Boost搜索引擎:如何建立 用户搜索内容 与 网页文件内容 之间的关系
如果想使“用户搜索内容”和“网页文件内容”之间产生联系,就应该将“用户搜索内容”和“网页文件”分为很小的单元 (这个单元就是关键词),寻找用户搜索单元是否出现在这个文档之中,如果出现就证明这个网页文件和用户搜索内容有关系,如果该搜索单元在这篇文章中出现的次数较高,也就证明:这篇文章与搜索内容有很强的相关性,这就是权值(weight)。
权值可以自己定义:比如标题出现一次对应的权值为10,内容出现一次对应的权值为5,再分别统计标题和文档内容中该搜素单元出现的次数。总权值(该搜索单元)= 标题出现的次数*10 +文档内容出现的次数*5;再将用户所有的搜索单元的总权值加在一起就是这篇文章与用户搜索内容的相关性。我们可以通过每一篇文档的权值去进行排序,给用户呈现出最想要的文档内容。
如何去存储这些网页文档内容呢?
网页文档内容有 标题,网页文档内容 url网址三个部分。所以就需要结构体将他们组织在一起。我们可以选择线性容器进行存储,因为线性容器存储的位置就可以代表这篇文章的 文档ID。
那么现在面临的问题就是,用户搜索单元(用户搜索关键词)和文档单元(文档关键词)之间如何建立联系。下面采用正排索引和倒排索引去建立它们之间的关系。
建立索引:
什么是正排索引?
正排索引就是文档ID与文档之间的关系。
| 文档ID | 文档内容 |
| 0 | 文档1 |
| 1 | 文档2 |
正排索引的建立,就是将文档ID与文档内容之间进行直接关联。如上表所示。
那问题来了,该如何关联呢?我们可以利用线性表,如数组,数组下标与文档ID正好是对应的,我们将解析出来的数据进行提取,存放到一个包含 标题(title),内容(content),url(网址信息)的结构体,再将结构体放到数组中,这样就建立好了正排索引。
什么是倒排索引?
比如用户搜索 菜鸡爱玩,分词工具将菜鸡爱玩分为 菜鸡和爱玩,分别用菜鸡和爱玩去文档中找对应的关键词。再将关键词存在的 文档ID 与 搜索关键词 之间建立关系。
| 关键词(唯一性)(关键词) | 文档ID,权重weigh(倒排索引拉链) |
| 菜鸡 | 文档2,文档1 |
| 爱玩 | 文档2 |
首先将处理好的数据进行关键词分割,用inverted_index(是map容器,map<关键词,倒排索引拉链>)统计关键词都出现在那些文档中,将关键词出现的这些文档放进倒排索引拉链中,这就行形成了关键词与文档ID之间的对应关系。从上面表可以看出,同一个文档ID是可以出现在不同的倒排索引拉链中的。
然而,刚开始建立索引的过程是有些慢的,很吃系统资源,所以关于网页文档内容太大并且服务器资源比较少的话,就会建立失败,因此前面才会下载Boost库的部分文件,也就是网络文件,而不是全部文件。虽然这个过程慢,但是带来的好处,还是不小的,因为索引建立过程是不会进行搜索的,当建立好之后,只要你有搜索内容,我就去inverted_index的map容器中进行查找,找到对应的倒排索引拉链,再返回。
当搜索关键词到来时,我就在inverted_index中利用关键词去找,如果存在这个关键词,那所有与这个关键词相关的文档我都找到了,如果不存在,那真就不存在。
这里的搜索关键词可能不止一个,搜索者会输入一段搜索语句,比如"菜鸡爱玩"可能会被分成“菜”“鸡”“菜鸡“”爱"“玩""爱玩”等。
正排索引代码:
DocInfo *BuildForwardIndex(const std::string &line){//1. 解析line,字符串切分//line -> 3 string, title, content, urlstd::vector<std::string> results;const std::string sep = "\3"; //行内分隔符ns_util::StringUtil::Split(line, &results, sep);//ns_util::StringUtil::CutString(line, &results, sep);if(results.size() != 3){return nullptr;}//2. 字符串进行填充到DocIinfoDocInfo doc;doc.title = results[0]; //titledoc.content = results[1]; //contentdoc.url = results[2]; ///urldoc.doc_id = forward_index.size(); //先进行保存id,在插入,对应的id就是当前doc在vector中的下标!//3. 插入到正排索引的vectorforward_index.push_back(std::move(doc)); //doc,html文件内容return &forward_index.back();}正排索引建立好之后,将构建好的结构体返回回去,交给倒排索引进行构建倒排索引拉链。
因为倒排索引的构建需要文档ID,文档标题和文档内容去进行关键词分割,还有权值的计算。
注意:这块不太理解就向后继续看,后面整体的构建索引会告诉你为什么这样做。
获取正排索引:
//根据doc_id找到找到文档内容DocInfo *GetForwardIndex(uint64_t doc_id){if(doc_id >= forward_index.size()){std::cerr << "doc_id out range, error!" << std::endl;return nullptr;}return &forward_index[doc_id];因为正排索引被构建了,所以直接利用文档ID在正排索引拉链(存放文档的结构体数组)中进行查找就可以了。
什么是权值?
权值决定这篇文档与用户搜索内容之间是否存在关系以及体现出它们之间相关性的强弱,因为每篇文章关于一个话题的侧重点不一样,所以我们就用权值的大小来区分是否是用户最想要的,将文档与搜索关键词之间的关系用关键词出现在标题和文档内容中的次数 和自定义权值大小 进行相关计算。
比如标题出现一次对应的权值为10,内容出现一次对应的权值为5,再分别统计标题和文档内容中该搜素单元出现的次数。总权值(该搜索单元)= 标题出现的次数*10 +文档内容出现的次数*5;再将用户所有的搜索单元的总权值加在一起就是这篇文章与用户搜索内容的相关性。我们可以通过每一篇文档的权值去进行排序,给用户呈现出最想要的文档内容。
你认为标题与搜索关键词的相关性大,就将标题的权值设置高点,同理,文档内容也是一样的。
倒排索引代码:
bool BuildInvertedIndex(const DocInfo &doc){//DocInfo{title, content, url, doc_id}//word -> 倒排拉链struct word_cnt{int title_cnt;int content_cnt;word_cnt():title_cnt(0), content_cnt(0){}};std::unordered_map<std::string, word_cnt> word_map; //用来暂存词频的映射表//对标题进行分词std::vector<std::string> title_words;ns_util::JiebaUtil::CutString(doc.title, &title_words);//if(doc.doc_id == 1572){// for(auto &s : title_words){// std::cout << "title: " << s << std::endl;// }//}//对标题进行词频统计for(std::string s : title_words){boost::to_lower(s); //需要统一转化成为小写word_map[s].title_cnt++; //如果存在就获取,如果不存在就新建}//对文档内容进行分词std::vector<std::string> content_words;ns_util::JiebaUtil::CutString(doc.content, &content_words);//if(doc.doc_id == 1572){// for(auto &s : content_words){// std::cout << "content: " << s << std::endl;// }//}//对内容进行词频统计for(std::string s : content_words){boost::to_lower(s);word_map[s].content_cnt++;}#define X 10
#define Y 1//Hello,hello,HELLOfor(auto &word_pair : word_map){InvertedElem item;item.doc_id = doc.doc_id;item.word = word_pair.first;item.weight = X*word_pair.second.title_cnt + Y*word_pair.second.content_cnt; //相关性InvertedList &inverted_list = inverted_index[word_pair.first];inverted_list.push_back(std::move(item));}return true;}重点代码讲解:
1 —— InvertedList &inverted_list = inverted_index[word_pair.first];
2 —— inverted_list.push_back(std::move(item));倒排索引拉链inverted_index是一个map<关键词,倒排索引拉链>,上面代码第一条就是将关键词对应的倒排索引拉链获取到,再将新的InvertedElem结构体插到倒排索引拉链中。这两条语句是可以合并的,看起来就会有些复杂。
经过上述操作于是就成功建立了的关键词和文档ID之间的关系,也就是说,我输入一段关键词,用分词工具将关键词进行分离,用分离的关键词,在文档(标题,文档内容也进行了分词)中进行查找,因为使用了同一套分词工具,所以不会出现,文档中有该关键词,而搜不到的情况。
获取倒排索引拉链:
//根据关键字string,获得倒排拉链InvertedList *GetInvertedList(const std::string &word){auto iter = inverted_index.find(word);if(iter == inverted_index.end()){std::cerr << word << " have no InvertedList" << std::endl;return nullptr;}return &(iter->second);}在倒排索引构建好之后,所有的倒排索引拉链都存放在inverted_index的map容器中,只需要提供关键词进行查找即可,将找到的倒排索引拉链返回出去。
构建索引(整合正排索引和倒排索引的构建):
//根据去标签,格式化之后的文档,构建正排和倒排索引//data/raw_html/raw.txtbool BuildIndex(const std::string &input) //parse处理完毕的数据交给我{std::ifstream in(input, std::ios::in | std::ios::binary);if(!in.is_open()){std::cerr << "sorry, " << input << " open error" << std::endl;return false;}std::string line;int count = 0;while(std::getline(in, line)){DocInfo * doc = BuildForwardIndex(line);if(nullptr == doc){std::cerr << "build " << line << " error" << std::endl; //for deubgcontinue;}BuildInvertedIndex(*doc);count++;//if(count % 50 == 0){//std::cout <<"当前已经建立的索引文档: " << count <<std::endl;LOG(NORMAL, "当前的已经建立的索引文档: " + std::to_string(count));//}}return true;}首先将处理好的网页文件读取取进来,利用std::ifstream类对文件进行相关操作,因为是以'\n'为间隔,将处理好的网页文件进行了分离,所以就采用getline(in,line)循环将文件中的数据读取到。
首先建立正排索引,其次再建立倒排索引,因为倒排索引的建立是基于正排索引的。
单例模式:
Index(){} //但是一定要有函数体,不能deleteIndex(const Index&) = delete;Index& operator=(const Index&) = delete;static Index* instance;static std::mutex mtx;public:~Index(){}public:static Index* GetInstance(){if(nullptr == instance){mtx.lock();if(nullptr == instance){instance = new Index();}mtx.unlock();}return instance;}单例模式,就是禁掉这个类的,拷贝构造和赋值重载,让这个类不能赋给别人,所有对象共用一个instance变量
因为在多线程模式下,会有很用户进行搜素,需要加把锁保证临界区资源不被破坏。
索引构建模块的整体代码Index.hpp:
#pragma once#include <iostream>
#include <string>
#include <vector>
#include <fstream>
#include <unordered_map>
#include <mutex>
#include "util.hpp"
#include "log.hpp"namespace ns_index{struct DocInfo{std::string title; //文档的标题std::string content; //文档对应的去标签之后的内容std::string url; //官网文档urluint64_t doc_id; //文档的ID,暂时先不做过多理解};struct InvertedElem{uint64_t doc_id;std::string word;int weight;InvertedElem():weight(0){}};//倒排拉链typedef std::vector<InvertedElem> InvertedList;class Index{private://正排索引的数据结构用数组,数组的下标天然是文档的IDstd::vector<DocInfo> forward_index; //正排索引//倒排索引一定是一个关键字和一组(个)InvertedElem对应[关键字和倒排拉链的映射关系]std::unordered_map<std::string, InvertedList> inverted_index;private:Index(){} //但是一定要有函数体,不能deleteIndex(const Index&) = delete;Index& operator=(const Index&) = delete;static Index* instance;static std::mutex mtx;public:~Index(){}public:static Index* GetInstance(){if(nullptr == instance){mtx.lock();if(nullptr == instance){instance = new Index();}mtx.unlock();}return instance;}//根据doc_id找到找到文档内容DocInfo *GetForwardIndex(uint64_t doc_id){if(doc_id >= forward_index.size()){std::cerr << "doc_id out range, error!" << std::endl;return nullptr;}return &forward_index[doc_id];}//根据关键字string,获得倒排拉链InvertedList *GetInvertedList(const std::string &word){auto iter = inverted_index.find(word);if(iter == inverted_index.end()){std::cerr << word << " have no InvertedList" << std::endl;return nullptr;}return &(iter->second);}//根据去标签,格式化之后的文档,构建正排和倒排索引//data/raw_html/raw.txtbool BuildIndex(const std::string &input) //parse处理完毕的数据交给我{std::ifstream in(input, std::ios::in | std::ios::binary);if(!in.is_open()){std::cerr << "sorry, " << input << " open error" << std::endl;return false;}std::string line;int count = 0;while(std::getline(in, line)){DocInfo * doc = BuildForwardIndex(line);if(nullptr == doc){std::cerr << "build " << line << " error" << std::endl; //for deubgcontinue;}BuildInvertedIndex(*doc);count++;//if(count % 50 == 0){//std::cout <<"当前已经建立的索引文档: " << count <<std::endl;LOG(NORMAL, "当前的已经建立的索引文档: " + std::to_string(count));//}}return true;}private:DocInfo *BuildForwardIndex(const std::string &line){//1. 解析line,字符串切分//line -> 3 string, title, content, urlstd::vector<std::string> results;const std::string sep = "\3"; //行内分隔符ns_util::StringUtil::Split(line, &results, sep);//ns_util::StringUtil::CutString(line, &results, sep);if(results.size() != 3){return nullptr;}//2. 字符串进行填充到DocIinfoDocInfo doc;doc.title = results[0]; //titledoc.content = results[1]; //contentdoc.url = results[2]; ///urldoc.doc_id = forward_index.size(); //先进行保存id,在插入,对应的id就是当前doc在vector中的下标!//3. 插入到正排索引的vectorforward_index.push_back(std::move(doc)); //doc,html文件内容return &forward_index.back();}bool BuildInvertedIndex(const DocInfo &doc){//DocInfo{title, content, url, doc_id}//word -> 倒排拉链struct word_cnt{int title_cnt;int content_cnt;word_cnt():title_cnt(0), content_cnt(0){}};std::unordered_map<std::string, word_cnt> word_map; //用来暂存词频的映射表//对标题进行分词std::vector<std::string> title_words;ns_util::JiebaUtil::CutString(doc.title, &title_words);//if(doc.doc_id == 1572){// for(auto &s : title_words){// std::cout << "title: " << s << std::endl;// }//}//对标题进行词频统计for(std::string s : title_words){boost::to_lower(s); //需要统一转化成为小写word_map[s].title_cnt++; //如果存在就获取,如果不存在就新建}//对文档内容进行分词std::vector<std::string> content_words;ns_util::JiebaUtil::CutString(doc.content, &content_words);//if(doc.doc_id == 1572){// for(auto &s : content_words){// std::cout << "content: " << s << std::endl;// }//}//对内容进行词频统计for(std::string s : content_words){boost::to_lower(s);word_map[s].content_cnt++;}#define X 10
#define Y 1//Hello,hello,HELLOfor(auto &word_pair : word_map){InvertedElem item;item.doc_id = doc.doc_id;item.word = word_pair.first;item.weight = X*word_pair.second.title_cnt + Y*word_pair.second.content_cnt; //相关性InvertedList &inverted_list = inverted_index[word_pair.first];inverted_list.push_back(std::move(item));}return true;}};Index* Index::instance = nullptr;std::mutex Index::mtx;
}
排序语句是一条lambda表达式,你也可以写个仿函数传递给sort系统函数。
//4.[构建]:根据查找出来的结果,构建json串 -- jsoncpp --通过jsoncpp完成序列化&&反序列化Json::Value root;for(auto &item : inverted_list_all){ns_index::DocInfo * doc = index->GetForwardIndex(item.doc_id);if(nullptr == doc){continue;}Json::Value elem;elem["title"] = doc->title;elem["desc"] = GetDesc(doc->content, item.words[0]); //content是文档的去标签的结果,但是不是我们想要的,我们要的是一部分 TODOelem["url"] = doc->url;//for deubg, for deleteelem["id"] = (int)item.doc_id;elem["weight"] = item.weight; //int->stringroot.append(elem);}//Json::StyledWriter writer;Json::FastWriter writer;*json_string = writer.write(root);相关文章:

Boost搜索引擎:如何建立 用户搜索内容 与 网页文件内容 之间的关系
如果想使“用户搜索内容”和“网页文件内容”之间产生联系,就应该将“用户搜索内容”和“网页文件”分为很小的单元 (这个单元就是关键词),寻找用户搜索单元是否出现在这个文档之中,如果出现就证明这个网页文件和用户搜…...
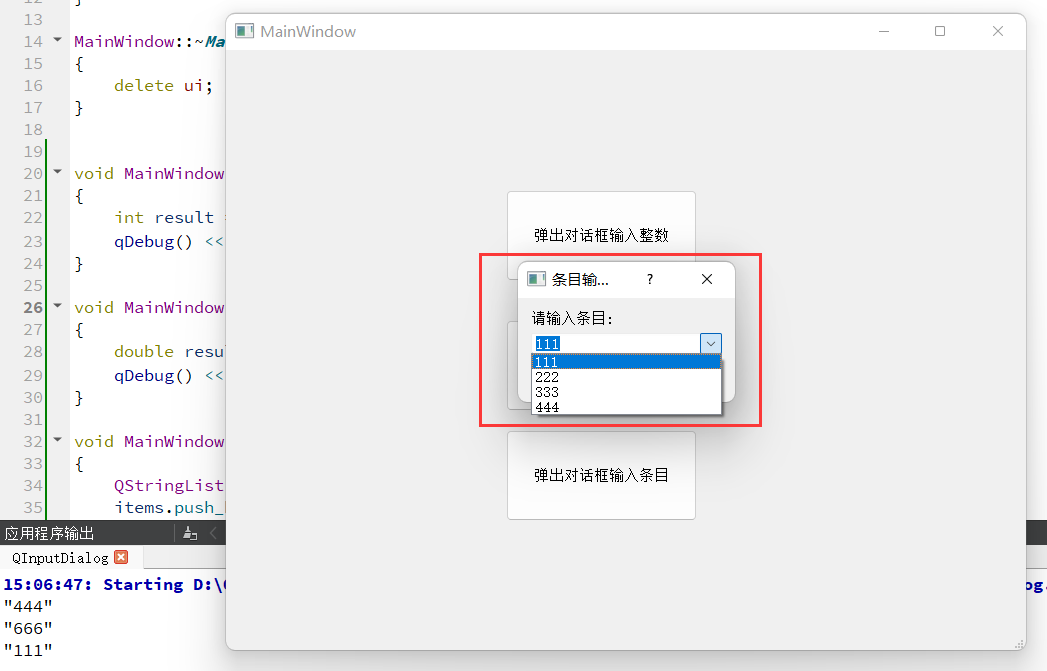
【QT】QT 窗口(菜单栏、工具栏、状态栏、浮动窗口、对话框)
Qt 窗口是通过 QMainWindow类来实现的。 QMainWindow 是一个为用户提供主窗口程序的类,继承自 QWidget 类,并且提供了⼀个预定义的布局。QMainWindow 包含一个菜单栏(Menu Bar)、多个工具栏(Tool Bars)、…...

Golang | Leetcode Golang题解之第283题移动零
题目: 题解: func moveZeroes(nums []int) {left, right, n : 0, 0, len(nums)for right < n {if nums[right] ! 0 {nums[left], nums[right] nums[right], nums[left]left}right} }...
ubuntu22.04 安装 NVIDIA 驱动以及CUDA
目录 1、事前问题解决 2、安装 nvidia 驱动 3、卸载 nvidia 驱动方法 4、安装 CUDA 5、安装 Anaconda 6、安装 PyTorch 1、事前问题解决 在安装完ubuntu之后,如果进入ubuntu出现黑屏情况,一般就是nvidia驱动与linux自带的不兼容,可以通…...
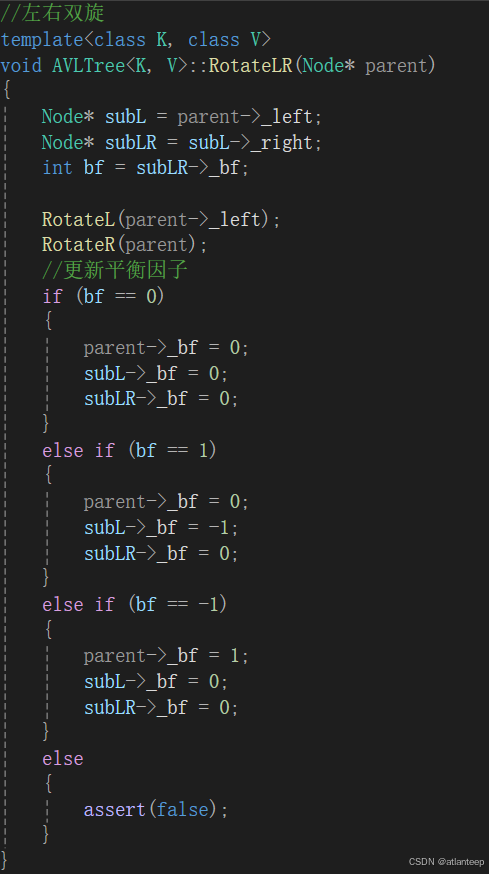
数据结构·AVL树
1. AVL树的概念 二叉搜索树虽可以缩短查找的效率,但如果存数据时接近有序,二叉搜索将退化为单支树,此时查找元素效率相当于在顺序表中查找,效率低下。因此两位俄罗斯数学家 G.M.Adelson-Velskii 和E.M.Landis 在1962年发明了一种解…...
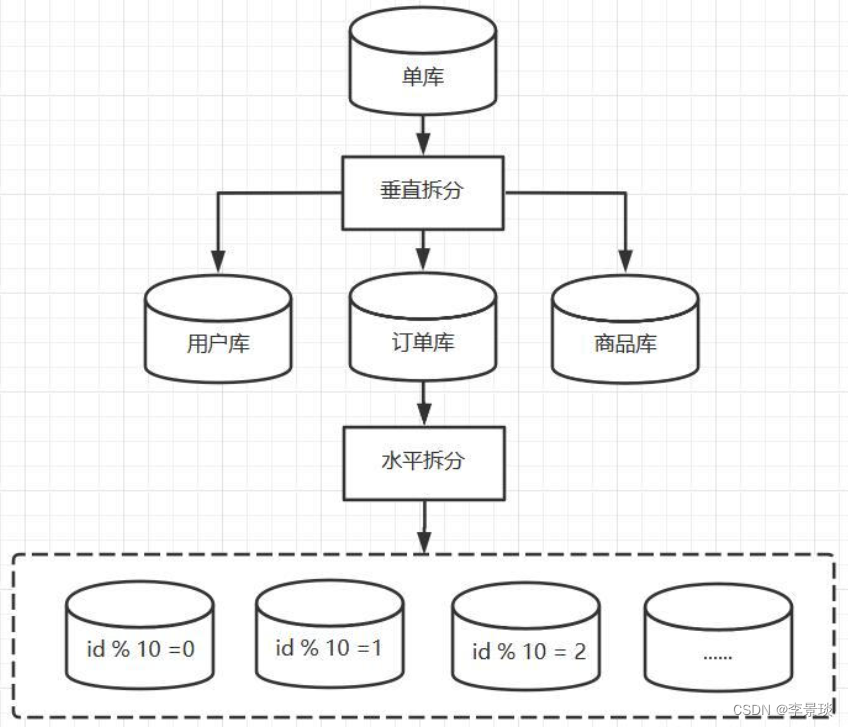
记一次Mycat分库分表实践
接了个活,又搞分库分表。 一、分库分表 在系统的研发过程中,随着数据量的不断增长,单库单表已无法满足数据的存储需求,此时就需要对数据库进行分库分表操作。 分库分表是随着业务的不断发展,单库单表无法承载整体的数据存储时,采取的一种将整体数据分散存储到不同服务…...
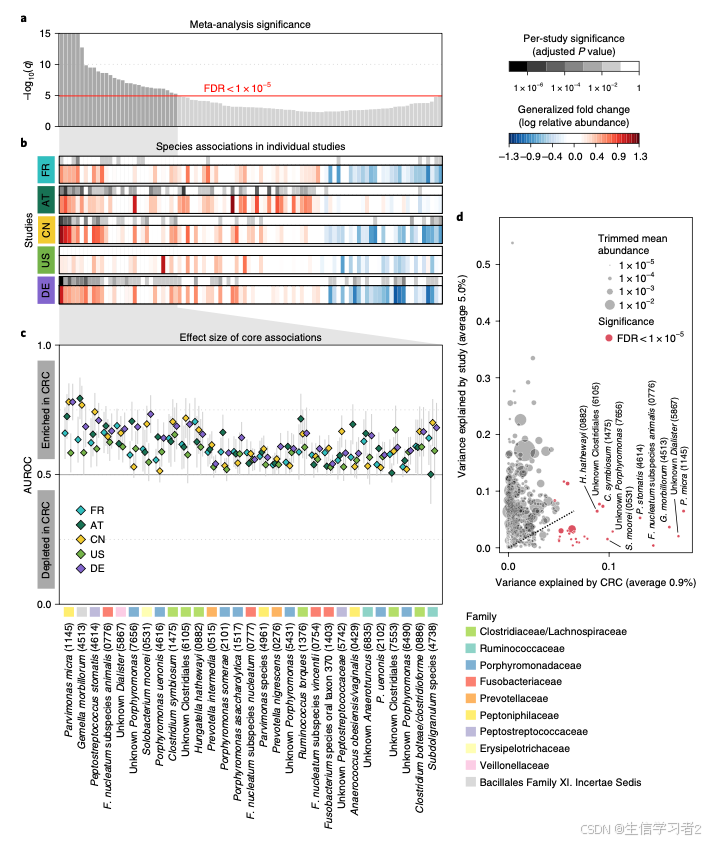
数据分析:微生物数据的荟萃分析框架
介绍 Meta-analysis of fecal metagenomes reveals global microbial signatures that are specific for colorectal cancer提供了一种荟萃分析的框架,它主要基于常用的Wilcoxon rank-sum test和Blocked Wilcoxon rank-sum test 方法计算显著性,再使用分…...
Django—admin后台管理
Django官网 https://www.djangoproject.com/ 如果已经有了Django跳过这步 安装Django: 如果你还没有安装Django,可以通过Python的包管理器pip来安装: pip install django 创建项目: 使用Django创建一个新的项目: …...
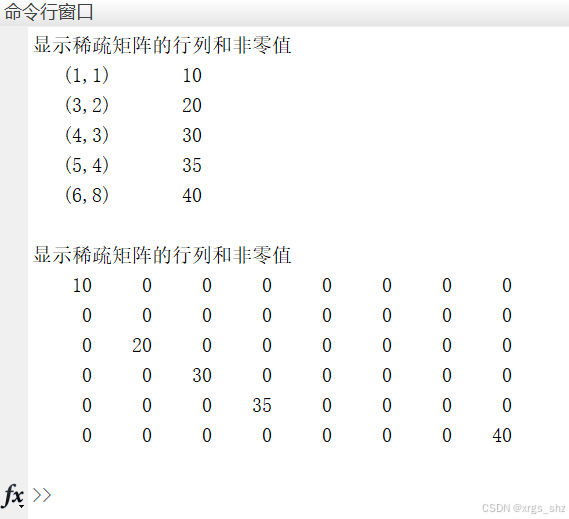
数字图像处理中的常用特殊矩阵及MATLAB应用
一、前言 Matlab的名称来源于“矩阵实验室(Matrix Laboratory)”,其对矩阵的操作具有先天性的优势(特别是相对于C语言的数组来说)。在数字图像处理中,为了提高编程效率,我们可以使用多种方式来创…...
精彩案例剖析一)
vue侦听器(Watch)精彩案例剖析一
目录 watch介绍 监视普通数据类型 监视对象类型 watch介绍 在 Vue 中,watch主要用于监视数据的变化,并执行相应操作。一旦被监视的属性发生变化,回调函数将自动被触发。当在 Vue 中使用watch来响应数据变化时,首先要清楚,watch本质上是一个对象,且必须以对象的…...

HTTP 协议浅析
HTTP(HyperText Transfer Protocol,超文本传输协议)是应用层最重要的协议之一。它定义了客户端和服务器之间的数据传输方式,并成为万维网(World Wide Web)的基石。本文将深入解析 HTTP 协议的基础知识、工作…...
VsCode | 让空文件夹始终展开不折叠
文章目录 1 问题引入2 解决办法3 效果展示 1 问题引入 可能很多小伙伴更新VsCode或者下载新版本时候 ,创建的文件 会出现xxx文件夹/xxx文件夹,看着很不舒服,所以该如何展开所有空文件夹呢? 2 解决办法 找到VsCode的设置 &…...

Centos7_Minimal安装Cannot find a valid baseurl for repo: base/7/x86_6
问题 运行yum报此问题 就是没网 解决方法 修改网络信息配置文件,打开配置文件,输入命令: vi /etc/sysconfig/network-scripts/ifcfg-网卡名字把ONBOOTno,改为ONBOOTyes 重启网卡 /etc/init.d/network restart 网路通了...
Spark_Oracle_II_Spark高效处理Oracle时间数据:通过JDBC桥接大数据与数据库的分析之旅
接前文背景, 当需要从关系型数据库(如Oracle)中读取数据时,Spark提供了JDBC连接功能,允许我们轻松地将数据从Oracle等数据库导入到Spark DataFrame中。然而,在处理时间字段时,可能会遇到一些挑战…...
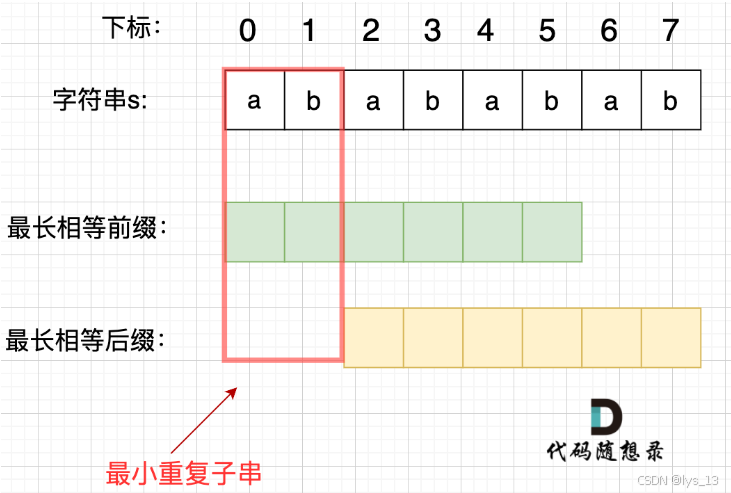
力扣 459重复的子字符串
思路: KMP算法的核心是求next数组 next数组代表的是当前字符串最大前后缀的长度 而求重复的子字符串就是求字符串的最大前缀与最大后缀之间的子字符串 如果这个子字符串是字符串长度的约数,则true /** lc appleetcode.cn id459 langcpp** [459] 重复…...

MyBatis XML配置文件
目录 一、引入依赖 二、配置数据库的连接信息 三、实现持久层代码 3.1 添加mapper接口 3.2 添加UserInfoXMLMapper.xml 3.3 增删改查操作 3.3.1 增(insert) 3.3.2 删(delete) 3.3.3 改(update) 3.3.4 查(select) 本篇内容仍然衔接上篇内容,使用的代码及案…...

读写RDS或RData等不同格式的文件,包括CSV和TXT、Excel的常见文件格式,和SPSS、SAS、Stata、Minitab等统计软件的数据文件
R语言是数据分析和科学计算的强大工具,其丰富的函数和包使得处理各种数据格式变得相对简单。在本文中,我们将详细介绍如何使用R语言的函数命令读取和写入不同格式的文件,包括RDS或RData格式文件、常见的文本文件(如CSV和TXT)、Excel文件,和和SPSS、SAS、Stata、Minitab等…...
视频支持格式)
Android 支持的媒体格式,(二)视频支持格式
视频支持格式: 格式编码器解码器具体说明文件类型 容器格式H.263是是对 H.263 的支持在 Android 7.0 及更高版本中并非必需• 3GPP (.3gp) • MPEG-4 (.mp4) • Matroska (.mkv)H.264 AVC Baseline Profile (BP)Android 3.0 及以上版本是 • 3GPP (.3gp) • MPEG-4…...

密码学原理精解【8】
文章目录 概率分布哈夫曼编码实现julia官方文档建议的变量命名规范:julia源码 熵一、信息熵的定义二、信息量的概念三、信息熵的计算步骤四、信息熵的性质五、应用举例 哈夫曼编码(Huffman Coding)基本原理编码过程特点应用具体过程1. 排序概…...
2024年钉钉杯大数据竞赛A题超详细解题思路+python代码手把手保姆级运行讲解视频+问题一代码分享
初赛A:烟草营销案例数据分析 AB题综合难度不大,难度可以视作0.4个国赛,题量可以看作0.35个国赛题量。适合于国赛前队伍练手,队伍内磨合。竞赛获奖率50%,八月底出成绩,参赛人数3000队左右。本文将为大家进行…...

Ubuntu系统下交叉编译openssl
一、参考资料 OpenSSL&&libcurl库的交叉编译 - hesetone - 博客园 二、准备工作 1. 编译环境 宿主机:Ubuntu 20.04.6 LTSHost:ARM32位交叉编译器:arm-linux-gnueabihf-gcc-11.1.0 2. 设置交叉编译工具链 在交叉编译之前&#x…...

C++:std::is_convertible
C++标志库中提供is_convertible,可以测试一种类型是否可以转换为另一只类型: template <class From, class To> struct is_convertible; 使用举例: #include <iostream> #include <string>using namespace std;struct A { }; struct B : A { };int main…...

srs linux
下载编译运行 git clone https:///ossrs/srs.git ./configure --h265on make 编译完成后即可启动SRS # 启动 ./objs/srs -c conf/srs.conf # 查看日志 tail -n 30 -f ./objs/srs.log 开放端口 默认RTMP接收推流端口是1935,SRS管理页面端口是8080,可…...

Nuxt.js 中的路由配置详解
Nuxt.js 通过其内置的路由系统简化了应用的路由配置,使得开发者可以轻松地管理页面导航和 URL 结构。路由配置主要涉及页面组件的组织、动态路由的设置以及路由元信息的配置。 自动路由生成 Nuxt.js 会根据 pages 目录下的文件结构自动生成路由配置。每个文件都会对…...

数据链路层的主要功能是什么
数据链路层(OSI模型第2层)的核心功能是在相邻网络节点(如交换机、主机)间提供可靠的数据帧传输服务,主要职责包括: 🔑 核心功能详解: 帧封装与解封装 封装: 将网络层下发…...

CocosCreator 之 JavaScript/TypeScript和Java的相互交互
引擎版本: 3.8.1 语言: JavaScript/TypeScript、C、Java 环境:Window 参考:Java原生反射机制 您好,我是鹤九日! 回顾 在上篇文章中:CocosCreator Android项目接入UnityAds 广告SDK。 我们简单讲…...

Robots.txt 文件
什么是robots.txt? robots.txt 是一个位于网站根目录下的文本文件(如:https://example.com/robots.txt),它用于指导网络爬虫(如搜索引擎的蜘蛛程序)如何抓取该网站的内容。这个文件遵循 Robots…...

Python基于历史模拟方法实现投资组合风险管理的VaR与ES模型项目实战
说明:这是一个机器学习实战项目(附带数据代码文档),如需数据代码文档可以直接到文章最后关注获取。 1.项目背景 在金融市场日益复杂和波动加剧的背景下,风险管理成为金融机构和个人投资者关注的核心议题之一。VaR&…...

计算机基础知识解析:从应用到架构的全面拆解
目录 前言 1、 计算机的应用领域:无处不在的数字助手 2、 计算机的进化史:从算盘到量子计算 3、计算机的分类:不止 “台式机和笔记本” 4、计算机的组件:硬件与软件的协同 4.1 硬件:五大核心部件 4.2 软件&#…...
)
【LeetCode】3309. 连接二进制表示可形成的最大数值(递归|回溯|位运算)
LeetCode 3309. 连接二进制表示可形成的最大数值(中等) 题目描述解题思路Java代码 题目描述 题目链接:LeetCode 3309. 连接二进制表示可形成的最大数值(中等) 给你一个长度为 3 的整数数组 nums。 现以某种顺序 连接…...