快速排序(上)
快速排序

前言
快速排序算法是最流行的排序算法,且有充足的理由,因为在大多数情况下,快速排序都是最快的。所以学习快速排序算法十分有必要。当然,既然它这么好,也就不太容易理解。
正文
Hoare版快排
快速排序是Hoare在1962年提出的一种二叉树结构的交换排序方法,其基本思想为:任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
既然是二叉树结构,在这个重复过程中就少不了是递归:

递归到什么程度?递归到只有一个数据或者没有数据,就开始“归”。
在头文件中我们对快速排序的声明如下:
void QuickSort(int* arr, int left, int right);
说明了我们需要传的参数是待排序的数组,以及左和右两个下标控制要排序的区间。
快速排序算法的具体实现
首先,我们要对left和right控制的区间找基准值。因为找到了基准值后,我们就能控制下一次递归的区间。
怎么找基准值?我们上面说基准值要满足左侧数据都小于基准值,右侧数据都大于基准值,所以我们从这一点入手。
我们现在有一个数组,我们让基准值先为第一个数据,让left为第二个数据,right为最后一个数据。然后,让left从左到右找比基准值大的数据,让right从右往左找比基准值小的数据。
找到后,我们让left和right的值交换;交换完再重复刚才的过程。

然后我们发现left走到right的后面去了, 这时我们让keyi和right交换,最后keyi就来到了正确的位置。检查一下,基准值左侧都是比基准值要小的数据,基准值右侧都是比基准值要大的数据。
现在我们在代码中实现找基准值,我们写一个QuickSort的子方法,就叫做_QuickSort,参数还是一样的。
(注意,在写快排代码的过程中,等于的情况会比较难处理,需要单独讨论,我们可以先跳过,到后面再来仔细讨论)
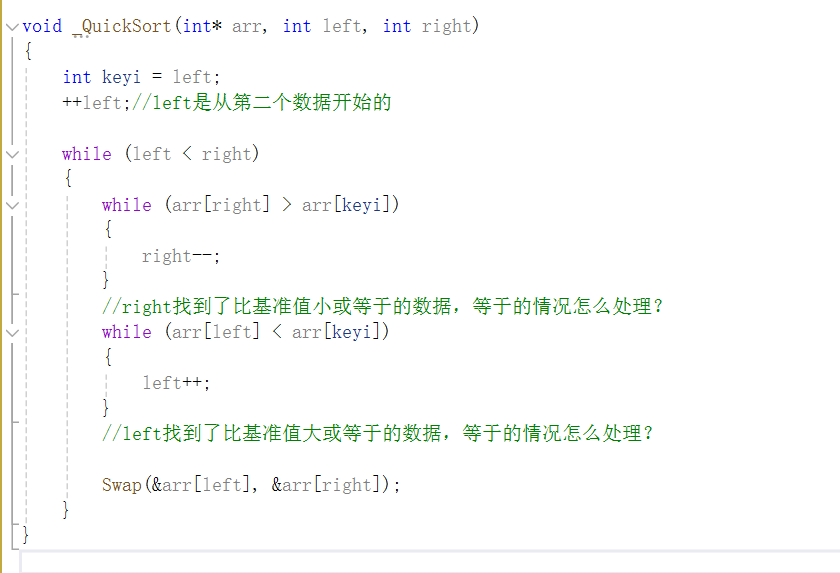
我们可以先写出这样的代码,left比right小进入循环,right从右往左找比基准值小的,left从左往右找比基准值大的,找到了就交换,这样逻辑顺下来写的代码似乎没有问题,实则有一个错误。
其实上面代码的运行逻辑是这样的:

在第一次循环后我们的left<right是满足的,所以再次进入循环,找到了新的left和right,但是此时的left已经比right大了,我们想要的是在此时将right与keyi交换,但是现在我们会执行left与right交换,然后终止循环。
所以我们不能直接交换,要在交换之前进行判断。
(注意函数的返回值是int,我们要把找到的基准值下标返回)
int _QuickSort(int* arr, int left, int right)
{int keyi = left;++left;//left是从第二个数据开始的while (left < right){while (arr[right] > arr[keyi]){right--;}//right找到了比基准值小或等于的数据,等于的情况怎么处理?while (arr[left] < arr[keyi]){left++;}//left找到了比基准值大或等于的数据,等于的情况怎么处理?if (left < right)//等于的情况怎么处理?{Swap(&arr[left], &arr[right]);}}//right与keyi交换Swap(&arr[keyi], &arr[right]);return right;
}
但是这是我们还没有仔细分析要不要取等的版本。
为了探讨等于情况,我们就需要更多的案例。
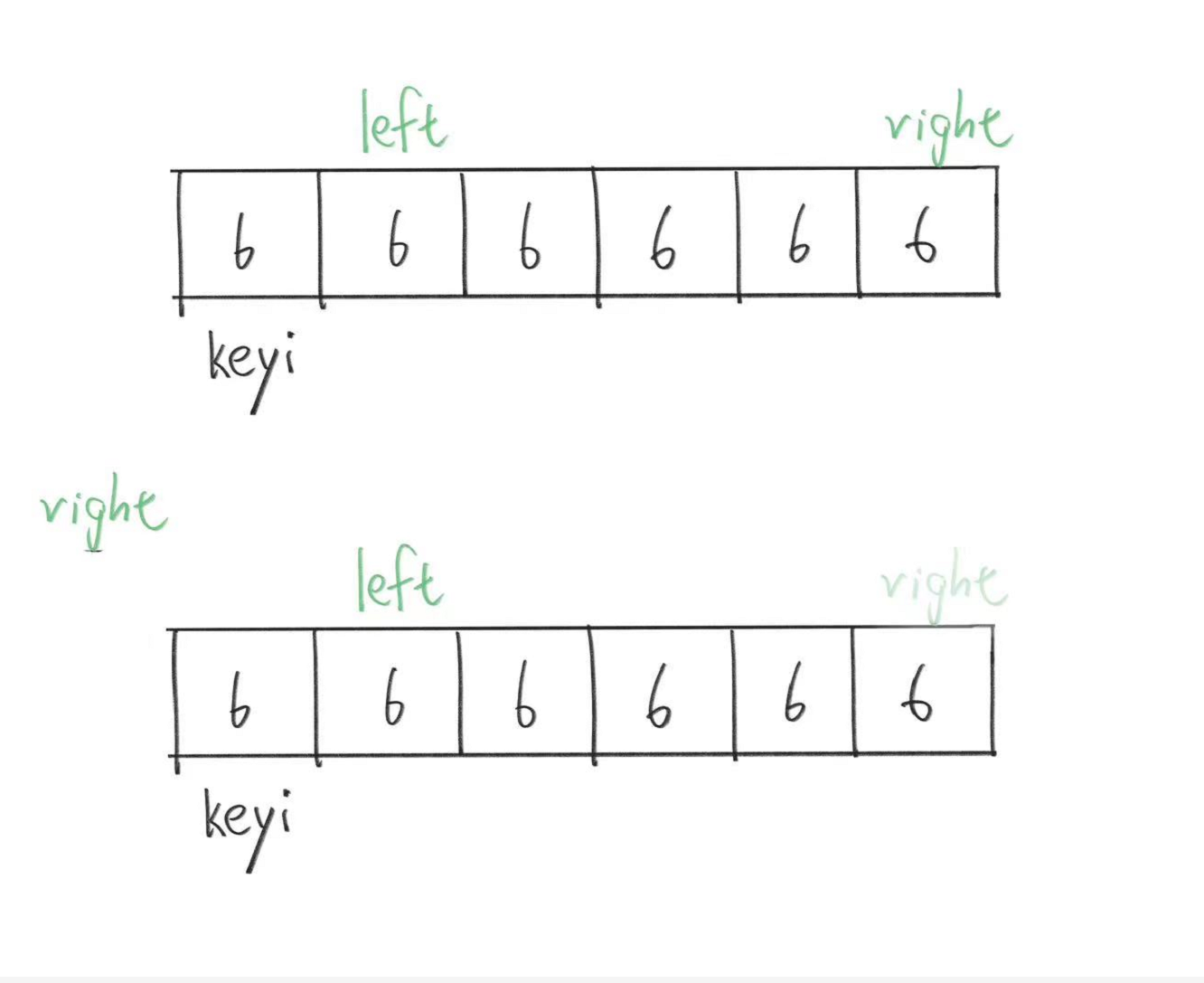
假如我们现在就必须要让right找到比keyi小的才停下来,也就是改为这样:
while (arr[right] >= arr[keyi])//这里改为了大于等于
{right--;
}
等于也还要往前走。
我们发现我们没有限制,所以right会一直走到越界,于是我们需要加上限制,让right顶多走到left前一个:
while (left<=right && arr[right] >= arr[keyi])//注意限制
{right--;
}

所以我们的left也不能一直往后走,要加上限制。
while (left < right)//我们先写为可以等于
{while (left<=right && arr[right] >= arr[keyi])//注意限制{right--;}while (left <= right && arr[left] <= arr[keyi]){left++;}if (left <= right)//我们先写为可以等于{Swap(&arr[left], &arr[right]);}
}
(注意在上述代码中我们让外层循环可以取等,让内层的if也可以取等,总之就是都让等,看看情况)
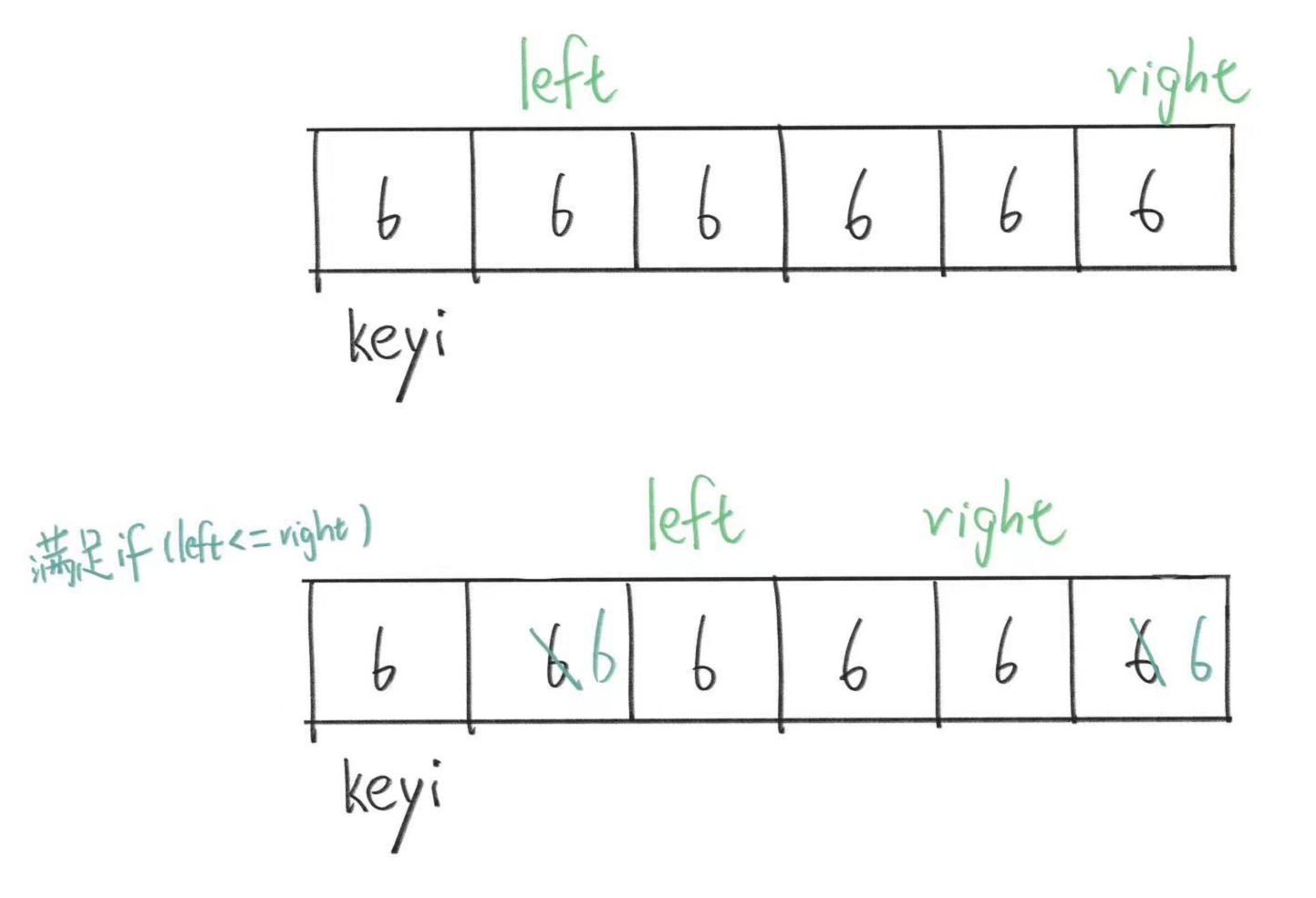
加上这个限制后,在我们举的这个例子中,right已经走到left前面去了,所以内层的第二个while循环我们是进不去了,退出循环,来到right与keyi交换的语句。
根据上面画的图,此时我们的keyi和right都在第一个6的位置。而我们找基准值的意义是要划分左子序列和右子序列。
一般情况,左子序列的区间为[left,keyi-1],右子序列为[keyi+1,right],但是此时我们基准值在第一个数位置,所以我们就没有左子序列了,剩下右边全是右子序列。
我们要再次递归划分子序列,而因为数据全是6,下一次划分的情况又是一样的,基准值又是第一个数。所以我们排完n个数据排n-1个数据,然后n-2个数据,所以我们要递归n次,而且每次都要排n-1 、n-2 、n-3个数据,所以时间复杂度就很差。而我们前面讲快排应该每次都以“二分”来排序所以才那么快。
那么,怎么解决这个问题或者说代码应该怎么优化呢?
while (left <= right)//这里先写为可以等于{while (left<=right && arr[right] > arr[keyi])//改为>,也就是等于时无法进入循环往前走{right--;}while (left <= right && arr[left] < arr[keyi])//改为<{left++;}if (left <= right)//这里先写为可以等于{Swap(&arr[left++], &arr[right--]);//改为了要++和--}}
所以这是我们现在代码的执行情况,然后left此时<=right所以我们再次进入循环,接着我们重复这个过程。
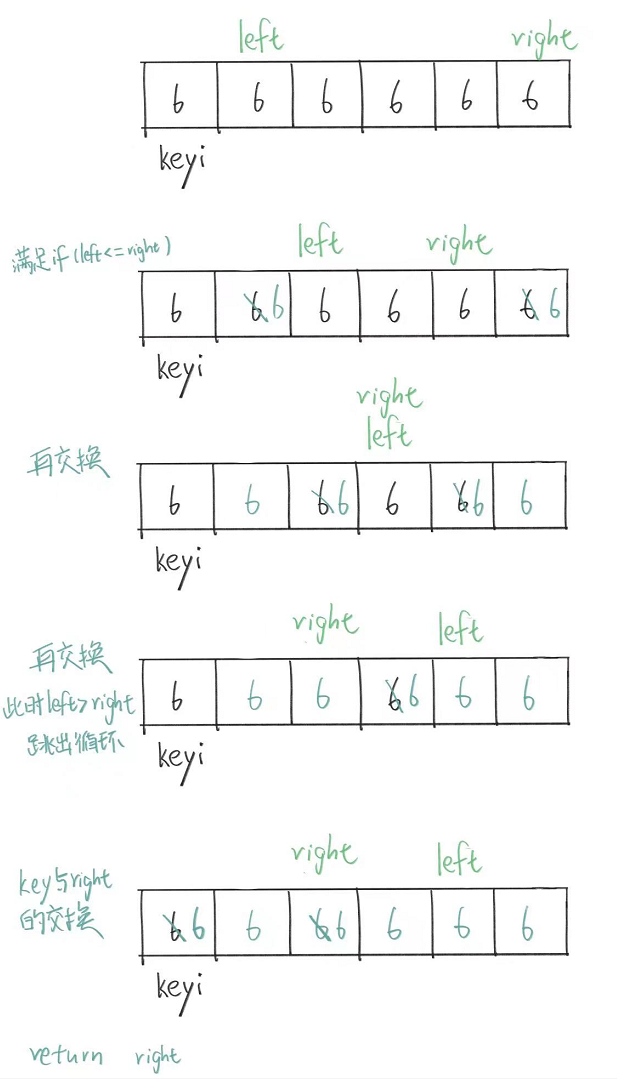
如图。
可以看到我们这么做的原因就是为了尽可能让基准值来到中间的位置,从而划分小的子序列。
现在我们再看一个场景:相遇值大于keyi值
(这个场景解释了为什么外循环是while (left <= right)而不是while (left < right),也就是说为什么left与right相遇时还要再进入循环。
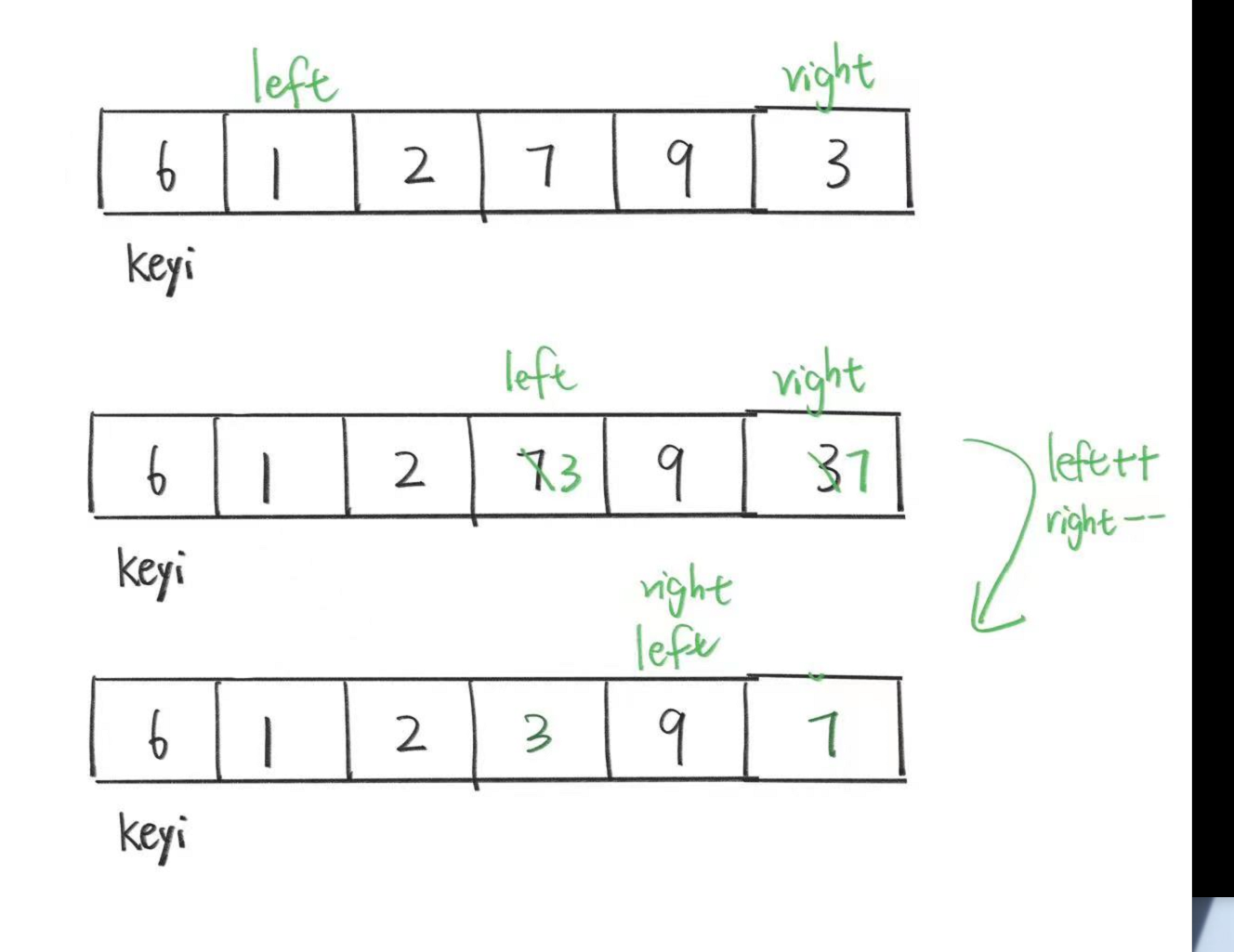
可以看到,如果我们写的是while (left < right),那么无法再进入循环,也就会执行
//right与keyi交换
Swap(&arr[keyi], &arr[right]);
return right;
那么我们就让9到了第一个位置,而这不是我们想要的。所以我们要有等号,也就是相遇时也要进入循环让left再向左走一次,让right再向右走一次,然后再退出循环让right与keyi交换,所以内层left与right比较的代码也要能取等。
所以,两个内循环的第二个条件不能取等是为了防止基准值找到第一个数然后最终代码效率低下;left与right比较要取等是因为要防止把更大的数换到第一个位置。
现在我们的子程序,也就是找基准值的程序写完了。
我们还可以发现,基准值待的位置就是它该待的地方,所以下一次找基准值它的位置不用发生改变。
所以也可以这么说,找基准值的目的就是把基准值放到它该待的位置。
然后根据递归的思路,我们就可以写出快排的代码:
//快速排序
void QuickSort(int* arr, int left, int right)
{if (left >= right)//这种情况没有子序列,不要递归return;//找基准值int keyi = _QuickSort(arr, left, right);QuickSort(arr, left, keyi - 1);QuickSort(arr, keyi+1, right);}
然后我们测试一下。
int main()
{int a[] = { 5, 3, 9, 6, 2, 4, 7, 1, 8 };int n = sizeof(a) / sizeof(int);printf("排序前: ");PrintArr(a, n);QuickSort(a, 0, n-1);printf("排序后: ");PrintArr(a, n);return 0;
}

测试代码:排序性能对比
在前面几种排序算法(前几篇博客)的探讨中我们都用到了10万个随机数的排序时间来检测排序速度,现在我们也再次使用这个方法(具体写法参考前面的文章)来检测一下快排的速度:
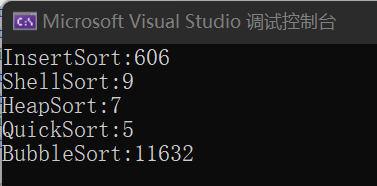
可以看到快排确实非常快。
现在我们改为100万个随机数据的排序,不看冒泡排序和直接插入了,来比较比较希尔排序、堆排序和快排的表现:

可以看到快排显著的优势。
快排的时间复杂度
我们知道快排是二叉树结构的交换排序方法,我们要递归logn次,空间复杂度为O(logn), 时间复杂度为O(nlogn)。可以看到空间复杂度和时间复杂度都很低。
其实快排还有其他版本,放到下篇文章再说=_=
相关文章:
快速排序(上)
快速排序 前言 快速排序算法是最流行的排序算法,且有充足的理由,因为在大多数情况下,快速排序都是最快的。所以学习快速排序算法十分有必要。当然,既然它这么好,也就不太容易理解。 正文 Hoare版快排 快速排序是Hoare在1962年提出的一种二叉树结构的…...

数据结构-队列
队列对于临时数据的处理也十分有趣,它跟栈一样都是有约束条件的数组。区别在于我们想要按什么顺序去处理数据,而这个顺序当然是要取决于具体的应用场景。 你可以将队列想象成是电影院排队。排在最前面的人会最先离队进入影院。套用到队列上,…...

MySQL:操作符
MySQL 操作符 MySQL 操作符是 MySQL 数据库操作中不可或缺的一部分,它们用于执行各种数据运算、比较、逻辑判断等。 MySQL 中有多种操作符可用于数据查询和筛选 MySQL 所提供的运算符可以直接对表中数据或字段进行运算 MySQL 支持 4 种运算符,分别是&…...

反序列化靶机实战serial(保姆级教程)
一.信息收集 靶机地址下载:https://download.vulnhub.com/serial/serial.zip 打开靶机,在kali虚拟机中进行主机存活探测 可以知道靶机ip地址为192.168.133.171 然后扫描端口 可以发现有一个22端口跟80端口 然后接下来用kali扫描它的目录 可以发现有一…...

【Git】git 从入门到实战系列(一)—— Git 的诞生,Linus 如何在 14 天内编写出 Git?
<> 博客简介:Linux、rtos系统,arm、stm32等芯片,嵌入式高级工程师、面试官、架构师,日常技术干货、个人总结、职场经验分享 <> 公众号:嵌入式技术部落 <> 系列专栏:C/C、Linux、rt…...

com.microsoft.sqlserve r:sqljdbc4:jar:4.0 was not found in......如何解决?
这个错误提示说 com.microsoft.sqlserver:sqljdbc4:jar:4.0 这个依赖无法从 Maven 中央仓库(https://repo.maven.apache.org/maven2)下载,导致项目无法构建。以下是解决该问题的几种方法: 方法一:手动安装依赖 下载 J…...

数据集——鸢尾花介绍和使用
文章目录 一、鸢尾花数据集内容二、使用中常转换DataFrame 一、鸢尾花数据集内容 from sklearn import svm, datasets # 鸢尾花数据 iris datasets.load_iris() print(iris.data) X iris.data[:, :2] # 为便于绘图仅选择2个特征 y iris.target它包含了150个样本,…...
)
ElasticSearch第4篇(亿级中文数据量 ElasticSearch与Sphinx建索引速度、查询速度、并发性能、实测对比)
经过实测:1.09亿的数据量进行中文检索。ElasticSearch单机的检索性能在0.005~5.6秒之间,此检索速度可满足95%的业务场景(注意:每条ES文档平均65个汉字,数据源取自几千本小说,大部分文档在15~300个汉字之间&…...

过期知识:thinkphp5 使用migrate给现有的数据表新增表字段
个人开发网站记录, 这个文章主要是个以后健忘的我看的. 我在搞我的画笔审核 , 发现数据表的画笔数据在审核驳回的时候还是软删除好一些, 免得用户找不到之前上传的画笔数据, 后期也可以考虑重新显示给用户,让用户可以修改画笔信息重新提交审核. 这个时候想起了…...

前端和Postman调用同一个接口,拿到的数据不一样
1、表现 联调一个List接口,Postman自测得到的ID和前端调用得到的ID,结果不一样。前者结果: 后者结果: 同一份代码、同一个数据库,出现这种错误,大概率是类型转换时出问题了,但检查代码发现&…...

1000W长连接,如何建立和维护?千万用户IM 架构设计
1000W长连接,如何建立和维护?千万用户IM 架构设计 在40岁老架构师 尼恩的读者交流群(50)中,最近有小伙伴拿到了一线互联网企业如得物、阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试资格,遇到很多很重要的架构类/设计类…...

vulhub:Apache解析漏洞CVE-2017-15715
Apache HTTPD是一款HTTP服务器,它可以通过mod_php来运行PHP网页。其2.4.0~2.4.29版本中存在一个换行解析漏洞,在解析PHP时,1.php\x0A将被按照PHP后缀进行解析,导致绕过一些服务器的安全策略。 #启动靶机 cd /Vulnhub/vulhub-mast…...

开发中可能会面临的真实问题及处理流程
接口返回数据不符合预期 问题描述:接口返回的数据结构或字段名称与前端预期不符,导致页面展示错误。 处理流程: 检查接口文档:确保前后端约定的接口文档是最新的,并且描述一致。 前后端沟通:与后端开发人员…...
个性化你的生产力工具:待办事项App定制指南
国内外主流的10款待办事项软件对比:PingCode、Worktile、滴答清单、番茄ToDo、Teambition、Todoist、Microsoft To Do、TickTick、Any.do、Trello。 在寻找合适的待办事项软件时,你是否感到选择众多、难以决断?一个好的待办事项工具可以大大提…...
本地部署持续集成工具Jenkins并配置公网地址实现远程自动化构建
文章目录 前言1. 安装Jenkins2. 局域网访问Jenkins3. 安装 cpolar内网穿透软件4. 配置Jenkins公网访问地址5. 公网远程访问Jenkins6. 固定公网地址 前言 本文主要介绍如何在Linux CentOS 7中安装Jenkins并结合cpolar内网穿透工具实现远程访问管理本地部署的Jenkins服务. Jenk…...

【数据结构】了解哈希表,解决哈希冲突,用Java模拟实现哈希桶
哈希表的概念 哈希表(Hash Table)是一种高效的数据结构,用于实现快速的数据存储和检索。它通过将数据映射到一个数组的索引位置,从而能够在平均情况下实现O(1)的时间复杂度进行查找、插入和删除操作。 哈希表的基本概念包括以下…...

qt5 ui转python或C++文件
firstMainWin.ui转换成.py文件,输入以下命令即可 pyuic5 -o firstMainWin.py firstMainwin. ui python -m PyQt5.uic.pyuic Img_ui.ui -o Img_ui.py firstMainWin.ui转换成c文件,输入以下命令即可 uic firstMainWin.ui -o hello.h ##用python转 新建…...

scp命令详解
scp(secure copy)是一个基于 SSH 的命令行工具,用于在不同计算机之间安全地复制文件和目录。scp 提供了在本地和远程主机之间传输文件的简单方法,并且支持加密和认证,确保文件传输的安全性。 基本用法 从本地复制到远…...

算法小白的进阶之路(力扣1~5)
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 非常期待和您一起在这个小…...

昇思25天学习打卡营第22天|MindSporeK基于Diffusion扩散模型学习- Diffusion与其他生成模型
Diffusion扩散模型 本文基于Hugging Face:The Annotated Diffusion Model一文翻译迁移而来,同时参考了由浅入深了解Diffusion Model一文。 本教程在Jupyter Notebook上成功运行。如您下载本文档为Python文件,执行Python文件时,请…...

二极管限幅与钳位电路设计全解析
1. 二极管基础特性回顾 在开始分析各种二极管应用电路之前,我们先快速回顾一下二极管的核心特性。二极管最显著的特点就是其单向导电性 - 当正向偏置电压超过导通阈值(硅管约0.7V)时导通,反向偏置或正向电压不足时截止。这个看似简…...

2025届学术党必备的十大降AI率助手实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 知网 AI 检测系统借助对文本的分析来生成逻辑以及进行语言模式识别,以此识别机器…...

2026知识付费SaaS避坑指南:数据安全与系统稳定性实测,创客匠人为何值得托付?
在知识付费行业,大多数选型对比只关注“前台功能”:能不能卖课、能不能直播、有没有拼团。但真正决定生意生死的,往往是看不见的“底层能力”——数据是否安全?系统是否稳定?学员资产能否真正归你所有?过去…...

从Flash到I2C:盘点那些让你头疼的时序图符号,并教你用Python+逻辑分析仪自动解析
从Flash到I2C:时序图符号解析与Python自动化实战 第一次翻开某款Flash芯片的数据手册时,我被密密麻麻的时序图符号彻底击垮了。灰色交叉、斜坡箭头、省略号标记...这些看似简单的图形背后,隐藏着芯片厂商精心设计的通信规则。作为嵌入式开发者…...

数字化转型深水区:技术从“支撑”到“驱动”的蜕变
对于身处一线的软件测试从业者而言,“数字化转型”早已不是一个陌生的词汇。我们经历了从手工测试到自动化测试的转变,见证了敏捷与DevOps带来的流程革新。然而,当转型浪潮进入“深水区”,一种更为根本的变革正在发生:…...
)
Win10主机与Win7虚拟机共享文件夹超详细指南(VMware/虚拟机新手必看)
Win10主机与Win7虚拟机无缝共享文件夹全流程解析 刚接触虚拟机的用户经常会遇到一个棘手问题:如何在主机和虚拟机之间高效传输文件?复制粘贴受限、U盘来回插拔效率低下,而共享文件夹功能正是解决这一痛点的最佳方案。本文将手把手带你完成从零…...

别再让你的Druid监控裸奔了!手把手教你配置账户密码与访问控制
Druid监控安全加固实战:从零构建企业级防护体系 在Java生态中,Druid作为阿里巴巴开源的数据库连接池,凭借其强大的监控功能成为众多企业的标配组件。但令人担忧的是,超过60%的生产环境存在Druid监控页面暴露的安全隐患——这相当于…...

解决WPS标题编号不从‘一‘开始的烦恼:新手必看避坑指南
WPS标题编号异常全解析:从问题根源到高阶应用技巧 刚接触WPS文字处理的新手们,经常会遇到一个令人困惑的现象——文档中的标题编号莫名其妙地从"二"或"三"开始,而不是预期的"一"。这种情况不仅影响文档美观&am…...

终极Cursor Pro破解教程:告别免费限制,解锁无限AI编程体验
终极Cursor Pro破解教程:告别免费限制,解锁无限AI编程体验 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve r…...

OpenCV透视变换实战:从文档矫正到AR应用
1. 透视变换基础:从原理到生活场景 想象一下你正在用手机拍摄一张放在桌上的发票,由于角度问题,发票在照片里变成了梯形。这时候你需要的正是透视变换——它能把这个梯形"掰正"成规整的矩形。在计算机视觉领域,透视变换…...