Flink 实时数仓(二)【DIM 层搭建】
1、DIM 层搭建
1.1、设计要点
DIM层设计要点:
- DIM层存的是维度表(环境信息,比如人、场、货等)
- DIM层的数据存储在 HBase 表中
- DIM层表名的命名规范为dim_表名
DIM 层表是用于维度关联的,要通过主键(维度外键)去获取相关维度信息,这种场景下 K-V 类型数据库的效率较高。常见的 K-V 类型数据库有 Redis、HBase,而 Redis 的数据常驻内存,会给内存造成较大压力,所以这里选用 HBase 存储维度数据。
1.2、设计分析
在 ODS 层,我们需要首先把所有维表全量同步一次,之后当事实数据来了的时候就可以直接关联;现在 DIM 层,我们需要考虑的问题就是,如何把维表信息保存到 HBase:
- 读取数据
- Kafka 的 topic_db 主题中(包含所有46张业务表)
- 可以使用 Flink 的 Kafka 连接器读取
- 过滤数据
- 从 46 张业务表中过滤出所有维表数据
- 在代码中写死十几张维度表的表名
- 问题:如果增加维表就需要修改代码重新编译项目,重启任务
- 思考:如何不修改代码且不重启任务?
- 1)定时任务:每隔一段时间加载一次配置信息(实时性不好,不可取)
- 2)监控配置信息:
- MySQL binlog:配置信息写到 MySQL,然后使用 FlinkCDC 监控直接创建流(数据流 connect 配置流,将配置流中的信息写入到状态中,然后数据流把状态中存在的表过滤出来)
- 文件:Flume tailDir Source -> Kafka -> Flink 的 kafka source 消费创建流(太复杂了,不可取)
- 从 46 张业务表中过滤出所有维表数据
注意:多个并行度下,配置流中的数据(需要过滤的表名)会被分配给多个相同的算子处理,会导致并行算子之间的状态不一致,可能导致数据丢失的问题;这就需要把配置流做成一个广播流来和数据流进行 connect,这样写入并行算子的状态就是一致的了;
广播流的缺点就是存在冗余,而且并行度越大冗余也越大;配置信息小点还好,如果配置信息很大,那么将会占用的资源页越大;这种情况下我们的解决办法就是分流:
对数据流和配置流都按照表名进行 keyby,相同的 key 再去做 connect,但是这种方案会产生数据倾斜;
- 写出数据
- 使用 Phoenix 写出到 HBase(使用 JdbcSink,如果不行就自定义 Sink)
1.3、DIM 层实现
DIM 层的主要任务:读取 Kafka 的数据 -> 简单ETL -> 保存到HBase
Maxwell 同步过来的数据是到 Kafka 的,我们通过 Flink 自带的 Kafka 连接器进行连接读取,然后对数据先进行简单的 ETL,比如
- 删除掉非 JSON 格式的数据(这里因为是业务数据所以一般不会有非JSON的情况出现,但是日志数据可能会存在这种情况)
- 删除掉 type 为 bootstrap-start 和 bootstrap-complete 的数据;
- 删除掉 type 为 delete 的数据;
最后,通过 Phoenix API 将数据插入到 HBase;

1.3.1、读取 Kafka 中的数据
读取 Kafka 中的数据为的是创建主流,这里设计到的一个重点就是:Flink 作为消费者在从 Kafka 消费的时候需要对数据进行反序列化,而在反序列时如果使用 Flink 默认的 Kafka 反序列化器(FlinkKafkaConsumer)进行消费的话,可能会出现空指针异常:


可以看到,反序列化方法中是直接把 kafka message 创建为一个 String 对象,但是 String 的构造器源码中明确声明构造参数不可为 null,而我们的 message 又不可避免存在一些空值,所以这里我们需要重写 FlinkKafkaConsumer 的反序列化方法:
public class MyKafkaUtil {private static final String KAFKA_SERVER = "hadoop102:9092";public static FlinkKafkaConsumer<String> getFlinkKafkaConsumer(String topic,String groupId){Properties properties = new Properties();properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG,groupId);properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,KAFKA_SERVER);return new FlinkKafkaConsumer<String>(topic,// 反序列化格式new KafkaDeserializationSchema<String>() {@Overridepublic boolean isEndOfStream(String nextElement) {return false; // 无界流所以返回 false}@Overridepublic String deserialize(ConsumerRecord<byte[], byte[]> record) throws Exception {if (record == null || record.value() == null){return null;}else {return new String(record.value());}}@Overridepublic TypeInformation<String> getProducedType() {return BasicTypeInfo.STRING_TYPE_INFO;}},properties);}
}这样,我们就可以直接使用通过 Kafka 地址、主题 和 组id 使用 Flink 对 Kafka 的主题进行消费:
env.addSource(MyKafkaUtil.getFlinkKafkaConsumer(topic, groupId));
至此,我们的主流已经创建完毕;
1.3.2、简单 ETL
这一步主要为的是将不必要的数据移除掉,比如非JSON数据(日志数据中才可能出现)、maxwell 的脏数据( bootstrap-start 、bootstrap-complete 和 delete)这种无意义的信息;
public class DimApp {public static void main(String[] args) {// TODO 1. 获取执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1); // 生产环境中设置为kafka主题的分区数// 1.1 开启checkpointenv.enableCheckpointing(5 * 60000L, CheckpointingMode.EXACTLY_ONCE);env.getCheckpointConfig().setCheckpointStorage("hdfs://hadoop102:8020/s/ck");env.getCheckpointConfig().setCheckpointTimeout(10 * 60000L);env.getCheckpointConfig().setMaxConcurrentCheckpoints(2); // 设置最大共存的checkpoint数量env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3,5000L)); // 固定频率重启: 尝试3次重启,每5s重启一次// 1.2 设置状态后端env.setStateBackend(new HashMapStateBackend());// TODO 2. 读取Kafka的topic_db主题,创建主流String topic = "topic_db";String groupId = "test";DataStreamSource<String> kafkaDS = env.addSource(MyKafkaUtil.getFlinkKafkaConsumer(topic, groupId));// TODO 3. ETL// TODO 3.1 过滤掉非JSON数据以及Maxwell的脏数据SingleOutputStreamOperator<JSONObject> filterJsonDS = kafkaDS.flatMap(new FlatMapFunction<String, JSONObject>() {@Overridepublic void flatMap(String value, Collector<JSONObject> out) throws Exception {try {// 过滤非JSON数据JSONObject jsonObject = JSON.parseObject(value);String type = jsonObject.getString("type");if ("bootstrap-insert".equals(type) || "insert".equals(type) || "update".equals(type)) {out.collect(jsonObject);}} catch (Exception e) {System.out.println("发现脏数据" + value);}}});// ...}
}关于 Flink 的并行度,生产中一般设置为 Kafka 的分区数量(使消费者数量 = 主题分区数量),而不是机器的 CPU核数(机器总不能只跑这一个任务)!
1.3.3、动态增删维表
现在我们需要从 46 张业务表中过滤出需要的维表,而且这个维表并不是写死的,很可能会出现新增和删除,所以我们希望做到不修改代码且不重启服务的情况下实现,我们上面业说过了,最好使用监控配置信息的方式,一共有三种解决方案:
- MySQL binlog
- 也就是把配置信息做成表格,使用 FlinkCDC 实时监控,使用双流联结(主流和配置流),配置流把配置信息(需要同步的维度表信息,包括业务系统中的维表名、写入到phoenix的表名、字段、主键、额外信息等)写入到状态当中,然后主流再去状态中读取并处理;
- 文件:使用 Flume 的 tailDir source 实时监听文件内容,写到 Kafka 当中,Flink 再从 Kafka 去读,这种方式太复杂了,一般不用
- Zookeeper:通过 Zookeeper 的 watch 机制将配置信息写入到一个 znode 节点,同样比较复杂
综上,我们一般选择第一种方案:
1)创建配置表
CREATE TABLE `table_process` (`source_table` varchar(200) NOT NULL COMMENT '业务系统来源表', -- mysql业务系统中的表名`sink_table` varchar(200) DEFAULT NULL COMMENT 'phoenix输出表', -- phoenix的表名`sink_columns` varchar(2000) DEFAULT NULL COMMENT 'phoenix建表所需字段', -- 建表需要的字段,过滤主流数据字段`sink_pk` varchar(200) DEFAULT NULL COMMENT 'phoenix建表的主键字段', -- 建表使用的主键(表名做主键)`sink_extend` varchar(200) DEFAULT NULL COMMENT 'phoenix建表扩展', -- 比如预分区等信息PRIMARY KEY (`source_table`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;这里,我们将 source_table 作为配置表的主键,这样可以通过它获取到该表需要同步的字段、主键和建表扩展,从而得到完整的 Phoenix 建表语句。
2)创建配置表的实体类
配置流在创建的时候我们并不会直接把它转为 JSON 格式,毕竟我们还要对它进行一些处理,而操作java对象比json对象要更容易;
@Data
public class TableProcess {//来源表String sourceTable;//输出表String sinkTable;//输出字段String sinkColumns;//主键字段String sinkPk;//建表扩展String sinkExtend;
}3)使用 FlinkCDC 创建配置流
注意:FlinkCDC 把 binlog 读取过来会转为 json 格式
// TODO 4. 使用FlinkCDC读取MySQL配置信息表创建配置流MySqlSource<String> mySqlSource = MySqlSource.<String>builder().hostname("hadoop102").port(3306).username("root").password("123456").databaseList("gmall").tableList("gmall.table_config").startupOptions(StartupOptions.initial()) // 全部读取.deserializer(new JsonDebeziumDeserializationSchema()) // flink读取binlog会把它转为json格式,所以这里需要一共json的反序列化方式.build();DataStreamSource<String> mysqlSourceDS = env.fromSource(mySqlSource,WatermarkStrategy.noWatermarks(),"MysqlSource");4)配置流形成广播流
配置流不能直接和主流联结,会造成数据丢失(多并行度下,配置信息会轮询发送到相同的算子上),所以我们需要把它转为广播流;
创建广播流需要传入一个 Map 类型的状态描述器:
- K 必须是主流和配置流都有的信息,这样主流才能和广播流产生关联,所以这里我们使用表名做为 K;
- V 是配置流中的数据,这里我们选择上面自定义 TableProcess 对象,这个对象包含了该表(K)的所有配置信息;
// TODO 5. 将配置流处理为广播流// K的要求: 1.必须是主流和配置流都有的字段 2. 唯一// V: 这里的v应该是配置流中的数据,但是为了方便过滤字段(操作java对象比json对象要容易),所以这里转为Java对象MapStateDescriptor<String, TableProcess> mapStateDescriptor = new MapStateDescriptor<>("map-state", String.class, TableProcess.class);// 这里的泛型是广播流的类型BroadcastStream<String> configBroadcastStream = mysqlSourceDS.broadcast(mapStateDescriptor);
5)双流联结并处理
这里对主流和配置流联结后需要进行处理:
- 把配置流中的配置信息写入到状态后端使其自动广播
- 从配置流(FlinkCDC 读取过来 json 信息)中提取出表格信息
- 校验 phoenix 表格(不存在就创建)
- 写入到状态中(因为现在是广播流所以会自动广播)
- 把主流中的非维表去除掉,以及维表中不需要的字段
- 从状态中获得配置信息
- 除去非维表并过滤字段,只留下配置流当中存在的字段
- 给主流添加上配置信息中的 sinkTable 字段(因为主流不知道最终向哪个phoenix表写入)
// TODO 6. 连接主流和广播流// 这里的泛型: 1. 非广播流的数据类型 2. 广播流的数据类型BroadcastConnectedStream<JSONObject, String> connectedStream = filterJsonDS.connect(configBroadcastStream);// TODO 7. 处理连接流,根据配置信息处理主流数据// 得到维表数据流(已经把配置流中不需要的维表字段过滤掉了,以及非维表也被过滤掉了)SingleOutputStreamOperator<JSONObject> dimDS = connectedStream.process(new TableProcessFunction(mapStateDescriptor));
这里的 TableProcessFunction 是我们自定义的广播流处理函数:
// 这里的泛型: 1. 非广播流的数据类型 2. 广播流的数据类型 3. 输出类型这里选择主流的数据类型,因为毕竟我们用配置流的目的就是为了得到过滤后的主流数据
public class TableProcessFunction extends BroadcastProcessFunction<JSONObject, String, JSONObject> {private Connection connection;private MapStateDescriptor<String, TableProcess> mapStateDescriptor;public TableProcessFunction(MapStateDescriptor<String, TableProcess> mapStateDescriptor){this.mapStateDescriptor = mapStateDescriptor;}// 保证每个并行度创建一个连接@Overridepublic void open(Configuration parameters) throws Exception {connection = DriverManager.getConnection(GmallConfig.PHOENIX_SERVER);}@Overridepublic void close() throws Exception {connection.close();}/*** value 的值:* {* "before":null,* "after":{* "source_table":"aa",* "sink_table":"bb",* "sink_columns":"cc",* "sink_pk":"id",* "sink_extend":"xxx"},* "source":{* "version":"1.5.4.Final",* "connector":"mysql",* "name":"mysql_binlog_source",* "ts_ms":1652513039549,* "snapshot":"false",* "db":"gmall-211126-config",* "sequence":null,* "table":"table_process",* "server_id":0,* "gtid":null,* "file":"",* "pos":0,* "row":0,* "thread":null,* "query":null},* "op":"r",* "ts_ms":1652513039551,* "transaction":null}*/@Overridepublic void processBroadcastElement(String value, Context context, Collector<JSONObject> collector) throws Exception {// TODO 1. 获取并解析数据,方便主流操作(把 "after" 字段的内容解析为 TableProcess 对象)JSONObject jsonObject = JSONObject.parseObject(value);TableProcess tableProcess = JSONObject.parseObject(jsonObject.getString("after"), TableProcess.class);// TODO 2. 校验表在phoenix中是否存在checkTable(tableProcess.getSinkTable(),tableProcess.getSinkColumns(),tableProcess.getSinkPk(),tableProcess.getSinkExtend());// TODO 3. 写入状态,广播出去BroadcastState<String, TableProcess> broadcastState = context.getBroadcastState(mapStateDescriptor);broadcastState.put(tableProcess.getSourceTable(),tableProcess);}/*** 校验并创建phoenix表: create table if not exists db.tb(xx varchar primary key,xx varchar, ...) xxx* @param sinkTable 表名* @param sinkColumns 字段* @param sinkPk 主键* @param sinkExtend 扩展字段*/private void checkTable(String sinkTable, String sinkColumns, String sinkPk, String sinkExtend) {PreparedStatement preparedStatement = null;try {// 处理特殊字段值(null)if (sinkPk == null || "".equals(sinkPk))sinkPk = "id";if (sinkExtend == null)sinkExtend = "";// 拼接 SQLStringBuilder sql = new StringBuilder("create table if not exists ").append(GmallConfig.HBASE_SCHEMA).append(".").append(sinkTable).append("(");String[] columns = sinkColumns.split(",");for (int i = 0; i < columns.length-1; i++) {sql.append(" ").append(columns[i]).append(" varchar");if (columns[i].equals(sinkPk))sql.append(" primary key");sql.append(",");}sql.append(columns[columns.length-1]).append(") ").append(sinkExtend);// 编译 SQLpreparedStatement = connection.prepareStatement(sql.toString());// 执行 SQLpreparedStatement.execute();}catch (SQLException e){// 要停止程序必须使用运行时异常而不是编译时异常throw new RuntimeException("建表失败 " + sinkTable);}finally {// 释放资源if (preparedStatement != null){try {preparedStatement.close();} catch (SQLException e) {e.printStackTrace();}}}}// 主流数据是一个json格式(maxwell数据)/*** {* "database":"gmall-211126-flink",* "table":"base_trademark",* "type":"bootstrap-insert",* "ts":1652499295,* "data":{* "id":1,* "tm_name":"三星",* "logo_url":"/static/default.jpg"* }* }*/@Overridepublic void processElement(JSONObject jsonObject, ReadOnlyContext readOnlyContext, Collector<JSONObject> collector) throws Exception {// TODO 1. 获取广播的配置数据ReadOnlyBroadcastState<String, TableProcess> broadcastState = readOnlyContext.getBroadcastState(mapStateDescriptor);// 如果返回 null 说明不是维表TableProcess tableProcess = broadcastState.get(jsonObject.getString("table"));// TODO 2. 过滤字段,只留下配置流当中存在的字段if (tableProcess == null) return;filterColumns(jsonObject.getJSONObject("data"),tableProcess.getSinkColumns());// TODO 3. 补充 SinkTable 字段(因为主流中是不包含phoenix表名的)jsonObject.put("sinkTable",tableProcess.getSinkTable());collector.collect(jsonObject);}/*** 过滤字段: 将主流中配置流中有的字段留下,其它字段删除* @param data 可能是维表,也可能是事实表 {"database":"gmall-211126-flink","table":"base_trademark","type":"bootstrap-insert","ts":1652499295,"data":{"id":1,"tm_name":"三星","logo_url":"/static/default.jpg"}}* @param sinkColumns phoenix 列名*/private void filterColumns(JSONObject data, String sinkColumns) {// 把 JSONObject 当做 Map 处理即可String[] split = sinkColumns.split(",");Set<String> phoenix_columns = new HashSet<>(Arrays.asList(split));for (String column : data.keySet()){if (!phoenix_columns.contains(column)){data.remove(column);}}// 简写: data.entrySet().removeIf(entry -> !phoenix_columns.contains(entry.getKey()));}}至此,我们就得到了最终等待写入到 HBase 的流 dimDS;
1.3.4、写入 Phoenix
上面我们在连接 phoenix 校验表格的时候用的是 jdbc 来访问的,而 Flink 也提供了 JdbcSink 连接器,那这里我们能不能使用呢?

其实这里使用 JdbcSink 是可以的,但是不推荐,因为 JdbcSink 适合的是单表写入的场景,而我们的 dimDS 数据流中存放的是多个维度表的数据,这就要求当数据来的时候,我们要根据不同的表生成不同的 SQL,而这里的 addSink 方法中的 sql 语句必须是先给定的,尽管不确定的表名、字段名等可以使用占位符,但是我们不能保证所有维表的字段数量都是一样的;所以,这种方式显然不可取,那我们就只能自定义一个 Sink 了:
1)创建 Druid 连接池
Phoenix 是支持 JDBC 协议,这里为了方便连接管理我们使用 Druid 来创建连接池;
public class DruidDSUtil {private static DruidDataSource druidDataSource = null;public static DruidDataSource createDataSource() {// 创建连接池druidDataSource = new DruidDataSource();// 设置驱动全类名druidDataSource.setDriverClassName(GmallConfig.PHOENIX_DRIVER);// 设置连接 urldruidDataSource.setUrl(GmallConfig.PHOENIX_SERVER);// 设置初始化连接池时池中连接的数量druidDataSource.setInitialSize(5);// 设置同时活跃的最大连接数druidDataSource.setMaxActive(20);// 设置空闲时的最小连接数,必须介于 0 和最大连接数之间,默认为 0druidDataSource.setMinIdle(1);// 设置没有空余连接时的等待时间,超时抛出异常,-1 表示一直等待druidDataSource.setMaxWait(-1);// 验证连接是否可用使用的 SQL 语句druidDataSource.setValidationQuery("select 1");// 指明连接是否被空闲连接回收器(如果有)进行检验,如果检测失败,则连接将被从池中去除// 注意,默认值为 true,如果没有设置 validationQuery,则报错// testWhileIdle is true, validationQuery not setdruidDataSource.setTestWhileIdle(true);// 借出连接时,是否测试,设置为 false,不测试,否则很影响性能druidDataSource.setTestOnBorrow(false);// 归还连接时,是否测试druidDataSource.setTestOnReturn(false);// 设置空闲连接回收器每隔 30s 运行一次druidDataSource.setTimeBetweenEvictionRunsMillis(30 * 1000L);// 设置池中连接空闲 30min 被回收,默认值即为 30 mindruidDataSource.setMinEvictableIdleTimeMillis(30 * 60 * 1000L);return druidDataSource;}
}2)Phoenix 工具类
为了方法的复用性,我们把写入 Phoenix 的方法抽出来:
public class PhoenixUtil {/*** 将主流数据写入 phoenix* @param connection phoenix连接* @param sinkTable 表名* @param data 数据* @throws SQLException 这里的异常直接抛出去.因为工具类中的方法是给大家公用的,而不同的业务捕获到异常的处理方案是不一样的* 所以这里把处理异常的权利交给每个调用该方法的人*/public static void upsertValues(DruidPooledConnection connection, String sinkTable, JSONObject data) throws SQLException {// 1. 拼接 SQL: upsert into db.tb(id,name,sex) values ('1001','zhangsan','man')Set<String> columns = data.keySet();Collection<Object> values = data.values();String sql = "upsert into " + GmallConfig.HBASE_SCHEMA + "." + sinkTable + "("+ StringUtils.join(columns,",") +") values ( '"+ StringUtils.join(values,"','") + "')";// 2. 预编译 SQLPreparedStatement preparedStatement = connection.prepareStatement(sql);// 3. 执行preparedStatement.execute();connection.commit();// 4. 释放资源preparedStatement.close(); // connection 在 Sink 的 invoke 里面关}
}3)自定义 Sink
自定义 Sink ,在 open 方法中获得连接,在 invoke 中执行插入数据到 Phoenix ,然后回收连接;
// 输入数据类型应该是 dimDS 的类型,也就是主流类型 JSONObject
public class DimSinkFunction extends RichSinkFunction<JSONObject> {private DruidDataSource druidDataSource = null;@Overridepublic void open(Configuration parameters) throws Exception {druidDataSource = DruidDSUtil.createDataSource();}/*** value:* {* "database":"gmall-211126-flink",* "table":"base_trademark",* "type":"bootstrap-insert",* "ts":1652499295,* "data":{* "id":1,* "tm_name":"三星"* },* "sinkTable": "dim_xxx"* }*/@Overridepublic void invoke(JSONObject value, Context context) throws Exception {// 获取连接DruidPooledConnection connection = druidDataSource.getConnection();// 写出数据(需要知道写出的表名、字段)String sinkTable = value.getString("sinkTable");JSONObject data = value.getJSONObject("data");// 如果插入数据失败 invoke 方法抛出的 Exception 会导致程序停止PhoenixUtil.upsertValues(connection,sinkTable,data);// 归还连接connection.close();}
}总结
至此,DIM 层搭建完毕,在离线数仓的 DIM 层中,它需要在 ODS 层的基础上抽取出主维表和相关维表,然后主维表通过 left join 相关维表得到最终的 dim 层的维表;而实时数仓中我们主要是通过 Flink 代码来对数据流进行实时处理,代码的编写确实比 SQL 更有意思;
相关文章:
Flink 实时数仓(二)【DIM 层搭建】
1、DIM 层搭建 1.1、设计要点 DIM层设计要点: DIM层存的是维度表(环境信息,比如人、场、货等)DIM层的数据存储在 HBase 表中DIM层表名的命名规范为dim_表名 DIM 层表是用于维度关联的,要通过主键(维度外…...
知识图谱开启了一个可以理解的人工智能未来
概述 本文是对利用知识图谱(KG)的综合人工智能(CAI)的全面调查研究,其中 CAI 被定义为可解释人工智能(XAI)和可解释机器学习(IML)的超集。 首先,本文澄清了…...

借助Aspose.html控件, 将SVG 转PNG 的 C# 图像处理库
Aspose.HTML for .NET 不仅提供超文本标记语言 ( HTML ) 文件处理,还提供流行图像文件格式之间的转换。您可以利用丰富的渲染和转换功能将SVG文件渲染为PNG、JPG或其他广泛使用的文件格式。但是,我们将使用此C# 图像处理库以编程方式在 C# 中将 SVG 转换…...

vs-2015安装教程
双击安装包 2-如图先选自定义,然后选安装路径(英文路径) 3-安装选项一个就够了,如图 4-点击下一步,之后如下图 5-点击安装 启动,如图则恭喜你成功安装...
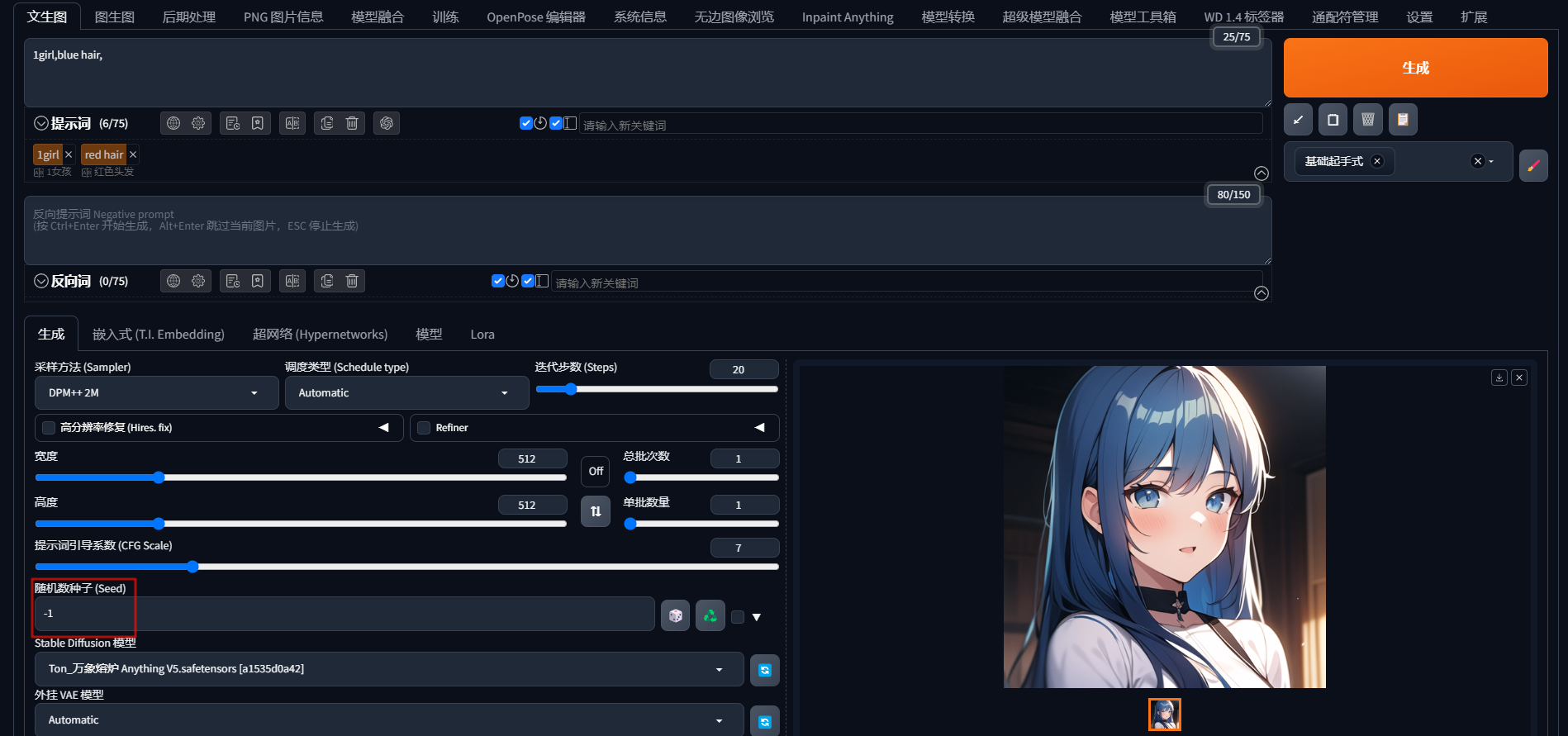
Stable Diffusion绘画 | 文生图设置详解—随机种子数(Seed)
随机种子数(Seed) Midjourney 也有同样的概念,通过 --seed 种子数值 来使用。 每次操作「生成」所得到的图片,都会随机分配一个 seed值,数值不同,生成的画面就会不同。 默认值为 -1:每次随机分…...

56、php实现N的阶乘末尾有多个0
题目: php实现N的阶乘末尾有多个0 描述: 阶乘 N! 123*…N; 比如 5! 12345 120 末端有1个0 解题思路: N! K*(10^M) N的阶乘为K和10的M次方的乘积,那么N!末尾就有M个0。如果将N的阶乘分解后,那么N的阶乘可以分解为&…...
混合域注意力机制(空间+通道)
在计算机视觉任务中,空间域注意力通常关注图像中不同位置的重要性,例如突出图像中的关键对象或区域。而通道域注意力则侧重于不同通道(特征图)的重要性,决定哪些特征对于任务更具判别力。混合域注意力机制结合了空间域…...

springboot长春旅游安全地图平台-计算机毕业设计源码90075
摘 要 本文详细阐述了基于微信小程序前端和Spring Boot后端框架的长春旅游安全地图平台的设计思路与实现过程。该平台旨在为长春游客提供安全、便捷的旅游服务,同时为旅游管理部门提供高效的信息管理和应急响应机制。 在平台设计上,我们充分考虑了用户体…...

apex正则表达式匹配富文本字段内容,如何只匹配文本而忽略富文本符号
在Apex中处理富文本字段时,如果你只想匹配其中的纯文本而忽略富文本符号,可以使用正则表达式来去除HTML标签,然后再进行文本匹配。以下是一个示例代码,展示了如何实现这一点: public class RichTextHandler {// Funct…...
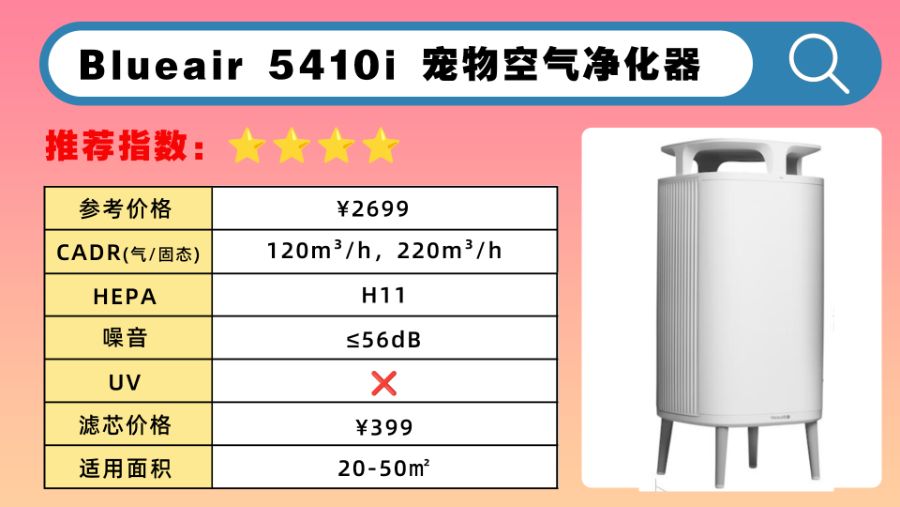
空气净化器对去除宠物毛有效吗?小型猫毛空气净化器使用感受
作为一个养猫多年的猫奴,家里有两只可爱的小猫咪:小白和小花。虽然相处起来很开心,但也给生活带来了一些小麻烦。谁懂啊,我真的受够了,每天都在粘毛。猫窝的猫毛一周不清理就要堆成山,空气中也全是浮毛&…...

vue的nextTick是下一次事件循环吗
如题,nextTick的回调是在下一次事件循环被执行的吗? 是不是下一次事件循环取决于nextTick的实现,如果是用的微任务,那么就是本次事件循环;否则如果用的是宏任务,那么就是下一次事件循环。 我们看下Vue3中…...

5.4.软件工程-系统设计
考试占比不高 概述 系统设计的主要目的就是为系统制定蓝图,在各种技术和实施方法中权衡利弊,精心设计,合理地使用各种资源,最终勾画出新系统的详细设计方案。系统设计的主要内容包括新系统总体结构设计、代码设计、输出设计、输…...

Apache Kylin与BI工具集成:数据可视化实战
Apache Kylin与BI工具集成:数据可视化实战 1. 引言 Apache Kylin是一个开源的分布式分析引擎,专注于大数据的OLAP(在线分析处理)。它可以快速地对大量数据进行多维分析,并支持与多种BI(商业智能ÿ…...
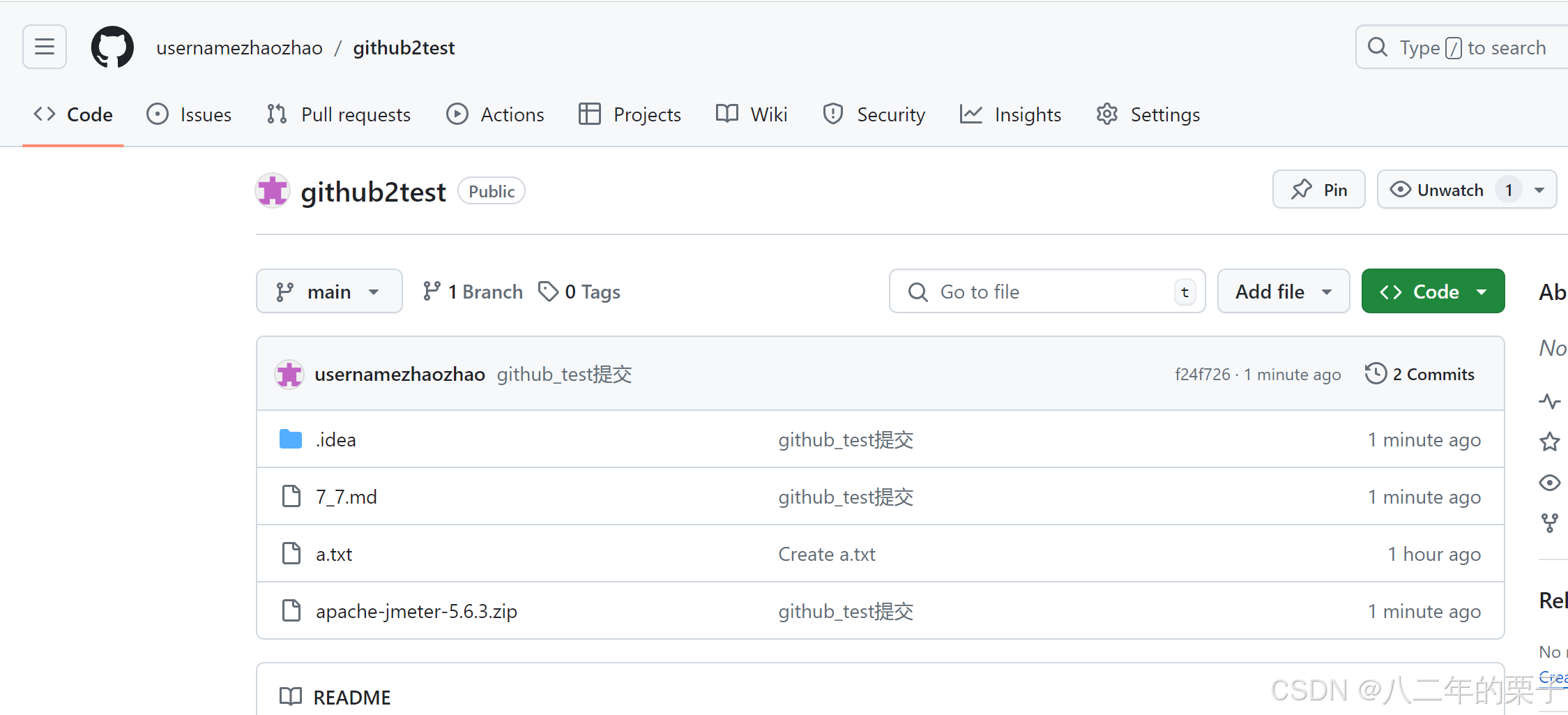
通过idea图形化界面就能push到github流程
建好自己要提交的项目 建好github想提交的地址 git initgit remote add origin https://github.com/usernamezhaozhao/github2test/tree/maingit branch maingit checkout main创建一个文件,我起了一个a.txt git pull origin main 好了,可以idea打开了 …...

C语言初阶(10)
1.野指针 野指针就是指向未知空间的指针,有以下几种情况 (1)指针未初始化 int main() {int a0;int*b;return 0; } 上面指针就是没有初始化,形成一种指向一个随机空间的地址的指针,我们可以修改成 int main() {int a0;int*bNU…...
Javaweb用过滤器写防跳墙功能和退出登录
一、什么是防跳墙功能: 防跳墙功能通常指的是防止用户在未完成认证的情况下直接访问受保护资源的功能。在 Web 开发中,这种功能通常被称为“登录拦截”或“身份验证拦截”。 在 Spring MVC 中,实现这种功能通常使用的是“拦截器”(…...

小试牛刀-Telebot区块链游戏机器人(TS升级)
目录 1.编写目的 2.为什么使用TypeScript实现? 3.实现功能 3.1 AI图片生成 3.2 签到 3.3 邀请 3.4 WalletConnect连接 4.功能实现详解 4.1 AI图片生成 4.2 签到 4.3 邀请 4.4 WalletConnect连接 5.功能截图 6.问题整理 Welcome to Code Blocks blog 本篇文章主…...

MySQL:Prepared Statement 预处理语句
预处理语句(Prepared Statement) 是一种在数据库管理系统中使用的编程概念,用于执行对数据库进行操作的 SQL 语句。 使用预处理语句的具体方式和语法依赖于所用的编程语言和数据库管理系统。常见的编程语言如 Java、PHP、Python 和 C# 都提供…...

Java:Thread类以及线程状态
文章目录 Thread类等待一个线程 - join()获取当前线程的引用sleep 线程状态 Thread类 等待一个线程 - join() 操作系统,针对多个线程的执行,是一个"随机调度,抢占式执行“的过程. 线程等待就是在确定两个线程的"结束顺序”. 我们无法确定两个线程调度执行的顺序,但…...
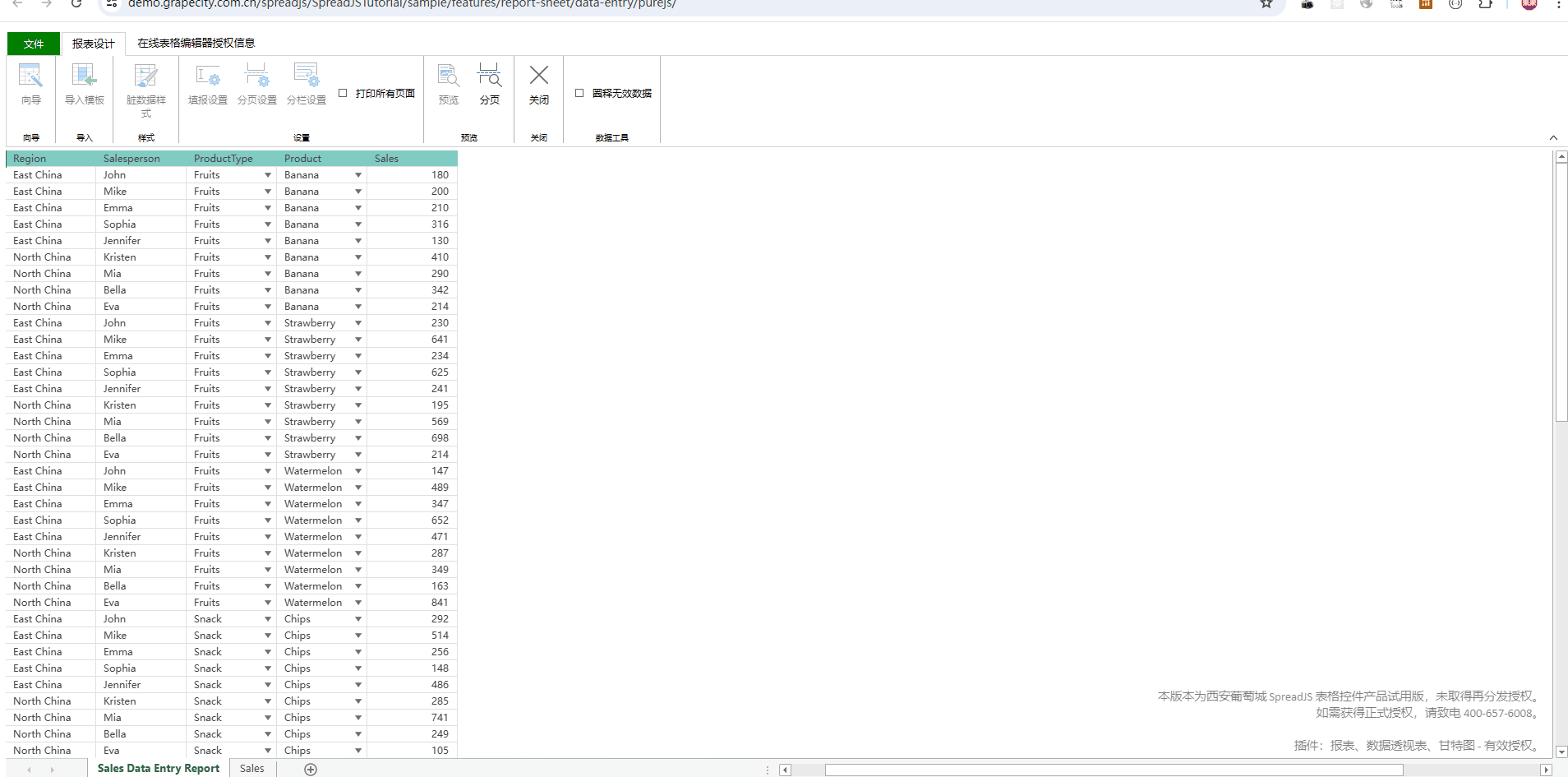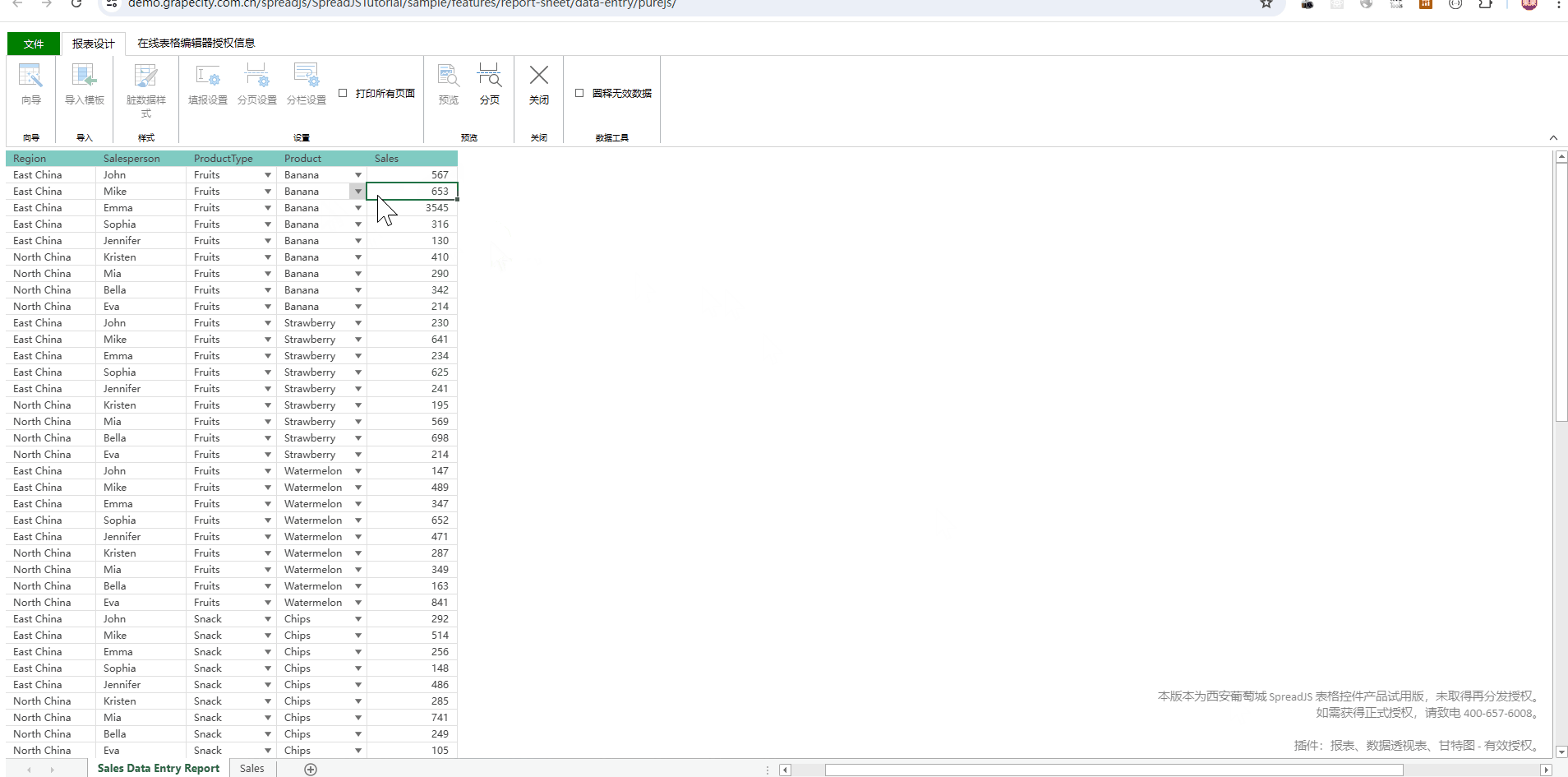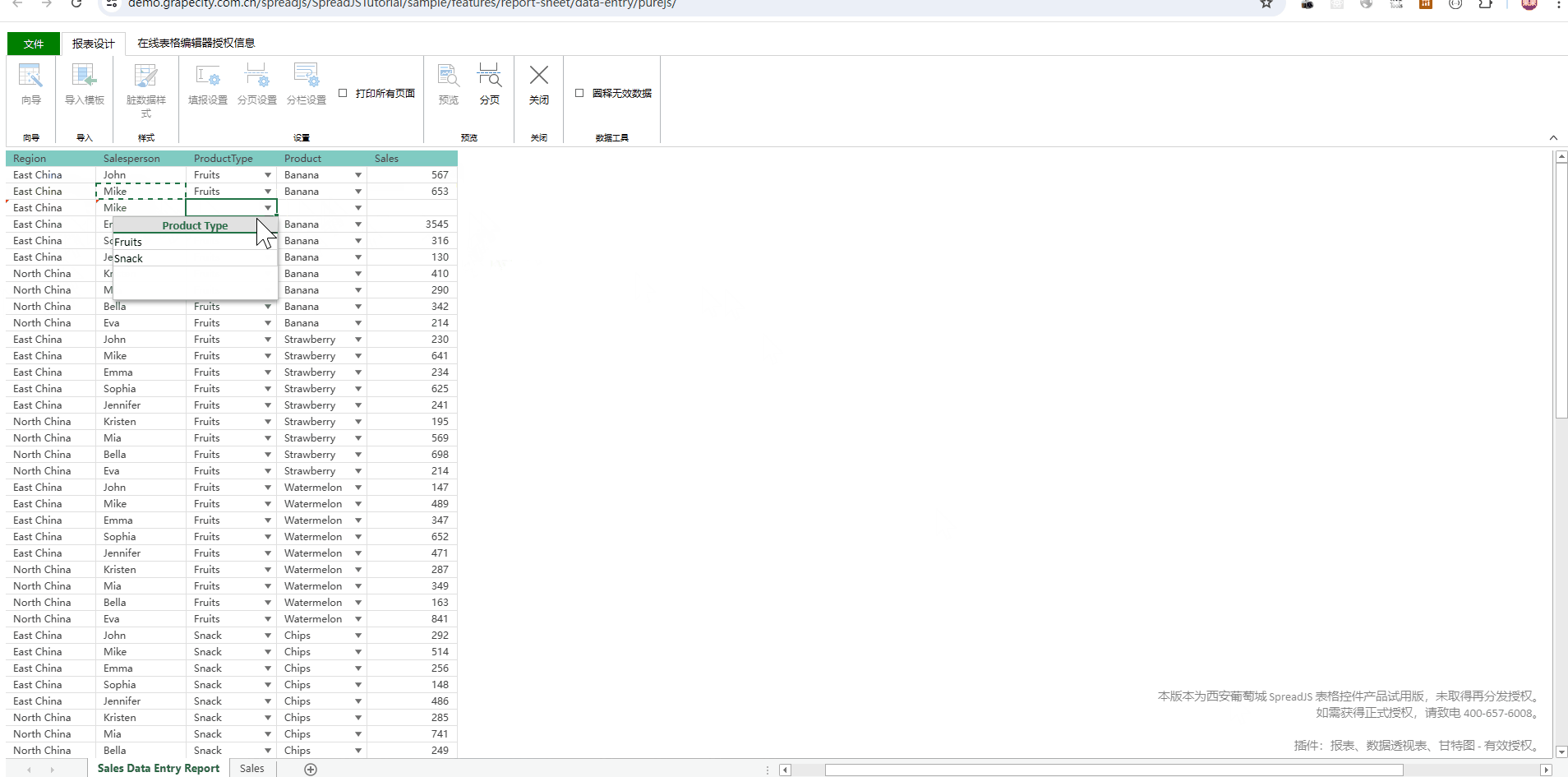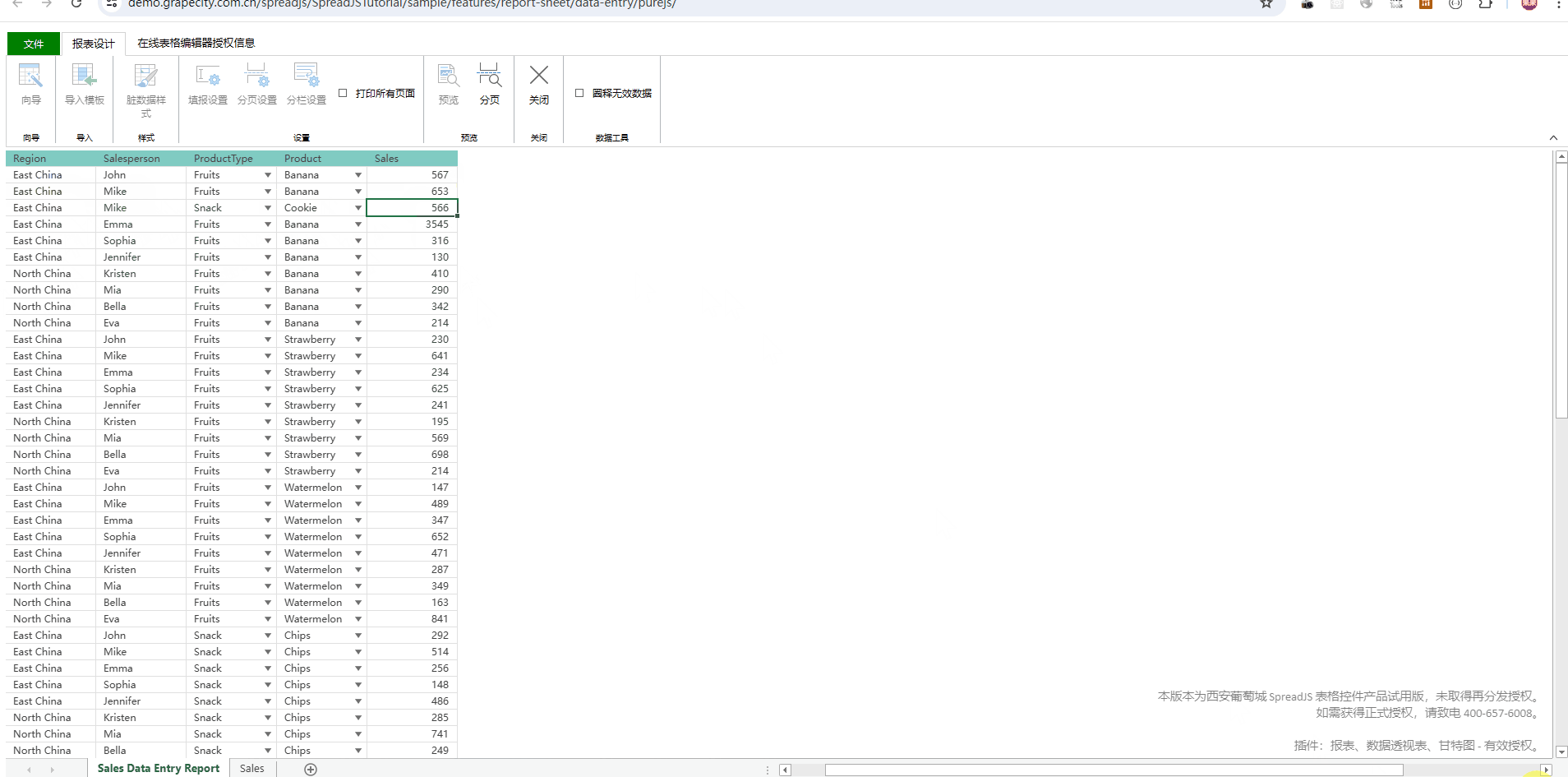
如何通过前端表格控件实现自动化报表?
背景 最近伙伴客户的项目经理遇见一个问题,他们在给甲方做自动化报表工具,项目已经基本做好了,但拿给最终甲方,业务人员不太买账,项目经理为此也是天天抓狂,没有想到合适的应对方案。 现阶段主要面临的问…...

SCAU期末笔记 - 数据分析与数据挖掘题库解析
这门怎么题库答案不全啊日 来简单学一下子来 一、选择题(可多选) 将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?(C) A. 频繁模式挖掘 B.分类和预测 C.数据预处理 D.数据流挖掘 A. 频繁模式挖掘:专注于发现数据中…...

vscode(仍待补充)
写于2025 6.9 主包将加入vscode这个更权威的圈子 vscode的基本使用 侧边栏 vscode还能连接ssh? debug时使用的launch文件 1.task.json {"tasks": [{"type": "cppbuild","label": "C/C: gcc.exe 生成活动文件"…...

聊聊 Pulsar:Producer 源码解析
一、前言 Apache Pulsar 是一个企业级的开源分布式消息传递平台,以其高性能、可扩展性和存储计算分离架构在消息队列和流处理领域独树一帜。在 Pulsar 的核心架构中,Producer(生产者) 是连接客户端应用与消息队列的第一步。生产者…...

Spring AI 入门:Java 开发者的生成式 AI 实践之路
一、Spring AI 简介 在人工智能技术快速迭代的今天,Spring AI 作为 Spring 生态系统的新生力量,正在成为 Java 开发者拥抱生成式 AI 的最佳选择。该框架通过模块化设计实现了与主流 AI 服务(如 OpenAI、Anthropic)的无缝对接&…...

Maven 概述、安装、配置、仓库、私服详解
目录 1、Maven 概述 1.1 Maven 的定义 1.2 Maven 解决的问题 1.3 Maven 的核心特性与优势 2、Maven 安装 2.1 下载 Maven 2.2 安装配置 Maven 2.3 测试安装 2.4 修改 Maven 本地仓库的默认路径 3、Maven 配置 3.1 配置本地仓库 3.2 配置 JDK 3.3 IDEA 配置本地 Ma…...

有限自动机到正规文法转换器v1.0
1 项目简介 这是一个功能强大的有限自动机(Finite Automaton, FA)到正规文法(Regular Grammar)转换器,它配备了一个直观且完整的图形用户界面,使用户能够轻松地进行操作和观察。该程序基于编译原理中的经典…...

【Redis】笔记|第8节|大厂高并发缓存架构实战与优化
缓存架构 代码结构 代码详情 功能点: 多级缓存,先查本地缓存,再查Redis,最后才查数据库热点数据重建逻辑使用分布式锁,二次查询更新缓存采用读写锁提升性能采用Redis的发布订阅机制通知所有实例更新本地缓存适用读多…...

毫米波雷达基础理论(3D+4D)
3D、4D毫米波雷达基础知识及厂商选型 PreView : https://mp.weixin.qq.com/s/bQkju4r6med7I3TBGJI_bQ 1. FMCW毫米波雷达基础知识 主要参考博文: 一文入门汽车毫米波雷达基本原理 :https://mp.weixin.qq.com/s/_EN7A5lKcz2Eh8dLnjE19w 毫米波雷达基础…...

解析奥地利 XARION激光超声检测系统:无膜光学麦克风 + 无耦合剂的技术协同优势及多元应用
在工业制造领域,无损检测(NDT)的精度与效率直接影响产品质量与生产安全。奥地利 XARION开发的激光超声精密检测系统,以非接触式光学麦克风技术为核心,打破传统检测瓶颈,为半导体、航空航天、汽车制造等行业提供了高灵敏…...

在 Spring Boot 项目里,MYSQL中json类型字段使用
前言: 因为程序特殊需求导致,需要mysql数据库存储json类型数据,因此记录一下使用流程 1.java实体中新增字段 private List<User> users 2.增加mybatis-plus注解 TableField(typeHandler FastjsonTypeHandler.class) private Lis…...