ThreadLocal详解及ThreadLocal源码分析
提示:ThreadLocal详解、ThreadLocal与synchronized的区别、ThreadLocal的优势、ThreadLocal的内部结构、ThreadLocalMap源码分析、ThreadLocal导致内存泄漏的原因、要避免内存泄漏可以用哪些方式、ThreadLocal怎么解决Hash冲突问题、避免共享的设计模式、ThreadLocal的场景面试题、并发编程的相关设计
文章目录
- 前言
- 一、ThreadLoacl介绍
- 1、什么是ThreadLocal
- 2、基本使用
- 3、使用案例
- 3.1、不使用ThreadLocal(存在并发问题)
- 3.2、使用ThreadLocal
- 4、ThreadLocal与synchronized的区别?
- 4.1、synchronized代码
- 4.2、ThreadLocal代码
- 5、ThreadLocal的优势
- 6、ThreadLocal在spring事务中的应用
- 二、底层原理
- 1、ThreadLocal的内部结构
- 2、这样设计的好处?
- 3、ThreadLocalMap源码分析
- 4、ThreadLocal怎么解决Hash冲突问题(源码角度)?
- 4.1、threadLocal的set方法源码:
- 4.2、threadLocal的set方法
- 三、ThreadLocal的场景面试题
- 1、ThreadLocal导致内存泄漏的原因?
- 2、那明明是弱引用,也会有内存泄漏的问题,为何还要用弱引用呢?
- 3、要避免内存泄漏可以用哪些方式?
- 四、避免共享的设计模式
- 1、不变性模式
- 1.1、概念
- 2、不变性模式的好处:
- 3、如何实现不可变性:
- 2、写时复制模式
- 3、线程本地存储模式(Thread-Specific Storag)
- 总结
前言
ThreadLocal是并发编程中的一块内容, 工作中也有一定的使用频率,今天与大家一起探讨一下ThreadLocal的源码,同时也为自己以后的查阅提供一些资料。本人水平有限,如有误导,欢迎斧正,一起学习,共同进步!
一、ThreadLoacl介绍
1、什么是ThreadLocal
官方文档:ThreadLocal类用来提供线程内部的局部变量。这种变量在多线程环境下访问(通过get、set方法访问)时能保证各个线程的变量相对独立于其他线程内的变量。ThreadLocal实例通常来说都是private static类型的,用于关联线程和线程上下文。
特性:
- 线程安全:在多线程并发的场景下保证线程安全
- 传递数据:我们可以通过ThreadLocal在同一线程,不同组件中传递公共变量
- 线程隔离:每个线程的变量都是独立的,不会互相影响。
2、基本使用
在使用前,我们先来认识几个ThreadLocal的常用方法
| 方法声明 | 描述 |
|---|---|
| ThreadLocal() | 创建ThreadLocal对象 |
| public void set(T value) | 设置当前线程绑定的局部变量 |
| public T get() | 获取当前线程绑定的局部变量 |
| public void remove() | 移除当前线程绑定的局部变量 |
3、使用案例
3.1、不使用ThreadLocal(存在并发问题)
因为是5个线程,操作同一个共享变量(content),所以会有并发问题。
package com.zheng.test.threadLocak;/*** @author: ztl* @date: 2024/07/07 23:08* @desc:*/
public class ThreadLocalDemo {private String content;private String getContent() {return content;}private void setContent(String content) {this.content = content;}public static void main(String[] args) {ThreadLocalDemo demo = new ThreadLocalDemo();for (int i = 0; i < 5; i++) {Thread thread = new Thread(new Runnable() {@Overridepublic void run() {demo.setContent(Thread.currentThread().getName() + "的数据");System.out.println(Thread.currentThread().getName() + "--->" +demo.getContent());}});thread.setName("线程" + i);thread.start();// 执行结果:
// 线程0--->线程1的数据
// 线程3--->线程3的数据
// 线程1--->线程1的数据
// 线程4--->线程4的数据
// 线程2--->线程2的数据}}
}3.2、使用ThreadLocal
使用ThreadLocal就不会有并发问题了,代码:
public class ThreadLocalDemo2 {private static ThreadLocal<String > threadLocal = new ThreadLocal<>();private String content;private String getContent() {return threadLocal.get();}private void setContent(String content) {threadLocal.set(content);}public static void main(String[] args) {ThreadLocalDemo2 demo = new ThreadLocalDemo2();for (int i = 0; i < 5; i++) {Thread thread = new Thread(new Runnable() {@Overridepublic void run() {demo.setContent(Thread.currentThread().getName() + "的数据");System.out.println(Thread.currentThread().getName() + "--->" +demo.getContent());}});thread.setName("线程" + i);thread.start();// 执行结果:
// 线程0--->线程0的数据
// 线程3--->线程3的数据
// 线程1--->线程1的数据
// 线程4--->线程4的数据
// 线程2--->线程2的数据}}
}4、ThreadLocal与synchronized的区别?
synchronized是独占锁,相当于串行执行了,那多线程就没啥意义了, 你执行完毕,才到我。
而ThreadLocal是并发执行,效率更高.、
| synchronized | threadLocal | |
|---|---|---|
| 原理 | 同步机制采用"以时间换空间"的方式,只提供了一份变量,让不同的线程排队访问 | 采用“以空间换时间”的方式,为每个线程都提供了一份变量的副本,从而实现同时访问而互不干扰 |
| 侧重点 | 多个线程之间访问公共资源的同步 | 多线程中让每个线程之间的数据互相隔离 |
4.1、synchronized代码
synchronized代码如下:
public class ThreadLocalDemo3 {private String content;private String getContent() {return content;}private void setContent(String content) {this.content = content;}public static void main(String[] args) {ThreadLocalDemo3 demo = new ThreadLocalDemo3();long start = System.currentTimeMillis();for (int i = 0; i < 5; i++) {Thread thread = new Thread(new Runnable() {@Overridepublic void run() {synchronized (demo){demo.setContent(Thread.currentThread().getName() + "的数据");try {Thread.sleep(2000);} catch (InterruptedException e) {e.printStackTrace();}}long end = System.currentTimeMillis();System.out.println(Thread.currentThread().getName() + "--->" +demo.getContent()+"耗时"+(end - start) + "毫秒");}});thread.setName("线程" + i);thread.start();}}
}
执行结果:
线程0—>线程4的数据耗时2013毫秒
线程4—>线程4的数据耗时4019毫秒
线程3—>线程3的数据耗时6026毫秒
线程2—>线程2的数据耗时8034毫秒
线程1—>线程1的数据耗时10041毫秒
4.2、ThreadLocal代码
ThreadLocal代码如下:
public class ThreadLocalDemo4 {private static ThreadLocal<String > threadLocal = new ThreadLocal<>();private String content;private String getContent() {return threadLocal.get();}private void setContent(String content) {threadLocal.set(content);}public static void main(String[] args) {ThreadLocalDemo4 demo = new ThreadLocalDemo4();long start = System.currentTimeMillis();for (int i = 0; i < 5; i++) {Thread thread = new Thread(new Runnable() {@Overridepublic void run() {demo.setContent(Thread.currentThread().getName() + "的数据");try {Thread.sleep(2000);} catch (InterruptedException e) {e.printStackTrace();}long end = System.currentTimeMillis();System.out.println(Thread.currentThread().getName() + "--->" +demo.getContent()+"耗时"+(end - start) + "毫秒");}});thread.setName("线程" + i);thread.start();}}
}
执行结果,就是:
线程4—>线程4的数据耗时2004毫秒
线程0—>线程0的数据耗时2004毫秒
线程2—>线程2的数据耗时2004毫秒
线程3—>线程3的数据耗时2004毫秒
线程1—>线程1的数据耗时2004毫秒
5、ThreadLocal的优势
在一些特定的场景下,ThreadLocal有两个突出的优势:
- 传递数据:保存每个线程绑定的数据,有需要的地方可以直接获取,避免参数直接传递带来的代码耦合问题
- 线程隔离:各线程之间的数据相互隔离又具备并发性,避免同步方式带来的性能损失(比如上面的synchronized,要比ThreadLocal慢的多)
6、ThreadLocal在spring事务中的应用
spring的事务就借助了ThreadLocal类。spring会从数据库连接池中获的一个connection,然后把connection放进ThreadLocal中,也就和线程绑定了,事务需要提交或者回滚,只要从ThreadLocal中拿到connection进行操作。
为何spring的事务要借助ThreadLocal类?
以下面的代码为例,主要有3个步骤:
事务准备阶段:1-3行
业务处理阶段: 4-6行
事务提交阶段: 7行
很明显,不管是事务的开启、执行具体的sql、提交事务、都是需要数据库连接(connction)的。如果我们把控制事务的代码放在dao层,那肯定是需要一个字段比如说connectionObject字段,来存储这个connection对象,毕竟我们都是需要一个数据库连接的(如何让三个DAO使用同一个数据源连接呢?我们就必须为每个DAO传递同一个数据库连接,要么就是在DAO实例化的时候作为构造方法的参数传递,要么在每个DAO的实例方法中作为方法的参数传递。)。那我们如果只调用一个dao层,这样还算合适。那如果我们要连续操作3个dao呢,30个dao呢,难道要这30个dao,每个dao中都加一个connectionObject字段,然后把这30个dao中,挨着传递下去这个connection连接吗?毕竟我们一定是要基于同一个connection连接来操作的。那要保证这30个dao一定是同一个connection,那肯定要把这个connection传递下去,如果纯代码实现的话,那必然要加一个字段,然后挨着传递下去的。这样实现,肯定是不如直接把connection存在线程的threadlocal中,然后直接从线程的threadlocal中获取,这样也不用传递,还能获得同一个connection,还没有并发问题,肯定是比代码硬写要优美的多的。
1 dbc = new DataBaseConnection();//第1行
2 Connection con = dbc.getConnection();//第2行
3 con.setAutoCommit(false);// //第3行
4 con.executeUpdate(...);//第4行
5 con.executeUpdate(...);//第5行
6 con.executeUpdate(...);//第6行
7 con.commit();第7行
web容器中,每个完整的请求周期都会由一个线程来处理。因此,如果我们能把一些参数用threadlocal绑定到线程的话,就可以实现参数共享(隐形共享),结合spring中的ioc和aop,就可以很好的解决这一点。只要将一个数据库连接放到threadLocal中,当前线程执行时,直接从threadLocal中获取,是比较方便的。
二、底层原理
1、ThreadLocal的内部结构
如果我们不去看源码的话,可能以为ThreadLocal是这么设计的:创建一个map,其中map的key是thread,v是要存的内容。jdk早期版本的threadLocal确实是这么设计的,但现在早已不是了(因为有各种缺点,也就是后面设计方案的优点)。
在jdk8中,ThreadLocal的设计是:每个Thread都维护一个自己的ThreadLocalMap,这个map的key是ThreadLocal实例本身,value是真正要存储的值Object,具体的过程:
- 每个Thread线程内部都有一个Map(ThreadLocalMap)
- Map中存储ThreadLocal对象(key)和线程的变量副本(value)
- Thread内部的Map是由ThreadLocal维护的,由ThreadLocal负责像map获取和设置线程的变量值
- 对于不同的线程,每次获取副本时,别的线程并不能获取到当前线程的副本值,形成了副本的隔离,互补干扰。

2、这样设计的好处?
- threadLocal存的数据(entity)会变小。同时防止了大的对象。按最开始的设计方案:我有一个大的Map,key是线程,v是数据。那来一个线程,我就得存一个线程,再来一个线程,我在存第二个。。那100个线程,1000个线程,我同时存1000份的key、value,那这个对象也太大了。然后存的entity也太多了。但是如果分开的话,是每个线程都有自己独立的threadLocal,最起码不会有大的Map对象。而且我用到了threadLocal才有,不用就没有。
- 减少内存的使用。还有一个好处就是,我存储到Thread内部的话,一旦Thread销毁了,那么对应的ThreadLocalMap也会随之销毁。能减少内存的使用。毕竟如果用原始的设计的话,你这个thread在threadLocalmap中添加了,添加的时候key是thread,v是数据。那你这个thread一旦被销毁了,我threadLocalMap可不会销毁,毕竟我又不是只有你一个thread,我还有别的thread呢,我总不能因为你死了,我就直接全部销毁。我还得专门去销毁你这个单独的thread,不然就浪费资源,我要是单独消耗,也好消耗我的性能,那还真不如,是在thread内部添加上threadLocalMap对象,一旦thread消耗了,那threadLocalMap也自动销毁了。
3、ThreadLocalMap源码分析
ThreadLocalMap是ThreadLocal的内部类,没有实现Map接口,用独立的方式实现了Map功能,其内部的entry也是独立实现。

entry是真正存储数据的,entry继承了WeakReference,并用ThreadLocal作为key。其目的是将threadLocal对象的生命周期和线程声明周期解绑
强引用:就是我们最常见的普通对象引用,只要还有强引用指向一个对象,就能表名对象还“活着”,垃圾回收器就不会回收这种对象
弱引用:(WeakReference),垃圾回收器一旦发现了只具有弱引用的对象,不管当前内存空间是否足够,都会回收他的内存。
4、ThreadLocal怎么解决Hash冲突问题(源码角度)?
threadLocal是通过线性探测法来解决hash冲突的。可以通过阅读源码来验证:
4.1、threadLocal的set方法源码:
public void set(T value) {Thread t = Thread.currentThread();ThreadLocalMap map = getMap(t);if (map != null)map.set(this, value);elsecreateMap(t, value);
}ThreadLocalMap getMap(Thread t) {return t.threadLocals;
}void createMap(Thread t, T firstValue) {t.threadLocals = new ThreadLocalMap(this, firstValue);
}ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {table = new Entry[INITIAL_CAPACITY];int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);table[i] = new Entry(firstKey, firstValue);size = 1;setThreshold(INITIAL_CAPACITY);
}
这个就是单纯的说,如果map不为空,则将参数设置到map中;如果map为空,则创建map,并设置初始值。
- int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1); 的意思是说,求模,来获取在map中的巢(其实就是map中的数组,对应的位置)。就比如说,101 % 16,任何数对16取模,结果一定是0-15的数据,也就是为了确定,是存到哪个节点中的。
- setThreshold(INITIAL_CAPACITY); 这个点进去就是threshold = len * 2 / 3; ,意思是,当占了2/3的空间以后,就开始扩容了。
4.2、threadLocal的set方法
map.set(this, value);(上面代码块的5行)源码:
private void set(ThreadLocal<?> key, Object value) {// We don't use a fast path as with get() because it is at// least as common to use set() to create new entries as// it is to replace existing ones, in which case, a fast// path would fail more often than not.Entry[] tab = table;int len = tab.length;int i = key.threadLocalHashCode & (len-1);for (Entry e = tab[i];e != null;e = tab[i = nextIndex(i, len)]) {ThreadLocal<?> k = e.get();if (k == key) {e.value = value;return;}if (k == null) {replaceStaleEntry(key, value, i);return;}}tab[i] = new Entry(key, value);int sz = ++size;if (!cleanSomeSlots(i, sz) && sz >= threshold)rehash();
}
上面这段的意思,简单的说就是:
- 没元素,直接插入
- 有元素,判断key相等不相等,不相等,就往后移一位,看有元素没,没元素直接插入,
- 有元素,key相等,直接覆盖
e = tab[i = nextIndex(i, len)]) { 上面代码中的这行点击去就是:
private static int nextIndex(int i, int len) {return ((i + 1 < len) ? i + 1 : 0);
}
也就是说,他是个环形数组: 如果数组的当前位置+1到达了数组的最后,那么就返回0(数组的第一个位置);如果数组的当前位置+1还没达到数组的最后,那么就往后移动一位。也就是,这是一个收尾相连的数组。从这里,我们可以看出来:他是通过线性探测法去解决hash冲突的。毕竟冲突了以后他往后移动一位继续比较,有位置就塞进去,没位置就继续往后走,可不就是线性探测法嘛。
三、ThreadLocal的场景面试题
1、ThreadLocal导致内存泄漏的原因?
从下面的图可以看出来: 当前线程指向map,map指向entry,entry中的key指向ThreadLocal,entry的v指向自己的my value。一旦触发了垃圾回收,key与ThreadLocal之间的引用是弱引用,直接回收了;但map跟entry之间是强引用,entry的v和v的内容之间也是强引用(v和v的内容的强引用是导致内存泄漏的真实原因)。其实要想内存泄漏,必须满足两点:
- 没有手动删除这个entry
- 当前线程(currentThread)仍在执行。因为我们很可能使用线程池之类的技术,导致这个线程一直都没结束。 总结一下,ThreadLocal内存泄漏的根源是:由于ThreadLocalMap的生命周期和Thread一样长,如果没有手动删除对应的key就会导致内存泄漏。
那怎么解决这种内存泄漏呢?:每次用完threadLocal,都给remove掉对应的threadLocal就行。

2、那明明是弱引用,也会有内存泄漏的问题,为何还要用弱引用呢?
- 如果是弱引用的话,是只有entry中的v会有内存泄漏,一旦我用强引用的话,我entry中的key也会有内存泄漏的问题的。能优化一点是一点,肯定是用弱引用啊。而且ThreadLocalMap中的set/getEntry方法中,会对key为null(也就是ThreadLocal为null,就是弱引用被gc掉的那个)进行判断,如果为null的话,那么会对value置为null的。
- 比用强引用来说,多一层保障:弱引用的threadLocal会被回收,对应的value在下一次ThreadLocalMap调用get、set、remove任一方法的时候会被清除。
3、要避免内存泄漏可以用哪些方式?
- 使用完ThreadLocal,调用其remove方法删除对应的entry
- 使用完threadLocal,当前的thread也随之运行结束。
相比于第一种方式,第二种方式更不好控制,特别是使用线程池的时候,线程结束是不会被销毁的,因此更推荐使用方式1,remove掉对应的entry。
四、避免共享的设计模式
不变性模式、写时复制模式、线程本地存储模式,都可以避免共享。
- 使用时需要注意不变形模式的属性不可变性
- 写时复制模式需要注意拷贝的性能问题
- 线程本地存储模式需要注意异步执行问题
1、不变性模式
1.1、概念
多个线程同时读写同一个共享变量会存在并发问题。同时读写才会有问题。那我只能读,不能写,就没这个问题了。不变性模式是一种创建不可变对象的设计模式。即对象一旦创建成功后,就不能在修改。在多线程下,使用不可变对象可以避免线程安全问题,并提高程序的性能和可读性。
2、不变性模式的好处:
- 线程安全:不可变对象在多线程环境下不需要同步操作,可以避免线程安全问题
- 可读性:不可变对象在创建后不可修改,可以更加清晰的表达对象的含义和作用
- 性能:由于不可变对象的状态不可变,可以进行更有效的缓存和优化操作
- 可测试性:不可变对象对单元测试非常友好,可以更容易的进行测试和验证。
3、如何实现不可变性:
不可变性模式的主要思想是通过将对象的状态设置为final和私有,并提供只读方法来保证对象的不可变性。在创建不可变对象时,需要确保对象的所有属性都是不可变的,在创建后不会被修改,同时还需要注意不可变对象间的引用关系,以避免出现对象的状态变化。
jdk中很对类都具备不可变性,例如:Sting和Long、Integer、Double 等基础类型的包装类都具备不可变性,他们都遵循了不可变类的三点要求:类和属性都是final的,所有方法均是只读的。
2、写时复制模式
该模式的基本思想是:在共享数据被修改时,先将数据复制一份,然后对副本进行修改,最后再讲副本替换为原始的共享数据。
不可变对象的写操作往往都是通过使用Copy-on-Write方法解决的,当然,Copy-on-Write不局限于这个模式。Copy-on-Write才是最简单的并发解决方案,他是如此的简单,以至于Java中的数据类型String、Integer、Long 都是基于Copy-on-Write方案实现的。
Copy-on-Write的缺点是消耗内存。每次修改都需要复制一个新的对象,好在随着gc算法的成熟,这种内存消耗渐渐可以接收了。在实际工作中,如果读多写少的场景,可以使用Copy-on-Write。
3、线程本地存储模式(Thread-Specific Storag)
该模式的基本思想的为每个线程创建独立的存储空间,用于存储线程私有的数据。ThreadLocal类实现了该模式。
如果你在并发场景中使用一个线程不安全的工具,最简单的方案就是避免共享。避免共享有两种方案,一种方案是将这个类作为局部变量使用,另一种方案就是线程本地存储模式。局部变量的方案的缺点是在高并发场景下会频繁创建对象,而现场本地存储方案,每个线程值需要创建一个工具类的实例,所以不存在频繁创建对象的问题,
线程本地存储通常用于以下场景
- 保存上下文信息:在多线程环境中,每个线程都有自己的执行上下文,包括线程的状态、环境变量、运行时状态等。
- 管理线程安全对象:在多线程环境中,共享对象通常需要同步操作以避免竞争条件,但是有些对象多线程安全的么可以被多个线程同时访问而不需要同步操作。线程本地存储可以用来管理这些线程安全对象,使得每个线程都可以独立的访问自己的对象实例,而不需要进行同步操作。
- 实现线程的特定的行文:优先应用程序需要再每个线程中执行特定的行为,比如记录日志、统计数据、授权访问等。线程本地存储可以实现这个线程的特定行为,而不需要跟其他线程进行协调
总结
有时候我们阅读源码,不单单是为了看他的源码是啥样的,更多的是给我们扩展了视野,以后工作中遇到类似的问题,可能有一个新的解决方案或是方向,来帮助我们更好更快的解决各种问题。
相关文章:
ThreadLocal详解及ThreadLocal源码分析
提示:ThreadLocal详解、ThreadLocal与synchronized的区别、ThreadLocal的优势、ThreadLocal的内部结构、ThreadLocalMap源码分析、ThreadLocal导致内存泄漏的原因、要避免内存泄漏可以用哪些方式、ThreadLocal怎么解决Hash冲突问题、避免共享的设计模式、ThreadLoca…...
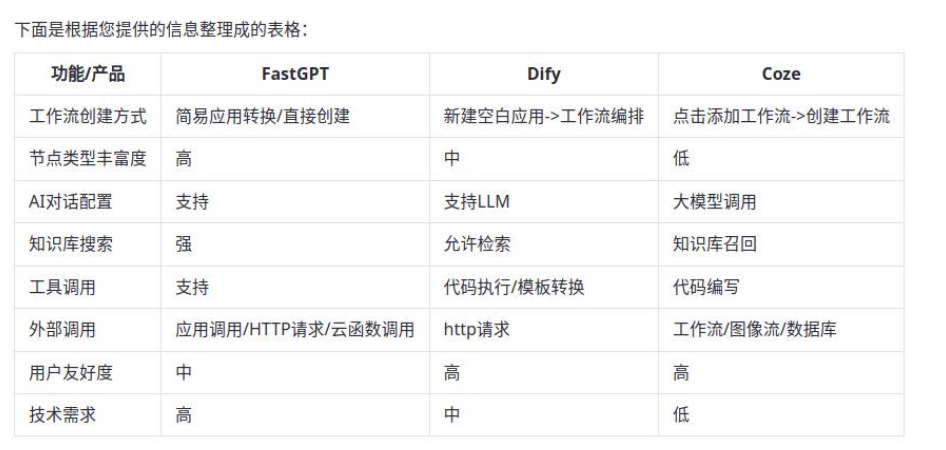
FastGPT、Dify、Coze产品功能对比分析
在当前的人工智能领域,模型接入、应用发布、应用构建、知识库和工作流编排等功能是衡量一个AI平台综合能力的重要指标。本文将对FastGPT、Dify和Coze这三款产品的功能进行详细对比分析,以帮助用户更好地了解它。 订阅模式及市场概况 在订阅模式及市场概…...

【Linux】缓冲区的理解
目录 一、实验现象二、初步认知缓冲区2.1 缓冲区的刷新策略2.2 缓冲区在哪里 三、缓冲区模拟实现四、再次全面理解缓冲区4.1 用户强制刷新缓冲区(fflush/fsync) 一、实验现象 我们先来看一个现象: 在显示器中打印内容时,fprintf先打印出来,w…...

基于单片机的电梯控制系统的设计
摘 要: 本文提出了一种基于单片机的电梯控制系统设计 。 设计以单片机为核心,通过使用和设计新型先进的硬件和控制程序来模拟和控制整个电梯的运行,在使用过程中具有成本低廉、 维护方便、 运行稳定 、 易于操作 、 安全系数高等优点 。 主要设计思路是…...

IP-GUARD文档云备份服务器迁移数据操作说明
一、功能简介 使用文档云备份过程可能出现需要迁移旧数据到新目录的情况(如一开始存储目录设置 不合理,之后变更存储目录),下面介绍迁移备份数据到新目录的方法,迁移后可正常查看、 下载、删除原备份文件。 二、同一计算机上迁移存储目录 当仅需要将存储目录迁移到同一计…...

linux常用命令ls详细说明
目录 1.ls的基本功能就是显示当前目录的文件和目录 2.ls输出是按照字母顺序排列的 3.默认不显示隐藏内容,加上参数-a可以显示隐藏的文件和文件夹 4.-R参数可以地柜列出当前目录以及它包含的字目录中的文件 5.-l参数辉显示长列表,也可以显示文件更多信…...
数据的存储)
Python3网络爬虫开发实战(4)数据的存储
文章目录 一、文本文件存储1. os 文件 mode2. TXT3. JSON4. CSV 二、数据库存储1. SQLAlchemy2. MongoDB3. Redis1) 键操作2) 字符串操作3) 列表操作4) 集合操作5) 有序集合操作6) 散列操作 4. Elasticsearch1) 检索数据:利用 elasticsearch-analysis-ik 进行分词2)…...

《C++基础入门与实战进阶》专栏介绍
🚀 前言 本文是《C基础入门与实战进阶》专栏的说明贴(点击链接,跳转到专栏主页,欢迎订阅,持续更新…)。 专栏介绍:以多年的开发实战为基础,总结并讲解一些的C/C基础与项目实战进阶内…...
- 数据清洗)
每天一个数据分析题(四百五十)- 数据清洗
数据在真正被使用前需进行必要的清洗,使脏数据变为可用数据。下列不属于“脏数据”的是() A. 重复数据 B. 错误数据 C. 交叉数据 D. 缺失数据 数据分析认证考试介绍:点击进入 题目来源于CDA模拟题库 点击此处获取答案 数据…...

昇思25天学习打卡营第XX天|Pix2Pix实现图像转换
Pix2Pix是一种基于条件生成对抗网络(cGAN)的图像转换模型,由Isola等人在2017年提出。它能够实现多种图像到图像的转换任务,如从草图到彩色图像、从白天到夜晚的场景变换等。与传统专用机器学习方法不同,Pix2Pix提供了一…...

数据结构经典测试题5
1. int main() { char arr[2][4]; strcpy (arr[0],"you"); strcpy (arr[1],"me"); arr[0][3]&; printf("%s \n",arr); return 0; }上述代码输出结果是什么呢? A: you&me B: you C: me D: err 答案为A 因为arr是一个2行4列…...

React Native初次使用遇到的问题
Write By Monkeyfly 以下内容均为原创,如需转载请注明出处。 前提:距离上次写博文已经过去了5年之久,诸多原因导致的,写一篇优质博文确实费时费力,中间有其他更感兴趣的事要做(打游戏、旅游、逛街、看电影…...

2024西安铁一中集训DAY28 ---- 模拟赛(简单dp + 堆,模拟 + 点分治 + 神秘dp)
文章目录 前言时间安排及成绩题解A. 江桥不会做的签到题(简单dp)B. 江桥树上逃(堆,模拟)C. 括号平衡路径(点分治)D. 回到起始顺序(dp,组合数学) 前言 T2好难…...

【论文阅读笔记 + 思考 + 总结】MoMask: Generative Masked Modeling of 3D Human Motions
创新点: VQ-VAE 👉 Residual VQ-VAE,对每个 motion sequence 输出一组 base motion tokens 和 v 组 residual motion tokensbidirectional 的 Masked transformer 用来生成 base motion tokensResidual Transformer 对 residual motion toke…...

Mojo控制语句详解
Mojo 包含几个传统的控制流结构,用于有条件和重复执行代码块。 The if statement Mojo 支持条件代码执行语句。有了它,当给定的布尔表达式计算结果为 时,if您可以有条件地执行缩进的代码块 。True temp_celsius = 25 if temp_celsius > 20:print("It is warm.&quo…...

web安全基础学习
http基础 HTTP(HyperText Transfer Protocol,超文本传输协议)是一种用于分布式、协作式和超媒体信息系统的应用层协议。本文将介绍如何使用HTTP协议,以及在Linux操作系统中如何使用curl工具发起HTTP请求。 一、HTTP特性 无状态…...

天气预报的爬虫内容打印并存储用户操作
系统名称: 基于网络爬虫技术的天气数据查询系统文档作者:清馨创作时间:2024-7-29最新修改时间:2024-7-29最新版本号: 1.0 1.背景描述 该系统将基于目前比较流行的网络爬虫技术,对网站上(NowAPI…...
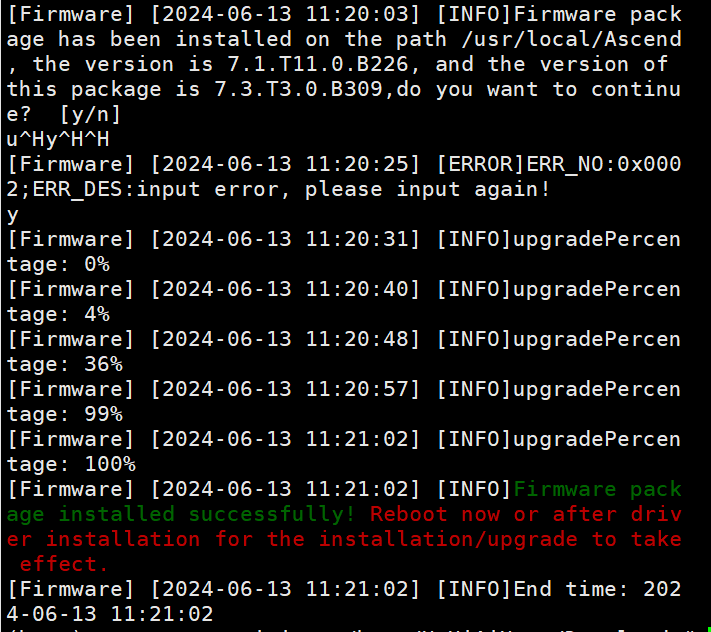
OrangePi AI Pro 固件升级 —— 让主频从 1.0 GHz 到 1.6 GHz 的巨大升级
前言 OrangePi AI Pro 最近发布了Ascend310B-firmware 固件包,据说升级之后可以将 CPU 主频从 1.0 GHz 提升至 1.6 GHz,据群主大大说,算力也从原本的 8T 提升到了 12T,这波开发板的成长让我非常的 Amazing 啊!下面就来…...

学习大数据DAY27 Linux最终阶段测试
满分:100 得分:72 目录 一选择题(每题 3 分,共计 30 分) 二、编程题(共 70…...

ctr管理containerd基本命令
1. 创建命名空间 创建名为custom的命令空间 ctr ns create custom2. 导入镜像 把镜像导入到刚刚创建的空间 ctr -n custom images improt restfulapi.tar3. 创建容器 创建一个test_api的容器 ctr -n custom run --null-io --net-host -d --mount typebind,src/etc,dst/ho…...

springboot 百货中心供应链管理系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,百货中心供应链管理系统被用户普遍使用,为方…...

深入解析C++中的extern关键字:跨文件共享变量与函数的终极指南
🚀 C extern 关键字深度解析:跨文件编程的终极指南 📅 更新时间:2025年6月5日 🏷️ 标签:C | extern关键字 | 多文件编程 | 链接与声明 | 现代C 文章目录 前言🔥一、extern 是什么?&…...

接口自动化测试:HttpRunner基础
相关文档 HttpRunner V3.x中文文档 HttpRunner 用户指南 使用HttpRunner 3.x实现接口自动化测试 HttpRunner介绍 HttpRunner 是一个开源的 API 测试工具,支持 HTTP(S)/HTTP2/WebSocket/RPC 等网络协议,涵盖接口测试、性能测试、数字体验监测等测试类型…...

WEB3全栈开发——面试专业技能点P7前端与链上集成
一、Next.js技术栈 ✅ 概念介绍 Next.js 是一个基于 React 的 服务端渲染(SSR)与静态网站生成(SSG) 框架,由 Vercel 开发。它简化了构建生产级 React 应用的过程,并内置了很多特性: ✅ 文件系…...
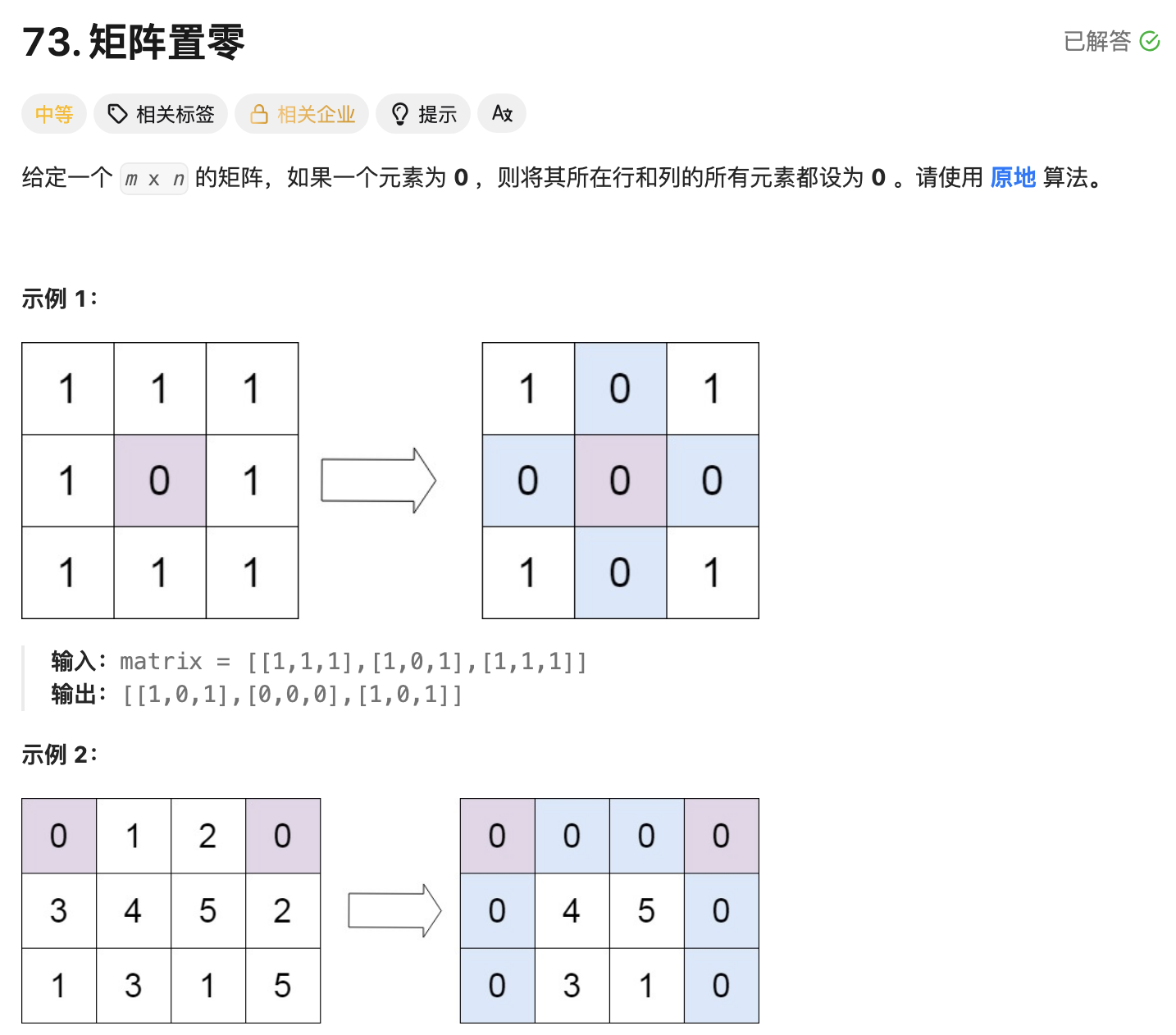
leetcode73-矩阵置零
leetcode 73 思路 记录 0 元素的位置:遍历整个矩阵,找出所有值为 0 的元素,并将它们的坐标记录在数组zeroPosition中置零操作:遍历记录的所有 0 元素位置,将每个位置对应的行和列的所有元素置为 0 具体步骤 初始化…...

HTML中各种标签的作用
一、HTML文件主要标签结构及说明 1. <!DOCTYPE html> 作用:声明文档类型,告知浏览器这是 HTML5 文档。 必须:是。 2. <html lang“zh”>. </html> 作用:包裹整个网页内容,lang"z…...

aurora与pcie的数据高速传输
设备:zynq7100; 开发环境:window; vivado版本:2021.1; 引言 之前在前面两章已经介绍了aurora读写DDR,xdma读写ddr实验。这次我们做一个大工程,pc通过pcie传输给fpga,fpga再通过aur…...
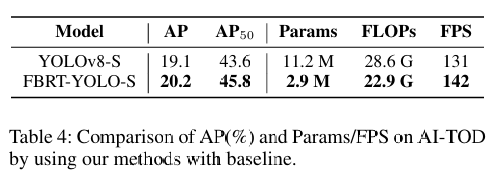
Yolo11改进策略:Block改进|FCM,特征互补映射模块|AAAI 2025|即插即用
1 论文信息 FBRT-YOLO(Faster and Better for Real-Time Aerial Image Detection)是由北京理工大学团队提出的专用于航拍图像实时目标检测的创新框架,发表于AAAI 2025。论文针对航拍场景中小目标检测的核心难题展开研究,重点解决…...

Go 并发编程基础:select 多路复用
select 是 Go 并发编程中非常强大的语法结构,它允许程序同时等待多个通道操作的完成,从而实现多路复用机制,是协程调度、超时控制、通道竞争等场景的核心工具。 一、什么是 select select 类似于 switch 语句,但它用于监听多个通…...

python3GUI--基于PyQt5+DeepSort+YOLOv8智能人员入侵检测系统(详细图文介绍)
文章目录 一.前言二.技术介绍1.PyQt52.DeepSort3.卡尔曼滤波4.YOLOv85.SQLite36.多线程7.入侵人员检测8.ROI区域 三.核心功能1.登录注册1.登录2.注册 2.主界面1.主界面简介2.数据输入3.参数配置4.告警配置5.操作控制台6.核心内容显示区域7.检…...