Python爬虫实战案例(爬取图片)
爬取图片的信息
爬取图片与爬取文本内容相似,只是需要加上图片的url,并且在查找图片位置的时候需要带上图片的属性。
这里选取了一个4K高清的壁纸网站(彼岸壁纸https://pic.netbian.com)进行爬取。
具体步骤如下:
- 第一步依然是进入这个页面,这个壁纸网站分为好几种类型的壁纸图片,点击一个你想要爬取的类型,然后按F12,从中获取URL和请求方式(复制URL,会用到),这次就不用网页的"User-Agent’'了,用pycharm包中别人写好的。
然后发送我们的请求并获取这个网页的数据

# url
url = "https://pic.netbian.com/4kmeinv/"
# UA伪装 用下载好的库中别人写好的UA
head = {"User-Agent": fake_useragent.UserAgent().random}
# 发送请求
response = requests.get(url, headers=head)
# 获取想要的数据
res_text = response.text
- 第二步打开元素栏,用左上角的寻找工具放在图片上,定位到元素栏中对应的标签,用数据分析的方法获取到图片信息。
其实每一张图片的排放就好像是一个个列表,其所有的信息都粗存在元素栏中的li标签中,我们想要获取多张照片,首先需要先将这些li标签都获取下来。

# 数据解析 获取所有的li标签,并存放在li_list中
tree = etree.HTML(res_text)
li_list = tree.xpath("//div[@class='slist']/ul/li")
- 第三步获取图片与获取文本内容不同的是,需要再获取图片的url,图片的url就在上图箭头所指的位置,但是这个仅仅只是图片在这个板块的位置,所以前面需要在前面加上这个壁纸网站的地址,这样获取的图片信息才是完整的,可以被打开。
因为先前已经将存放图片信息的li标签都存放在了li_list中,所以我们就用for循环遍历这个列表,以便获取更多的图片信息。
for li in li_list:# 图片的urlimg_url = "https://pic.netbian.com" + "".join(li.xpath("./a/img/@src"))# 发送请求img_response = requests.get(img_url, headers=head)# 获取想要的数据img_content = img_response.content
- 第四步将获取到的图片存放在文件夹中
# pic_name = 0 这次的代码封装在函数中,将这个变量放在了函数外面,给获取的图片编号
# 将pic_name定义为全局变量,方便调用
global pic_namewith open(f"./picLibbb/{pic_name}.jpg", "wb") as fp:fp.write(img_content)pic_name += 1
- 第五步为了获取更多的照片,因为每一页能展示的照片有限,所以我们需要for循环遍历每一页的网址;
每一页的网址都只是在页面数量上的差别,所以可以遍历。
第一页的网址

第二页的网址

第三页的网址

url = "https://pic.netbian.com/4kmeinv/"request_pic(url)for i in range(1,10):next_url = f"https://pic.netbian.com/4kmeinv/index_{i}.html"request_pic(next_url)
完整代码:
# 获取图片数据
import os.path
import fake_useragent
import requests
from lxml import etree# UA伪装
head = {"User-Agent": fake_useragent.UserAgent().random}pic_name = 0
def request_pic(url):# 发送请求response = requests.get(url, headers=head)# 获取想要的数据res_text = response.text# 数据解析tree = etree.HTML(res_text)li_list = tree.xpath("//div[@class='slist']/ul/li")for li in li_list:# 图片的urlimg_url = "https://pic.netbian.com" + "".join(li.xpath("./a/img/@src"))# 发送请求img_response = requests.get(img_url, headers=head)# 获取想要的数据img_content = img_response.contentglobal pic_namewith open(f"./picLib/{pic_name}.jpg", "wb") as fp:fp.write(img_content)pic_name += 1if __name__ == '__main__':# 创建存放照片的文件夹if not os.path.exists("./picLib"):os.mkdir("./picLibbb")# 网站的urlurl = "https://pic.netbian.com/4kdongman/"request_pic(url)for i in range(1,10):next_url = f"https://pic.netbian.com/4kmeinv/index_{i}.html"request_pic(next_url)
爬取后的效果如下:

相关文章:
Python爬虫实战案例(爬取图片)
爬取图片的信息 爬取图片与爬取文本内容相似,只是需要加上图片的url,并且在查找图片位置的时候需要带上图片的属性。 这里选取了一个4K高清的壁纸网站(彼岸壁纸https://pic.netbian.com)进行爬取。 具体步骤如下: …...

智慧工地视频汇聚管理平台:打造现代化工程管理的全新视界
一、方案背景 科技高速发展的今天,工地施工已发生翻天覆地的变化,传统工地管理模式很容易造成工地管理混乱、安全事故、数据延迟等问题,人力资源的不足也进一步加剧了监管不到位的局面,严重影响了施工进度质量和安全。 视频监控…...

ASP.NET中的六大对象有哪些?以及各自的功能以及使用方式
在ASP.NET Web Forms中,并没有严格意义上的“六大对象”,但通常我们指的是与HTTP请求和响应处理紧密相关的几个内置对象。以下是这些对象及其功能、使用方式以及简单的实现源码示例: Response对象 功能:用于向客户端发送HTTP响应…...

Elastic 及阿里云 AI 搜索 Tech Day 将于 7 月 27 日在上海举办
活动主题 面向开发者的 AI 搜索相关技术分享,如 RAG、多模态搜索、向量检索等。 活动介绍 参加 Elastic 原厂与阿里云联合举办的 Generative AI 技术交流分享日。借助 The Elastic Search AI Platform, 使用开放且灵活的企业解决方案,以前所…...

基于ssm+vue医院住院管理系统源码数据库
摘 要 随着时代的发展,医疗设备愈来愈完善,医院也变成人们生活中必不可少的场所。如今,已经2021年了,虽然医院的数量和设备愈加完善,但是老龄人口也越来越多。在如此大的人口压力下,医院住院就变成了一个…...

【在排序数组中查找元素的第一个和最后一个位置】python刷题记录
R2-分治 有点easy的感觉,感觉能用哈希表 class Solution:def searchRange(self, nums: List[int], target: int) -> List[int]:nlen(nums)dictdefaultdict(list)#初始赋值哈希表,记录出现次数for num in nums:if not dict[num]:dict[num]1else:dict[…...
Pytorch基础:Tensor的squeeze和unsqueeze方法
相关阅读 Pytorch基础https://blog.csdn.net/weixin_45791458/category_12457644.html?spm1001.2014.3001.5482 在Pytorch中,squeeze和unsqueeze是Tensor的一个重要方法,同时它们也是torch模块中的一个函数,它们的语法如下所示。 Tensor.…...

PHP压缩打包,下载目录或者文件,解压zip文件
函数 /*** 压缩整个文件夹为zip文件* 本地需要绝对路径,服务器需要相对路径*/function makeZipFile($zip_path , $folder_path ) {$rootPath realpath($folder_path);$zip new ZipArchive(); // $zip->open($zip_path, ZipArchive::CREATE | ZipArchi…...

后端面试题日常练-day08 【Java基础】
题目 希望这些选择题能够帮助您进行后端面试的准备,答案在文末 Java中的静态变量和实例变量有何区别? a) 静态变量属于类,实例变量属于对象 b) 静态变量只能在静态方法中访问,实例变量只能在实例方法中访问 c) 静态变量在类加载时…...

Linux:core文件无法生成排查步骤
1、进程的RLIMIT_CORE或RLIMIT_SIZE被设置为0。使用getrlimit和ulimit检查修改。 使用ulimit -a 命令检查是否开启core文件生成限制 如果发现-c后面的结果是0,就临时添加环境变量ulimit -c unlimited,之后在启动程序观察是否有core生成,如果…...

大模型学习资源
上一篇扯了一堆废话,关于大模型,提供一下建议 说实话,大模型更新太快,以我30岁的高龄实在不适合再去研究技术。偶然发现,国内的大模型厂家在做推广的培训。比如上海人工智能实验室,阿里,百度。…...
)
约定(模拟赛2 T3)
题目描述 小A在你的帮助下成功打开了山洞中的机关,虽然他并没有找到五维空间,但他在山洞中发现了无尽的宝藏,这个消息很快就传了出去。人们为了争夺洞中的宝藏相互陷害,甚至引发了战争,世界都快要毁灭了。小A非常地难…...

Java推送xml数据进行http请求
将json转成xml数据进行推送,打印出最终推送xml的数据格式,再调整代码 直接上代码,详情请看代码注释 public void pushReceipt(JSONObject jsonObj) {try {// 创建 XML 文档Document doc createXmlDocument();// 构建 XML 结构Element rootE…...

Docker安装 OpenResty详细教程
OpenResty 是一个基于 Nginx 的高性能 Web 平台,它集成了 Lua 脚本语言,使得开发者可以在 Nginx 服务器上轻松地进行动态 Web 应用开发。OpenResty 的核心目标是通过将 Nginx 的高性能与 Lua 的灵活性结合起来,提供一个强大且高效的 Web 开发…...
)
前端位运算运用场景小知识(权限相关)
前提:此篇结合AI、公司实际业务产出,背景是公司有个业务涉及权限,用位运算来控制的,比较新奇,所以记录一下(可能自己比较low) 前端js位运算一般实际的应用场景在哪 ai回答: 整数运算与性能优化ÿ…...

【云原生】Kubernetes中的DaemonSet介绍、原理、用法及实战应用案例分析
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,…...

使用框架构建React Native应用程序的最佳实践
在React Conf上,我们更新了关于开始构建React Native应用程序的最佳工具的指导:一个React Native框架——一个包含所有必要API的工具箱,让您能够构建生产就绪的应用程序。 现在推荐使用React Native框架(如Expo)来创建…...

Godot入门 02玩家1.0版
添加Node2D节点,重命名Game 创建玩家场景,添加CharacterBody2D节点 添加AnimatedSprite2D节点 从精灵表中添加帧 选择文件 设置成8*8 图片边缘模糊改为清晰 设置加载后自动播放,动画循环 。动画速度10FPS,修改动画名称idle。 拖动…...

Docker-Compose配置zookeeper+KaFka+CMAK简单集群
1. 本地DNS解析管理 # 编辑hosts文件 sudo nano /etc/hosts # 添加以下三个主机IP 192.168.186.77 zoo1 k1 192.168.186.18 zoo2 k2 192.168.186.216 zoo3 k3注:zoo1是192.168.186.77的别名,zoo2是192.168.186.18的别名,zoo3是192.168.186.1…...

Python中,集合几种基本运算
在Python中,集合具有几种基本的集合运算,这些运算可以用于处理集合中的数据。以下是Python集合的常见运算,包括并集、交集、差集和对称差集等,并提供代码示例来显示其用法。 并集 (Union) 并集是两个集合中所有唯一元素的结合&a…...

接口测试中缓存处理策略
在接口测试中,缓存处理策略是一个关键环节,直接影响测试结果的准确性和可靠性。合理的缓存处理策略能够确保测试环境的一致性,避免因缓存数据导致的测试偏差。以下是接口测试中常见的缓存处理策略及其详细说明: 一、缓存处理的核…...

docker详细操作--未完待续
docker介绍 docker官网: Docker:加速容器应用程序开发 harbor官网:Harbor - Harbor 中文 使用docker加速器: Docker镜像极速下载服务 - 毫秒镜像 是什么 Docker 是一种开源的容器化平台,用于将应用程序及其依赖项(如库、运行时环…...

Oracle查询表空间大小
1 查询数据库中所有的表空间以及表空间所占空间的大小 SELECTtablespace_name,sum( bytes ) / 1024 / 1024 FROMdba_data_files GROUP BYtablespace_name; 2 Oracle查询表空间大小及每个表所占空间的大小 SELECTtablespace_name,file_id,file_name,round( bytes / ( 1024 …...

Keil 中设置 STM32 Flash 和 RAM 地址详解
文章目录 Keil 中设置 STM32 Flash 和 RAM 地址详解一、Flash 和 RAM 配置界面(Target 选项卡)1. IROM1(用于配置 Flash)2. IRAM1(用于配置 RAM)二、链接器设置界面(Linker 选项卡)1. 勾选“Use Memory Layout from Target Dialog”2. 查看链接器参数(如果没有勾选上面…...

HBuilderX安装(uni-app和小程序开发)
下载HBuilderX 访问官方网站:https://www.dcloud.io/hbuilderx.html 根据您的操作系统选择合适版本: Windows版(推荐下载标准版) Windows系统安装步骤 运行安装程序: 双击下载的.exe安装文件 如果出现安全提示&…...

Maven 概述、安装、配置、仓库、私服详解
目录 1、Maven 概述 1.1 Maven 的定义 1.2 Maven 解决的问题 1.3 Maven 的核心特性与优势 2、Maven 安装 2.1 下载 Maven 2.2 安装配置 Maven 2.3 测试安装 2.4 修改 Maven 本地仓库的默认路径 3、Maven 配置 3.1 配置本地仓库 3.2 配置 JDK 3.3 IDEA 配置本地 Ma…...

Yolov8 目标检测蒸馏学习记录
yolov8系列模型蒸馏基本流程,代码下载:这里本人提交了一个demo:djdll/Yolov8_Distillation: Yolov8轻量化_蒸馏代码实现 在轻量化模型设计中,**知识蒸馏(Knowledge Distillation)**被广泛应用,作为提升模型…...

【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的“no matching...“系列算法协商失败问题
【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的"no matching..."系列算法协商失败问题 摘要: 近期,在使用较新版本的OpenSSH客户端连接老旧SSH服务器时,会遇到 "no matching key exchange method found", "n…...

Scrapy-Redis分布式爬虫架构的可扩展性与容错性增强:基于微服务与容器化的解决方案
在大数据时代,海量数据的采集与处理成为企业和研究机构获取信息的关键环节。Scrapy-Redis作为一种经典的分布式爬虫架构,在处理大规模数据抓取任务时展现出强大的能力。然而,随着业务规模的不断扩大和数据抓取需求的日益复杂,传统…...
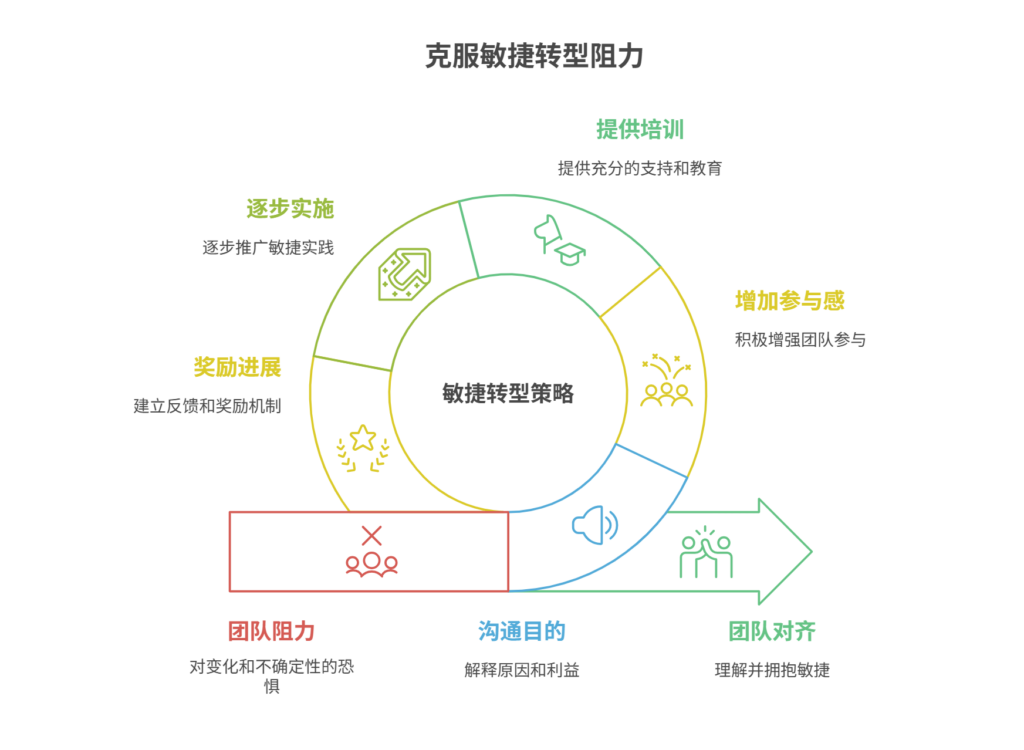
如何应对敏捷转型中的团队阻力
应对敏捷转型中的团队阻力需要明确沟通敏捷转型目的、提升团队参与感、提供充分的培训与支持、逐步推进敏捷实践、建立清晰的奖励和反馈机制。其中,明确沟通敏捷转型目的尤为关键,团队成员只有清晰理解转型背后的原因和利益,才能降低对变化的…...