Transformer预测模型及其Python和MATLAB实现
### 一、背景
在自然语言处理(NLP)领域,传统的序列到序列(Seq2Seq)模型大多依赖于循环神经网络(RNN)和长短期记忆(LSTM)网络。这些模型虽然在许多任务中取得了成功,但由于其计算效率低下以及长距离依赖关系处理的不足,导致模型训练时间漫长,并在处理较长文本时效果不佳。
2017年,Vaswani等人提出的Transformer模型在《Attention is All You Need》一文中引起了广泛关注。Transformer摒弃了RNN的结构,完全基于自注意力机制(Self-Attention)来捕获序列中不同位置之间的关联。这一创新在机器翻译、文本摘要、情感分析等任务中取得了显著的效果,并迅速成为NLP研究的主流模型。
### 二、原理
#### 1. 自注意力机制
自注意力机制是Transformer的核心。它可以让模型在处理每个词时,考虑到整个序列中的其他词,从而更好地捕捉上下文信息。自注意力的计算通常包括以下步骤:
- **输入嵌入**(Input Embeddings):将每个词通过嵌入层转换为向量表示。
- **查询(Query)、键(Key)和值(Value)**:对输入的词嵌入进行线性变换,得到查询、键和值。这里的查询用于判断每个词对于其他词的重要性,键和值则用于存储词的信息。
- **注意力权重计算**:通过计算查询与所有键的点积,再经过Softmax函数得到注意力权重,最终通过加权平均值得到每个词的表示。
\[
\text{Attention}(Q, K, V) = \text{softmax}\left( \frac{QK^T}{\sqrt{d_k}} \right)V
\]
其中\(d_k\)是键的维度,用于缩放以避免点积过大导致的梯度消失。
#### 2. 位置编码
由于Transformer没有递归结构,因此无法捕捉序列中词的位置信息。为了解决这个问题,Vaswani等人引入了位置编码(Positional Encoding),它通过对每个位置的词嵌入进行正弦和余弦变换,给每一个词增添了位置信息。位置编码的计算公式如下:
\[
PE(pos, 2i) = \sin\left(\frac{pos}{10000^{2i/d_{model}}}\right)
\]
\[
PE(pos, 2i+1) = \cos\left(\frac{pos}{10000^{2i/d_{model}}}\right)
\]
其中,\(pos\)表示词的位置,\(i\)表示维度索引。
#### 3. 多头注意力机制
为了提高模型的表达能力,Transformer使用了多头注意力机制。通过将输入的查询、键和值线性变换为多个不同的头部,然后并行计算每个头的注意力,最后将所有头的结果拼接后经过线性变换。多头注意力的优点在于它能够从多个子空间学习信息。
#### 4. 编码器-解码器结构
Transformer的架构主要分为编码器(Encoder)和解码器(Decoder)两个部分。
- **编码器**:编码器由多个相同的层堆叠而成,每层包括自注意力机制和前馈神经网络。每个编码器层中还包含残差连接和层归一化,使得训练更加稳定。
- **解码器**:解码器结构类似于编码器,但在每个层中加入了对先前生成的输出的自注意力机制,确保了模型在生成文本时不会依赖当前时间步以后的信息。
### 三、实现过程
#### 1. 数据准备
在应用Transformer进行预测任务时,第一步是进行数据准备。数据包括文本预处理、分词、词嵌入以及训练集和测试集的划分。
- **文本预处理**:去掉无用字符、统一大小写、处理标点符号等。
- **分词**:将文本切分成词,使用词典将词映射为对应的索引。
- **词嵌入**:可以使用词嵌入模型(如Word2Vec、GloVe)或直接使用可训练的嵌入层。
#### 2. 模型构建
使用深度学习框架(如TensorFlow或PyTorch)构建Transformer模型。
```python
import torch
import torch.nn as nn
class TransformerModel(nn.Module):
def __init__(self, n_layers, n_heads, input_dim, hidden_dim, output_dim):
super(TransformerModel, self).__init__()
self.encoder = nn.TransformerEncoderLayer(input_dim, n_heads, hidden_dim)
self.decoder = nn.TransformerDecoderLayer(input_dim, n_heads, hidden_dim)
self.fc = nn.Linear(input_dim, output_dim)
def forward(self, src, tgt):
enc_output = self.encoder(src)
dec_output = self.decoder(tgt, enc_output)
output = self.fc(dec_output)
return output
```
#### 3. 模型训练
- **选择损失函数和优化器**:模型通常使用交叉熵损失(Cross Entropy Loss)和Adam优化器进行训练。
- **训练循环**:在每个epoch中,通过训练集进行正向传播、计算损失、反向传播更新参数。
```python
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
for epoch in range(num_epochs):
model.train()
for src, tgt in train_loader:
optimizer.zero_grad()
output = model(src, tgt)
loss = criterion(output.view(-1, output_dim), tgt.view(-1))
loss.backward()
optimizer.step()
```
#### 4. 模型评估
在测试集上评估模型的性能,并通过计算准确率、F1-score等指标来判断模型的效果。
```python
model.eval()
with torch.no_grad():
total_loss = 0
for src, tgt in test_loader:
output = model(src, tgt)
loss = criterion(output.view(-1, output_dim), tgt.view(-1))
total_loss += loss.item()
avg_loss = total_loss / len(test_loader)
```
#### 5. 预测
在完成模型训练后,可以使用模型进行预测。
```python
with torch.no_grad():
predictions = model(input_data)
```
### 四、总结
Transformer模型的提出不仅有效地解决了长距离依赖的问题,还提高了训练效率和模型性能,开创了无数NLP任务的新局面。其在多头注意力、自注意力机制以及编码器-解码器结构等方面的创新,使得它在当前的深度学习领域中稳居前列。尽管如此,Transformer仍面临着许多挑战,例如对计算资源的高需求、复杂性以及对大规模数据的依赖。未来的发展方向可能会包括更轻量级的变种、训练方法的优化以及在其他领域的应用扩展。随着研究的深入和技术的进步,Transformer必将在人工智能的未来扮演更加重要的角色。
下面将提供一个基本的Transformer预测模型的Python和MATLAB实现示例。将使用PyTorch实现Python版本,而MATLAB示例将使用其深度学习工具箱。
### Python实现(使用PyTorch)
以下是一个简单的Transformer模型的实现,假设在进行时间序列预测或序列到序列预测的任务。
```python
import torch
import torch.nn as nn
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 数据生成(示例)
def generate_data(n_samples=1000, seq_length=10):
X = np.random.rand(n_samples, seq_length, 1) # 假设有一个特征
y = np.sum(X, axis=1) # 标签是序列之和
return X, y
# 生成数据
X, y = generate_data()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 转换为PyTorch tensor
X_train_tensor = torch.FloatTensor(X_train)
y_train_tensor = torch.FloatTensor(y_train).view(-1, 1)
X_test_tensor = torch.FloatTensor(X_test)
y_test_tensor = torch.FloatTensor(y_test).view(-1, 1)
# 定义Transformer模型
class TransformerModel(nn.Module):
def __init__(self, input_dim, model_dim=64, n_heads=4, num_encoder_layers=2):
super(TransformerModel, self).__init__()
self.model_dim = model_dim
self.fc_in = nn.Linear(input_dim, model_dim)
self.transformer_encoder = nn.TransformerEncoder(
nn.TransformerEncoderLayer(model_dim, n_heads), num_layers=num_encoder_layers)
self.fc_out = nn.Linear(model_dim, 1)
def forward(self, x):
x = self.fc_in(x) # 输入线性变换
x = self.transformer_encoder(x)
x = x.mean(dim=1) # 使用序列平均池化
x = self.fc_out(x)
return x
# 实例化模型
model = TransformerModel(input_dim=1)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练模型
num_epochs = 100
for epoch in range(num_epochs):
model.train()
optimizer.zero_grad()
outputs = model(X_train_tensor)
loss = criterion(outputs, y_train_tensor)
loss.backward()
optimizer.step()
if (epoch + 1) % 10 == 0:
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')
# 评估模型
model.eval()
with torch.no_grad():
predicted = model(X_test_tensor)
mse = criterion(predicted, y_test_tensor)
print(f'Test Mean Squared Error: {mse.item():.4f}')
```
### MATLAB实现
以下是用MATLAB实现简单的Transformer预测模型的示例。
```matlab
% 生成示例数据
[X, y] = generate_data(1000, 10); % 自定义的生成数据函数。
cv = cvpartition(size(X, 1), 'HoldOut', 0.2);
idx = cv.test;
X_train = X(~idx, :, :);
y_train = y(~idx);
X_test = X(idx, :, :);
y_test = y(idx);
% 数据标准化
X_train = (X_train - mean(X_train, 1)) ./ std(X_train, 0, 1);
X_test = (X_test - mean(X_train, 1)) ./ std(X_train, 0, 1);
% 定义Transformer模型
layers = [
sequenceInputLayer(1, "Name", "input")
transformerEncoderLayer(64, 4, "Name", "encoder")
attentionLayer(64, 4, "Name", "attention")
fullyConnectedLayer(1, "Name", "output")
regressionLayer("Name", "regression")
];
% 训练网络
options = trainingOptions('adam', ...
'MaxEpochs', 100, ...
'MiniBatchSize', 32, ...
'Verbose', false, ...
'Plots', 'training-progress');
% 训练模型
net = trainNetwork(X_train, y_train, layers, options);
% 预测
YPred = predict(net, X_test);
% 计算均方误差
mse = mean((YPred - y_test).^2);
fprintf('Test Mean Squared Error: %.4f\n', mse);
```
### 说明
- Python实现中,使用了PyTorch构建了一个基本的Transformer模型,使用了线性层在输入和输出之间的映射。
- MATLAB实现中,定义了输入层、Transformer编码器层和输出层,使用了MATLAB深度学习工具箱模块来实现Transformer。
- 注意,MATLAB中的数据生成和标准化部分需要根据实际情况实现或修改,并且MATLAB中新版本的编程符号可能有所变化。
相关文章:
Transformer预测模型及其Python和MATLAB实现
### 一、背景 在自然语言处理(NLP)领域,传统的序列到序列(Seq2Seq)模型大多依赖于循环神经网络(RNN)和长短期记忆(LSTM)网络。这些模型虽然在许多任务中取得了成功&…...

草的渲染理论
Unity引擎提供了基础的terrain工具,可以制作地形,在上面刷树刷草。对于树,Unity是支持带LOD的Prefab,不同距离显示不同细节的模型,效果还不错。对于草,Unity支持两种方式来刷草,一种是Add Grass…...

Redis:十大数据类型
键(key) 常用命令 1. 字符串(String) 1.1 基本命令 set key value 如下:设置kv键值对,存货时长为30秒 get key mset key value [key value ...]mget key [key ...] 同时设置或者获取多个键值对 getrange…...

bugku-web-source
kali中先用dirsearch工具扫描后台目录,然后用wget -r url/.git命令递归下载后,进入txt文件使用git reflog命令然后只用git show查看作者提交flag日志,用git show 一个一个去尝试,很多假的flag git reflog 是一个 Git 命令&#x…...

一键生成视频并批量上传视频抖音、bilibili、腾讯(已打包)
GenerateAndAutoupload Github地址:https://github.com/cmdch2017/GenerateAndAutoupload 如何下载(找到最新的release) https://github.com/cmdch2017/GenerateAndAutoupload/releases/download/v1.0.1/v1.0.1.zip 启动必知道 conf.py …...

Python WSGI服务器库之gunicorn使用详解
概要 在部署 Python Web 应用程序时,选择合适的 WSGI 服务器是关键的一步。Gunicorn(Green Unicorn)是一个高性能、易于使用的 Python WSGI HTTP 服务器,适用于各种应用部署场景。Gunicorn 设计简洁,支持多种工作模式,能够有效地管理和处理大量并发请求。本文将详细介绍…...

Java编程达人:每日一练,提升自我
目录 题目1.以下哪个单词不是 Java 的关键字?2.boolean 类型的默认值为?3.以下代码输出正确的是?4.以下代码,输出结果为:5.以下代码输出结果为:6.以下代码输出结果为?7.float 变量的默认值为&am…...

(35)远程识别(又称无人机识别)(二)
文章目录 前言 4 ArduRemoteID 5 终端用户数据的设置和使用 6 测试 7 为OEMs添加远程ID到ArduPilot系统的视频教程 前言 在一些国家,远程 ID 正在成为一项法律要求。以下是与 ArduPilot 兼容的设备列表。这里(here)有一个关于远程 ID 的很好解释和常见问题列表…...

提供三方API接口、调用第三方接口API接口、模拟API接口(一)通过signature签名验证,避免参数恶意修改
为什么要设计安全的api接口 运行在外网服务器的接口暴露在整个互联网中,可能会受到各种攻击,例如恶意爬取服务器数据、恶意篡改请求数据等,因此需要一个机制去保证api接口是相对安全的。 本项目api接口安全设计 本项目api接口的安全性主要…...

CDO学习
1.备份instie.mdb文件 2....

奥运会Ⅱ---谁会先抢走你的工作?
Devin AI 与 Microsoft AutoDev,谁会先抢走你的工作? 软件开发领域正处于一场革命的风口浪尖。Devin AI和Microsoft AutoDev 的出现,是人工智能编码领域的两项突破性进步,有望重塑软件构建方式。但是,在如此截然不同的…...

用Python打造精彩动画与视频,4.3 创建动态文本和字幕
第四章:深入MoviePy 4.3 创建动态文本和字幕 在视频编辑中,动态文本和字幕是传达信息、增强观众体验的重要元素。MoviePy 提供了丰富的工具来添加和自定义文本和字幕,包括字体、颜色、动画效果等。本节将介绍如何在视频中添加动态文本和字幕…...
spring boot + vue3 接入钉钉实现扫码登录
1:准备工作 1.1:进入钉钉开放平台创建开发者应用。应用创建和类型介绍,参考下方。 应用类型介绍 - 钉钉开放平台 (dingtalk.com) 应用能力介绍 - 钉钉开放平台 (dingtalk.com) 扫码登录第三方网站 - 钉钉开放平台 (dingtalk.com) 1.2&…...

二叉树构建(从3种遍历中构建)python刷题记录
R3-树与二叉树篇. 目录 从前序与中序遍历序列构造二叉树 算法思路: 灵神套路 从中序与后序遍历序列构造二叉树 算法思路: 灵神套路 从前序和后序遍历序列构造二叉树 算法思路: 灵神套路 从前序与中序遍历序列构造二叉树 算法…...

计算机网络中协议与报文的关系
协议和报文在网络通信中扮演着不同的角色,但它们是紧密相关的。 协议是计算机网络中实现通信的“约定”,它规定了计算机之间如何进行通信,包括数据传输的格式、步骤和规则。协议确保了不同厂商的设备、不同的CPU和操作系统之间的计算机能够相…...

机器学习 第8章-集成学习
机器学习 第8章-集成学习 8.1 个体与集成 集成学习(ensemble learning)通过构建并结合多个学习器来完成学习任务,有时也被称为多分类器系统(multi-classifersystem)、基于委员会的学习(committee-based learning)等。 图8.1显示出集成学习的一般结构:先产生一组“…...

Docker 安装 GitLab教程
本章教程,主要介绍如何在Docker 中安装GitLab。 GitLab 是一个开源的 DevOps 平台,提供了一整套工具,用于软件开发生命周期的各个阶段,从代码管理到 CI/CD(持续集成和持续交付/部署),再到监控和安全分析。 一、拉取镜像 docker pull gitlab/gitlab-ce:latest二、创建 G…...

如何在生产环境中千万表添加索引并保证数据一致性
技术分享文档:如何在生产环境中千万表添加索引并保证数据一致性 目录 引言添加索引的挑战解决方案概述详细步骤 4.1 创建新表并添加索引 4.2 批量导入数据 4.3 处理增量数据 4.4 表名切换确保数据一致性 5.1 暂停写操作 5.2 记录增量数据 5.3 应用增量数据设置回滚…...

Uni-APP页面跳转问题(十六)
【背景】最近在做公司一个PAD端,谁被点检功能,主要时为了移动端点检设备和打印标签,需求比较简单就是扫描设备二维码,问题在于扫描后要能够重复进行多设备的扫描;早期开发的设备点检能够满足需求但是当连续扫描五六十个设备后,APP卡死,必须重启才能使用。 界面原图: 输…...

Java新特性(二) Stream与Optional详解
Java8新特性(二) Stream与Optional详解 一. Stream流 1. Stream概述 1.1 基本概念 Stream(java.util.stream) 是Java 8中新增的一种抽象流式接口,主要用于配合Lambda表达式提高批量数据的计算和处理效率。Stream不是…...

springboot 百货中心供应链管理系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,百货中心供应链管理系统被用户普遍使用,为方…...

剑指offer20_链表中环的入口节点
链表中环的入口节点 给定一个链表,若其中包含环,则输出环的入口节点。 若其中不包含环,则输出null。 数据范围 节点 val 值取值范围 [ 1 , 1000 ] [1,1000] [1,1000]。 节点 val 值各不相同。 链表长度 [ 0 , 500 ] [0,500] [0,500]。 …...

3403. 从盒子中找出字典序最大的字符串 I
3403. 从盒子中找出字典序最大的字符串 I 题目链接:3403. 从盒子中找出字典序最大的字符串 I 代码如下: class Solution { public:string answerString(string word, int numFriends) {if (numFriends 1) {return word;}string res;for (int i 0;i &…...
可以参考以下方法:)
根据万维钢·精英日课6的内容,使用AI(2025)可以参考以下方法:
根据万维钢精英日课6的内容,使用AI(2025)可以参考以下方法: 四个洞见 模型已经比人聪明:以ChatGPT o3为代表的AI非常强大,能运用高级理论解释道理、引用最新学术论文,生成对顶尖科学家都有用的…...

在Mathematica中实现Newton-Raphson迭代的收敛时间算法(一般三次多项式)
考察一般的三次多项式,以r为参数: p[z_, r_] : z^3 (r - 1) z - r; roots[r_] : z /. Solve[p[z, r] 0, z]; 此多项式的根为: 尽管看起来这个多项式是特殊的,其实一般的三次多项式都是可以通过线性变换化为这个形式…...
)
华为OD最新机试真题-数组组成的最小数字-OD统一考试(B卷)
题目描述 给定一个整型数组,请从该数组中选择3个元素 组成最小数字并输出 (如果数组长度小于3,则选择数组中所有元素来组成最小数字)。 输入描述 行用半角逗号分割的字符串记录的整型数组,0<数组长度<= 100,0<整数的取值范围<= 10000。 输出描述 由3个元素组成…...

消防一体化安全管控平台:构建消防“一张图”和APP统一管理
在城市的某个角落,一场突如其来的火灾打破了平静。熊熊烈火迅速蔓延,滚滚浓烟弥漫开来,周围群众的生命财产安全受到严重威胁。就在这千钧一发之际,消防救援队伍迅速行动,而豪越科技消防一体化安全管控平台构建的消防“…...
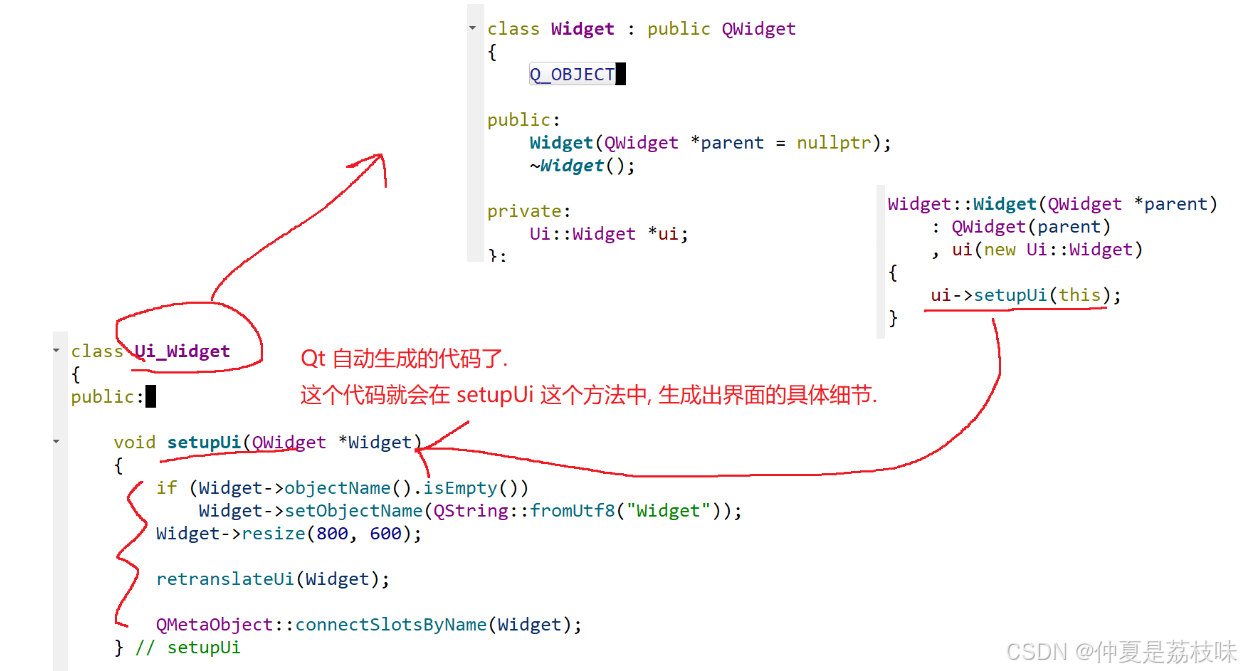
Qt的学习(一)
1.什么是Qt Qt特指用来进行桌面应用开发(电脑上写的程序)涉及到的一套技术Qt无法开发网页前端,也不能开发移动应用。 客户端开发的重要任务:编写和用户交互的界面。一般来说和用户交互的界面,有两种典型风格&…...

负载均衡器》》LVS、Nginx、HAproxy 区别
虚拟主机 先4,后7...
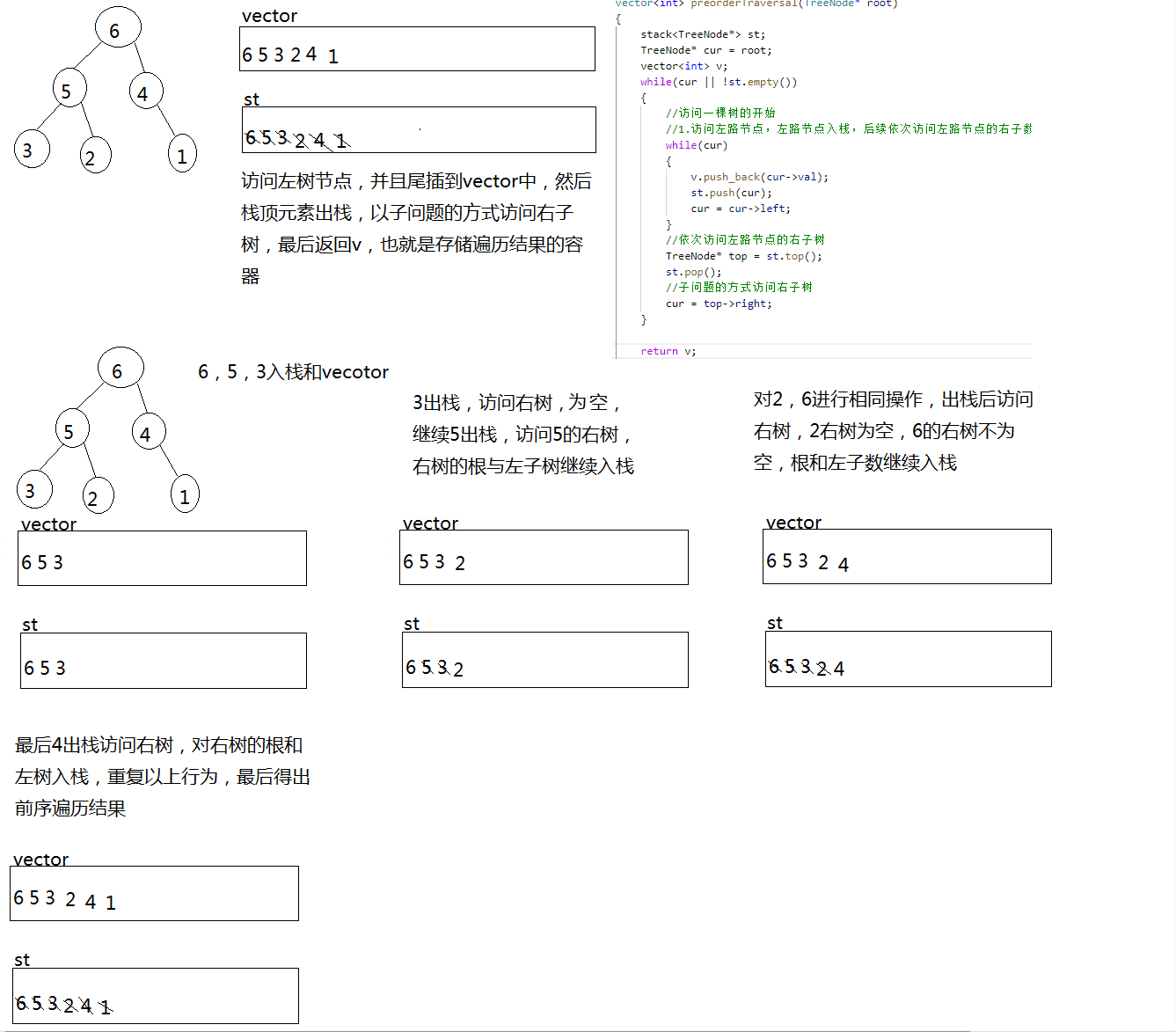
二叉树-144.二叉树的前序遍历-力扣(LeetCode)
一、题目解析 对于递归方法的前序遍历十分简单,但对于一位合格的程序猿而言,需要掌握将递归转化为非递归的能力,毕竟递归调用的时候会调用大量的栈帧,存在栈溢出风险。 二、算法原理 递归调用本质是系统建立栈帧,而非…...