书生大模型实战营闯关记录----第五关:LlamaIndex+Internlm2 RAG实践Demo:效果对比,文档加载,向量库构建,检索器,模型推理
文章目录
- 1. 前置知识
- RAG背景
- RAG 效果比对
- 2. 环境、模型准备
- 2.1 配置基础环境
- 2.2 安装 Python环境和依赖包
- 2.3 下载 Sentence Transformer 模型
- 2.4 下载 NLTK 相关资源
- 3. LlamaIndex HuggingFaceLLM
- 4. LlamaIndex RAG
- 加载文档
- 构建向量存储索引库
- 检索器
- RAG代码
- 5. LlamaIndex web
本文将分为以下几个部分来介绍,如何使用 LlamaIndex 来部署 InternLM2 1.8B并实现RAG功能。
- 前置知识
- 环境、模型准备
- LlamaIndex HuggingFaceLLM
- LlamaIndex RAG
1. 前置知识
RAG背景
给模型注入新知识的方式,可以简单分为两种方式,一种是内部的,即更新模型的权重,另一个就是外部的方式,给模型注入格外的上下文或者说外部信息,不改变它的的权重。
第一种方式,改变了模型的权重即进行模型训练,这是一件代价比较大的事情,大语言模型具体的训练过程,可以参考InternLM2技术报告。第二种方式,并不改变模型的权重,只是给模型引入额外的信息。


对比两种注入知识方式,第二种更容易实现。RAG正是这种方式。它能够让基础模型实现非参数知识更新,无需训练就可以掌握新领域的知识。本次课程选用了LlamaIndex框架。LlamaIndex 是一个上下文增强的 LLM 框架,旨在通过将其与特定上下文数据集集成,增强大型语言模型(LLMs)的能力。它允许您构建应用程序,既利用 LLMs 的优势,又融入您的私有或领域特定信息。
在RAG中有五个关键阶段,这些阶段将成为你构建的任何更大应用程序的一部分。这些阶段包括:
-
加载:这指的是从数据源(无论是文本文件、PDF、另一个网站、数据库或API)获取你的数据并将其放入你的流水线中。LlamaHub 提供了数百个可供选择的连接器。
-
索引:这意味着创建一个允许查询数据的数据结构。对于LLM来说,这几乎总是意味着创建向量嵌入,即你的数据含义的数值表示,以及许多其他元数据策略,使其易于准确找到上下文相关的数据。
-
存储:一旦你的数据被索引,你几乎总是希望存储你的索引,以及其他元数据,以避免重新对其进行索引。
-
查询:对于任何给定的索引策略,你可以利用LLM和LlamaIndex数据结构进行查询的许多方式,包括子查询、多步查询和混合策略。
-
评估:在任何流水线中的一个关键步骤是检查它相对于其他策略的有效性,或者当你进行更改时。评估提供了关于你对查询的响应有多准确、忠实和快速的客观度量。
RAG 效果比对
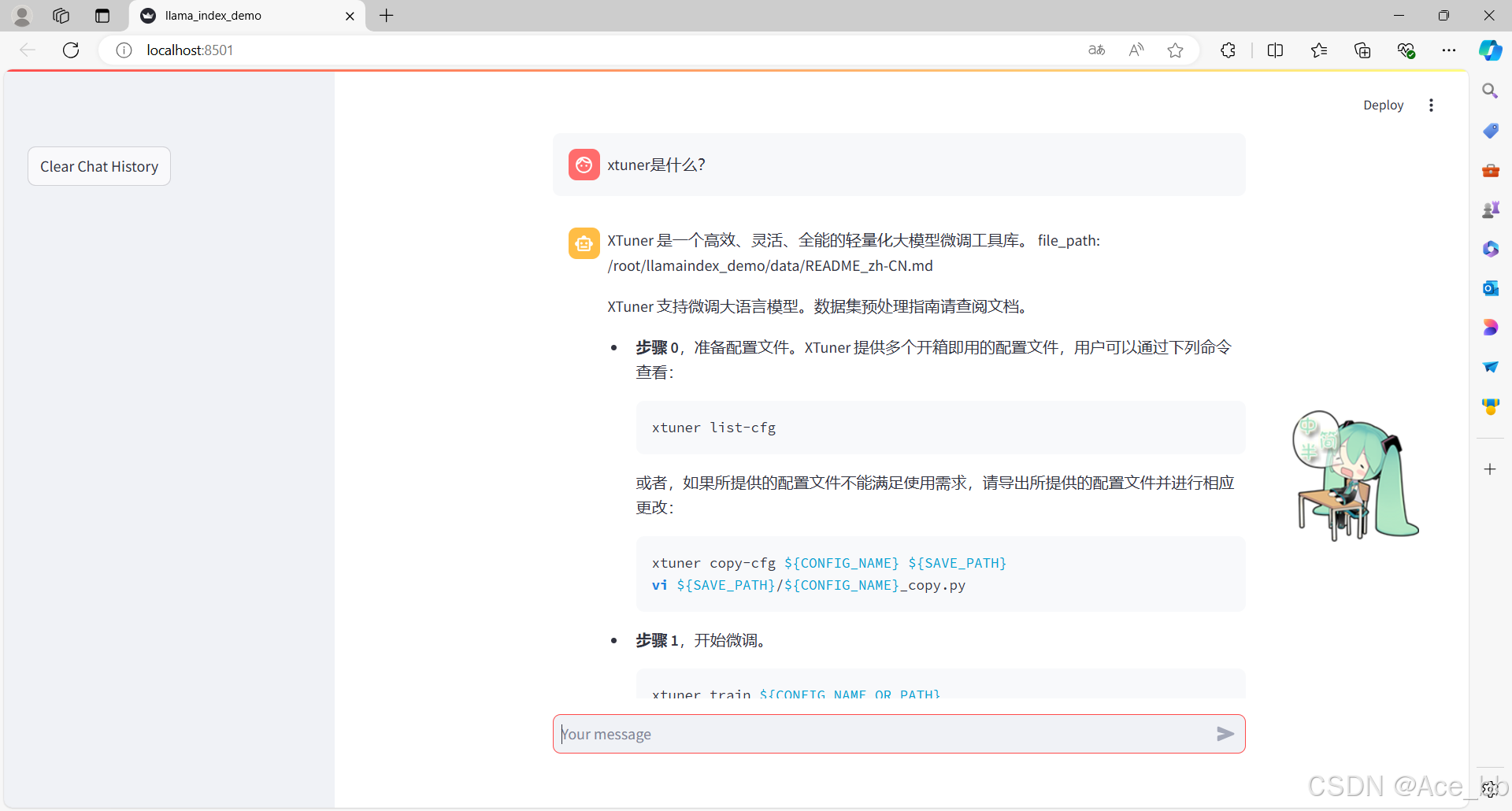
如图所示,由于xtuner是一款比较新的框架, InternLM2-Chat-1.8B 训练数据库中并没有收录到它的相关信息。左图中问答均未给出准确的答案。右图未对 InternLM2-Chat-1.8B 进行任何增训的情况下,通过 RAG 技术实现的新增知识问答。

2. 环境、模型准备
2.1 配置基础环境
这里以在 Intern Studio 服务器上部署LlamaIndex为例。
进入开发机后,创建新的conda环境,命名为 llamaindex,在命令行模式下运行:
conda create -n llamaindex python=3.10
复制完成后,在本地查看环境。
conda env list
结果如下所示。
# conda environments:
#
base * /root/.conda
llamaindex /root/.conda/envs/llamaindex
运行 conda 命令,激活 llamaindex 然后安装相关基础依赖
python 虚拟环境:
conda activate llamaindex
conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.7 -c pytorch -c nvidia
安装python 依赖包
pip install einops
pip install protobuf
环境激活。
2.2 安装 Python环境和依赖包
安装Python3.10版本的Anaconda虚拟环境和相关的包
conda create -n llamaindex python=3.10
conda activate llamaindex
conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.7 -c pytorch -c nvidia
pip install einops
pip install protobuf
pip install llama-index==0.10.38 llama-index-llms-huggingface==0.2.0 "transformers[torch]==4.41.1" "huggingface_hub[inference]==0.23.1" huggingface_hub==0.23.1 sentence-transformers==2.7.0 sentencepiece==0.2.0
2.3 下载 Sentence Transformer 模型
源词向量模型 Sentence Transformer:(我们也可以选用别的开源词向量模型来进行 Embedding,目前选用这个模型是相对轻量、支持中文且效果较好的,同学们可以自由尝试别的开源词向量模型)
运行以下指令,新建一个python文件,贴入以下代码
然后,执行该脚本即可自动开始下载:
cd /root/llamaindex_demo
conda activate llamaindex
python download_hf.py
更多关于镜像使用可以移步至 HF Mirror 查看。
2.4 下载 NLTK 相关资源
我们在使用开源词向量模型构建开源词向量的时候,需要用到第三方库 nltk 的一些资源。正常情况下,其会自动从互联网上下载,但可能由于网络原因会导致下载中断,此处我们可以从国内仓库镜像地址下载相关资源,保存到服务器上。
我们用以下命令下载 nltk 资源并解压到服务器上:
cd /root
git clone https://gitee.com/yzy0612/nltk_data.git --branch gh-pages
cd nltk_data
mv packages/* ./
cd tokenizers
unzip punkt.zip
cd ../taggers
unzip averaged_perceptron_tagger.zip
之后使用时服务器即会自动使用已有资源,无需再次下载
3. LlamaIndex HuggingFaceLLM
运行以下指令,把 InternLM2 1.8B 软连接出来
cd ~/model
ln -s /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b/ ./
运行以下指令,新建一个python文件
cd ~/llamaindex_demo
touch llamaindex_internlm.py
打开llamaindex_internlm.py 贴入以下代码
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.core.llms import ChatMessage
llm = HuggingFaceLLM(model_name="/root/model/internlm2-chat-1_8b",tokenizer_name="/root/model/internlm2-chat-1_8b",model_kwargs={"trust_remote_code":True},tokenizer_kwargs={"trust_remote_code":True}
)rsp = llm.chat(messages=[ChatMessage(content="什么是丛集性头痛?")])
print(rsp)
运行结果为:

回答的效果并不好,并不是我们想要的xtuner。
4. LlamaIndex RAG
安装 LlamaIndex 词嵌入向量依赖
conda activate llamaindex
pip install llama-index-embeddings-huggingface llama-index-embeddings-instructor
加载文档
LlamaIndex提供了两种方式创建文档,文档可以通过数据加载器自动创建,也可以手动构建。
默认情况下,我们所有的数据加载器(包括 LlamaHub 上提供的)都通过 load_data 函数返回 Document 对象。
详细使用方法建议看官方文档:http://www.aidoczh.com/llamaindex/module_guides/loading/documents_and_nodes/usage_documents/
from llama_index.core import SimpleDirectoryReaderdocuments = SimpleDirectoryReader("./data").load_data()
您也可以选择手动构建文档。LlamaIndex 提供了 Document 结构。
from llama_index.core import Documenttext_list = [text1, text2, ...]
documents = [Document(text=t) for t in text_list]
数据加载器由LlamaHub提供,支持pdf, docs, pptx, epub等格式的数据。数据连接器使用指南建议看官方文档:
http://www.aidoczh.com/llamaindex/module_guides/loading/connector/。
部分如下:

这里使用的了丁香医生网站丛集性头痛内容作为知识库,原链接为:丛集性头痛
导出为markdown文件。然后在项目目录下创建data目录,将md文件存入data目录中。通过配置,LlamaIndex会自动加载这个目录中的文件存入知识库中。
mkdir data
cd data
构建向量存储索引库
建议阅读LlamaIndex官方文档介绍:http://www.aidoczh.com/llamaindex/module_guides/indexing/vector_store_index/
要构建向量索引库,首先需要完成第一步的加载文档。向量库可以接收SimpleDirectoryReader().load_data()返回的documents对象,构建成vector store,并提供相似度查询的接口。
使用 Vector Store 的最简单方法是使用 from_documents 加载一组文档并从中构建索引:
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader# 加载文档并构建索引
documents = SimpleDirectoryReader("../../examples/data/paul_graham"
).load_data()
index = VectorStoreIndex.from_documents(documents)
VectorStoreIndex构建向量库时会自动对文档进行分片。
检索器
检索器定义了如何在给定查询时有效地从索引中检索相关上下文。检索策略对于检索到的数据的相关性和效率至关重要。检索器主要建立在向量库索引之上,被用作查询引擎,用于从向量库中检索出相关的上下文。
最简单的方式是使用向量索引库提供的默认检索器,也就是直接进行相似度检索。
retriever = index.as_retriever()
nodes = retriever.retrieve("Who is Paul Graham?")
使用检索器检索到与用户query相关的结果之后,便可以将检索结果交给LLM来进行回答。
RAG代码
完整的RAG代码如下,包含了模型加载,文档加载,向量索引库构建,检索器构建和模型输出。
运行以下指令,新建一个python文件,打开llamaindex_RAG.py贴入以下代码
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settingsfrom llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.huggingface import HuggingFaceLLM#初始化一个HuggingFaceEmbedding对象,用于将文本转换为向量表示
embed_model = HuggingFaceEmbedding(
#指定了一个预训练的sentence-transformer模型的路径model_name="/root/model/sentence-transformer"
)
#将创建的嵌入模型赋值给全局设置的embed_model属性,
#这样在后续的索引构建过程中就会使用这个模型。
Settings.embed_model = embed_modelllm = HuggingFaceLLM(model_name="/root/model/internlm2-chat-1_8b",tokenizer_name="/root/model/internlm2-chat-1_8b",model_kwargs={"trust_remote_code":True},tokenizer_kwargs={"trust_remote_code":True}
)
#设置全局的llm属性,这样在索引查询时会使用这个模型。
Settings.llm = llm#从指定目录读取所有文档,并加载数据到内存中
documents = SimpleDirectoryReader("/root/Demo/LlamaIndex/data").load_data()
#创建一个VectorStoreIndex,并使用之前加载的文档来构建索引。
# 此索引将文档转换为向量,并存储这些向量以便于快速检索。
index = VectorStoreIndex.from_documents(documents)
# 创建一个查询引擎,这个引擎可以接收查询并返回相关文档的响应。
query_engine = index.as_query_engine()
response = query_engine.query("什么是丛集性头痛?")print(response)
运行结果为:

借助RAG技术后,就能获得我们想要的答案了。可以看到回答得比没有加RAG要好很多。
5. LlamaIndex web
运行之前首先安装依赖
pip install streamlit==1.36.0
运行以下指令,新建一个python文件
cd ~/llamaindex_demo
touch app.py
打开app.py贴入以下代码
import streamlit as st
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.huggingface import HuggingFaceLLMst.set_page_config(page_title="llama_index_demo", page_icon="🦜🔗")
st.title("llama_index_demo")# 初始化模型
@st.cache_resource
def init_models():embed_model = HuggingFaceEmbedding(model_name="/root/model/sentence-transformer")Settings.embed_model = embed_modelllm = HuggingFaceLLM(model_name="/root/model/internlm2-chat-1_8b",tokenizer_name="/root/model/internlm2-chat-1_8b",model_kwargs={"trust_remote_code": True},tokenizer_kwargs={"trust_remote_code": True})Settings.llm = llmdocuments = SimpleDirectoryReader("/root/llamaindex_demo/data").load_data()index = VectorStoreIndex.from_documents(documents)query_engine = index.as_query_engine()return query_engine# 检查是否需要初始化模型
if 'query_engine' not in st.session_state:st.session_state['query_engine'] = init_models()def greet2(question):response = st.session_state['query_engine'].query(question)return response# Store LLM generated responses
if "messages" not in st.session_state.keys():st.session_state.messages = [{"role": "assistant", "content": "你好,我是你的助手,有什么我可以帮助你的吗?"}] # Display or clear chat messages
for message in st.session_state.messages:with st.chat_message(message["role"]):st.write(message["content"])def clear_chat_history():st.session_state.messages = [{"role": "assistant", "content": "你好,我是你的助手,有什么我可以帮助你的吗?"}]st.sidebar.button('Clear Chat History', on_click=clear_chat_history)# Function for generating LLaMA2 response
def generate_llama_index_response(prompt_input):return greet2(prompt_input)# User-provided prompt
if prompt := st.chat_input():st.session_state.messages.append({"role": "user", "content": prompt})with st.chat_message("user"):st.write(prompt)# Gegenerate_llama_index_response last message is not from assistant
if st.session_state.messages[-1]["role"] != "assistant":with st.chat_message("assistant"):with st.spinner("Thinking..."):response = generate_llama_index_response(prompt)placeholder = st.empty()placeholder.markdown(response)message = {"role": "assistant", "content": response}st.session_state.messages.append(message)
之后运行
streamlit run app.py
然后在命令行点击,红框里的url。
即可进入以下网页,然后就可以开始尝试问问题了。
询问结果为:
相关文章:
书生大模型实战营闯关记录----第五关:LlamaIndex+Internlm2 RAG实践Demo:效果对比,文档加载,向量库构建,检索器,模型推理
文章目录 1. 前置知识RAG背景RAG 效果比对 2. 环境、模型准备2.1 配置基础环境2.2 安装 Python环境和依赖包2.3 下载 Sentence Transformer 模型2.4 下载 NLTK 相关资源 3. LlamaIndex HuggingFaceLLM4. LlamaIndex RAG加载文档构建向量存储索引库检索器RAG代码 5. LlamaIndex …...
如何使用极狐GitLab CI/CD Component Catalog?【上】
极狐GitLab 是 GitLab 在中国的发行版,专门面向中国程序员和企业提供企业级一体化 DevOps 平台,用来帮助用户实现需求管理、源代码托管、CI/CD、安全合规,而且所有的操作都是在一个平台上进行,省事省心省钱。可以一键安装极狐GitL…...
详解Xilinx FPGA高速串行收发器GTX/GTP(3)--GTX的时钟架构
目录 1、参考时钟 2、时钟方案 2.1、单个外部参考时钟驱动单个QUAD中的多个transceiver 2.2、单个外部参考时钟驱动多个QUAD中的多个transceiver 2.3、同一个Quad中,多个GTX Transceiver使用多个参考时钟 2.4、不同Quad中,多个GTX Transceiver 使用多个参考时钟 3、QP…...
简单搭建dns服务器
目录 一.安装服务 二.编写子配置文件 三.编写主配置文件 四.编写文件 五.重启服务测试 配置端:IP地址为172.25.254.100、主机名为node1.rhel9.org 测试端:IP地址为172.25.254.101、主机名为node2.rhel9.org 一.安装服务 [rootnode1 ~]# dnf inst…...
)
大数据进阶(Advanced Big Data)
大数据进阶(Advanced Big Data) 目录 引言大数据架构 Lambda架构Kappa架构 大数据技术栈 数据采集与预处理数据存储与管理数据处理与分析数据可视化与展示 大数据分析方法 机器学习深度学习自然语言处理图数据分析 大数据在工业中的应用 制造业能源管理…...

微信小程序开发优惠券制作源码
微信小程序开发优惠券制作源码。制作一个自带流量的小程序商城,功能强大玩法新,轻松实现引流,推广,卖货,分销,会员管理,直播等多种功能需求需要哪些编辑代码源码呢?http://m.bokequ.com/list/124-2.html 代码分享 <!DOCTYPE HTML> <html xmlns"http://www.w3.o…...

mongodb的安装操作记录
mongodb的安装操作记录 1 上传软件包,并解压 [rootmonitor local]# tar -xvf mongodb-linux-x86_64-rhel70-7.0.12.tgz mongodb-linux-x86_64-rhel70-7.0.12/LICENSE-Community.txt mongodb-linux-x86_64-rhel70-7.0.12/MPL-2 mongodb-linux-x86_64-rhel70-7.0.1…...

C++客户端Qt开发——多线程编程(二)
多线程编程(二) ③线程池 Qt中线程池的使用 | 爱编程的大丙 1>线程池 我们使用线程的时候就去创建一个线程,这样实现起来非常简便,但是就会有一个问题:如果并发的线程数量很多,并且每个线程都是执行…...

ubuntu20复现NBV探索
官网代码 后退地平线下一个最佳景观规划师 这个代码有些久远,issue里面有人已经在ubuntu20里面使用了3dmr,但是他那个代码我也运行不成功,docker网络一直也不佳,所以还是自己重新修改源码靠谱。 最终实现的代码等有时间上传到gi…...
【51单片机仿真】基于51单片机设计的温湿度采集检测系统仿真源码文档视频——文末资料下载
演示 目录 1.系统功能 2.背景介绍 3.硬件电路设计 4.软件设计 4.1 主程序设计 4.2 温湿度采集模块程序设计 4.3 LCD显示屏程序设计 5.系统测试 6.结束语 源码、仿真、文档视频等资料下载链接 1.系统功能 该系统通过与AT89C51单片机、LCD1602显示屏和DHT11温湿度传感器…...

【Hadoop-驯化】一文学会hadoop访问hdfs中常用命令使用技巧
【Hadoop-驯化】一文学会hadoop访问hdfs中常用命令使用技巧 本次修炼方法请往下查看 🌈 欢迎莅临我的个人主页 👈这里是我工作、学习、实践 IT领域、真诚分享 踩坑集合,智慧小天地! 🎇 免费获取相关内容文档关注&am…...

【Spring】Bean详细解析
1.Spring Bean的生命周期 整体上可以简单分为四步:实例化 —> 属性赋值 —> 初始化 —> 销毁。初始化这一步涉及到的步骤比较多,包含 Aware 接口的依赖注入、BeanPostProcessor 在初始化前后的处理以及 InitializingBean 和 init-method 的初始…...

决策树总结
决策树总结 决策树是一种广泛应用的机器学习算法,它模拟了人类进行决策时的逻辑思维过程,通过构建一棵树状结构来进行数据的分类或回归预测。决策树模型因其直观易懂、易于解释、能够处理多类问题以及无需进行复杂的特征缩放等优点,在数据挖…...

通俗易懂!495页看漫画学Python入门教程(全彩版)Git首发破万Star
前言 在编程的世界里,Python无疑是一颗璀璨的明星。从最初作为打发圣诞节闲暇时间的项目,到如今成为最受欢迎的程序设计语言之一,Python以其简洁、易学、强大的特点吸引了无数编程爱好者。然而,对于初学者来说,编程的…...

websocket实现简易聊天室
websocket实现简易聊天室 又做了一个关于websocket广播和在线人数统计的练习,实现一个简易的聊天室。 前端vue3 前端里的内容主要包含: 1.css的animation来实现公告从右到左的轮播。 2.websocket的onmessage里对不同消息的处理。 <template>&l…...
vulhub-wordpress
1.打开wordpress关卡,选择简体中文 添加信息——点击安装WordPress 安装完成——登录 点击外观——编辑主题 可以加入一句话木马,但是我写入的是探针文件 也可以去上传一个带有木马的主题 上传之后会自动解压 1.php就是里面的木马文件...

【机器学习算法基础】(基础机器学习课程)-10-逻辑回归-笔记
一、模型的保存与加载 逻辑回归是一种常见的机器学习算法,广泛用于分类问题。为了在不同的时间或环境下使用训练好的模型,我们通常需要将其保存和加载。 保存模型 训练模型:首先,你需要用你的数据训练一个逻辑回归模型。例如&…...

自动驾驶行业知识汇总
应届生月薪2W的自动驾驶开发、机器人、后端开发,软件开发该如何学习相关技术栈_哔哩哔哩_bilibili 两万字详解自动驾驶开发工具链的现状与趋势 (qq.com) 九章智驾 - 2023年度文章大合集 (qq.com) 九章 - 2022年度文章大合集 (qq.com)...

C#根据反射操作对象
前言 反射使用,让我们的程序可以动态增加一些功能,让原本固化的步骤逻辑变得动态,这是它的优点。当然使用反射首次加载会有性能损耗以及使用复杂;但是现在大家都在讲动态,使用好它应该是一个重要的编程理念提升。MVC、…...
为exe文件)
打包python脚本(flask、jinja2)为exe文件
20240803 概述 在我很早时候学习python的时候,就利用过某个工具将其打包为exe文件,然后在没有python环境的机器上运行,这样可以减少安装python环境和各种库的过程。 最近在开发一个在虚拟机上运行的程序的时候就遇到了打包一些环境的问题&…...

OpenClaw深度配置:Qwen3.5-9B模型参数调优指南
OpenClaw深度配置:Qwen3.5-9B模型参数调优指南 1. 为什么需要关注模型参数调优? 第一次用OpenClaw对接Qwen3.5-9B模型时,我遇到了一个奇怪现象:同样的"整理桌面截图并分类归档"任务,白天执行成功率能达到8…...

基于主从博弈的主动配电网阻塞管理探索
基于主从博弈的主动配电网阻塞管理 首先,在日前市场中,LA(负荷聚合商)根据历史数据预测次日向上级电网购电的电价信息和预测分布式电源(燃气轮机)出力、风电场出力信息,同时考虑事前与用户签订协议的可中断负荷&#x…...

3D元器件库技术解析与工程应用指南
## 1. 3D元器件库技术解析与应用指南### 1.1 3D封装库的技术价值 在现代电子设计自动化(EDA)流程中,高质量的3D元器件库可显著提升设计效率。本套封装库包含1088个标准封装模型,涵盖电阻器、电容器、接线端子、IC芯片、晶振等常见电子元件,所…...

深入理解incubator-pagespeed-ngx配置:50个实用参数详解与最佳实践
深入理解incubator-pagespeed-ngx配置:50个实用参数详解与最佳实践 Apache incubator-pagespeed-ngx是一个强大的Nginx性能优化模块,能够自动优化网站资源,显著提升页面加载速度。无论你是网站管理员还是开发人员,掌握其配置参数…...

Docker镜像的制作
什么是Docker镜像? Docker镜像是一个轻量级、独立的可执行软件包,包含运行应用程序所需的一切:代码、运行时、系统工具、系统库和设置。镜像是容器的基础,容器是镜像的运行实例。 准备工作 安装Docker 首先确保你的系统已安装D…...

【linux】Xorg与X Window System的交互机制解析
1. X Window System与Xorg的关系 当你打开Linux电脑看到图形界面时,背后默默工作的就是X Window System。这个诞生于1984年的图形系统至今仍是Linux桌面环境的基石,而Xorg则是它的现代实现版本。简单来说,X Window System定义了图形显示的标准…...

isac毕设选题效率提升实战:从任务调度到自动化部署的全流程优化
最近在忙 ISAC 相关的毕业设计选题,和不少同学交流后发现,大家的时间很大一部分都耗在了“重复劳动”上:环境配半天跑不起来,代码改一点就要手动重启服务测试,版本一多自己都忘了哪个是能用的。这哪是做毕设࿰…...

塔罗牌选框架:准确率超机器学习模型
技术选型困境与创新突破在软件测试领域,技术栈选择一直是核心挑战。传统方法依赖历史数据和机器学习模型,但常陷入“预测陷阱”——过度依赖过往经验导致创新盲区。例如,自动化测试框架的错误选型每年造成巨额损失:38.7%源于技术生…...

SakuraLLM:二次元翻译的终极解决方案,完全离线的日中翻译大模型
SakuraLLM:二次元翻译的终极解决方案,完全离线的日中翻译大模型 【免费下载链接】Sakura-13B-Galgame 适配轻小说/Galgame的日中翻译大模型 项目地址: https://gitcode.com/gh_mirrors/sa/Sakura-13B-Galgame 如果你热爱日本轻小说、Galgame等二次…...

别再只调包了!手把手拆解OpenCV车位识别核心代码:像素统计、背景建模与形态学处理
从像素到决策:OpenCV车位识别核心技术实战解析 停车场监控画面中那些看似简单的"空"或"满"状态判定,背后隐藏着一系列精妙的图像处理魔法。今天,我们将抛开现成的API,直接解剖计算机视觉在车位检测中的核心算…...