一文解决 | Linux(Ubuntn)系统安装 | 硬盘挂载 | 用户创建 | 生信分析配置
原文链接:一文解决 | Linux(Ubuntn)系统安装 | 硬盘挂载 | 用户创建 | 生信分析配置
本期教程
获得本期教程文本文档,在后台回复:20240724。请大家看清楚回复关键词,每天都有很多人回复错误关键词,我这边没时间和精力一一回复。
往期教程部分内容





写在前面
昨天(2024年7月23日)我们分享了学生及科研人员电脑配置推荐 | 笔记本+外置显卡配置,性能足够支持完成你博士论文文本内容,那么今天我们就分享一文解决 | Linux(Ubuntn)系统安装 | 硬盘挂载 | 用户创建 | 生信分析配置的教程,我们使用一文来解决大家在做生信时遇到安装系统、配置环境的问题。
在此文中,我们尽快可能给出一套全网最全的教程。目标是解决新手小白同学查资源的困惑和难题。
但是,每个童鞋遇到的问题不一样,此教程也不可能把你遇到的每个问题都归纳在其中。
我们也希望,大家可以在留言区进行补充,最终形成一个完整的教程文档。
1. 制作启动盘
对于制作启动盘的工具更多,我们这里只是进行介绍我们本次安装时所使用到的工具,其余的工具,大家可以结合自己实际情况而定。
1.1 使用rufus制作启动盘
软件下载网址:https://github.com/pbatard/rufus/releases/download/v4.5/rufus-4.5.exe(点击下载)
http://rufus.ie/downloads
1.2. 点击打开rufus-4.5.exe
1.3. Ubuntu系统的下载
下载网址:
https://cn.ubuntu.com

1.3.1 Ubuntu桌面版下载
下载链接:https://releases.ubuntu.com/24.04/ubuntu-24.04-desktop-amd64.iso
1.3.2 Ubuntu服务器版本下载
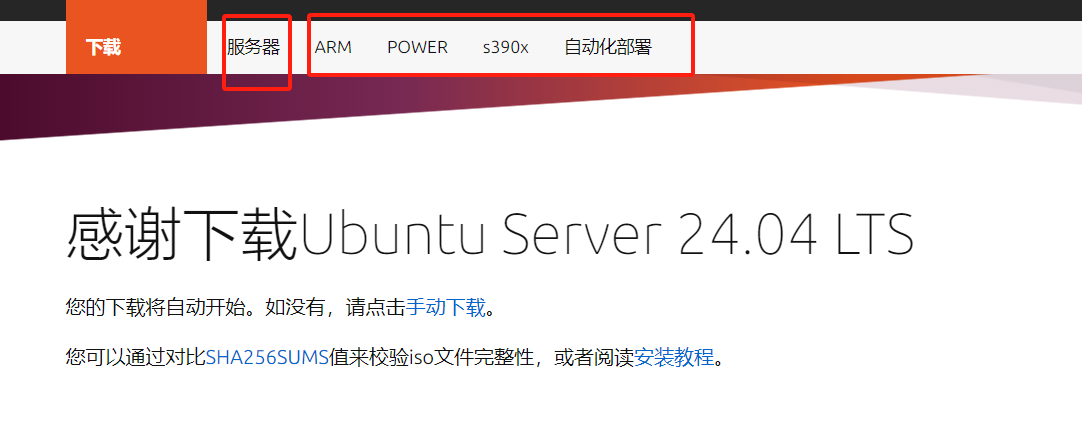
https://cn.ubuntu.com/download/server/thank-you?version=24.04&architecture=amd64
下载对应的版本即可
ubuntu官方也给对应的安装教程,科研进行参考。
https://ubuntu.com/tutorials/install-ubuntu-server#3-boot-from-install-medi
直接点击链接:https://ubuntu.com/tutorials/install-ubuntu-server#3-boot-from-install-media
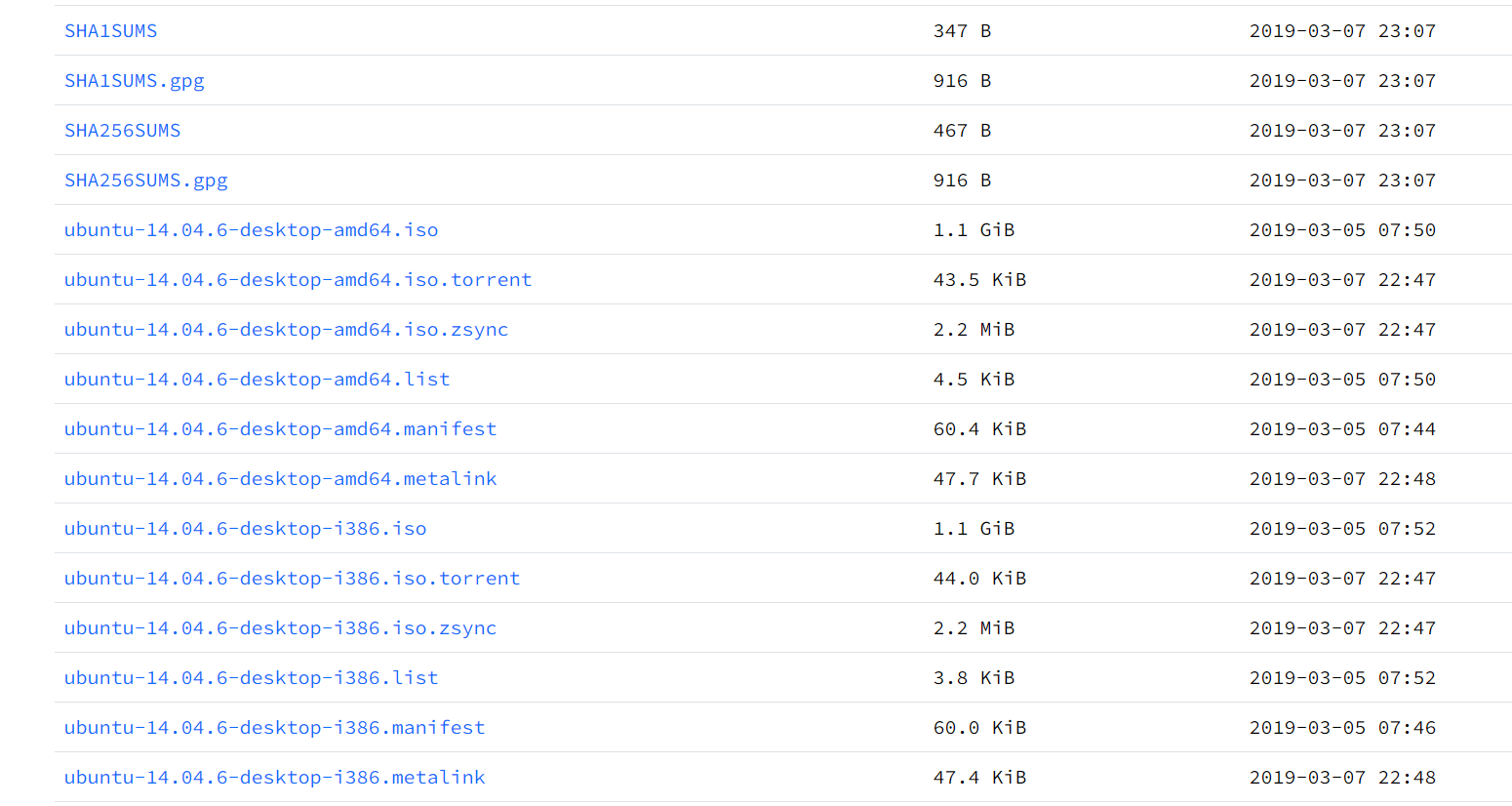
1.3.3 Ubuntu系统下载
若是在官网下载速度很慢,可以在清华源下载,下载https://mirrors.tuna.tsinghua.edu.cn/ubuntu-releases/14.04/ubuntu-14.04.6-desktop-amd64.iso
# 网址:
https://mirrors.tuna.tsinghua.edu.cn/ubuntu-releases/14.04/
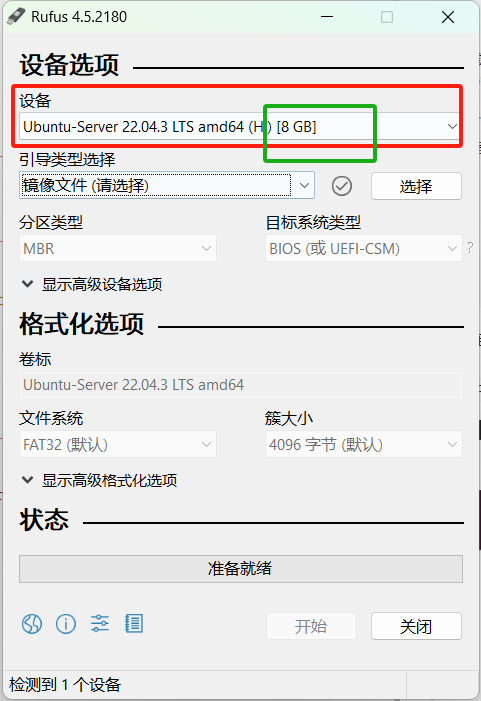
1.4. 使用rufus制作启动盘
需要使用8G的U盘进行制作。
1.4.1 插上U盘,打开软件
1.4.2 选择系统镜像
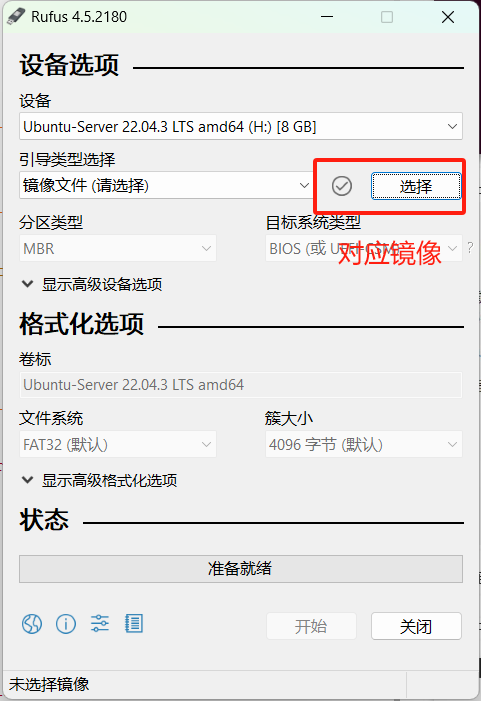
1.4.3 进行制作
以上操作完成后,软件中其他设置默认即可。
点击“开始”
1.4.4 完成后,文件夹中获得一下信息
2. 开始安装
进入系统BIOS进行安装,结合自己的电脑进入BIOS的快捷键,进入。我们这里不在介绍。
进入BIOS,使用直接点击使用U盘安装即可,后面等在安装结束。以及设置相关的信息,结束后,直接重启即可。
2.1 安装
过一会儿,您应该会看到如下显示在屏幕上内容。
2.2 设置语言
after the boot messages appear, a ‘Language’ menu will be displayed.
2.3 选择正确的键盘布局
默认即可
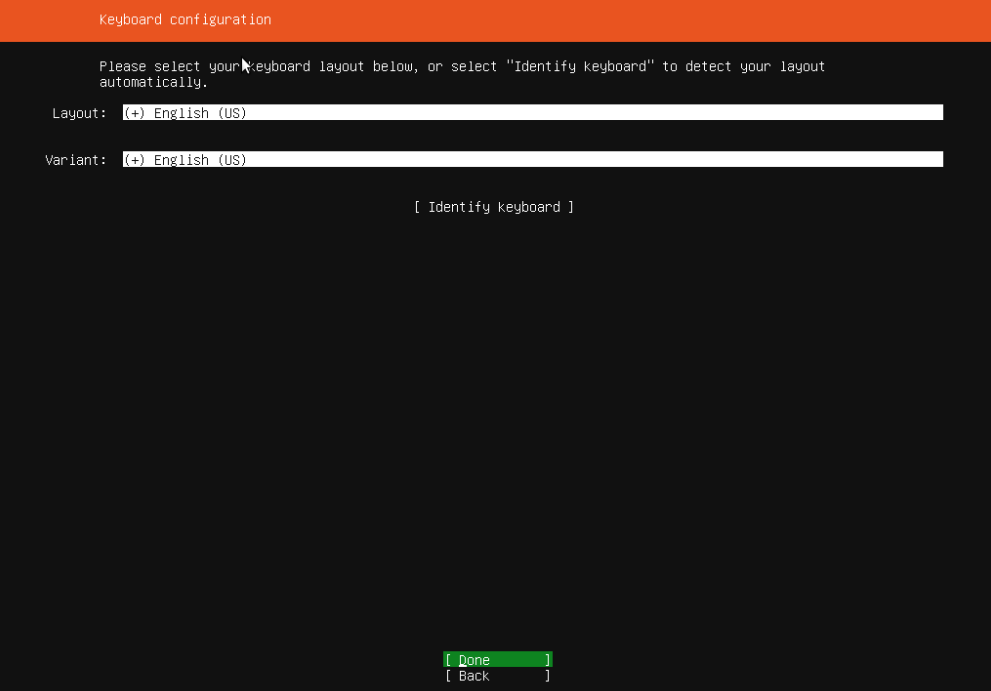
2.4 选择安装
在这里,小杜建议选择“直接安装”
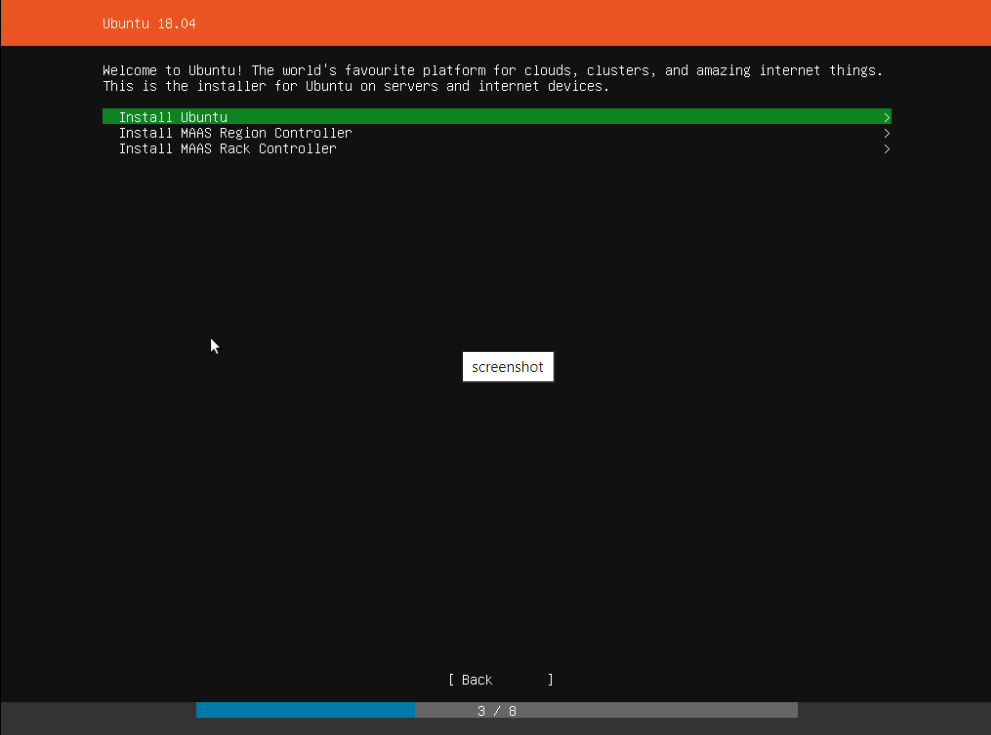
2.5 网络设置
安装程序将自动检测并尝试通过DHCP配置任何网络连接。
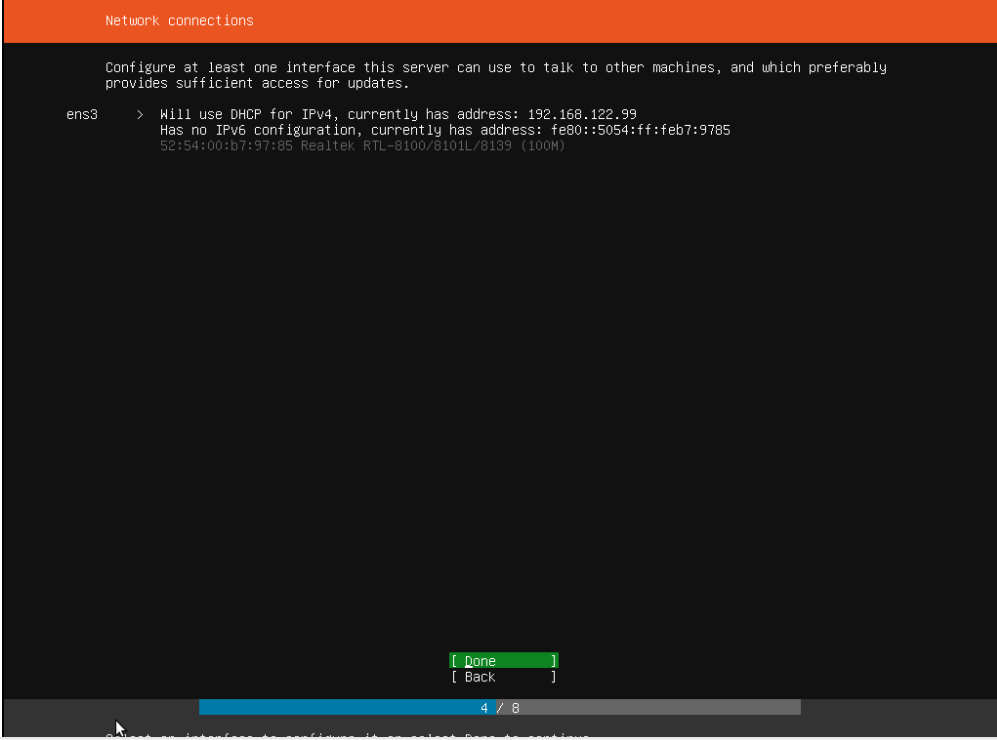
2.6 磁盘设置
我们建议使用一个空的磁盘作为系统盘,因此,直接默认相关参数即可。(以下图片不是我们安装过程中看到的图片,直接默认参数即可)
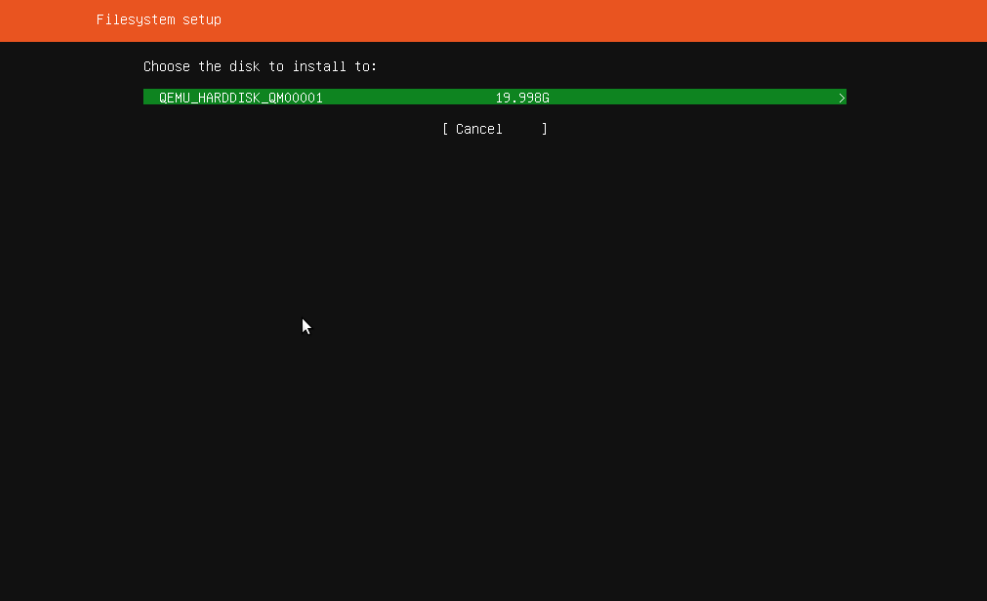
2.7 分区设置
默认参数。
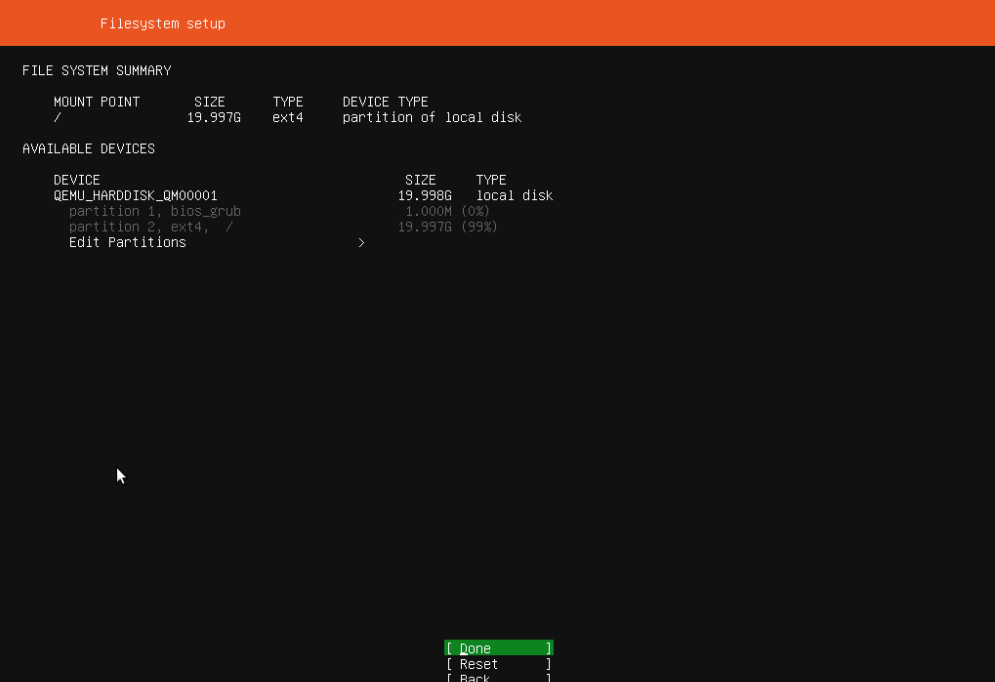
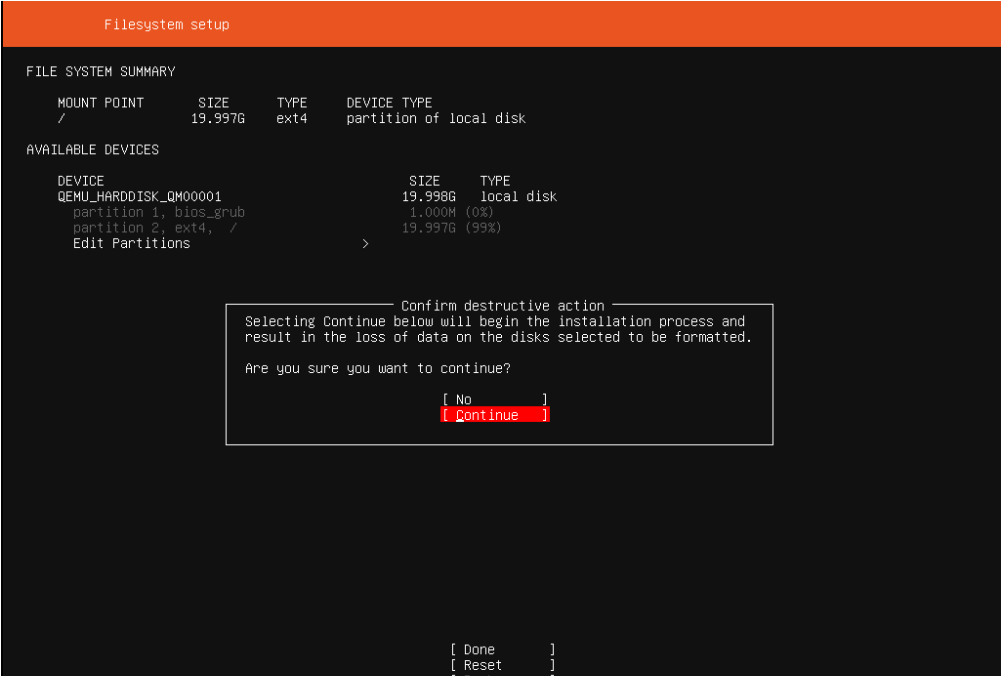
2.8 确认
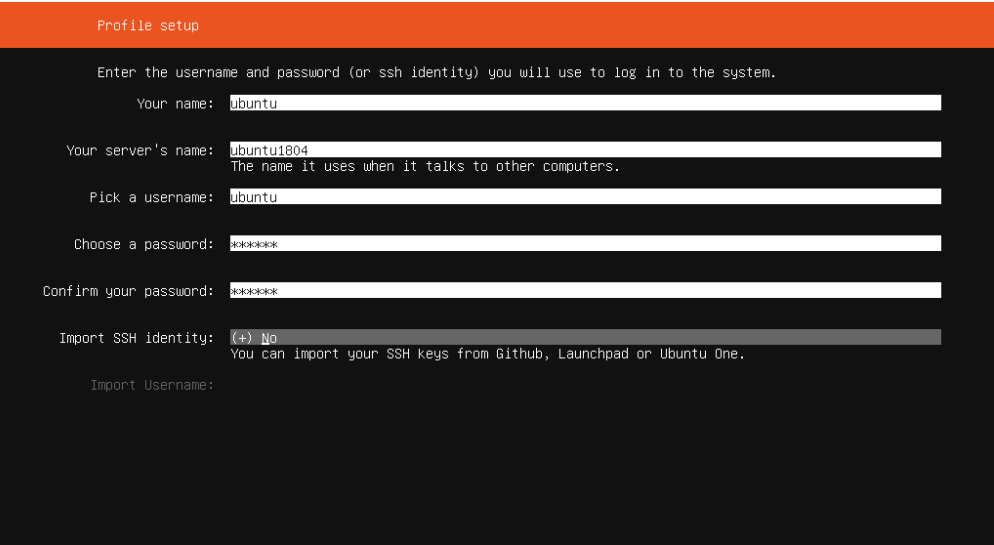
2.9 建立服务器信息
软件现在正在磁盘上安装,但是安装程序需要更多的信息。Ubuntu Server 需要至少有一个已知的系统用户和一个主机名。用户还需要一个密码。
2.10 安装软件或更新
在安装过程中,可能会设置安装软件,或更新。
我们建议在安装过程中,不选择更新选项,可能会无法下载或更新,导致安装失败。
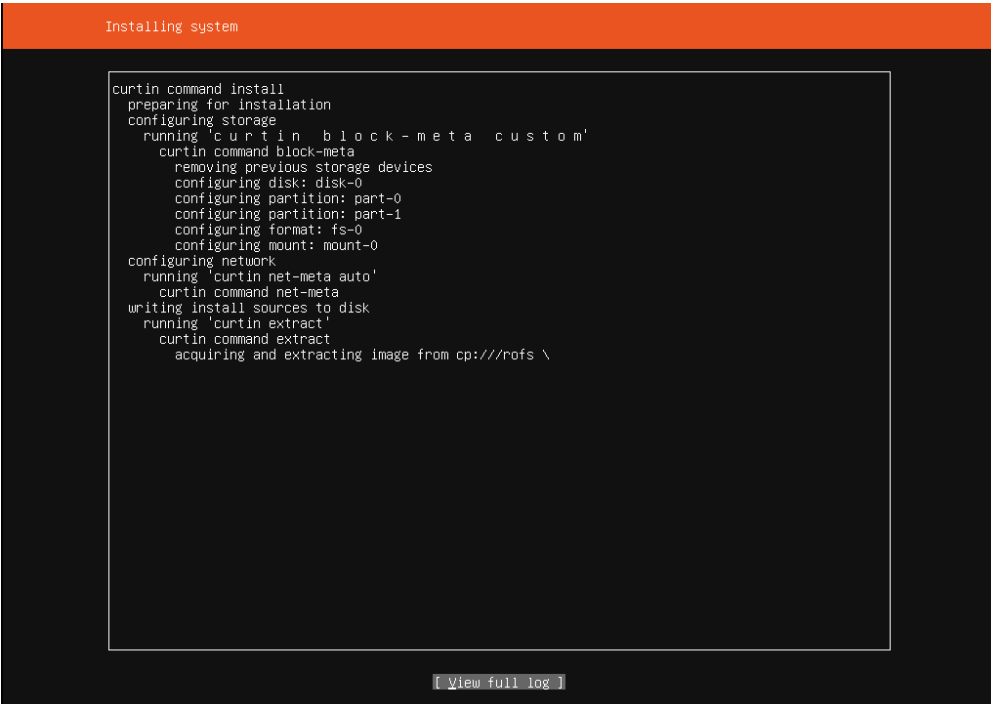
安装完成后,重启即可。到这里,Linux系统的安装就完成了,与正常的Windows系统安装一样。
3. 使用Xshell连接
3.1 安装后,我们可以直接只用局域网进行连接操作。
网址:
https://www.xshell.com/zh/xshell/
Xshell可以下载免费授权版。
https://www.xshell.com/zh/xshell-download/
点击下载:

3.2 使用局域网
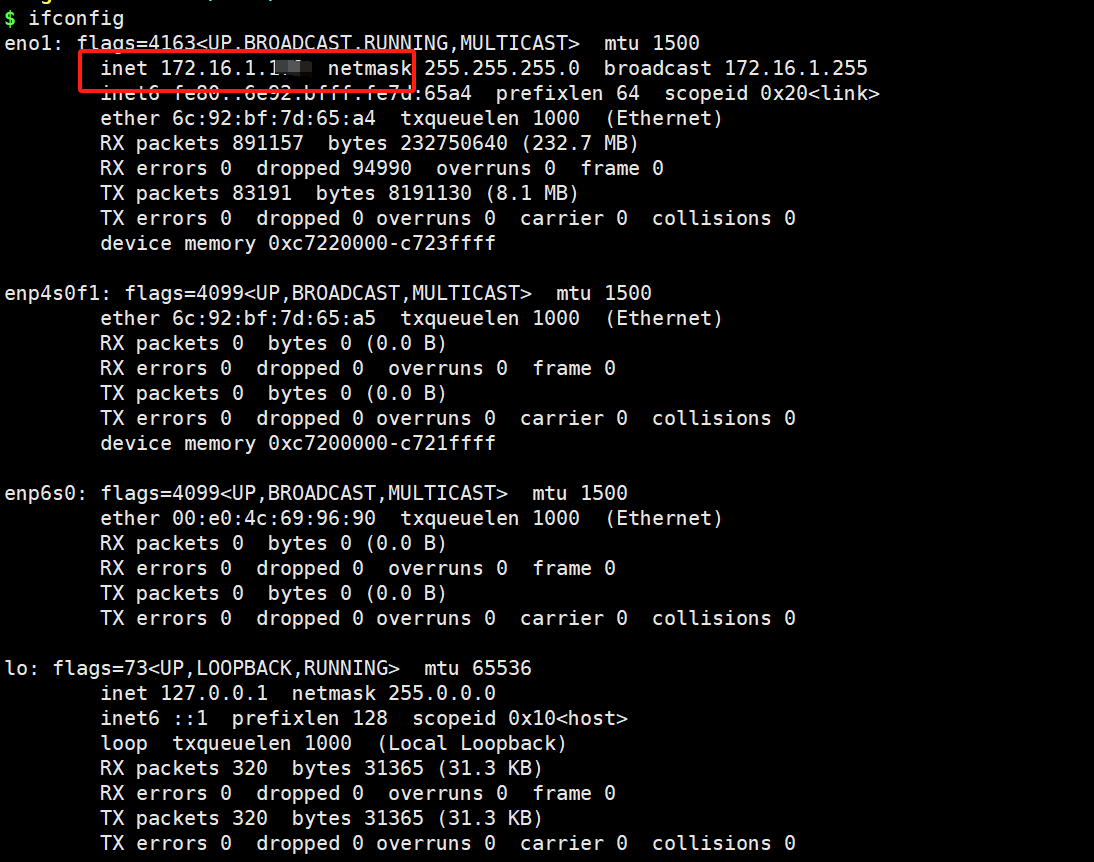
我们在安装时,会出现自动配置网络,此网段即时局域网IP。或使用ifconfig进行查看。
ifconfig
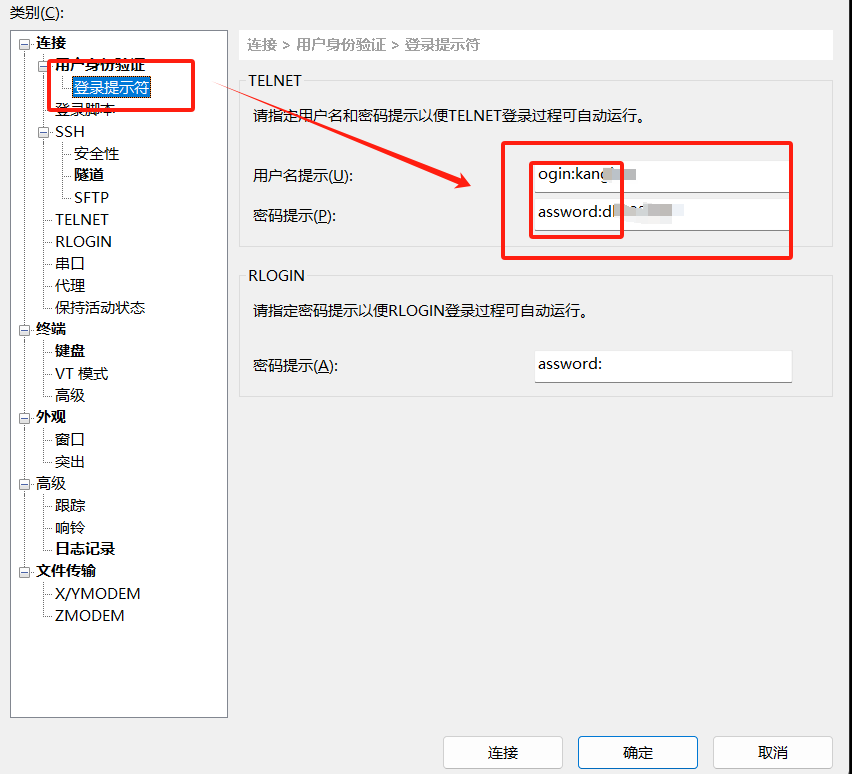
连接时,就使用我们设置的账户和密码登录即可。
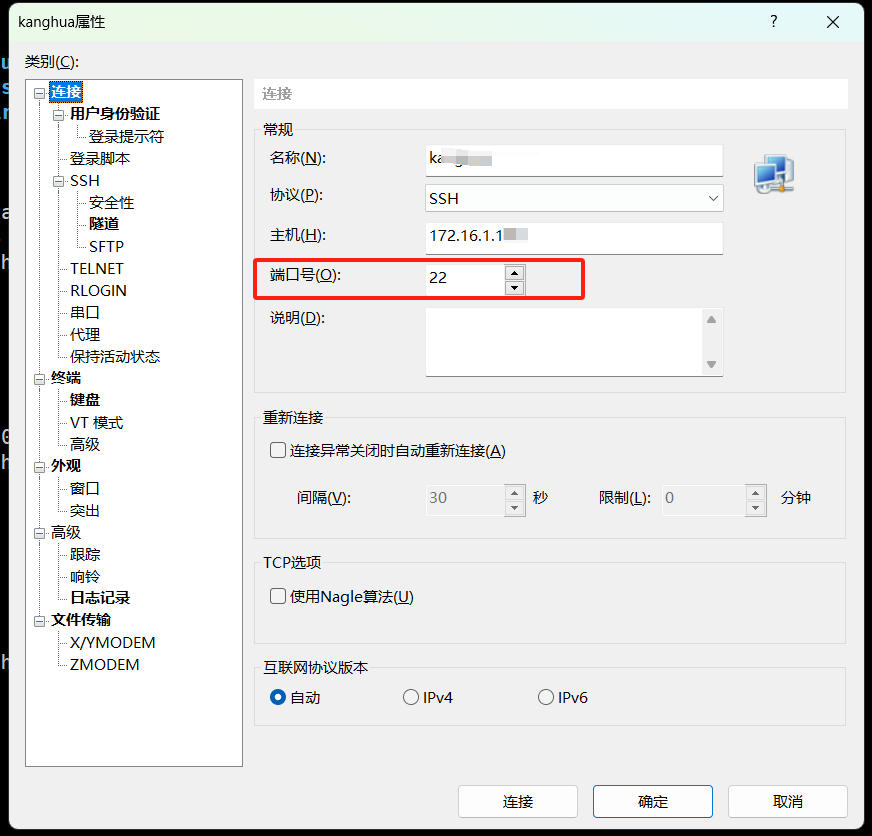
端口若是没有改变,一般默认是22。
4. 查看CUP信息和内存大小
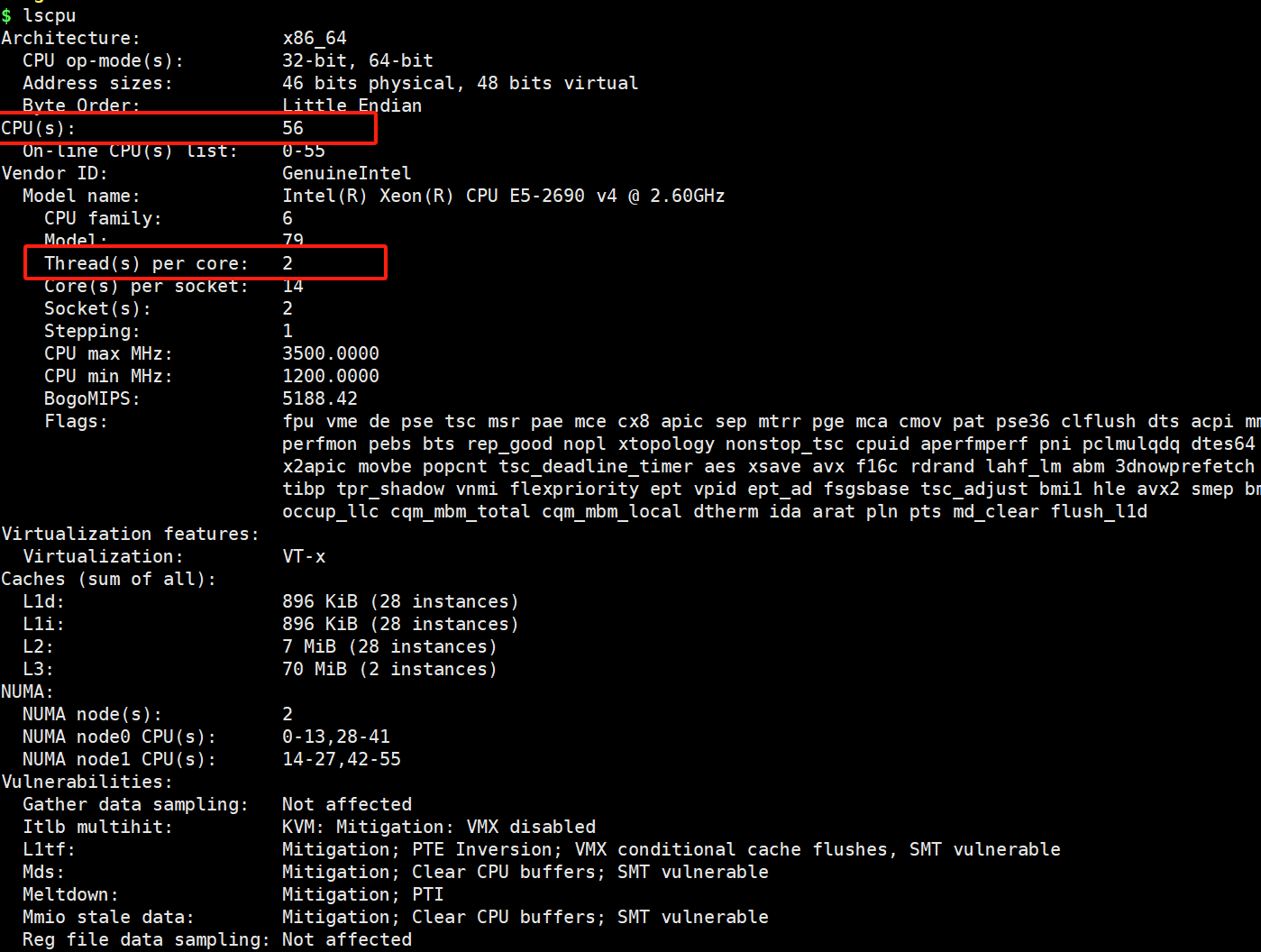
4.1 查看CUP信息
lscpu
或
cat /proc/cpuinfo
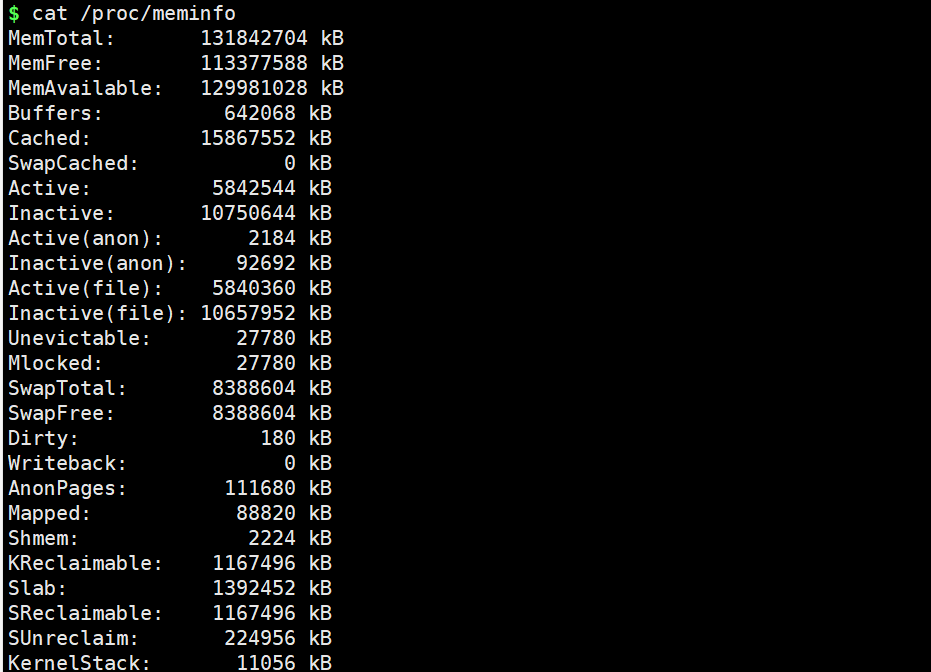
4.2 查看内存信息
cat /proc/meminfo
free -h

4.3 查看硬盘
lsblk
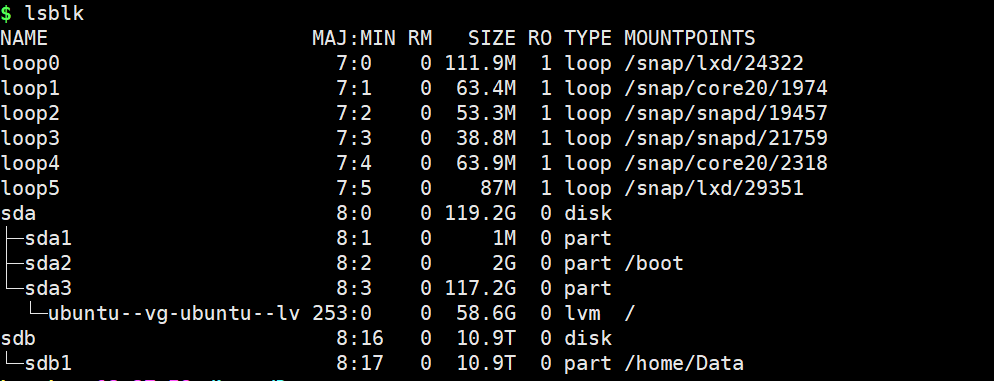
其中,sdb1是我挂载的硬盘。
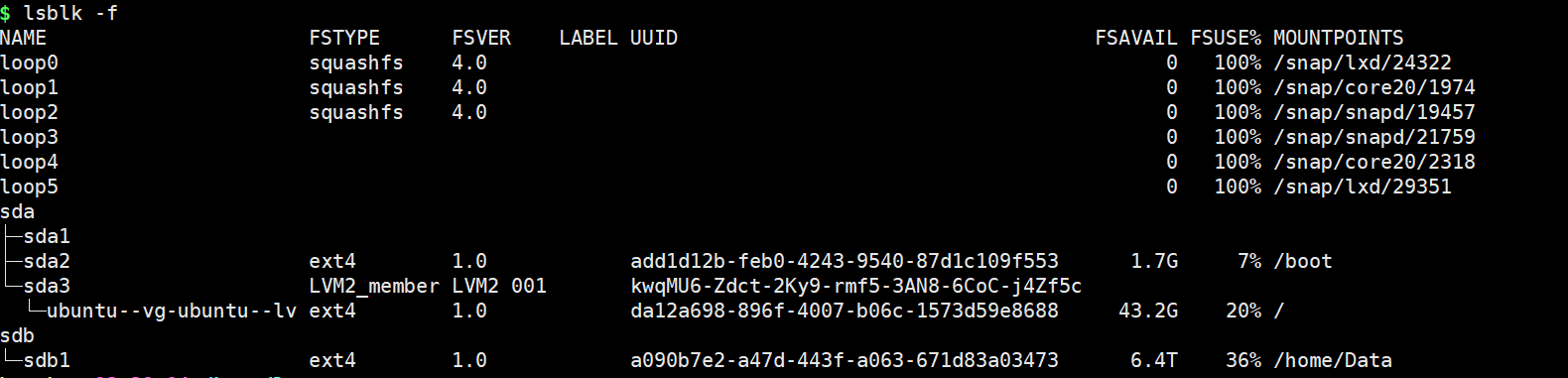
lsblk -f # 查看是否挂载
lsblk -p -o NAME,SIZE,TYPE,MOUNTPOINT # 查看有几个分区
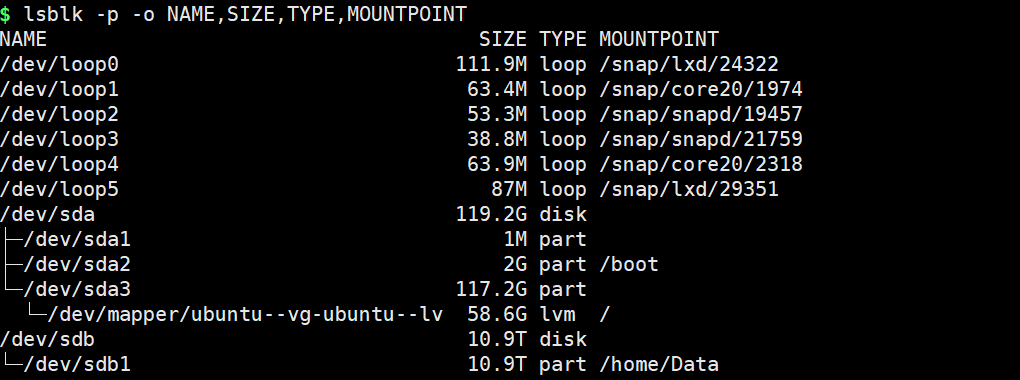
4.4 查看硬盘大小
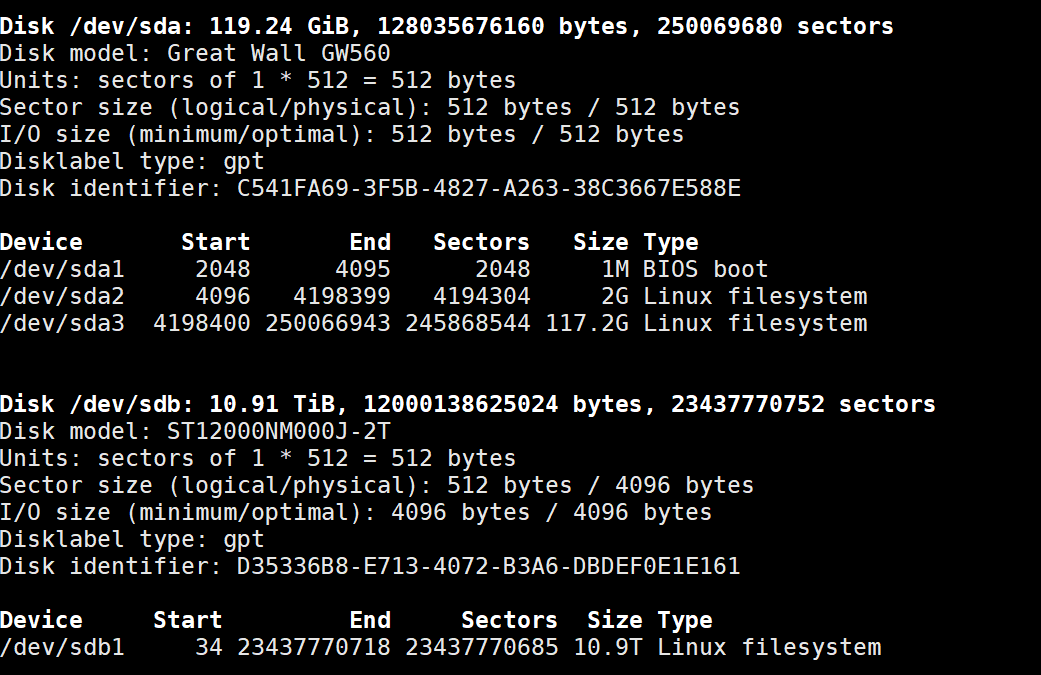
fdisk -l | grep Disk
5. 磁盘挂载
我们的数据盘和系统盘是分开的,因此,需要进行磁盘的挂载。以及,我们需要将挂载磁盘设置为开机自动挂载。
以下命令,需要使用sudo进行操作,也可以直接在root用户下进行。
5.1 查看分区
sudo fdisk -l
5.2 创建挂载目录文件夹
我一般是挂载/home/目录下,有的教程也挂载在/mnt/目录下。(在root用户下进行操作)
mkdir /home/Data
新的硬盘需要进行分区和格式化,若是已经做过分区,或是硬盘中已有数据,可以直接进行挂载,挂载后,数据依旧存在。
5.3 分区
fdisk /dev/sdb
输入n表示建立新的分区。
默认是p,表示主分区。e为扩展分区
Partition number(1-4)时,1表示只分一个区。
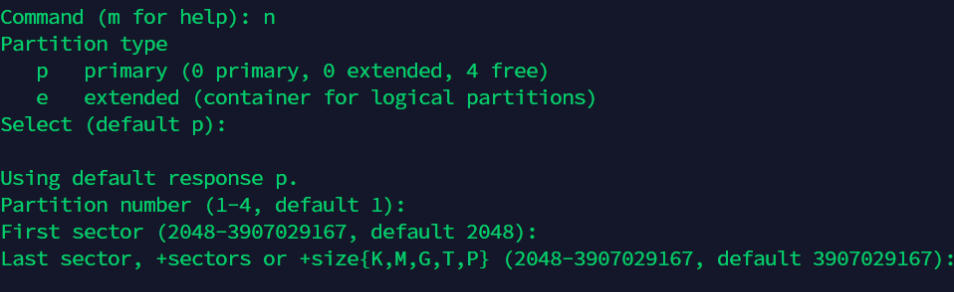
在Command (m for help)提示符后面输入p,显示分区表。
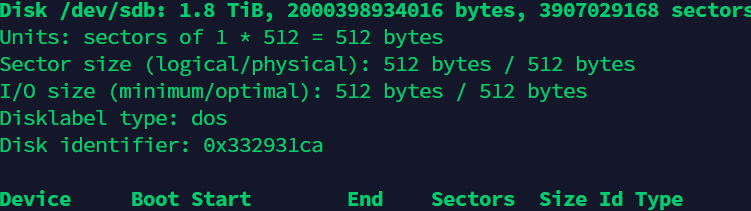
5.4 格式化
将分区/dev/sdb1格式化为ext4文件系统:
mkfs -t ext4 /dev/sdb1
5.5 将分区挂载到/home/Data
mount -t ext4 /dev/sdb1 /home/Data
6. 开机自动挂载
我们上一步已经将硬盘挂载/home/Data目录下,现在进行自动挂载操作。
6.1 查询挂载硬盘UUID
sudo blkid /dev/sda2
输出结果:
$ sudo blkid /dev/sdb
/dev/sda2: UUID="add1d12b-feb0-4243-9540-87d1c109f553" BLOCK_SIZE="4096" TYPE="ext4" PARTUUID="7c0dc869-2a6a-4594-b2c2-4d132c6afb15"
UUID="add1d12b-feb0-4243-9540-87d1c109f553"即是我们需要的信息。
6.2 修改/etc/fstab文件
vim /etc/fstab
在文档末尾添加裹在磁盘的信息。
格式为:
[UUID=************] [挂载磁盘分区] [挂载磁盘格式] 0 2
#-------
UUID=a090b7e2-a47d-443f-a063-671d83a03473 /home/Data ext4 defaults 0 2
第一个数字:0表示开机不检查磁盘,1表示开机检查磁盘;
第二个数字:0表示交换分区,1代表启动分区(Linux),2表示普通分区
挂载的分区是磁盘格式为ext4
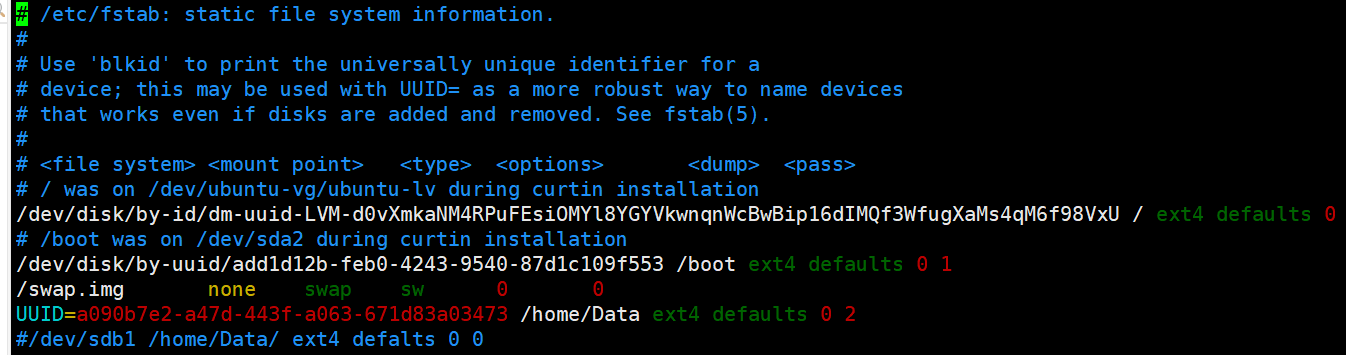
ok!到这里,磁盘自动挂载就完成了!我们的磁盘会随着的系统启动,自动挂载。
6.3 磁盘的卸载
使用umount命令用于卸载磁盘。
umount /home/Data
相关参数:
参数:-a 卸除/etc/mtab中记录的所有文件系统。-h 显示帮助。 -n 卸除时不要将信息存入/etc/mtab文件中。-r 若无法成功卸除,则尝试以只读的方式重新挂入文件系统。-t<文件系统类型> 仅卸除选项中所指定的文件系统。-v 执行时显示详细的信息。-V显示版本信息。
7. Ubuntu在指定路径下创建用户
这一步目的是减少储存不够用的情况,我直接将用户挂载到磁盘中,此用户可以随意使用磁盘,直至这块磁盘满盘为止。
以下操作,在root用户中进行。
7.1 新建用户
useradd -d /home/Data/Bioinfo -m -s /bin/bash Bioinfo
/home/Data/:路径
Bioinfo:用户名
shell指定:/bin/bash
7.2 修改用户密码
passwd Bioinfo
7.3 将用户设置成管理权限(此设置慎重)
#将新用户添加到sudo组:如果你想让新用户具有管理员权限,可以将其添加到sudo组
sudo usermod -aG sudo newuser
7.4 检查用户权限
sudo -l -U newuser

7.5 修改用户权限
可以使用chmod命令来修改用户对文件或目录的权限。例如,要将/var/www/html目录的所有权转移给新用户,可以运行以下命令:
sudo chown -R newuser:newuser /var/www/html
7.6 修改文件权限
可以使用chmod命令来修改文件或目录的权限。例如,要将/var/www/html/index.html文件的所有者赋予新用户,可以运行以下命令:
sudo chown newuser /var/www/html/index.html
以上操作基本将我们的用户设置完成了。
8. 用户权限设置
我们这里单独使用一小节,介绍设置用户和权限。原文链接:https://blog.csdn.net/qq_43116031/article/details/133858239,作者已经在原文中介绍很详细了,我们这里直接引用过来。
8.1 sudo
sudo(Super User Do)是在Linux和Unix系统中用于执行具有超级用户(root)权限的命令的命令。它允许普通用户以特权身份运行特定命令,通常需要输入密码以确认其身份。
sudo 是一种安全的方式,用于限制哪些用户可以执行特权操作,以减少潜在的系统损害。通常,只有系统管理员或有需要的用户才能使用 sudo。
以下是一些 sudo 命令的常见用法:
- 以超级用户(root)身份运行单个命令:
例如,要以超级用户权限安装软件,你可以运行:
sudo apt-get install package_name
- 切换到超级用户(root)模式:
sudo -i
这将打开一个新的Shell会话,将以超级用户身份运行所有命令。要退出超级用户模式,只需输入exit。
3. 编辑系统文件:
sudo nano /etc/file_to_edit
这将以超级用户权限使用文本编辑器打开文件以进行编辑。你可以使用 vim、nano 或其他文本编辑器。
4. 管理系统服务
sudo systemctl start|stop|restart service_name
这将启动、停止或重启特定系统服务。
5. 管理用户和组:
sudo useradd new_username
sudo userdel existing_username
sudo usermod -aG group_name username
8.2 useradd
useradd命令来创建新用户,但它不会自动为用户分配home目录或设置密码。以下是使用 useradd 命令创建用户的基本语法:
sudo useradd [options] username
以下是一些常用的useradd选项:
-m:自动为用户创建家目录。
-s:指定用户的默认Shell。例如,-s /bin/bash 会将用户的默认Shell设置为Bash。
-G:指定用户要加入的附加组。多个组可以用逗号分隔。
-d:指定用户的家目录路径。
-p:指定用户的加密密码。密码通常使用 passwd 命令设置,而不是直接在 useradd 命令中指定密码。
8.3 passwd
passwd是一个用于更改用户密码的命令,或者具有管理员权限的用户可以更改其他用户的密码。以下是 passwd 命令的一些常见用法:
- 更改当前用户的密码:
用户可以使用 passwd 命令来更改自己的密码。在终端中,只需键入:
passwd
然后按照提示输入当前密码,然后输入新密码两次。
2. 更改其他用户的密码:
如果有管理员权限,可以使用passwd命令来更改其他用户的密码。在终端中,使用以下命令:
sudo passwd username
其中 username 是要更改密码的用户的用户名。然后按照提示输入新密码两次。
3. 强制用户更改密码
如果需要强制用户在下次登录时更改密码,使用以下命令:
sudo passwd -e username
这将使用户的密码在下次登录时过期,用户将被要求立即更改密码。
4. 查看用户密码策略:
使用以下命令来查看密码策略的详细信息:
sudo chage -l username
这将显示密码过期日期、最小和最大密码年龄等信息。

5. 锁定用户账户
使用以下命令来锁定用户账户,使用户无法登录:
sudo passwd -l username
要解锁用户账户,使用以下命令:
sudo passwd -u username
8.4 chmod
chmod用于更改文件或目录权限的命令。用来分配或更改文件的访问权限,以确定哪些用户或用户组可以读取、写入或执行文件。
chmod命令可以通过符号模式或八进制模式进行操作。以下是一些常见的chmod命令用法:
符号模式:
- 添加权限:
chmod +[权限] [文件名]
例如,要添加执行权限给文件 file.txt,可以使用:
chmod +x file.txt
- 删除权限:
chmod -[权限] [文件名]
例如,要删除写入权限从文件 file.txt,可以使用:
chmod -w file.txt
- 设置权限:
chmod [权限] [文件名]
例如,要将文件 file.txt 的权限设置为读取和写入,可以使用:
chmod rw file.txt
- 同时设置多个权限:
chmod [权限1][权限2] [文件名]
例如,要为文件 file.txt 设置读取和执行权限,可以使用:
chmod rx file.txt
八进制模式:
- 分配权限:
chmod [八进制权限] [文件名]
在八进制模式中,每个权限都用数字表示,如下所示:
4:读权限
2:写权限
1:执行权限
例如,为了将文件 file.txt 的权限设置为读取和写入权限,可以使用:
chmod 600 file.txt
8.5 chown
chown用于更改文件或目录的所有者和组的命令。分配文件的所有者(user)和组(group)权限。以下是一些常见的 chown 命令用法:
- 更改所有者:
sudo chown [新用户] [文件名/目录名]
新用户 是要将文件或目录的所有权分配给的用户名。
例如,要将文件 file.txt 的所有权更改为用户 newuser,可以使用:
sudo chown newuser file.txt
- 更改组:
sudo chown :[新组] [文件名/目录名]
新组 是要将文件或目录的组权限分配给的组名。
例如,要将文件 file.txt 的组权限更改为组 newgroup,可以使用:
sudo chown :newgroup file.txt
- 更改所有者和组:
sudo chown [新用户]:[新组] [文件名/目录名]
新用户:是新的文件或目录所有者的用户名。
新组:是新的文件或目录组的组名。
例如,要将文件file.txt的所有者更改为newuser并将组更改为newgroup,可以使用:
sudo chown newuser:newgroup file.txt
- 递归更改权限:
递归地更改目录及其子目录中的文件的所有者和组,可以使用-R或--recursive选项:
sudo chown -R [新用户]:[新组] [目录名]
例如,要递归地将目录mydir及其所有子目录中的文件的所有者和组设置为newuser和 newgroup,可以使用:
sudo chown -R newuser:newgroup mydir
请小心使用chown命令,确保有足够的权限来更改文件或目录的所有者和组。通常,只有系统管理员或文件的所有者应具有更改所有者和组的权利。
9. 配置生信分析环境
生信环境的配置,是我们进入生信分析门槛前的最后一步,若是没有这边,前面做的工作白做,后续的想做的工作无法进行。
我们这里使用的是Bioinfo Note社群中,@九筒同学的教程,这个教程他在23日刚做了更新,比较全面,我们就直接引用他的教程即可。若是这个教程,无法满足您的需求,那么你也可以继续查找其他的教程,在网上一搜索,会有很多个教程。
教程网址:https://www.yuque.com/jiutong-3byul/jiutong/imcg0lxd6zg5s39a?singleDoc#
教程作者:@九筒
9.1 升级组件
# 解决90%问题
sudo apt update
sudo apt upgrade
9.2 miniconda安装
# 可以去官网看看是否更新,安装最新的提示操作
mkdir -p ~/miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
rm -rf ~/miniconda3/miniconda.sh
为 bash 和 zsh shell 初始化
~/miniconda3/bin/conda init bash
~/miniconda3/bin/conda init zsh
在这里我们更推荐大家下载mamba,conda下载确实慢。以及你也可以使用Pixi,速度是conda的10倍以上,mamba的4倍,Pixi是何方神圣呢?真有这么快吗?

mamaba下载网址:
https://github.com/conda-forge/miniforge/releases/
后面的操作基本一致,若是你使用conda直接copy即可,若是你使用mamba,那么需要更换一下相关命令即可。
9.3 conda 常用命令
- 增加生信分析常用的镜像
conda config --add channels defaults
conda config --add channels bioconda
conda config --add channels conda-forge
- 关闭base环境自动启动
conda config --set auto_activate_base false
- 创建虚拟环境
# 创建环境
conda create -n my_env_name# 也可以在创建时指定要安装的包及版本
conda create -n my_env_name python=3.12 pytorch
- 克隆环境
conda create -n new_env --clone old_env
- 连接和退出环境
conda activate env_name
conda deactivate
- 安装包的命令, 通常有三种安装方式:
## 安装一般的软件
conda install 软件名字
conda install -c conda-forge 软件名字## 安装CRAN中的R包
conda install r-包的名字## 安装bioconductor中的R包
conda install bioconductor-包的名字
- mamba代替conda
作者在教程中也提供mamba操作
软件安装:
## 安装mamba
conda install mamba## 安装一般的软件
mamba install 软件名字
mamba install -c conda-forge 软件名字## 安装CRAN中的R包
mamba install r-包的名字## 安装bioconductor中的R包
mamba install bioconductor-包的名字
- 其他 conda 命令
# 显示conda 版本
conda --version# 查看当前已创建环境的名称及位置
conda info --envs
conda env list#查看当前安装的软件
conda list# 删除虚拟环境
conda remove -n your_env_name --all# 当前的 cofig
conda config --set show_channel_urls yes# 查看添加的镜像:
conda config --show# 当前channels文件
conda config --get channels# 或者直接系统层面看conda的源
sudo nano ~/.condarc# 删除源
conda config --remove-key channels
9.4 安装 Jupyter Notebook
9.4.1 安装 Jupyter
- 方法一:每个环境安装一个jupyter
# 进入要安装jupyter的虚拟环境
conda activate omicverse# 检查pip的版本
pip3 --version# 检测pip是不是位于 omicverse 的虚拟环境下
which pip3
# 显示:/home/bio/miniconda3/envs/omicverse/bin/pip3# 使用pip安装jupyter
pip3 install -U jupyter
- 方法二:只在 base 环境中安装 jupyter
首先,需要在已经安装了 python 的环境中,安装 ipykernel
# 新建一个目标环境,指定python版本3.12
conda create -n pytest python=3.12# 进入该环境
conda activate pytest# 检查是否已经安装了ipykernel(如果该环境安装过jupyter,就会有ipkernel,不用再次安装)
conda list# 如果没有,则安装ipykernel
conda install ipkernel -c conda-forge
然后,我们到 把 jupyter 安装到 base,用同一个 jupyter 来使用所有环境中的 python
# 回到base环境
conda deactivate# 检查pip的版本
pip3 --version# 检测pip是不是位于 miniconda 的 base 虚拟环境下
which pip3
# 显示:/home/bio/miniconda3/bin/pip3# 使用pip安装jupyer
pip3 install -U jupyter
最后,将 conda 中的所有 python 环境添加到 Jupyter Notebook 中
# 安装这个工具
conda install nb_conda_kernels# 这个只需要安装一次,以后新建的环境,安装了ipykernel后会自动添加
9.4.2 配置 jupyter
● 这里配置 jupyter 是为了方便我们进行远程访问
● 注意,配置文件是全局的,即同一个用户,各个虚拟环境中的 jupyer 默认都使用同一个配置文件
● 因此,即使在不同的虚拟环境中安装了多个 jupyter,只需要配置一次
- 检查jupyter配置文件
# 生成配置文件,记住返回的文件地址
jupyter notebook --generate-config
# 默认是:/home/bio/.jupyter/jupyter_notebook_config.py# 进入python解释器
python3
- 计算密码的hash值
from jupyter_server.auth import passwd
passwd ()# 设置密码
# Enter password:
# Verify password:# 输入密码,返回该密码的hash值
# 如[1]:'argon2:$argon2id$v=19$m=10240,t=10,p=8$NljykjG3OllNHs9cEnhHmw$4Yvv/CCHEir9PzzdSBFUJMHSa3OucpG+XgH3Fr0UMys'# 退出python
quit()
- 修改Jupyter配置文件
用 nano 编辑器打开配置文件
nano /home/bio/.jupyter/jupyter_notebook_config.py
4. 增加如下内容
```R
# 增加如下内容# hash= 填上刚才生成的hash
hash='argon2:$argon2id$v=19$m=10240,t=10,p=8$NljykjG3OllNHs9cEnhHmw$4Yvv/CCHEir9PzzdSBFUJMHSa3OucpG+XgH3Fr0UMys'# 允许任意ip访问
c.ServerApp.ip = '0.0.0.0'# 设置密码
c.ServerApp.password = hash# 关闭自动打开浏览器
c.ServerApp.open_browser = False# 设置端口号
c.ServerApp.port = 8888# 允许远程连接
c.ServerApp.allow_remote_access = True# nano编辑器的操作很简单,修改完成后按 ctrl + x 退出
- 安装中文语言包
# 安装中文语言包(推荐)
pip install jupyterlab-language-pack-zh-CN# 或者用conda
conda install jupyterlab-language-pack-zh-CN
当然,如果你不修改配置文件,也可以通过 ssh 端口映射的方式远程访问,但不推荐
- 端口映射
# windows terminal 连接服务器时映射端口号
# 不建议使用
ssh -L8888:localhost:8888 root@服务器IP
9.4.3 启动并打开 Jupyter Notebook
- 启动Jupyter
激活 conda 环境
# 如果是在每个环境中都安装了jupyter,则进入对应的环境启动
conda activate omicverse# 如果是在base中安装的jupyter
conda activate base
进入对应的工作目录
# 我这里使用的是bio用户,进入后默认是/home/bio目录# 检查当前目录
pwd
# 返回:/home/bio# 我平时的项目都存储在/home/bio/work目录# 如果没有,新建一个工作目录
mkdir work# 进入work目录
cd work
启动Jupyter
# 启动 notebook
jupyter notebook# 或者使用 jupyter lab
jupyter-lab# 如果你是root用户(不建议)
jupyter notebook --allow-root# 如果你是root用户(不建议)
jupyter-lab --allow-root
- 浏览器访问
地址:服务器 IP:端口号
如:192.168.3.128:8888
第一次访问需要密码,就是你之前设置的密码(如 admin)
10. 安装R和Rstudio Server
关于安装R和Rstudio Server,我们的教程Ubuntu中安装R和Rstudio软件也介绍很详细,可以作为参考。

10.1 创建R的虚拟环境
# 创建名为R的环境
conda create -n R
10.2 安装R
# 进入到R这个环境
conda activate R#安装R,指定r-base=4.3.2,那么就会安装R-4.3.2,你也可以不指定
conda install r-base=4.3.2# 进入R解释器
R# 退出R解释器
q()# 查看当前的R解释器
which R
10.3 安装 Rstudio server
● 建议查看官网地址:https://posit.co/download/rstudio-server/
● 我这里安装的版本可能已经不是最新的
# 装gdebi-core
sudo apt-get install gdebi-core# 下载Ubuntu 22对应的.deb文件
wget https://download2.rstudio.org/server/jammy/amd64/rstudio-server-2024.04.0-735-amd64.deb# 安装
sudo gdebi rstudio-server-2024.04.0-735-amd64.deb# 如果始终安装不上,试一下更新源
sudo apt update
sudo apt upgrade# 验证是否安装
sudo rstudio-server verify-installation
sudo rstudio-server verify-installation
# 正常会提示:Server is running and must be stopped before running verify-installation
# 但这里极大可能是报错的,没关系,因为我们是在虚拟环境中安装的R,因此会提示找不到R,先不管它
10.4 配置 Rstudio server 中的R解释器
● 因为Rstudio server 是一个 linux 系统服务,你无法安装多个(除非你使用 docker,这个教程里不涉及)
● 如果你有多个不同的 R 环境,你就需要查看不同环境中的R解释器的位置
● 然后我们告诉rstudio-server 使用哪个R 解释器
# 进入到某个安装了R解释器的环境
# 如刚刚我们安装的# 进入到R这个环境
conda activate R# 查看当前环境的R解释器地址
which R
# 返回:/home/bio/miniconda3/envs/R/bin/R# 打开/etc/rstudio/rserver.conf文件
sudo nano /etc/rstudio/rserver.conf# =后的地址修改为目标R解释器地址
rsession-which-r=/home/bio/miniconda3/envs/R/bin/R# nano编辑器的操作很简单,修改完成后按ctrl + o,覆盖原文件,然后 ctrl + x 退出
10.5 重启 Rstudio server 服务
# sudo rstudio-server status #查看RStudio-server
# sudo rstudio-server stop #关闭RStudio-server
# sudo rstudio-server restart #重启RStudio-server# 这里我们手动重启一下
sudo rstudio-server restart# 验证是否在运行,在启动状态下输入
sudo rstudio-server verify-installation
# 会提示:Server is running and must be stopped before running verify-installation# 我们关闭服务
sudo rstudio-server stop# 再次输入
sudo rstudio-server verify-installation
# 会输出诊断报告# 重启服务
sudo rstudio-server restart
10.6 浏览器访问
地址:服务器 IP:端口号
默认端口号:8787
如:192.168.3.128:8787
账号:linux 用户名(bio)
密码:对应的用户密码(admin)
10.6 其他 Rstudio server 配置
官方配置教程:https://support.posit.co/hc/en-us/articles/200552316-Configuring-RStudio-Workbench-RStudio-Server
1.Rstudio server设置文件
cat /etc/rstudio/rserver.conf
# Server Configuration File# 查看rsession配置文件
cat /etc/rstudio/rsession.conf
/etc/rstudio/rserver.conf
## In /etc/rstudio/rserver.conf# 更改端口为8787,默认就是8787
www-port=8787# 默认情况下,RStudio绑定到地址0.0.0.0
www-address=0.0.0.0# 添加系统的库路径作为外部库以供RStudio server调用
rsession-ld-library-path=/xxxxxx/lib# 指定conda中的R
rsession-which-r=/home/bio/miniconda3/envs/R/bin/R# 限制能够使用RStudio-server的用户组,例如
auth-required-user-group=rstudio_users
/etc/rstudio/rserver.conf
## In /etc/rstudio/rserver.conf# 默认用户超过2个小时没有发出命令,RStudio会将该用户的R session挂起到磁盘
# 这样他们就不再消耗服务器资源(下次用户尝试访问服务器时,他们的会话将被还原)
# 当用户在运行代码时是不会因为超时被挂起
# 可以使用session-timeout-minutes设置更改超时(包括通过指定值为0来禁用它)
session-timeout-minutes=30# 更改R包安装地址
# 通过修改r-libs-user可以更改用户的默认R包安装地址
# 这样的好处是确保最终用户安装的R包在路径中没有R版本号
# 这使管理员可以在服务器上升级R版本而不用重置用户安装的软件包
r-libs-user=~/R/packages# 更改默认镜像
r-cran-repos=https://mirrors.nics.utk.edu/cran/
ok!到这里,我们就完成了Ubuntu系统的安装+用户设置+磁盘挂载+生信环境基础配置。注意:我们文章中只是总结了一部分内容,很多详细的内容,都需要自己有正对性的设置,大家可以尽情地“度娘”。
获得本期教程文本文档,在后台回复:20240724。请大家看清楚回复关键词,每天都有很多人回复错误关键词,我这边没时间和精力一一回复。
参考:
- https://blog.csdn.net/mayue_web/article/details/124750653
- https://blog.csdn.net/winycg/article/details/109517512
- https://blog.csdn.net/qq_35451572/article/details/79541106
- https://www.yisu.com/ask/88822632.html
- https://blog.csdn.net/Mcy7ycM/article/details/124347504
- https://blog.csdn.net/qq_43116031/article/details/133858239
- https://www.yuque.com/jiutong-3byul/jiutong/imcg0lxd6zg5s39a?singleDoc#
若我们的教程对你有所帮助,请
点赞+收藏+转发,这是对我们最大的支持。
往期部分文章
1. 最全WGCNA教程(替换数据即可出全部结果与图形)
-
WGCNA分析 | 全流程分析代码 | 代码一
-
WGCNA分析 | 全流程分析代码 | 代码二
-
WGCNA分析 | 全流程代码分享 | 代码三
-
WGCNA分析 | 全流程分析代码 | 代码四
-
WGCNA分析 | 全流程分析代码 | 代码五(最新版本)
2. 精美图形绘制教程
- 精美图形绘制教程
3. 转录组分析教程
-
转录组上游分析教程[零基础]
-
一个转录组上游分析流程 | Hisat2-Stringtie
4. 转录组下游分析
-
批量做差异分析及图形绘制 | 基于DESeq2差异分析
-
GO和KEGG富集分析
-
单基因GSEA富集分析
-
全基因集GSEA富集分析
小杜的生信筆記 ,主要发表或收录生物信息学教程,以及基于R分析和可视化(包括数据分析,图形绘制等);分享感兴趣的文献和学习资料!!
相关文章:
一文解决 | Linux(Ubuntn)系统安装 | 硬盘挂载 | 用户创建 | 生信分析配置
原文链接:一文解决 | Linux(Ubuntn)系统安装 | 硬盘挂载 | 用户创建 | 生信分析配置 本期教程 获得本期教程文本文档,在后台回复:20240724。请大家看清楚回复关键词,每天都有很多人回复错误关键词…...

Matlab M_map工具箱绘制Interrupted Mollweide Projection
GMT自带了许多的地图投影,但是对于Interrupted Mollweide投影效果却不好。 作为平替的m_map工具箱中带有的投影类型可完美解决这一问题。 Interrupted Mollweide Projection长这样 全球陆地 全球海洋 使用Matlab工具箱m_map展示全球海平面变化的空间分布 addpath(…...

Python 变量与基本数据类型
重点内容 1 掌握变量及厂里在数据输入、输出及计算中的应用; 2 熟练使用datetime模块来处理日期和时间问题; 3 熟练掌握abs()、round()、pow()、sum()、min()、max()等的应用; 4 利用变量、字符等知识模拟开发中一些场景的输入与输出&…...

Pytorch深度学习实践(5)逻辑回归
逻辑回归 逻辑回归主要是解决分类问题 回归任务:结果是一个连续的实数分类任务:结果是一个离散的值 分类任务不能直接使用回归去预测,比如在手写识别中(识别手写 0 − − 9 0 -- 9 0−−9),因为各个类别…...

认识漏洞-GitLab 远程命令执行漏洞、致远OA-ajax.do未授权任意文件上传漏洞
为方便您的阅读,可点击下方蓝色字体,进行跳转↓↓↓ 01 [GitLab 远程命令执行漏洞复现(CVE-2021-22205)](https://mp.weixin.qq.com/s/4QT-vxKpBn4ppNM9ipt-nQ)02 [致远OA-ajax.do未授权任意文件上传Getshell](https://mp.weixin.qq.com/s/TH2A5J5TXU36Y…...

vue实现电子签名、图片合成、及预览功能
业务功能:电子签名、图片合成、及预览功能 业务背景:需求说想要实现一个电子签名,然后需要提供一个预览的功能,可以查看签完名之后的完整效果。 需求探讨:后端大佬跟我说,文档我返回给你一个PDF的oss链接…...

【flink】之如何消费kafka数据?
为了编写一个使用Apache Flink来读取Apache Kafka消息的示例,我们需要确保我们的环境已经安装了Flink和Kafka,并且它们都能正常运行。此外,我们还需要在项目中引入相应的依赖库。以下是一个详细的步骤指南,包括依赖添加、代码编写…...

科研绘图系列:R语言山脊图(Ridgeline Chart)
介绍 山脊图(Ridge Chart)是一种用于展示数据分布和比较不同类别或组之间差异的数据可视化技术。它通常用于展示多个维度或变量之间的关系,以及它们在不同组中的分布情况。山脊图的特点: 多变量展示:山脊图可以同时展示多个变量的分布情况,允许用户比较不同变量之间的关…...

Boost搜索引擎:如何建立 用户搜索内容 与 网页文件内容 之间的关系
如果想使“用户搜索内容”和“网页文件内容”之间产生联系,就应该将“用户搜索内容”和“网页文件”分为很小的单元 (这个单元就是关键词),寻找用户搜索单元是否出现在这个文档之中,如果出现就证明这个网页文件和用户搜…...
【QT】QT 窗口(菜单栏、工具栏、状态栏、浮动窗口、对话框)
Qt 窗口是通过 QMainWindow类来实现的。 QMainWindow 是一个为用户提供主窗口程序的类,继承自 QWidget 类,并且提供了⼀个预定义的布局。QMainWindow 包含一个菜单栏(Menu Bar)、多个工具栏(Tool Bars)、…...

Golang | Leetcode Golang题解之第283题移动零
题目: 题解: func moveZeroes(nums []int) {left, right, n : 0, 0, len(nums)for right < n {if nums[right] ! 0 {nums[left], nums[right] nums[right], nums[left]left}right} }...
ubuntu22.04 安装 NVIDIA 驱动以及CUDA
目录 1、事前问题解决 2、安装 nvidia 驱动 3、卸载 nvidia 驱动方法 4、安装 CUDA 5、安装 Anaconda 6、安装 PyTorch 1、事前问题解决 在安装完ubuntu之后,如果进入ubuntu出现黑屏情况,一般就是nvidia驱动与linux自带的不兼容,可以通…...
数据结构·AVL树
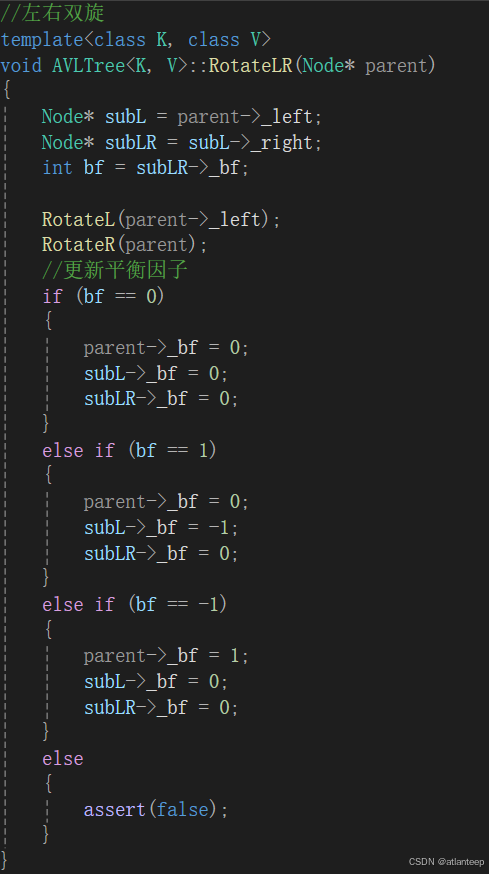
1. AVL树的概念 二叉搜索树虽可以缩短查找的效率,但如果存数据时接近有序,二叉搜索将退化为单支树,此时查找元素效率相当于在顺序表中查找,效率低下。因此两位俄罗斯数学家 G.M.Adelson-Velskii 和E.M.Landis 在1962年发明了一种解…...
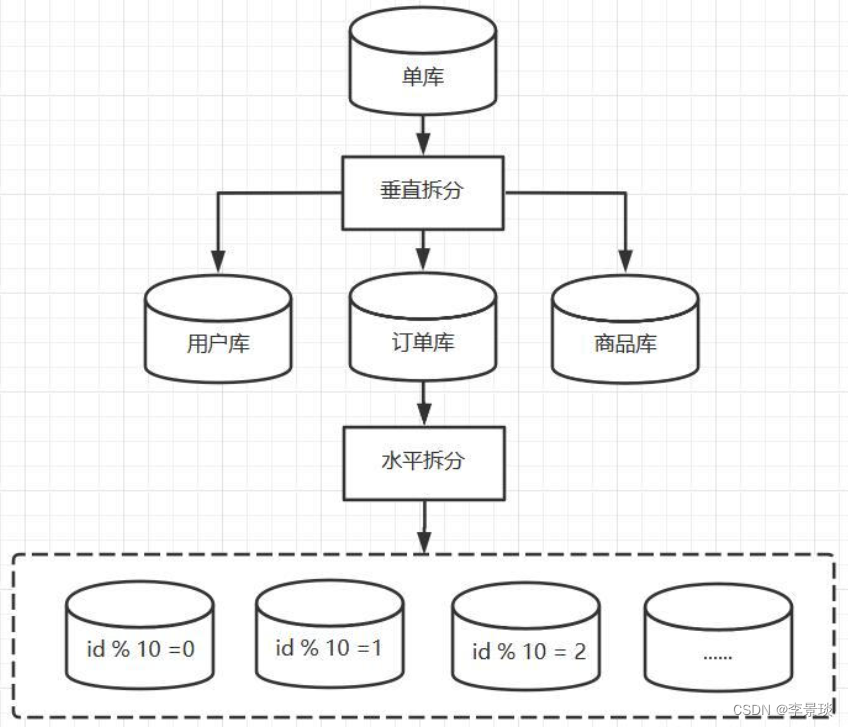
记一次Mycat分库分表实践
接了个活,又搞分库分表。 一、分库分表 在系统的研发过程中,随着数据量的不断增长,单库单表已无法满足数据的存储需求,此时就需要对数据库进行分库分表操作。 分库分表是随着业务的不断发展,单库单表无法承载整体的数据存储时,采取的一种将整体数据分散存储到不同服务…...
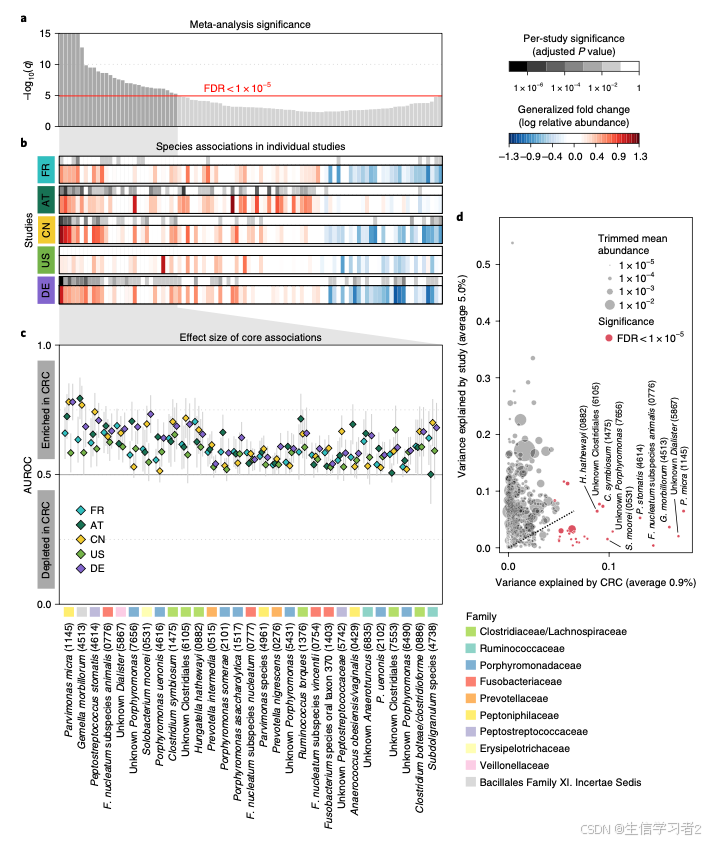
数据分析:微生物数据的荟萃分析框架
介绍 Meta-analysis of fecal metagenomes reveals global microbial signatures that are specific for colorectal cancer提供了一种荟萃分析的框架,它主要基于常用的Wilcoxon rank-sum test和Blocked Wilcoxon rank-sum test 方法计算显著性,再使用分…...
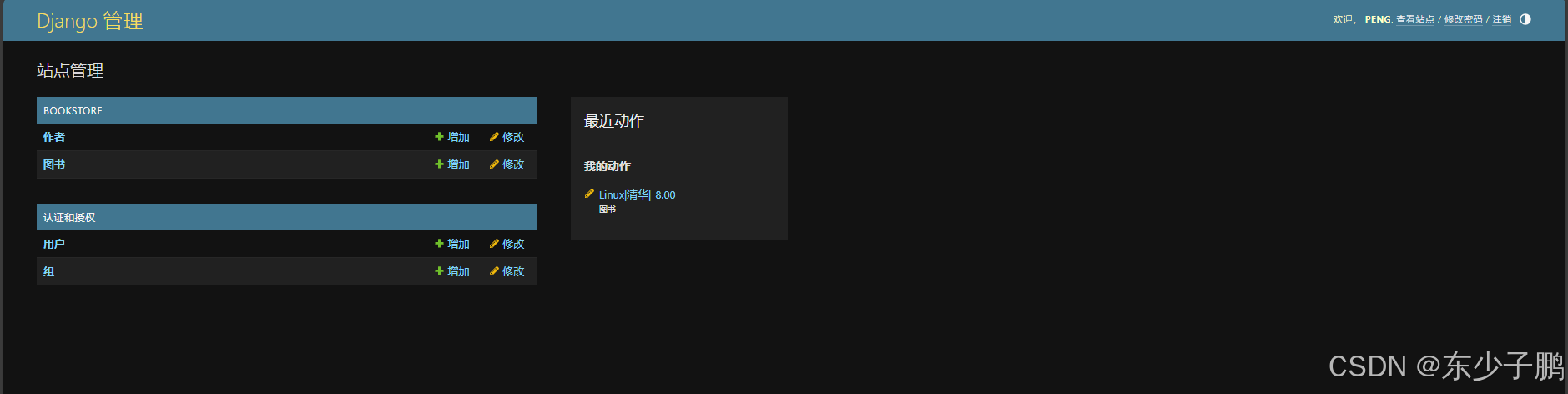
Django—admin后台管理
Django官网 https://www.djangoproject.com/ 如果已经有了Django跳过这步 安装Django: 如果你还没有安装Django,可以通过Python的包管理器pip来安装: pip install django 创建项目: 使用Django创建一个新的项目: …...
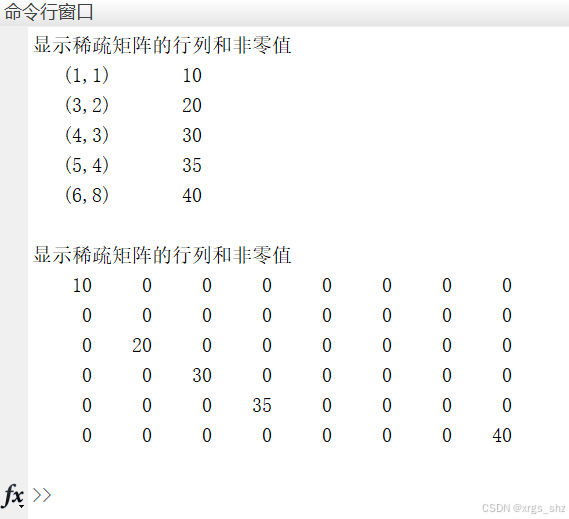
数字图像处理中的常用特殊矩阵及MATLAB应用
一、前言 Matlab的名称来源于“矩阵实验室(Matrix Laboratory)”,其对矩阵的操作具有先天性的优势(特别是相对于C语言的数组来说)。在数字图像处理中,为了提高编程效率,我们可以使用多种方式来创…...
精彩案例剖析一)
vue侦听器(Watch)精彩案例剖析一
目录 watch介绍 监视普通数据类型 监视对象类型 watch介绍 在 Vue 中,watch主要用于监视数据的变化,并执行相应操作。一旦被监视的属性发生变化,回调函数将自动被触发。当在 Vue 中使用watch来响应数据变化时,首先要清楚,watch本质上是一个对象,且必须以对象的…...

HTTP 协议浅析
HTTP(HyperText Transfer Protocol,超文本传输协议)是应用层最重要的协议之一。它定义了客户端和服务器之间的数据传输方式,并成为万维网(World Wide Web)的基石。本文将深入解析 HTTP 协议的基础知识、工作…...
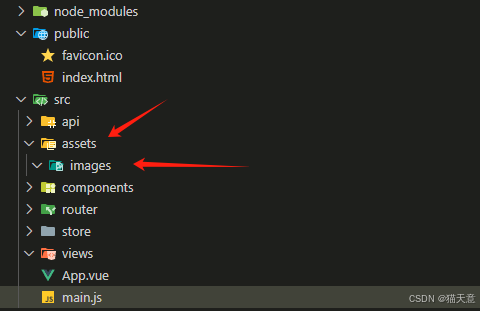
VsCode | 让空文件夹始终展开不折叠
文章目录 1 问题引入2 解决办法3 效果展示 1 问题引入 可能很多小伙伴更新VsCode或者下载新版本时候 ,创建的文件 会出现xxx文件夹/xxx文件夹,看着很不舒服,所以该如何展开所有空文件夹呢? 2 解决办法 找到VsCode的设置 &…...

在软件开发中正确使用MySQL日期时间类型的深度解析
在日常软件开发场景中,时间信息的存储是底层且核心的需求。从金融交易的精确记账时间、用户操作的行为日志,到供应链系统的物流节点时间戳,时间数据的准确性直接决定业务逻辑的可靠性。MySQL作为主流关系型数据库,其日期时间类型的…...
: K8s 核心概念白话解读(上):Pod 和 Deployment 究竟是什么?)
云原生核心技术 (7/12): K8s 核心概念白话解读(上):Pod 和 Deployment 究竟是什么?
大家好,欢迎来到《云原生核心技术》系列的第七篇! 在上一篇,我们成功地使用 Minikube 或 kind 在自己的电脑上搭建起了一个迷你但功能完备的 Kubernetes 集群。现在,我们就像一个拥有了一块崭新数字土地的农场主,是时…...

内存分配函数malloc kmalloc vmalloc
内存分配函数malloc kmalloc vmalloc malloc实现步骤: 1)请求大小调整:首先,malloc 需要调整用户请求的大小,以适应内部数据结构(例如,可能需要存储额外的元数据)。通常,这包括对齐调整,确保分配的内存地址满足特定硬件要求(如对齐到8字节或16字节边界)。 2)空闲…...

linux之kylin系统nginx的安装
一、nginx的作用 1.可做高性能的web服务器 直接处理静态资源(HTML/CSS/图片等),响应速度远超传统服务器类似apache支持高并发连接 2.反向代理服务器 隐藏后端服务器IP地址,提高安全性 3.负载均衡服务器 支持多种策略分发流量…...

Python:操作 Excel 折叠
💖亲爱的技术爱好者们,热烈欢迎来到 Kant2048 的博客!我是 Thomas Kant,很开心能在CSDN上与你们相遇~💖 本博客的精华专栏: 【自动化测试】 【测试经验】 【人工智能】 【Python】 Python 操作 Excel 系列 读取单元格数据按行写入设置行高和列宽自动调整行高和列宽水平…...

前端倒计时误差!
提示:记录工作中遇到的需求及解决办法 文章目录 前言一、误差从何而来?二、五大解决方案1. 动态校准法(基础版)2. Web Worker 计时3. 服务器时间同步4. Performance API 高精度计时5. 页面可见性API优化三、生产环境最佳实践四、终极解决方案架构前言 前几天听说公司某个项…...

java 实现excel文件转pdf | 无水印 | 无限制
文章目录 目录 文章目录 前言 1.项目远程仓库配置 2.pom文件引入相关依赖 3.代码破解 二、Excel转PDF 1.代码实现 2.Aspose.License.xml 授权文件 总结 前言 java处理excel转pdf一直没找到什么好用的免费jar包工具,自己手写的难度,恐怕高级程序员花费一年的事件,也…...

【Zephyr 系列 10】实战项目:打造一个蓝牙传感器终端 + 网关系统(完整架构与全栈实现)
🧠关键词:Zephyr、BLE、终端、网关、广播、连接、传感器、数据采集、低功耗、系统集成 📌目标读者:希望基于 Zephyr 构建 BLE 系统架构、实现终端与网关协作、具备产品交付能力的开发者 📊篇幅字数:约 5200 字 ✨ 项目总览 在物联网实际项目中,**“终端 + 网关”**是…...

leetcodeSQL解题:3564. 季节性销售分析
leetcodeSQL解题:3564. 季节性销售分析 题目: 表:sales ---------------------- | Column Name | Type | ---------------------- | sale_id | int | | product_id | int | | sale_date | date | | quantity | int | | price | decimal | -…...

HTML前端开发:JavaScript 常用事件详解
作为前端开发的核心,JavaScript 事件是用户与网页交互的基础。以下是常见事件的详细说明和用法示例: 1. onclick - 点击事件 当元素被单击时触发(左键点击) button.onclick function() {alert("按钮被点击了!&…...