第一章 PDF语法
第一章 PDF语法
- PDF Objects
- Null Objects
- Boolean Objects
- Numeric Objects
- Name Objects
- String Objects
- Array Objects
- Dictionary Objects
- Name trees
- Number trees
- Stream Objects
- Direct versus Indirect Objects
- File Structure
- White-Space
- The Four Sections of a PDF
- Header
- Trailer
- Body
- Cross-reference table
- Incremental Update
- Linearization
- Document Structure
- The Catalog Dictionary
- The Page Tree
- Pages
- PDF units
- Rects and boxes
- Inheritance
- The Name Dictionary
- What’s Next
我们将通过深入了解PDF文件格式的构建块来开始我们对PDF的探索。使用这些块,您将看到如何构建PDF以生成您熟悉的基于页面的格式。
PDF Objects
PDF文件的核心部分是PDF标准(ISO 32000)称为对象(有时是COS对象)的“事物”集合。
COS代表Carousel Object System,是指Adobe的Acrobat产品的原始名称/代号。
这些不是“面向对象编程”这个词意义上的对象;相反,它们是PDF的基础。有九种类型的对象:null, Boolean, integer, real, name, string, array, dictionary, and stream(空、布尔、整数、实数、名称、字符串、数组、字典和流)。
让我们看看这些对象类型中的每一种,以及它们是如何序列化为PDF文件的。从那里,您将看到如何获取这些对象类型,并使用它们来构建更高级别的构造和PDF格式本身。
Null Objects
如果实际写入到文件中,空对象就是四个字符空。它是缺失值的同义词,这就是为什么在PDF中很少看到缺失值的原因。如果您有理由使用空值,请务必仔细咨询ISO 32000,了解其处理的细节。
Boolean Objects
布尔对象表示逻辑值true和false,并在PDF中相应地表示为true或false。
在编写PDF时,您将始终使用true或false。但是,如果您正在阅读/分析的PDF希望对此宽容,请注意,不标准的PDF可能会使用其他形式,包括前导大写(True或False)或所有大写(TRUE或FALSE)。
Numeric Objects
PDF支持两种类型的数字对象:integer(整数)和real(浮点型)——表示它们在数学上的等价物。虽然PDF的旧版本已经声明了与Adobe的旧实现相匹配的实现限制,但这些限制不应该再被视为文件格式限制(任何供应商的任何特定实现也不应该被视为文件格式限制)。
虽然PDF支持64位数字(以便启用非常大的文件),但您会发现大多数PDF实际上并不需要它们。然而,如果你正在阅读PDF,你可能确实会遇到它们,所以要做好准备。
整数数字对象由一个或多个十进制数字组成,可选地前面加一个符号,表示有符号的值(以10为基数)。示例1-1显示了几个整数示例。
Example 1-1. Integers
1
-2
+100
612
实数对象由一个或多个带可选符号的十进制数字和表示带符号实数值的前导、尾随或嵌入句点组成。与PostScript不同,PDF不支持科学/指数格式,也不支持非十进制根。
虽然在PDF中使用“real”一词来表示对象类型,但给定查看器的实际实现可能使用双精度、浮点或甚至固定点数。由于实现方式可能不同,精度的小数位数也可能不同。因此,出于可靠性和文件大小的考虑,建议不要写入超过四位小数。
示例1-2显示了PDF中实数的一些示例。
Example 1-2. Reals
0.05
.25
-3.14159
300.9001
Name Objects
PDF中的name对象是唯一的字符序列(字符代码0、ASCII、null除外)通常用于有固定值集的情况。名称以/(SOLIDUS)字符后跟UTF-8字符串写入PDF,任何非正则字符都有特殊的编码形式。非正则字符是定义的字符在0x21(!)到0x7E(~)的范围之外,以及任何空格字符(请参见表1-1)。这些非规则字符以#(数字符号)开始编码,然后是字符的两位十六进制代码。
由于其独特的性质,您将写入PDF的大多数名称都是在ISO 32000中预先定义的,或者将从外部数据(例如字体或颜色名称)中导出。
如果您需要创建自己的基于非外部数据的自定义名称(如私有元数据),如果您希望文件被视为有效的PDF,则必须遵循ISO 32000-1:2008附录E中定义的第二类名称规则。第二个类名是以四个字符的ISO注册前缀开头,后跟下划线(_),然后是密钥名。实例包括在实例1-3的末尾。
Example 1-3. Names
/Type
/ThisIsName37
/Lime#20Green
/SSCN_SomeSecondClassName
String Objects
当字符串被序列化为PDF时,它们只是一系列(零或更多)8位字节,可以写成括号(and)中的文字字符,也可以写成尖括号()中的十六进制数据。
文字字符串由括号中任意数量的8位字符组成。因为字符串中可能会出现任何8位值,所以通过使用反斜杠转义特殊值,对不平衡括号())和反斜杠(\)进行特殊处理。此外,反斜杠可以与特殊的\ddd符号一起使用,以指定其他字符值。
文字字符串有几种不同的类型:
ASCII:仅包含ASCII字符的字节序列
PDFDocEncoded:根据PDFDocEncoding(ISO 32000–1:2008,7.9.2.3)编码的字节序列
Text:编码为PDFDocEncoding或UTF–16BE(带前导字节顺序标记)的字节序列
Date:ISO 32000–1:2008,7.9.4中描述了一个ASCII字符串,其格式为D:YYYYMMDDHHMMSOSOHH’mm
日期作为字符串的一种类型,在1.1版中被添加到PDF中。
一系列十六进制数字(0–9,A–F)可以写在尖括号之间,这对于在字符串对象中包含更多人类可读的任意二进制数据或Unicode值(UCS-2或UCS-4)非常有用。数字的数量必须始终是偶数,尽管可以在数字对之间添加空格字符以提高人类的阅读能力。示例1-4显示了PDF中字符串的几个示例。
Example 1-4. Strings
(Testing) % ASCII
(A\053B) % Same as (A+B)
(Français) % PDFDocEncoded
<FFFE0040> % Text with leading BOM
(D:19990209153925-08'00') % Date
<1C2D3F> % Arbitrary binary data
百分号(%)表示注释;它后面的任何文本都将被忽略。
之前关于字符串的讨论是关于如何将值序列化为PDF文件,而不一定是PDF处理器如何在内部处理这些值。虽然这种内部处理超出了标准的范围,但必须记住,不同的文件序列化可以产生相同的内部表示(如示例1-4中的(A\053B)和(A+B))。
Array Objects
数组对象是用方括号([and])括起来并用空格分隔的其他对象的异类集合。您可以在一个数组中混合和匹配任何类型的对象,而PDF在许多地方都利用了这一点。数组也可以是空的(即,包含零元素)。
虽然一个数组仅由一个维度组成,但可以构造与多维数组等效的数组。这种构造在PDF中不经常使用,但它确实出现在一些地方,例如称为可选内容组字典的数据结构中的Order数组。(请参阅第151页的“可选内容组”。)
PDF数组中的元素数量没有限制。但是,如果您找到了大型数组的替代方案(例如单个Kids数组的页面树),出于性能原因,最好避免使用它们。
示例1-5中给出了数组的一些示例。
Example 1-5. Arrays
[ 0 0 612 792 ] % 4-element array of all integers
[ (T) –20.5 (H) 4 (E) ] % 5-element array of strings, reals, and integers
[ [ 1 2 3 ] [ 4 5 6 ] ] % 2-element array of arrays
Dictionary Objects
因为它是几乎所有高级对象的基础,所以PDF中最常见的对象是字典对象。它是键/值对的集合,也称为关联表。每个键始终是一个名称对象,但值可以是任何其他类型的对象,包括另一个字典,甚至是null。
当该值为空时,将视为该键不存在。因此,最好不要简单的编写密钥,以节省处理时间和文件大小。
字典用双尖括号(<<and>>)括起来。在这些括号内,键可以按任何顺序显示,后面紧跟着它们的值。字典中出现的键将由正在编写的高级对象的定义(在ISO 32000中)决定。
虽然许多现有的实现倾向于按字母顺序编写键,但这既不是必需的,也不是期望的。事实上,不应假设字典的处理方式,字典可以按任何顺序读取和处理键。两次包含同一关键字的字典无效,所选值未定义。最后,虽然在键/值对之间放置换行符可以提高可读性,但这也不是必需的,只用于将字节添加到总文件大小中。
字典中键/值对的数量没有限制。
示例1-6显示了几个示例。
Example 1-6. Dictionaries
% a more human-readable dictionary
<</Type /Page/Author (Leonard Rosenthol)/Resources << /Font [ /F1 /F2 ] >>
>>
% a dictionary with all white-space stripped out
<</Length 3112/Subtype/XML/Type/Metadata>>
Name trees
名称树的作用类似于字典,因为它提供了一种将键与值相关联的方法。然而,与字典不同,键是字符串对象而不是名称,需要根据标准Unicode排序算法进行排序。
这一概念被称为名称树,因为有一个“根”字典(或节点)引用一个或多个子字典/节点,而这些字典/节点本身可以引用一个或者多个子字典或节点,从而创建树状结构的许多分支。
根节点保存一个键,Names(对于简单树)或Kids(对于更复杂的树)。在复杂树的情况下,每个中间节点也会有一个Kids键;每个分支的final/terminal节点将包含Names关键字。Names键的数组值通过交替键/值指定键及其值,如示例1-7所示。
示例1-7。名称树示例
% Simple name tree with just some names
1 0 obj
<</Names [(Apple) (Orange) % These are sorted, hence A, N, Z...(Name 1) 1 % and values can be any type(Name 2) /Value2(Zebra) << /A /B >>]
>>
endobj
Number trees
数字树与名称树相似,不同的是它的键是整数而不是字符串,并且按升序排列。此外,叶(或根)节点中包含键/值对的条目作为Nums键的值而不是Names键。
Stream Objects
PDF中的流是8位字节的任意序列,可以无限长,可以压缩或编码。因此,它们是用于存储大数据块的对象类型,这些数据块采用其他一些标准化格式,例如XML语法、字体文件和图像数据。
流对象由对象的数据表示,该对象前面有一个包含流属性的字典,称为流字典。使用单词stream(后面跟着行尾标记)和endstream(前面跟着行尾标志)用于描绘其字典中的流数据,同时也将其与标准字典对象区分开来。流字典从不单独存在;它始终是流对象的一部分。
流字典始终至少包含一个键Length,它表示从stream后面的行开始到endstream前面的行字符结束前的最后一个字节的字节数。换句话说,它是序列化到PDF文件中的实际字节数。对于压缩流,它是压缩字节数。虽然通常不提供,但原始未压缩长度可以指定为DL密钥的值。
流字典中最重要的键之一是Filter键,它指定在原始数据包含在流中之前对其应用了什么(如果有的话)压缩或编码。使用FlateDecode过滤器压缩大型图像和嵌入字体非常常见,该过滤器使用与ZIP文件格式相同的无损压缩技术。对于图像,最常见的两个过滤器是DCTDecode,它生成JPEG/JFIF兼容的流,以及JPXDe代码,它生成与JPEG2000兼容的流。其他过滤器见ISO 32000-12008,表6。示例1-8显示了PDF中的steam对象的外观。
示例1-8。示例流
Example 1-8. An example stream
<</Type /XObject/Subtype /Image/Filter /FlateDecode/Length 496/Height 32/Width 32
>>
stream
% 496 bytes of Flate-encoded data goes here...
endstream
Direct versus Indirect Objects
既然已经介绍了对象的类型,了解这些对象可以直接或间接地在PDF中表示是很重要的。
直接对象是那些显示为“内联”的对象,在从文件中读取对象时直接获取(因此得名)。它们通常作为字典键的值或数组中的条目找到,并且是迄今为止在所有示例中看到的对象类型。
间接对象是指通过引用(间接!)引用的对象,PDF阅读器必须在文件周围跳转才能找到实际值。为了识别所引用的对象,每个间接对象都有一个唯一的(每个PDF)ID,该ID表示为正数,以及一个生成号,该生成号总是非负数,通常为零(0)。这些数字用于定义对象和引用对象。
虽然最初打算用作跟踪PDF版本的方法,但现代PDF系统几乎从未使用过版本号,因此它们几乎总是零。
要使用间接对象,必须首先使用ID和generation以及obj和endobj关键字来定义它,如示例1-9所示。
示例1-9。完全由直接对象构成的间接对象
3 0 obj % object ID 3, generation 0
<</ProcSet [ /PDF /Text /ImageC /ImageI ]/Font <</F1 <</Type /Font/Subtype /Type1/Name /F1/BaseFont/Helvetica>>>>
>>
endobj
5 0 obj
(an indirect string)
endobj
% an indirect number
4 0 obj
1234567890
endobj
当你引用一个间接对象时,你可以使用它的ID、它的生成和字符R。例如,很常见的例子1-10,其中引用了两个间接对象(ID 4和5)。
示例1-10。引用其他间接对象的间接对象
3 0 obj % object ID 3, generation 0
<</ProcSet 5 0 R % reference the indirect object with ID 5, generation 0/Font <</F1 4 0 R >> % reference the indirect object with ID 4, generation 0
>>
endobj
4 0 obj % object ID 4, generation 0
<</Type /Font/Subtype /Type1/Name /F1/BaseFont/Helvetica
>>
endobj
5 0 obj % object ID 5, generation 0
[ /PDF /Text /ImageC /ImageI ]
endobj
通过使用ID和生成的组合,可以在给定的PDF中唯一地标识每个对象。使用PDF的交叉引用表功能,可以根据需要从引用中轻松定位和加载每个间接对象。
除非ISO 32000另有规定,否则任何时候使用对象时,它都可以是除流之外的任何一种类型,流只能是间接的。
File Structure
如果您要查看一个简单的PDF文件,让我们在PDF查看器中将其称为HelloWorld.PDF,它将如图1-1所示。
 但是,如果您要在文本编辑应用程序中查看HelloWorld.pdf,它看起来像示例1-11。
但是,如果您要在文本编辑应用程序中查看HelloWorld.pdf,它看起来像示例1-11。
示例1-11。“Hello World.pdf”在文本编辑器中的样子
%PDF-1.4
%%EOF
6 0 obj
<</Type /Catalog/Pages 5 0 R
>>
endobj
1 0 obj
<</Type /Page/Parent 5 0 R/MediaBox [ 0 0 612 792 ]/Resources 3 0 R/Contents 2 0 R
>>
endobj
4 0 obj
<</Type /Font/Subtype /Type1/Name /F1/BaseFont/Helvetica
>>
endobj
2 0 obj
<</Length 53
>>
stream
BT/F1 24 Tf1 0 0 1 260 600 Tm(Hello World)Tj
ET
endstream
endobj
5 0 obj
<</Type /Pages/Kids [ 1 0 R ]/Count 1
>>
endobj
3 0 obj
<</ProcSet[/PDF/Text]/Font <</F1 4 0 R >>
>>
endobj
xref
0 7
0000000000 65535 f
0000000060 00000 n
0000000228 00000 n
0000000424 00000 n
0000000145 00000 n
0000000333 00000 n
0000000009 00000 n
trailer
<</Size 7/Root 6 0 R
>>
startxref
488
%%EOF
看到这里,您可能会误以为PDF文件是一个文本文件,可以使用文本编辑器进行常规编辑,但事实并非如此!PDF文件是一个结构化的8位二进制文档,由一系列基于8位字符的标记描绘,用空格分隔并排列成(任意长)行。这些标记不仅用于描述各种对象及其类型,如您在上一节中所见,还用于定义PDF的四个逻辑部分的开始和结束位置。(见图1-2。)
如前所述,PDF中的标记始终以ASCII的8位字节进行编码(并因此进行解码)。它们不能以任何其他方式编码,例如Unicode。当然,特定的数据或对象值可以Unicode编码;我们将在出现这些情况时进行讨论。
White-Space
表1-1中所示的空白字符在PDF中用于将名称和数字等句法结构相互分离。


在除注释、字符串、交叉引用表条目和流之外的所有上下文中,PDF将任何连续空格字符序列视为一个字符。
CARRIAGE RETURN(0Dh)和LINE FEED(0Ah)字符,也称为换行符,被视为行尾(EOL)标记。CARRIAGE RETURN和LINE FEED的组合被视为一个EOL标记。EOL标记通常与任何其他空白字符相同。然而,有时需要EOL标记,位于出现在行开头的标记之前。
The Four Sections of a PDF
图1-2说明了PDF的四个部分:标题、尾部、正文和交叉引用表。

Header
PDF的标题从文件的字节0开始,至少由8个字节组成,后跟行尾标记。这8个字节用于明确标识文件是PDF(%PDF-),并建议文件符合的标准版本号(例如1.4)。如果您的PDF包含实际的二进制数据(现在,几乎所有的数据都包含),则后面会出现第二行,该行也以PDF注释字符%(PERCENT SIGN)开头。第二行的%后面至少有四个ASCII值大于127的字符。尽管任何四个(或更多)值都可以,但最常用的是âãÏÓ (0xE2E3CFD3)。
第二行是通过简单地计算高阶ASCII值来欺骗执行ASCII与二进制检测的程序,以确保PDF始终被视为二进制
Trailer
在PDF的标题的另一端,可以找到trailer。示例1-12显示了一个简单的示例。trailer主要是一个包含关键字和值的字典,它提供了处理文档本身所需的文档级信息。
示例1-12。一辆简单的trailer
trailer
<</Size 23/Root 5 0 R/ID[<E3FEB541622C4F35B45539A690880C71><E3FEB541622C4F35B45539A690880C71>]/Info 6 0 R
>>
两个最重要的键,也是必须的两个键,是Size和Root。Size键告诉您应该在尾部字典之前的交叉引用表中找到多少条目。Root键的值是文档的目录字典,您将从中开始查找PDF中的所有对象。
trailer中的其他常见密钥是Encrypt密钥,其存在可快速识别给定已加密的PDF;ID密钥,它为文档提供两个唯一的ID;以及Info键,它表示提供文档级元数据的原始方法(如第12章所述,该方法已被替换)。
Body
body是构成实际文档本身的所有九种类型的对象位于文件中的位置。您将在第21页的“文档结构”中看到更多关于这一点的信息,因为您会看到各种对象及其组织方式。
Cross-reference table
交叉引用表在概念和实现上很简单,但它是PDF的核心属性之一。该表为文件中的每个间接对象提供了从文件开头的二进制偏移量,允许PDF处理器在任何时候快速查找并读取任何对象。这种随机访问模式意味着可以快速打开和处理PDF,而无需将整个文档加载到内存中。此外,无论页码中的“数字跳跃”有多大,页面之间的导航都很快。将交叉引用表放在文件末尾还提供了两个额外的好处:可以在一次扫描中创建PDF(无回溯),并且可以方便地支持文档的增量更新(示例参见第18页的“增量更新”)。
交叉引用表的原始格式(从PDF 1.0到1.4)由一个或多个交叉引用部分组成,其中每个部分都是一系列条目(每个对象一行),其中包含对象的文件偏移量、其生成以及是否仍在使用。最常见的表类型如图1-3所示,只有一个部分列出了所有对象。

这种类型的交叉引用表遵循非常严格的格式,其中列位置是固定的,并且需要零
您可能会注意到,交叉引用表每行第二列中的数字值始终为零,第一行除外,第一行为65535。该值与f相结合,明确表示具有该ID的对象无效。因为PDF文件可能永远不会有ID为0的对象,所以在本例中,第一行看起来总是与您看到的一样。
然而,当PDF包含增量更新时,您可能会看到一个与示例1-13中类似的交叉引用部分。
示例1-13。更新的交叉引用部分
xref
0 1
0000000000 65535 f
4 1
0000000000 00001 f
6 2
0000014715 00000 n
0000018902 00000 n
10 1
0000019077 00000 n
trailer
<</Size 18/Root 9 0 R/Prev 14207
/ID[<86E7D6BF23F4475FB9DEED829A563FA7><507D41DDE6C24F52AC1EE1328E44ED26>]>>
随着PDF文档越来越大,很明显,拥有这种非常冗长(且不可压缩)的格式是一个需要解决的问题。因此,在PDF1.5中,引入了一种称为交叉引用流的新型交叉引用存储系统(因为数据存储为标准流对象)。除了可以压缩外,新格式更紧凑,支持大小超过10GB的文件,同时还提供了其他类型的未来扩展(尚未使用)。除了将交叉引用表移动到流之外,这个新系统还可以在另一种特殊类型的流(称为对象流)中存储间接对象的集合。通过在多个流中智能地分割对象,可以优化PDF的加载时间和/或内存消耗。示例1-14显示了交叉引用流的外观。
示例1-14。交叉引用流内部
stream
01 0E8A 0 % Entry for object 2 (0x0E8A = 3722)
02 0002 00 % Entry for object 3 (in object stream 2, index 0)
02 0002 01 % Entry for object 4 (in object stream 2, index 1)
02 0002 02 % . . .
02 0002 03
02 0002 04
02 0002 05
02 0002 06
02 0002 07 % Entry for object 10 (in object stream 2, index 7)
01 1323 0 % Entry for object 11 (0x1323 = 4899)
endstream
Incremental Update
如前所述,通过在文档末尾使用trailer和交叉引用表,PDF的一个关键特性是增量更新的概念。如图1-4所示,由于更改的对象被写入到PDF的末尾,因此保存修改非常快速,因为不需要读取和处理每个对象。

第一个交叉引用节之后的每个交叉引用节都指向前面的交叉引用节,该交叉引用节通过尾部字典中的Prev键(参见第16页的“Trailer”),然后仅在新表中列出新的、更改的或删除的对象,如示例1-13所示。
尽管观看者实际上不提供此功能(除非应用了数字签名,如第119页的“签名字段”),但使用增量更新意味着可以支持跨保存边界的多个撤销。然而,这也会给正在查看你的PDF文件的人带来危险。即使你认为自己从文件中删除了某些内容,但如果应用了增量更新而不是完全保存,则该内容可能仍然存在。
在增量更新PDF时,不要将经典交叉引用与交叉引用流混合,这一点非常重要。原始文件中使用的任何类型的交叉引用也必须在更新部分中使用。如果您将它们混合在一起,PDF阅读器可能会选择忽略更新。
Linearization
正如您所看到的,在文件末尾有交叉引用表提供了各种好处。然而,也有一个很大的缺点,那就是PDF必须通过“流接口”(如web浏览器中的HTTP流)读取。在这种情况下,一个普通的PDF文件必须完整下载,才能阅读到一个页面,这不是一个很好的用户体验。
为了解决这个问题,PDF提供了一个称为线性化的功能(ISO 32000-1:2008,附录F),但更为人所知的是“快速Web视图”。
线性化文件与标准PDF有三个不同之处:
- 文件中的对象以特殊的方式排序,使得特定页面的所有对象被分组在一起,然后以数字页面顺序组织(例如,页面1的对象,然后是页面2的对象,等等)。
- 标题后面有一个特殊的线性化参数字典,它将文件标识为线性化,并包含处理文件所需的各种信息。
- 部分交叉引用表和尾部放置在文件的开头,以允许访问根对象所需的所有对象,以及表示要显示的第一页的对象(通常为1)。
当然,与标准PDF一样,对象仍然以相同的方式引用,继续允许通过交叉引用表随机访问任何对象。线性化PDF的片段显示在示例1-15中。
示例1-15。线性化PDF片段
%PDF-1.7
%%EOF
8 0 obj
<</Linearized 1/L 7546/O 10/E 4079/N 1/T 7272/H [ 456 176]>>
endobj
xref
8 8
0000000016 00000 n
0000000632 00000 n
0000000800 00000 n
0000001092 00000 n
0000001127 00000 n
0000001318 00000 n
0000003966 00000 n
0000000456 00000 n
trailer
<</Size 16/Root 9 0 R/Info 7 0 R/ID[<568899E9010A45B5A30E98293
C6DCD1D><068A37E2007240EF9D346D00AD08F696>]/Prev 7264>>
startxref
0
%%EOF
% body objects go here...
混合线性化和增量更新可能会产生意想不到的结果,因为将使用线性化交叉引用表而不是更新版本,更新版本仅存在于文件末尾。因此,必须完全保存指定用于联机的文件,以删除更新并确保正确的线性化表。
Document Structure
现在,您已经了解了PDF中的各种对象,以及它们是如何组合在一起形成物理文件布局/结构的,现在是将它们组合在一起以形成实际文档的时候了。
The Catalog Dictionary
PDF文档是一个对象集合,从Root对象开始(图1-5)。之所以称为根,是因为如果您将PDF中的对象视为树(或有向图),则该对象位于树/图的根。从该对象中,您可以找到处理PDF页面及其内容所需的所有其他对象。

Root始终是Catalog类型的对象,称为文档的目录字典。它有两个必需的键:
- Type,其值始终为名称对象Catalog
- Pages,其值是对页面树的间接引用(第24页的“页面树”)
虽然能够进入PDF页面显然很重要,但也有二十多个可选键(见ISO 32000-1:2008,表28)。这些表示文档级信息,包括以下内容:
- 基于XML的元数据(第179页的“XMP”)
- OpenActions(“第79页的Actions”)
- Fillable forms (可填写表格,第7章)
- Optional content (可选内容,第10章)
- Logical structure and tags (逻辑结构和标记,第11章)
示例1-16显示了目录对象的示例。
Example 1-16. Catalog object
<</Type /Catalog/Pages 533 0 R/Metadata 537 0 R/PageLabels 531 0 R/OpenAction 540 0 R/AcroForm 541 0 R/Names 542 0 R/PageLayout /SinglePage/ViewerPreferences << /DisplayDocTitle true >>
>>
让我们看看你可能会发现在PDF中包含的一些键(及其值),以改善用户体验:
PageLayout(页面布局)
PageLayout键用于告诉查看器如何显示PDF页面。其值是name对象(请参见第3页的“name对象”)。要一次显示一个页面,请使用SinglePage的值,或者如果您希望所有页面都是长连续的列,使用值OneColumn。也可以一次为两页指定值(有时称为跨页),具体取决于奇数页的位置:TwoPageLeft和TwoPageRight。
PageMode(页面模式)
除了显示PDF页面内容之外,您可能还希望用户能够立即访问PDF的一些导航元素。例如,您可能希望书签或大纲可见(请参见第83页的“书签或大纲”了解更多信息)。PageMode键是一个名称对象,它的值决定显示哪些(如果有)额外元素,例如UseOut行、UseThumbs或UseAttachments。
ViewerPreferences(查看器首选项)
与前面两个示例不同,其中键的值是name对象,ViewerPreferences键的值为viewer preferences dictionary(参见ISO 32000-1:2008,12.2),要使用的最重要的一个(前提是向文档添加元数据,如第12章所述)如前一个示例所示:DisplayDocTitle。如果该值为true,则指示PDF查看器在窗口的标题栏中显示的不是文档的文件名,如图1-6所示,而是其真实标题,如图1-7所示。

The Page Tree
PDF中的页面通过页面树访问,页面树定义了页面的顺序。页面树通常被实现为平衡树,但也可以只是一个简单的页面数组。
建议您在一个叶子节点中的页数不超过25–50页。这意味着任何大于此值的文档都不应该使用单个数组,而是应该构建一个平衡的树。这样做的原因是,平衡树的设计意味着在内存或资源有限的设备上,可以找到任何特定页面,而不必加载整个阵列,然后依次访问阵列中的每个页面。
如图1-8所示,页面树中有两种类型的节点:中间节点(Pages类型)和终端或叶节点(page类型)。中间节点(包括树的起始节点)提供对其父节点(如果有)和子节点的间接引用,以及树的特定分支中叶节点的计数。叶节点是实际的Page对象。

图1-8的一部分(以PDF语法表示)可能与示例1-17类似。
Example 1-17. Objects making up a sample page tree
2 0 obj
<</Type /Pages/Kids[ 4 0 R ]/Count 3
>>
endobj
4 0 obj
<</Type /Pages/Parent 2 0 R/Rotate 90/Kids[ 5 0 R 6 0 R ]/Count 3
>>
endobj
5 0 obj
<</Type /Page% Additional entries describing the attributes of Page 1
>>
endobj
6 0 obj
<</Type /Page% Additional entries describing the attributes of Page 2
>>
endobj
Pages
正如刚才讨论的,页面树中的每个叶节点都表示一个页面对象。page对象是一个字典,其Type键的值为page;它还包含一些其他必需的键,可能包含十几个或更多可选键及其值。
示例1-18显示了一些示例页面字典。
Example 1-18. Two sample page dictionaries
% simplest valid page object, with the four required keys
<</Type /Page/Parent 2 0 R/MediaBox [ 0 0 612 792 ] % Page Size == 8.5 x 11 in (612/72 x 792/72)/Resources <<>>
>>
% a real-world page object
<</Type /Page/Parent 532 0 R/MediaBox [ 0 0 612 792 ]/CropBox [ 0 0 500 600 ]/Contents 564 0 R/Resources <</ExtGState << /GS0 571 0 R /GS1 572 0 R >>/Font << /T1_0 566 0 R >>/XObject << /Im0 577 0 R >>>>/Trans << /S /Dissolve >>/Rotate 90/Annots 549 0 R/AA << /C 578 0 R /O 579 0 R >>
>>
这里有几个要点需要指出,我们将在未来的章节中深入探讨其中的一些要点:
Content
除非您希望PDF中有空白页面,否则这是页面字典中最重要的关键字,因为它指向包含在页面上绘制内容的说明的内容流(请参见第35页的“内容流”)。
Rotate
此键可用于以90度为增量旋转页面。然而,虽然它是PDF的一个适当和有效的部分,但它经常被许多低端工具忽略。因此,请考虑使用适当大小的页面和(如有必要)转换后的内容,如第42页“Transformations”中所述。
Trans
如果存在,此键告诉查看器,当以“演示样式”显示页面时,它应该使用定义的转换从它之前的页面移到此页面。此键值的详细信息可以在ISO 32000-1:2008,12.4.4中找到。
Annots
该键的值是页面内容顶部的所有注释(参见第6章)的数组。
Resources
这些用于帮助完成图形对象的定义,如要在页面上绘制所需的字体或颜色。它们将在下一章中介绍。
PDF units
当您使用图形系统时,通常直接使用输出设备的分辨率,例如72或90 dpi(每英寸点数)屏幕或600 dpi打印机。这被称为设备空间(图1-9)。
然而,如图所示,如果您希望无论设备的特性如何都显示相同大小的对象,则需要在设备空间以外的其他空间中工作。对于PDF,这称为用户空间,无论输出设备如何,它都保持不变(图1-10)。

用户空间默认为每英寸72个用户单位(也称为“点”),原点位于左下角。可以通过在页面内容中使用坐标变换(参见第42页的“Transformations”)或在页面字典中存在UserUnit键(如示例1-19所示)来更改用户单元的数量。坐标系的原点始终为[0 0],但可能与可见PDF页面的左下角不对应,具体取决于页面框的值(请参见第30页的“Rects and boxes”)。
Example 1-19. Example pages that use the UserUnit key
2 0 obj
<</Type /Pages/Kids[ 3 0 R 4 0 R 5 0 R ]/Count >>
endobj
3 0 obj
<</Type /Page/Parent 2 0 R/UserUnit 1.0 % default of 72 units/inch/MediaBox [ 0 0 612 792 ] % 8.5 x 11 inches% more keys here...
>>
endobj
4 0 obj
<</Type /Page/Parent 2 0 R/UserUnit 2.0 % 144 units/inch (2 * 72)/MediaBox [ 0 0 612 792 ] % 17 x 22 inches% more keys here...
>>
endobj
5 0 obj
<</Type /Page/Parent 2 0 R/UserUnit 3.14159 % something funny but perfectly valid/MediaBox [ 0 0 612 792 ] % 26.70 x 34.56 inches% more keys here...
>>
endobj
Rects and boxes
在PDF语法中描述矩形时,使用四个数字的数组。数字的顺序是:左、下、宽、高。在PDF语法中,你会发现在不同的地方使用了矩形,但你最常用的矩形类型是定义页面框中不同区域的大小。
五个页面框(ISO 32000-1:2008,14.11.2)中的每一个都表示直接或通过注释在页面上绘制的图形元素的矩形查看区域(“box”)。数组中的四个数字始终以用户为单位,即用户空间的单位(见图1-10)。因为它表示页面坐标系中的视图,所以矩形不需要左下角位于[0 0]。
页面的MediaBox定义将在其上进行绘图的页面的大小。通常情况下,这相当于普通纸张尺寸,例如美国信纸(8.5 x 11英寸)或A4(21 x 29.7厘米),尽管它可以是任何尺寸。
默认(1.0)用户单位的MediaBox为[0 0 612 792],相当于一张美国信纸大小的纸张(8.572=612;1172=792)。
除了MediaBox之外,还有四个其他页面框可能会出现在页面上。如图1-11所示。

CropBox用于指示PDF查看器显示或打印页面时页面的实际可见区域。这主要用于当您不希望用户看到页面上的内容时,因此您“裁剪”它。与图像编辑器不同,应用CropBox不会删除任何内容;它只是将其隐藏在可见区域之外。
尽管CropBox可能扩展到MediaBox之外,但PDF查看器将有效地将值固定到MediaBox的值。
在印刷行业,TrimBox也有类似的用途。它定义了裁切器在打印完纸张后修剪(切割)纸张的位置,从而将TrimBox外的内容从最终纸张上移除。当你有东西想直接到达纸的边缘,没有任何空白或空隙时,就可以使用它。为了实现这一点,几乎总是有一个相关的BleedBox,它定义了“修剪框”外部的区域,其中内容“bleeds”,以便可以正确修剪。
最后一个box,叫做ArtBox,几乎从未使用过。它最初被认为是用来表示一个区域,它只覆盖了页面的“艺术品”,人们可能会使用它来重新调整用途,将其放置或强加到另一张纸上。然而,它从未真正流行起来,您不应该在文档中使用它们。
Inheritance
正如您在第26页的“Pages”中看到的,page对象中通常存在的一些值也可以出现在中间节点(Pages对象)中。发生这种情况时,这些值将由该节点的所有子节点继承,除非它们选择覆盖它们。例如,如果文档的所有页面大小相同,可以将MediaBox键放在页面树的根节点中。
并非页面对象中存在的所有键都可以继承,只有ISO 32000-1:2008表30中标识的键才能继承。
线性化PDF不能使用继承。必须直接在每个页面对象中指定所有值。
The Name Dictionary
PDF文件中的某些类型的对象可以通过name而不是对象引用来引用。name和对象之间的这种对应关系是通过使用名为name字典文档的东西来建立的。name字典是通过在文档的目录字典中包含名称键来指定的(请参阅第21页的“目录字典”)。此字典中可以出现的每个已定义键都指定了名称树的根,该名称树定义了特定类别对象的name。表1-2列出了一些可以通过name引用的对象类型:

What’s Next
在本章中,您学习了PDF的基本语法,从对象的基本类型开始,然后转到PDF文件的结构。您还了解了这些对象如何组合在一起形成文档及其页面,以及在页面对象中可以找到哪些键。
接下来,您将了解PDF图像模型、内容流以及如何在页面上实际绘制内容。
相关文章:
第一章 PDF语法
第一章 PDF语法PDF ObjectsNull ObjectsBoolean ObjectsNumeric ObjectsName ObjectsString ObjectsArray ObjectsDictionary ObjectsName treesNumber treesStream ObjectsDirect versus Indirect ObjectsFile StructureWhite-SpaceThe Four Sections of a PDFHeaderTrailerBo…...
IntelliJ IDEA 创建JavaFX项目运行
IntelliJ IDEA 创建JavaFX项目运行JavaFX官网文档:https://openjfx.io/openjfx-docs/ JavaFX 2008年12月05日诞生,是一个开源的下一代客户端应用程序平台,适用于基于 Java 构建的桌面、移动和嵌入式系统。这是许多个人和公司的协作努力&#…...

IC封装常见形式
参考:https://blog.csdn.net/dhs888888/article/details/127673300?utm_mediumdistribute.pc_relevant.none-task-blog-2defaultbaidujs_baidulandingword~default-0-127673300-blog-115610343.pc_relevant_multi_platform_whitelistv4&spm1001.2101.3001.4242…...

Linux通配符、转义符讲解
目录 通配符 通过通配符定义匹配条件 转义符 将所有的逻辑操作符都转换成字符 通配符 通过通配符定义匹配条件 * 任意字符都可以通配(也可以匹配空值) ? 匹配单个字符 [a-z] 匹配单个的小写英文字母 [A-Z] 匹配单个的大写英文…...

[OpenMMLab]提交pr时所需的git操作
git开发流程 准备工作 作为一个开发者,fork一个仓库之后应该先做什么? 1、下载仓库,创建上游代码库,查看当前的分支情况 git clone https://github.com/<your_name>/<repo_name>.git git remote add upstream git…...
pandas——groupby操作
Pandas——groupby操作 文章目录Pandas——groupby操作一、实验目的二、实验原理三、实验环境四、实验内容五、实验步骤一、实验目的 熟练掌握pandas中的groupby操作 二、实验原理 groupby(byNone, axis0, levelNone, as_indexTrue, sortTrue, group_keysTrue, squeezeFalse&…...
webpack.config.js哪里找?react项目关闭eslint监测
目录 webpack.config.js哪里找? react项目关闭eslint监测 webpack.config.js哪里找? 在React项目中,当我们需要修改一些配置时,发现找不到webpack.config.js,是我们创建的项目有问题吗,还需新创建项目的项…...
OpenCV 图像梯度算子
本文是OpenCV图像视觉入门之路的第12篇文章,本文详细的介绍了图像梯度算子的各种操作,例如:Sobel算子Scharr算子laplacian算子等操作。 OpenCV 图像梯度算子目录 1 Sobel算子 2 Scharr算子 3 laplacian算子 1 Sobel算子 Sobel算子是一种图…...
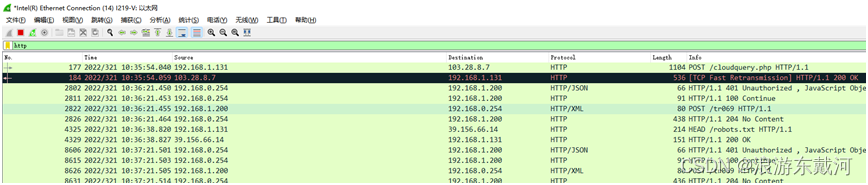
Linux c编程之Wireshark
Wireshark是一个网络报文分析软件,是网络应用问题分析必不可少的工具软件。网络管理员可以使用wireshark排查网络问题。程序开发人员可以用来分析应用协议、定位分析应用问题。无论是网络应用程序开发人员、测试人员、部署人员、技术支持人员,掌握wireshark的使用对于分析网络…...

极客时间_FlinkSQL 实战
一、批处理以及流处理技术发展 1.Lambda架构三层划分Batch Layer、Speed Layer和Serving Layer。 ①、Batch Layer:主要用于实现对历史数据计算结果的保存,每天计算的结果都保存成为一个Batch View,然后通过对Batch View的计算,实现历史数据的计算。 ②、Speed Layer正是用…...
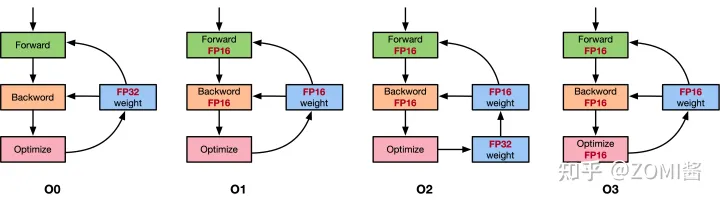
Pytorch 混合精度训练 (Automatically Mixed Precision, AMP)
Contents混合精度训练 (Mixed Precision Training)单精度浮点数 (FP32) 和半精度浮点数 (FP16)为什么要用 FP16为什么只用 FP16 会有问题解决方案损失缩放 (Loss Scaling)FP32 权重备份黑名单Tensor CoreNVIDIA apex 库代码解读opt-level (o1, o2, o3, o4)apex 的 o1 实现apex …...

使用太极taichi写一个只有一个三角形的有限元
公式来源 https://blog.csdn.net/weixin_43940314/article/details/128935230 GAME103 https://games-cn.org/games103-slides/ 初始化我们的三角形 全局的坐标范围为0-1 我们的三角形如图所示 ti.kernel def init():X[0] [0.5, 0.5]X[1] [0.5, 0.6]X[2] [0.6, 0.5]x[0…...
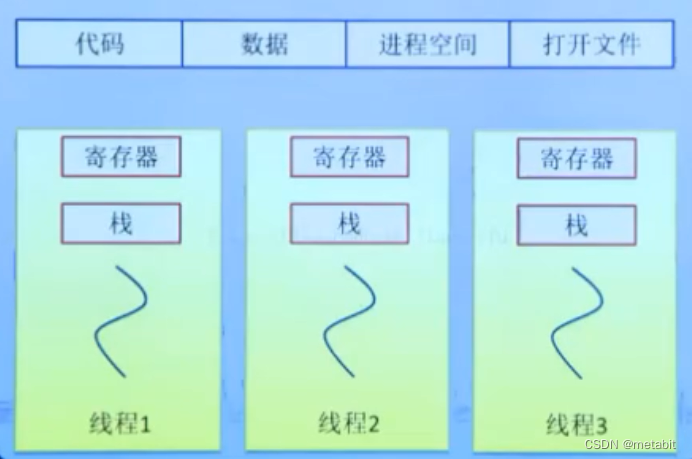
进程,线程
进程是操作系统分配资源的基本单位,线程是CPU调度的基本单位。 PCB:进程控制块,操作系统描述程序的运行状态,通过结构体task,struct{…},统称为PCB(process control block)。是进程管理和控制的…...

第03章_基本的SELECT语句
第03章_基本的SELECT语句 讲师:尚硅谷-宋红康(江湖人称:康师傅) 官网:http://www.atguigu.com 1. SQL概述 1.1 SQL背景知识 1946 年,世界上第一台电脑诞生,如今,借由这台电脑发展…...

干货 | 简单了解运算放大器...
运算放大器发明至今已有数十年的历史,从最早的真空管演变为如今的集成电路,它在不同的电子产品中一直发挥着举足轻重的作用。而现如今信息家电、手机、PDA、网络等新兴应用的兴起更是将运算放大器推向了一个新的高度。01 运算放大器简述运算放大器&#…...
C++定位new用法及注意事项
使用定位new创建对象,显式调用析构函数是必须的,这是析构函数必须被显式调用的少数情形之一!, 另有一点!!!析构函数的调用必须与对象的构造顺序相反!切记!!&a…...

【Android笔记75】Android之翻页标签栏PagerTabStrip组件介绍及其使用
这篇文章,主要介绍Android之翻页标签栏PagerTabStrip组件及其使用。 目录 一、PagerTabStrip翻页标签栏 1.1、PagerTabStrip介绍 1.2、PagerTabStrip的使用 (1)创建布局文件...

【Kafka】【二】消息队列的流派
消息队列的流派 ⽬前消息队列的中间件选型有很多种: rabbitMQ:内部的可玩性(功能性)是⾮常强的rocketMQ: 阿⾥内部⼀个⼤神,根据kafka的内部执⾏原理,⼿写的⼀个消息队列中间 件。性能是与Kaf…...

现代 cmake (cmake 3.x) 操作大全
cmake 是一个跨平台编译工具,它面向各种平台提供适配的编译系统配置文件,进而调用这些编译系统完成编译工作。cmake 进入3.x 版本,指令大量更新,一些老的指令开始被新的指令集替代,并加入了一些更加高效的指令/参数。本…...
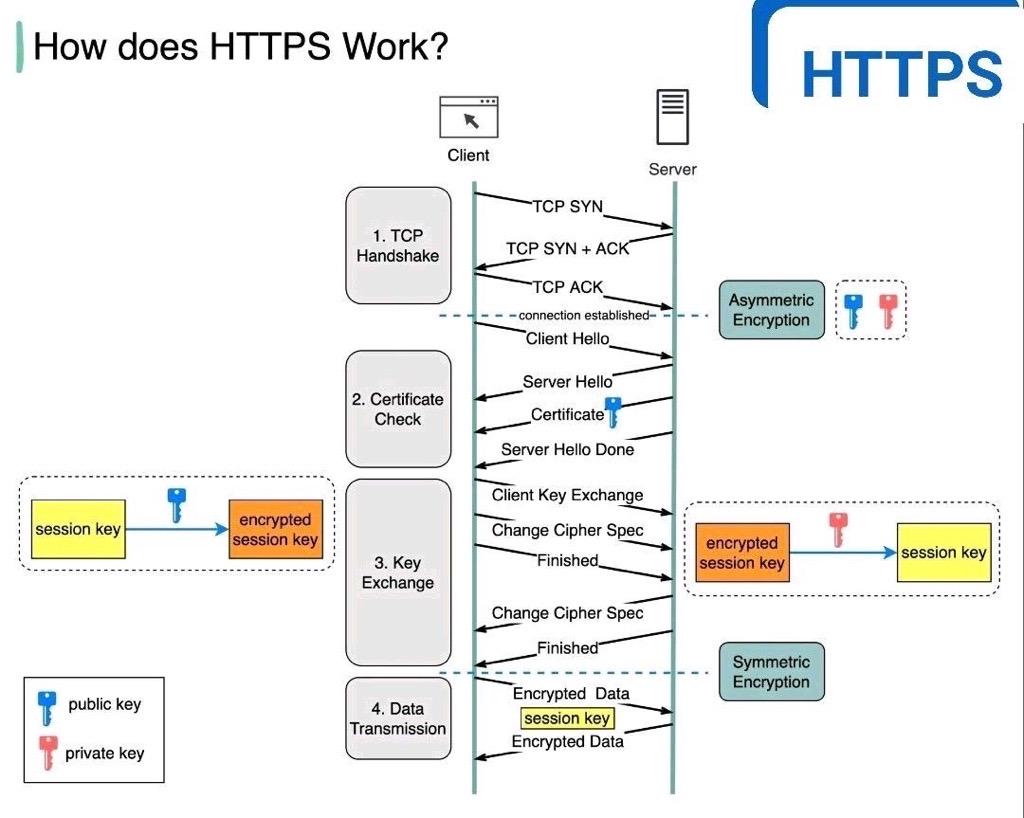
how https works?https工作原理
简单一句话: https http TLShttps 工作原理:HTTPS (Hypertext Transfer Protocol Secure)是一种带有安全性的通信协议,用于在互联网上传输信息。它通过使用加密来保护数据的隐私和完整性。下面是 HTTPS 的工作原理:初始化安全会…...

基于深度学习yolov13+qwen与deepseek的脑肿瘤识别与分析系统
基于YOLOv13AI的智能脑肿瘤检测系统 项目简介 基于YOLOv13深度学习模型与DeepSeek、Qwen大语言模型的智能脑肿瘤检测系统。本系统将前沿的计算机视觉技术与人工智能分析能力结合,为用户提供快速、精准的脑部医学影像分析与肿瘤识别服务,为医疗诊断、科研…...

十分钟搞定飞书机器人:用快马平台快速原型化你的openclaw应用
最近在做一个飞书机器人的小项目,发现用openclaw框架配合InsCode(快马)平台可以快速完成原型验证,整个过程比想象中简单很多。这里分享一下我的实践过程,从零开始十分钟就能跑通一个基础功能的飞书机器人。 项目准备阶段 传统开发需要先配置本…...

深度解析:RAKE算法在文本挖掘中的实战应用与性能优化
深度解析:RAKE算法在文本挖掘中的实战应用与性能优化 【免费下载链接】rake-nltk Python implementation of the Rapid Automatic Keyword Extraction algorithm using NLTK. 项目地址: https://gitcode.com/gh_mirrors/ra/rake-nltk 在当今信息过载的时代&a…...

YOLOv11算法优化实战:从特征融合到动态推理的性能跃迁
1. YOLOv11算法核心优化方向 目标检测领域近年来最令人兴奋的进展之一,就是YOLO系列算法的持续进化。作为这个家族的最新成员,YOLOv11在保持实时性的同时,通过多项技术创新实现了检测精度的显著提升。但在实际工业应用中,我们发现…...

WangEditor自定义元素踩坑实录:除了换行问题,这些API细节和样式继承你也得小心
WangEditor自定义元素深度避坑指南:从样式继承到API边界问题全解析 第一次在项目中尝试用WangEditor扩展自定义标题样式时,我对着编辑器里莫名其妙消失的边框样式发了半小时呆。官方文档明明写着"简单四步实现元素扩展",但实际开发…...

SpringBoot项目实战:5分钟搞定XXL-JOB 3.0.0与Admin控制台的本地联调
SpringBoot与XXL-JOB 3.0.0深度联调实战:从零搭建到避坑指南 当你需要在本地开发环境快速验证定时任务逻辑时,是否遇到过调度中心与业务项目无法联通的困扰?本文将手把手带你完成SpringBoot与XXL-JOB 3.0.0控制台的无缝对接,重点解…...

利用快马AI快速生成浏览器内容增强插件原型
利用快马AI快速生成浏览器内容增强插件原型 最近在开发一个浏览器插件时,发现从零开始搭建整个项目框架特别耗时。特别是当需要快速验证一个插件创意是否可行时,传统开发方式往往需要花费大量时间在基础架构上。这时候,我发现InsCode(快马)平…...

实战派必备:基于快马平台打造全能型ventoy系统救援启动盘
实战派必备:基于快马平台打造全能型ventoy系统救援启动盘 最近在折腾系统维护工具时,发现ventoy真是个神器。它不仅能同时装多个系统镜像到一个U盘,还能自定义菜单和工具包。不过网上的ventoy教程大多只教基础用法,真正适合实战的…...

如何快速构建全响应式应用:Reactor Core 与 WebFlux 集成终极指南
如何快速构建全响应式应用:Reactor Core 与 WebFlux 集成终极指南 【免费下载链接】reactor-core Non-Blocking Reactive Foundation for the JVM 项目地址: https://gitcode.com/gh_mirrors/re/reactor-core 在当今高并发、低延迟的微服务架构时代ÿ…...

避坑指南:ArcGIS核密度分析做POI研究,这3个参数设置错了等于白做
避坑指南:ArcGIS核密度分析做POI研究,这3个参数设置错了等于白做 在商业选址、城市规划或学术研究中,POI(兴趣点)数据的空间分布分析往往直接影响决策质量。核密度分析作为ArcGIS中最常用的空间统计工具之一࿰…...