MongoDB - 聚合阶段 $count、$skip、$project
文章目录
- 1. $count 聚合阶段
- 2. $skip 聚合阶段
- 3. $project 聚合阶段
- 1. 包含指定字段
- 2. 排除_id字段
- 3. 排除指定字段
- 4. 不能同时指定包含字段和排除字段
- 5. 排除嵌入式文档中的指定字段
- 6. 包含嵌入式文档中的指定字段
- 7. 添加新字段
- 8. 重命名字段
1. $count 聚合阶段
计算匹配到的文档数量:
db.collection.aggregate([// 匹配条件{ $match: { field: "value" } },// 其他聚合阶段// ...// 计算匹配到的文档数量{ $count: "total" }
])
首先使用 $match 阶段来筛选出满足条件的文档。然后可以添加其他的聚合阶段来进行进一步的数据处理。最后,使用 $count 阶段来计算匹配到的文档数量,并将结果存储在一个字段中(在示例中是 “total”)。
请注意,$count 阶段只返回一个文档,其中包含一个字段,表示匹配到的文档数量。如果没有匹配到任何文档,将返回一个文档,该字段的值为 0。
构造测试数据:
db.scores.drop()db.scores.insertMany([{ "_id" : 1, "subject" : "History", "score" : 88 },{ "_id" : 2, "subject" : "History", "score" : 92 },{ "_id" : 3, "subject" : "History", "score" : 97 },{ "_id" : 4, "subject" : "History", "score" : 71 },{ "_id" : 5, "subject" : "History", "score" : 79 },{ "_id" : 6, "subject" : "History", "score" : 83 }
])
$match阶段筛选 score 大于 80 的文档并计算匹配到的文档数量:
db.scores.aggregate([// 第一阶段{$match: {score: {$gt: 80}}},// 第二阶段{$count: "passing_scores"}]
)
{ "passing_scores" : 4 }
SpringBoot整合MongoDB实现:
// 输入文档实体类
@Data
@Document(collection = "scores")
public class Score {private int _id;private String subject;private int score;
}// 输出文档实体类
@Data
public class AggregationResult {private String passing_scores;
}// 聚合操作
@SpringBootTest
@RunWith(SpringRunner.class)
public class BeanLoadServiceTest {@Autowiredprivate MongoTemplate mongoTemplate;@Testpublic void aggregateTest() {// $match 聚合阶段Criteria criteria = Criteria.where("score").gt(80);MatchOperation match = Aggregation.match(criteria);// $count 聚合阶段CountOperation count = Aggregation.count().as("passing_scores");// 组合聚合阶段Aggregation aggregation = Aggregation.newAggregation(match,count);// 执行聚合查询AggregationResults<AggregationResult> results= mongoTemplate.aggregate(aggregation, Score.class, AggregationResult.class);List<AggregationResult> mappedResults = results.getMappedResults();// 打印结果mappedResults.forEach(System.out::println);//AggregationResult(passing_scores=4)}
}
2. $skip 聚合阶段
$skip 用于跳过指定数量的文档,并将剩余的文档传递给下一个聚合阶段。
{ $skip: <num> }
构造测试数据:
db.scores.drop()db.scores.insertMany([{ "_id" : 1, "subject" : "History", "score" : 88 },{ "_id" : 2, "subject" : "History", "score" : 92 },{ "_id" : 3, "subject" : "History", "score" : 97 },{ "_id" : 4, "subject" : "History", "score" : 71 },{ "_id" : 5, "subject" : "History", "score" : 79 },{ "_id" : 6, "subject" : "History", "score" : 83 }
])
db.scores.aggregate([{ $skip : 3 }
]);
// 1
{"_id": 4,"subject": "History","score": 71
}// 2
{"_id": 5,"subject": "History","score": 79
}// 3
{"_id": 6,"subject": "History","score": 83
}
$skip 跳过管道传递给它的前 3 个文档,并将剩余的文档传递给下一个聚合阶段。
// 输入文档实体类
@Data
@Document(collection = "scores")
public class Score {private int _id;private String subject;private int score;
}// 输出文档实体类
@Data
public class AggregationResult {private int _id;private String subject;private int score;
}// 聚合操作
@SpringBootTest
@RunWith(SpringRunner.class)
public class BeanLoadServiceTest {@Autowiredprivate MongoTemplate mongoTemplate;@Testpublic void aggregateTest() {// $skip 聚合阶段SkipOperation skip = Aggregation.skip(3);// 组合聚合阶段Aggregation aggregation = Aggregation.newAggregation(skip);// 执行聚合查询AggregationResults<AggregationResult> results= mongoTemplate.aggregate(aggregation, Score.class, AggregationResult.class);List<AggregationResult> mappedResults = results.getMappedResults();// 打印结果mappedResults.forEach(System.out::println);//AggregationResult(_id=4, subject=History, score=71)//AggregationResult(_id=5, subject=History, score=79)//AggregationResult(_id=6, subject=History, score=83)}
}
3. $project 聚合阶段
将带所请求字段的文档传递至管道中的下个阶段。$project 返回的文档可以指定包含字段、排除 _id 字段、添加新字段以及计算现有字段的值。
$project 阶段具有以下原型形式:
{ $project: { <specification(s)> } }
1. 包含指定字段
默认情况下,_id 字段包含在输出文档中。要在输出文档中包含输入文档中的任何其他字段,必须在 $project指定,如果您指定包含的字段在文档中并不存在,那么 $project 将忽略该字段包含,同时不会将该字段添加到文档中。
构造测试数据:
db.books.drop()db.books.insertOne({"_id" : 1,title: "abc123",isbn: "0001122223334",author: { last: "zzz", first: "aaa" },copies: 5}
)
以下 $project 阶段输出文档中仅包含 _id、title 和 author 字段:
db.books.aggregate( [ { $project: { title: 1 , author: 1 } }
] )
{"_id": 1,"title": "abc123","author": {"last": "zzz","first": "aaa"}
}
SpringBoot 整合 MongoDB实现:
// 输入文档实体类
@Data
@Document(collection = "books")
public class Book {private int _id;private String title;private String isbn;private Author author;private int copies;@Datapublic static class Author {private String last;private String first;}
}// 输出文档实体类
@Data
public class AggregationResult {private int _id;private String title;private Author author;@Datapublic static class Author {private String last;private String first;}
}// 聚合操作
@SpringBootTest
@RunWith(SpringRunner.class)
public class BeanLoadServiceTest {@Autowiredprivate MongoTemplate mongoTemplate;@Testpublic void testAggregate(){// project 阶段ProjectionOperation project = Aggregation.project("title", "author");// 组合阶段Aggregation aggregation = Aggregation.newAggregation(project);// 执行聚合AggregationResults<AggregationResult> aggregationResults = mongoTemplate.aggregate(aggregation, Book.class, AggregationResult.class);List<AggregationResult> mappedResults = aggregationResults.getMappedResults();// 打印结果mappedResults.forEach(System.out::println);// AggregationResult(_id=1, title=abc123, author=AggregationResult.Author(last=zzz, first=aaa))}
}
2. 排除_id字段
构造测试数据:
db.books.drop()db.books.insertOne({"_id" : 1,title: "abc123",isbn: "0001122223334",author: { last: "zzz", first: "aaa" },copies: 5}
)
以下 $project 阶段输出文档中仅包含 title 和 author 字段:
db.books.aggregate( [ { $project: { _id: 0, title: 1, author: 1 } }
] )
{"title": "abc123","author": {"last": "zzz","first": "aaa"}
}
SpringBoot 整合 MongoDB实现:
// 输入文档实体类
@Data
@Document(collection = "books")
public class Book {private int _id;private String title;private String isbn;private Author author;private int copies;@Datapublic static class Author {private String last;private String first;}
}// 输出文档实体类
@Data
public class AggregationResult {private int _id;private String title;private String isbn;private Author author;private int copies;@Datapublic static class Author {private String last;private String first;}
}// 聚合操作
@SpringBootTest
@RunWith(SpringRunner.class)
public class BeanLoadServiceTest {@Autowiredprivate MongoTemplate mongoTemplate;@Testpublic void testAggregate(){// project 阶段ProjectionOperation project = Aggregation.project("title", "author").andExclude("_id");// 组合阶段Aggregation aggregation = Aggregation.newAggregation(project);// 执行聚合AggregationResults<AggregationResult> aggregationResults = mongoTemplate.aggregate(aggregation, Book.class, AggregationResult.class);List<AggregationResult> mappedResults = aggregationResults.getMappedResults();// 打印结果mappedResults.forEach(System.out::println);// AggregationResult(title=abc123, author=AggregationResult.Author(last=zzz, first=aaa))}
}
3. 排除指定字段
构造测试数据:
db.books.drop()db.books.insertOne({"_id" : 1,title: "abc123",isbn: "0001122223334",author: { last: "zzz", first: "aaa" },copies: 5,lastModified: "2016-07-28"}
)
在 $project 阶段中输出文档排除 title 和 isbn 字段:
db.books.aggregate( [ { $project: { title: 0, isbn: 0 } }
] )
// 1
{"_id": 1,"author": {"last": "zzz","first": "aaa"},"copies": 5,"lastModified": "2016-07-28"
}
SpringBoot 整合 MongoDB实现:
@SpringBootTest
@RunWith(SpringRunner.class)
public class BeanLoadServiceTest {@Autowiredprivate MongoTemplate mongoTemplate;@Testpublic void testAggregate(){// project 阶段ProjectionOperation project = Aggregation.project().andExclude("isbn","title");// 组合阶段Aggregation aggregation = Aggregation.newAggregation(project);// 执行聚合AggregationResults<AggregationResult> aggregationResults = mongoTemplate.aggregate(aggregation, Book.class, AggregationResult.class);List<AggregationResult> mappedResults = aggregationResults.getMappedResults();// 打印结果mappedResults.forEach(System.out::println);// AggregationResult(_id=1, title=null, isbn=null, author=AggregationResult.Author(last=zzz, first=aaa), copies=5, lastModified=2016-07-28)}
}
4. 不能同时指定包含字段和排除字段
构造测试数据:
db.books.drop()db.books.insertOne({"_id" : 1,title: "abc123",isbn: "0001122223334",author: { last: "zzz", first: "aaa" },copies: 5,lastModified: "2016-07-28"}
)
在 $project 阶段中输出文档排除 title 和 isbn 字段:
db.books.aggregate( [ { $project: { title: 0, isbn: 1 } }
] )
报错信息:
[Error] Bad projection specification, cannot include fields or add computed fields during an exclusion projection: { title: 0.0, isbn: 1.0 }
原因分析:在投影规范中,除_id字段外,不要在包含投影规范中使用排除操作。下面这样是可以的:
db.books.aggregate( [ { $project: { _id: 0, isbn: 1 } }
] )
5. 排除嵌入式文档中的指定字段
构造测试数据:
db.books.drop()db.books.insertOne({"_id" : 1,title: "abc123",isbn: "0001122223334",author: { last: "zzz", first: "aaa" },copies: 5,lastModified: "2016-07-28"}
)
以下 $project 阶段中输出文档排除 author.first 和 lastModified 字段:
db.books.aggregate( [ { $project: { "author.first": 0, lastModified: 0 } }
] )
{"_id": 1,"title": "abc123","isbn": "0001122223334","author": {"last": "zzz"},"copies": 5
}
6. 包含嵌入式文档中的指定字段
构造测试数据:
db.books.drop()db.books.insertMany([{ _id: 1, user: "1234", stop: { title: "book1", author: "xyz", page: 32 } },{_id: 2, user: "7890", stop: [ { title: "book2", author: "abc", page: 5 }, { title: "book3", author: "ijk", page: 100 } ] }]
)
以下 $project 阶段仅包含嵌入式文档中的 title 字段:
db.books.aggregate( [ { $project: { "stop.title": 1 } }
] )
// 1
{"_id": 1,"stop": {"title": "book1"}
}// 2
{"_id": 2,"stop": [{"title": "book2"},{"title": "book3"}]
}
7. 添加新字段
构造测试数据:
db.books.drop()db.books.insertOne({"_id" : 1,title: "abc123",isbn: "0001122223334",author: { last: "zzz", first: "aaa" },copies: 5}
)
以下 $project 阶段添加新字段 isbn、lastName 和 copiesSold:
db.books.aggregate([{$project: {title: 1,isbn: {prefix: { $substr: [ "$isbn", 0, 3 ] },group: { $substr: [ "$isbn", 3, 2 ] },publisher: { $substr: [ "$isbn", 5, 4 ] },title: { $substr: [ "$isbn", 9, 3 ] },checkDigit: { $substr: [ "$isbn", 12, 1] }},lastName: "$author.last",copiesSold: "$copies"}}]
)
{"_id": 1,"title": "abc123","isbn": {"prefix": "000","group": "11","publisher": "2222","title": "333","checkDigit": "4"},"lastName": "zzz","copiesSold": 5
}
8. 重命名字段
构造测试数据:
db.books.drop()db.books.insertOne({"_id" : 1,title: "abc123",isbn: "0001122223334",author: { last: "zzz", first: "aaa" },copies: 5}
)
以下 $project 阶段将字段 copies重命名为 copiesSold :
db.books.aggregate([{$project: {title: 1,copiesSold: "$copies"}}]
)
{"_id": 1,"title": "abc123","copiesSold": 5
}
SpringBoot 整合MongoDB实现:
// 输入文档
@Data
@Document(collection = "books")
public class Book {private int _id;private String title;private String isbn;private Author author;private int copies;private String lastModified;@Datapublic static class Author {private String last;private String first;}
}// 输出文档
@Data
public class AggregationResult {private int _id;private String title;private String isbn;private Author author;private int copiesSold;private String lastModified;@Datapublic static class Author {private String last;private String first;}
}// 聚合操作
@SpringBootTest
@RunWith(SpringRunner.class)
public class BeanLoadServiceTest {@Autowiredprivate MongoTemplate mongoTemplate;@Testpublic void testAggregate(){// project 阶段ProjectionOperation project = Aggregation.project("title").and("copies").as("copiesSold");// 组合阶段Aggregation aggregation = Aggregation.newAggregation(project);// 执行聚合AggregationResults<AggregationResult> aggregationResults = mongoTemplate.aggregate(aggregation, Book.class, AggregationResult.class);List<AggregationResult> mappedResults = aggregationResults.getMappedResults();// 打印结果mappedResults.forEach(System.out::println);// AggregationResult(_id=1, title=abc123, isbn=null, author=null, copiesSold=5, lastModified=null)}
}
相关文章:

MongoDB - 聚合阶段 $count、$skip、$project
文章目录 1. $count 聚合阶段2. $skip 聚合阶段3. $project 聚合阶段1. 包含指定字段2. 排除_id字段3. 排除指定字段4. 不能同时指定包含字段和排除字段5. 排除嵌入式文档中的指定字段6. 包含嵌入式文档中的指定字段7. 添加新字段8. 重命名字段 1. $count 聚合阶段 计算匹配到…...
)
如何获取文件缩略图(C#和C++实现)
在C中,可以有以下两种办法 使用COM接口IThumbnailCache 文档链接:IThumbnailCache (thumbcache.h) - Win32 apps | Microsoft Learn 示例代码如下: VOID GetFileThumbnail(PCWSTR path) {HRESULT hr CoInitialize(nullptr);IShellItem* i…...

create-vue项目的README中文版
使用方法 要使用 create-vue 创建一个新的 Vue 项目,只需在终端中运行以下命令: npm create vuelatest[!注意] (latest 或 legacy) 不能省略,否则 npm 可能会解析到缓存中过时版本的包。 或者,如果你需要支持 IE11,你…...
Centos 7系统(最小化安装)安装Git 、git-man帮助、补全git命令-详细文章
安装之前由于是最小化安装centos7安装一些开发环境和工具包 文章使用国内阿里源 cd /etc/yum.repos.d/ && mkdir myrepo && mv * myrepo&&lscurl -O https://mirrors.aliyun.com/repo/epel-7.repo;curl -O https://mirrors.aliyun.com/repo/Centos-7…...
Golang零基础入门课_20240726 课程笔记
视频课程 最近发现越来越多的公司在用Golang了,所以精心整理了一套视频教程给大家,这个只是其中的第一部,后续还会有很多。 视频已经录制完成,完整目录截图如下: 课程目录 01 第一个Go程序.mp402 定义变量.mp403 …...

杂记-镜像
-i https://pypi.tuna.tsinghua.edu.cn/simple 清华 pip intall 出现 error: subprocess-exited-with-error 错误的解决办法———————————pip install --upgrade pip setuptools57.5.0 ————————————————————————————————————…...

如何将WordPress文章中的外链图片批量导入到本地
在使用采集软件进行内容创作时,很多文章中的图片都是远程链接,这不仅会导致前端加载速度慢,还会在微信小程序和抖音小程序中添加各种域名,造成管理上的麻烦。特别是遇到没有备案的外链,更是让人头疼。因此,…...

primetime如何合并不同modes的libs到一个lib文件
首先,用primetime 抽 timing model 的指令如下。 代码如下(示例): #抽lib时留一些margin, setup -max/hold -min set_extract_model_margin -port [get_ports -filter "!defined(clocks)"] -max 0.1 #抽lib extract_mod…...
【运维笔记】数据库无法启动,数据库炸后备份恢复数据
事情起因 在做docker作业的时候,把卷映射到了宿主机原来的mysql数据库目录上,宿主机原来的mysql版本为8.0,docker容器版本为5.6,导致翻车。 具体操作 备份目录 将/var/lib/mysql备份到~/mysql_backup:cp /var/lib/…...
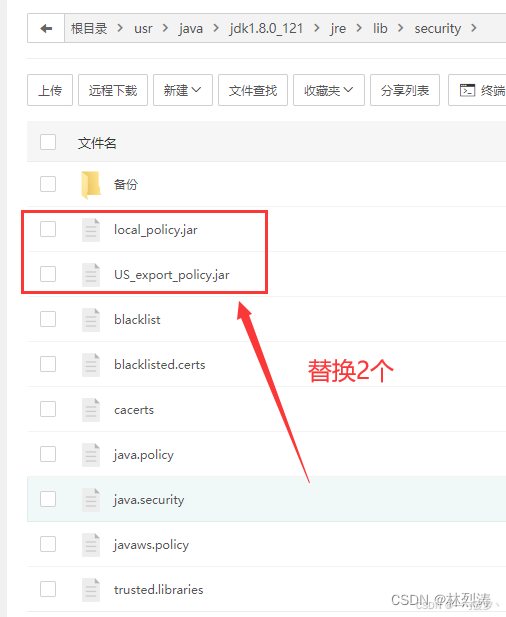
成功解决:java.security.InvalidKeyException: Illegal key size
在集成微信支付到Spring Boot项目时,可能会遇到启动报错 java.security.InvalidKeyException: Illegal key size 的问题。这是由于Java加密扩展(JCE)限制了密钥的长度。幸运的是,我们可以通过简单的替换文件来解决这个问题。 解决…...
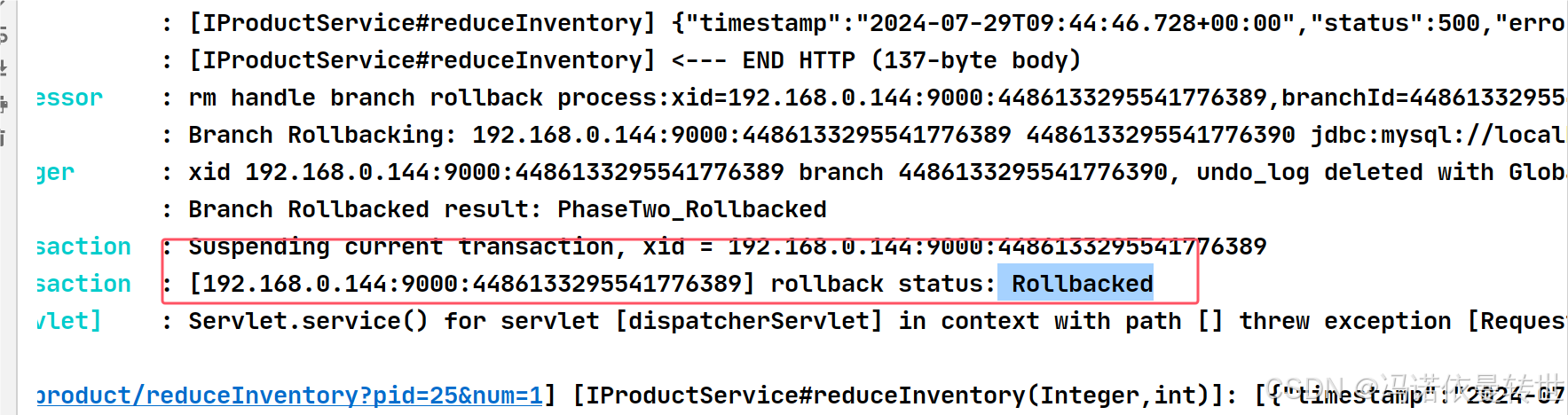
微服务事务管理(分布式事务问题 理论基础 初识Seata XA模式 AT模式 )
目录 一、分布式事务问题 1. 本地事务 2. 分布式事务 3. 演示分布式事务问题 二、理论基础 1. CAP定理 1.1 ⼀致性 1.2 可⽤性 1.3 分区容错 1.4 ⽭盾 2. BASE理论 3. 解决分布式事务的思路 三、初识Seata 1. Seata的架构 2. 部署TC服务 3. 微服务集成Se…...
—— fiddler的工作原理)
测试面试宝典(三十五)—— fiddler的工作原理
Fiddler 是一款强大的 Web 调试工具,其工作原理主要基于代理服务器的机制。 首先,当您在计算机上配置 Fiddler 为系统代理时,客户端(如浏览器)发出的所有 HTTP 和 HTTPS 请求都会被导向 Fiddler。 Fiddler 接收到这些…...

旷野之间32 - OpenAI 拉开了人工智能竞赛的序幕,而Meta 将会赢得胜利
他们通过故事做到了这一点(Snapchat 是第一个)他们用 Reels 实现了这个功能(TikTok 是第一个实现这个功能的)他们正在利用人工智能来实现这一点。 在人工智能竞赛开始时,Meta 的人工智能平台的表现并没有什么特别值得…...
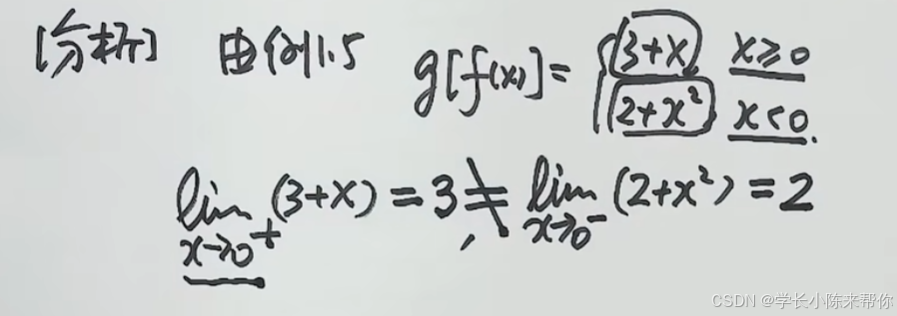
机械学习—零基础学习日志(高数15——函数极限性质)
零基础为了学人工智能,真的开始复习高数 这里我们将会学习函数极限的性质。 唯一性 来一个练习题: 再来一个练习: 这里我问了一下ChatGPT,如果一个值两侧分别趋近于正无穷,以及负无穷。理论上这个极限值应该说是不存…...

树 形 DP (dnf序)
二叉搜索子树的最大键值 /*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(null…...

React的生命周期?
React的生命周期分为三个主要阶段:挂载(Mounting)、更新(Updating)和卸载(Unmounting)。 1、挂载(Mounting) 当组件实例被创建并插入 DOM 时调用的生命周期方法&#x…...
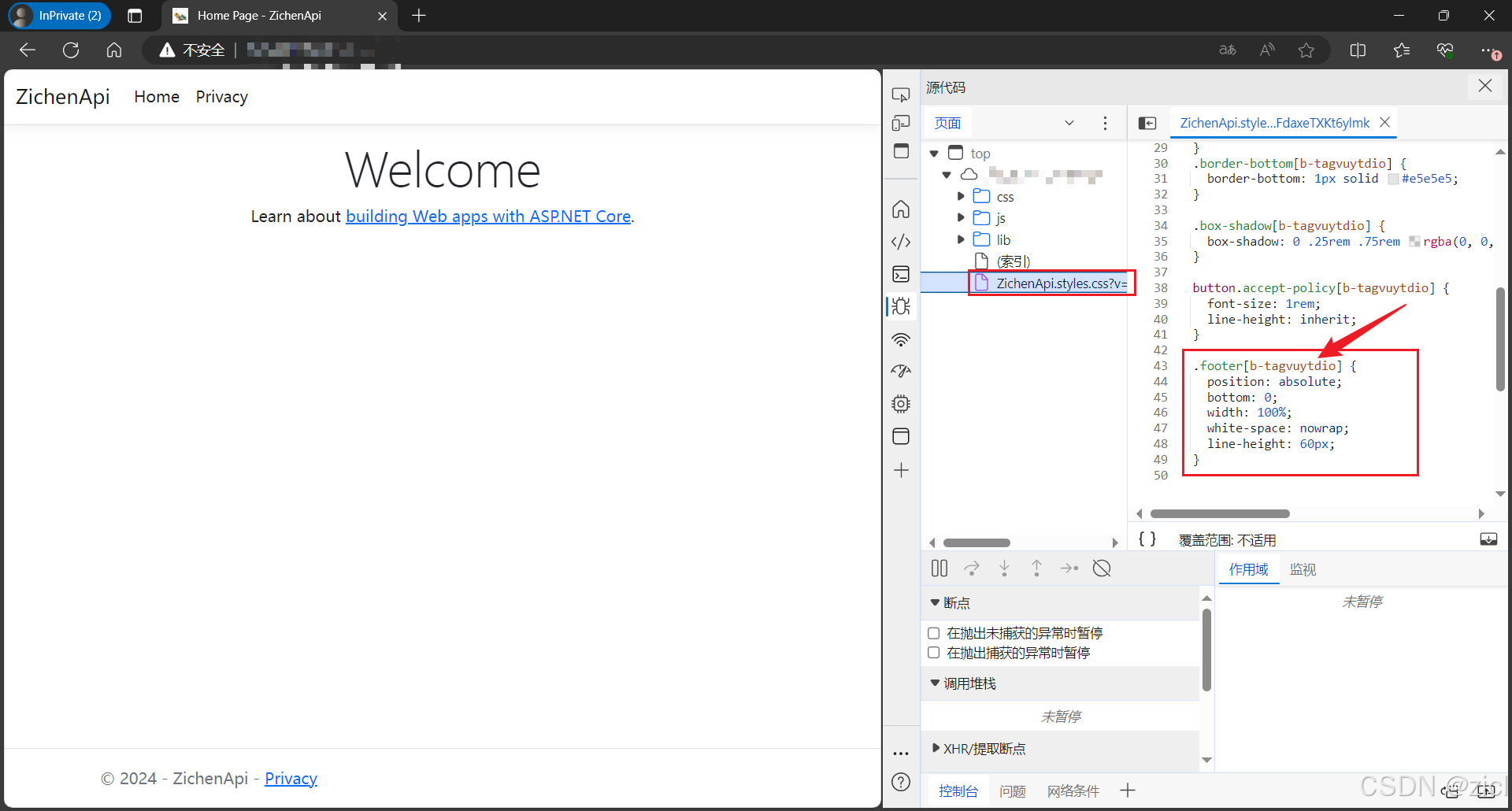
c# - - - ASP.NET Core 网页样式丢失,样式不对
c# - - - ASP.NET Core 网页样式丢失,样式不对 问题 正常样式是这样的。 修改项目名后,样式就变成这样了。底部的内容跑到中间了。 解决 重新生成解决方案,然后发布网站。 原因: 修改项目名之前的 div 上有个这个自定义属…...

Cannot find module ‘html-webpack-plugin
当你在使用Webpack构建项目时遇到Cannot find module html-webpack-plugin这样的错误,这意味着Webpack在构建过程中找不到html-webpack-plugin模块。要解决这个问题,你需要确保已经正确安装了html-webpack-plugin模块,并且在Webpack配置文件中…...

vue、react部署项目的 hashRouter 和 historyRouter模式
Vue 项目 使用 hashRouter 如果你使用的是 hashRouter,通常不需要修改 base,因为 hashRouter 使用 URL 的哈希部分来管理路由,这部分不会被服务器处理。你只需要确保 publicPath 设置正确即可。 使用 historyRouter 如果你使用的是 histo…...

Qt 实现抽屉效果
1、实现效果和UI设计界面 2、工程目录 3、mainwindow.h #ifndef MAINWINDOW_H #define MAINWINDOW_H#include <QMainWindow> #include <QToolButton> #include <QPushButton> #include <vector> using namespace std;QT_BEGIN_NAMESPACE namespace…...

WordPress开发工具链配置:IDE集成与CI/CD自动化
WordPress开发工具链配置:IDE集成与CI/CD自动化 【免费下载链接】WordPress-Coding-Standards PHP_CodeSniffer rules (sniffs) to enforce WordPress coding conventions 项目地址: https://gitcode.com/gh_mirrors/wo/WordPress-Coding-Standards WordPres…...

Asian Beauty Z-Image Turbo商业应用:快速生成品牌宣传东方形象照
Asian Beauty Z-Image Turbo商业应用:快速生成品牌宣传东方形象照 大家好,今天我们来聊一个对品牌方、市场人员和内容创作者特别有吸引力的工具——Asian Beauty Z-Image Turbo。如果你正在为品牌宣传、社交媒体内容或营销活动寻找高质量的东方形象照&a…...
3步打造个性化Windows任务栏:轻量级桌面美化工具TranslucentTB使用指南
3步打造个性化Windows任务栏:轻量级桌面美化工具TranslucentTB使用指南 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 你是否…...

seo综合查询工具和网站分析工具有什么区别_seo综合查询工具如何分析网站关键词排名
SEO综合查询工具和网站分析工具有什么区别 在当今的数字营销环境中,SEO(搜索引擎优化)工具是企业和营销人员提升网站排名的关键。其中,SEO综合查询工具和网站分析工具虽然都在帮助提升网站的搜索引擎排名,但它们之间有…...

Qwen2.5-VL-7B-Instruct多模态实战:产品包装图→成分识别→过敏原标注→合规建议
Qwen2.5-VL-7B-Instruct多模态实战:产品包装图→成分识别→过敏原标注→合规建议 1. 这不是普通OCR,是能“读懂”包装的AI助手 你有没有遇到过这样的场景:手头有一张进口食品的包装图,密密麻麻全是外文成分表,想快速…...

Obsidian-skills日志系统:如何记录和分析AI技能使用情况
Obsidian-skills日志系统:如何记录和分析AI技能使用情况 【免费下载链接】obsidian-skills Agent skills for Obsidian. Teach your agent to use Markdown, Bases, JSON Canvas, and use the CLI. 项目地址: https://gitcode.com/GitHub_Trending/ob/obsidian-sk…...

FolioReaderKit文本转语音功能:如何实现TTS语音朗读的详细指南
FolioReaderKit文本转语音功能:如何实现TTS语音朗读的详细指南 【免费下载链接】FolioReaderKit 📚 A Swift ePub reader and parser framework for iOS. 项目地址: https://gitcode.com/gh_mirrors/fo/FolioReaderKit 📚 FolioReader…...
)
DeepSeek LeetCode 1210. 穿过迷宫的最少移动次数 public int minimumMoves(int[][] grid)
我来分析 LeetCode 1210 “穿过迷宫的最少移动次数” 的解题思路和实现。 问题分析 我们有一条长度为 2 的蛇,需要从起点 (0,0) 和 (0,1)(水平放置)移动到终点 (n-1, n-2) 和 (n-1, n-1)(仍为水平放置)。蛇可以&#x…...

JavaScript中类的装饰器提案在属性与方法上的应用
JavaScript类装饰器处于TC39 Stage 3提案阶段,未标准化但Babel/TS已实验支持;方法装饰器接收target、propertyKey、descriptor,可增强行为;属性装饰器无统一签名,TS常用Reflect元数据;装饰器静态执行、不可…...
)
SEO_2024年最新SEO趋势与实战操作指南(313 )
2024年最新SEO趋势分析:揭秘百度收录的核心要点 在数字营销的快速发展中,SEO(搜索引擎优化)始终是网站运营者和内容创作者关注的重点。尤其是在中国市场,百度作为主流搜索引擎,其优化策略和趋势更是需要深…...