的关于工作中遇到的如何对接淘宝小程序开发的步骤,它能够帮助大家省略在和淘宝侧对接沟通过程中的一些繁琐问题,便捷大家直接快速开展工作~~一、步骤演示1、首先我们打开淘宝开放平台,进入控制台2、进入控制台后,…...

【Python】正则表达式re库
文章目录函数re.match函数re.search函数re.findall函数re.compile函数re.sub函数re.split函数修饰符正则表达式模式正则表达式实例函数 re.match函数 re.match()函数用于尝试从字符串的 起始位置 匹配一个模式,匹配成功返回一个匹配对象,否则返回None。…...

JDK8使用Visual VM根据Dump文件排查OutOfMemoryError生产问题思路
文章目录1. 前言2. 堆内存溢出3. GC执行异常4. 元空间内存溢出5. 创建线程异常6. 内存交换问题7. 数组长度过大8. 系统误杀异常1. 前言 当系统异常产生了dump文件需要我们对其进行排查时,其本质上考验的是我们对于Java运行时内存结构的知识掌握是否牢固以及对业务代…...
2023年网络安全比赛--网络安全事件响应中职组(超详细)
一、竞赛时间 180分钟 共计3小时 二、竞赛阶段 1.找出黑客植入到系统中的二进制木马程序,并将木马程序的名称作为Flag值(若存在多个提交时使用英文逗号隔开,例如bin,sbin,…)提交; 2.找出被黑客修改的系统默认指令,并将被修改的指令里最后一个单词作为Flag值提交; 3.找出…...

【半监督学习】3、PseCo | FPN 错位对齐的高效半监督目标检测器
文章目录一、背景二、方法2.1 基础框架结构2.2 带噪声的伪边界框学习2.3 多视图尺度不变性学习三、实验论文:PseCo: Pseudo Labeling and Consistency Training for Semi-Supervised Object Detection 代码:https://github.com/ligang-cs/PseCo 出处&a…...

如何通过 SEO 和 ASO 提高网站和应用的转化率
SEO和ASO:双管齐下提高网站和应用的转化率 在当今数字化时代,网站和应用的成功不仅取决于其功能和用户体验,更在于如何吸引流量并将其转化为实际用户。这就需要我们深入了解和运用搜索引擎优化(SEO)和应用商店优化&am…...

PyTorch 2.8 镜像实战:基于LSTM的时序预测模型开发与部署
PyTorch 2.8 镜像实战:基于LSTM的时序预测模型开发与部署 1. 时序预测的LSTM解决方案 时序数据预测是AI领域最具挑战性的任务之一。传统统计方法在处理复杂非线性关系时往往力不从心,而长短期记忆网络(LSTM)凭借其独特的记忆单元…...

OpenClaw定时任务配置:Phi-3-mini-128k-instruct每日早报自动生成
OpenClaw定时任务配置:Phi-3-mini-128k-instruct每日早报自动生成 1. 为什么需要自动化早报服务 每天早上打开电脑第一件事,就是花20分钟浏览各大新闻网站,手动整理成简报发到团队群。这种重复劳动持续三个月后,我开始思考&…...

StructBERT情感分类镜像保姆级教程:GPU加速中文情感分析快速上手
StructBERT情感分类镜像保姆级教程:GPU加速中文情感分析快速上手 10分钟学会部署和使用专业级中文情感分析模型,让AI帮你读懂用户情绪 1. 前言:为什么要用StructBERT做情感分析? 你有没有遇到过这些情况? 电商平台上…...
)
BUCK变换器断续模式实战:从公式推导到MATLAB仿真验证(附代码)
BUCK变换器断续模式实战:从公式推导到MATLAB仿真验证(附代码) 在电力电子领域,BUCK变换器作为最基础的降压型拓扑结构,其工作模式的理解直接影响着电源设计的可靠性。许多初学者往往对断续模式(DCM)的特性感到困惑——…...
)
从216MB到19MB:某头部智能网关固件编译瘦身全过程(含patch文件与CI/CD集成checklist)
第一章:边缘计算 C 轻量化编译方法概览在资源受限的边缘设备(如工业网关、嵌入式摄像头、车载ECU)上部署C应用,传统编译流程常导致二进制体积臃肿、启动延迟高、内存占用超标。轻量化编译并非简单裁剪功能,而是围绕**目…...

跨境电商利器:OpenClaw+Phi-3-vision-128k-instruct自动翻译商品图片
跨境电商利器:OpenClawPhi-3-vision-128k-instruct自动翻译商品图片 1. 为什么需要自动化图片翻译 作为跨境电商卖家,我每天都要处理大量商品图片的翻译工作。传统流程需要人工截图、翻译、PS替换文字、再导出图片,整个过程耗时耗力。一张简…...

32-字体反爬
本文需要借助工具:fontcreator,或者在线网站:字体设计在线网站 字体反爬介绍 字体反爬是网站常用的前端反爬手段,核心逻辑是用自定义字体文件替代明文文本,爬虫自动化也无法拿到正确的明文数据 字体反爬原理 本文主…...

已登CVPR&Nature子刊,小波变换+深度学习杀疯了 !!
融合小波变换的深度学习模型是当前的研究热点之一,这个交叉领域热度高、前景好、创新空间大,只要选对结合点和方法,冲顶会顶刊问题不大。比如Transformer、GNN、KAN、CNN、mamba等,就是目前比较前沿而且热度很高的结合方式&#x…...

从进度到资源:7款适合PMO的项目集管理系统
本文将深入对比7大项目集管理系统:PingCode、Worktile、GanttPRO、奥博思、TAPD、Trello、氚云 在管理大型、跨部门的复杂项目时,PMO(项目管理办公室)常面临资源冲突、信息孤岛和进度失控的挑战。传统的单项目管理工具已难以承载组…...