爬虫学习2:爬虫爬取网页的信息与图片的方法
爬虫爬取网页的信息与图片的方法
import requestshead = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0"
}
# 这是get请求带参数的模式
def get_param():# 1、urlurl = "https://www.sogou.com/web?"# 2、发送请求 get带参数使用params参数response = requests.get(url, headers=head, params={"query": "刘亦菲"})# 3、获取想要的数据with open("./dilireba.html", "w", encoding="utf8") as fp:fp.write(response.text)print(type(response.text))pass
get_param()

import requests
def post_data():# 1、urlurl = 'https://fanyi.baidu.com/sug'# 2、发送请求response = requests.post(url, headers=head, data={"kw": "dog"})# 获取想要的数据print(response.json())
post_data()

import requests
from lxml import etree
if __name__ == '__main__':tree = etree.parse("./test.html")#读取文件# xpath返回的都是列表# / 标识一个层级print(tree.xpath("/html/body/div/p"))#找到想要数据的位置print(tree.xpath("/html/head/title"))# 定位百里守约 索引定位 从1开始print(tree.xpath("/html/body/div[1]/p"))#读取第一个div的pprint(tree.xpath("/html/body/div/p[1]"))#读取body下面所有div下的第一个p#print(tree.xpath("/html/body/div[2]/a[2]"))print(tree.xpath("/html/body/div[3]/ul/li[3]/a"))## # // 标识多个层级 属性定位 attr = class id# 定位李清照print(tree.xpath("//div[@class='song']/p[1]"))#查看class或id 对应的信息是不是独一无二的,如是采用div[@class='song']这种形式,如不是查看其上一级是不是独一无二的。print(tree.xpath("//div[@class='song']/a[@class='du']"))# # 取所有的li标签print(tree.xpath("//div[@class='tang']/ul/li"))# # 取li标签内的所有a标签for li in tree.xpath("//div[@class='tang']/ul/li"):try:#数据正确print("".join(li.xpath("./a/text()")))#将列表形式变成字符串形式except Exception as e:#数据失败,执行下一个,不会影响其他数据执行pass## # 取标签下的直系文本内容print(tree.xpath("/html/body/div[1]/p/text()"))# 取标签下的所有文本print(tree.xpath("/html/body/div[2]//text()"))# 取标签内的属性值 @attr_nameprint(tree.xpath("//div[@class='song']/img/@src"))

test.html文件
<html lang="en"><head><meta charset="UTF-8" /><title>测试bs4</title></head><body><div><p>百里守约</p></div><div class="song">你好<p>李清照</p><p>王安石</p><p>苏轼</p><p>柳宗元</p><a href="http://www.song.com/" title="赵匡胤" target="_self"><span>this is span</span>宋朝是最强大的王朝,不是军队的强大,而是经济很强大,国民都很有钱</a><a href="" class="du">总为浮云能蔽日,长安不见使人愁</a><img src="http://www.baidu.com/meinv.jpg" alt="" /></div><div class="tang"><ul>清明时节雨纷纷,路上行人欲断魂<li><a href="http://www.baidu.com" title="qing">清明时节雨纷纷,路上行人欲断魂,借问酒家何处有,牧童遥指杏花村</a></li><li><a href="http://www.163.com" title="qin">秦时明月汉时关,万里长征人未还,但使龙城飞将在,不教胡马度阴山</a></li><li><a href="http://www.126.com" alt="qi">岐王宅里寻常见,崔九堂前几度闻,正是江南好风景,落花时节又逢君</a></li><li><a href="http://www.sina.com" class="du">杜甫</a></li><li><a href="http://www.dudu.com" class="du">杜牧</a></li><li><b>杜小月</b></li><li><i>度蜜月</i></li><li><a href="http://www.haha.com" id="feng">凤凰台上凤凰游,凤去台空江自流,吴宫花草埋幽径,晋代衣冠成古丘</a></li></ul></div></body>
</html>
# pip install fake_useragent
import timeimport requests
import fake_useragent
from lxml import etree
import reif __name__ == '__main__':# UA伪装head = {# "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0""User-Agent": fake_useragent.UserAgent().random}# 打开一个文件写入数据fp = open("./doubanFilm.txt", "w", encoding="utf8")# 1、url# url = "https://movie.douban.com/top250"# url2 = "https://movie.douban.com/top250?start=25&filter="# url3 = "https://movie.douban.com/top250?start=50&filter="for i in range(0, 250, 25):#所有网页地址url = f"https://movie.douban.com/top250?start={i}&filter="time.sleep(5)# 2、发送请求response = requests.get(url, headers=head)# 3、获取想要的数据res_text = response.text# 4、数据解析tree = etree.HTML(res_text)# 定位所有的li标签li_list = tree.xpath("//ol[@class='grid_view']/li") # 所有的li标签,包含信息for li in li_list:film_name = "".join(li.xpath(".//span[@class='title'][1]/text()")) # 改成字符串形式director_actor_y_country_type = "".join(li.xpath(".//div[@class='bd']/p[1]/text()"))score = "".join(li.xpath(".//span[@class='rating_num']/text()"))quote = "".join(li.xpath(".//span[@class='inq']/text()"))# director_actor_y_country_type需要修改new_str = director_actor_y_country_type.strip() # 去除空格y = re.match(r"([\s\S]+?)(\d+)(.*?)", new_str).group(2) # 正则表达式方式country = new_str.rsplit("/")[-2].strip()types = new_str.rsplit("/")[-1].strip()director = re.match(r"导演: ([a-zA-Z\u4e00-\u9fa5·]+)(.*?)", new_str).group(1)try:actor = re.match(r"(.*?)主演: ([a-zA-Z\u4e00-\u9fa5·]+)(.*?)", new_str).group(2)except Exception as e:actor = "no"fp.write(film_name + "#" + y + "#" + country + "#" + types + "#" + director + "#" +actor + "#" + score + "#" + quote + "\n") # 连接信息,连接符最好采用不常见的符号防止误读取print(film_name, y, country, types, director, actor, score, quote)fp.close()

import os.path
import fake_useragent
import requests
from lxml import etree
# UA伪装
head = {"User-Agent": fake_useragent.UserAgent().random#自动伪装
}
pic_name = 0
def request_pic(url):# 2、发送请求response = requests.get(url, headers=head)# 3、获取想要的数据res_text = response.text# 4、数据解析tree = etree.HTML(res_text)li_list = tree.xpath("//div[@class='slist']/ul/li")#获取所有的照片信息for li in li_list:# 1、获取照片的urlimg_url = "https://pic.netbian.com" + "".join(li.xpath("./a/img/@src"))#img/@src,代表img的src属性# 2、发送请求img_response = requests.get(img_url, headers=head)# 3、获取想要的数据img_content = img_response.contentglobal pic_namewith open(f"./picLib/{pic_name}.jpg", "wb") as fp:#命名照片名称,并写下fp.write(img_content)pic_name += 1
if __name__ == '__main__':if not os.path.exists("./picLib"):#若没有一个此文件夹,建立一个文件夹存放照片os.mkdir("./picLib")# 1、urlurl = "https://pic.netbian.com/4kdongman/"request_pic(url)for i in range(2,10):#之后照片的urlnext_url = f"https://pic.netbian.com/4kdongman/index_{i}.html"request_pic(next_url)pass

相关文章:
爬虫学习2:爬虫爬取网页的信息与图片的方法
爬虫爬取网页的信息与图片的方法 爬取人物信息 import requestshead {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0" } # 这是get请求带参数的模式…...

MySQL定时备份数据,并上传到oss
1.环境准备 1.安装阿里云的ossutil 2.安装mysql 2.编写脚本 脚本内容如下 #!/bin/bash # 数据库的配置信息,根据自己的情况进行填写 db_hostlocalhost db_usernameroot db_passwordroot db_namedb_root # oss 存贮数据的bucket地址 bucket_namerbsy-backup-buck…...
)
极速删除 node_modules 仅3 秒()
今天教大家如何快速删除 node_modules 依赖的一个小秘诀,告别繁琐!!! 前言 作为前端开发者,相信大家都曾经历过删除 node_modules 文件夹时的漫长等待。 尤其是在处理那些依赖库繁多的项目时,删除操作…...

vue this.$refs 动态拼接
业务需要,refs是不固定的 <vxe-grid refgridWarehouse v-bind"gridWarehouseOptions" v-if"tableHeight" :height"tableHeight":expand-config"{iconOpen: vxe-icon-square-minus, iconClose: vxe-icon-square-plus}"c…...

一次搞定!中级软件设计师备考通关秘籍
大家好,我是小欧! 今天我们来聊聊软考这个话题。要是你准备参加计算机技术与软件专业技术资格(软考),那么这篇文章就是为你量身定做的。话不多说,咱们直接进入正题。 什么是软考? 软考…...

第十六讲 python中的序列-列表简介-特点-常用方法-创建-添加-删除-访问-切片-排序-复制-反转
目录 1. 序列的本质和内存结构 2.列表 2.1 列表简介 2.2 列表的特点 2.3 列表对象的常用方法大全: 2.4 列表的创建 2.4.1 使用方括号 [] 2.4.2 使用 list() 函数 2.4.3 使用 range() 函数 2.4.3.1 range的基本用法 2.4.3.2 返回值 2.4.3.3 range的使用例子 2.4.3.4 range的使…...

大模型日报 2024-07-22
大模型日报 2024-07-22 大模型资讯 谷歌将在ICML 2024展示机器学习研究成果 摘要: 谷歌研究人员将在ICML 2024会议上展示他们在机器学习领域的探索,从理论到应用,构建解决深层问题的ML系统。 代理符号学习:优化AI系统符号组件的框架 摘要: 大…...

Electron 的open-file事件
在 Electron 中,open-file 事件是一个重要的事件,它允许开发者在应用程序已经运行的情况下,通过文件打开请求(如双击文件或在命令行中使用 open 命令打开文件)来捕获文件路径。以下是对 open-file 事件的详细解析: 触发条件 应用已经打开。用户通过双击与应用程序关联的…...

前端面试 vue 接口权限控制
接口权限目前一般采用jwt的形式来验证,没有通过的话一般返回401,跳转到登录页面重新进行登录 对于 jwt的理解 (前端接口权限的控制主要通过接口权限配置和JWT(Json Web Token)技术来实现。 首先,…...

【DevOps系列】构建Devops系统
开始介绍 那就着手开始干吧。先介绍一下我们的工具链。 主要工具:GitHub、Jenkins、Kubernetes、Ansible、Prometheus和JMeter 着手动 1. 设置GitHub作为源代码仓库 登录GitHub: 打开浏览器并访问 https://github.com,使用您的GitHub账户登录。 创建…...
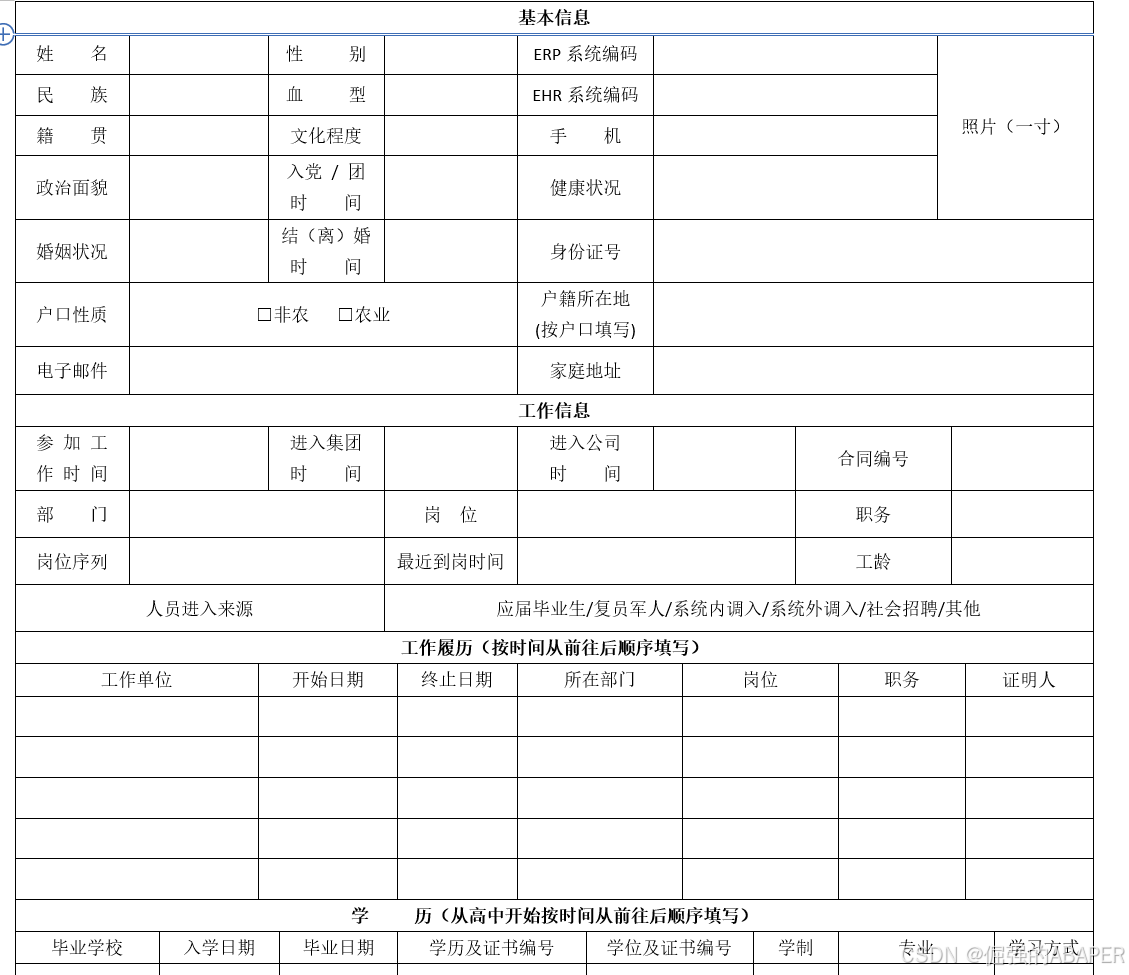
ABAP打印WORD的解决方案
客户要求按照固定格式输出到WORD模板中,目前OLE和DOI研究了均不太适合用于这种需求。 cl_docx_document类可以将WORD转化为XML文件,利用替换字符串方法将文档内容进行填充同 时不破坏WORD现有格式。 首先需要将WORD的单元格用各种预定义的字符进行填充,为后续替换作准备…...
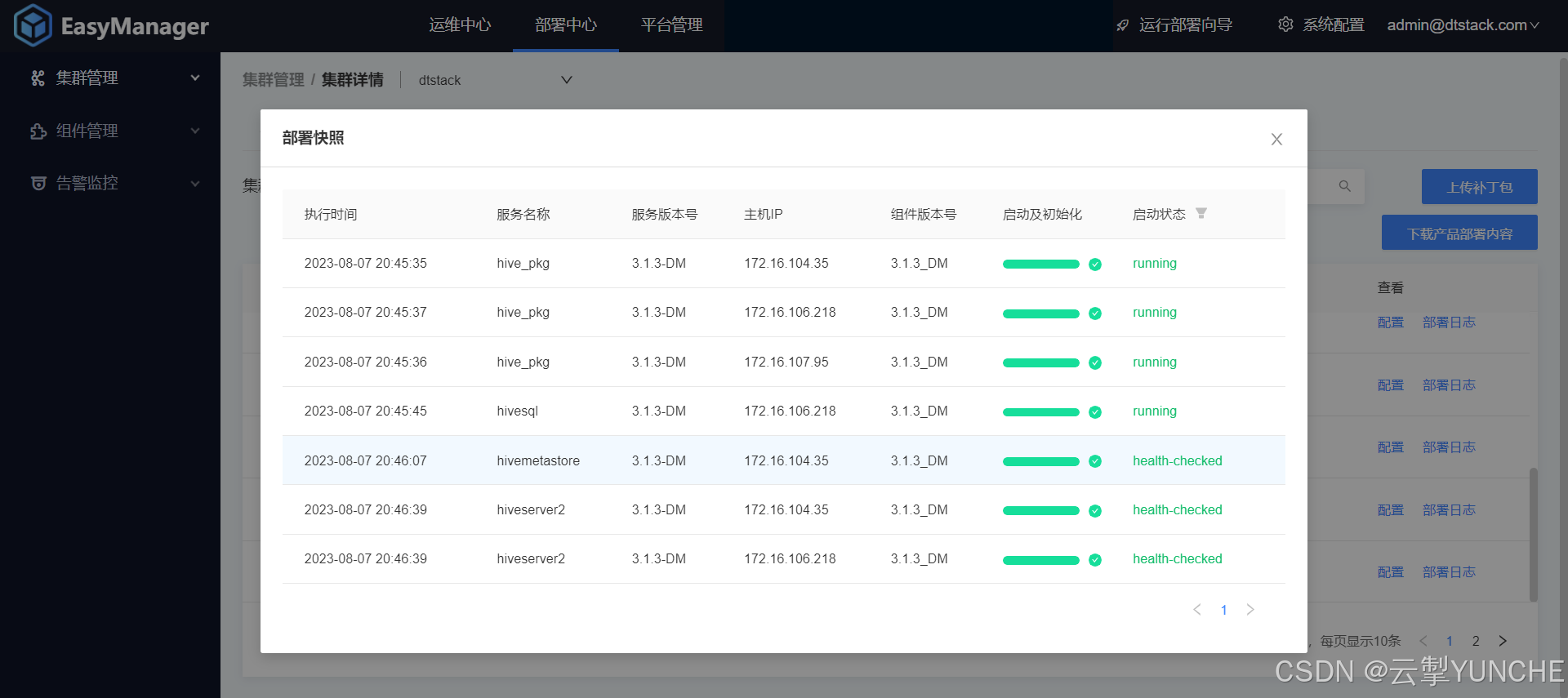
emr部署hive并适配达梦数据库
作者:振鹭 一、达梦 用户、数据库初始化 1、创建hive的元数据库 create tablespace hive_meta datafile /dm8/data/DAMENG/hive_meta.dbf size 100 autoextend on next 1 maxsize 2048;2、创建数据库的用户 create user hive identified by "hive12345&quo…...

王春城:怎么用精益思维重塑企业战略规划格局?
当下,企业战略规划的灵活性和适应性变得至关重要。传统的战略规划方法往往过于僵化和静态,难以应对市场的不确定性和变化。因此,引入精益思维来重塑企业战略规划格局,成为了许多企业寻求突破和创新的途径。具体步骤如深圳天行健企…...
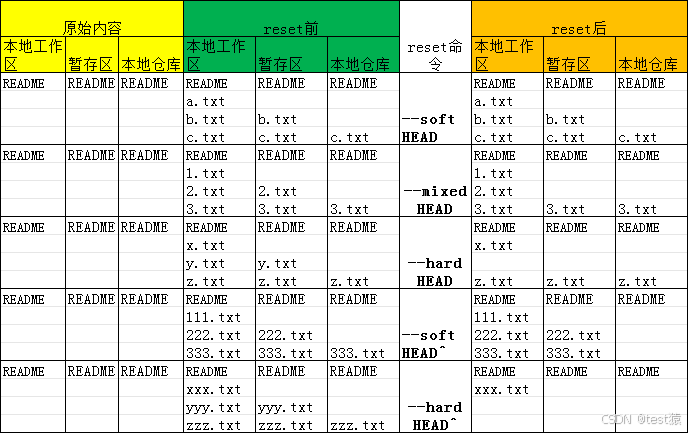
git reset
git reset [--soft | --mixed | --hard] [HEAD] 表格版 原始内容reset前reset命令reset后本地工作区暂存区本地仓库本地工作区暂存区本地仓库本地工作区暂存区本地仓库READMEREADMEREADMEREADMEREADMEREADME--soft HEADREADMEREADMEREADMEa.txta.txtb.txtb.txtb.txtb.txtc.tx…...

E17.【C语言】练习:sizeof和strlen的辨析
先回顾http://t.csdnimg.cn/aYHl6 1. char acX[] "abcdefg"; char acY[] { a,b,c,d,e,f,g}; 以下说法正确的是( ) A.数组acX和数组acY等价 B.数组acX和数组acY的长度相同 C.sizeof(acX)>sizeof (acY) D.strlen (acX)>strlen (acY) 分析:…...

便携气象站:科技助力气象观测
在科技飞速发展的今天,便携气象站以其轻便、高效、全面的特点,正逐渐改变着气象观测的传统模式。这款小巧而强大的设备,不仅为气象学研究和气象灾害预警提供了有力支持,更为户外活动、农业生产等领域带来了诸多便利。 便携气象站是…...

php 存储复杂的json格式查询(如:经纬度)
在开发中,有时我们可能存了一些复杂json格式不知道怎么查。我这里提供给大家参考下: 一、先上表数据格式(location字段的possiton经纬度以逗号分开的) {"title":"澳海文澜府","position":"11…...

UDP网口(1)概述
文章目录 1.计算机网络知识在互联网中的应用2.认识FPGA实现UDP网口通信3.FPGA实现UDP网口通信的方案4.FPGA实现UDP网口文章安排5.传送门 1.计算机网络知识在互联网中的应用 以在浏览器中输入淘宝网为例,介绍数据在互联网是如何传输的。我们将要发送的数据包称作A&a…...

Linux - 进程的概念、状态、僵尸进程、孤儿进程及进程优先级
进程基本概念 课本概念:在编程或软件工程的上下文中,进程通常被视为正在执行的程序的实例。当你启动一个应用程序时,操作系统会为这个程序创建一个进程。每个进程都有自己的独立内存空间,可以运行自己的指令序列,并可能…...

Gradle依赖报告:项目依赖树的X光机
Gradle依赖报告:项目依赖树的X光机 在复杂的软件项目中,依赖管理是确保应用正常构建和运行的关键。Gradle作为一个强大的构建工具,提供了依赖报告功能,帮助开发者分析和理解项目的依赖树。本文将详细介绍如何在Gradle中使用依赖报…...

装饰模式(Decorator Pattern)重构java邮件发奖系统实战
前言 现在我们有个如下的需求,设计一个邮件发奖的小系统, 需求 1.数据验证 → 2. 敏感信息加密 → 3. 日志记录 → 4. 实际发送邮件 装饰器模式(Decorator Pattern)允许向一个现有的对象添加新的功能,同时又不改变其…...

基于大模型的 UI 自动化系统
基于大模型的 UI 自动化系统 下面是一个完整的 Python 系统,利用大模型实现智能 UI 自动化,结合计算机视觉和自然语言处理技术,实现"看屏操作"的能力。 系统架构设计 #mermaid-svg-2gn2GRvh5WCP2ktF {font-family:"trebuchet ms",verdana,arial,sans-…...

Unity3D中Gfx.WaitForPresent优化方案
前言 在Unity中,Gfx.WaitForPresent占用CPU过高通常表示主线程在等待GPU完成渲染(即CPU被阻塞),这表明存在GPU瓶颈或垂直同步/帧率设置问题。以下是系统的优化方案: 对惹,这里有一个游戏开发交流小组&…...

最新SpringBoot+SpringCloud+Nacos微服务框架分享
文章目录 前言一、服务规划二、架构核心1.cloud的pom2.gateway的异常handler3.gateway的filter4、admin的pom5、admin的登录核心 三、code-helper分享总结 前言 最近有个活蛮赶的,根据Excel列的需求预估的工时直接打骨折,不要问我为什么,主要…...

智能在线客服平台:数字化时代企业连接用户的 AI 中枢
随着互联网技术的飞速发展,消费者期望能够随时随地与企业进行交流。在线客服平台作为连接企业与客户的重要桥梁,不仅优化了客户体验,还提升了企业的服务效率和市场竞争力。本文将探讨在线客服平台的重要性、技术进展、实际应用,并…...

如何为服务器生成TLS证书
TLS(Transport Layer Security)证书是确保网络通信安全的重要手段,它通过加密技术保护传输的数据不被窃听和篡改。在服务器上配置TLS证书,可以使用户通过HTTPS协议安全地访问您的网站。本文将详细介绍如何在服务器上生成一个TLS证…...

新能源汽车智慧充电桩管理方案:新能源充电桩散热问题及消防安全监管方案
随着新能源汽车的快速普及,充电桩作为核心配套设施,其安全性与可靠性备受关注。然而,在高温、高负荷运行环境下,充电桩的散热问题与消防安全隐患日益凸显,成为制约行业发展的关键瓶颈。 如何通过智慧化管理手段优化散…...

多种风格导航菜单 HTML 实现(附源码)
下面我将为您展示 6 种不同风格的导航菜单实现,每种都包含完整 HTML、CSS 和 JavaScript 代码。 1. 简约水平导航栏 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport&qu…...

基于Java Swing的电子通讯录设计与实现:附系统托盘功能代码详解
JAVASQL电子通讯录带系统托盘 一、系统概述 本电子通讯录系统采用Java Swing开发桌面应用,结合SQLite数据库实现联系人管理功能,并集成系统托盘功能提升用户体验。系统支持联系人的增删改查、分组管理、搜索过滤等功能,同时可以最小化到系统…...

GO协程(Goroutine)问题总结
在使用Go语言来编写代码时,遇到的一些问题总结一下 [参考文档]:https://www.topgoer.com/%E5%B9%B6%E5%8F%91%E7%BC%96%E7%A8%8B/goroutine.html 1. main()函数默认的Goroutine 场景再现: 今天在看到这个教程的时候,在自己的电…...