记录使用FlinkSql进行实时工作流开发
使用FlinkSql进行实时工作流开发
- 引言
- Flink SQL实战
- 常用的Connector
- 1. MySQL-CDC 连接器配置
- 2. Kafka 连接器配置
- 3. JDBC 连接器配置
- 4. RabbitMQ 连接器配置
- 5. REST Lookup 连接器配置
- 6. HDFS 连接器配置
- FlinkSql数据类型
- 1. 基本数据类型
- 2. 字符串数据类型
- 3. 日期和时间数据类型
- 4. 复杂数据类型
- 5. 特殊数据类型
- 数据类型的使用示例
引言

在大数据时代,实时数据分析和处理变得越来越重要。Apache Flink,作为流处理领域的佼佼者,提供了一套强大的工具集来处理无界和有界数据流。其中,Flink SQL是其生态系统中一个重要的组成部分,允许用户以SQL语句的形式执行复杂的数据流操作,极大地简化了实时数据处理的开发流程。
什么是Apache Flink?
Apache Flink是一个开源框架,用于处理无边界(无尽)和有边界(有限)数据流。它提供了低延迟、高吞吐量和状态一致性,使开发者能够构建复杂的实时应用和微服务。Flink的核心是流处理引擎,它支持事件时间处理、窗口操作以及精确一次的状态一致性。
为什么选择Flink SQL?
易用性:Flink SQL使得非专业程序员也能快速上手,使用熟悉的SQL语法进行实时数据查询和处理。
灵活性:可以无缝地将SQL与Java/Scala API结合使用,为用户提供多种编程模型的选择。
性能:利用Flink的高性能流处理引擎,Flink SQL能够实现实时响应和低延迟处理。
集成能力:支持多种数据源和数据接收器,如Kafka、JDBC、HDFS等,易于集成到现有的数据生态系统中。
Flink SQL实战
常用的Connector
在配置FlinkSQL实时开发时,使用mysql-cdc、Kafka、jdbc和rabbitmq作为连接器是一个很常见的场景。以下是详细的配置说明,你可以基于这些信息来撰写你的博客:
1. MySQL-CDC 连接器配置
MySQL-CDC(Change Data Capture)连接器用于捕获MySQL数据库中的变更数据。配置示例如下:
CREATE TABLE mysql_table (-- 定义表结构id INT,name STRING,-- 其他列
) WITH ('connector' = 'mysql-cdc', -- 使用mysql-cdc连接器'hostname' = 'mysql-host', -- MySQL服务器主机名'port' = '3306', -- MySQL端口号'username' = 'user', -- MySQL用户名'password' = 'password', -- MySQL密码'database-name' = 'db', -- 数据库名'table-name' = 'table' -- 表名'server-time-zone' = 'GMT+8', -- 服务器时区'debezium.snapshot.mode' = 'initial', -- 初始快照模式,initial表示从头开始读取所有数据;latest-offset表示从最近的偏移量开始读取;timestamp则可以指定一个时间戳,从该时间戳之后的数据开始读取。'scan.incremental.snapshot.enabled' = 'true' -- 可选,设置为true时,Flink会尝试维护一个数据库表的增量快照。这意味着Flink不会每次都重新读取整个表,而是只读取自上次读取以来发生变化的数据。这样可以显著提高读取效率,尤其是在处理大量数据且频繁更新的场景下。'scan.incremental.snapshot.chunk.size' = '1024' -- 可选, 增量快照块大小'debezium.snapshot.locking.mode' = 'none', -- 可选,控制在快照阶段锁定表的方式,以防止数据冲突。none表示不锁定,lock-tables表示锁定整个表,transaction表示使用事务来锁定。'debezium.properties.include-schema-changes' = 'true', -- 可选,如果设置为true,则在CDC事件中会包含模式变更信息。'debezium.properties.table.whitelist' = 'mydatabase.mytable', -- 可选,指定要监控的表的白名单。如果table-name未设置,可以通过这个属性来指定。'debezium.properties.database.history' = 'io.debezium.relational.history.FileDatabaseHistory' -- 可选,设置数据库历史记录的实现类,通常使用FileDatabaseHistory来保存历史记录,以便在重启后能恢复状态。
);
2. Kafka 连接器配置
Kafka连接器用于读写Kafka主题中的数据。配置示例如下:
CREATE TABLE kafka_table (-- 定义表结构id INT,name STRING,-- 其他列
) WITH ('connector' = 'kafka', -- 使用kafka连接器'topic' = 'topic_name', -- Kafka主题名'properties.bootstrap.servers' = 'kafka-broker:9092', -- Kafka服务器地址'format' = 'json' -- 数据格式,例如json'properties.group.id' = 'flink-consumer-group', -- 消费者组ID'scan.startup.mode' = 'earliest-offset', -- 启动模式(earliest-offset, latest-offset, specific-offset, timestamp)'format' = 'json', -- 数据格式'json.fail-on-missing-field' = 'false', -- 是否在字段缺失时失败'json.ignore-parse-errors' = 'true', -- 是否忽略解析错误'properties.security.protocol' = 'SASL_SSL', -- 安全协议(可选)'properties.sasl.mechanism' = 'PLAIN', -- SASL机制(可选)'properties.sasl.jaas.config' = 'org.apache.kafka.common.security.plain.PlainLoginModule required username="user" password="password";' -- SASL配置(可选)
);
3. JDBC 连接器配置
JDBC连接器用于与其他关系型数据库进行交互。配置示例如下:
CREATE TABLE jdbc_table (-- 定义表结构id INT,name STRING,-- 其他列
) WITH ('connector' = 'jdbc', -- 使用jdbc连接器'url' = 'jdbc:mysql://mysql-host:3306/db', -- JDBC连接URL'table-name' = 'table_name', -- 数据库表名'username' = 'user', -- 数据库用户名'password' = 'password' -- 数据库密码'driver' = 'com.mysql.cj.jdbc.Driver', -- JDBC驱动类'lookup.cache.max-rows' = '5000', -- 可选,查找缓存的最大行数'lookup.cache.ttl' = '10min', -- 可选,查找缓存的TTL(时间到期)'lookup.max-retries' = '3', -- 可选,查找的最大重试次数'sink.buffer-flush.max-rows' = '1000', -- 可选,缓冲区刷新最大行数'sink.buffer-flush.interval' = '2s' -- 可选,缓冲区刷新间隔
);
4. RabbitMQ 连接器配置
RabbitMQ连接器用于与RabbitMQ消息队列进行交互。配置示例如下:
CREATE TABLE rabbitmq_table (-- 定义表结构id INT,name STRING,-- 其他列
) WITH ('connector' = 'rabbitmq', -- 使用rabbitmq连接器'host' = 'rabbitmq-host', -- RabbitMQ主机名'port' = '5672', -- RabbitMQ端口号'username' = 'user', -- RabbitMQ用户名'password' = 'password', -- RabbitMQ密码'queue' = 'queue_name', -- RabbitMQ队列名'exchange' = 'exchange_name' -- RabbitMQ交换机名'routing-key' = 'routing_key', -- 路由键'delivery-mode' = '2', -- 投递模式(2表示持久)'format' = 'json', -- 数据格式'json.fail-on-missing-field' = 'false', -- 是否在字段缺失时失败'json.ignore-parse-errors' = 'true' -- 是否忽略解析错误
);
5. REST Lookup 连接器配置
REST Lookup 连接器允许在 SQL 查询过程中,通过 REST API 进行查找操作。
CREATE TABLE rest_table (id INT,name STRING,price DECIMAL(10, 2),PRIMARY KEY (id) NOT ENFORCED
) WITH ('connector' = 'rest-lookup','url' = 'http://api.example.com/user/{id}', -- REST API URL,使用占位符 {product_id}'lookup-method' = 'POST' -- 'GET' 或 'POST''format' = 'json', -- 数据格式'asyncPolling' = 'false' -- 可选,指定查找操作是否使用异步轮询模式。默认值为 'false'。当设置为 'true' 时,查找操作会以异步方式执行,有助于提高性能。'gid.connector.http.source.lookup.header.Content-Type' = 'application/json' -- 可选,设置 Content-Type 请求头。用于指定请求体的媒体类型。例如,设置为 application/json 表示请求体是 JSON 格式。'gid.connector.http.source.lookup.header.Origin' = '*' -- 可选,设置 Origin 请求头。通常用于跨域请求。'gid.connector.http.source.lookup.header.X-Content-Type-Options' = 'nosniff' -- 可选,设置 X-Content-Type-Options 请求头。用于防止 MIME 类型混淆攻击。'json.fail-on-missing-field' = 'false', -- 可选,是否在字段缺失时失败'json.ignore-parse-errors' = 'true' -- 可选,是否忽略解析错误'lookup.cache.max-rows' = '5000', -- 可选,查找缓存的最大行数'lookup.cache.ttl' = '10min', -- 可选,查找缓存的TTL(时间到期)'lookup.max-retries' = '3' -- 可选,查找的最大重试次数
);6. HDFS 连接器配置
HDFS connector用于读取或写入Hadoop分布式文件系统中的数据。
创建HDFS Source
CREATE TABLE hdfsSource (line STRING
) WITH ('connector' = 'filesystem','path' = 'hdfs://localhost:9000/data/input', -- HDFS上的路径。'format' = 'csv' -- 文件格式。
);
创建HDFS Sink
CREATE TABLE hdfsSink (line STRING
) WITH ('connector' = 'filesystem','path' = 'hdfs://localhost:9000/data/output','format' = 'csv'
);
FlinkSql数据类型
在FlinkSQL中,数据类型的选择和定义是非常重要的,因为它们直接影响数据的存储和处理方式。FlinkSQL提供了多种数据类型,可以满足各种业务需求。以下是FlinkSQL中的常见数据类型及其详细介绍:
1. 基本数据类型
-
BOOLEAN: 布尔类型,表示
TRUE或FALSE。CREATE TABLE example_table (is_active BOOLEAN ); -
TINYINT: 8位带符号整数,范围是
-128到127。CREATE TABLE example_table (tiny_value TINYINT ); -
SMALLINT: 16位带符号整数,范围是
-32768到32767。CREATE TABLE example_table (small_value SMALLINT ); -
INT: 32位带符号整数,范围是
-2147483648到2147483647。CREATE TABLE example_table (int_value INT ); -
BIGINT: 64位带符号整数,范围是
-9223372036854775808到9223372036854775807。CREATE TABLE example_table (big_value BIGINT ); -
FLOAT: 单精度浮点数。
CREATE TABLE example_table (float_value FLOAT ); -
DOUBLE: 双精度浮点数。
CREATE TABLE example_table (double_value DOUBLE ); -
DECIMAL(p, s): 精确数值类型,
p表示总精度,s表示小数位数。CREATE TABLE example_table (decimal_value DECIMAL(10, 2) );
2. 字符串数据类型
-
CHAR(n): 定长字符串,
n表示字符串的长度。CREATE TABLE example_table (char_value CHAR(10) ); -
VARCHAR(n): 可变长字符串,
n表示最大长度。CREATE TABLE example_table (varchar_value VARCHAR(255) ); -
STRING: 可变长字符串,无长度限制。
CREATE TABLE example_table (string_value STRING );
3. 日期和时间数据类型
-
DATE: 日期类型,格式为
YYYY-MM-DD。CREATE TABLE example_table (date_value DATE ); -
TIME§: 时间类型,格式为
HH:MM:SS,p表示秒的小数位精度。CREATE TABLE example_table (time_value TIME(3) ); -
TIMESTAMP§: 时间戳类型,格式为
YYYY-MM-DD HH:MM:SS.sss,p表示秒的小数位精度。CREATE TABLE example_table (timestamp_value TIMESTAMP(3) ); -
TIMESTAMP§ WITH LOCAL TIME ZONE: 带有本地时区的时间戳类型。
CREATE TABLE example_table (local_timestamp_value TIMESTAMP(3) WITH LOCAL TIME ZONE );
4. 复杂数据类型
-
ARRAY: 数组类型,
T表示数组中的元素类型。CREATE TABLE example_table (array_value ARRAY<INT> ); -
MAP<K, V>: 键值对映射类型,
K表示键的类型,V表示值的类型。CREATE TABLE example_table (map_value MAP<STRING, INT> ); -
ROW<…>: 行类型,可以包含多个字段,每个字段可以有不同的类型。
CREATE TABLE example_table (row_value ROW<name STRING, age INT> );
5. 特殊数据类型
-
BINARY(n): 定长字节数组,
n表示长度。CREATE TABLE example_table (binary_value BINARY(10) ); -
VARBINARY(n): 可变长字节数组,
n表示最大长度。CREATE TABLE example_table (varbinary_value VARBINARY(255) );
数据类型的使用示例
以下是一个包含各种数据类型的表的定义示例:
CREATE TABLE example_table (id INT,name STRING,is_active BOOLEAN,salary DECIMAL(10, 2),birth_date DATE,join_time TIMESTAMP(3),preferences ARRAY<STRING>,attributes MAP<STRING, STRING>,address ROW<street STRING, city STRING, zip INT>
);
相关文章:
记录使用FlinkSql进行实时工作流开发
使用FlinkSql进行实时工作流开发 引言Flink SQL实战常用的Connector1. MySQL-CDC 连接器配置2. Kafka 连接器配置3. JDBC 连接器配置4. RabbitMQ 连接器配置5. REST Lookup 连接器配置6. HDFS 连接器配置 FlinkSql数据类型1. 基本数据类型2. 字符串数据类型3. 日期和时间数据类…...
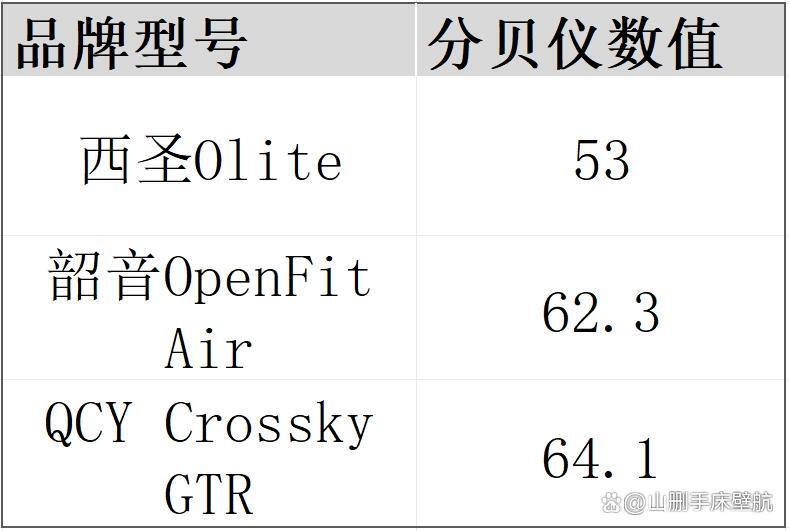
韶音开放式耳机怎么样?韶音、西圣、QCY热门款实测横评
开放式耳机是目前最火爆的的耳机市场细分赛道,开放式耳机的优点包括健康卫生,佩戴舒适性高,方便我们接收外部环境音等等,以上这些优势使得开放式耳机特别适配户外运动场景,在工作、日常生活等场景下使用也是绰绰有余。…...

求值(河南萌新2024)
我真的服了,注意数据范围!!!!!!!!!!!!!!!!!!&#…...

【Linux】文件描述符 fd
目录 一、C语言文件操作 1.1 fopen和fclose 1.2 fwrite和fread 1.3 C语言中的输入输出流 二、Linux的文件系统调用 2.1 open和文件描述符 2.2 close 2.3 read 2.4 write 三、Linux内核数据结构与文件描述符 一、C语言文件操作 在C语言中我们想要打开一个文件并对其进…...

带通采样定理
一、采样定理 1.1 低通采样定理(奈奎斯特采样) 低通采样定理(奈奎斯特采样)是要求大于信号的最高上限频率的两倍 1.2 带通采样定理 带通信号的采样频率在某个时间小于采样频率也能无失真恢复原信号 二、频谱混叠 对一个连续时域信号,采…...
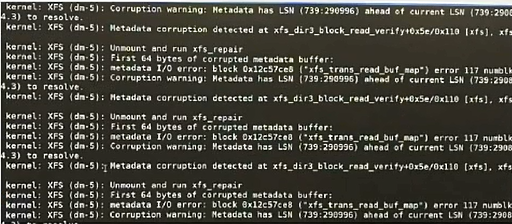
运维工作中的事件、故障排查处理思路
一、运维工作中的事件 https://www.51cto.com/article/687753.html 二、运维故障排查 一)故障排查步骤 1、明确故障 故障现象的直接表现故障发生的时间、频率故障发生影响哪些系统故障发生是否有明确的触发条件 故障举例:无法通过ssh登录系统 影响…...

深入源码P3C-PMD:使用流程(1)
PMD开源组件启动流程介绍 在软件开发领域,代码质量是项目成功的关键因素之一。为了提升代码质量,开发者们常常借助各种工具进行代码分析和检查。PMD作为一款开源的静态代码分析工具,在Java、JavaScript、PLSQL等语言项目中得到了广泛应用。本…...

java~反射
反射 使用的前提条件:必须先得到代表的字节码的Class,Class类用于表示.class文件(字节码) 原理图 加载完类后,在堆中就产生了一个Class类型的对象(一个类只有一个Class对象),这个对…...

【Linux】(26) 详解磁盘与文件系统:从物理结构到inode机制
目录 1.认识磁盘、 1.1 理论 1.2 磁盘的物理结构 CHS 寻址 1.3 磁盘的逻辑抽象结构 2. inode 结构 1.Boot Block 启动块 2.Super Block(超级块) 3.Group Descriptor Block(块组描述符) 4.Data Blocks (数据块) 5.Inode…...

8.1 字符串中等 43 Multiply Strings 38 Count and Say
43 Multiply Strings【默写】 那个难点我就没想先解决,原本想法是先想其他思路,但也没想出。本来只想chat一下使用longlong数据类型直接stoi()得不得行,然后就看到了答案,直接一个默写的大动作。但这道题确实考察的是还原乘法&…...

upload-labs靶场:1—10通关教程
目录 Pass-01(JS 验证) Pass-02(MIME) Pass-03(黑名单绕过) Pass-04(.htaccess 绕过) Pass-05(大小写绕过) Pass-06(空格绕过) …...
)
Hive3:一键启动、停止、查看Hive的metastore和hiveserver2两个服务的脚本(好用)
脚本内容 #!/bin/bash # 一键启动、停止、查看Hive的metastore和hiveserver2两个服务的脚本 function start_metastore {# 启动Hive metastore服务hive --service metastore >/dev/null 2>&1 &for i in {1..30}; doif is_metastore_running; thenecho "Hiv…...

遗传算法与深度学习实战——生命模拟及其应用
遗传算法与深度学习实战——生命模拟及其应用 0. 前言1. 康威生命游戏1.1 康威生命游戏的规则1.2 实现康威生命游戏1.3 空间生命和智能体模拟 2. 实现生命模拟3. 生命模拟应用小结系列链接 0. 前言 生命模拟是进化计算的一个特定子集,模拟了自然界中所观察到的自然…...

大数据|使用Apache Spark 删除指定表中的指定分区数据
文章目录 概述方法 1: 使用 Spark SQL 语句方法 2: 使用 DataFrame API方法 3: 使用 Hadoop 文件系统 API方法 4: 使用 Delta Lake使用注意事项常见相关问题及处理结论 概述 Apache Spark 是一个强大的分布式数据处理引擎,支持多种数据处理模式。在处理大型数据集时…...

OSPF动态路由协议实验
首先地址划分 一个骨干网段分成三个,r1,r2,r5三个环回网段 ,总共要四个网段 192.168.1.0/24 192.168.1.0/26---骨干网段 192.168.1.0/28 192.168.1.16/28 192.168.1.32/28 备用 192.168.1.64/28 192.168.1.64/26---r1环回 192.1…...
的理解)
tcp中accept()的理解
源码 参数理解 NAMEaccept, accept4 - accept a connection on a socketSYNOPSIS#include <sys/types.h> /* See NOTES */#include <sys/socket.h>int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);#define _GNU_SOURCE …...
让我们逐行重现 GPT-2:第 1 部分
欢迎来到雲闪世界。Andrej Karpathy 是人工智能 (AI) 领域的顶尖研究人员之一。他是 OpenAI 的创始成员之一,曾领导特斯拉的 AI 部门,目前仍处于 AI 社区的前沿。 在第一部分中,我们重点介绍如何实现 GPT-2 的架构。虽然 GPT-2 于 2018 年由 …...

第十九天内容
上午 1、构建vue发行版本 2、java环境配置 jdk软件包路径: https://download.oracle.com/java/22/latest/jdk-22_linux-x64_bin.tar.gz 下午 1、安装tomcat软件 tomcat软件包路径: https://dlcdn.apache.org/tomcat/tomcat-10/v10.1.26/bin/apache-to…...
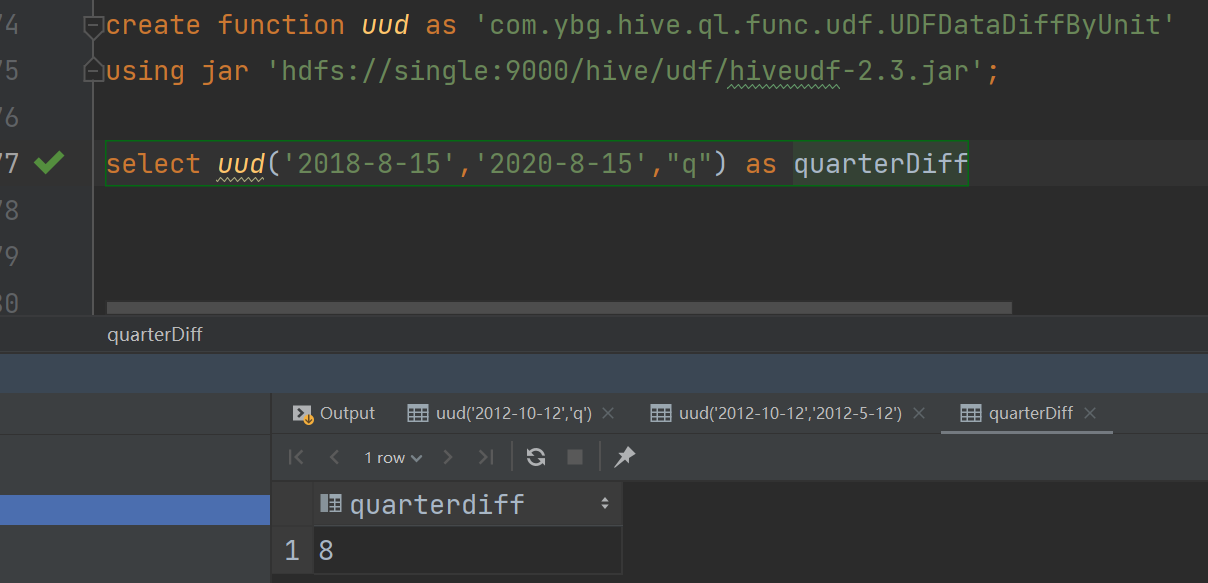
Hive之扩展函数(UDF)
Hive之扩展函数(UDF) 1、概念讲解 当所提供的函数无法解决遇到的问题时,我们通常会进行自定义函数,即:扩展函数。Hive的扩展函数可分为三种:UDF,UDTF,UDAF。 UDF:一进一出 UDTF:一进多出 UDAF:…...

jdk1.8中HashMap为什么不直接用红黑树
最开始使用链表的时候,空间占用比较少,而且由于链表短,所以查询时间也没有太大的问题。可是当链表越来越长,需要用红黑树的形式来保证查询的效率。 参考资料: https://blog.51cto.com/u_13294304/3075723...

如何使用usearch进行水资源分配优化:用水数据的向量分析完整指南
如何使用usearch进行水资源分配优化:用水数据的向量分析完整指南 【免费下载链接】usearch Fastest Open-Source Search & Clustering engine for Vectors & 🔜 Strings in C, C, Python, JavaScript, Rust, Java, Objective-C, Swift, C#, Go…...

避坑指南:RuoYi-Vue2集成Flowable 6.7.2时,关于database-schema-update和nullCatalogMeansCurrent的配置详解
深度解析:RuoYi-Vue2集成Flowable 6.7.2的数据库配置陷阱与实战策略 当企业级应用需要引入工作流引擎时,Flowable因其轻量化和高性能成为许多开发团队的首选。然而在RuoYi-Vue2框架中集成Flowable 6.7.2版本时,数据库配置环节往往成为开发者的…...

开源工具MelonLoader:Unity游戏模组开发的3大突破与零基础上手指南
开源工具MelonLoader:Unity游戏模组开发的3大突破与零基础上手指南 【免费下载链接】MelonLoader The Worlds First Universal Mod Loader for Unity Games compatible with both Il2Cpp and Mono 项目地址: https://gitcode.com/gh_mirrors/me/MelonLoader …...
)
SSCOM串口助手5个隐藏技巧:多窗口同步调试效率翻倍(附配置截图)
SSCOM串口助手5个隐藏技巧:多窗口同步调试效率翻倍(附配置截图) 在嵌入式开发和硬件调试领域,串口通信工具的效率直接影响着工程师的工作节奏。SSCOM作为一款广受欢迎的串口调试助手,其简洁界面背后隐藏着许多能显著提…...

1998-2025年区县政府工作报告文本数据
县域政府工作报告是县级政府向同级人民代表大会汇报年度工作的核心文件,报告既总结上一年度经济社会发展和政府工作成效,也提出当前形势判断、政策取向及下一阶段重点任务,是集中反映政府施政理念、政策重点和发展方向的重要文本 整理了1998…...

SwiftHub:终极GitHub iOS客户端开发指南 - RxSwift与MVVM-C架构实践
SwiftHub:终极GitHub iOS客户端开发指南 - RxSwift与MVVM-C架构实践 【免费下载链接】SwiftHub GitHub iOS client in RxSwift and MVVM-C clean architecture 项目地址: https://gitcode.com/gh_mirrors/sw/SwiftHub SwiftHub是一款功能强大的GitHub iOS客户…...

HunyuanVideo-Foley与Java后端集成:构建高并发音效生成服务
HunyuanVideo-Foley与Java后端集成:构建高并发音效生成服务 1. 场景需求与技术挑战 在线教育平台面临一个共同痛点:海量视频课程需要配乐,但人工配乐成本高、效率低。一个中等规模的平台每月新增课程可能达到上万节,传统音乐制作…...

革新性植物大战僵尸全能修改工具:重定义游戏体验
革新性植物大战僵尸全能修改工具:重定义游戏体验 【免费下载链接】pvztoolkit 植物大战僵尸 PC 版综合修改器 项目地址: https://gitcode.com/gh_mirrors/pv/pvztoolkit 植物大战僵尸辅助工具PVZ Toolkit是一款专为经典游戏《植物大战僵尸》PC版设计的开源修…...

【OFDM通信】室内NOMA-OFDM-VLC系统仿真【含Matlab源码 15240期】
💥💥💥💥💥💥💥💥💞💞💞💞💞💞💞💞💞Matlab领域博客之家💞&…...

Nunchaku FLUX.1-dev 提示词工程入门:编写高质量Prompt的实用技巧与范例
Nunchaku FLUX.1-dev 提示词工程入门:编写高质量Prompt的实用技巧与范例 你是不是也遇到过这种情况:用同一个开源大模型,别人生成的图片精美绝伦,自己生成的却总差点意思,要么主体不对,要么风格跑偏&#…...