Mysql大单表JSON优化
优化方案
MySQL 8.0.32 中,有几种方法可以优化存储 JSON 字符串的数据表。以下是一些建议,可以帮助您减少存储空间:
- 使用压缩: MySQL 8.0 支持表级压缩,可以通过修改表来启用压缩。
ALTER TABLE your_table ROW_FORMAT=COMPRESSED;
- 优化 JSON 存储: JSON 数据通常会有一些冗余,您可以考虑对 JSON 数据进行预处理,删除不必要的字段或缩短字段名。
- 分区表: 分区表可以有助于更好地管理大表的数据,可以通过 RANGE、LIST、HASH 或 KEY 分区。
ALTER TABLE your_table PARTITION BY RANGE (TO_DAYS(creation_date)) (PARTITION p0 VALUES LESS THAN (TO_DAYS('2023-01-01')),PARTITION p1 VALUES LESS THAN (TO_DAYS('2024-01-01')),PARTITION p2 VALUES LESS THAN (TO_DAYS('2025-01-01')),PARTITION p3 VALUES LESS THAN MAXVALUE
);
- 使用适当的数据类型: 如果可能,尽量避免使用 JSON 存储大数据量,可以使用结构化的表来存储数据,这样更容易进行优化和压缩。
- 外部存储: 如果 JSON 数据非常大,考虑将其存储在外部文件系统或对象存储中,如 Amazon S3,然后在表中只存储文件路径或索引。
- 删除重复数据: 检查是否有重复的数据,删除重复数据可以节省大量存储空间。
- 数据库清理: 定期清理和维护数据库,如删除无用的索引、归档旧数据等。
- 使用 InnoDB 压缩: InnoDB 支持透明的数据压缩,可以启用表或索引级的压缩。
ALTER TABLE your_table ENGINE=InnoDB, ROW_FORMAT=COMPRESSED KEY_BLOCK_SIZE=8;
- 调整 InnoDB 配置: 适当地调整 InnoDB 的配置参数,如 innodb_file_format, innodb_file_per_table 等,以获得更好的性能和存储效率。
- 手动压缩 JSON 数据: 在插入数据之前,可以使用压缩算法(如 gzip)手动压缩 JSON 字符串,然后在查询时解压缩。
通过这些方法,您可以优化存储 JSON 字符串的数据表,从而减少存储空间。具体采用哪种方法可以根据您的实际情况和需求进行选择和组合。
使用 InnoDB 压缩
InnoDB 引擎支持表和索引的压缩,可以通过 ROW_FORMAT=COMPRESSED 来启用压缩。压缩可以显著减少存储空间,同时还能提高某些查询的性能(尤其是读取更多数据时)。
启用压缩
要启用压缩,可以在创建表时指定 ROW_FORMAT=COMPRESSED 和 KEY_BLOCK_SIZE。KEY_BLOCK_SIZE 指定压缩块的大小,通常可以设置为 1, 2, 4, 8, 或 16 KB。
CREATE TABLE your_table (id INT PRIMARY KEY,data JSON
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED KEY_BLOCK_SIZE=8;
对于已有表,您可以通过 ALTER TABLE 命令启用压缩:
ALTER TABLE your_table ROW_FORMAT=COMPRESSED KEY_BLOCK_SIZE=8;
KEY_BLOCK_SIZE 是 InnoDB 表和索引压缩时使用的一个参数,它指定压缩块的大小。该参数在启用 InnoDB 表压缩时非常重要,因为它直接影响到数据的压缩率和性能。
含义和使用
- KEY_BLOCK_SIZE 参数:定义压缩块的大小,以千字节(KB)为单位。有效的值通常为 1, 2, 4, 8, 或 16 KB。
- 压缩块的大小:指定的块大小决定了数据在磁盘上的存储方式。较小的块大小通常会有更高的压缩率,但可能会对性能产生负面影响,因为更多的块需要被管理和访问。较大的块大小通常会有较好的性能,但压缩率可能会较低。
选择合适的块大小
选择 KEY_BLOCK_SIZE 时,可以考虑以下因素:
- 数据类型和大小:如果您的数据比较小且重复性高,较小的块大小可能会提供更高的压缩率。对于较大的数据,较大的块大小可能会更合适。
- 性能需求:如果性能是关键考虑因素,较大的块大小通常会更好,因为它减少了压缩和解压缩的开销。
- 存储空间:如果存储空间有限且需要最大化压缩率,较小的块大小可能会更好。
示例配置的含义
使用 KEY_BLOCK_SIZE=8:
- 块大小为 8 KB:指定每个压缩块的大小为 8 KB。
- 压缩效率和性能的平衡:8 KB 的块大小通常在压缩效率和性能之间提供一个良好的平衡。它通常适用于大多数应用程序,但具体效果仍然需要根据实际数据和查询模式进行测试和调整。
总之,KEY_BLOCK_SIZE 是一个关键参数,用于调整 InnoDB 压缩表的压缩块大小,从而影响表的存储效率和性能。选择合适的块大小需要根据具体应用场景和数据特性进行权衡和测试。
调整 InnoDB 配置
适当调整 InnoDB 配置参数可以提高性能和存储效率。以下是一些重要的 InnoDB 配置参数及其含义:
innodb_file_format
这个参数指定 InnoDB 的文件格式。MySQL 8.0 默认使用 Barracuda 文件格式,支持表压缩和动态行格式。
SET GLOBAL innodb_file_format = Barracuda;
在 MySQL 8.0 中,innodb_file_format 变量已被废弃(deprecated),并且默认的文件格式已经固定为 Barracuda,因此执行 SHOW VARIABLES LIKE ‘innodb_file_format’; 返回为空是预期行为。
在 MySQL 8.0 中,不再需要手动设置 innodb_file_format,因为 Barracuda 文件格式是默认的且唯一支持的格式。这也是为什么即使您尝试查询这个变量,返回的结果会是空的。
如果您想确认当前的表使用的是 Barracuda 文件格式,您可以通过以下命令查看表的行格式:
SHOW TABLE STATUS LIKE 'your_table_name';
在输出中,Row_format 列会显示 Compressed 或 Dynamic,这表示使用的是 Barracuda 文件格式。
innodb_file_per_table
这个参数决定 InnoDB 是否为每个表使用单独的表空间文件。启用这个选项后,每个表的数据和索引将存储在独立的 .ibd 文件中。这可以更容易管理表的压缩和存储。
SET GLOBAL innodb_file_per_table = ON;
innodb_page_size
这个参数指定 InnoDB 页的大小,默认是 16KB。较小的页面大小可能有助于压缩率,但会增加开销。一般情况下,保持默认设置即可。
SET GLOBAL innodb_page_size = 16384; -- 16KB
innodb_log_file_size
这个参数指定 InnoDB 日志文件的大小。较大的日志文件可以减少写入的频率,改善性能,但也会增加恢复时间。
SET GLOBAL innodb_log_file_size = 512M; -- 512MB
innodb_buffer_pool_size
这个参数指定 InnoDB 缓冲池的大小。缓冲池用于缓存数据和索引,提高读取性能。根据系统内存大小进行调整,通常设置为系统内存的 70-80%。
SET GLOBAL innodb_buffer_pool_size = 8G; -- 8GB
配置示例
在 MySQL 配置文件 (my.cnf 或 my.ini) 中进行这些设置:
[mysqld]
innodb_file_format = Barracuda
innodb_file_per_table = 1
innodb_page_size = 16384
innodb_log_file_size = 512M
innodb_buffer_pool_size = 8G
应用这些配置
修改配置文件后,您需要重启 MySQL 服务以使更改生效。
sudo systemctl restart mysql
通过以上调整和配置,您可以有效地减少存储空间,并在某些情况下提高性能。确保在更改配置前备份数据,并逐步测试这些调整对系统的影响。
案例
版本:8.0.32
text类型字段,底层为JSON字符串
全量数据: 35G -> 开启压缩后: 26G 压缩比=0.74,压缩率=0.26
2010-01-01数据: 18G -> 开启压缩后: 8.9G 压缩比=0.49,压缩率=0.51
读写
未开启压缩
Seconds % Task name
3441.68033 98% write task
0079.842993 02% read task
开启压缩后
Seconds % Task name
3442.119693 85% write task
0627.699276 15% read task
开启压缩+关闭binlog,性能没有太大的变化,cpu负载整体有降低
Seconds % Task name
3442.033828 85% write task
0624.982888 15% read task
CPU
4核心设备
未开启压缩:load avg 4.x
开启压缩后:load avg 7.x
cpu负载在优化webClient线程池后(8个IO-worker),稳定在3.x-4.x之间。并且任务完成时间没有波动,还是在3442.412387S左右。生产消息的队列也没有了满队告警日志"buffer full"。
也就是说cpu负载加大主要是因为webClient请求并行度过高导致的
小结
开启压缩后,CPU负载显著增高,写入性能稳定,读取性能显著降低,约增加了7倍。
多次实验验证在数据量达到350W+之后写入性能也会下降,导致应用程序操作并发受限,cpu使用率飙升,mybatis线程出现锁竞争,劣化严重导致应用程序宕机,同样配置环境,取消压缩表之后表现良好。
非压缩表在并发提升后,数据量达到300W左右时也会出现同样的劣化效果
其根本原因在于压缩数据的cpu成本
"web-client-consumer-7" #64 daemon prio=5 os_prio=31 cpu=108005.30ms elapsed=2343.21s tid=0x00007f8b55ba7600 nid=0xc203 waiting for monitor entry [0x000070000b6fa000]java.lang.Thread.State: BLOCKED (on object monitor)at org.apache.ibatis.ognl.OgnlRuntime.invokeMethod(OgnlRuntime.java:1151)- waiting to lock <0x0000000703f319d8> (a java.lang.reflect.Method)at org.apache.ibatis.ognl.OgnlRuntime.callAppropriateMethod(OgnlRuntime.java:1958)"web-client-consumer-1" #50 daemon prio=5 os_prio=31 cpu=109368.51ms elapsed=2344.58s tid=0x00007f8b5fe31000 nid=0xb907 waiting for monitor entry [0x000070000aee2000]java.lang.Thread.State: BLOCKED (on object monitor)at org.apache.ibatis.ognl.OgnlRuntime.invokeMethod(OgnlRuntime.java:1151)- locked <0x0000000703f319d8> (a java.lang.reflect.Method)at org.apache.ibatis.ognl.OgnlRuntime.callAppropriateMethod(OgnlRuntime.java:1958)
数据存在本地环境的客观因素,mysql与服务共用一台设备等等,以及mysql配置合理性问题,案例仅供参考,具体数据建议参考相关官方文档
TEXT 类型 vs JSON 类型
TEXT 类型
TEXT 类型用于存储长文本数据,包括 JSON 字符串。它适用于大多数文本存储需求,但对 JSON 数据的处理功能有限。
优点:
- 兼容性高:TEXT 类型在不同版本和工具中具有广泛的支持。
- 无额外开销:没有 JSON 数据类型的内部处理开销。
缺点:
- 缺乏内置功能:TEXT 类型没有 JSON 数据类型的内置函数和操作符,例如 JSON_EXTRACT、JSON_SET 等。
- 性能问题:大 JSON 数据的查询和操作可能会影响性能。
示例定义:
ALTER TABLE your_table ADD COLUMN json_text TEXT;
JSON 类型
JSON 类型是 MySQL 5.7+ 中的专用数据类型,用于存储 JSON 数据。它提供了丰富的功能来操作 JSON 数据。
优点:
- 内置函数:支持各种 JSON 函数,如 JSON_EXTRACT、JSON_SET、JSON_ARRAYAGG 等。
- 数据验证:MySQL 会验证 JSON 格式是否合法。
- 索引支持:可以对 JSON 字段创建虚拟列,并在虚拟列上创建索引,提高查询性能。
缺点:
- 性能开销:存储 JSON 数据时可能会有额外的开销。
- 兼容性问题:某些旧版工具和应用可能不完全支持 JSON 数据类型。
示例定义:
ALTER TABLE your_table ADD COLUMN json_data JSON;
选择建议
对于包含大 JSON 数据的字段,推荐使用 JSON 类型。以下是详细的理由和操作步骤:
推荐使用 JSON 类型
推荐理由:
- 数据验证:JSON 类型自动验证数据格式,确保数据符合 JSON 标准。
- 功能丰富:JSON 类型提供了丰富的 JSON 操作函数,适合需要对 JSON 数据进行操作和查询的场景。
- 未来兼容性:JSON 类型在未来版本中可能会得到更多支持和优化。
使用 TEXT 类型的情况
如果您的 JSON 数据是一次性写入且不需要经常查询或操作,可以继续使用 TEXT 类型
在这种情况下,您只需确保 JSON 数据在写入时是有效的,并且查询和操作的复杂度较低。
总结
| 类型 | 优点 | 缺点 |
|---|---|---|
| TEXT | 兼容性高;无额外的 JSON 数据类型开销 | 没有 JSON 数据类型的内置功能;查询性能较差 |
| JSON | 内置函数和操作符;数据验证;可以创建索引 | 存储 JSON 数据时有额外开销;兼容性问题 |
对于大 JSON 数据,推荐使用 JSON 类型,以利用 MySQL 的内置功能和优化。对于简单的文本存储,TEXT 类型也可以满足需求,但可能需要额外的处理步骤来管理 JSON 数据。
相关文章:

Mysql大单表JSON优化
优化方案 MySQL 8.0.32 中,有几种方法可以优化存储 JSON 字符串的数据表。以下是一些建议,可以帮助您减少存储空间: 使用压缩: MySQL 8.0 支持表级压缩,可以通过修改表来启用压缩。 ALTER TABLE your_table ROW_FORMATCOMPRESS…...

电脑开机启动项管理小工具,绿色免安装
HiBit Startup Manager 是一款功能强大的启动项管理工具,旨在帮助用户管理和优化计算机的自动启动程序。该软件通过添加或删除应用程序、编辑它们的属性以及管理流程、服务、任务调度程序和上下文菜单来实现这一目标。 HiBit Startup Manager 提供了以下主要功能&a…...
一例AutoHotkey语言生成的文件夹病毒分析
概述 这是一个使用AutoHotkey语言编写的文件夹病毒,使用ftp服务器来当作C2,通过U盘传播,样本很古老,原理也很简单,这种语言的样本还是第一次见到,记录一下。 样本的基本信息 PE32库: AutoIt(3.XX)[-]编译…...

【机器学习第7章——贝叶斯分类器】
机器学习第7章——贝叶斯分类器 7.贝叶斯分类器7.1贝叶斯决策论7.2 朴素贝叶斯分类器条件概率的m估计 7.3 极大似然估计优点基本原理 7.4 贝叶斯网络7.5 半朴素贝叶斯分类器7.6 EM算法7.7 EM算法实现 7.贝叶斯分类器 7.1贝叶斯决策论 一个医疗判断问题 有两个可选的假设&#…...

C++ QT开发 学习笔记(3)
C QT开发 学习笔记(3) - WPS项目 标准对话框 对话框类说明静态函数函数说明QFileDialog文件对话框getOpenFileName()选择打开一个文件getOpenFileNames()选择打开多个文件getSaveFileName()选择保存一个文件getExistingDirectory()选择一个己有的目录getOpenFileUrl()选择打幵…...

【Python实战】如何优雅地实现文字 二维码检测?
前几篇,和大家分享了如何通过 Python 和相关库,自动化处理 PDF 文档,提高办公效率。 【Python实战】自动化处理 PDF 文档,完美实现 WPS 会员功能【Python实战】如何优雅地实现 PDF 去水印?【Python实战】一键生成 PDF…...

行为型设计模式3:模板方法/备忘录/解释器/迭代器
设计模式:模板方法/备忘录/解释器/迭代器 (qq.com)...
思源笔记软件的优缺点分析
在过去一年里,我用了很多款笔记,从word文档到onenote到语雀再到思源,最后坚定的选择了思源笔记 使用感受 首先是用word文档来记笔记,主要是开始时不知道笔记软件怎么好用,等到笔记越来越膨胀的时候我发现,…...

追问试面试系列:Dubbo
欢迎来到Dubbo系列,在面试中被问到Dubbo相关的问题时,大部分都是简历上写了Dubbo,或者面试官想尝试问问你对Dubbo是否了解。 本系列主要是针对面试官通过一个点就使劲儿往下问的情况。 面试官:说说你们项目亮点 好的面试官 我们这个项目的技术亮点在于采用了Spring Cloud…...

动手学深度学习V2每日笔记(卷积层)
本文主要参考沐神的视频教程 https://www.bilibili.com/video/BV1L64y1m7Nh/p2&spm_id_from333.1007.top_right_bar_window_history.content.click&vd_sourcec7bfc6ce0ea0cbe43aa288ba2713e56d 文档教程 https://zh-v2.d2l.ai/ 本文的主要内容对沐神提供的代码中个人不…...

qcom ucsi probe
ucsi glink 注册一个ucsi 设备,和pmic glink进行通信,ucsi作为pmic glink的一个client。 lkml的patch https://lkml.org/lkml/2023/1/30/233 dtsi中一般会定义 qcom,ucsi-glink 信息,用于和驱动进行匹配 static const struct of_device_id …...

flask和redis配合
对于涉及数据提交的场景,比如更新用户信息,你可能会使用POST或PUT请求。但是,这些操作通常与直接从Redis缓存中检索数据不同,因为它们可能涉及到对后端数据库或其他存储系统的修改。并且可能需要将更新后的数据同步回Redis缓存&am…...

深度学习中的早停法
早停法(Early Stopping)是一种用于防止模型过拟合的技术,在训练过程中监视验证集(或者测试集)上的损失值。具体设立早停的限制包括两个主要参数: Patience(耐心):这是指验…...

科普文:JUC系列之多线程门闩同步器CountDownLatch的使用和源码
CountDownLatch类位于java.util.concurrent包下,利用它可以实现类似计数器的功能。比如有一个任务A,它要等待其他10个线程的任务执行完毕之后才能执行,此时就可以利用CountDownLatch来实现这种功能了。 CountDownLatch是通过一个计数器来实现…...

foreach循环和for循环在PHP中各有什么优势
在PHP中,foreach循环和for循环都是用来遍历数组的常用结构,但它们各有其优势和使用场景。 foreach循环的优势 简化代码:foreach循环提供了一种更简洁的方式来遍历数组,不需要手动控制索引或指针。易于阅读:对于简单的…...

巧用casaos共享挂载自己的外接硬盘为局域网共享
最近入手了个魔改机顶盒,已经刷好了的armbian,虽然是原生的,但是我觉得挺强大的,内置了很多 常用的docker和应用,只需要armbian-software 安装就行,缺点就是emmc太小了。 买到之后第一时间装上了casaos和1p…...

标题:解码“八股文”:助力、阻力,还是空谈?
标题:解码“八股文”:助力、阻力,还是空谈? 在程序员的面试与职场发展中,“八股文”一直是一个备受争议的话题。它既是求职者展示自己技术功底的途径,也是一些公司筛选人才的标准之一。但“八股文”在实际…...

语言无界,沟通无限:2024年好用在线翻译工具推荐
随着技术的发展现在的翻译在线工具从基础词句翻译到复杂的文章翻译都不在话下。为了防止你被五花八门的工具挑花眼,我给你介绍几款我用过的便捷、高效、准确的翻译工具吧。 1.福晰翻译端 链接直通:https://www.foxitsoftware.cn/fanyi/ 这个软件支持…...

【Golang 面试 - 进阶题】每日 3 题(十八)
✍个人博客:Pandaconda-CSDN博客 📣专栏地址:http://t.csdnimg.cn/UWz06 📚专栏简介:在这个专栏中,我将会分享 Golang 面试中常见的面试题给大家~ ❤️如果有收获的话,欢迎点赞👍收藏…...

二分+dp,CF 1993D - Med-imize
一、题目 1、题目描述 2、输入输出 2.1输入 2.2输出 3、原题链接 D - Med-imize 二、解题报告 1、思路分析 对于n < k的情况直接排序就行 对于n > k的情况 最终的序列长度一定是 (n - 1) % k 1 这个序列是原数组的一个子序列 对于该序列的第一个元素࿰…...

Flask RESTful 示例
目录 1. 环境准备2. 安装依赖3. 修改main.py4. 运行应用5. API使用示例获取所有任务获取单个任务创建新任务更新任务删除任务 中文乱码问题: 下面创建一个简单的Flask RESTful API示例。首先,我们需要创建环境,安装必要的依赖,然后…...

边缘计算医疗风险自查APP开发方案
核心目标:在便携设备(智能手表/家用检测仪)部署轻量化疾病预测模型,实现低延迟、隐私安全的实时健康风险评估。 一、技术架构设计 #mermaid-svg-iuNaeeLK2YoFKfao {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg…...

【ROS】Nav2源码之nav2_behavior_tree-行为树节点列表
1、行为树节点分类 在 Nav2(Navigation2)的行为树框架中,行为树节点插件按照功能分为 Action(动作节点)、Condition(条件节点)、Control(控制节点) 和 Decorator(装饰节点) 四类。 1.1 动作节点 Action 执行具体的机器人操作或任务,直接与硬件、传感器或外部系统…...

浅谈不同二分算法的查找情况
二分算法原理比较简单,但是实际的算法模板却有很多,这一切都源于二分查找问题中的复杂情况和二分算法的边界处理,以下是博主对一些二分算法查找的情况分析。 需要说明的是,以下二分算法都是基于有序序列为升序有序的情况…...

Spring AI与Spring Modulith核心技术解析
Spring AI核心架构解析 Spring AI(https://spring.io/projects/spring-ai)作为Spring生态中的AI集成框架,其核心设计理念是通过模块化架构降低AI应用的开发复杂度。与Python生态中的LangChain/LlamaIndex等工具类似,但特别为多语…...

AGain DB和倍数增益的关系
我在设置一款索尼CMOS芯片时,Again增益0db变化为6DB,画面的变化只有2倍DN的增益,比如10变为20。 这与dB和线性增益的关系以及传感器处理流程有关。以下是具体原因分析: 1. dB与线性增益的换算关系 6dB对应的理论线性增益应为&…...

【WebSocket】SpringBoot项目中使用WebSocket
1. 导入坐标 如果springboot父工程没有加入websocket的起步依赖,添加它的坐标的时候需要带上版本号。 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-websocket</artifactId> </dep…...
JDK 17 序列化是怎么回事
如何序列化?其实很简单,就是根据每个类型,用工厂类调用。逐个完成。 没什么漂亮的代码,只有有效、稳定的代码。 代码中调用toJson toJson 代码 mapper.writeValueAsString ObjectMapper DefaultSerializerProvider 一堆实…...
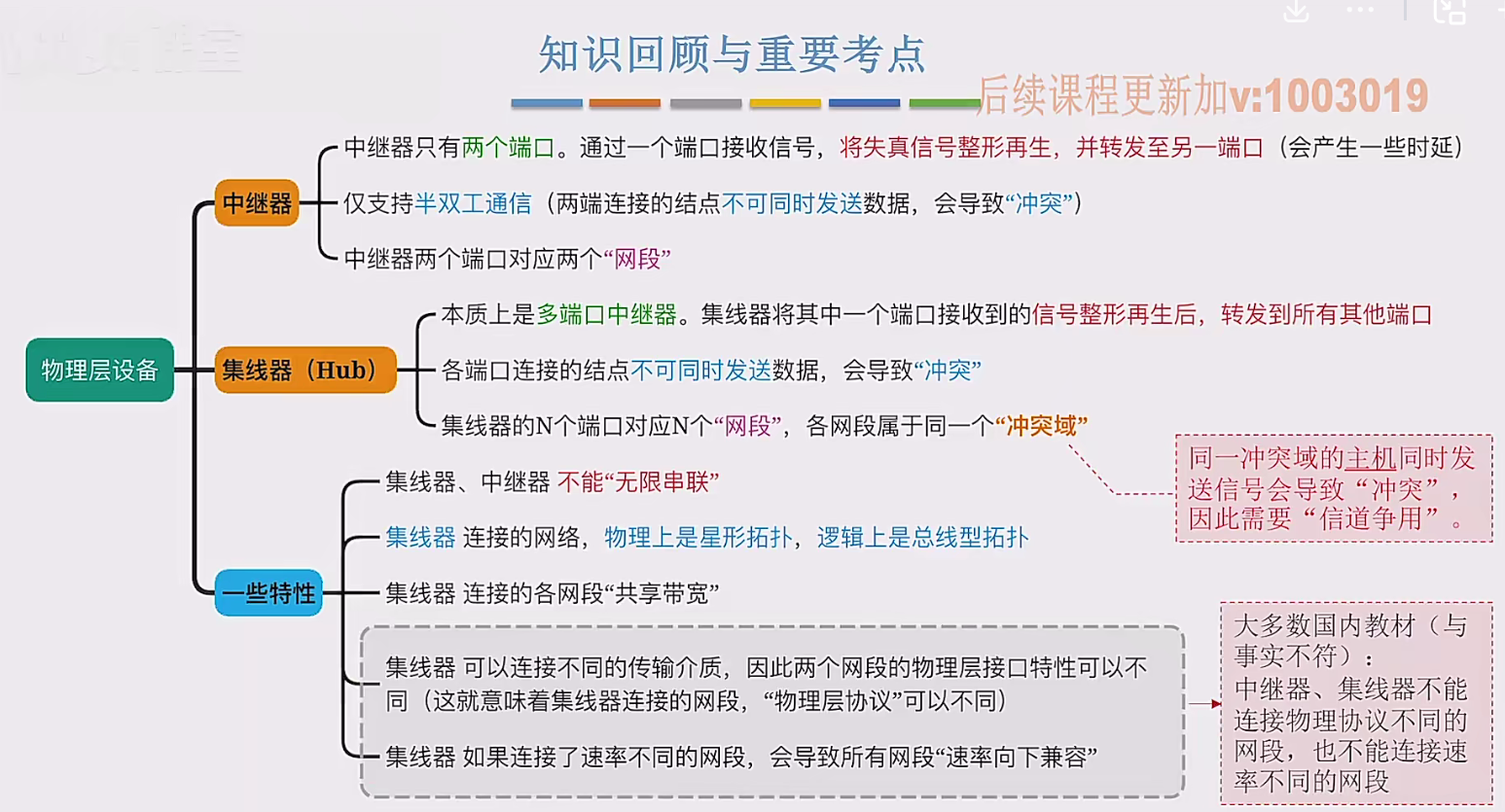
2.3 物理层设备
在这个视频中,我们要学习工作在物理层的两种网络设备,分别是中继器和集线器。首先来看中继器。在计算机网络中两个节点之间,需要通过物理传输媒体或者说物理传输介质进行连接。像同轴电缆、双绞线就是典型的传输介质,假设A节点要给…...

[特殊字符] 手撸 Redis 互斥锁那些坑
📖 手撸 Redis 互斥锁那些坑 最近搞业务遇到高并发下同一个 key 的互斥操作,想实现分布式环境下的互斥锁。于是私下顺手手撸了个基于 Redis 的简单互斥锁,也顺便跟 Redisson 的 RLock 机制对比了下,记录一波,别踩我踩过…...