XGBoost和LightGBM时间序列预测对比
XGBoost和LightGBM都是目前非常流行的基于决策树的机器学习模型,它们都有着高效的性能表现,但是在某些情况下,它们也有着不同的特点。

XGBoost和LightGBM简单对比
训练速度
LightGBM相较于xgboost在训练速度方面有明显的优势。这是因为LightGBM使用了一些高效的算法和数据结构,比如直方图算法和基于梯度单边采样算法(GOSS),这些算法使得LightGBM在训练大规模数据集时速度更快。
内存消耗
由于LightGBM使用了一些高效的算法和数据结构,因此其内存消耗相对较小。而xgboost在处理大规模数据集时可能会需要较大的内存。
鲁棒性
xgboost在处理一些不规则数据时更加鲁棒,比如一些缺失值和异常值。而LightGBM在这方面相对较弱。
精度
在相同的数据集和参数设置下,两个模型的精度大致相当。不过在某些情况下,xgboost可能表现得更好,比如在特征数较少的情况下,或者是需要更加平滑的决策树时。
参数设置
xgboost的参数比较多,需要根据实际情况进行调整。而LightGBM的参数相对较少,大多数情况下使用默认参数即可。
XGBoost和 LightGBM 算法对比
XGBoost和 LightGBM 都是基于决策树的梯度提升框架,它们的核心思想都是通过组合多个弱学习器来提升模型的预测能力。它们在实现上有很多相似之处,但在算法方面有一些明显的不同:
分裂点选择方法
在构建决策树时,xgboost 采用的是一种贪心算法,称为 Exact Greedy Algorithm,它会枚举每一个特征的每一个取值作为分裂点,然后计算对应的增益值,选取最大增益的分裂点作为最终的分裂点。
而 LightGBM 使用的是一种基于梯度单边采样(Gradient-based One-Side Sampling,GOSS)和直方图算法的分裂点选择方法,它会先对数据进行预排序,然后将数据划分成若干个直方图,每个直方图包含多个数据点。在寻找最优分裂点时,LightGBM 只会在直方图中选取一个代表点(即直方图中的最大梯度值)进行计算,这样大大降低了计算量。
特征并行处理
xgboost 将数据按特征进行划分,然后将每个特征分配到不同的节点上进行计算。这种方法可以有效提高训练速度,但需要额外的通信和同步开销。
LightGBM 将数据按行进行划分,然后将每个分块分配到不同的节点上进行计算。这种方法避免了通信和同步开销,但需要额外的内存空间。
处理缺失值
xgboost 会自动将缺失值分配到左右子树中概率更高的那一边。这种方法可能会引入一些偏差,但对于处理缺失值较多的数据集比较有效。
LightGBM 则采用的方法称为 Zero As Missing(ZAM),它将所有的缺失值都视为一个特殊的取值,并将其归入其中一个子节点中。这种方法可以避免偏差,但需要更多的内存空间。
训练速度
LightGBM 在训练速度方面具有显著优势,这是因为它使用了 GOSS 和直方图算法,减少了计算量和内存消耗。而 xgboost 的计算速度相对较慢,但是在处理较小的数据集时表现良好。
电力能源消耗预测
在当今世界,能源是主要的讨论点之一,能够准确预测能源消费需求是任何电力公司的关键,所以我们这里以能源预测为例,对这两个目前最好的表格类数据的模型做一个对比。
我们使用的是伦敦能源数据集,其中包含2011年11月至2014年2月期间英国伦敦市5567个随机选择的家庭的能源消耗。我们将这个集与伦敦天气数据集结合起来,作为辅助数据来提高模型的性能。
1、预处理
在每个项目中,我们要做的第一件事就是很好地理解数据,并在需要时对其进行预处理:
import pandas as pdimport matplotlib.pyplot as pltdf = pd.read_csv("london_energy.csv")print(df.isna().sum())df.head()
“LCLid”是标识每个家庭的唯一字符串,“Date”就是我们的时间索引,“KWH”是在该日期花费的总千瓦时数,没有任何缺失值。由于我们想要以一般方式而不是以家庭为单位来预测耗电量,所以我们需要将结果按日期分组并平均千瓦时。
df_avg_consumption = df.groupby("Date")["KWH"].mean()df_avg_consumption = pd.DataFrame({"date": df_avg_consumption.index.tolist(), "consumption": df_avg_consumption.values.tolist()})df_avg_consumption["date"] = pd.to_datetime(df_avg_consumption["date"])print(f"From: {df_avg_consumption['date'].min()}")print(f"To: {df_avg_consumption['date'].max()}")
我们来做一个折线图:
df_avg_consumption.plot(x="date", y="consumption")
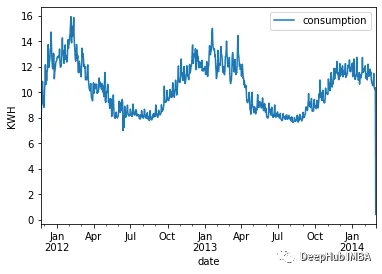
季节性特征非常明显。冬季能源需求很高,而夏季的消耗是最低的。这种行为在数据集中每年都会重复,具有不同的高值和低值。可视化一年内的波动:
df_avg_consumption.query("date > '2012-01-01' & date < '2013-01-01'").plot(x="date", y="consumption")
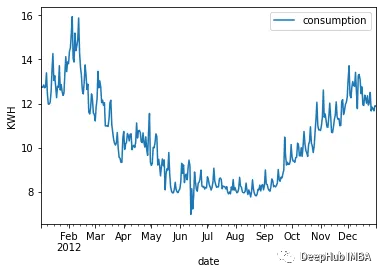
训练像XGBoost和LightGB这样的模型,我们需要自己创建特征。因为目前我们只有一个特征:日期。所欲需要根据完整的日期提取不同的特征,例如星期几、一年中的哪一天、月份和其他日期:
df_avg_consumption["day_of_week"] = df_avg_consumption["date"].dt.dayofweekdf_avg_consumption["day_of_year"] = df_avg_consumption["date"].dt.dayofyeardf_avg_consumption["month"] = df_avg_consumption["date"].dt.monthdf_avg_consumption["quarter"] = df_avg_consumption["date"].dt.quarterdf_avg_consumption["year"] = df_avg_consumption["date"].dt.yeardf_avg_consumption.head()
’ date '特征就变得多余了。但是在删除它之前,我们将使用它将数据集分割为训练集和测试集。与传统的训练相反,在时间序列中,我们不能只是以随机的方式分割集合,因为数据的顺序非常重要,所以对于测试集,将只使用最近6个月的数据。如果训练集更大,可以用去年全年的数据作为测试集。
training_mask = df_avg_consumption["date"] < "2013-07-28"training_data = df_avg_consumption.loc[training_mask]print(training_data.shape)testing_mask = df_avg_consumption["date"] >= "2013-07-28"testing_data = df_avg_consumption.loc[testing_mask]print(testing_data.shape)
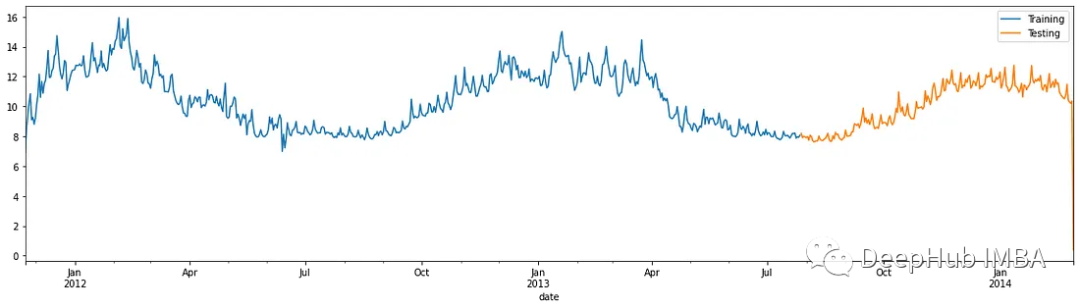
可视化训练集和测试集之间的分割:
figure, ax = plt.subplots(figsize=(20, 5))training_data.plot(ax=ax, label="Training", x="date", y="consumption")testing_data.plot(ax=ax, label="Testing", x="date", y="consumption")plt.show()
现在我们可以删除’ date '并创建训练和测试集:
# Dropping unnecessary `date` columntraining_data = training_data.drop(columns=["date"])testing_dates = testing_data["date"]testing_data = testing_data.drop(columns=["date"])X_train = training_data[["day_of_week", "day_of_year", "month", "quarter", "year"]]y_train = training_data["consumption"]X_test = testing_data[["day_of_week", "day_of_year", "month", "quarter", "year"]]y_test = testing_data["consumption"]
2、训练模型
我们这里的超参数优化将通过网格搜索完成。因为是时间序列,所以不能只使用普通的k-fold交叉验证。Scikit learn提供了TimeSeriesSplit方法,这里可以直接使用。
from xgboost import XGBRegressorimport lightgbm as lgbfrom sklearn.model_selection import TimeSeriesSplit, GridSearchCV# XGBoostcv_split = TimeSeriesSplit(n_splits=4, test_size=100)model = XGBRegressor()parameters = {"max_depth": [3, 4, 6, 5, 10],"learning_rate": [0.01, 0.05, 0.1, 0.2, 0.3],"n_estimators": [100, 300, 500, 700, 900, 1000],"colsample_bytree": [0.3, 0.5, 0.7]}grid_search = GridSearchCV(estimator=model, cv=cv_split, param_grid=parameters)grid_search.fit(X_train, y_train)
对于LightGB,代码是这样的:
# LGBMcv_split = TimeSeriesSplit(n_splits=4, test_size=100)model = lgb.LGBMRegressor()parameters = {"max_depth": [3, 4, 6, 5, 10],"num_leaves": [10, 20, 30, 40, 100, 120],"learning_rate": [0.01, 0.05, 0.1, 0.2, 0.3],"n_estimators": [50, 100, 300, 500, 700, 900, 1000],"colsample_bytree": [0.3, 0.5, 0.7, 1]}grid_search = GridSearchCV(estimator=model, cv=cv_split, param_grid=parameters)grid_search.fit(X_train, y_train)
3、评估
为了评估测试集上的最佳估计量,我们将计算:平均绝对误差(MAE)、均方误差(MSE)和平均绝对百分比误差(MAPE)。因为每个指标都提供了训练模型实际性能的不同视角。我们还将绘制一个折线图,以更好地可视化模型的性能。
from sklearn.metrics import mean_absolute_error, mean_absolute_percentage_error,\mean_squared_errordef evaluate_model(y_test, prediction):print(f"MAE: {mean_absolute_error(y_test, prediction)}")print(f"MSE: {mean_squared_error(y_test, prediction)}")print(f"MAPE: {mean_absolute_percentage_error(y_test, prediction)}")def plot_predictions(testing_dates, y_test, prediction):df_test = pd.DataFrame({"date": testing_dates, "actual": y_test, "prediction": prediction })figure, ax = plt.subplots(figsize=(10, 5))df_test.plot(ax=ax, label="Actual", x="date", y="actual")df_test.plot(ax=ax, label="Prediction", x="date", y="prediction")plt.legend(["Actual", "Prediction"])plt.show()
然后我们运行下面代码进行验证:
# Evaluating GridSearch resultsprediction = grid_search.predict(X_test)plot_predictions(testing_dates, y_test, prediction)evaluate_model(y_test, prediction)
XGB:
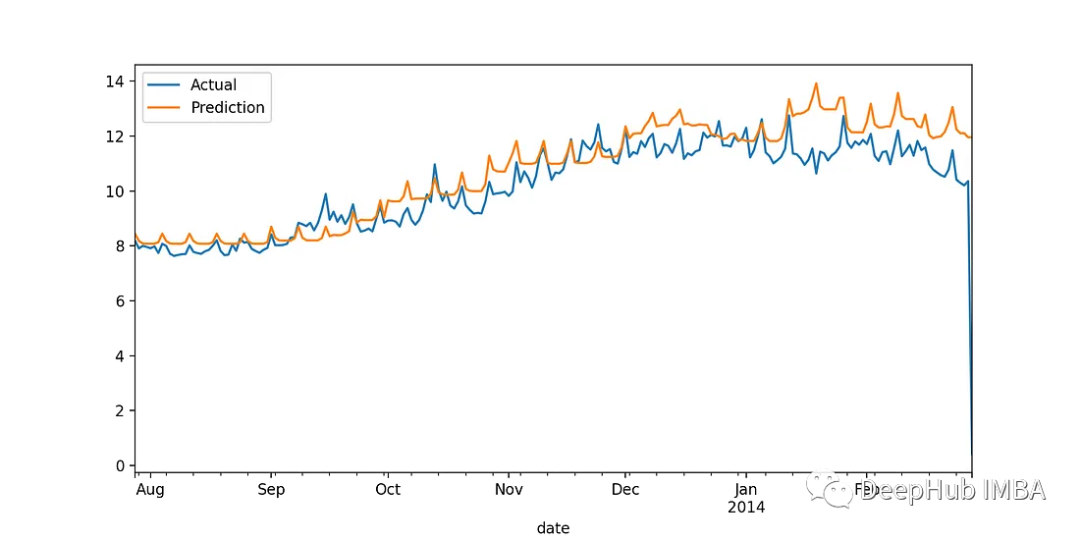
LightGBM:
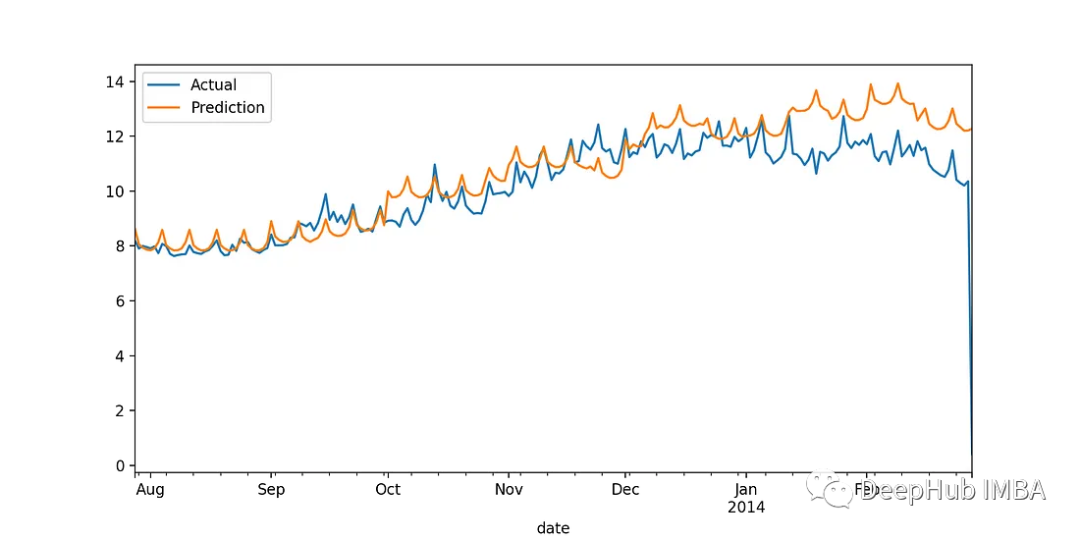
从图上可以看到,XGBoost可以更准确地预测冬季的能源消耗,但为了量化和比较性能,我们计算误差指标。通过查看下面的表,可以很明显地看出XGBoost在所有情况下都优于LightGBM。
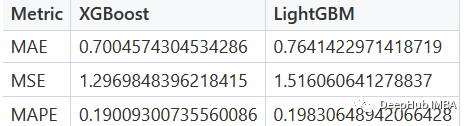
使用外部辅助天气数据
该模型表现还不错,我们看看还能不能提高呢?为了达到更好的效果,可以采用许多不同的技巧和技巧。其中之一是使用与能源消耗直接或间接相关的辅助特征。例如,在预测能源需求时,天气数据可以发挥决定性作用。这就是为什么我们选择使用伦敦天气数据集的天气数据的原因。
首先让我们来看看数据的结构:
df_weather = pd.read_csv("london_weather.csv")print(df_weather.isna().sum())df_weather.head()
这个数据集中有各种缺失的数据需要填充。填充缺失的数据也不是一件简单的事情,因为每种不同的情况填充方法是不同的。我们这里的天气数据,每天都取决于前几天和下一天,所以可以通过插值来填充这些值。另外还需要将’ date ‘列转换为’ datetime ',然后合并两个DF,以获得一个增强的完整数据集。
# Parsing datesdf_weather["date"] = pd.to_datetime(df_weather["date"], format="%Y%m%d")# Filling missing values through interpolationdf_weather = df_weather.interpolate(method="ffill")# Enhancing consumption dataset with weather informationdf_avg_consumption = df_avg_consumption.merge(df_weather, how="inner", on="date")df_avg_consumption.head()
在生成增强集之后,必须重新运行拆分过程获得新的’ training_data ‘和’ testing_data '。
# Dropping unnecessary `date` columntraining_data = training_data.drop(columns=["date"])testing_dates = testing_data["date"]testing_data = testing_data.drop(columns=["date"])X_train = training_data[["day_of_week", "day_of_year", "month", "quarter", "year",\"cloud_cover", "sunshine", "global_radiation", "max_temp",\"mean_temp", "min_temp", "precipitation", "pressure",\"snow_depth"]]y_train = training_data["consumption"]X_test = testing_data[["day_of_week", "day_of_year", "month", "quarter", "year",\"cloud_cover", "sunshine", "global_radiation", "max_temp",\"mean_temp", "min_temp", "precipitation", "pressure",\"snow_depth"]]y_test = testing_data["consumption"]
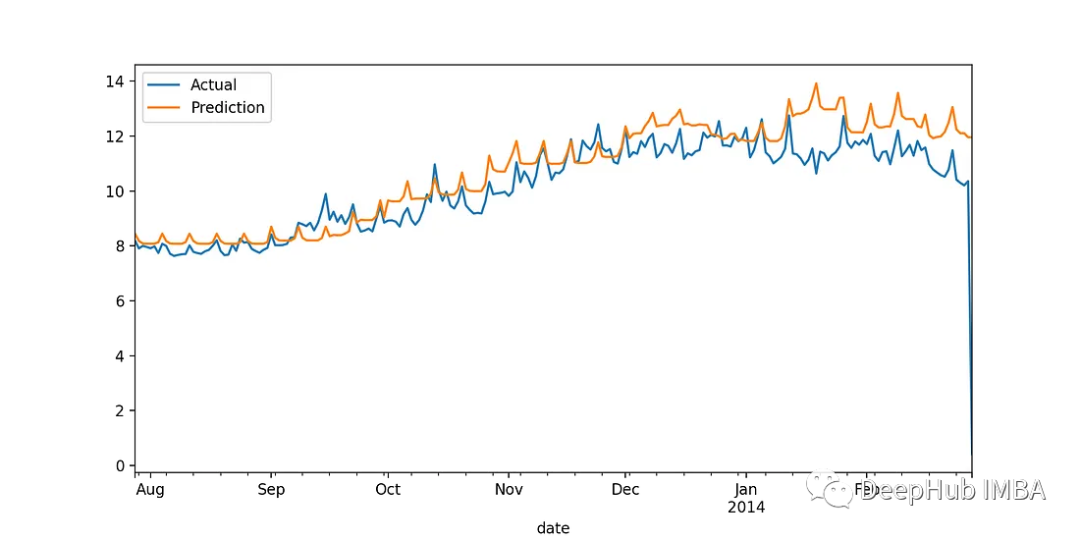
训练步骤不需要做更改。在新数据集上训练模型后,我们得到以下结果:
XGBoost
LightGBM
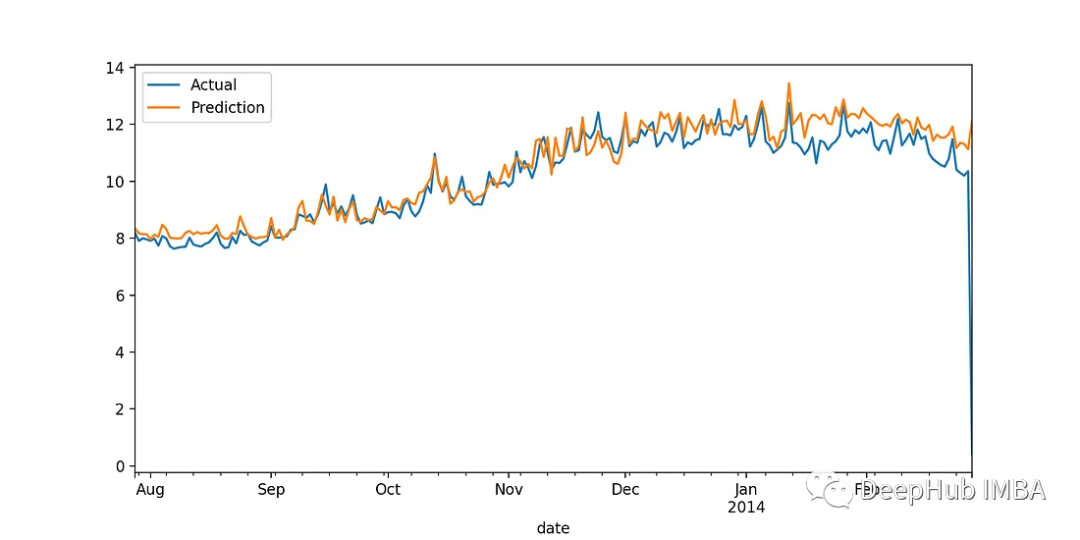
整合上面的表格:

我们看到:天气数据大大提高了两个模型的性能。特别是在XGBoost场景中,MAE减少了近44%,而MAPE从19%减少到16%。对于LightGBM, MAE下降了42%,MAPE从19.8%下降到16.7%。
总结
xgboost 和 LightGBM 都是优秀的梯度提升框架,它们各自具有一些独特的优点和缺点,选择哪一种算法应该根据实际应用场景和数据集的特征来决定。如果数据集中缺失值较多,可以选择 xgboost。如果需要处理大规模数据集并追求更快的训练速度,可以选择 LightGBM。如果需要解释模型的特征重要性,xgboost 提供了更好的特征重要性评估方法,并且如果需要更加鲁棒的模型,可以优先选择xgboost。
在本文中我们还介绍了一种提高模型的方法,就是使用附加数据,通过附加我们认为相关的辅助数据,也可以大大提高模型的性能。
除此以外,我们还可以结合滞后特征或尝试不同的超参数优化技术(如随机搜索或贝叶斯优化),来作为提高性能的尝试,如果你有任何新的结果,欢迎留言。
以下是2个数据集的链接:
https://avoid.overfit.cn/post/bfcd5ca1cd7741acac137fade88bd747
作者:George Kamtziridis
相关文章:
XGBoost和LightGBM时间序列预测对比
XGBoost和LightGBM都是目前非常流行的基于决策树的机器学习模型,它们都有着高效的性能表现,但是在某些情况下,它们也有着不同的特点。 XGBoost和LightGBM简单对比 训练速度 LightGBM相较于xgboost在训练速度方面有明显的优势。这是因为Ligh…...
JVM高频面试题
1、项目中什么情况下会内存溢出,怎么解决? (1)误用固定大小线程池导致内存溢出 Excutors.newFixedThreadPool内最大线程数是21亿(2) 误用带缓冲线程池导致内存溢出最大线程数是21亿(3)一次查询太多的数据,导致内存占用…...
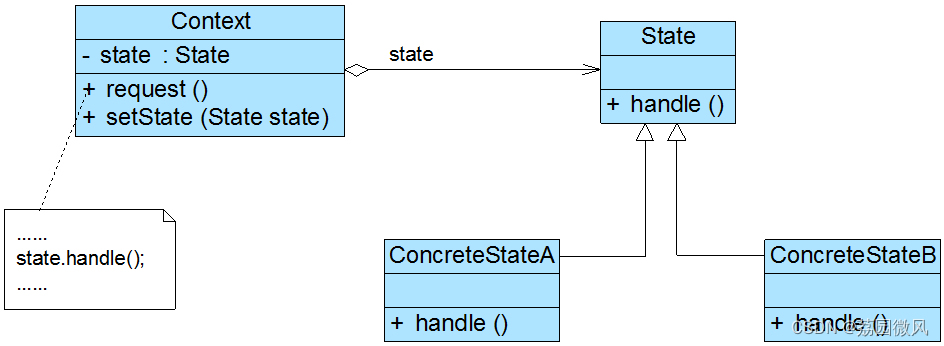
Windows环境下实现设计模式——状态模式(JAVA版)
我是荔园微风,作为一名在IT界整整25年的老兵,今天总结一下Windows环境下如何编程实现状态模式(设计模式)。不知道大家有没有这样的感觉,看了一大堆编程和设计模式的书,却还是很难理解设计模式,无…...
)
【总结】多个条件排序(pii/struct/bool)
目录 pii struct bool pii 现在小龙同学要吃掉它们,已知他有n颗苹果,并且打算每天吃一个。 但是古人云,早上金苹果,晚上毒苹果。由此可见,早上吃苹果和晚上吃苹果的效果是不一样的。 已知小龙同学在第 i 天早上吃苹果能…...
基于stm32mp157 linux开发板ARM裸机开发教程Cortex-A7 开发环境搭建(连载中)
前言:目前针对ARM Cortex-A7裸机开发文档及视频进行了二次升级持续更新中,使其内容更加丰富,讲解更加细致,全文所使用的开发平台均为华清远见FS-MP1A开发板(STM32MP157开发板)针对对FS-MP1A开发板ÿ…...

最适合游戏开发的语言是什么?
建议初学者学习主流的开发技术 主流开发技术有大量成熟的教程、很多可以交流的学习者、及时的学习反馈等;技术的内里基本都是相同的,学习主流技术的经验、知识可以更好更快地疏通学习新知识和技术。 因此,对C#或者C二选一进行学习较好。 Un…...

C语言刷题(7)(字符串旋转问题)——“C”
各位CSDN的uu们你们好呀,今天,小雅兰的内容依旧是复习之前的知识点,那么,就是做一道小小的题目啦,下面,让我们进入C语言的世界吧 实现一个函数,可以左旋字符串中的k个字符。 例如: A…...
有趣且重要的JS知识合集(18)浏览器实现前端录音功能
1、主题描述 兼容多个浏览器下的前端录音功能,实现六大录音功能: 1、开始录音 2、暂停录音 3、继续录音 4、结束录音 5、播放录音 6、上传录音 2、示例功能 初始状态: 开始录音: 结束录音: 录音流程 …...
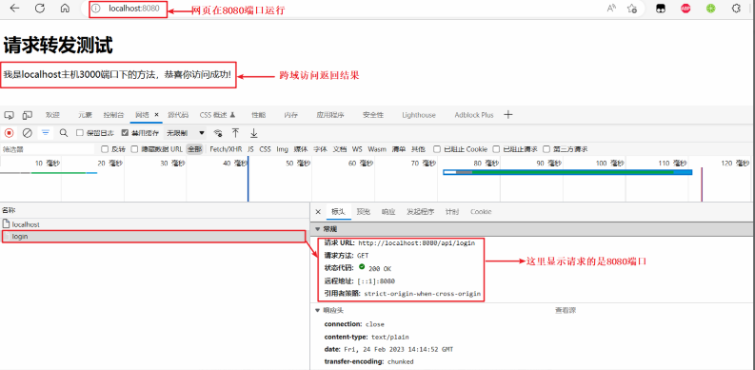
面试官:聊聊你知道的跨域解决方案
跨域是开发中经常会遇到的一个场景,也是面试中经常会讨论的一个问题。掌握常见的跨域解决方案及其背后的原理,不仅可以提高我们的开发效率,还能在面试中表现的更加游刃有余。 因此今天就来和大家从前端的角度来聊聊解决跨域常见的几种方式。…...
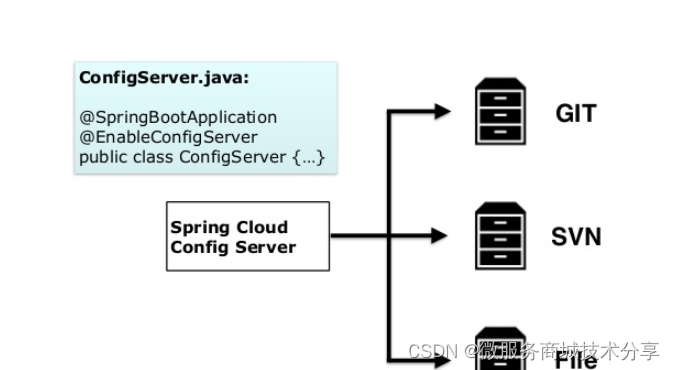
SpringCloud五大核心组件
Consul 等,提供了搭建分布式系统及微服务常用的工具,如配置管理、服务发现、断路器、智能路由、微代理、控制总线、一次性token、全局锁、选主、分布式会话和集群状态等,满足了构建微服务所需的所有解决方案。 服务发现——Netflix Eureka …...
)
Verilog HDL语言入门(二)
强烈建议用同步设计2.在设计时总是记住时序问题3.在一个设计开始就要考虑到地电平或高电平复位、同步或异步复位、上升沿或下降沿触发等问题,在所有模块中都要遵守它4.在不同的情况下用if和case,最好少用if的多层嵌套(1层或2层比较合适&#…...
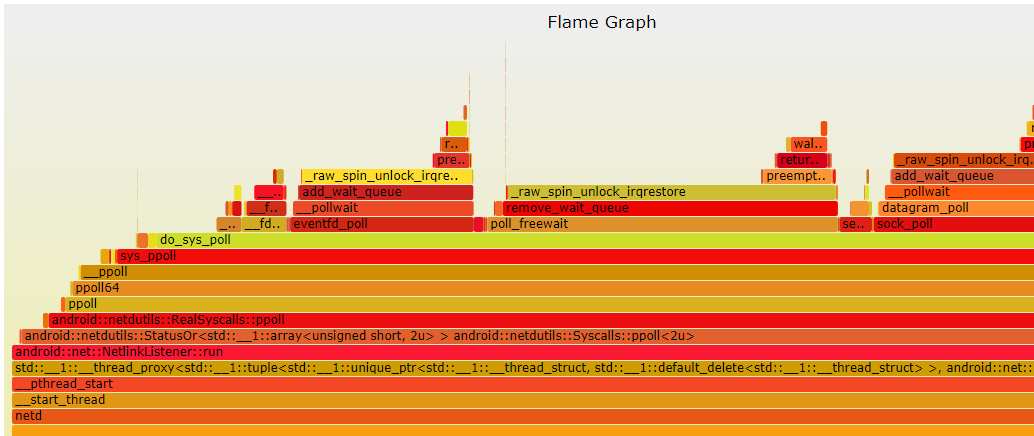
Simpleperf详细使用
一、Simpleperf介绍 Simpleperf是一个强大的命令行工具,它包含在NDK中,可以帮助我们分析应用的CPU性能。Simpleperf可以帮助我们找到应用的热点,而热点往往与性能问题相关,这样我们就可以分析修复热点源。 如果您更喜欢使用命令…...

【算法基础】二分图(染色法 匈牙利算法)
一、二分图 1. 染色法 一个图是二分图,当且仅当,图中不含奇数环。在判别一个图是否为二分图⑩,其实相当于染色问题,每条边的两个点必须是不同的颜色,一共有两种颜色,如果染色过程中出现矛盾,则说明不是二分图。 for i = 1 to n:if i 未染色DFS(i, 1); //将i号点染色未…...

Caputo 分数阶微分方程-慢扩散方程初边值问题基于L1 逼近的空间二阶方法及其Matlab程序实现
2.3.3 Caputo 分数阶一维问题基于 L1 逼近的空间二阶方法 考虑如下时间分数阶慢扩散方程初边值问题 { 0 C D t α u ( x , t ) = u...
 GPIO驱动)
I.MX6ULL_Linux_驱动篇(29) GPIO驱动
Linux 下的任何外设驱动,最终都是要配置相应的硬件寄存器。所以本篇的 LED 灯驱动最终也是对 I.MX6ULL 的 IO 口进行配置,与裸机实验不同的是,在 Linux 下编写驱动要符合 Linux 的驱动框架。I.MX6U-ALPHA 开发板上的 LED 连接到 I.MX6ULL 的 …...

jupyter的安装和使用
目录 ❤ Jupyter Notebook是什么? notebook jupyter 简介 notebook jupyter 组成 网页应用 文档 主要特点 ❤ jupyter notebook的安装 notebook jupyter 安装有两种途径 1.通过Anaconda进行安装 2.通过pip进行安装 启动jupyter notebook ❤ jupyter …...

Springboot新手开发 Cloud篇
前言: 👏作者简介:我是笑霸final,一名热爱技术的在校学生。 📝个人主页:个人主页1 || 笑霸final的主页2 📕系列专栏:后端专栏 📧如果文章知识点有错误的地方,…...

Linux:函数指针做函数参数
#include <stdio.h> #include <stdlib.h> //创建带有函数指针做参数的函数框架api //调用者要先实现回调函数 //调用者再去调用函数框架 //所谓的回调是指 调用者去调用一个带有函数指针做参数的函数框架,函数框架反过来要调用调用者提供的回调函数 …...
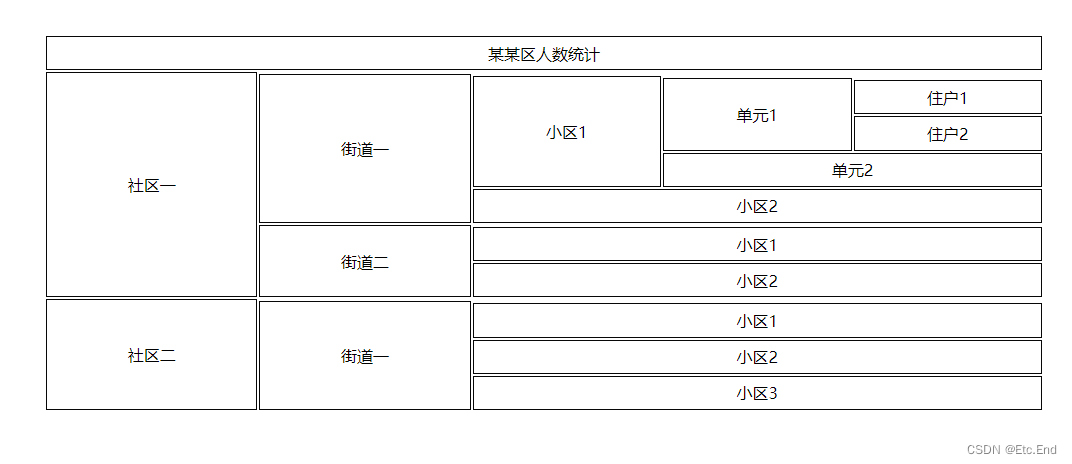
Vue3(递归组件) + 原生Table 实现树结构复杂表格
一、递归组件 什么是递归,Javascript中经常能接触到递归函数。也就是函数自己调用自己。那对于组件来说也是一样的逻辑。平时工作中见得最多应该就是菜单组件,大部分系统里面的都是递归组件。文章中我做了按需引入的配置,所以看不到我引用组…...
ArrayList底层源码解析
Java源码系列:下方连接 http://t.csdn.cn/Nwzed 文章目录前言一、**ArrayList底层结构和源码分析**无参构造调用创建ArrayList集合无参构造总结:发文3个工作日后 up 会把总结放入前言部分,但也诚邀读者总结,可放入评论区有参构造…...

国防科技大学计算机基础课程笔记02信息编码
1.机内码和国标码 国标码就是我们非常熟悉的这个GB2312,但是因为都是16进制,因此这个了16进制的数据既可以翻译成为这个机器码,也可以翻译成为这个国标码,所以这个时候很容易会出现这个歧义的情况; 因此,我们的这个国…...

业务系统对接大模型的基础方案:架构设计与关键步骤
业务系统对接大模型:架构设计与关键步骤 在当今数字化转型的浪潮中,大语言模型(LLM)已成为企业提升业务效率和创新能力的关键技术之一。将大模型集成到业务系统中,不仅可以优化用户体验,还能为业务决策提供…...

屋顶变身“发电站” ,中天合创屋面分布式光伏发电项目顺利并网!
5月28日,中天合创屋面分布式光伏发电项目顺利并网发电,该项目位于内蒙古自治区鄂尔多斯市乌审旗,项目利用中天合创聚乙烯、聚丙烯仓库屋面作为场地建设光伏电站,总装机容量为9.96MWp。 项目投运后,每年可节约标煤3670…...

3-11单元格区域边界定位(End属性)学习笔记
返回一个Range 对象,只读。该对象代表包含源区域的区域上端下端左端右端的最后一个单元格。等同于按键 End 向上键(End(xlUp))、End向下键(End(xlDown))、End向左键(End(xlToLeft)End向右键(End(xlToRight)) 注意:它移动的位置必须是相连的有内容的单元格…...

SiFli 52把Imagie图片,Font字体资源放在指定位置,编译成指定img.bin和font.bin的问题
分区配置 (ptab.json) img 属性介绍: img 属性指定分区存放的 image 名称,指定的 image 名称必须是当前工程生成的 binary 。 如果 binary 有多个文件,则以 proj_name:binary_name 格式指定文件名, proj_name 为工程 名&…...

论文笔记——相干体技术在裂缝预测中的应用研究
目录 相关地震知识补充地震数据的认识地震几何属性 相干体算法定义基本原理第一代相干体技术:基于互相关的相干体技术(Correlation)第二代相干体技术:基于相似的相干体技术(Semblance)基于多道相似的相干体…...

elementUI点击浏览table所选行数据查看文档
项目场景: table按照要求特定的数据变成按钮可以点击 解决方案: <el-table-columnprop"mlname"label"名称"align"center"width"180"><template slot-scope"scope"><el-buttonv-if&qu…...
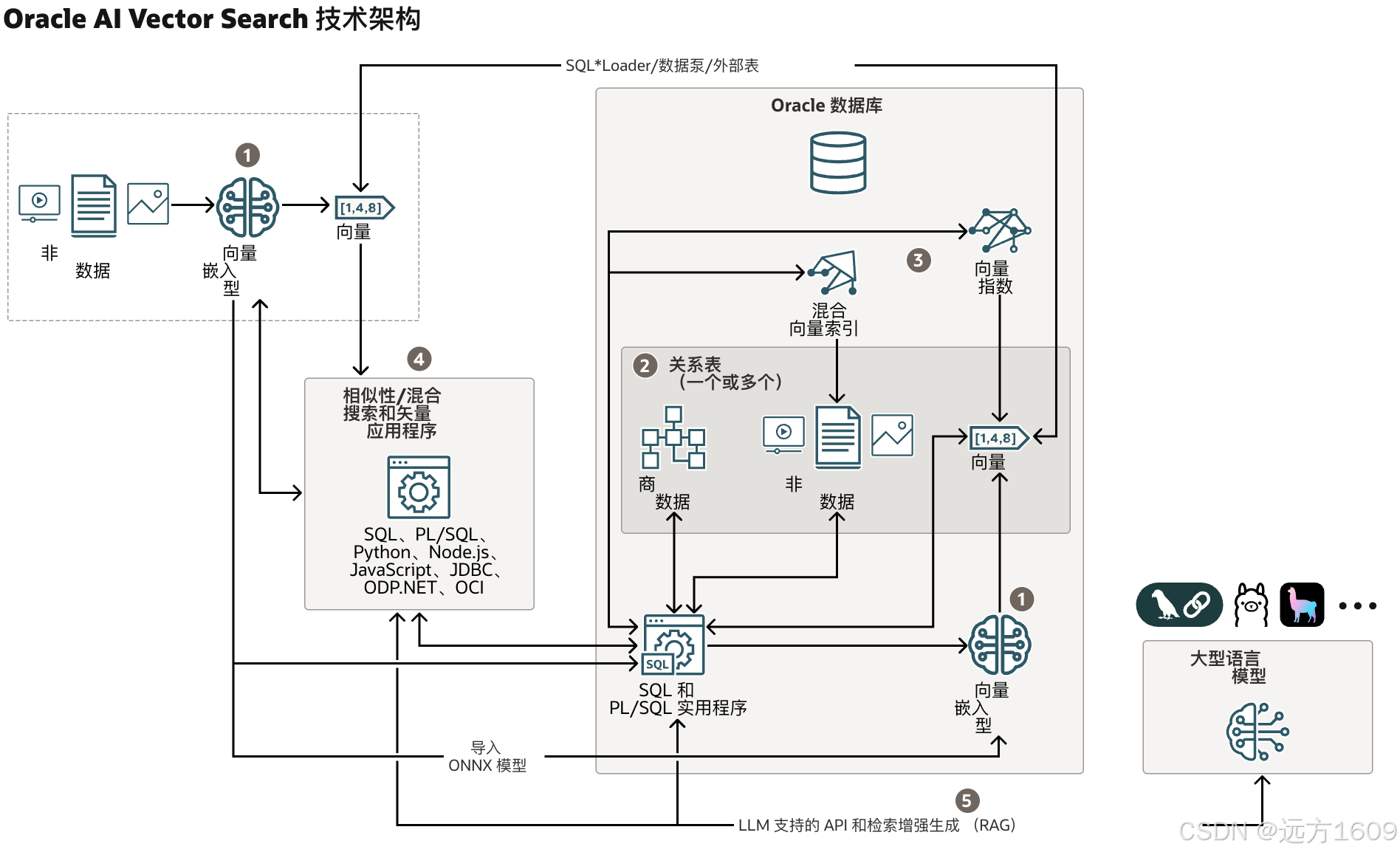
9-Oracle 23 ai Vector Search 特性 知识准备
很多小伙伴是不是参加了 免费认证课程(限时至2025/5/15) Oracle AI Vector Search 1Z0-184-25考试,都顺利拿到certified了没。 各行各业的AI 大模型的到来,传统的数据库中的SQL还能不能打,结构化和非结构的话数据如何和…...

区块链技术概述
区块链技术是一种去中心化、分布式账本技术,通过密码学、共识机制和智能合约等核心组件,实现数据不可篡改、透明可追溯的系统。 一、核心技术 1. 去中心化 特点:数据存储在网络中的多个节点(计算机),而非…...

医疗AI模型可解释性编程研究:基于SHAP、LIME与Anchor
1 医疗树模型与可解释人工智能基础 医疗领域的人工智能应用正迅速从理论研究转向临床实践,在这一过程中,模型可解释性已成为确保AI系统被医疗专业人员接受和信任的关键因素。基于树模型的集成算法(如RandomForest、XGBoost、LightGBM)因其卓越的预测性能和相对良好的解释性…...