C语言数据结构初阶(6)----链表常见OJ题
CSDN的uu们,大家好!编程能力的提高不仅需要学习新的知识,还需要大量的练习。所以,C语言数据结构初阶的第六讲邀请uu们一起来看看链表的常见oj题目。

移除链表元素
原题链接:203. 移除链表元素 - 力扣(Leetcode)
题目描述:给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val == val 的节点,并返回 新的头节点 。
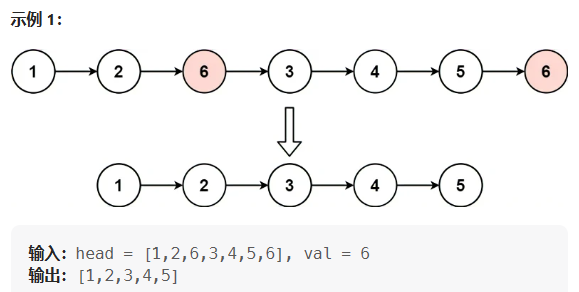
1.1 解法1:三指针
下面我们以一个具体的例子来分析一下:1->2->3->2->4->NULL,假设我们要删除的元素是2,即val==2。
我们可以维护三个指针,prev,cur和next,用cur遍历整个链表,如果说cur->val == val,我们就释放掉cur指向 的节点,然后令prev->next = next,然后更新cur的指向:cur = next,更新prev的指向:prev = cur,直到cur指向NULL结束遍历链表。
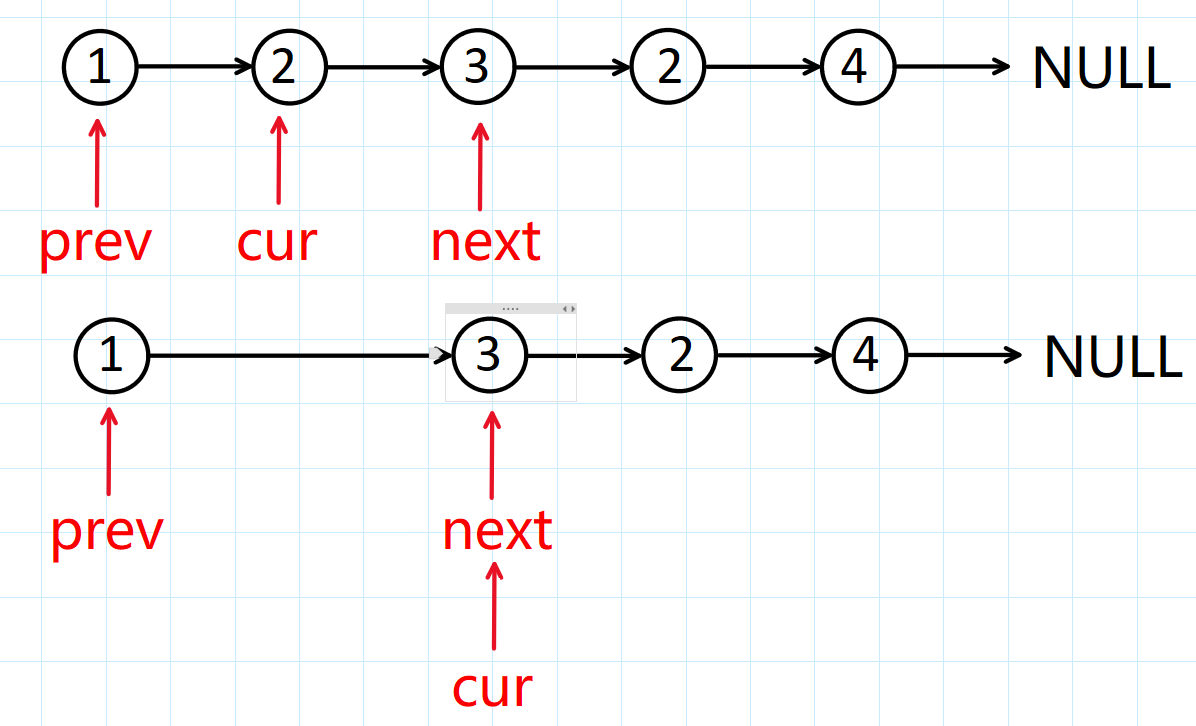
我们来看看有什么特殊情况?
以链表:2->3->2->4->NULL为例。如果说要删除的节点是头结点,我们在释放cur指向的节点之后,还需要改变原来链表的头结点,然后更新cur指向的节点!
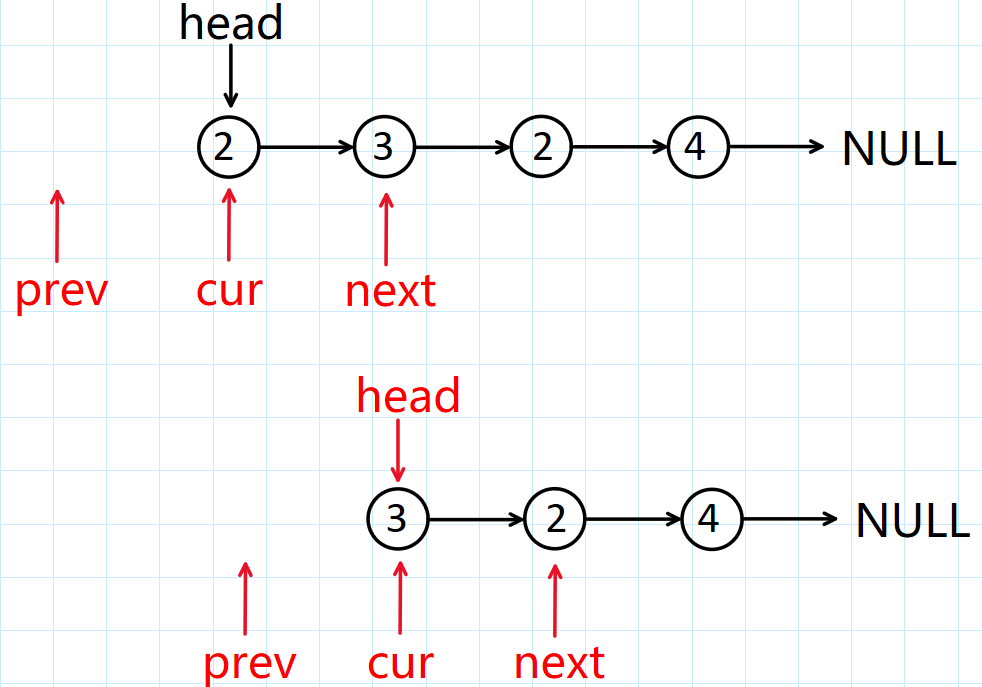
如果说cur指向的节点的val值等于要删除的val值,并且此时的prev为空,那么我们是不需要令
prev->next = next的,这样会发生空指针的解引用,程序会崩溃!因此我们需要对此情况进行特殊处理!当prev指向空指针时,并且此时cur指向的节点正是要删除的节点!需要跳过prev->next=next这一步。
时间复杂度:O(N),空间复杂度:O(1)。
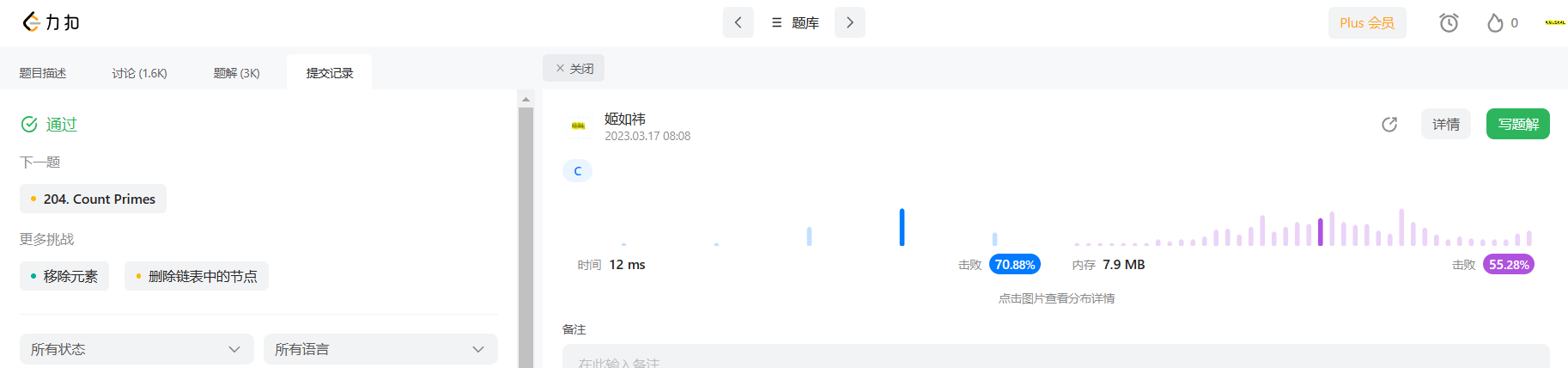
struct ListNode* removeElements(struct ListNode* head, int val){//处理极端情况if(!head)return NULL;//初始化cur和prevstruct ListNode* prev = NULL, *cur = head;while(cur){//找到cur的下一个节点struct ListNode* next = cur->next;//如果cur指向的节点是要删除的节点if(cur->val == val){//如果prev==NULL,不需要令prev->next = nextif(!prev){free(cur);cur = next;//if(prev == NULL)也说明了删除的是头结点//更新新的头节点head = next;}else{//if(prev!=NULL),释放链接即可free(cur);prev->next = next;cur = next;}}else{//如果说cur指向的节点不是要删除的节点//正常迭代三个指针就行prev = cur;cur = next;}}return head;
}
1.2 解法二:尾插法
我们初始化如下指针:cur指针用来遍历整个链表,newHead指针用来当新链表的头结点,tail指针指向新链表的尾节点,方便尾插!当然新的链表你可以整一个哨兵位的头结点,这样就不要对newHead是否为空指针进行特殊判断了!
我们用cur指针遍历整个链表,因为涉及节点的释放,在遍历的过程中我们需要临时保存一下cur节点的下一个节点!例如:用next指针保存cur的下一个节点。在遍历的过程中,如果说cur指向的节点val值不等于要删除的val值,我们就将该节点头插到新的链表。
如果你没有用带哨兵位的头结点,那么就需要对newHead进行判断,如果newHead为空指针,你需要更新newHead的值,如果不为空指针,你只需要令tail->next = cur,然后更新tail指针的指向就行!
如果cur指向的节点的val值等于要删除的val值,我们free掉cur,然后令cur = next即可!直到cur指针完成对链表的遍历。
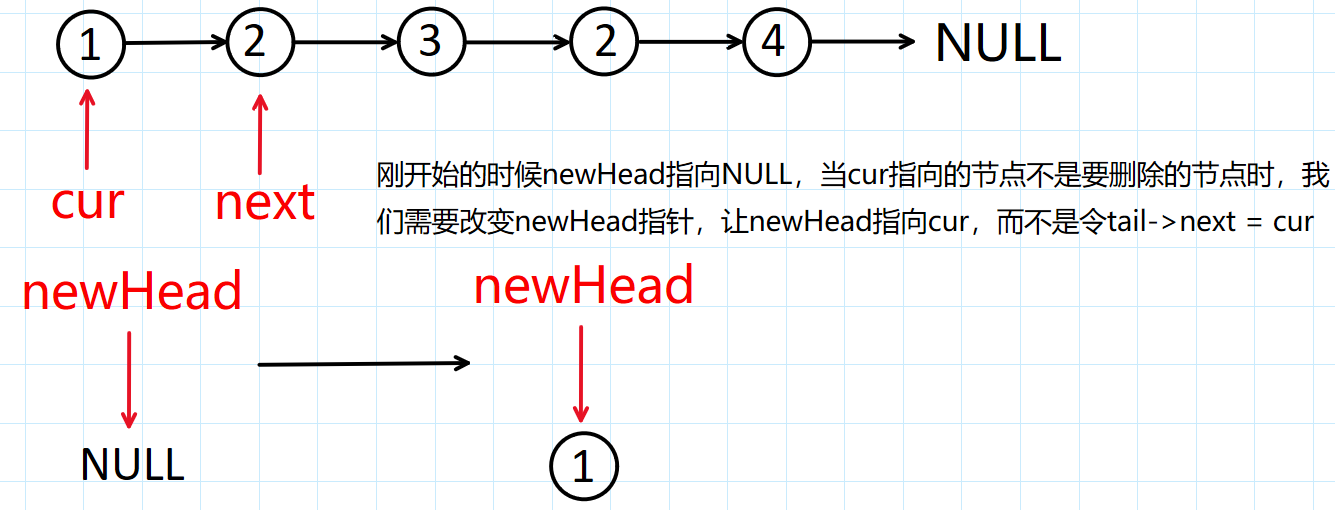
还有一个要注意的点是:tail在遍历过程中的更新是令tail = cur的,因为我们不知道哪个节点是新链表的尾节点,所以在tail不为空指针的时候需要将tail->next置为NULL。
例如:1->2->3->4->2,要删除节点值为2的节点。尾插后我们得到新链表:1-3->4,如果我们不在此过程中令tail->next = NULL,那么新链表4这个节点的next,指向的还是原来链表中的尾节点2。因为2这个节点已经被释放了!2这个节点的指针就是个野指针。显然会出问题的。
时间复杂度:O(N),空间复杂度:O(1)。
struct ListNode* removeElements(struct ListNode* head, int val)
{//初始化节点struct ListNode* cur = head, *newHead = NULL, *tail = NULL;while(cur){//临时保存cur->nextstruct ListNode* next = cur->next;//删除值等于val的节点if(cur->val == val){free(cur);}else{//如果newHead==NULL,改变newHead的指向if(!newHead){newHead = cur;tail = cur;}else{//正常连接tail->next = cur;tail = cur;}}cur = next;//如果tail不为空,需要将tail->next=NULLif(tail)tail->next = NULL;}return newHead;
}

2. 反转单链表
原题链接:206. 反转链表 - 力扣(Leetcode)
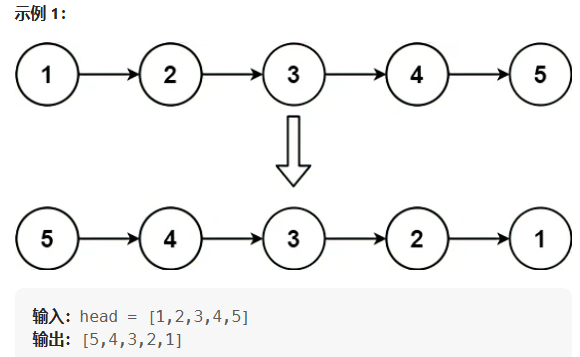
题目描述:给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
2.1 反转指针
看到这道题之后我们会很自然地想到只要将链接节点的指针反转过来,改变原来链表的方向,然后再从头到尾遍历输出到数组即可。
我们可以维护三个指针prev,cur,next。prev初始化为空指针,cur初始化为头结点的指针,next初始化为头结点的下一个节点的指针。
为什么要这么做呢?维护prev的目的是方便反转节点指针后,指向新的节点或者NULL,维护cur的目的就是遍历整个的链表,维护next的目的是方便找到cur的下一个节点,因为一旦反转了指针不用一个指针提前找到cur的下一个节点,就真的找不到下一个节点了!
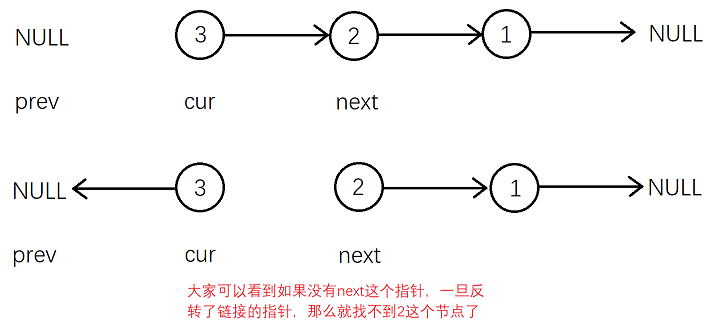
反转一次之后,把cur给给prev,把next给给cur,next的下一个节点的指针给给next,以此类推直到cur为空指针。我们就完成了反转链表。最后将新的头结点prev赋值给原链表的头结点(见下图)。
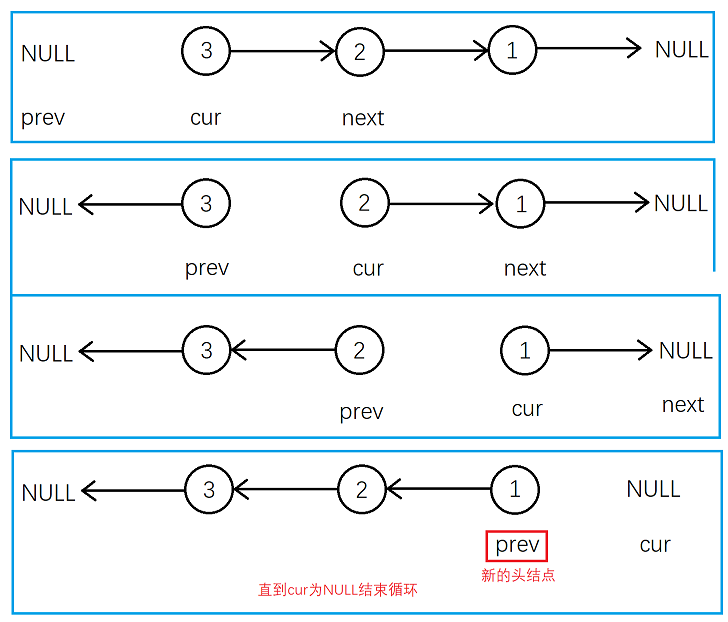
struct ListNode* reverseList(struct ListNode* head){//处理特殊情况if(head == NULL)return NULL;struct ListNode* prev = NULL, *cur = head;while(cur){//保存下一个节点struct ListNode* next = cur->next;//链接cur->next = prev;prev = cur;cur = next;}//返回return prev;
}
2.2 头插节点
我们可以维护一个指针newHead,初始化为NULL,然后用一个指针cur遍历原链表,将cur指向的节点头插到新的链表,同样这里需要对newHead进行特殊判断。因为上面那道题我们没有用哨兵位的头结点,所以这里就使用带哨兵位的头结点的链表来完成解题,这样就不需要做特殊判断啦!
这里的头插不是新搞一个链表而是取原节点下来头插哦!因此需要保存cur->next。
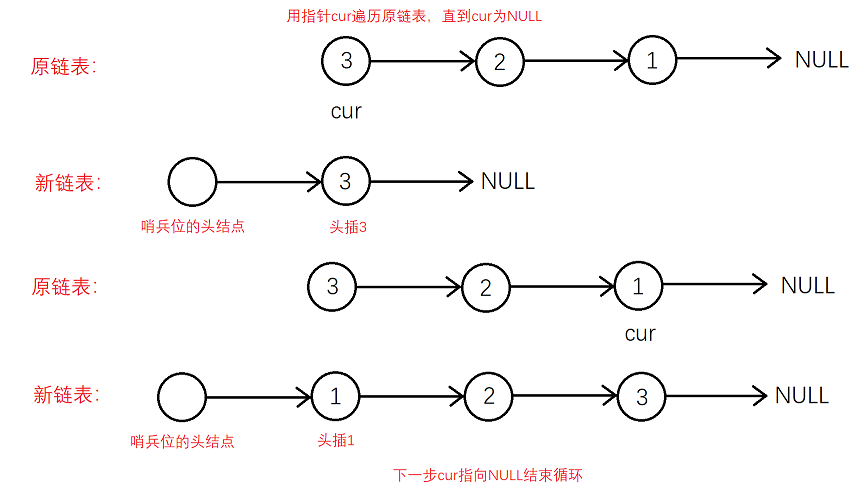
struct ListNode* reverseList(struct ListNode* head){struct ListNode* newHead = (struct ListNode*)malloc(sizeof(struct ListNode));struct ListNode* cur = head;newHead->next = NULL;while(cur){//保存下一个节点struct ListNode* next = cur->next;//新链表的下一个节点struct ListNode* pnext = newHead->next;//链接newHead->next = cur;cur->next = pnext;cur = next;}//返回节点return newHead->next;
}
3. 链表的中间节点
原题链接:876. 链表的中间结点 - 力扣(Leetcode)
题目描述:给你单链表的头结点 head ,请你找出并返回链表的中间结点。如果有两个中间结点,则返回第二个中间结点。
3.1 双指针
我们维护两个指针slow,fast均初始化为头结点head,然后让slow向前走一步,fast向后走两步。
当节点个数为偶数时:判断结束的条件就是fast == NULL。
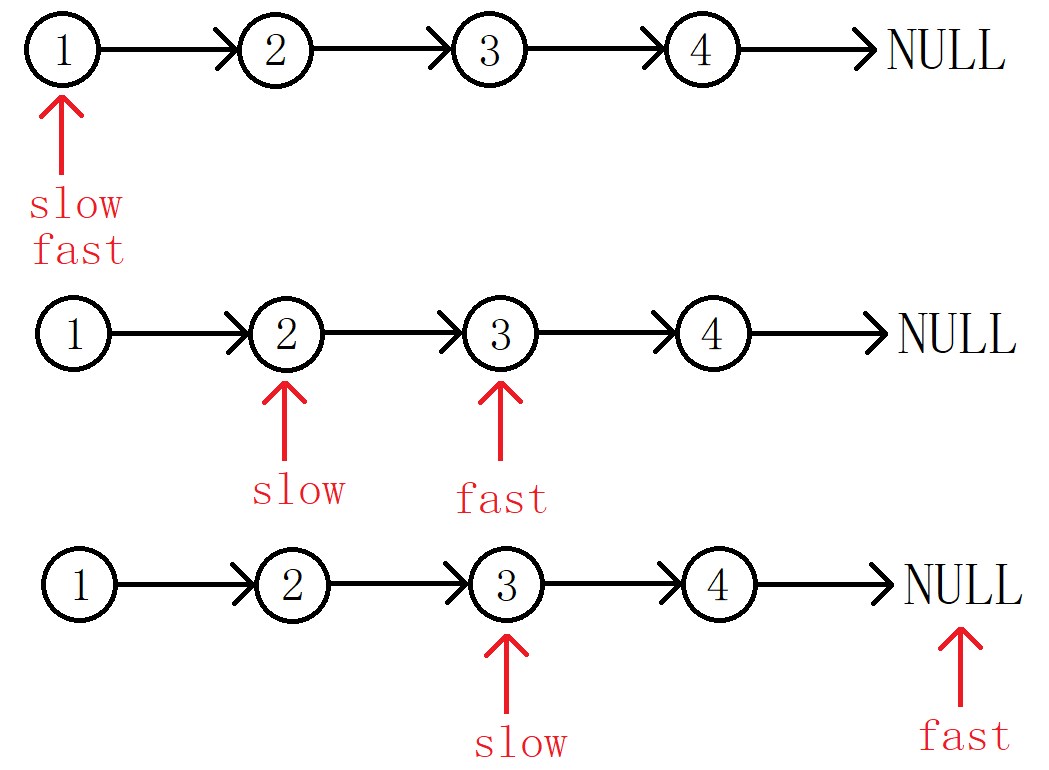
当节点个数为奇数时:判断结束的条件就是fast->next = NULL。
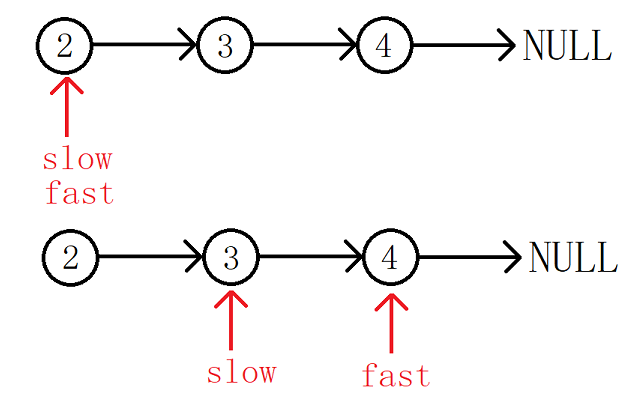
struct ListNode* middleNode(struct ListNode* head){//初始化节点struct ListNode* slow = head, *fast = head;//两个判断结束的条件while(fast && fast->next){//slow走一步,fast走两步slow = slow->next;fast = fast->next->next;}//返回slowreturn slow;
}
4. 链表中倒数第K个节点
原题链接:剑指 Offer 22. 链表中倒数第k个节点 - 力扣(Leetcode)
题目描述:
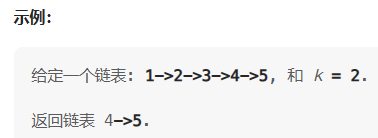
输入一个链表,输出该链表中倒数第k个节点。为了符合大多数人的习惯,本题从1开始计数,即链表的尾节点是倒数第1个节点。
例如,一个链表有 6 个节点,从头节点开始,它们的值依次是 1、2、3、4、5、6。这个链表的倒数第 3 个节点是值为 4 的节点。
4.1 统计链表长度
题目求的是链表的倒数第 k 个节点,根据题目得知这是一个单向链表,我们无法从后往前找到链表的倒数第 k 个节点,于是我们会想到从前往后去找倒数第 k 个节点。但是我们不知道倒数第 k 个节点前面有多少个节点。于是,我们很自然地想到先求出链表的节点个数 count,然后就求出了倒数第 k 个节点前有 count - k 个节点,然后我们再用一个指针去遍历找到倒数第 k 个节点就可以啦。
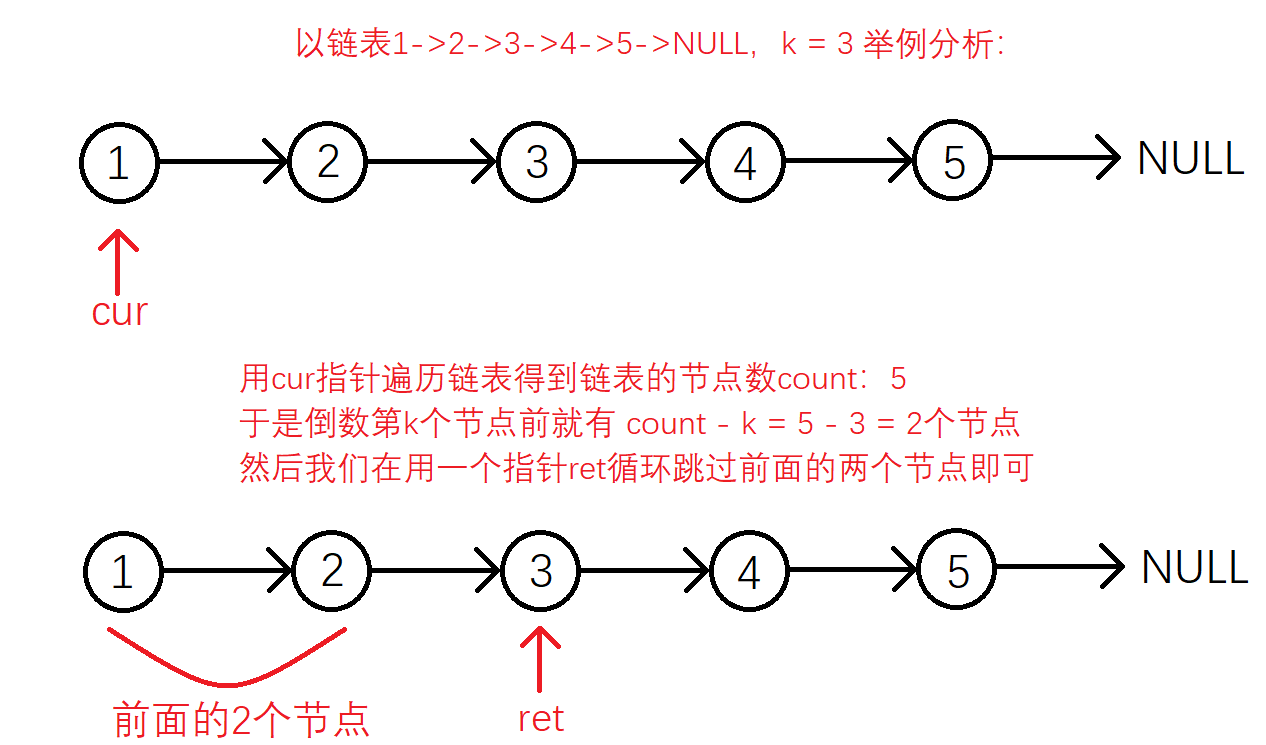
struct ListNode* getKthFromEnd(struct ListNode* head, int k){//deal with special circumstancesif(head == NULL || k <= 0)return NULL;struct ListNode* cur = head;int count = 0;//statistical the length of listwhile(cur){cur = cur->next;++count;}//deal with special circumstanceif(k > count) return NULL;//search the answerstruct ListNode* ret = head;for(int i = 1; i < count - k + 1; ++i){ret = ret->next;}return ret;
}
4.2 快慢指针
遍历两次链表还是太麻烦了,能不能只遍历一次链表就找到结果呢?
答案是肯定的,我们可以维护两个指针slow,fast,将他们均初始化为头结点 head。然后让 slow 指针先不动,让 fast 指针先向后走k-1步,此时slow与fast之间就隔了 k - 1 个节点,然后保持slow与fast之间的距离始终为 k - 1个节点,即之后让 slow 与 fast 同时向后移动。直到 fast 指向尾节点,此时 slow 就指向了链表的倒数第 k 个节点。
下面以链表 1->2->3->4->5->NULL ,k = 3,举例分析:
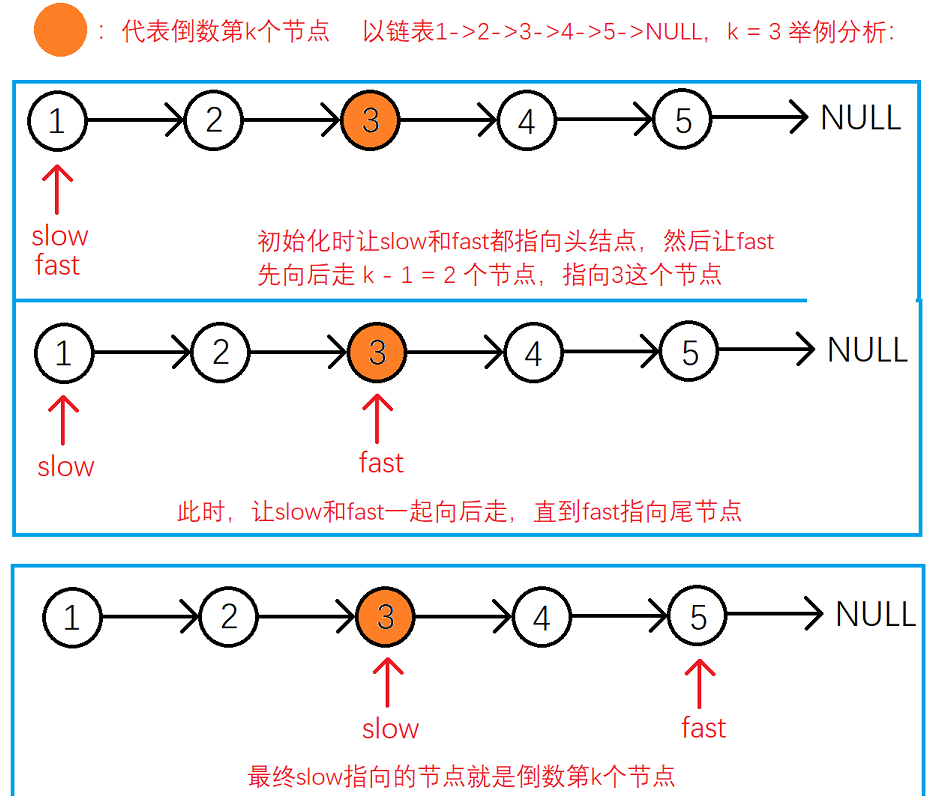
struct ListNode* getKthFromEnd(struct ListNode* head, int k){//deal with special circumstancesif(k <= 0)return NULL;struct ListNode* fast = head, *slow = head;while(--k){//head == NULL or k > the length of listif(fast == NULL)return NULL;fast = fast->next;}while(fast->next){//move respectivelyslow = slow->next;fast = fast->next;}//return resultreturn slow;
}
5. 合并两个有序的链表
原题链接:21. 合并两个有序链表 - 力扣(Leetcode)
题目描述:将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
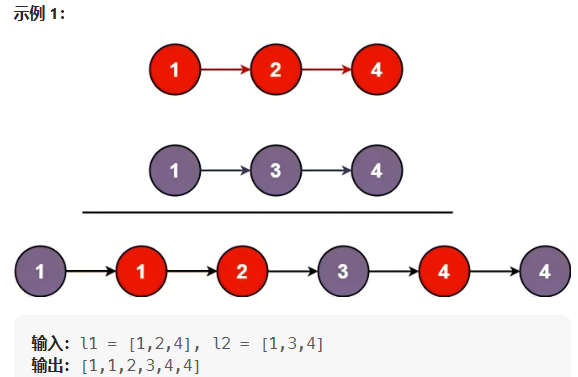
5.1 归并思想
这道题的思路和合并两个有序数组的思路相似,都是用归并的思想解题。为了方便节点的插入,同样我们新建一个带哨兵位的头结点的链表,然后我们维护两个指针p1,p2初始化为两个链表的头结点,比较两指针指向的节点的val值,将val值较小的节点尾插到新的链表中。依次类推,当有一个指针指向NULL时终止循环,然后链接指向不为NULL的链表,最后返回结果即可。
注意:当待合并的链表中有空的链表时直接返回另一个链表的头结点即可。
下面以链表:0->2->3->NULL
1->4->5->NULL
举例分析:
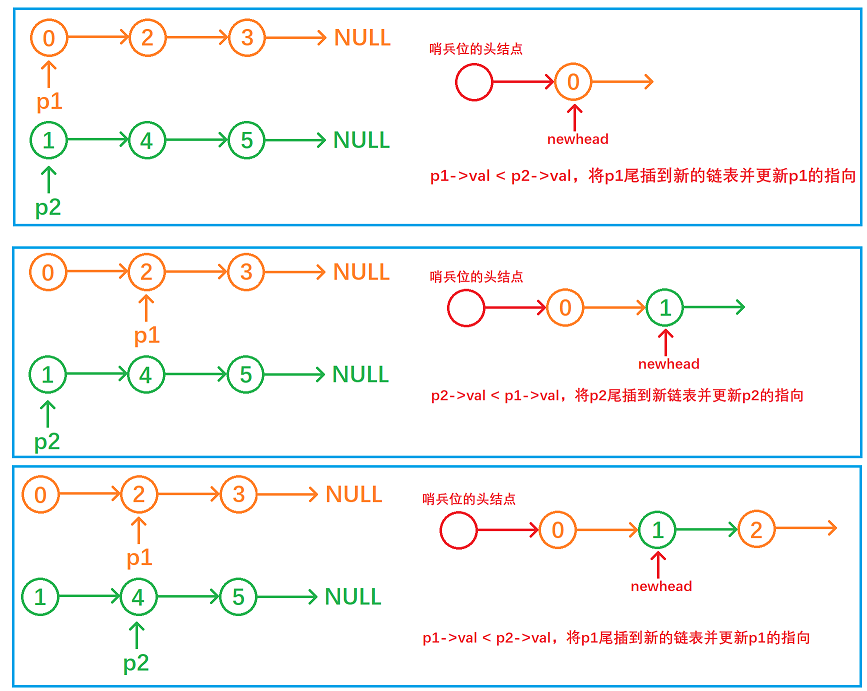
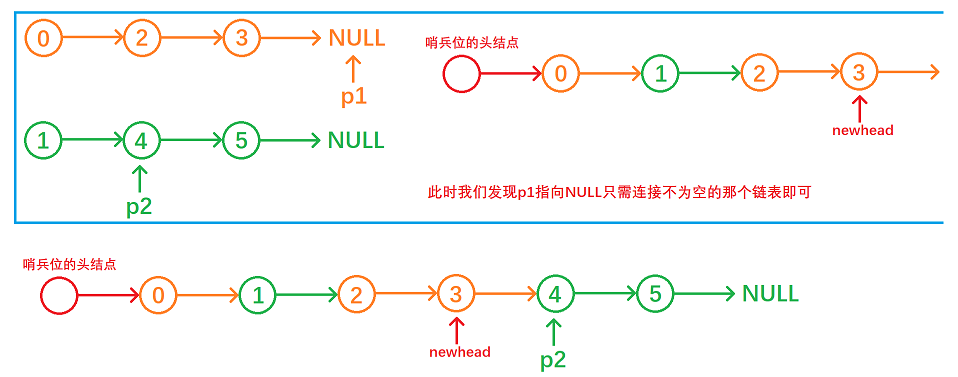
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2){//deal with special circumstancesif(!list1 || !list2)return list1 ? list1 : list2;//head node of sentinel positionstruct ListNode* newHead = (struct ListNode*)malloc(sizeof(struct ListNode));//cur1 and cur2 is used to traverse liststruct ListNode* tail = newHead, *cur1 = list1, *cur2 = list2;//until one of the lists is empty, the loop endswhile(cur1 && cur2){//compare the valif(cur1->val < cur2->val){tail->next = cur1;tail = cur1;cur1 = cur1->next;}else{tail->next = cur2;tail = cur2;cur2 = cur2->next;}}//connectif(!cur1)tail->next = cur2;elsetail->next = cur1;//free the head node of sentinel position struct ListNode* returnNode = newHead->next;free(newHead);newHead = NULL;//return answerreturn returnNode;
}
6. 链表分割
原题链接:链表分割_牛客题霸_牛客网 (nowcoder.com)
题目描述:现有一链表的头指针 ListNode* pHead,给一定值x,编写一段代码将所有小于x的结点排在其余结点之前,且不能改变原来的数据顺序,返回重新排列后的链表的头指针。
6.1 尾插法
我做这道题的时候想的是遍历原链表两次,一次将小于x的节点尾插到新链表,另一次就是将大于等于x的节点尾插到新链表。显然是没有这个必要的!
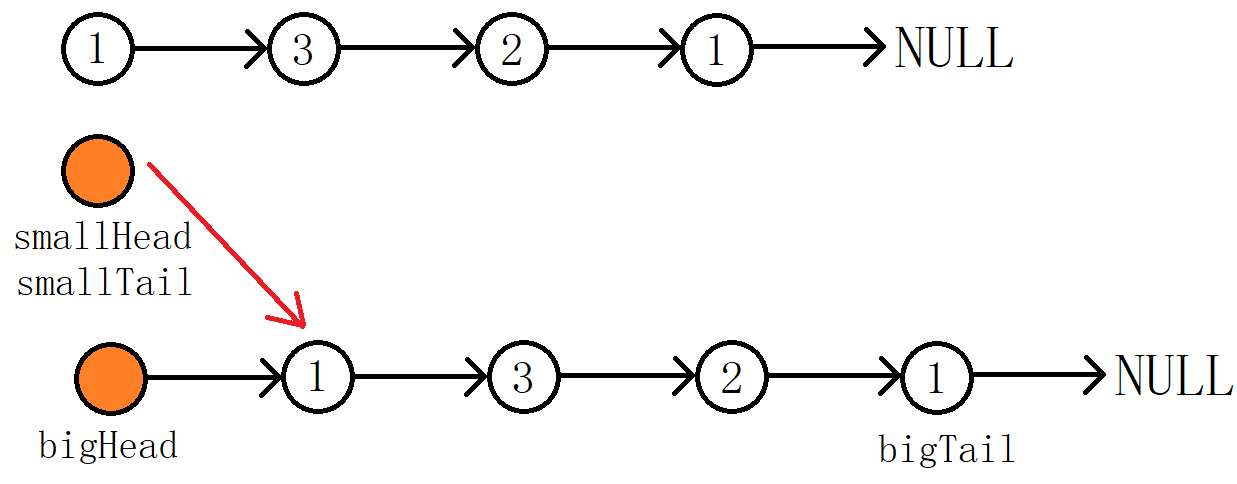
前面的链表OJ题我们已经可以看到哨兵位的头结点的优势。这里我们维护两个带哨兵位头结点的新链表,bigHead和smallHead,然后用一个指针cur遍历原来的链表,比x小的节点尾插到smallHead,大于等于X的节点尾插到bigHead。最后再将smallHead与bigHead连接起来,返回smallhead的下一个节点即可!尾插的话我们维护两个指针bigTail和smallTail,方便尾插!
注意点:
1:因为原链表的尾节点不一定是最大的节点,所以,在bigHead尾插完毕后需要令bigTail->next = NULL。
以链表1->3->2->1->NULL,x = 2,举例分析:
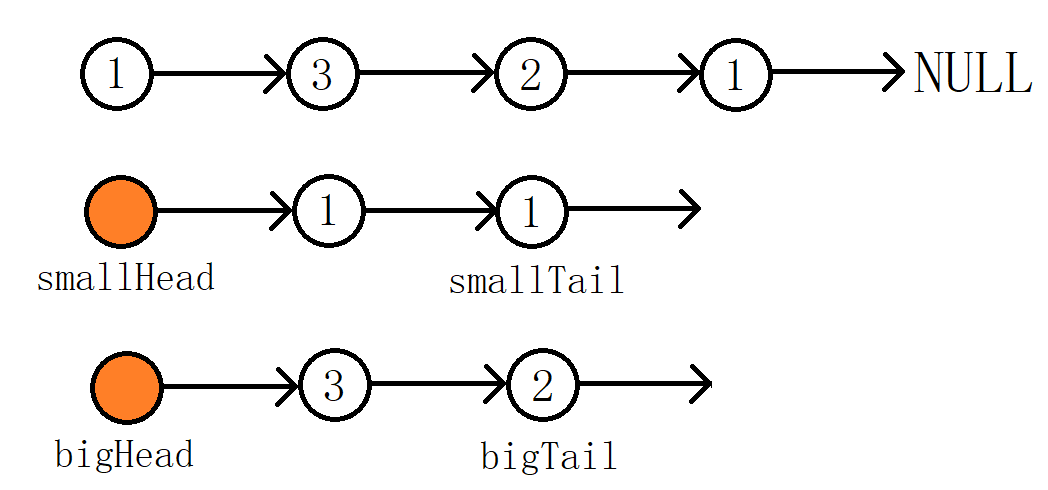
经过cur的遍历之后不难发现bigTail->next指向的其实是最后那个值为1的节点,如果这时候直接将smallHead与bigHead连接起来,返回结果显然是不对的,因此尾插完毕后需要令
bigHead->next = NULL。
2:当原链表中的所有节点均大于等于x会有问题吗?
以链表1->3->2->1->NULL,x = 1,举例分析:
cur指针遍历原链表后,smallHead中并没有尾插任何元素,现在我们尝试进行连接:
smallTail->next = bigHead->next;
return bigHead->next;
显然连接之后在返回结果是没啥问题的!
class Partition {
public:ListNode* partition(ListNode* pHead, int x) {//deal with special circumstanceif(pHead == nullptr)return nullptr;//init two lists with head node of the sentinel position//bigHead list is used to push back the node whose value is greater than x or equal to xauto bigHead = (ListNode*)malloc(sizeof(ListNode));auto bigTail = bigHead;//smallHead list is used to push back the node whose value is less than x auto smallHead = (ListNode*)malloc(sizeof(ListNode));auto smallTail = smallHead;//pointer cur is used to traverse the listauto cur = pHead;//until pointer cur point to nullptr, the loop will endwhile(cur){//campare the node val with xif(cur->val < x){//connect to the cur nodesmallTail->next = cur;smallTail = cur;cur = cur->next;}else{bigTail->next = cur;bigTail = cur;cur = cur->next;}}//bigTail->next must point to nullptr, otherwise it will time limit exceedbigTail->next = nullptr;//connectionsmallTail->next = bigHead->next;return smallHead->next;}
};
7. 链表的回文结构
原题链接:剑指 Offer II 027. 回文链表 - 力扣(Leetcode)
题目描述:给定一个链表的 头节点 head ,请判断其是否为回文链表。
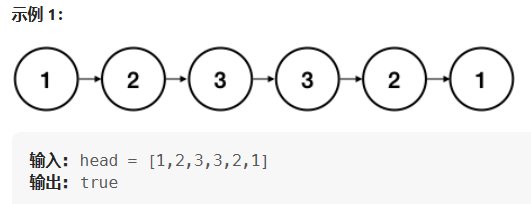
如果一个链表是回文,那么链表节点序列从前往后看和从后往前看是相同的。
7.1 栈
这个题目的知识点他给的是栈哈,我刚开始就是用的栈解题!其实有一种方法是不需要用栈的,将上面几道题的函数拼接一下就可以啦!大家可以先思考思考!这里我们先来看看栈的解法:
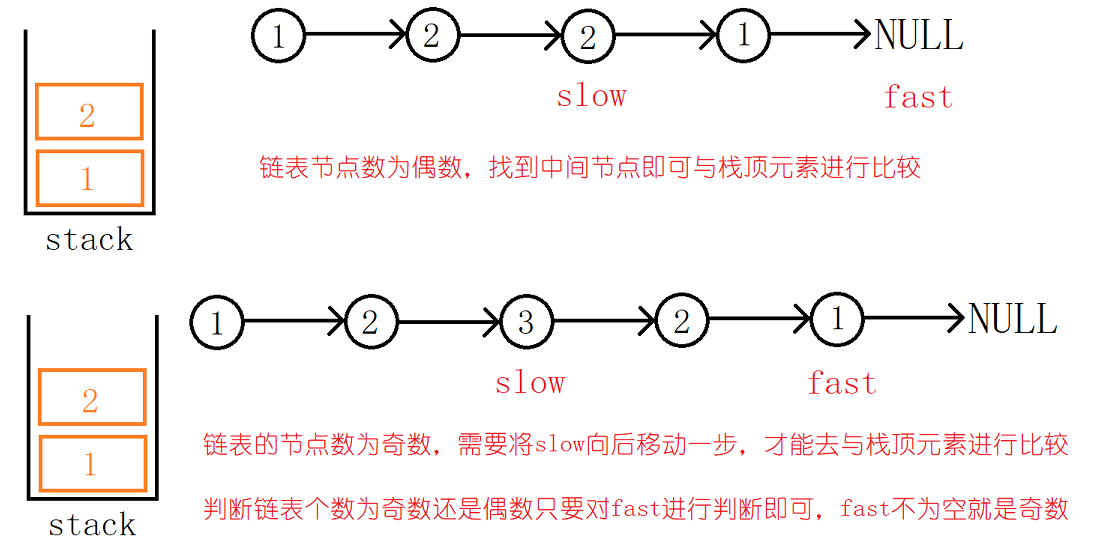
栈的特点就是先进后出,因此我们遍历链表,将原链表中前一半的节点的val值压入栈中,紧接着在继续遍历原链表中后半部分的节点,弹出栈顶元素与遍历得到的节点的val值比较,如果说不相等,显然就不是回文结构!当把整个链表均遍历完毕后还没有返回false,那么这个链表就是回文链表。
注意点:
1:将前一半节点的val值压入栈中需要与题目三:链表的中间节点配合。当链表的节点数为奇数时,最后slow指向的节点时链表的中间节点,这个节点是不用参与与栈顶元素的比较的,因此将slow向后移动一步!当链表的节点数为偶数时,slow指向的节点就是第一个需要与栈顶元素进行比较的节点,无需做任何处理!
2:我们选择用数组模拟实现栈!
如有疑问请参考:http://t.csdn.cn/hvpKx
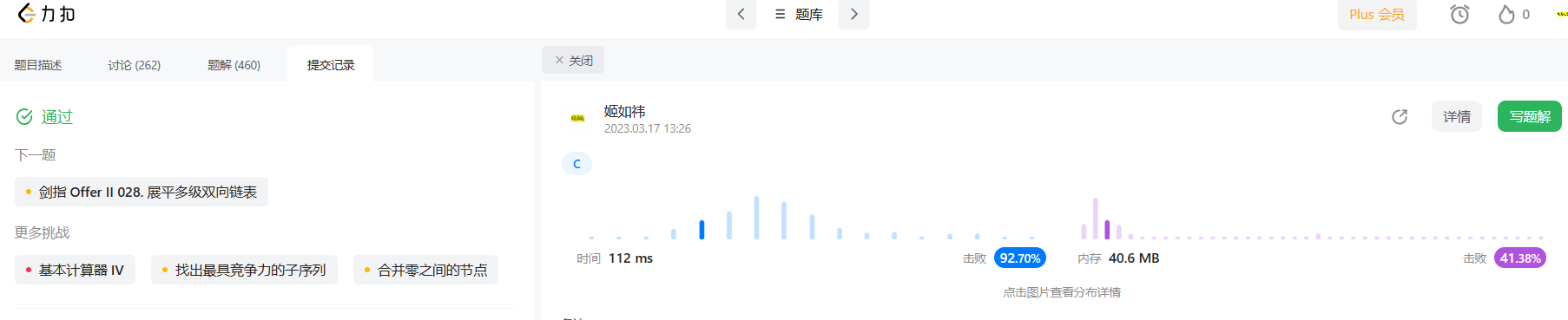
bool isPalindrome(struct ListNode* head){//deal with special circumstances//A is a nullptrif (!head)return false;//only one nodeif (!head->next)return true;//we chosse simulate a stackint stack[100010];int tt = 0;//using fast and slow pointer traverse the liststruct ListNode* slow = head, *fast = head;while (fast && fast->next) {//push the val of slow pointerstack[++tt] = slow->val;slow = slow->next;fast = fast->next->next;}//the length of list is oddif (fast)slow = slow->next;//compare with the stack top valuewhile (slow) {if (slow->val == stack[tt])tt--;else //slow->val is not equal to the stack top value, return falsereturn false;slow = slow->next;}return true;
}
7.2 部分反转链表
我们需要通过题目三:链表的中间节点找到链表的中间节点!然后将得到的中间节点返回,传入题目2:反转链表的函数,反转链表的函数会返回一个新的节点newHead,然后我们同时遍历newHead指向的链表和原链表,如果出现节点值不相同的情况我们返回false就行了!
注意点:
1:如果我们对奇数链表的中间节点不做处理,我们来看看在遍历newHead指向的链表和原链表时循环条件应该怎么写?

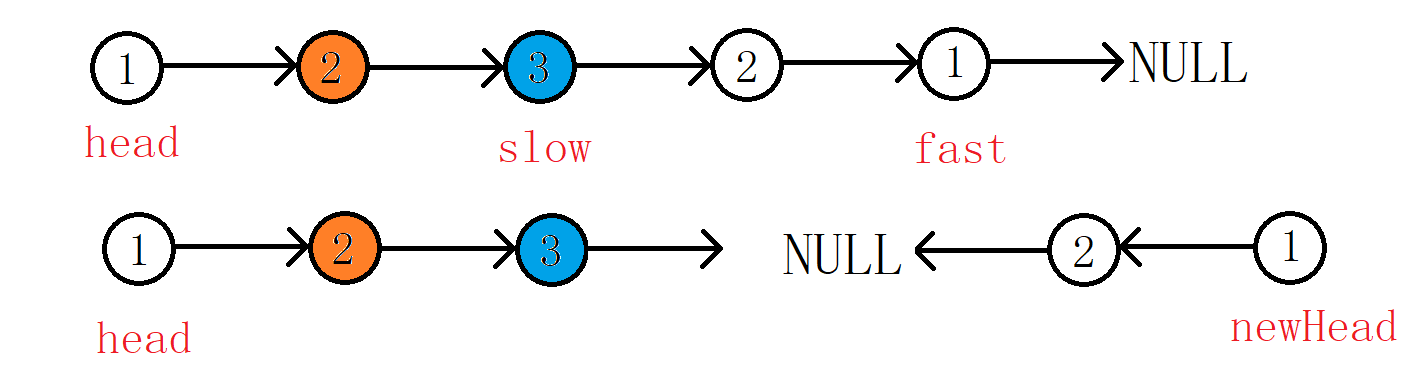
如上图,对于奇数节点的链表,我们找到中间节点就传参给反转链表的函数,得到了新的newHead。
因为在反转链表的过程中我们并没有对图中橙色节点的next指针做处理,他的next还是指向蓝色这个节点的,在遍历head和newHead时我们的循环结束的条件就不好与链表的节点数为偶数的情况统一。因此在返回链表的中间节点时我们对奇数个节点数的链表做同解法一的处理,让slow向后走一步后再返回。
再来看链表个数时偶数的时候,我们就不需要做什么处理了!
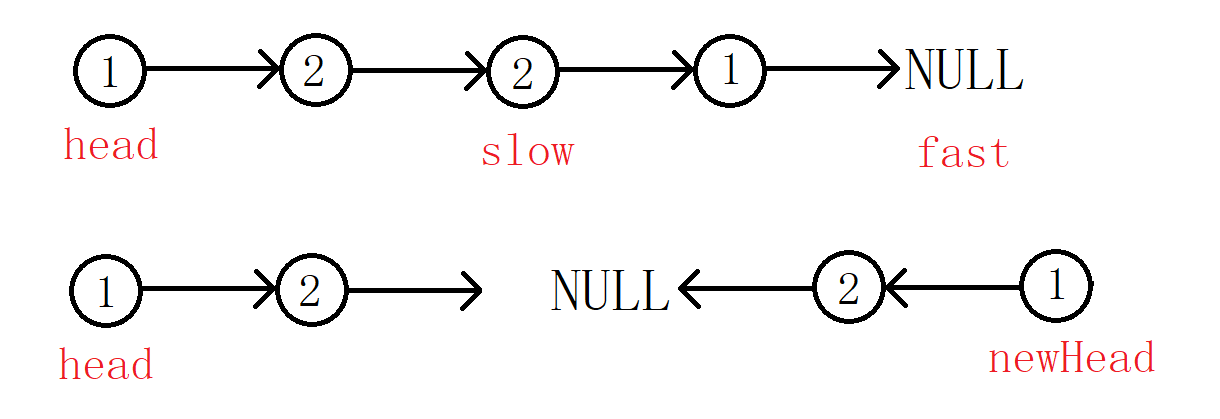
想必大家都能看出循环的结束条件就是遍历newHead的指针为空了!为了统一还是有必要做一点点处理的。处理方法与方法一的相同。
//reverse list
struct ListNode* reverseList(struct ListNode* head)
{struct ListNode* prev = NULL, *cur = head;struct ListNode* next;while (cur) {if (next)next = cur->next;cur->next = prev;prev = cur;cur = next;}return prev;
}//find middle node
struct ListNode* middleNode(struct ListNode* head)
{struct ListNode* slow = head, *fast = head;while (fast && fast->next) {slow = slow->next;fast = fast->next->next;}//if list's length is odd, slow = slow->nextif(fast)slow = slow->next;return slow;
}bool isPalindrome(struct ListNode* head){//deal with special circumstanceif (!head)return false;//middle nodestruct ListNode* mid = middleNode(head);//reverse the list after middle nodestruct ListNode* newHead = reverseList(mid);//traverse respectivelywhile (newHead) {//compare the valueif (head->val != newHead->val)return false;//iterationhead = head->next;newHead = newHead->next;}return true;
}
8. 相交链表
原题链接:160. 相交链表 - 力扣(Leetcode)
题目描述:给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。
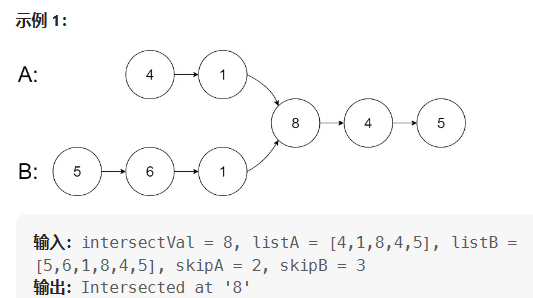
8.1 最好想的思路
我们无法确定相等的节点会在什么时候出现,即使你想到去比较节点的地址也不行的哦!
我们看到在两个链表的相交节点之前的节点数是不确定的!这限制了我们的解题。
因此我们可以先统计每个链表的长度,找到两个链表中较长的那个。然后让遍历较长的那个链表的指针先向前走两个链表长度之差的绝对值步。这样在相交的节点之前的两个链表的节点数就相等了!我们在同时遍历,找到节点的地址相同的节点就行啦!
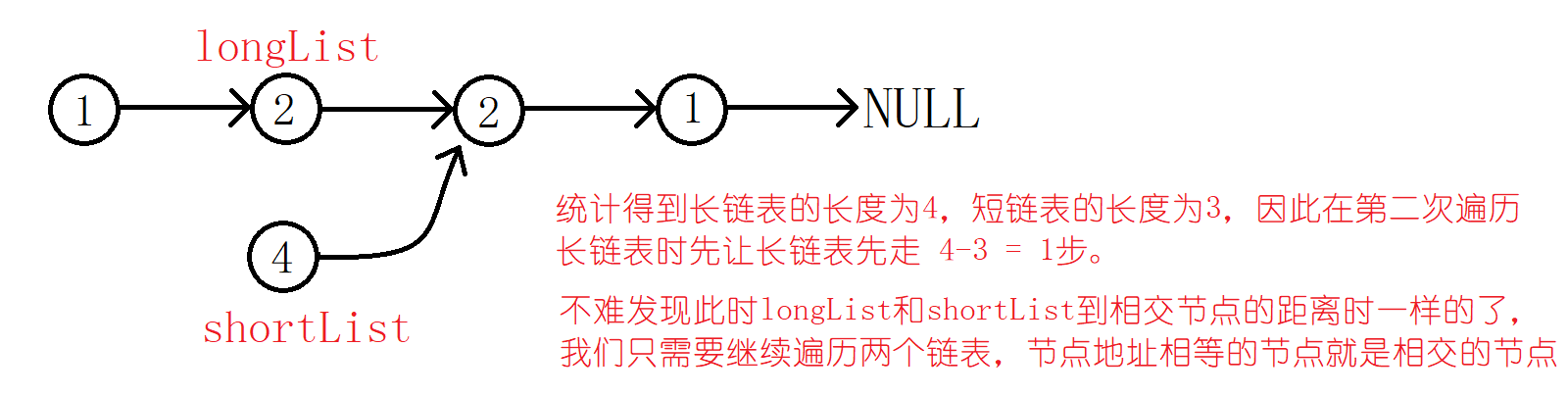
测试用例中两个链表中可能不存在交点的,因此我们还得知道如何判断两个链表是否有交点。很简单的,我们在统计链表的长度时,看看两个链表的尾节点的地址是否相同就行啦!
struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) {//deal with special circumstanceif(!headA || !headB)return NULL;//count the length of each listint lenA = 1, lenB = 1;struct ListNode* cur1 = headA, *cur2 = headB;while(cur1->next){++lenA;cur1 = cur1->next;}while(cur2->next){++lenB;cur2 = cur2->next;}//there is no node of intersectionif(cur1 != cur2)return NULL;int count = abs(lenA - lenB);//hypothesize the longer list is listAstruct ListNode* longList = headA, *shortList = headB;if(lenA < lenB){//assumption failslongList = headB;shortList = headA;}//find the returned nodewhile(count--){longList = longList->next;}while(shortList != longList){shortList = shortList->next;longList = longList->next;}return longList;
}
9. 环形链表Ⅰ
原题链接:141. 环形链表 - 力扣(Leetcode)
题目描述:给你一个链表的头节点 head ,判断链表中是否有环。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。注意:pos 不作为参数进行传递 。仅仅是为了标识链表的实际情况。
如果链表中存在环 ,则返回 true 。 否则,返回 false 。
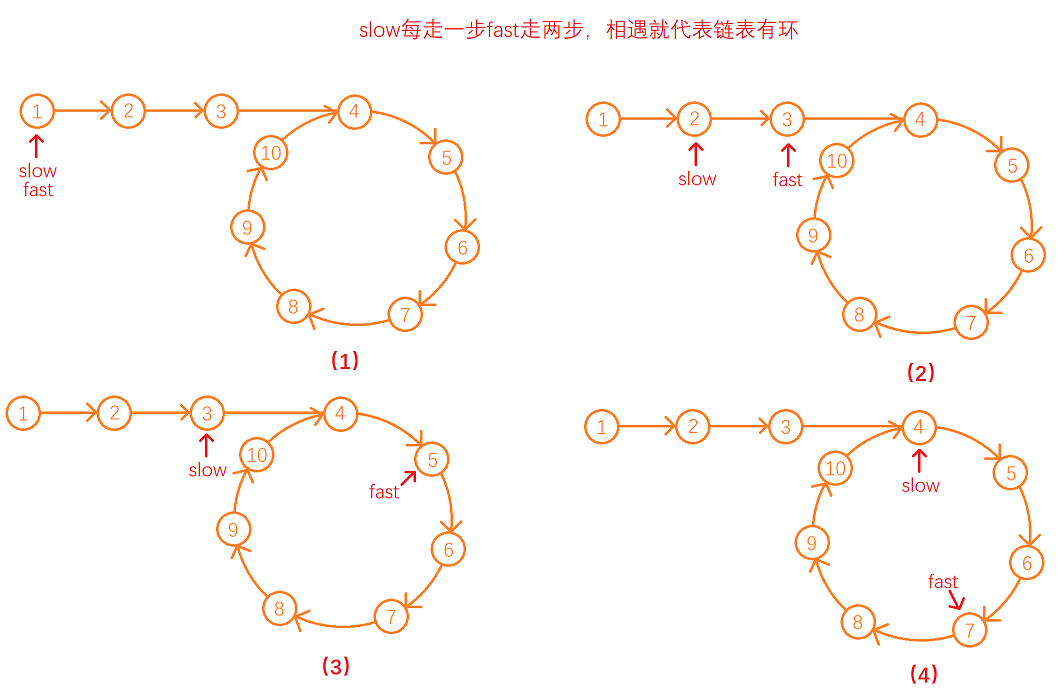
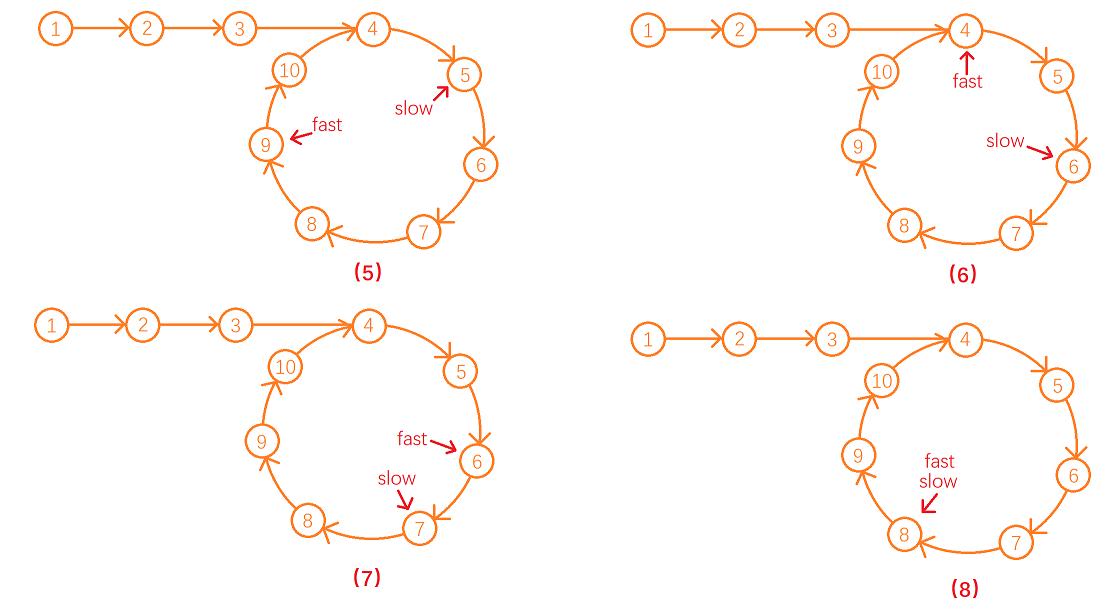
9.1 快慢指针
这道题的解题思路和“链表中的倒数第k个节点”的解题思路是相似的。快慢指针的问题,我们维护两个指针slow,fast,初始化为链表的头结点。然后我们让slow向后走一步,而fast向后走两步,如果说链表不存在环,那么fast会最终会指向NULL,此时我们结束循环返回false;
如果链表中存在环,因为fast走得快,slow走得慢,当slow刚进入环指向环内节点时,fast已经走了若干圈环,指向环上的某一个节点,此时slow和fast之间会有一段距离x (x>=0)。
因为fast走得比slow快一步,每一回合slow与fast之间的节点个数都会减一,所以在环内fast在与slow相遇之前一直在追slow,无论在slow进入环时,fast与slow相距多少个节点最终都会相遇,故当slow与fast相遇时即可判断链表中有环。
下面以环形链表1->2->3->4->5->6->7->8->9->10->4来举例分析:
bool hasCycle(struct ListNode *head) {//deal with special circumstanceif(!head)return false;//init two pointersstruct ListNode* slow = head, *fast = head;//if there is not circle in the list, the fast pointer will point to nullptrwhile(fast && fast->next){//fast pointer moves two stepsfast = fast->next->next;//slow pointer moves one stepslow = slow->next;//if the slow pointer equals to the fast pointer//it shows it has circleif(slow == fast)return true;}return false;
}
9.2 扩展问题
(1):在slow走一步,fast走两步的条件下有环就一定会相遇吗?
(2):如果slow走一步,fast走三步行不行?如果slow走一步,fast走四步呢?
答:
(1):根据上面解题的分析在slow走一步,fast走两步的条件下,有环必定相遇。
(2):slow走一步,fast走三步,以及slow走一步fast走四步均不一定能相遇,证明过程如下:
因为环中的节点个数是不确定的,我就直接画一个圆来代表链表中的环哈。
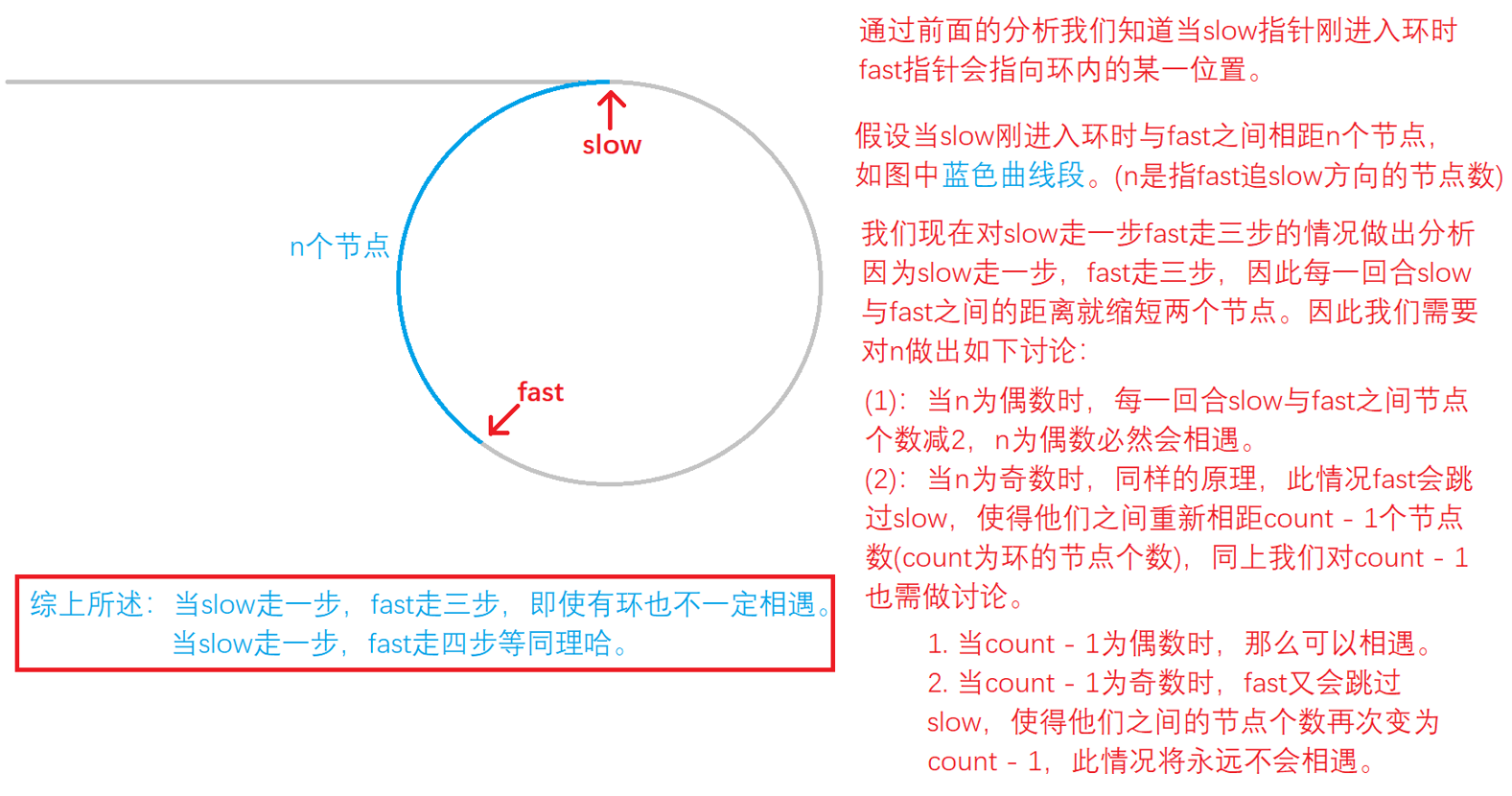
我们把的得到的结论往Leetcode上去测试,发现slow走一步,fast走三步也是可以通过的,对于本题leetcode上的测试用例似乎并没有考虑到这一点。
bool hasCycle(struct ListNode *head) {//deal with special circumstanceif(!head)return false;//init two pointersstruct ListNode* slow = head, *fast = head;//if there is not circle in the list, the fast pointer will point to nullptrwhile(fast && fast->next && fast->next->next){//fast pointer moves two stepsfast = fast->next->next->next;//slow pointer moves one stepslow = slow->next;//if the slow pointer equals to the fast pointer//it shows it has circleif(slow == fast)return true;}return false;
}
10. 环形链表Ⅱ
原题链接:142. 环形链表 II - 力扣(Leetcode)
题目描述:
给定一个链表的头节点 head ,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递,仅仅是为了标识链表的实际情况。
不允许修改 链表。
10.1 转化为两个链表的交点
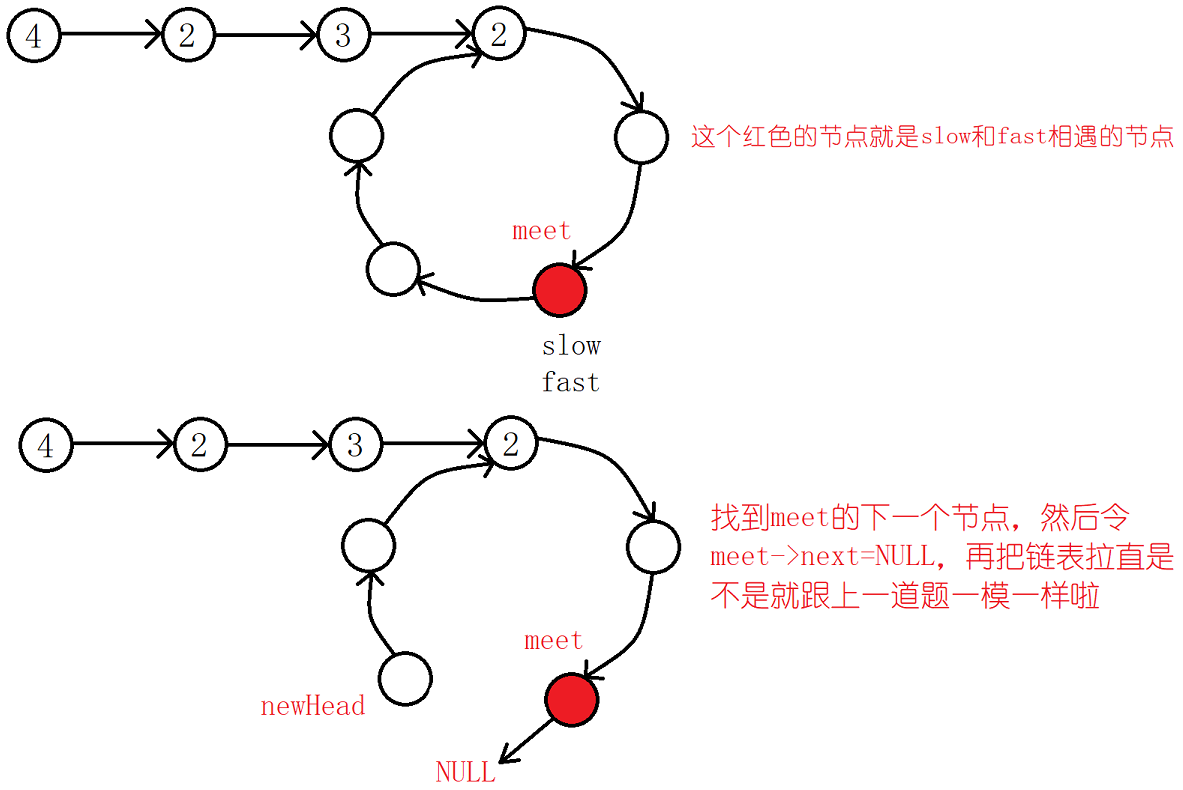
如果说链表有环的环,那么我们可以找到环形链表中1中fast和slow相遇的节点,让后将环断开。这样一来这个问题就转化为了找两个链表的相交节点啦!
具体怎么做呢?我们假设在环中slow与fast相遇的节点为meet,那么我们找到meet的下一个节点,记为newHead,让后再令meet->next=NULL,这样做就转化成功啦!
struct ListNode *detectCycle(struct ListNode *head) {//deal with special circumstanceif(!head)return NULL;//init two pointers to find the meet nodestruct ListNode* slow = head, *fast = head;while(fast && fast->next){slow = slow->next;fast = fast->next->next;//if slow == meet, shows the list has circleif(slow == fast){//find the meet nodestruct ListNode* meet = slow;//record meet->nextstruct ListNode* l1 = head, *l2 = meet->next, *pl2 = meet->next;meet->next = NULL;//count the length of each list//there must be the node of intersectionint len1 = 0, len2 = 0;while(l1){len1++;l1 = l1->next;}while(pl2){len2++;pl2 = pl2->next;}//find the longListstruct ListNode* longlist = head, *shortlist = l2;if(len1 < len2){longlist = l2, shortlist = head;}int count = abs(len1 - len2);//let the longList move advancedwhile(count--){longlist = longlist -> next;}//find the nodes which have same addresswhile(shortlist != longlist){longlist = longlist->next;shortlist = shortlist->next;}return longlist;}}return NULL;
}
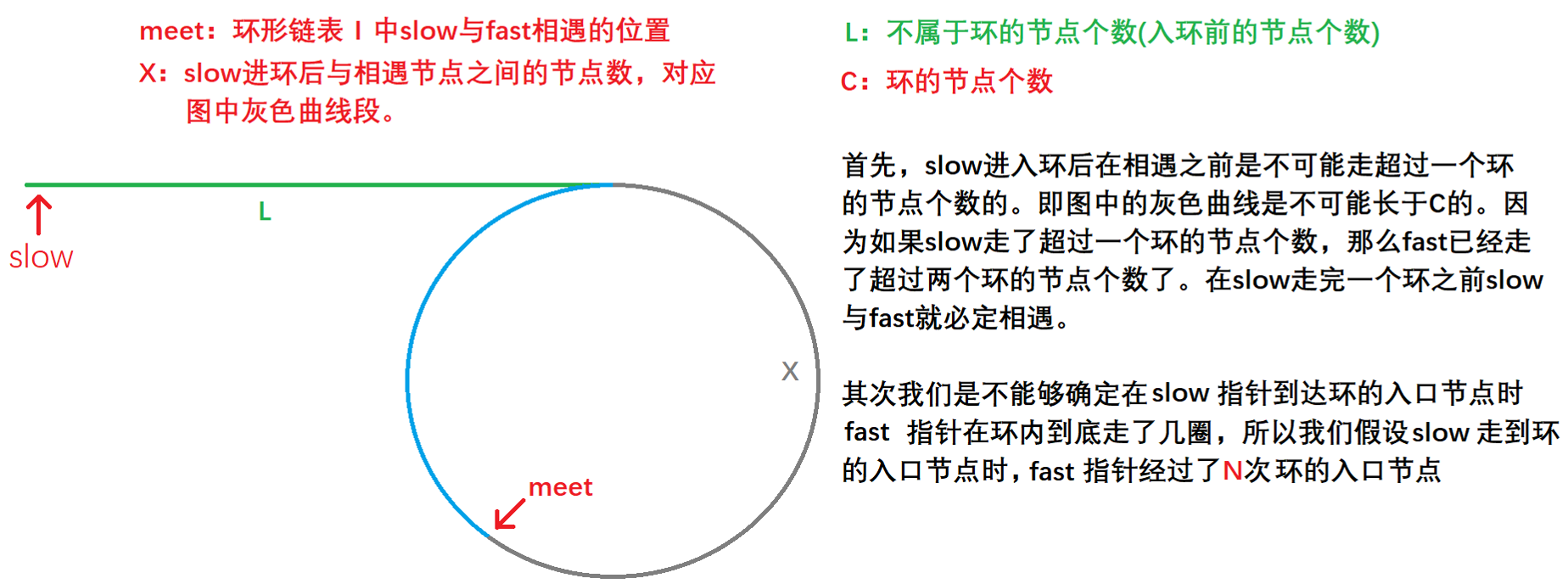
10.2 结论解题
直接上结论:初始化一个指针:meet,让他指向在环形链表Ⅰ中slow与fast相遇的位置,再初始化一个指针:cur,让他指向链表的头结点,然后让cur和meet指针以相同的速度(一次循环走一步)往后走,最终他们会在环形链表的入口处相遇。
嘶,第一次看到这个结论的我是一脸懵啊。但是这个结论是有严格的证明滴,现在我们就来证明证明。

struct ListNode *detectCycle(struct ListNode *head) {//deal with special circumstanceif(!head)return NULL;//init two pointer to find meet nodestruct ListNode* slow = head, *fast = head;while(fast && fast->next){slow = slow->next;fast = fast->next->next;if(fast == slow){//conclusionstruct ListNode* meet = slow, *cur = head;while(meet!=cur){meet = meet->next;cur = cur->next;}return cur;}}//there is not circlereturn NULL;
}
11. 复制带随机指针的链表
原题链接:138. 复制带随机指针的链表 - 力扣(Leetcode)
题目描述:
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
返回复制链表的头节点。
用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
val:一个表示 Node.val 的整数。
random_index:随机指针指向的节点索引(范围从 0 到 n-1);如果不指向任何节点,则为 null 。
你的代码 只 接受原链表的头节点 head 作为传入参数。
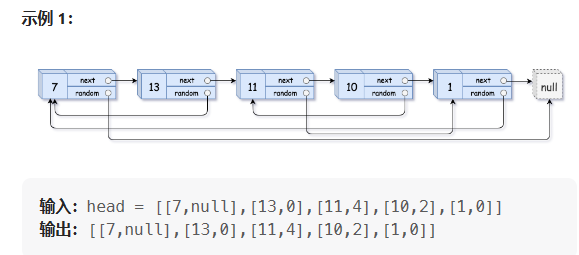
11.1 解题思路
因为链表中可能存在重复的val值,我们不能仅凭节点的val值来判断random指针的指向。因此可能会想到使用结构体指针数组。遍历原链表在深拷贝节点的同时,将每个节点random指针指向节点的相对位置用数组记录下来:首先我们让原链表中的节点分别对应下标1,2,3,4,5,11这个节点是原链表的第三个节点,因为1这个节点的random指针指向的是11这个节点,所以数组下标为5的位置就存3。
同时将拷贝出的节点的地址记录在另一个数组中。进行random指针的链接时,我们同时遍历两个数组,就可以链接成功了!是不是特别麻烦,这么看来的确是的。有没有更简单的方法呢?答案是肯定的。
更简单的方法分为三步:
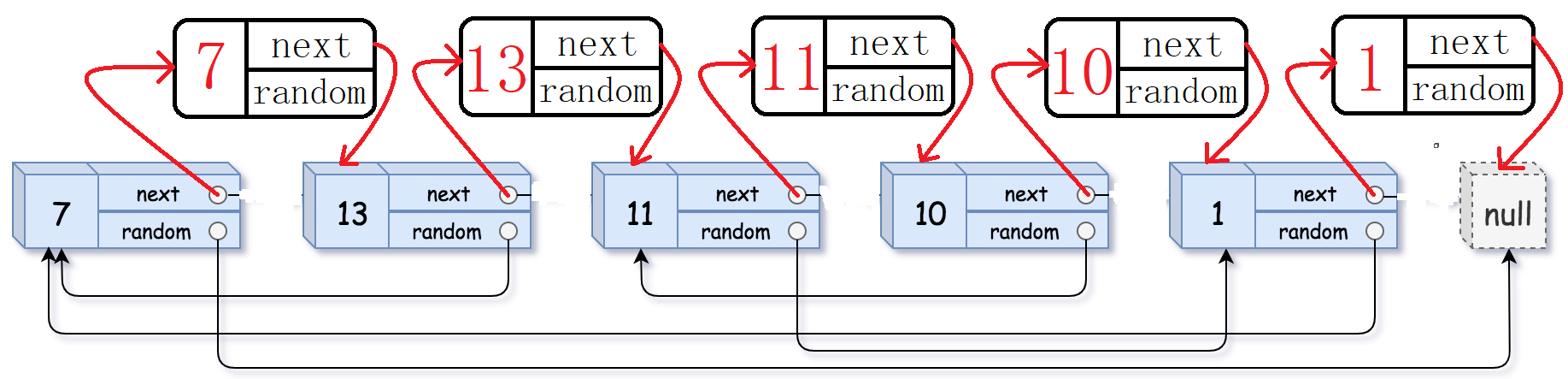
第一步:拷贝原节点。我们用一个指针,例如cur,去遍历原链表,每遍历一个节点,我们就开辟一个新的节点。然后将cur指向节点的val值赋给新开辟的节点。最重要的一步来咯:我们将新节点链接到cur指向的节点和cur->next指向的节点之间。至于为什么这么做,且看第二步。要完成这一步操作我们需要维护三个指针:cur,next,copyNode。cur就是遍历原链表的那个节点,next用于保存cur的下一个节点,方便copyNode节点的插入,copyNode就是cur的拷贝节点。
我们来看看完成之后的效果:
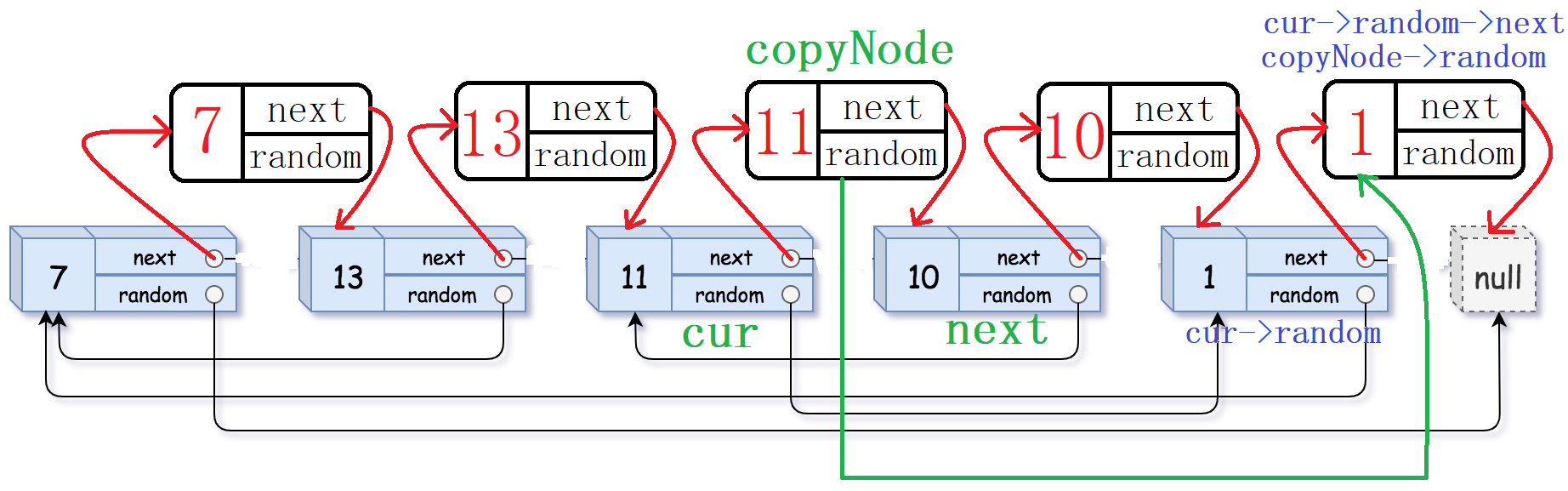
第二步:链接random指针。这里就能体现出第一步的妙处所在了。怎么链接呢?这里我们需要维护三个指针:cur,copyNode,next。cur指针用来遍历原链表,copyNode就是cur->next,也就是第一步拷贝的节点,next是copyNode->next。
我们来看怎么链接:
copyNode->random = cur->random->next
是不是非常的厉害,下面演示了random的一次链接,画全的话太混乱了。
一个节点连接完成之后,就令cur = next进行下一个节点的链接就行!当cur->random = NULL时需要特殊处理一下哦!
第三步:取下拷贝节点,恢复原链表。这一步就比较简单啦!同样维护三个指针,cur,copyNode,next。cur指针用于遍历原链表,copyNode用来尾插,next是copyNode->next,cur遍历一个节点后就令cur = next。emm还要有一个哨兵位的头结点phead,用于copyNode的尾插,当然不用哨兵位的头结点就需要对特殊情况进行处理啦!链接就是cur->next = next,就行啦!
struct Node* copyRandomList(struct Node* head) {//deal with special circumstanceif(!head)return NULL;//copy liststruct Node* cur = head;while(cur){//record the next node to avoid fail to find next nodestruct Node* next = cur->next;//malloc a new nodestruct Node* copyNode = (struct Node*)malloc(sizeof(struct Node));//assignmentcopyNode->val = cur->val;//connectcur->next = copyNode;copyNode->next = next;//iterationcur = next;}//connect the random pointercur = head;while(cur){struct Node* copyNode = cur->next, *next = copyNode->next;//special circumstanceif(cur->random == NULL)copyNode->random = NULL;elsecopyNode->random = cur->random->next;//iterationcur = next;}//resume the original listcur = head;//the head node of the sentinel positionstruct Node* pHead = (struct Node*)malloc(sizeof(struct Node));//make push back convenientstruct Node* tail = pHead;while(cur){struct Node* copyNode = cur->next, *next = copyNode->next;//resumecur->next = next;//push backtail->next = copyNode;tail = copyNode;//iterationcur = next;}//return answerreturn pHead->next;
}
链表常见的OJ题讲到这里就差不多啦🌸🌸!谢谢大家的阅读,如有讲的不对的地方,还请指正!👍
相关文章:
C语言数据结构初阶(6)----链表常见OJ题
CSDN的uu们,大家好!编程能力的提高不仅需要学习新的知识,还需要大量的练习。所以,C语言数据结构初阶的第六讲邀请uu们一起来看看链表的常见oj题目。移除链表元素原题链接:203. 移除链表元素 - 力扣(Leetcod…...

关键字 const
目录 一、符号常量与常变量 二、const的用法 2.1 const常用方法 2.2 const用于指针 2.2.1 p指针所指的对象值不能改变,但是p指针的指向可以改变 2.2.2 常指针p的指向不能改变,但是所指的对象的值可以改变 2.2.3 p所指对象的指向以及对象的值都不可…...
MybatisPlus------MyBatisX插件:快速生成代码以及快速生成CRUD(十二)
MybatisPlus------MyBatisX插件(十二) MyBatisX插件是IDEA插件,如果想要使用它,那么首先需要在IDEA中进行安装。 安装插件 搜索"MyBatisX",点击Install,之后重启IDEA即可。 插件基本用途&…...
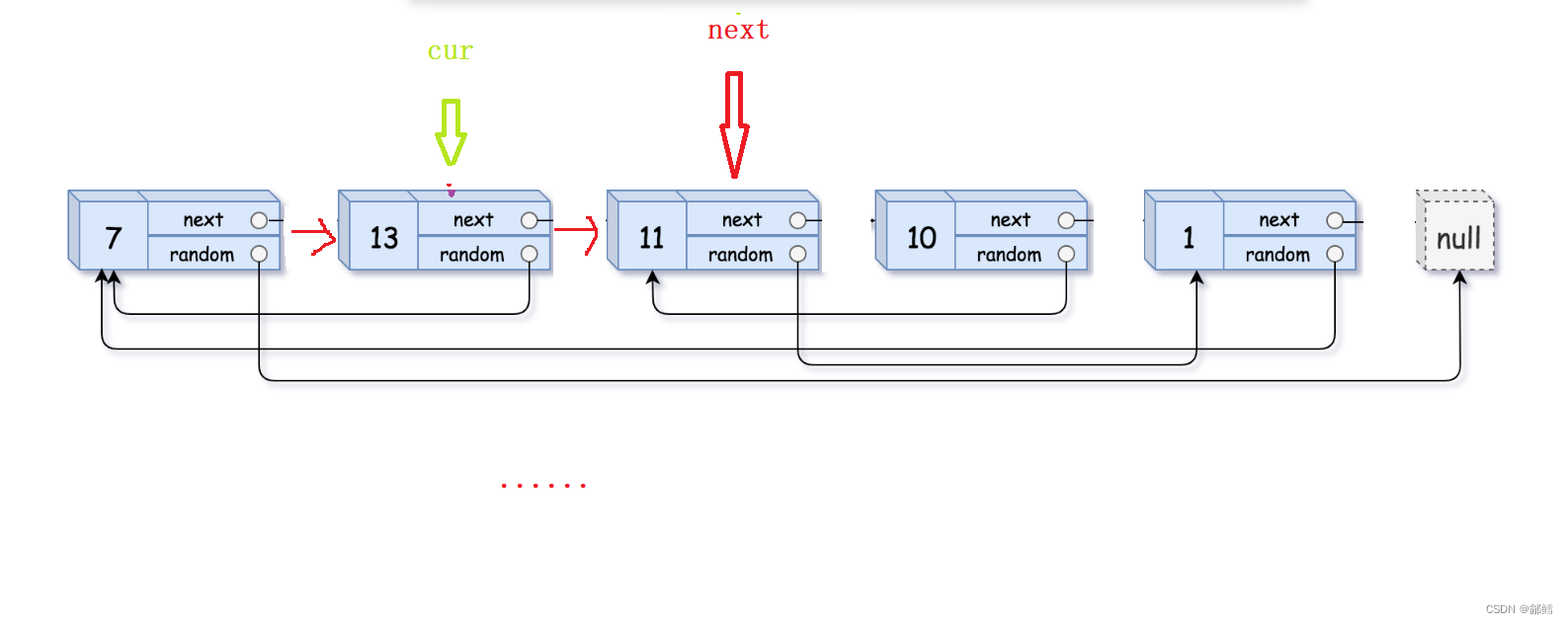
Leetcode138. 复制带随机指针的链表
复制带随机指针的链表 第一步 拷贝节点链接在原节点的后面 第二步拷贝原节点的random , 拷贝节点的 random 在原节点 random 的 next 第三步 将拷贝的节点尾插到一个新链表 ,并且将原链表恢复 从前往后遍历链表 ,将原链表的每个节点进行复制,并l链接到原…...
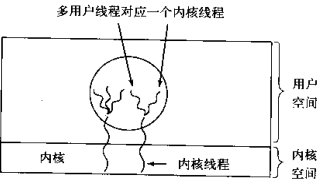
python并发编程多线程
在传统操作系统中,每个进程有一个地址空间,而且默认就有一个控制线程 线程顾名思义,就是一条流水线工作的过程,一条流水线必须属于一个车间,一个车间的工作过程是一个进程 车间负责把资源整合到一起,是一个…...

使用Maven实现Servlet程序
创建Maven项目我们打开idea的新建项目,选中里面Maven即可,如下图:创建完成之后,会看到这样的目录结构其中,main目录存放业务代码,其中的java目录存放的就是java代码,而resources目录存放是程序中依赖的文件,比如:图片,视频等.然后是 test目录,test目录存放的是测试代码.最后一个…...
百度的文心一言 ,没有想像中那么差
robin 的演示 我们用 robin 的演示例子来对比一下 文心一言和 ChatGPT 的真实表现(毕竟发布会上是录的)。 注意,我使用的 GPT 版本是 4.0 文学创作 1 三体的作者是哪里人? 文心一言: ChatGPT: 嗯&a…...

文心一言发布的个人看法
文心一言发布宣传视频按照发布会上说的,文心一言并非属于百度赶工抄袭Chat-GPT的作品,而是十几年一直布局AI产业厚积薄发的成果,百度在芯片,机器学习,自然语言处理,知识图谱等方面均有相对深厚的积累。 国…...

【C5】111
文章目录bmc_wtd:syscpld.c中wd_en和wd_kick节点对应寄存器,crontab,FUNCNAMEAST2500/2600 WDT切换主备:BMC用WDT2作为主备切换的watchdog控制器AC后读取:bmc处于主primary flash(设完后:实际主…...

静态成员,友元函数
🐶博主主页:ᰔᩚ. 一怀明月ꦿ ❤️🔥专栏系列:线性代数,C初学者入门训练,题解C,C的使用文章,「初学」C 🔥座右铭:“不要等到什么都没有了,才下…...
:函数)
数学分析课程笔记(张平):函数
01 函数 \quad作为数学分析的第一节课,首先深入了解一下函数。 \quad翻看一些教材可以发现,有些教材将“函数”与“映射”区分为两个概念,有些教材(尤其是前苏联时期的一些教材)则将其视为一个概念。实际上,…...

spring事务 只读此文
文章目录一. 事务概述1.1. MySQL 数据库事务1.2 spring的事务支持:1.2.1 编程式事务:1.2.2 声明式事务1.2.3 事务传播行为:1.2.4 事务隔离级别1.2.5 事务的超时时间1.2.6 事务的只读属性1.2.7 事务的回滚策略二. spring事务(注解 Transaction…...
真实的软件测试日常工作是咋样的?
最近很多粉丝问我,小姐姐,现在大环境不景气,传统行业不好做了,想转行软件测试,想知道软件测试日常工作是咋样的?平常的工作内容是什么? 别急,今天跟大家细细说一下一个合格的软件测…...
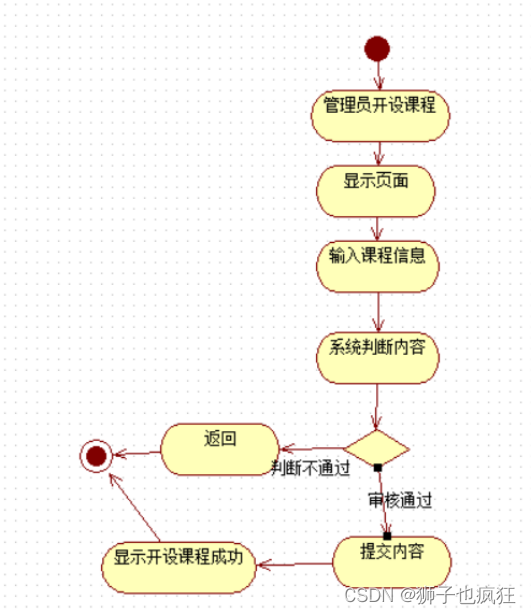
【UML】软件需求说明书
目录🦁 故事的开端一. 🦁 引言1.1编写目的1.2背景1.3定义1.4参考资料二. 🦁 任务概述2.1目标2.2用户的特点2.3假定和约束三. 🦁 需求规定3.1 功能性需求3.1.1系统用例图3.1.2用户登录用例3.1.3学员注册用例3.1.4 学员修改个人信息…...

面试官:html里面哪个元素可以让文字换行展示
在HTML中,可以使用 <br> 元素来强制换行,也可以使用CSS的 word-break 或 white-space 属性来实现自动换行。以下是这些方法的具体说明: 1.使用 <br> 元素 <br> 元素可以在文本中插入一个换行符,使文本从该位置…...

XGBoost和LightGBM时间序列预测对比
XGBoost和LightGBM都是目前非常流行的基于决策树的机器学习模型,它们都有着高效的性能表现,但是在某些情况下,它们也有着不同的特点。 XGBoost和LightGBM简单对比 训练速度 LightGBM相较于xgboost在训练速度方面有明显的优势。这是因为Ligh…...
JVM高频面试题
1、项目中什么情况下会内存溢出,怎么解决? (1)误用固定大小线程池导致内存溢出 Excutors.newFixedThreadPool内最大线程数是21亿(2) 误用带缓冲线程池导致内存溢出最大线程数是21亿(3)一次查询太多的数据,导致内存占用…...
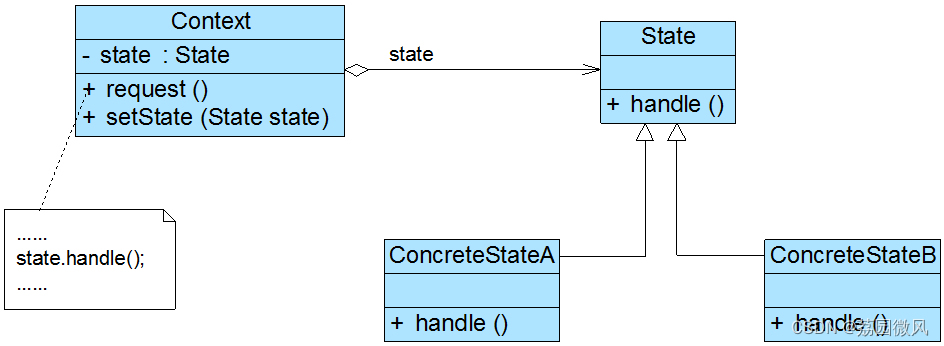
Windows环境下实现设计模式——状态模式(JAVA版)
我是荔园微风,作为一名在IT界整整25年的老兵,今天总结一下Windows环境下如何编程实现状态模式(设计模式)。不知道大家有没有这样的感觉,看了一大堆编程和设计模式的书,却还是很难理解设计模式,无…...
)
【总结】多个条件排序(pii/struct/bool)
目录 pii struct bool pii 现在小龙同学要吃掉它们,已知他有n颗苹果,并且打算每天吃一个。 但是古人云,早上金苹果,晚上毒苹果。由此可见,早上吃苹果和晚上吃苹果的效果是不一样的。 已知小龙同学在第 i 天早上吃苹果能…...
基于stm32mp157 linux开发板ARM裸机开发教程Cortex-A7 开发环境搭建(连载中)
前言:目前针对ARM Cortex-A7裸机开发文档及视频进行了二次升级持续更新中,使其内容更加丰富,讲解更加细致,全文所使用的开发平台均为华清远见FS-MP1A开发板(STM32MP157开发板)针对对FS-MP1A开发板ÿ…...

地震勘探——干扰波识别、井中地震时距曲线特点
目录 干扰波识别反射波地震勘探的干扰波 井中地震时距曲线特点 干扰波识别 有效波:可以用来解决所提出的地质任务的波;干扰波:所有妨碍辨认、追踪有效波的其他波。 地震勘探中,有效波和干扰波是相对的。例如,在反射波…...

基于Flask实现的医疗保险欺诈识别监测模型
基于Flask实现的医疗保险欺诈识别监测模型 项目截图 项目简介 社会医疗保险是国家通过立法形式强制实施,由雇主和个人按一定比例缴纳保险费,建立社会医疗保险基金,支付雇员医疗费用的一种医疗保险制度, 它是促进社会文明和进步的…...

vscode(仍待补充)
写于2025 6.9 主包将加入vscode这个更权威的圈子 vscode的基本使用 侧边栏 vscode还能连接ssh? debug时使用的launch文件 1.task.json {"tasks": [{"type": "cppbuild","label": "C/C: gcc.exe 生成活动文件"…...

(二)TensorRT-LLM | 模型导出(v0.20.0rc3)
0. 概述 上一节 对安装和使用有个基本介绍。根据这个 issue 的描述,后续 TensorRT-LLM 团队可能更专注于更新和维护 pytorch backend。但 tensorrt backend 作为先前一直开发的工作,其中包含了大量可以学习的地方。本文主要看看它导出模型的部分&#x…...

在 Nginx Stream 层“改写”MQTT ngx_stream_mqtt_filter_module
1、为什么要修改 CONNECT 报文? 多租户隔离:自动为接入设备追加租户前缀,后端按 ClientID 拆分队列。零代码鉴权:将入站用户名替换为 OAuth Access-Token,后端 Broker 统一校验。灰度发布:根据 IP/地理位写…...

高危文件识别的常用算法:原理、应用与企业场景
高危文件识别的常用算法:原理、应用与企业场景 高危文件识别旨在检测可能导致安全威胁的文件,如包含恶意代码、敏感数据或欺诈内容的文档,在企业协同办公环境中(如Teams、Google Workspace)尤为重要。结合大模型技术&…...

IT供电系统绝缘监测及故障定位解决方案
随着新能源的快速发展,光伏电站、储能系统及充电设备已广泛应用于现代能源网络。在光伏领域,IT供电系统凭借其持续供电性好、安全性高等优势成为光伏首选,但在长期运行中,例如老化、潮湿、隐裂、机械损伤等问题会影响光伏板绝缘层…...

高防服务器能够抵御哪些网络攻击呢?
高防服务器作为一种有着高度防御能力的服务器,可以帮助网站应对分布式拒绝服务攻击,有效识别和清理一些恶意的网络流量,为用户提供安全且稳定的网络环境,那么,高防服务器一般都可以抵御哪些网络攻击呢?下面…...

大学生职业发展与就业创业指导教学评价
这里是引用 作为软工2203/2204班的学生,我们非常感谢您在《大学生职业发展与就业创业指导》课程中的悉心教导。这门课程对我们即将面临实习和就业的工科学生来说至关重要,而您认真负责的教学态度,让课程的每一部分都充满了实用价值。 尤其让我…...

10-Oracle 23 ai Vector Search 概述和参数
一、Oracle AI Vector Search 概述 企业和个人都在尝试各种AI,使用客户端或是内部自己搭建集成大模型的终端,加速与大型语言模型(LLM)的结合,同时使用检索增强生成(Retrieval Augmented Generation &#…...