PRISM-Python 中的规则一个简单的 Python 规则感应系统
欢迎来到雲闪世界.PRISM 是一种现有算法(尽管我确实创建了一个 Python 实现),PRISM 相对简单,但在机器学习中,有时最复杂的解决方案效果最好,有时最简单的解决方案效果最好。然而,当我们希望建立可解释的模型时,简单性会带来很大的好处。
PRISM 是一种规则归纳工具。也就是说,它创建一组规则来根据其他特征预测目标特征。
规则在机器学习中至少有几个非常重要的用途。一是预测。与决策树、线性回归、GAM、ikNN、加性决策树、决策表和少数其他工具类似,它们可以提供可解释的分类模型。
规则也可以简单地用作理解数据的一种技术。事实上,即使没有标签,它们也可以以无监督的方式使用,创建一组规则来预测每个特征之间的区别(依次将表中的每个特征视为目标列),这可以突出显示数据中的任何强模式。
还有其他用于在 Python 中创建规则的工具,包括非常强大的imodels 库。但是,创建一组既准确又易于理解的规则仍然具有挑战性。规则感应系统通常无法创建合理准确的模型,或者,如果可以,也只能通过创建许多规则和包含许多术语的规则来实现。例如,以下规则:
如果颜色 =’蓝色’ 并且高度 < 3.4 并且宽度 > 3.2 并且长度 > 33.21 并且温度 > 33.2 并且温度 < 44.2 并且宽度 < 5.1 并且重量 > 554.0 并且 … 那么…
如果规则包含超过五到十个术语,它们就会变得难以遵循。如果术语足够多,规则最终可能会变得无法解释。如果规则集包含的规则数量超过中等数量,整个规则集就会变得难以遵循(如果每条规则都包含许多术语,情况就更是如此)。
PRISM 规则
PRISM 是一个规则归纳系统,由 Chendrowska 首次提出,并在《数据挖掘原理》中进行了描述。
PRISM 支持生成规则,既可以作为描述模型:描述表中的模式(以特征之间的关联形式);也可以作为预测模型。它通常会生成一组非常简洁、清晰的可解释规则。
作为一个预测模型,它提供了所谓的全局和局部解释(在可解释人工智能(XAI)中使用的术语中)。也就是说,它是完全可解释的,既可以理解整个模型,也可以理解单个预测。
测试多个规则感应系统后,我经常发现 PRISM 生成的规则集最简洁。不过,没有一个系统始终表现最佳,通常需要尝试一些规则感应工具。
生成的规则采用析取范式(AND 的 OR),每个单独的规则都是一个或多个项的 AND,每个项的形式为特征 = 值,其中某个值位于该特征的值集合中。例如:生成的规则可能采用以下形式:
目标值“蓝色”的规则:
- 如果 feat_A = ‘hot’ 并且 feat_C = ‘round’ 那么 ‘blue’
- 如果 feat_A = ‘warm’ 并且 feat_C = ‘square’ 那么 ‘blue’
目标值“red”的规则:
- 如果 feat_A = ‘冷’ 并且 feat_C = ‘三角形’ 那么 ‘红色’
- 如果 feat_A = ‘cool’ 并且 feat_C = ‘triangular’ 那么 ‘red’
该算法严格适用于 X 和 Y 列中的分类特征。因此,此实现将自动对所有数字列进行分箱以支持该算法。默认情况下,使用三个等计数分箱(代表特征的低、中、高值),但这可以通过 nbins 参数进行配置(可以使用更多或更少的分箱)。
PRISM 算法
对于本节,我们假设使用 PRISM 作为预测模型,具体来说是作为分类器。
该算法的工作原理是为目标列中的每个类创建一组规则。例如,如果在 Iris 数据集上执行,其中目标列中有三个值(Setosa、Versicolour 和 Virginica),那么将有一组与 Setosa 相关的规则、一组与 Versicolour 相关的规则和一组与 Virginica 相关的规则。
生成的规则应以“先触发规则”的方式读取,因此所有规则都以合理的顺序生成和呈现(从与每个目标类别最相关到最不相关)。例如,检查与 Setosa 相关的规则集,我们将有一组预测鸢尾花是否为 Setosa 的规则,这些规则将按预测性从高到低的顺序排列。其他两个类别的规则集也是如此。
生成规则
我们将在此描述 PRISM 用于为一个类别生成一组规则的算法。假设我们即将使用 Iris 数据集为 Setosa 类别生成规则。
首先,PRISM 会找到可用来预测目标值的最佳规则。Setosa 的第一条规则会预测尽可能多的 Setosa 记录。也就是说,我们会在其他特征的某个子集中找到唯一值集,这些值集最能预测记录何时会是 Setosa。这是 Setosa 的第一条规则。
但是,第一条规则不会涵盖所有 Setosa 记录,因此我们创建了额外的规则来涵盖 Setosa 的剩余行(或尽可能多的行)。
当发现每个规则时,将删除与该规则匹配的行,并找到下一个规则来最好地描述该目标值的剩余行。
每个规则可以有任意数量的术语。
对于目标列中的每个其他值,我们再次从完整数据集开始,在发现规则时删除行,并生成其他规则来解释此目标类值的剩余行。因此,在找到 Setosa 的规则后,PRISM 将生成 Versicolour 的规则,然后生成 Virginica 的规则。
覆盖范围和支持
此实现通过输出与每个规则相关的统计数据增强了数据挖掘原理中描述的算法,因为许多导出的规则可能比其他导出的规则更相关,或者相反,其重要性大大降低。
此外,跟踪有关每条规则的简单统计数据允许提供参数来指定每条规则的最小覆盖率(该规则适用的训练数据中的最小行数);以及最小支持度(目标类别与与规则匹配的行的期望值匹配的最小概率)。这些有助于减少噪音(额外的规则只会给模型的描述或预测能力增加很小的价值),但可能会导致某些目标类别的规则很少或没有规则,可能无法覆盖一个或多个目标列值的所有行。在这些情况下,用户可能希望调整这些参数。
与决策树的比较
决策树是最常见的可解释模型之一,很可能是最常见的。当足够小时,它们可以合理地解释,可能与任何模型类型一样可解释,并且它们对于许多问题(当然不是全部)都可以相当准确。然而,它们作为可解释模型确实有局限性,而 PRISM 的设计就是为了解决这个问题。
决策树并非专门为可解释性而设计的;决策树的一个方便属性就是它们具有可解释性。例如,它们通常会变得比容易理解的要大得多,并且经常会出现重复的子树,因为与特征的关系必须在树中重复多次才能被正确捕获。
此外,单个预测的决策路径可能包含与最终预测无关甚至具有误导性的节点,从而进一步降低可压缩性。
Cendrowska 的论文提供了一些无法用树轻易表示的简单规则集的示例。例如:
- 规则 1:如果 a = 1 并且 b = 1,则 class = 1
- 规则 2:如果 c = 1 并且 d = 1,则 class = 1
这些导致了一棵令人惊讶的复杂树。事实上,这是一种导致决策树过于复杂的常见模式:“有两个(底层)规则没有共同的属性,这种情况在实践中很可能经常发生” [3]
规则通常可以生成比决策树更易于解释的模型(尽管反之亦然),并且对于任何需要可解释模型的项目来说,规则都非常有用。而且,如果目标不是构建预测模型,而是理解数据,那么使用多个模型可能有利于捕获数据的不同元素。
安装
该项目由一个Python 文件组成,可以使用以下命令下载并包含在任何项目中:
从prism_rules导入PrismRules
使用 sklearn 的 Wine 数据集的示例
github 页面提供了两个示例笔记本,提供了使用该工具的简单但全面的示例。不过,该工具非常简单。要使用该工具生成规则,只需创建一个 PrismRules 对象并使用数据集调用 get_prism_rules(),指定目标列:
import pandas as pd from sklearn.datasets import load_winedata = datasets.load_wine() df = pd.DataFrame(data.data, columns=data.feature_names) df['Y'] = data['target'] display(df.head())prism = PrismRules() _ = prism.get_prism_rules(df, 'Y')
结果
该数据集在目标列中有三个值,因此将生成三组规则:
................................................................ Target: 00 ................................................................proline = High AND alcohol = HighSupport: the target has value: '0' for 100.000% of the 39 rows matching the rule Coverage: the rule matches: 39 out of 59 rows for target value: 0. This is:66.102% of total rows for target value: 021.910% of total rows in dataproline = High AND alcalinity_of_ash = LowSupport: The target has value: '0' for 100.000% of the 10 remaining rows matching the rule Coverage: The rule matches: 10 out of 20 rows remaining for target value: '0'. This is:50.000% of remaining rows for target value: '0'16.949% of total rows for target value: 05.618% of total rows in data0................................................................ Target: 1 ................................................................ color_intensity = Low AND alcohol = LowSupport: the target has value: '1' for 100.000% of the 46 rows matching the rule Coverage: the rule matches: 46 out of 71 rows for target value: 1. This is:64.789% of total rows for target value: 125.843% of total rows in datacolor_intensity = LowSupport: The target has value: '1' for 78.571% of the 11 remaining rows matching the rule Coverage: The rule matches: 11 out of 25 rows remaining for target value: '1'. This is:44.000% of remaining rows for target value: '1'15.493% of total rows for target value: 16.180% of total rows in data................................................................ Target: 2 ................................................................ flavanoids = Low AND color_intensity = MedSupport: the target has value: '2' for 100.000% of the 16 rows matching the rule Coverage: the rule matches: 16 out of 48 rows for target value: 2. This is:33.333% of total rows for target value: 28.989% of total rows in dataflavanoids = Low AND alcohol = HighSupport: The target has value: '2' for 100.000% of the 10 remaining rows matching the rule Coverage: The rule matches: 10 out of 32 rows remaining for target value: '2'. This is:31.250% of remaining rows for target value: '2'20.833% of total rows for target value: 25.618% of total rows in dataflavanoids = Low AND color_intensity = High AND hue = LowSupport: The target has value: '2' for 100.000% of the 21 remaining rows matching the rule Coverage: The rule matches: 21 out of 22 rows remaining for target value: '2'. This is:95.455% of remaining rows for target value: '2'43.750% of total rows for target value: 211.798% of total rows in data
对于每条规则,我们都可以看到支持和覆盖。
支持度表示有多少行支持该规则;即:在可以应用该规则的行中,有多少行是正确的。这里的第一条规则是:
proline = High AND alcohol = HighAND alcohol = HighSupport: the target has value: '0' for 100.000% of the 39 rows matching the rule
这表明,在脯氨酸 = 高(特征脯氨酸具有高数值)且酒精度为高(特征酒精具有高数值)的 39 行中,其中 100% 的目标为 0。
覆盖率表示规则覆盖了多少行。对于第一条规则,覆盖率是:
Coverage: the rule matches: 39 out of 59 rows for target value: 0. This is:matches: 39 out of 59 rows for target value: 0. This is:66.102% of total rows for target value: 021.910% of total rows in data
这表示行数和数据行百分比的覆盖率。
生成预测的示例
为了创建预测,我们只需调用 predict() 并传递具有与用于拟合模型的数据框相同特征的数据框(尽管可以选择省略目标列,如本例所示)。
y_pred = prism.predict(df.drop(columns=['Y']))'是' ]))
这样,PRISM 规则可以等效地用于任何其他预测模型,例如决策树、随机森林、XGBoost 等。
但是,在生成预测时,某些行可能不符合任何规则。在这种情况下,默认情况下,将使用训练期间目标列中最常见的值(可以通过访问 prism.default_target 看到)。predict() 方法还支持参数 leave_unknown。如果将其设置为 True,则任何不符合任何规则的记录都将设置为“无预测”。在这种情况下,即使原始目标列是数字,预测也将以字符串类型返回。
示例笔记本中提供了更多示例。
数值数据示例
在此示例中,我们使用 sklearn 的 make_classification() 方法创建数值数据(目标列除外),然后将其分箱。这将使用每个数值特征三个分箱的默认值。
x, y = make_classification(n_samples=1000, 1000, n_features=20, n_informative=2,n_redundant=2,n_repeated=0,n_classes=2,n_clusters_per_class=1,class_sep=2,flip_y=0, random_state=0)df = pd.DataFrame(x) df['Y'] = y prism = PrismRules() _ = prism.get_prism_rules(df, 'Y')
结果
每列的数据被分为低、中、高三个值。结果是每个目标类别的一组规则。
Target: 00 1 = HighSupport: the target has value: '0' for 100.000% of the 333 rows matching the rule Coverage: the rule matches: 333 out of 500 rows for target value: 0. This is:66.600% of total rows for target value: 033.300% of total rows in data15 = Low AND 4 = MedSupport: The target has value: '0' for 100.000% of the 63 remaining rows matching the rule Coverage: The rule matches: 63 out of 167 rows remaining for target value: '0'. This is:37.725% of remaining rows for target value: '0'12.600% of total rows for target value: 06.300% of total rows in data4 = High AND 1 = MedSupport: The target has value: '0' for 100.000% of the 47 remaining rows matching the rule Coverage: The rule matches: 47 out of 104 rows remaining for target value: '0'. This is:45.192% of remaining rows for target value: '0'9.400% of total rows for target value: 04.700% of total rows in data
《数据挖掘原理》一书中的示例
此示例是在 github 页面上的一个示例笔记本中提供的。

PRISM 制定了三条规则:
- 如果眼泪 = 1 那么目标=3
- 如果 astig = 1 并且 tears = 2 并且 specRX = 2 那么 Target=2
- 如果 astig = 2 且 tears = 2 AND specRX =1 那么 Target =1
执行时间处理时间
该算法通常能够在几秒或几分钟内生成一组规则,但如果需要减少算法的执行时间,可以使用数据样本代替完整数据集。该算法通常在数据样本上效果很好,因为模型寻找的是一般模式而不是例外,并且这些模式将存在于任何足够大的样本中。
github 页面上提供了有关调整模型的进一步说明。
结论
不幸的是,目前可用的可解释预测模型相对较少。此外,没有一个可解释模型对所有数据集都足够准确或足够可解释。因此,在可解释性很重要的地方,值得测试多个可解释模型,包括决策树、其他规则归纳工具、GAM、ikNN、加法决策树和 PRISM 规则。
PRISM 规则通常会生成清晰、可解释的规则,并且通常具有较高的准确度,尽管这会因项目而异。虽然与其他预测模型类似,但需要进行一些调整。
感谢关注雲闪世界。(亚马逊aws和谷歌GCP服务协助解决云计算及产业相关解决方案)
订阅频道(https://t.me/awsgoogvps_Host)
TG交流群(t.me/awsgoogvpsHost)d
相关文章:
PRISM-Python 中的规则一个简单的 Python 规则感应系统
欢迎来到雲闪世界.PRISM 是一种现有算法(尽管我确实创建了一个 Python 实现),PRISM 相对简单,但在机器学习中,有时最复杂的解决方案效果最好,有时最简单的解决方案效果最好。然而,当我们希望建立…...

DB-GPT:LLM应用的集大成者
整体架构 架构解读 可以看到,DB-GPT把架构抽象为7层,自下而上分别为: 运行环境:支持本地/云端&单机/分布式等部署方式。顺便一提,RAY是蚂蚁深度参与的一个开源项目,所以对RAY功能的支持应该非常完善。…...
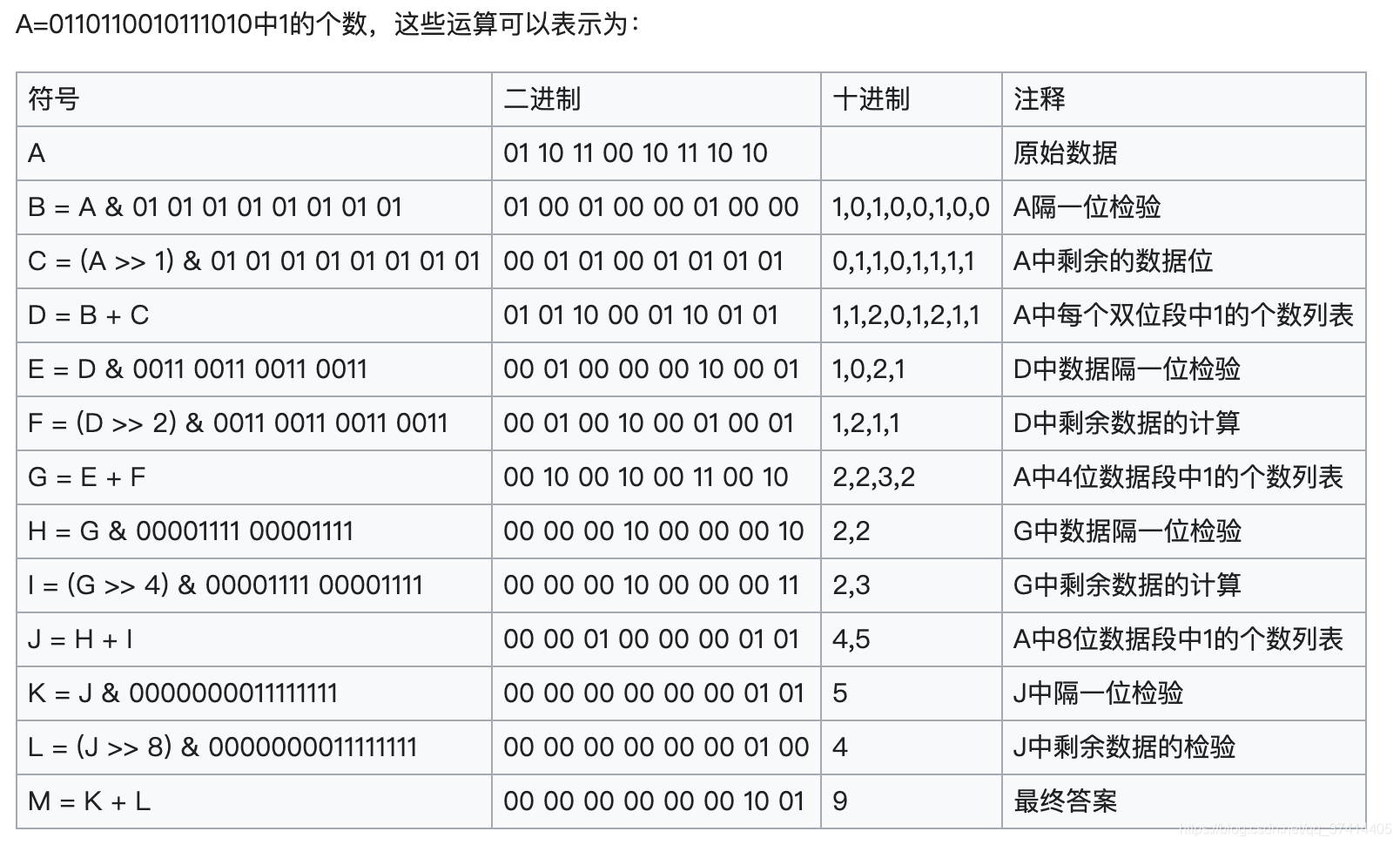
汉明权重(Hamming Weight)(统计数据中1的个数)VP-SWAR算法
汉明权重(Hamming Weight)(统计数据中1的个数)VP-SWAR算法 定义 汉明重量是一串符号中非零符号的个数。它等于同样长度的全零符号串的汉明距离(在信息论中,两个等长字符串之间的汉明距离等于两个字符串对应位置的不同…...

基于 PyTorch 的模型瘦身三部曲:量化、剪枝和蒸馏,让模型更短小精悍!
基于 PyTorch 的模型量化、剪枝和蒸馏 1. 模型量化1.1 原理介绍1.2 PyTorch 实现 2. 模型剪枝2.1 原理介绍2.2 PyTorch 实现 3. 模型蒸馏3.1 原理介绍3.2 PyTorch 实现 参考文献 1. 模型量化 1.1 原理介绍 模型量化是将模型参数从高精度(通常是 float32࿰…...

二、原型模式
文章目录 1 基本介绍2 实现方式深浅拷贝目标2.1 使用 Object 的 clone() 方法2.1.1 代码2.1.2 特性2.1.3 实现深拷贝 2.2 在 clone() 方法中使用序列化2.2.1 代码 2.2.2 特性 3 实现的要点4 Spring 中的原型模式5 原型模式的类图及角色5.1 类图5.1.1 不限制语言5.1.2 在 Java 中…...

【目标检测】Anaconda+PyTorch(GPU)+PyCharm(Yolo5)配置
前言 本文主要介绍在windows系统上的Anaconda、PyTorch、PyCharm、Yolov5关键步骤安装,为使用yolo所需的环境配置完善。同时也算是记录下我的配置流程,为以后用到的时候能笔记查阅。 Anaconda 软件安装 Anaconda官网:https://www.anaconda…...

Django实战项目之进销存数据分析报表——第二天:项目创建和 PyCharm 配置
在上一篇博客中,我们讨论了如何搭建一个全栈 Web 应用的开发环境,包括 Python 环境的创建、Django 和 MySQL 的安装以及前端技术栈的选择。现在,让我们继续深入,学习如何在 PyCharm 中创建一个新的 Django 项目并进行配置。 一…...

静态路由实验
1.实验拓扑图 二、实验要求 1.R6为ISP,接口IP地址均为公有地址,该设备只能配置IP地址,之后不能再对其进行任何配置; 2.R1-R5为局域网,私有IP地址192.168.1.0/24,请合理分配; 3.R1、R2、R4&…...

VSCode STM32嵌入式开发插件记录
要卸载之前搭建的VSCode嵌入式开发环境了,记录一下用的插件。 1.Cortex-Debug https://github.com/Marus/cortex-debug 2.Embedded IDE https://github.com/github0null/eide 3.Keil uVision Assistant https://github.com/jacksonjim/keil-assistant/ 4.RTO…...

linux cpu 占用超100% 分析。
感谢: https://www.cnblogs.com/wolfstark/p/16450131.html 总结: 查看进程中各个线程占用百分比 top -H -p <pid> 某线程100%了 说明 任务处理不过来 会卡 但是永远不可能超100% 系统监视器里面看到的是 所有线程占用的 总和会超100%。 所以最好的情况是&…...

自然学习法和科学学习法
一、自然学习法 自然学习法:什么事自然学习法,特意让kimi来回答了一下。所谓的自然学习法说的俗一点就是野路子学习方法。这种学习方法的特点是“慢”“没有系统性”,学完之后感觉都会了,但是又感觉什么都不会。 二、科学学习法 …...
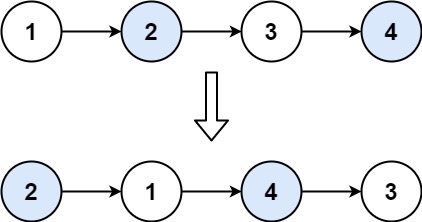
力扣第二十四题——两两交换链表中的节点
内容介绍 给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。 示例 1: 输入:head [1,2,3,4] 输出ÿ…...

C语言柔性数组详解
目录 1.柔性数组 2.柔性数组的特点 3.柔性数组的使用 4.柔性数组的优势 1.柔性数组 C99 中,结构体中的最后一个元素允许是未知大小的数组,这就叫做『柔性数组』成员。 例如: struct S {char c;int n;int arr[];//柔性数组 }; struct …...
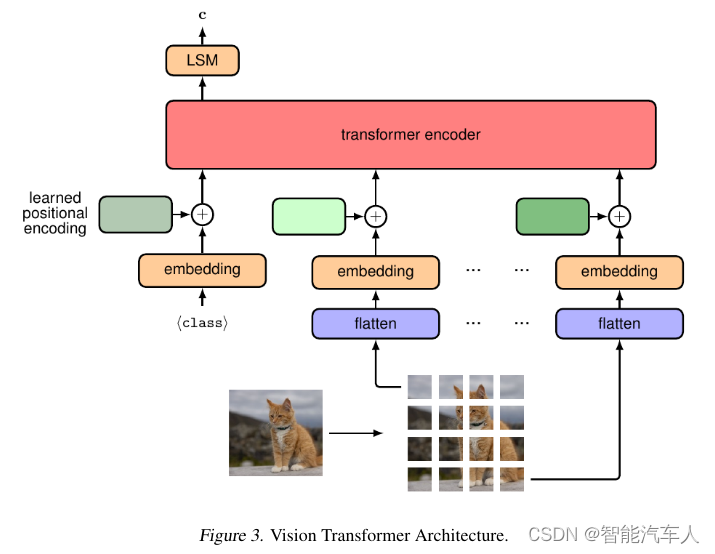
自动驾驶---视觉Transformer的应用
1 背景 在过去的几年,随着自动驾驶技术的不断发展,神经网络逐渐进入人们的视野。Transformer的应用也越来越广泛,逐步走向自动驾驶技术的前沿。笔者也在博客《人工智能---什么是Transformer?》中大概介绍了Transformer的一些内容:…...

预训练语言模型实践笔记
Roberta output_hidden_statesTrue和last_hidden_states和pooler_output 在使用像BERT或RoBERTa这样的transformer模型时,output_hidden_states和last_hidden_state是两个不同的概念。 output_hidden_states: 这是一个布尔值,决定了模型是否应该返回所…...

Perl 哈希
Perl 哈希 Perl 哈希是一种强大的数据结构,用于存储键值对集合。它是 Perl 语言的核心特性之一,广泛应用于各种编程任务中。本文将详细介绍 Perl 哈希的概念、用法和最佳实践。 什么是 Perl 哈希? Perl 哈希是一种关联数组,其中…...

Linux之Mysql索引和优化
一、MySQL 索引 索引作为一种数据结构,其用途是用于提升数据的检索效率。 1、索引分类 - 普通索引(INDEX):索引列值可重复 - 唯一索引(UNIQUE):索引列值必须唯一,可以为NULL - 主键索引(PRIMARY KEY):索引列值必须唯一,不能为NULL,一个表只能有一个主键索引 - 全…...

springboot业务逻辑写在controller层吗
Spring Boot中的业务逻辑不应该直接写在Controller层。 在Spring Boot项目中,通常将业务逻辑分为几个层次,包括Controller层、Service层、Mapper层和Entity层。 1.其中,Controller层主要负责处理HTTP请求,通过注…...

Ubuntu 24.04 LTS 桌面安装MT4或MT5 (MetaTrader)教程
运行脚本即可在 Ubuntu 24.04 LTS Noble Linux 上轻松安装 MetaTrader 5 或 4 应用程序,使用 WineHQ 进行外汇交易。 MetaTrader 4 (MT4) 或 MetaTrader 5 是用于交易外汇对和商品的流行平台。它支持各种外汇经纪商、内置价格分析工具以及通过专家顾问 (EA) 进行自…...

Go基础编程 - 12 -流程控制
流程控制 1. 条件语句1.1. if...else 语句1.2. switch 语句1.3. select 语句1.3.1. select 语句的通信表达式1.3.2. select 的基特性1.3.3. select 的实现原理1.3.4. 经典用法1.3.4.1 超时控制1.3.4.2 多任务并发控制1.3.4.3 监听多通道消息1.3.4.4 default 实现非堵塞读写 2. …...

C语言编译运行:巧用记事本,轻松搭建cmd编译环境
不少人惯于运用VC6.0或者Visual Studio去书写C语言程序,然而当碰到简易代码之际,反倒会感觉开启这些大型IDE显得太过笨重。采用记事本编写代码,接着借助命令提示符来手工编译并运行,此种方式在配置完善之后极为灵活,并…...

Ubuntu22.04手动编译GCC12.2全流程解析与避坑指南
1. 为什么要手动编译GCC12.2? 在Ubuntu22.04系统中,默认的软件仓库可能不会立即提供最新版本的GCC编译器。虽然可以通过添加PPA源来安装较新版本,但手动编译安装GCC12.2能带来几个独特优势: 首先,你可以完全控制编译选…...

突破设备限制:如何用Equalizer APO实现专业级音效
突破设备限制:如何用Equalizer APO实现专业级音效 【免费下载链接】equalizerapo Equalizer APO mirror 项目地址: https://gitcode.com/gh_mirrors/eq/equalizerapo 当你花费数千元购买的耳机却无法展现应有的音质,或笔记本内置扬声器播放音乐时…...

南北阁Nanbeige 4.1-3B多语言支持:技术文档翻译与本地化实践
南北阁Nanbeige 4.1-3B多语言支持:技术文档翻译与本地化实践 最近在折腾一些开源项目时,发现不少优秀的工具和框架,文档只有英文版。对于国内开发者来说,这多少是个门槛。虽然现在翻译工具不少,但技术文档的翻译是个精…...

Faktory生产环境监控终极指南:指标收集、告警设置和故障排查
Faktory生产环境监控终极指南:指标收集、告警设置和故障排查 【免费下载链接】faktory Language-agnostic persistent background job server 项目地址: https://gitcode.com/gh_mirrors/fa/faktory Faktory作为一款语言无关的持久化后台任务服务器ÿ…...

基于STM32MP157与OpenCV的嵌入式Linux人脸识别系统从零构建实战
1. 项目背景与核心价值 第一次拿到STM32MP157开发板时,我盯着这个巴掌大的板子有点发懵——这玩意儿真能跑人脸识别?事实证明它不仅能够,还能跑得很流畅。这个基于Cortex-A7内核的跨界处理器,配合OpenCV这个计算机视觉界的"瑞…...

SEER‘S EYE模型原理入门:图解卷积神经网络与注意力机制
SEERS EYE模型原理入门:图解卷积神经网络与注意力机制 你是不是经常听到“卷积神经网络”、“注意力机制”、“Transformer”这些词,感觉它们很厉害,但又有点云里雾里?特别是当看到像SEERS EYE这类先进的视觉模型时,更…...

RocketMQ 5.3.1生产环境避坑指南:Broker配置优化与Proxy分离部署实战
RocketMQ 5.3.1生产环境避坑指南:Broker配置优化与Proxy分离部署实战 在企业级消息中间件的选型中,RocketMQ凭借其高吞吐、低延迟和金融级可靠性的特点,已成为众多互联网公司和金融机构的核心基础设施。随着5.x版本的发布,Proxy分…...

LiuJuan人像模型效果优化实验:不同参数组合下的细节对比分析
LiuJuan人像模型效果优化实验:不同参数组合下的细节对比分析 1. 实验背景与目标 最近在使用LiuJuan20260223Zimage模型生成人像时,发现同样的提示词在不同参数设置下会产生截然不同的效果。有些生成结果面部特征清晰、皮肤质感真实,而有些则…...

基于生成对抗网络、采用双尺度自适应高效注意力网络的高精度戴口罩人脸识别模型
点击蓝字关注我们关注并星标从此不迷路计算机视觉研究院公众号ID|计算机视觉研究院学习群|扫码在主页获取加入方式https://pmc.ncbi.nlm.nih.gov/articles/PMC12095821/pdf/41598_2025_Article_2144.pdf计算机视觉研究院专栏Column of Computer Vision I…...