【黑马java基础】Lamda, 方法引用,集合{Collection(List, Set), Map},Stream流
文章目录
- JDK8新特性:Lambda表达式
- 认识Lambda表达式
- Lambda表达式的省略规则
- JDK8新特性:方法引用
- 静态方法的引用
- 实例方法的引用
- 特定类型方法的引用
- 构造器的应用
- 集合
- ➡️Collection单列集合体系
- Collection的常用方法
- Collection的遍历方法
- 迭代器
- 增强for循环
- lambda表达式
- 案例
- List集合
- List特点、特有方法
- List的遍历方式
- ArrayList集合的底层原理
- ArrayList集合的底层原理
- ArrayList集合适合的应用场景
- LinkedList集合的底层原理
- LinkedList集合的底层原理
- **LinkedList**新增特有方法
- **LinkedList**集合适合的应用场景
- 场景一:可以用来设计队列
- 场景二:可以用来设计栈
- Set集合
- Set集合的特点
- HashSet集合的底层逻辑
- 前导知识
- 哈希值
- 对象哈希值的特点
- 哈希表
- 数据结构(树)
- HashSet集合底层原理
- HashSet集合去重复的机制
- LinkedHashSet集合的底层逻辑
- TreeSet集合
- ✅总结(场景选择)
- 注意事项:集合的并发修改异常问题
- Collection的其他相关知识
- 可变参数
- Collections工具类
- 综合案例
- ➡️Map集合
- 概述
- 常用方法
- 遍历方法
- 方法1:键找值
- 方法2:键值对
- 方法3:Lambda
- 案例 Map集合-统计投票人数
- HashMap
- HashMap底层原理
- LinkedHashMap
- LinkedHashMap底层原理
- TreeMap
- 补充知识:集合的嵌套
- Stream流
- 认识Stream
- Stream流的使用步骤
- Stream的常用方法
- 1、获取Stream流
- 2、Stream流常见的中间方法
- 3、Stream流常见的终结方法
JDK8新特性:Lambda表达式
认识Lambda表达式
-
Lambda表达式是DK8开始新增的一种语法形式,作用:用于简化匿名内部类的代码写法。
-
格式:

-
注意:Lambda表达式并不能简化全部匿名内部类的写法,只能简化函数式接口(有且只有一个抽象方法的接口)的匿名内部类。
package lambda;public class LambdaTest1 {public static void main(String[] args) {Swimming s = new Swimming() {@Overridepublic void swim() {System.out.println("学生游泳");}};s.swim();}
}interface Swimming{void swim();
}
简化后:
package lambda;public class LambdaTest1 {public static void main(String[] args) {
// Swimming s = new Swimming() {
// @Override
// public void swim() {
// System.out.println("学生游泳");
// }
// };
// s.swim();//简化后:Swimming s = () -> {System.out.println("学生游泳");};s.swim();}
}interface Swimming{void swim();
}
- 将来我们见到的大部分函数式接口,上面都可能会有一个@FunctionalInterface的注解,有该注解的接口就必定是函数式接口。

Lambda表达式的省略规则
Lambda表达式的省略写法(进一步简化Lambda表达式的写法)
- 参数类型可以省略不写。
- 如果只有一个参数,参数类型可以省略,同时()也可以省略。
- 如果Lambda表达式中的方法体代码只有一行代码,可以省略大括号不写,同时要省略分号!此时,如果这行代码是return语句,也必须去掉return不写。
Arrays.setAll(prices, (int value) ->{return prices[value] * 0.8;
});//可以简化为:
Arrays.setAll(prices, (value) ->{return prices[value] * 0.8;
});//接着简化:
Arrays.setAll(prices, value ->{return prices[value] * 0.8;
});//接着简化:
Arrays.setAll(prices, value -> prices[value] * 0.8);
再或者:
Arrays.sort(students, new Comparator<Student>() {@Overridepublic int compare(Student o1, Student o2){return Double.compare(o1.getHeight)}
});//可以简化为:
Arrays.sort(students, (Student o1, Student o2) -> {return Double.compare(o1.getHeight(), o2.getHeight()); //升序
});//接着简化:
Arrays.sort(students, (o1, o2) -> {return Double.compare(o1.getHeight(), o2.getHeight()); //升序
});//接着简化:
Arrays.sort(students, (o1, o2) -> Double.compare(o1.getHeight(), o2.getHeight()) );
用来简化函数式接口的匿名内部类
JDK8新特性:方法引用
用于进一步简化Lambda表达式的
方法引用的标志性符号 “ :: ”
静态方法的引用
- 类名 :: 静态方法
- 使用场景:如果某个Lambda表达式里只是调用一个静态方法,并且前后参数的形式一致,就可以使用静态方法引用

实例方法的引用
-
对象名 :: 实例方法
-
使用场景:如果某个Lambda表达式里只是调用一个实例方法,并且前后参数的形式一致,就可以使用实例方法引用

特定类型方法的引用
-
类型 :: 方法
-
使用场景:如果某个Lambda表达式里只是调用一个实例方法,并且前面参数列表中的第一个参数是作为方法的主调,后面的所有参数都是作为该实例方法入参的,则此时就可以使用特定类型的方法引用。

构造器的应用
- 类名 :: new
- 使用场景:如果某个Lambda表达式里只是在创建对象,并且前后参数的情况一致,就可以使用构造器引用

集合
集合是一种容器,用来装数据的,类似于数组,但集合的大小可变,开发中也非常常用
- 集合的体系结构


集合分为:Collection单列集合,Map双列集合
➡️Collection单列集合体系

Collection集合特点:
- List系列集合:添加的元素是有序(取时的顺序和拿时的顺序是一致的)、可重复(可以往集合中加一模一样的数据)、有索引。
- ArrayList:有序、可重复、有索引
- LinkedList:有序、可重复、有索引
- Set系列集合:添加的元素是无序、不重复、无索引。
- HashSet:无序、不重复、无索引
- LinkedHashSet:有序、不重复、无索引
- TreeSet:按照大小默认升序排序、不重复、无索引
package collection;import java.util.ArrayList;
import java.util.HashSet;public class CollectionTest1 {public static void main(String[] args) {ArrayList<String> list = new ArrayList<>(); //List:有序 可重复 有索引list.add("java1");list.add("java2");list.add("java3");list.add("java4");list.add("java5");System.out.println(list);HashSet<String> set = new HashSet<>(); //Set: 无序 无重复 无索引set.add("java1");set.add("java2");set.add("java3");set.add("java2");set.add("java1");System.out.println(set);}
}//Out:
[java1, java2, java3, java4, java5]
[java3, java2, java1]
集合的存储对象存的并不是元素本身,而是元素的地址,通过元素地址到栈里面获取元素
Collection的常用方法
Collection是单列集合的祖宗,它规定的方法(功能)是全部单列集合都会继承的。
- Collection的常见方法:(单列集合都能用)

package collection;import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collection;public class CollectionTest2API {public static void main(String[] args) {Collection<String> c = new ArrayList<>();//1.public boolean add(E e):添加元素,添加成功返回true。c.add("java1");c.add("java1");c.add("java2");c.add("java2");c.add("java3");System.out.println(c);//2.public void clear():清空集合的元素。
// c.clear();
// System.out.println(c);//3.public boolean isEmpty():判断集合是否为空是空返回true,反之。System.out.println(c.isEmpty());//4.public int size():获取集合的大小。System.out.println(c.size());//5.public boolean contains(object obj):判断集合中是否包含某个元素。System.out.println(c.contains("java3"));System.out.println(c.contains("Java3")); //精确匹配,所以是false//6.public boolean remove(E e):删除某个元素:如果有多个重复元素默认删除前面的第一个!System.out.println(c.remove("java1")); //trueSystem.out.println(c);//7.public Object[] toArray():把集合转换成数组Object[] arr = c.toArray();System.out.println(Arrays.toString(arr));String[] arr2 = c.toArray(new String[c.size()]); //指定一个String类型的数组System.out.println(Arrays.toString(arr2));System.out.println("==============================");//把一个集合里的全部数据倒入到另一个集合中去Collection<String> c1 = new ArrayList<>();c1.add("java1");c1.add("java2");Collection<String> c2 = new ArrayList<>();c2.add("java3");c2.add("java4");c1.addAll(c2); //就是把c2集合的全部数据倒入到c1集合中去System.out.println(c1);System.out.println(c2); //不空,相当于拷贝}
}
//Out:
[java1, java1, java2, java2, java3]
false
5
true
false
true
[java1, java2, java2, java3]
[java1, java2, java2, java3]
[java1, java2, java2, java3]
==============================
[java1, java2, java3, java4]
[java3, java4]
Collection的遍历方法
迭代器
迭代器是用来遍历集合的专用方式(数组没有选代器),在java中选代器的代表是Iterator。
- Collection集合获取迭代器的方法

- Iterator迭代器中的常用方法

package collection;import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;public class CollectionDemo1 {public static void main(String[] args) {Collection<String> c = new ArrayList<>();c.add("aaa");c.add("sss");c.add("ddd");c.add("fff");System.out.println(c);// c = [aaa,sss,ddd,fff]// it it的位置,it会把数据取出来,然后往后移动一位//使用迭代器遍历集合//1、从集合对象中获取迭代器对象Iterator<String> it = c.iterator();
// System.out.println(it.next());
// System.out.println(it.next());
// System.out.println(it.next());
// System.out.println(it.next());// System.out.println(it.next()); //出现异常:NoSuchElementException//2、我们应该使用循环结合迭代器遍历集合while (it.hasNext()){String ele = it.next();System.out.println(ele);}}
}
//Out:
[aaa, sss, ddd, fff]
aaa
sss
ddd
fff
增强for循环

- 增强for可以用来遍历集合或者数组。
- 增强for遍历集合,本质就是迭代器遍历集合的简化写法。
package collection;import java.util.ArrayList;
import java.util.Collection;public class CollectionDemo2 {public static void main(String[] args) {Collection<String> c = new ArrayList<>();c.add("aaa");c.add("sss");c.add("ddd");c.add("fff");System.out.println(c);// c = [aaa,sss,ddd,fff]// ele ele类似游标//使用增强for遍历集合或者数组//快捷键:c.for 然后回车,改变量名就行for (String ele : c){System.out.println(ele);}String[] names = {"11","22","33"};for (String name : names){System.out.println(name);}}
}//Out:
[aaa, sss, ddd, fff]
aaa
sss
ddd
fff
11
22
33
lambda表达式
- Lambda表达式遍历集合:
得益于JDK8开始的新技术Lambda表达式,提供了一种更简单、更直接的方式来遍历集合。
- 需要使用Collection的如下方法来完成


package collection;import java.util.ArrayList;
import java.util.Collection;
import java.util.function.Consumer;public class CollectionDemo3 {public static void main(String[] args) {Collection<String> c = new ArrayList<>();c.add("aaa");c.add("sss");c.add("ddd");c.add("fff");System.out.println(c);// c = [aaa,sss,ddd,fff]// sc.forEach(new Consumer<String>() {@Overridepublic void accept(String s) {System.out.println(s);}});}
}
//Out:
[aaa, sss, ddd, fff]
aaa
sss
ddd
fff
可以用Lambda进行简化:
c.forEach((String s) -> {System.out.println(s);});
//再简化
c.forEach(s -> {System.out.println(s);});
//再简化
c.forEach(s -> System.out.println(s));
//再简化
c.forEach(System.out::println);
案例

集合的存储对象存的并不是元素本身,而是元素的地址,通过元素地址到栈里面获取元素
List集合
有啥特点?是否有特有功能?适合什么业务场景?
List系列集合:有序、可重复、有索引。(两个底层实现不同,适合的场景不同)
- ArrayList:有序、可重复、有索引
- LinkedList:有序、可重复、有索引
List特点、特有方法
List集合特有的方法:
List集合因为支持索引,所以多了很多与索引相关的方法。同时,Collection的功能List也都继承了。

List list = new ArrayList<>();
//一行经典代码(设计到多态,优雅,用的多)
package list;import java.util.ArrayList;
import java.util.List;public class ListTest1 {public static void main(String[] args) {//1、创建一个ArrayList集合对象(有序、可重复、有索引)List<String> list = new ArrayList<>(); //一行经典代码(设计到多态,优雅,用的多)list.add("aaa");list.add("bbb");list.add("ccc");list.add("ddd");System.out.println(list);//2、public void add(int index, E element): 在某个索引位置插入元素。list.add(2,"chacha");System.out.println(list);// 3.public E remove(int index): 根据索引删除元素,返回被删除元素System.out.println(list.remove(2));System.out.println(list);// 4.public E get(int index): 返回集合中指定位置的元素。System.out.println(list.get(2));// 5.public E set(int index, E element): 修改索引位置处的元素,修改成功后,会返回原来的数据System.out.println("========");System.out.println(list.set(2, "gaigai"));System.out.println(list);}
}//
[aaa, bbb, ccc, ddd]
[aaa, bbb, chacha, ccc, ddd]
chacha
[aaa, bbb, ccc, ddd]
ccc
========
ccc
[aaa, bbb, gaigai, ddd]List的遍历方式
List集合相比于前面的Collection多了一种可以通过索引遍历的方式,所以List集合遍历方式一共有四种:
- 普通for循环(只因为List有索引)
- 迭代器
- 增强for
- Lambda表达式
package list;import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;public class ListTest2 {public static void main(String[] args) {List<String> list = new ArrayList<>();list.add("糖宝宝");list.add("蜘蛛精");list.add("至尊宝");//(1)for循环for (int i = 0; i < list.size(); i++) {//i=0,1,2...System.out.println(list.get(i));}//(2)迭代器。Iterator<String> it = list.iterator();while (it.hasNext()) {System.out.println(it.next());}//(3)增强for循环(foreach遍历)for (String s : list) {//s=0,1,2...System.out.println(s);}//(4)JDK 1.8开始之后的Lambda表达式list.forEach(s -> {System.out.println(s);});}
}ArrayList集合的底层原理
ArrayList和LinkedList底层采用的数据结构不同,应用场景也不同
所谓数据结构,就是存储、组织数据的方式
ArrayList集合的底层原理
-
基于数组实现(数组的特点:查询快、增删慢)
-
特点:
- 查询速度快(注意:是根据索引查询数据快):查询数据通过地址值和索引定位,查询任意数据耗时相同。
- 删除效率低:可能需要把后面很多的数据进行前移。
- 添加效率极低:可能需要把后面很多的数据后移,再添加元素;或者也可能需要进行数组的扩容。
-
原理:
- 利用无参构造器创建的集合,会在底层创建一个默认长度为0的数组;
- 添加第一个元素时,底层会创建一个新的长度为10的数组;
- 存满时,会扩容1.5倍,然后把原数组的数据迁移到新数组里;
- 如果一次添加多个元素,1.5倍还放不下,则新创建数组的长度以实际为准
-
注意:数组扩容,并不是在原数组上扩容(原数组是不可以扩容的),底层是创建一个新数组,然后把原数组中的元素全部复制到新数组中去。
ArrayList集合适合的应用场景
1、ArrayList适合:根据索引查询数据,比如根据随机索引取数据(高效)!或者数据量不是很大时!
2、ArrayList不适合:数据量大的同时 又要频繁的讲行增删操作!
LinkedList集合的底层原理
LinkedList集合的底层原理
- 基于双链表实现(链表的特点:查询慢<无论查询哪个数据都要从头开始找>、增删快)
- 特点:查询慢,增删相对较快,但对首尾元素进行增删改查的速度是极快的。

LinkedList新增特有方法
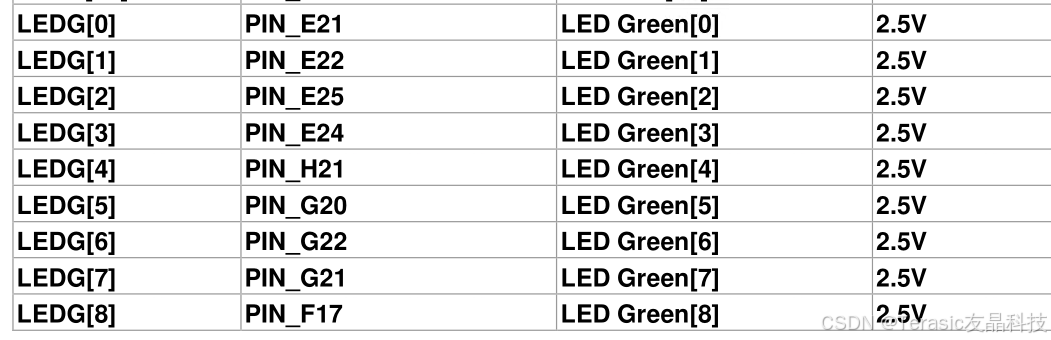
LinkedList新增了:很多首尾操作的特有方法。
| 方法名称 | 说明 |
|---|---|
| public void addFirst(E e) | 在该列表开头插入指定的元素 |
| public void addLast(E e) | 将指定的元素追加到此列表的末尾 |
| public E getFirst() | 返回此列表中的第一个元素 |
| public E getLast() | 返回此列表中的最后一个元素 |
| public E removeFirst() | 从此列表中删除并返回第一个元素 |
| public E removeLast() | 从此列表中删除并返回最后一个元素 |
LinkedList集合适合的应用场景
场景一:可以用来设计队列
先进先出,后进后出。(排号)
只是在首尾增删元素,用LinkedList来实现很合适!
// 1、创建一个队列。LinkedList<String> queue = new LinkedList<>();// 入队queue.addLast("1");queue.addLast("2");queue.addLast("3");queue.addLast("4");System.out.println(queue);// 出队System.out.println(queue.removeFirst());System.out.println(queue.removeFirst());System.out.println(queue.removeFirst());System.out.println(queue);//
[1, 2, 3, 4]
1
2
3
[4]
场景二:可以用来设计栈
先进后出,后进先出。
数据进入栈模型的过程称为:压/进栈(push)
数据离开栈模型的过程称为:弹/出栈(pop)
只是在首部增删云素,用LinkedList来实现很合适!
// 2、创建一个栈对象。LinkedList<String> stack = new LinkedList<>();// 压栈(push)stack.addFirst("a");stack.addFirst("b");stack.addFirst("c");stack.addFirst("d");System.out.println(stack);// 出栈(pop)System.out.println(stack.removeFirst());System.out.println(stack.removeFirst());System.out.println(stack.removeFirst());System.out.println(stack.removeFirst());System.out.println(stack);//
[d, c, b, a]
d
c
b
a
[]
但是java对于栈有专门的方法:
// 2、创建一个栈对象。LinkedList<String> stack = new LinkedList<>();
// 压栈(push) 等价于 addFirst()stack.push("第1颗子弹");stack.push("第2颗子弹");stack.push("第3颗子弹");stack.push("第4颗子弹");System.out.println(stack);
// 出栈(pop) 等价于 removeFirst()System.out.println(stack.pop());System.out.println(stack.pop());System.out.println(stack);
Set集合
Set集合的特点
无序(添加数据的顺序和获取出的数据顺序不一致); 不重复; 无索引;
- HashSet : 无序、不重复、无索引。
- LinkedHashSet:有序、不重复、无索引。
- TreeSet:排序、不重复、无索引。
Set set = new HashSet<>();
//创建了一个HashSet的集合对象。 一行经典代码
package set;import java.util.HashSet;
import java.util.LinkedHashSet;
import java.util.Set;
import java.util.TreeSet;public class SetTest1 {public static void main(String[] args) {// 1、创建一个Set集合的对象
// Set<Integer> set = new HashSet<>(); //创建了一个HashSet的集合对象。 一行经典代码 HashSet: 无序 不重复 无索引
// Set<Integer> set = new LinkedHashSet<>(); //LinkedHashSet: 有序 不重复 无索引Set<Integer> set = new TreeSet<>(); //TreeSet: 可排序(默认升序) 不重复 无索引set.add(444);set.add(111);set.add(333);set.add(222);set.add(555);set.add(333);System.out.println(set);}
}
//
[555, 444, 333, 222, 111] HashSet
[444, 111, 333, 222, 555] LinkedHashSet
[111, 222, 333, 444, 555] TreeSet
注意:
Set要用到的常用方法,基本上就是Collection提供的!!自己几乎没有额外新增一些常用功能!
HashSet集合的底层逻辑
HashSet : 无序、不重复、无索引
前导知识
哈希值
-
就是一个int类型的数值,Java中每个对象都有一个哈希值。
-
Java中的所有对象,都可以调用Obejct类提供的hashCode方法,返回该对象自己的哈希值。
- public int hashCode() : 返回对象的哈希码值
对象哈希值的特点
- 同一个对象多次调用hashCode()方法返回的哈希值是相同的。
- 不同的对象,它们的哈希值一般不相同,但也有可能会相同(哈希碰撞)。
哈希表
- JDK8以前:哈希表 = 数组+链表
- JDK8以后:哈希表 = 数组+链表+红黑树
JDK8之前:

默认加载因子为0.75的意思是,一旦数组中的数据占满了数组长度的0.75倍了,就开始扩容,扩容到原数组的2倍,然后把原数组的数据放到新数组里
JDK8开始,当链表长度超过8,且数组长度>=64时,自动将链表转成红黑树:

数据结构(树)
二叉树-》二叉查找树-》平衡二叉树-》红黑树
- 二叉树分为普通二叉树(没啥用),二叉查找树(左小右大,一样不放)


二叉查找树存在的问题:当数据已经是排好序的,导致查询的性能与单链表一样,查询速度变慢!
在满足查找二叉树的大小规则下,让树尽可能矮小,以此提高查数据的性能。所以有了平衡二叉树

红黑树,就是可以自平衡的二叉树。红黑树是一种增删改查数据性能相对都较好的结构。

HashSet集合底层原理
- 是基于哈希表实现的
- 哈希表是一种增删改查数据性能都较好的数据结构
HashSet集合去重复的机制
HashSet集合默认不能对内容一样的两个不同对象去重复!
比如内容一样的两个学生对象存入到HashSet集合中去,HashSet集合是不能去重复的!因为比较的是哈希地址,内容一样,哈希地址不一定一样。
如何让HashSet集合能够实现对内容一样的两个不同对象也能去重复?
结论:如果希望Set集合认为2个内容一样的对象是重复的,必须重写对象的hashCode()和equals()方法(右键generate->equals() and hashCode()->一路next,finish)
LinkedHashSet集合的底层逻辑
LinkedHashSet:有序、不重复、无索引
- 依然是基于哈希表**(数组、链表、红黑树)**实现的。
- 但是,它的每个元素都额外的多了一个双链表的机制记录它前后元素的位置。

缺点就是更占内存,空间换时间
TreeSet集合
TreeSet:不重复、无索引、可排序(默认升序排序 ,按照元素的大小,由小到大排序)
- 底层是基于红黑树实现的排序。
排序规则:
- 对于数值类型:Integer , Double,默认按照数值本身的大小进行升序排序。
- 对于字符串类型:默认按照首字符的编号升序排序。
- 对于自定义类型如Student对象,TreeSet默认是无法直接排序的。
如果往TreeSet集合中存储自定义类型的元素,比如说Student类型,则需要我们自己指定排序规则,否则会出现异常。
比如:此时运行代码,会直接报错。原因是TreeSet不知道按照什么条件对Student对象来排序。

TreeSet集合存储自定义类型的对象时,必须指定排序规则,支持如下两种方式来指定比较规则。
自定义排序规则
方式一:
让自定义的类(如学生类)实现Comparable接口,重写里面的compareTo方法来指定比较规则。
方式二
通过调用TreeSet集合有参数构造器,可以设置Comparator对象(比较器对象),用于指定比较规则。
public TreeSet(Comparator<? super E> comparator)
方法一:重写compareTo方法

方法二:Comparator对象

Lambda简化后:

注意:如果有自定义了两个比较规则,Treeset会采取就近选择自带的比较器对象进行比较
两种方式中,关于返回值的规则:
- 如果认为第一个元素 > 第二个元素 返回正整数即可。
- 如果认为第一个元素 < 第二个元素返回负整数即可。
- 如果认为第一个元素 = 第二个元素返回0即可,此时Treeset集合只会保留一个元素,认为两者重复。
✅总结(场景选择)


注意事项:集合的并发修改异常问题
集合的并发修改异常:就是使用迭代器遍历集合时,又同时在删除集合中的数据,程序就会出现并发修改异常的错误。
List<String> list = new ArrayList<>();
list.add("王麻子");
list.add("小李子");
list.add("李爱花");
list.add("张全蛋");
list.add("晓李");
list.add("李玉刚");
System.out.println(list); // [王麻子, 小李子, 李爱花, 张全蛋, 晓李, 李玉刚]//需求:找出集合中带"李"字的姓名,并从集合中删除
Iterator<String> it = list.iterator();
while(it.hasNext()){String name = it.next();if(name.contains("李")){list.remove(name);}
}
System.out.println(list);
运行上面的代码,会出现下面的异常。这就是并发修改异常:

为什么会出现这个异常呢?那是因为迭代器遍历机制,规定迭代器遍历集合的同时,不允许集合自己去增删元素,否则就会出现这个异常。
怎么解决这个问题呢?不使用集合的删除方法,而是使用迭代器的删除方法,代码如下:
List<String> list = new ArrayList<>();
list.add("王麻子");
list.add("小李子");
list.add("李爱花");
list.add("张全蛋");
list.add("晓李");
list.add("李玉刚");
System.out.println(list); // [王麻子, 小李子, 李爱花, 张全蛋, 晓李, 李玉刚]//需求:找出集合中带"李"字的姓名,并从集合中删除
Iterator<String> it = list.iterator();
while(it.hasNext()){String name = it.next();if(name.contains("李")){//list.remove(name);it.remove(); //当前迭代器指向谁,就删除谁✅}
}
System.out.println(list);
由于增强for循环遍历集合就是迭代器遍历集合的简化写法,因此,使用增强for循环遍历集合,又在同时删除集合中的数据时,程序也会出现并发修改异常的错误。
怎么保证遍历集合同时删除数据时不出bug?
- 使用迭代器遍历集合,用迭代器自己的删除方法删除数据即可。
- 如果能用for循环遍历时:可以倒着遍历并删除;或者从前往后遍历,但删除元素后做**i --**操作。
Collection的其他相关知识
可变参数
什么是可变参数?
可变参数就是一种特殊形参,定义在方法、构造器的形参列表里,它可以让方法接收多个同类型的实际参数。
什么格式
格式是:数据类型…参数名称;
public class ParamTest{public static void main(String[] args){//不传递参数,下面的nums长度则为0, 打印元素是[]test(); //传递3个参数,下面的nums长度为3,打印元素是[10, 20, 30]test(10,20,30); //传递一个数组,下面数组长度为4,打印元素是[10,20,30,40] int[] arr = new int[]{10,20,30,40}test(arr); }public static void test(int...nums){//可变参数在方法内部,本质上是一个数组System.out.println(nums.length);System.out.println(Arrays.toString(nums));System.out.println("----------------");}
}
注意事项:
最后还有一些错误写法,需要让大家写代码时注意一下,不要这么写哦!!!
- 一个形参列表中,只能有一个可变参数;否则会报错
- 一个形参列表中如果多个参数,可变参数需要写在最后;否则会报错
- 可变参数对外接收数据,但是在方法内部,本质上是一个数组

可变参数的特点和好处
特点:可以不传数据给它;可以传一个或者同时传多个数据给它;也可以传一个数组给它。
好处:常常用来灵活的接收数据。
Collections工具类
是一个用来操作集合的工具类
注意Collections并不是集合,它比Collection多了一个s,一般后缀为s的类很多都是工具类。这里的Collections是用来操作Collection的工具类。
Collections提供的常用静态方法
| 方法名称 | 说明 |
|---|---|
| public static boolean addAll(Collection<? super T> c, T… elements) | 给集合批量添加元素。Collection下的种类都能用 |
| public static void shuffle(List<?> list) | 打乱List集合中的元素顺序。仅用于List集合 |
| public static void sort(List list) | 对List集合中的元素进行升序排序 |
| public static void sort(List list,Comparator<? super T> c) | 对List集合中元素,按照比较器对象指定的规则进行排序 |
public class CollectionsTest{public static void main(String[] args){//1.public static <T> boolean addAll(Collection<? super T> c, T...e):为集合批量添加数据List<String> names = new ArrayList<>();Collections.addAll(names, "张三","王五","李四", "张麻子");System.out.println(names);//2.public static void shuffle(List<?> list):对集合打乱顺序Collections.shuffle(names);System.out.println(names);//3.public static <T> void short(List<T list): 对List集合排序List<Integer> list = new ArrayList<>();list.add(3);list.add(5);list.add(2);Collections.sort(list);System.out.println(list);//4、使用调用sort方法,传递比较器Collections.sort(students, new Comparator<Student>(){@Overridepublic int compare(Student o1, Student o2){return o1.getAge()-o2.getAge();}
});
System.out.println(students);}
}

综合案例
斗地主
➡️Map集合
概述
什么是Map集合
所谓双列集合,就是说集合中的元素是一对一对的。Map集合中的每一个元素是以key=value的形式存在的,一个key=value就称之为一个键值对,而且在Java中有一个类叫Entry类,Entry的对象用来表示键值对对象。
- Map集合称为双列集合,格式:{key1=value1 , key2=value2 , key3=value3 , …}, 一次需要存一对数据做为一个元素.
- Map集合的每个元素“key=value”称为一个键值对/键值对对象/一个Entry对象,Map集合也被叫做“键值对集合”
- Map集合的所有键是不允许重复的,但值可以重复,键和值是一一对应的,每一个键只能找到自己对应的值
Map集合在什么业务场景下使用
需要存储一一对应的数据时,就可以考虑使用Map集合来做。
Map集合体系

Map集合体系的特点
注意:Map系列集合的特点都是由键决定的,值只是一个附属品,值是不做要求的
- HashMap(由键决定特点): 无序、不重复、无索引; (用的最多)
- LinkedHashMap (由键决定特点):有序、不重复、无索引。
- TreeMap (由键决定特点):按照大小默认升序排序**、**不重复、无索引。
Map<String, Integer> map = new HashMap<>(); // 一行经典代码
public class MapTest1 {public static void main(String[] args) {// Map<String, Integer> map = new HashMap<>(); // 一行经典代码。 按照键 无序,不重复,无索引。Map<String, Integer> map = new LinkedHashMap<>(); // 有序,不重复,无索引。map.put("手表", 100);map.put("手表", 220); // 后面重复的数据会覆盖前面的数据(键)map.put("手机", 2);map.put("Java", 2);map.put(null, null);System.out.println(map);Map<Integer, String> map1 = new TreeMap<>(); // 可排序,不重复,无索引map1.put(23, "Java");map1.put(23, "MySQL");map1.put(19, "李四");map1.put(20, "王五");System.out.println(map1);}
}
常用方法
由于Map是所有双列集合的父接口,所以我们只需要学习Map接口中每一个方法是什么含义,那么所有的Map集合方法就都会用了。
Map的常用方法如下:
| 方法名称 | 说明 |
|---|---|
| public V put(K key,V value) | 添加元素 |
| public int size() | 获取集合的大小 |
| public void clear() | 清空集合 |
| public boolean isEmpty() | 判断集合是否为空,为空返回true , 反之 |
| public V get(Object key) | 根据键获取对应值 |
| public V remove(Object key) | 根据键删除整个元素 |
| public boolean containsKey(Object key) | 判断是否包含某个键 |
| public boolean containsValue(Object value) | 判断是否包含某个值 |
| public Set keySet() | 获取全部键的集合 |
| public Collection values() | 获取Map集合的全部值 |
public class MapTest2 {public static void main(String[] args) {// 1.添加元素: 无序,不重复,无索引。Map<String, Integer> map = new HashMap<>();map.put("手表", 100);map.put("手表", 220);map.put("手机", 2);map.put("Java", 2);map.put(null, null);System.out.println(map);// map = {null=null, 手表=220, Java=2, 手机=2}// 2.public int size():获取集合的大小System.out.println(map.size());// 3、public void clear():清空集合//map.clear();//System.out.println(map);// 4.public boolean isEmpty(): 判断集合是否为空,为空返回true ,反之!System.out.println(map.isEmpty());// ✅5.public V get(Object key):根据键获取对应值int v1 = map.get("手表");System.out.println(v1);System.out.println(map.get("手机")); // 2System.out.println(map.get("张三")); // null// 6. public V remove(Object key):根据键删除整个元素(删除键会返回键的值)System.out.println(map.remove("手表"));System.out.println(map);// 7.public boolean containsKey(Object key): 判断是否包含某个键 ,包含返回true ,反之。(精确匹配!)System.out.println(map.containsKey("手表")); // falseSystem.out.println(map.containsKey("手机")); // trueSystem.out.println(map.containsKey("java")); // falseSystem.out.println(map.containsKey("Java")); // true// 8.public boolean containsValue(Object value): 判断是否包含某个值。System.out.println(map.containsValue(2)); // trueSystem.out.println(map.containsValue("2")); // false// 9.public Set<K> keySet(): 获取Map集合的全部键。Set<String> keys = map.keySet();System.out.println(keys);// 10.public Collection<V> values(); 获取Map集合的全部值。Collection<Integer> values = map.values();System.out.println(values);// 11.把其他Map集合的数据倒入到自己集合中来。(拓展)Map<String, Integer> map1 = new HashMap<>();map1.put("java1", 10);map1.put("java2", 20);Map<String, Integer> map2 = new HashMap<>();map2.put("java3", 10);map2.put("java2", 222);map1.putAll(map2); // putAll:把map2集合中的元素全部倒入一份到map1集合中去。System.out.println(map1); //{java3=10, java2=222, java1=10}System.out.println(map2); //{java3=10, java2=222}}
}
遍历方法

方法1:键找值
需要用到Map的如下方法:
| 方法名称 | 说明 |
|---|---|
| public Set keySet() | 获取所有键的集合 |
| public V get(Object key) | 根据键获取其对应的值 |
/*** 目标:掌握Map集合的遍历方式1:键找值*/
public class MapTest1 {public static void main(String[] args) {// 准备一个Map集合。Map<String, Double> map = new HashMap<>();map.put("蜘蛛精", 162.5);map.put("蜘蛛精", 169.8);map.put("紫霞", 165.8);map.put("至尊宝", 169.5);map.put("牛魔王", 183.6);System.out.println(map);// map = {蜘蛛精=169.8, 牛魔王=183.6, 至尊宝=169.5, 紫霞=165.8}// 1、获取Map集合的全部键Set<String> keys = map.keySet();// System.out.println(keys);// [蜘蛛精, 牛魔王, 至尊宝, 紫霞]// key// 2、遍历全部的键,根据键获取其对应的值for (String key : keys) {// 根据键获取对应的值double value = map.get(key);System.out.println(key + "=====>" + value);}}
}
方法2:键值对
Map集合是用来存储键值对的,而每一个键值对实际上是一个Entry对象。
这里Map集合的第二种方式,是直接获取每一个Entry对象,把Entry存储扫Set集合中去,再通过Entry对象获取键和值。
用到的方法:
| Map提供的方法 | 说明 |
|---|---|
| Set<Map.Entry<K, V>> entrySet() | 获取所有“键值对”的集合 |
| Map.Entry提供的方法 | 说明 |
|---|---|
| K getKey() | 获取键 |
| V getValue() | 获取值 |

/*** 目标:掌握Map集合的第二种遍历方式:键值对。*/
public class MapTest2 {public static void main(String[] args) {Map<String, Double> map = new HashMap<>();map.put("蜘蛛精", 169.8);map.put("紫霞", 165.8);map.put("至尊宝", 169.5);map.put("牛魔王", 183.6);System.out.println(map);// map = {蜘蛛精=169.8, 牛魔王=183.6, 至尊宝=169.5, 紫霞=165.8}// entries = [(蜘蛛精=169.8), (牛魔王=183.6), (至尊宝=169.5), (紫霞=165.8)]// entry = (蜘蛛精=169.8)// entry = (牛魔王=183.6)// ...// 1、调用Map集合提供entrySet方法,把Map集合转换成键值对类型的Set集合Set<Map.Entry<String, Double>> entries = map.entrySet();for (Map.Entry<String, Double> entry : entries) {String key = entry.getKey();double value = entry.getValue();System.out.println(key + "---->" + value);}}
}
方法3:Lambda
需要用到Map的如下方法
| 方法名称 | 说明 |
|---|---|
| default void forEach(BiConsumer<? super K, ? super V> action) | 结合lambda遍历Map集合 |
/*** 目标:掌握Map集合的第三种遍历方式:Lambda。*/
public class MapTest3 {public static void main(String[] args) {Map<String, Double> map = new HashMap<>();map.put("蜘蛛精", 169.8);map.put("紫霞", 165.8);map.put("至尊宝", 169.5);map.put("牛魔王", 183.6);System.out.println(map);// map = {蜘蛛精=169.8, 牛魔王=183.6, 至尊宝=169.5, 紫霞=165.8}//✅遍历map集合,传递Lambda表达式map.forEach(( k, v) -> {System.out.println(k + "---->" + v);});//上面的原始的遍历架子//遍历map集合,传递匿名内部类map.forEach(new BiConsumer<String, Double>() {@Overridepublic void accept(String k, Double v) {System.out.println(k + "---->" + v);}});}
}
案例 Map集合-统计投票人数

public class MapDemo4 {public static void main(String[] args) {// 1、把80个学生选择的景点数据拿到程序中来。List<String> data = new ArrayList<>();String[] selects = {"A", "B", "C", "D"};Random r = new Random();for (int i = 1; i <= 80; i++) {// 每次模拟一个学生选择一个景点,存入到集合中去。int index = r.nextInt(4); // 0 1 2 3data.add(selects[index]);}System.out.println(data);// 2、开始统计每个景点的投票人数// 准备一个Map集合用于统计最终的结果Map<String, Integer> result = new HashMap<>();// 3、开始遍历80个景点数据for (String s : data) {// 问问Map集合中是否存在该景点if(result.containsKey(s)){// 说明这个景点之前统计过。其值+1. 存入到Map集合中去result.put(s, result.get(s) + 1);}else {// 说明这个景点是第一次统计,存入"景点=1"result.put(s, 1);}}System.out.println(result);}
}
需要存储一一对应的数据时,就可以考虑使用Map集合来做
HashMap
HashMap(由键决定特点): 无序、不重复、无索引; (用的最多)
-
HashMap跟HashSet的底层原理是一模一样的,都是基于哈希表实现的。
-
实际上:原来学的Set系列集合的底层就是基于Map实现的,只是Set集合中的元素只要键数据,不要值数据而已。

哈希表
JDK8之前,哈希表 = 数组+链表
JDK8开始,哈希表 = 数组+链表+红黑树
哈希表是一种增删改查数据,性能都较好的数据结构。
HashMap底层原理
-
利用键计算哈希值,跟值无关。
-
如何处理哈希碰撞
-
JDK8之前,如果新元素和老元素位置一样,新元素占据老元素位置,老元素挂到新元素下面
-
JDK8之后,新元素直接挂到老元素下面
-
挂的长度超过8&数组长度>=64,自动转成红黑树
-
-
基于哈希表实现的,增删改查都较好
-
HashMap的键依赖*hashCode*方法和equals方法保证键的唯一
用hashCode算位置,用equals算内容,如果都一样,则两个元素一样
-
如果键存储的是自定义类型的对象,可以通过重写hashCode和equals方法,这样可以保证多个对象内容一样时,HashMap集合就能认为是重复的。
LinkedHashMap
LinkedHashMap (由键决定特点):有序、不重复、无索引。
public static void main(String[] args) {// Map<String, Integer> map = new HashMap<>(); // 按照键 无序,不重复,无索引。LinkedHashMap<String, Integer> map = new LinkedHashMap<>(); // 按照键 有序,不重复,无索引。map.put("手表", 100);map.put("手表", 220);map.put("手机", 2);map.put("Java", 2);map.put(null, null);System.out.println(map);}//Out
{null=null,手表=220,Java=2,手机=2} //HashMap
{手表=220,手机=2,Java=2,null=null} //LinkedHashMap
LinkedHashMap底层原理
底层数据结构依然是基于哈希表实现的,只是每个键值对元素又额外的多了一个双链表的机制记录元素顺序(保证有序)。
和LinkedHashSet很像
实际上:原来学习的LinkedHashSet集合的底层原理就是LinkedHashMap。

增删改查性能都还可以,有序,不重复,选LinkedHashMap
TreeMap
特点:不重复、无索引、可排序(按照键的大小默认升序排序,只能对键排序)
原理:TreeMap跟TreeSet集合的底层原理是一样的,都是基于红黑树实现的排序。
TreeMap集合同样也支持两种方式来指定排序规则:
- 让类实现Comparable接口,重写比较规则。
- TreeMap集合有一个有参数构造器,支持创建Comparator比较器对象,以便用来指定比较规则。
排序方式1:写一个Student类,让Student类实现Comparable接口
//第一步:先让Student类,实现Comparable接口
public class Student implements Comparable<Student>{private String name;private int age;private double height;//无参数构造方法public Student(){}//全参数构造方法public Student(String name, int age, double height){this.name=name;this.age=age;this.height=height;}//...get、set、toString()方法自己补上..//按照年龄进行比较,只需要在方法中让this.age和o.age相减就可以。/*原理:在往TreeSet集合中添加元素时,add方法底层会调用compareTo方法,根据该方法的结果是正数、负数、还是零,决定元素放在后面、前面还是不存。*/@Overridepublic int compareTo(Student o) {//this:表示将要添加进去的Student对象//o: 表示集合中已有的Student对象return this.age-o.age;}
}
排序方式2:在创建TreeMap集合时,直接传递Comparator比较器对象。
/*** 目标:掌握TreeMap集合的使用。*/
public class Test3TreeMap {public static void main(String[] args) {Map<Student, String> map = new TreeMap<>(new Comparator<Student>() {@Overridepublic int compare(Student o1, Student o2) {return Double.compare(o1.getHeight(), o2.getHeight());}});
// Map<Student, String> map = new TreeMap<>(( o1, o2) -> Double.compare(o2.getHeight(), o1.getHeight()));map.put(new Student("蜘蛛精", 25, 168.5), "盘丝洞");map.put(new Student("蜘蛛精", 25, 168.5), "水帘洞");map.put(new Student("至尊宝", 23, 163.5), "水帘洞");map.put(new Student("牛魔王", 28, 183.5), "牛头山");System.out.println(map);}
}
这种方式都可以对TreeMap集合中的键排序。注意:只有TreeMap的键才能排序,HashMap键不能排序。
补充知识:集合的嵌套
集合的嵌套就是集合中的元素又是一个集合

- 案例分析
1.从需求中我们可以看到,有三个省份,每一个省份有多个城市我们可以用一个Map集合的键表示省份名称,而值表示省份有哪些城市
2.而又因为一个省份有多个城市,同一个省份的多个城市可以再用一个List集合来存储。所以Map集合的键是String类型,而指是List集合类型HashMap<String, List<String>> map = new HashMap<>();
- 代码如下
/*** 目标:理解集合的嵌套。* 江苏省 = "南京市","扬州市","苏州市“,"无锡市","常州市"* 湖北省 = "武汉市","孝感市","十堰市","宜昌市","鄂州市"* 河北省 = "石家庄市","唐山市", "邢台市", "保定市", "张家口市"*/
public class Test {public static void main(String[] args) {// 1、定义一个Map集合存储全部的省份信息,和其对应的城市信息。Map<String, List<String>> map = new HashMap<>();List<String> cities1 = new ArrayList<>();Collections.addAll(cities1, "南京市","扬州市","苏州市" ,"无锡市","常州市");map.put("江苏省", cities1);List<String> cities2 = new ArrayList<>();Collections.addAll(cities2, "武汉市","孝感市","十堰市","宜昌市","鄂州市");map.put("湖北省", cities2);List<String> cities3 = new ArrayList<>();Collections.addAll(cities3, "石家庄市","唐山市", "邢台市", "保定市", "张家口市");map.put("河北省", cities3);System.out.println(map);List<String> cities = map.get("湖北省");for (String city : cities) {System.out.println(city);}map.forEach((p, c) -> {System.out.println(p + "----->" + c);});}
}
Stream流
JDK8开始最大的改变:Lambda, Stream
认识Stream
也叫Stream流,是Jdk8开始新增的一套API (java.util.stream.*),可以用于操作集合或者数组的数据。
优势: Stream流大量的结合了Lambda的语法风格来编程,提供了一种更加强大,更加简单的方式操作集合或者数组中的数据,代码更简洁,可读性更好。

public class StreamTest1 {public static void main(String[] args) {List<String> names = new ArrayList<>();Collections.addAll(names, "张三丰","张无忌","周芷若","赵敏","张强");System.out.println(names);// names = [张三丰, 张无忌, 周芷若, 赵敏, 张强]// name// 找出姓张,且是3个字的名字,存入到一个新集合中去。List<String> list = new ArrayList<>();for (String name : names) {if(name.startsWith("张") && name.length() == 3){list.add(name);}}System.out.println(list);// 开始使用Stream流来解决这个需求。List<String> list2 = names.stream().filter(s -> s.startsWith("张")).filter(a -> a.length()==3).collect(Collectors.toList());System.out.println(list2);}
}
Stream流的使用步骤

Stream的常用方法

1、获取Stream流
- 获取 集合 的Stream流
| Collection提供的如下方法 | 说明 |
|---|---|
| default Stream stream() | 获取当前集合对象的Stream流 |
- 获取 数组 的Stream流
| Arrays类提供的如下 方法 | 说明 |
|---|---|
| public static Stream stream(T[] array) | 获取当前数组的Stream流 |
| Stream类提供的如下 方法 | 说明 |
|---|---|
| public static Stream of(T… values) | 获取当前接收数据的Stream流 |
/*** 目标:掌握Stream流的创建。*/
public class StreamTest2 {public static void main(String[] args) {// 1、如何获取List集合的Stream流?List<String> names = new ArrayList<>();Collections.addAll(names, "张三丰","张无忌","周芷若","赵敏","张强");Stream<String> stream = names.stream();// 2、如何获取Set集合的Stream流?Set<String> set = new HashSet<>();Collections.addAll(set, "刘德华","张曼玉","蜘蛛精","马德","德玛西亚");Stream<String> stream1 = set.stream();stream1.filter(s -> s.contains("德")).forEach(s -> System.out.println(s));// 3、如何获取Map集合的Stream流?Map<String, Double> map = new HashMap<>();map.put("古力娜扎", 172.3);map.put("迪丽热巴", 168.3);map.put("马尔扎哈", 166.3);map.put("卡尔扎巴", 168.3);Set<String> keys = map.keySet();Stream<String> ks = keys.stream();Collection<Double> values = map.values();Stream<Double> vs = values.stream();Set<Map.Entry<String, Double>> entries = map.entrySet();Stream<Map.Entry<String, Double>> kvs = entries.stream();kvs.filter(e -> e.getKey().contains("巴")).forEach(e -> System.out.println(e.getKey()+ "-->" + e.getValue()));// 4、如何获取数组的Stream流?String[] names2 = {"张翠山", "东方不败", "唐大山", "独孤求败"};Stream<String> s1 = Arrays.stream(names2);Stream<String> s2 = Stream.of(names2);}
}2、Stream流常见的中间方法
中间方法指的是调用完成后会返回新的Stream流,可以继续使用(支持链式编程)。

/** 目标:掌握Stream流提供的常见中间方法。*/
public class StreamTest3 {public static void main(String[] args) {List<Double> scores = new ArrayList<>();Collections.addAll(scores, 88.5, 100.0, 60.0, 99.0, 9.5, 99.6, 25.0);// 需求1:找出成绩大于等于60分的数据,并升序后,再输出。scores.stream().filter(s -> s >= 60).sorted().forEach(s -> System.out.println(s));List<Student> students = new ArrayList<>();Student s1 = new Student("蜘蛛精", 26, 172.5);Student s2 = new Student("蜘蛛精", 26, 172.5);Student s3 = new Student("紫霞", 23, 167.6);Student s4 = new Student("白晶晶", 25, 169.0);Student s5 = new Student("牛魔王", 35, 183.3);Student s6 = new Student("牛夫人", 34, 168.5);Collections.addAll(students, s1, s2, s3, s4, s5, s6);// 需求2:找出年龄大于等于23,且年龄小于等于30岁的学生,并按照年龄降序输出.students.stream().filter(s -> s.getAge() >= 23 && s.getAge() <= 30).sorted((o1, o2) -> o2.getAge() - o1.getAge()).forEach(s -> System.out.println(s));// 需求3:取出身高最高的前3名学生,并输出。students.stream().sorted((o1, o2) -> Double.compare(o2.getHeight(), o1.getHeight())).limit(3).forEach(System.out::println);System.out.println("-----------------------------------------------");// 需求4:取出身高倒数的2名学生,并输出。 s1 s2 s3 s4 s5 s6students.stream().sorted((o1, o2) -> Double.compare(o2.getHeight(), o1.getHeight())).skip(students.size() - 2).forEach(System.out::println);// 需求5:找出身高超过168的学生叫什么名字,要求去除重复的名字,再输出。students.stream().filter(s -> s.getHeight() > 168).map(Student::getName).distinct().forEach(System.out::println);//简化前:.map(s -> s.getName())// distinct去重复,自定义类型的对象(希望内容一样就认为重复,重写hashCode,equals)students.stream().filter(s -> s.getHeight() > 168).distinct().forEach(System.out::println);Stream<String> st1 = Stream.of("张三", "李四");Stream<String> st2 = Stream.of("张三2", "李四2", "王五");Stream<String> allSt = Stream.concat(st1, st2);allSt.forEach(System.out::println);}
}
3、Stream流常见的终结方法
终结方法指的是调用完成后,不会返回新Stream了,没法继续使用流了。

有的需求需要我们把结果放到集合或者数组中去,所以需要收集Stream流:
收集Stream流:就是把Stream流操作后的结果转回到集合或者数组中去返回。
Stream流:方便操作集合/数组的手段; 集合/数组:才是开发中的目的。
| Stream提供的常用终结方法 | 说明 |
|---|---|
| R collect(Collector collector) | 把流处理后的结果收集到一个指定的集合中去 |
| Object[] toArray() | 把流处理后的结果收集到一个数组中去 |
| Collectors工具类提供了具体的收集方式 | 说明 |
|---|---|
| public static Collector toList() | 把元素收集到List集合中 |
| public static Collector toSet() | 把元素收集到Set集合中 |
| public static Collector toMap(Function keyMapper , Function valueMapper) | 把元素收集到Map集合中 |
/*** 目标:Stream流的终结方法*/
public class StreamTest4 {public static void main(String[] args) {List<Student> students = new ArrayList<>();Student s1 = new Student("蜘蛛精", 26, 172.5);Student s2 = new Student("蜘蛛精", 26, 172.5);Student s3 = new Student("紫霞", 23, 167.6);Student s4 = new Student("白晶晶", 25, 169.0);Student s5 = new Student("牛魔王", 35, 183.3);Student s6 = new Student("牛夫人", 34, 168.5);Collections.addAll(students, s1, s2, s3, s4, s5, s6);// 需求1:请计算出身高超过168的学生有几人。long size = students.stream().filter(s -> s.getHeight() > 168).count();System.out.println(size);// 需求2:请找出身高最高的学生对象,并输出。Student s = students.stream().max((o1, o2) -> Double.compare(o1.getHeight(), o2.getHeight())).get();System.out.println(s);// 需求3:请找出身高最矮的学生对象,并输出。Student ss = students.stream().min((o1, o2) -> Double.compare(o1.getHeight(), o2.getHeight())).get();System.out.println(ss);// 需求4:请找出身高超过170的学生对象,并放到一个新集合中去返回。// 流只能收集一次。List<Student> students1 = students.stream().filter(a -> a.getHeight() > 170).collect(Collectors.toList());System.out.println(students1);Set<Student> students2 = students.stream().filter(a -> a.getHeight() > 170).collect(Collectors.toSet());System.out.println(students2);// 需求5:请找出身高超过170的学生对象,并把学生对象的名字和身高,存入到一个Map集合返回。Map<String, Double> map =students.stream().filter(a -> a.getHeight() > 170).distinct().collect(Collectors.toMap(a -> a.getName(), a -> a.getHeight()));System.out.println(map);// Object[] arr = students.stream().filter(a -> a.getHeight() > 170).toArray();Student[] arr = students.stream().filter(a -> a.getHeight() > 170).toArray(len -> new Student[len]);System.out.println(Arrays.toString(arr));}
}
相关文章:
【黑马java基础】Lamda, 方法引用,集合{Collection(List, Set), Map},Stream流
文章目录 JDK8新特性:Lambda表达式认识Lambda表达式Lambda表达式的省略规则 JDK8新特性:方法引用静态方法的引用实例方法的引用特定类型方法的引用构造器的应用 集合➡️Collection单列集合体系Collection的常用方法Collection的遍历方法迭代器增强for循…...

Stable Diffusion 使用详解(1)---- 提示词及相关参数
目录 背景 提示词 内容提示词 人物及主体特征 场景 环境光照 画幅视角 注意事项及示例 标准化提示词 画质等级 风格与真实性 具体要求 背景处理 光线与色彩 负向提示词 小结 常用工具 另外几个相关参数 迭代步数 宽度与高度 提示词引导系数 图片数量 背景…...
 - 无序数组排序后的最大相邻差)
数据结构和算法(刷题) - 无序数组排序后的最大相邻差
无序数组排序后的最大相邻差 问题:一个无序的整型数组,求出该数组排序后的任意两个相邻元素的最大差值?要求时间和空间复杂度尽可能低。 三种方法: 排序后计算比较 简介:用任意一种时间复杂度为 O ( n log n ) O…...

HOW - React 处理不紧急的更新和渲染
目录 useDeferredValueuseTransitionuseIdleCallback 在 React 中,有一些钩子函数可以帮助你处理不紧急的更新或渲染,从而优化性能和用户体验。 以下是一些常用的相关钩子及其应用场景: useDeferredValue 用途:用于处理高优先级…...

基于A律压缩的PCM脉冲编码调制通信系统simulink建模与仿真
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 4.1A律压缩的原理 4.2 PCM编码过程 4.3 量化噪声与信噪比 5.算法完整程序工程 1.算法运行效果图预览 (完整程序运行后无水印) 2.算法运行软件版本 matlab2022a 3.部分核心程序 &#…...
【入门教程一】基于DE2-115的My First FPGA 工程
1.1. 概述 这是一个简单的练习, 可以帮助初学者开始了解如何使用Intel Quartus 软件进行 FPGA 开发。 在本章节中,您将学习如何编译 Verilog 代码,进行引脚分配,创建时序约束,然后对 FPGA 进行编程,驱动开…...

mysql中的索引和分区
目录 1.编写目的 2.索引 2.1 创建方法 2.2 最佳适用 2.3 索引相关语句 3.分区 3.1 创建方法 3.2 最佳适用 Welcome to Code Blocks blog 本篇文章主要介绍了 [Mysql中的分区和索引] ❤博主广交技术好友,喜欢文章的可以关注一下❤ 1.编写目的 在MySQL中&…...

项目实战--C#实现图书馆信息管理系统
本项目是要开发一个图书馆管理系统,通过这个系统处理常见的图书馆业务。这个系统主要功能是:(1)有客户端(借阅者使用)和管理端(图书馆管理员和系统管理员使用)。(2&#…...

信号【Linux】
文章目录 信号处理方式(信号递达)前后台进程 终端按键产生信号kill系统调用接口向进程发信号阻塞信号sigset_tsigprocmasksigpending内核态与用户态:内核空间与用户空间内核如何实现信号的捕捉 1、信号就算没有产生,进程也必须识别…...

Kafka Producer之ACKS应答机制
文章目录 1. 应答机制2. 等级03. 等级14. 等级all5. 设置等级6. ISR 1. 应答机制 异步发送的效率高,但是不安全,同步发送安全,但是效率低。 无论哪一种,有一个关键的步骤叫做回调,也就是ACKS应答机制。 其中ACKS也分…...

【深入理解SpringCloud微服务】深入理解Eureka核心原理
深入理解Eureka核心原理 Eureka整体设计Eureka服务端启动Eureka三级缓存Eureka客户端启动 Eureka整体设计 Eureka是一个经典的注册中心,通过http接收客户端的服务发现和服务注册请求,使用内存注册表保存客户端注册上来的实例信息。 Eureka服务端接收的…...

算法——滑动窗口(day7)
904.水果成篮 904. 水果成篮 - 力扣(LeetCode) 题目解析: 根据题意我们可以看出给了我们两个篮子说明我们在开始采摘到结束的过程中只能有两种水果的种类,又要求让我们返回收集水果的最大数目,这不难让我们联想到题目…...

Django学习第一天(如何创建和运行app)
前置知识: URL组成部分详解: 一个url由以下几部分组成: scheme://host:port/path/?query-stringxxx#anchor scheme:代表的是访问的协议,一般为http或者ftp等 host:主机名,域名,…...

VScode连接虚拟机运行Python文件的方法
声明:本文使用Linux发行版本为rocky_9.4 目录 1. 在rocky_9.4最小安装的系统中,默认是没有tar工具的,因此,要先下载tar工具 2. 在安装好的vscode中下载ssh远程插件工具 3. 然后连接虚拟机 4. 查看python是否已经安装 5. 下载…...

通义千问AI模型对接飞书机器人-模型配置(2-1)
一 背景 根据业务或者使用场景搭建自定义的智能ai模型机器人,可以较少我们人工回答的沟通成本,而且可以更加便捷的了解业务需求给出大家设定的业务范围的回答,目前基于阿里云的通义千问模型研究。 二 模型研究 参考阿里云帮助文档…...

[k8s源码]6.reflector
Reflector 和 Informer 是 Kubernetes 客户端库中两个密切相关但职责不同的组件。Reflector 是一个较低级别的组件,主要负责与 Kubernetes API 服务器进行交互,执行资源的初始列表操作和持续的监视操作,将获取到的数据放入队列中。而 Informe…...

前台文本直接取数据库值doFieldSQL插入SQL
实现功能:根据选择的车间主任带出角色。 实现步骤:OA的“字段联动”功能下拉选项带不出表“hrmrolemembers”,所以采用此方法。 doFieldSQL("select roleid from HrmResource as a inner join hrmrolemembers as b on a.id b.resource…...

【06】LLaMA-Factory微调大模型——微调模型评估
上文【05】LLaMA-Factory微调大模型——初尝微调模型,对LLama-3与Qwen-2进行了指令微调,本文则介绍如何对微调后的模型进行评估分析。 一、部署微调后的LLama-3模型 激活虚拟环境,打开LLaMA-Factory的webui页面 conda activate GLM cd LLa…...

数学建模学习(1)遗传算法
一、简介 遗传算法(Genetic Algorithm, GA)是一种用于解决优化和搜索问题的进化算法。它基于自然选择和遗传学原理,通过模拟生物进化过程来寻找最优解。 以下是遗传算法的主要步骤和概念: 初始化种群(Initialization&a…...

NumPy冷知识66个
NumPy冷知识66个 多维切片: NumPy支持多维切片,可以通过指定多个索引来提取多维数组的子集。 复杂数支持: NumPy可以处理复数,提供了复数的基本运算和函数。 比特运算: NumPy支持比特运算,如与、或、异或等。 数据存储格式: NumPy可以将数…...
)
rknn优化教程(二)
文章目录 1. 前述2. 三方库的封装2.1 xrepo中的库2.2 xrepo之外的库2.2.1 opencv2.2.2 rknnrt2.2.3 spdlog 3. rknn_engine库 1. 前述 OK,开始写第二篇的内容了。这篇博客主要能写一下: 如何给一些三方库按照xmake方式进行封装,供调用如何按…...

微软PowerBI考试 PL300-选择 Power BI 模型框架【附练习数据】
微软PowerBI考试 PL300-选择 Power BI 模型框架 20 多年来,Microsoft 持续对企业商业智能 (BI) 进行大量投资。 Azure Analysis Services (AAS) 和 SQL Server Analysis Services (SSAS) 基于无数企业使用的成熟的 BI 数据建模技术。 同样的技术也是 Power BI 数据…...

STM32+rt-thread判断是否联网
一、根据NETDEV_FLAG_INTERNET_UP位判断 static bool is_conncected(void) {struct netdev *dev RT_NULL;dev netdev_get_first_by_flags(NETDEV_FLAG_INTERNET_UP);if (dev RT_NULL){printf("wait netdev internet up...");return false;}else{printf("loc…...

MySQL 8.0 OCP 英文题库解析(十三)
Oracle 为庆祝 MySQL 30 周年,截止到 2025.07.31 之前。所有人均可以免费考取原价245美元的MySQL OCP 认证。 从今天开始,将英文题库免费公布出来,并进行解析,帮助大家在一个月之内轻松通过OCP认证。 本期公布试题111~120 试题1…...
可以参考以下方法:)
根据万维钢·精英日课6的内容,使用AI(2025)可以参考以下方法:
根据万维钢精英日课6的内容,使用AI(2025)可以参考以下方法: 四个洞见 模型已经比人聪明:以ChatGPT o3为代表的AI非常强大,能运用高级理论解释道理、引用最新学术论文,生成对顶尖科学家都有用的…...

蓝桥杯 冶炼金属
原题目链接 🔧 冶炼金属转换率推测题解 📜 原题描述 小蓝有一个神奇的炉子用于将普通金属 O O O 冶炼成为一种特殊金属 X X X。这个炉子有一个属性叫转换率 V V V,是一个正整数,表示每 V V V 个普通金属 O O O 可以冶炼出 …...

Razor编程中@Html的方法使用大全
文章目录 1. 基础HTML辅助方法1.1 Html.ActionLink()1.2 Html.RouteLink()1.3 Html.Display() / Html.DisplayFor()1.4 Html.Editor() / Html.EditorFor()1.5 Html.Label() / Html.LabelFor()1.6 Html.TextBox() / Html.TextBoxFor() 2. 表单相关辅助方法2.1 Html.BeginForm() …...

windows系统MySQL安装文档
概览:本文讨论了MySQL的安装、使用过程中涉及的解压、配置、初始化、注册服务、启动、修改密码、登录、退出以及卸载等相关内容,为学习者提供全面的操作指导。关键要点包括: 解压 :下载完成后解压压缩包,得到MySQL 8.…...

API网关Kong的鉴权与限流:高并发场景下的核心实践
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 引言 在微服务架构中,API网关承担着流量调度、安全防护和协议转换的核心职责。作为云原生时代的代表性网关,Kong凭借其插件化架构…...

Spring Boot + MyBatis 集成支付宝支付流程
Spring Boot MyBatis 集成支付宝支付流程 核心流程 商户系统生成订单调用支付宝创建预支付订单用户跳转支付宝完成支付支付宝异步通知支付结果商户处理支付结果更新订单状态支付宝同步跳转回商户页面 代码实现示例(电脑网站支付) 1. 添加依赖 <!…...