【07】LLaMA-Factory微调大模型——微调模型导出与微调参数分析
上文介绍了如何对微调后的模型进行使用与简单评估。本文将介绍对微调后的模型进行导出的过程。
一、llama-3微调后的模型导出
首先进入虚拟环境,打开LLaMA-Factory的webui页面
conda activate GLM
cd LLaMA-Factory
llamafactory-cli webui
之后,选择微调后模型对应的检查点路径文件,设置最大分块的大小,建议2-5GB,选择导出设备的类型并对导出目录进行指定。

完成配置后开始导出模型

模型导出后,可在对应的路径下查看其参数详细情况

二、调用导出后的模型
在LLaMA-Factory的webui页面中选择chat标签,模型路径输入导出后模型的绝对路径,从而加载模型机械能对话

模型成功加载后,即可使用问答框进行应用,至此导出后的模型可应用于实际的生成环境之中

使用测试用例进行分析,可发现与模型微调评估的效果一致,模型导出与应用完成
三、模型微调参数分析
模型微调应用,参数的选择极为关键,具体参数分析可见以下这篇博客
LLaMA-Factory参数的解答(命令,单卡,预训练)_llama-factory 增量预训练-CSDN博客![]() https://blog.csdn.net/m0_69655483/article/details/138229566?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7ERate-1-138229566-blog-139495955.235%5Ev43%5Epc_blog_bottom_relevance_base2&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7ERate-1-138229566-blog-139495955.235%5Ev43%5Epc_blog_bottom_relevance_base2&utm_relevant_index=1现对关键的几个参数进行分析
https://blog.csdn.net/m0_69655483/article/details/138229566?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7ERate-1-138229566-blog-139495955.235%5Ev43%5Epc_blog_bottom_relevance_base2&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7ERate-1-138229566-blog-139495955.235%5Ev43%5Epc_blog_bottom_relevance_base2&utm_relevant_index=1现对关键的几个参数进行分析
(1)finetuning_type lora
使用LoRA(Low-Rank Adaptation)作为微调类型。
其他参数
1.Full:这种方式就是从头到尾完全训练一个模型。想象一下,你有一块白纸,你要在上面画出一幅完整的画作,这就是Full Training。你从零开始,逐步训练模型,直到它能够完成你想要的任务。
2.Freeze:这种方式有点像是在一幅半完成的画上继续作画。在模型中,有些部分(通常是模型的初级部分,如输入层或底层特征提取部分)是已经训练好的,这部分会被“冻结”,不再在训练过程中更新。你只更新模型的其他部分,这样可以节省训练时间和资源。
3.LoRA:这是一种比较新的技术,全称是“Low-Rank Adaptation”。可以理解为一种轻量级的模型调整方式。它主要是在模型的某些核心部分插入小的、低秩的矩阵,通过调整这些小矩阵来实现对整个模型的微调。这种方法不需要对原始模型的大部分参数进行重训练,从而可以在不牺牲太多性能的情况下,快速适应新的任务或数据。
4.QLoRA:这是在LoRA的基础上进一步发展的一种方法。它使用量化技术(也就是用更少的比特来表示每个数字),来进一步减少模型调整过程中需要的计算资源和存储空间。这样做可以使得模型更加高效,尤其是在资源有限的设备上运行时。
(2)gradient_accumulation_steps
梯度累积步数,用于在更新模型前累积更多的梯度,有助于使用较小的批次大小训练大模型。选择多少步骤进行梯度累积取决于你的具体需求和硬件限制。一般来说,步数越多,模拟的批量大小就越大,但同时每次更新权重的间隔也更长,可能会影响训练速度和效率。
(3)lr_scheduler_type
学习率调度器类型
linear(线性):
描述:学习率从一个较高的初始值开始,然后随着时间线性地减少到一个较低的值。
使用场景:当你想要让模型在训练早期快速学习,然后逐渐减慢学习速度以稳定收敛时使用。cosine(余弦):
描述:学习率按照余弦曲线的形状进行周期性调整,这种周期性的起伏有助于模型在不同的训练阶段探索参数空间。
使用场景:在需要模型在训练过程中不断找到新解的复杂任务中使用,比如大规模的图像或文本处理。cosine_with_restarts(带重启的余弦):
描述:这是余弦调整的一种变体,每当学习率达到一个周期的最低点时,会突然重置到最高点,然后再次减少。
使用场景:适用于需要模型从局部最优解中跳出来,尝试寻找更好全局解的情况。polynomial(多项式):
描述:学习率按照一个多项式函数减少,通常是一个幂次递减的形式。
使用场景:当你需要更精细控制学习率减少速度时使用,适用于任务比较复杂,需要精细调优的模型。constant(常数):
描述:学习率保持不变。
使用场景:简单任务或者小数据集,模型容易训练到足够好的性能时使用。constant_with_warmup(带预热的常数):
描述:开始时使用较低的学习率“预热”模型,然后切换到一个固定的较高学习率。
使用场景:在训练大型模型或复杂任务时,帮助模型稳定地开始学习,避免一开始就进行大的权重调整。inverse_sqrt(逆平方根):
描述:学习率随训练步数的增加按逆平方根递减。
使用场景:常用于自然语言处理中,特别是在训练Transformer模型时,帮助模型在训练后期进行细微的调整。reduce_lr_on_plateau(在平台期降低学习率):
描述:当模型的验证性能不再提升时,自动减少学习率。
使用场景:适用于几乎所有类型的任务,特别是当模型很难进一步提高性能时,可以帮助模型继续优化和提升。
(4)warmup_steps

学习率预热步数。
预热步数(Warmup Steps):
这是模型训练初期用于逐渐增加学习率的步骤数。在这个阶段,学习率从一个很小的值(或者接近于零)开始,逐渐增加到设定的初始学习率。这个过程可以帮助模型在训练初期避免因为学习率过高而导致的不稳定,比如参数更新过大,从而有助于模型更平滑地适应训练数据。
例如,如果设置warmup_steps为20,那么在前20步训练中,学习率会从低到高逐步增加。
预热步数的具体数值通常取决于几个因素:
训练数据的大小:数据集越大,可能需要更多的预热步骤来帮助模型逐步适应。
模型的复杂性:更复杂的模型可能需要更长时间的预热,以避免一开始就对复杂的参数空间进行过激的调整。
总训练步数:如果训练步数本身就很少,可能不需要很多的预热步骤;反之,如果训练步数很多,增加预热步骤可以帮助模型更好地启动。
(5)save_steps eval_steps
保存和评估的步数
(6)learning_rate

学习率是机器学习和深度学习中控制模型学习速度的一个参数。你可以把它想象成你调节自行车踏板力度的旋钮:旋钮转得越多,踏板动得越快,自行车就跑得越快;但如果转得太快,可能会导致自行车失控。同理,学习率太高,模型学习过快,可能会导致学习过程不稳定;学习率太低,模型学习缓慢,训练时间长,效率低。
常见的学习率参数包括但不限于:
1e-1(0.1):相对较大的学习率,用于初期快速探索。
1e-2(0.01):中等大小的学习率,常用于许多标准模型的初始学习率。
1e-3(0.001):较小的学习率,适用于接近优化目标时的细致调整。
1e-4(0.0001):更小的学习率,用于当模型接近收敛时的微调。
5e-5(0.00005):非常小的学习率,常见于预训练模型的微调阶段,例如在自然语言处理中微调BERT模型。
选择学习率的情况:
快速探索:在模型训练初期或者当你不确定最佳参数时,可以使用较大的学习率(例如0.1或0.01),快速找到一个合理的解。
细致调整:当你发现模型的性能开始稳定,但还需要进一步优化时,可以减小学习率(例如0.001或0.0001),帮助模型更精确地找到最优解。
微调预训练模型:当使用已经预训练好的模型(如在特定任务上微调BERT)时,通常使用非常小的学习率(例如5e-5或更小),这是因为预训练模型已经非常接近优化目标,我们只需要做一些轻微的调整。
(7)精度相关
FP16 (Half Precision,半精度):
这种方式使用16位的浮点数来保存和计算数据。想象一下,如果你有一个非常精细的秤,但现在只用这个秤的一半精度来称重,这就是FP16。它不如32位精度精确,但计算速度更快,占用的内存也更少。
BF16 (BFloat16):
BF16也是16位的,但它在表示数的方式上和FP16不同,特别是它用更多的位来表示数的大小(指数部分),这让它在处理大范围数值时更加稳定。你可以把它想象成一个专为机器学习优化的“半精度”秤,尤其是在使用特殊的硬件加速器时。
FP32 (Single Precision,单精度):
这是使用32位浮点数进行计算的方式,可以想象为一个标准的、全功能的精细秤。它在深度学习中非常常见,因为它提供了足够的精确度,适合大多数任务。
Pure BF16:
在表示数的方式上和FP16不同,特别是它用更多的位来表示数的大小(指数部分),这让它在处理大范围数值时更加稳定。你可以把它想象成一个专为机器学习优化的“半精度”秤,尤其是在使用特殊的硬件加速器时。
FP32 (Single Precision,单精度):
这是使用32位浮点数进行计算的方式,可以想象为一个标准的、全功能的精细秤。它在深度学习中非常常见,因为它提供了足够的精确度,适合大多数任务。
Pure BF16:
这种模式下,所有计算都仅使用BF16格式。这意味着整个模型训练过程中,从输入到输出,都在使用为机器学习优化的半精度计算。
(8)LoRA的秩

LoRA(Low-Rank Approximation)是一种用于大模型微调的方法,它通过降低模型参数矩阵的秩来减少模型的计算和存储成本。在微调大模型时,往往需要大量的计算资源和存储空间,而LoRA可以通过降低模型参数矩阵的秩来大幅度减少这些需求。
具体来说,LoRA使用矩阵分解方法,将模型参数矩阵分解为两个较低秩的矩阵的乘积。这样做的好处是可以用较低秩的矩阵近似代替原始的参数矩阵,从而降低了模型的复杂度和存储需求。
在微调过程中,LoRA首先将模型参数矩阵分解为两个较低秩的矩阵。然后,通过对分解后的矩阵进行微调,可以得到一个近似的模型参数矩阵。这个近似矩阵可以在保持较高性能的同时大幅度减少计算和存储资源的使用。
LoRA的秩可以根据模型的需求进行设置。一般来说,秩越低,模型的复杂度越低,但性能可能会受到一定的影响。所以在微调大模型时,需要根据具体情况来选择合适的秩大小,以平衡模型的性能和资源的使用。
建议根据硬件条件进行选择,一般可选16或32,模型微调效果较佳。
(9)LoRA的缩放系数
缩放系数是用来表示模型中每个层的相对重要性的参数。在LoRA中,每个层都有一个缩放系数,用于调整该层对总体损失函数的贡献。较高的缩放系数表示该层的权重更大,较低的缩放系数表示该层的权重较小。
缩放系数的选取可以根据问题的特点和需求进行调整。通常情况下,较低层的缩放系数可以设置为较小的值,以保留更多的原始特征信息;而较高层的缩放系数可以设置为较大的值,以强调更高级别的抽象特征。
小结
本文介绍了对微调后的模型进行导出的过程与对微调过程中使用的参数进行分析的内容,下文【08】LLaMA-Factory微调大模型——GLM-4模型微调全流程将重数据准备到模型导出全流程进行记录分析。欢迎您持续关注,如果本文对您有所帮助,感谢您一键三连,多多支持。
相关文章:
【07】LLaMA-Factory微调大模型——微调模型导出与微调参数分析
上文介绍了如何对微调后的模型进行使用与简单评估。本文将介绍对微调后的模型进行导出的过程。 一、llama-3微调后的模型导出 首先进入虚拟环境,打开LLaMA-Factory的webui页面 conda activate GLM cd LLaMA-Factory llamafactory-cli webui 之后,选择…...
动态路由协议 —— EIGRP 与 OSPF 的区别
EIGRP(增强内部网关路由协议)和 OSPF(开放式最短路径优先)是两种最常见的动态路由协议,主要是用来指定路由器或交换机之间如何通信。将其应用于不同的情况下,可提高速率、延迟等方面的性能。那么它们之间到…...

【中项】系统集成项目管理工程师-第5章 软件工程-5.1软件工程定义与5.2软件需求
前言:系统集成项目管理工程师专业,现分享一些教材知识点。觉得文章还不错的喜欢点赞收藏的同时帮忙点点关注。 软考同样是国家人社部和工信部组织的国家级考试,全称为“全国计算机与软件专业技术资格(水平)考试”&…...

HarmonyOS应用开发者高级认证,Next版本发布后最新题库 - 多选题序号1
基础认证题库请移步:HarmonyOS应用开发者基础认证题库 注:有读者反馈,题库的代码块比较多,打开文章时会卡死。所以笔者将题库拆分,单选题20个为一组,多选题10个为一组,题库目录如下,…...

Windows11(24H2)LTSC长期版下载!提前曝光Build26100?
系统;windows11 文章目录 前言一、LTSC是什么?二、 Windows 11 Vision 24H2 LTSC 的版本号为 Build 26100,镜像中提供以下三个 SKU:总结 前言 好的系统也能给你带来不一样的效果。 一、LTSC是什么? & & L…...

【北京迅为】《i.MX8MM嵌入式Linux开发指南》-第三篇 嵌入式Linux驱动开发篇-第四十三章 驱动模块传参
i.MX8MM处理器采用了先进的14LPCFinFET工艺,提供更快的速度和更高的电源效率;四核Cortex-A53,单核Cortex-M4,多达五个内核 ,主频高达1.8GHz,2G DDR4内存、8G EMMC存储。千兆工业级以太网、MIPI-DSI、USB HOST、WIFI/BT…...

uniapp 小程序 支付逻辑处理
uniapp 小程序 支付逻辑处理 上代码如果你不需要支付宝适配,可以删除掉支付宝的条件判断代码 <button class"subBtn" :disabled"submiting" click"goPay">去支付</button>// 以下代码你需要改的地方// 1. order/app/v1…...

scikit-learn库学习之make_regression函数
scikit-learn库学习之make_regression函数 一、简介 make_regression是scikit-learn库中用于生成回归问题数据集的函数。它主要用于创建合成的回归数据集,以便在算法的开发和测试中使用。 二、语法和参数 sklearn.datasets.make_regression(n_samples100, n_feat…...
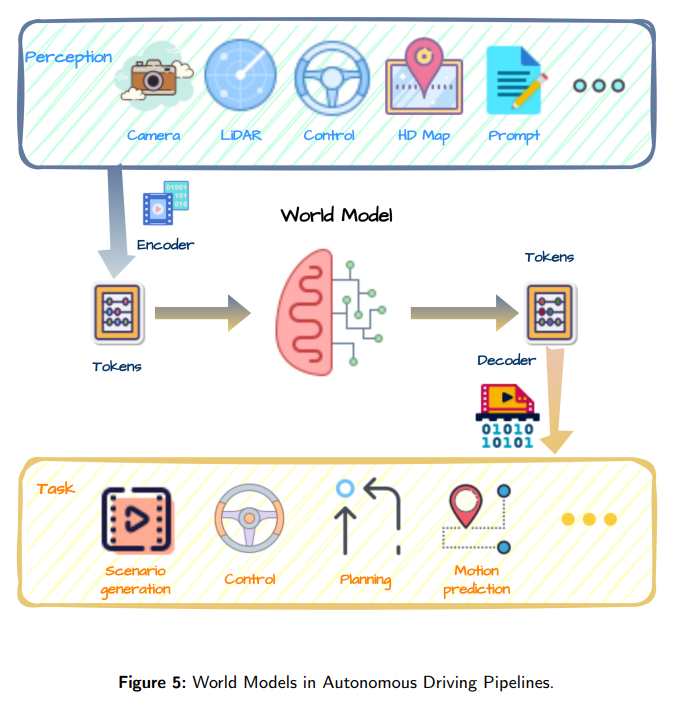
经典文献阅读之--World Models for Autonomous Driving(自动驾驶的世界模型:综述)
Tip: 如果你在进行深度学习、自动驾驶、模型推理、微调或AI绘画出图等任务,并且需要GPU资源,可以考虑使用UCloud云计算旗下的Compshare的GPU算力云平台。他们提供高性价比的4090 GPU,按时收费每卡2.6元,月卡只需要1.7元每小时&…...
)
孙健提到的实验室的研究方向之一是什么?()
孙健提到的实验室的研究方向之一是什么?() 点击查看答案 A.虚拟现实B.环境感知和理解 C.智能体博弈D.所有选项都正确 图灵奖是在哪一年设立的?() A.1962B.1966 C.1976D.1986 孙健代表的实验室的前身主要研究什么?&…...

初级java每日一道面试题-2024年7月23日-Iterator和ListIterator有什么区别?
面试官: Iterator和ListIterator有什么区别? 我回答: Iterator和ListIterator都是Java集合框架中用于遍历集合元素的接口,但它们之间存在一些关键的区别,主要体现在功能和使用场景上。下面我将详细解释这两种迭代器的不同之处: 1. Iterat…...

2024-07-23 Unity AI行为树2 —— 项目介绍
文章目录 1 项目介绍2 AI 代码介绍2.1 BTBaseNode / BTControlNode2.2 动作/条件节点2.3 选择 / 顺序节点 3 怪物实现4 其他功能5 UML 类图 项目借鉴 B 站唐老狮 2023年直播内容。 点击前往唐老狮 B 站主页。 1 项目介绍 本项目使用 Unity 2022.3.32f1c1,实现基…...

Unity-URP-SSAO记录
勾选After Opacity Unity-URP管线,本来又一个“bug”, 网上查不到很多关于ssao的资料 以为会不会又是一个极度少人用的东西 而且几乎都是要第三方替代 也完全没有SSAO大概的消耗是多少,完全是黑盒(因为用的人少,研究的人少,优…...

无人机上磁航技术详解
磁航技术,也被称为地磁导航,是一种利用地球磁场信息来实现导航的技术。在无人机领域,磁航技术主要用于辅助惯性导航系统(INS)进行航向角的测量与校正,提高无人机的飞行稳定性和准确性。其技术原理是&#x…...

使用 cURL 命令测试网站响应时间
文章目录 使用 cURL 命令测试网站响应时间工具介绍cURL 命令详解命令参数说明输出格式说明示例运行结果总结使用 cURL 命令测试网站响应时间 本文将介绍如何使用 cURL 命令行工具来测试一个网站的响应时间。具体来说,我们将使用 cURL 命令来测量并显示各种网络性能指标,包括 …...

「网络通信」HTTP 协议
HTTP 🍉简介🍉抓包工具🍉报文结构🍌请求🍌响应🍌URL🥝URL encode 🍌方法🍌报文字段🥝Host🥝Content-Length & Content-Type🥝User…...

科普文:后端性能优化的实战小结
一、背景与效果 ICBU的核心沟通场景有了10年的“积累”,核心场景的界面响应耗时被拉的越来越长,也让性能优化工作提上了日程,先说结论,经过这一波前后端齐心协力的优化努力,两个核心界面90分位的数据,FCP平…...

LeetCode-day23-3098. 求出所有子序列的能量和
LeetCode-day23-3098. 求出所有子序列的能量和 题目描述示例示例1:示例2:示例3: 思路代码 题目描述 给你一个长度为 n 的整数数组 nums 和一个 正 整数 k 。 一个 子序列的 能量 定义为子序列中 任意 两个元素的差值绝对值的 最小值 。 请…...
CSS3雷达扫描效果
CSS3雷达扫描效果https://www.bootstrapmb.com/item/14840 要创建一个CSS3的雷达扫描效果,我们可以使用CSS的动画(keyframes)和transform属性。以下是一个简单的示例,展示了如何创建一个类似雷达扫描的动画效果: HTM…...

单例模式懒汉模式和饿汉模式
线程安全 单例模式在单线程中,当然是安全的。但是如果在多线程中,由于并行判断,可能会导致创建多个实例。那么如何保证在多线程中单例还是只有一个实例呢? 常见的三种方式: 局部静态变量 原理和饿汉模式相似,利用static只会初始…...

设计模式和设计原则回顾
设计模式和设计原则回顾 23种设计模式是设计原则的完美体现,设计原则设计原则是设计模式的理论基石, 设计模式 在经典的设计模式分类中(如《设计模式:可复用面向对象软件的基础》一书中),总共有23种设计模式,分为三大类: 一、创建型模式(5种) 1. 单例模式(Sing…...

Prompt Tuning、P-Tuning、Prefix Tuning的区别
一、Prompt Tuning、P-Tuning、Prefix Tuning的区别 1. Prompt Tuning(提示调优) 核心思想:固定预训练模型参数,仅学习额外的连续提示向量(通常是嵌入层的一部分)。实现方式:在输入文本前添加可训练的连续向量(软提示),模型只更新这些提示参数。优势:参数量少(仅提…...

3.3.1_1 检错编码(奇偶校验码)
从这节课开始,我们会探讨数据链路层的差错控制功能,差错控制功能的主要目标是要发现并且解决一个帧内部的位错误,我们需要使用特殊的编码技术去发现帧内部的位错误,当我们发现位错误之后,通常来说有两种解决方案。第一…...

STM32F4基本定时器使用和原理详解
STM32F4基本定时器使用和原理详解 前言如何确定定时器挂载在哪条时钟线上配置及使用方法参数配置PrescalerCounter ModeCounter Periodauto-reload preloadTrigger Event Selection 中断配置生成的代码及使用方法初始化代码基本定时器触发DCA或者ADC的代码讲解中断代码定时启动…...

Java - Mysql数据类型对应
Mysql数据类型java数据类型备注整型INT/INTEGERint / java.lang.Integer–BIGINTlong/java.lang.Long–––浮点型FLOATfloat/java.lang.FloatDOUBLEdouble/java.lang.Double–DECIMAL/NUMERICjava.math.BigDecimal字符串型CHARjava.lang.String固定长度字符串VARCHARjava.lang…...

el-switch文字内置
el-switch文字内置 效果 vue <div style"color:#ffffff;font-size:14px;float:left;margin-bottom:5px;margin-right:5px;">自动加载</div> <el-switch v-model"value" active-color"#3E99FB" inactive-color"#DCDFE6"…...

2025盘古石杯决赛【手机取证】
前言 第三届盘古石杯国际电子数据取证大赛决赛 最后一题没有解出来,实在找不到,希望有大佬教一下我。 还有就会议时间,我感觉不是图片时间,因为在电脑看到是其他时间用老会议系统开的会。 手机取证 1、分析鸿蒙手机检材&#x…...

自然语言处理——Transformer
自然语言处理——Transformer 自注意力机制多头注意力机制Transformer 虽然循环神经网络可以对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,但是它有一个很大的缺陷——很难并行化。 我们可以考虑用CNN来替代RNN,但是…...

laravel8+vue3.0+element-plus搭建方法
创建 laravel8 项目 composer create-project --prefer-dist laravel/laravel laravel8 8.* 安装 laravel/ui composer require laravel/ui 修改 package.json 文件 "devDependencies": {"vue/compiler-sfc": "^3.0.7","axios": …...

人机融合智能 | “人智交互”跨学科新领域
本文系统地提出基于“以人为中心AI(HCAI)”理念的人-人工智能交互(人智交互)这一跨学科新领域及框架,定义人智交互领域的理念、基本理论和关键问题、方法、开发流程和参与团队等,阐述提出人智交互新领域的意义。然后,提出人智交互研究的三种新范式取向以及它们的意义。最后,总结…...