c++并发编程面试题
1. C++中lock_guard和unique_lock的区别?
在C++中,lock_guard和unique_lock都是用于管理互斥锁的类,它们提供了一种 RAII(Resource Acquisition Is Initialization)机制来确保锁在作用域结束时自动释放。尽管它们的目的相似,但在功能和适用场景上有一些区别:
- 功能上的区别
lock_guard:
- 主要用于一个简单的锁管理场景。
- 在构造时自动获取锁,并在析构时自动释放锁。
- 不支持手动解锁或重新锁定功能,锁的获取和释放是严格绑定到对象的生命周期。
unique_lock:
- 提供更丰富的功能。
- 可以在构造时指定是否立即锁定,可以在作用域内手动解锁和重新锁定。
- 支持状态查询(例如,检测锁是否被持有)和条件变量的等待功能(通过与条件变量配合使用)。
- 允许移动,但不可复制。
- 性能
- lock_guard相对更轻量,适合简单的加锁需求。
- unique_lock因为功能更丰富,可能在某些情况下性能稍逊,但提供了更多灵活性。
- 使用场景
使用 lock_guard:
- 当你只需要简单的锁保护,且生命周期管理是清晰的情况下,使用 lock_guard 是最佳选择。
使用 unique_lock:
- 当你需要更复杂的锁逻辑,例如需要在某个条件下释放锁,或者需要与条件变量一起使用时,选择 unique_lock 更为合适。
示例代码
#include <iostream>
#include <mutex>
#include <thread> std::mutex mtx; void function_with_lock_guard() { std::lock_guard<std::mutex> lock(mtx); // 保护的代码块 std::cout << "Lock guard is holding the lock." << std::endl;
} void function_with_unique_lock() { std::unique_lock<std::mutex> lock(mtx); // 保护的代码块 std::cout << "Unique lock is holding the lock." << std::endl; // 这里可以手动释放锁 lock.unlock(); std::cout << "Lock has been released." << std::endl; // 重新锁定 lock.lock(); std::cout << "Lock is locked again." << std::endl;
} int main() { std::thread t1(function_with_lock_guard); std::thread t2(function_with_unique_lock); t1.join(); t2.join(); return 0;
} 总结
在大多数情况下,如果只需要简单的锁定和解锁,建议使用 lock_guard。如果需要更复杂的锁操作或条件变量的支持,选择 unique_lock。
2. C++中thread的join和detach的区别?
在C++中,std::thread提供了两种主要的线程管理方法:join和detach。它们在处理线程的生命周期和回收资源方面有重要的区别。
- join
- 功能: 当你调用join方法时,主线程会等待被调用的线程完成执行。
- 阻塞行为: 调用join会阻塞调用线程,直到目标线程结束。
- 资源管理: 一旦调用了join,相关的线程资源会被正确地清理,确保没有资源泄漏。
- 使用场景: 通常在你需要确保一个线程完成其工作后再继续执行主线程的情况下使用。例如,当线程完成了一项重要的计算或任务,并且主线程需要该结果时。
#include <iostream>
#include <thread> void threadFunction() { std::cout << "Thread is running." << std::endl;
} int main() { std::thread t(threadFunction); t.join(); // 等待线程t执行完毕 std::cout << "Thread has finished." << std::endl; return 0;
}
- detach
- 功能: 当你调用detach时,被调用的线程会独立于创建它的线程继续执行。
- 非阻塞行为: 调用detach后,主线程不会阻塞,线程会在后台运行。
- 资源管理: 一旦线程被分离,主线程无法再与之交互,也不能调用join。系统会自动管理这个线程的资源,因此可能会出现资源泄漏或未定义的行为,特别是如果主线程在后台线程完成前就退出。
- 使用场景: 通常在你希望后台线程独立执行一些任务,同时不需要等待它完成的情况下使用。例如,处理日志记录或异步计算。
#include <iostream>
#include <thread> void threadFunction() { std::cout << "Thread is running." << std::endl;
} int main() { std::thread t(threadFunction); t.detach(); // 将线程t分离,不等待其结束 std::cout << "Thread has been detached." << std::endl; // 给线程一些时间完成任务(仅用于示范,实际应用中应使用更安全的方法) std::this_thread::sleep_for(std::chrono::seconds(1)); return 0;
}
总结
- join: 等待一个线程完成执行,适用于需要同步的场合。
- detach: 使线程独立于主线程执行,适用于后台处理或不需要同步的场合。
在使用这些方法时,确保理解线程的生命周期,以避免潜在的资源泄漏或未定义行为。
3. C++中jthread和thread的区别?
在C++20中,引入了std::jthread,这是对std::thread的一个改进。以下是std::jthread和std::thread之间的主要区别:
- 自动管理线程生命周期
std::jthread:
- 自动管理线程的生命周期,使用了RAII(资源获取即初始化)原则。
- 如果std::jthread对象离开作用域,它会自动调用join(),确保线程在对象析构时被正确地加入(join),避免了遗留的线程。
std::thread:
- 需要手动管理线程的生命周期,调用join()或detach(),如果不处理,将导致程序异常终止。
- 更简便的使用
std::jthread:
- 通过构造函数直接接收可调用对象和参数,并在析构时自动进行join,使用起来更为方便。
std::thread:
需要在确定线程应当结束时手动调用join(),增加了出错的可能性。
- 支持可中断的线程
std::jthread:
- 提供了request_shutdown()方法来请求线程的终止。线程可以在合适的位置检查这个请求,从而安全地退出。
std::thread:
- 没有内置的中断机制,终止线程需要使用其他方法(如设置标志位、使用条件变量等),不够灵活。
- 使用方法示例
#include <iostream>
#include <thread> void threadFunction(std::stop_token stoken) { while (!stoken.stop_requested()) { // 执行一些任务 std::this_thread::sleep_for(std::chrono::milliseconds(100)); } std::cout << "Thread exiting." << std::endl;
} int main() { std::jthread jt(threadFunction); // 自动管理线程的生命周期 // 模拟主线程工作 std::this_thread::sleep_for(std::chrono::seconds(1)); // 请求线程结束 jt.request_stop(); return 0; // 自动调用 jt.join(),确保线程结束
} 总结
std::jthread 添加了自动管理和中断机制,使得线程管理更为安全和便捷。
std::thread 需要手动管理线程的生命周期,对用户的责任要求更高。
在大多数情况下,如果在C++20及以上版本中使用线程,推荐使用 std::jthread 以避免常见的线程管理问题。
4. C++如何设计一个线程安全的类?
在 C++ 中设计一个线程安全的类,通常需要确保对共享资源的访问不会引发数据竞争。要实现这一点,你可以使用互斥量(mutex)来保护对共享资源的访问。以下是一个简单的线程安全类的示例:
示例:线程安全计数器类
#include <iostream>
#include <mutex>
#include <thread> class ThreadSafeCounter {
public: ThreadSafeCounter() : count(0) {} // 增加计数器 void increment() { std::lock_guard<std::mutex> lock(mtx); // 锁住互斥量 ++count; } // 获取当前计数 int getCount() { std::lock_guard<std::mutex> lock(mtx); // 锁住互斥量 return count; } private: int count; // 共享资源 std::mutex mtx; // 互斥量,用于保护共享资源
}; void incrementCounter(ThreadSafeCounter& counter) { for (int i = 0; i < 1000; ++i) { counter.increment(); // 安全地递增计数器 }
} int main() { ThreadSafeCounter counter; // 创建多个线程以递增计数器 std::thread t1(incrementCounter, std::ref(counter)); std::thread t2(incrementCounter, std::ref(counter)); std::thread t3(incrementCounter, std::ref(counter)); // 等待所有线程完成 t1.join(); t2.join(); t3.join(); std::cout << "Final count: " << counter.getCount() << std::endl; // 输出最终计数 return 0;
}
代码解析
-
互斥量:我们使用 std::mutex 来保护共享资源 count。在每次读取或修改 count 时,都需要加锁,以防止其他线程同时访问。
-
锁的使用:使用 std::lock_guardstd::mutex 来自动管理锁的生命周期。lock_guard 在进入作用域时锁住互斥量,在离开作用域时自动解锁,避免手动解锁造成的错误。
-
线程安全操作:通过 increment 和 getCount 函数对 count 进行安全的访问和修改。
-
多个线程:在 main 函数中,我们创建了多个线程并调用 incrementCounter 函数,它会递增计数器。使用 std::ref 将计数器以引用的形式传递给线程。
注意事项
- 死锁:在复杂的情况下,确保你的锁不会相互依赖,从而导致死锁。
- 性能:频繁锁定和解锁可能会影响性能,根据具体场景考虑使用更高级的同步技术(如读写锁、条件变量等)。
- 设计:考虑你的类的设计。尽量减少锁的范围以提高性能,同时确保线程安全。
5.什么场景下使用锁,什么场景下使用原子变量?
在多线程编程中,选择使用锁还是原子变量取决于具体的场景和需求。以下是一些常见的应用场景,帮助你决定何时使用锁,何时使用原子变量:
使用锁的场景
-
复杂数据结构的安全访问:当需要对复杂数据结构(如链表、树、哈希表等)进行读写操作,在操作过程中可能涉及多个步骤时,使用锁可以确保整个操作的原子性。
-
需要访问多个共享资源:当一个操作涉及多个共享资源,并且需要保证它们之间的一致性时,锁可以确保这一点。例如,转账操作需要同时访问两个账户的余额。
-
保证操作顺序:当需要保证某些操作按特定顺序执行时,例如队列中的消息处理顺序,锁可以帮助实现此需求。
-
复杂的条件同步:使用条件变量(通常与锁结合使用)来管理线程间的复杂同步情况。
使用原子变量的场景
-
简单计数器或标志:如果你只是需要对一个简单的计数器或状态标志进行增、减或更新操作,使用 std::atomic 可以提供更高效且无锁的解决方案。
-
避免锁的开销:对于频繁访问的变量,使用原子操作可以减少上下文切换和锁的开销,提高性能。
-
自旋锁:在某些情况下,自旋锁(使用原子变量表示锁定状态)可以是优于传统锁的选择,尤其是在临界区代码很短的情况下,自旋是合适的。
-
标志或条件变量:如果你只需检查标志或控制某些状态,而不需要复杂的锁机制,使用原子变量可以更简单、更高效。
小结
-
锁是适合保护复杂数据结构和需要执行多个步骤的操作,它们确保了对共享资源的完整性和一致性。
-
原子变量适用于简单的操作,其开销较小、性能更高,在只需要确保单个操作的原子性时是一个优雅的选择。
在实际应用中,你需要根据具体的需求和环境来选择合适的同步机制。最佳实践是,尽量减少临界区的大小,保持简单,同时考虑可读性和维护性。
6. 如何理解C++中的atomic?
在C++中,std::atomic是一种用于定义原子操作的类型,提供了无锁的线程安全机制。它支持对共享变量的操作而不会遭遇数据竞争(data race),确保在多线程环境下的操作是原子性的。以下是对std::atomic的深入理解:
- 原子性(Atomicity)
- 原子操作:一个操作被称为原子操作,如果它在执行时不会被中断。即,其他线程在操作进行时不会看到部分完成的状态。
- 数据竞争的消除:由于原子操作不会被线程中断,因此可以避免数据竞争。这在多线程环境中至关重要,因为数据竞争可能导致不一致的值和未定义行为。
- std::atomic的基本用法
std::atomic可以用于多种数据类型,包括整型、指针等。基本使用方法包括:
#include <iostream>
#include <atomic>
#include <thread> std::atomic<int> counter(0); void increment() { for(int i = 0; i < 1000; ++i) { counter++; // 原子递增 }
} int main() { std::thread t1(increment); std::thread t2(increment); t1.join(); t2.join(); std::cout << "Final counter value: " << counter << std::endl; // 期望输出2000 return 0;
} - 原子操作的示例
-
基本操作:load, store, exchange, fetch_add, compare_exchange等方法允许获取和设置原子变量的值。
-
比较与交换:compare_exchange_strong和compare_exchange_weak用于实现自定义的锁-free算法,只有在目标值匹配时才会更新为新值。
- 内存顺序(Memory Order)
std::atomic允许你指定内存顺序,这是控制多线程间可见性的关键。常见的内存顺序包括:
- memory_order_relaxed:不保证任何顺序,仅保证原子操作的原子性。
- memory_order_acquire:确保该操作之前的所有读操作在顺序上不会被重排到它之后。
- memory_order_release:确保该操作之后的所有写操作在顺序上不会被重排到它之前。
- memory_order_acq_rel:同时具有 acquire 和 release 的效果。
- memory_order_seq_cst:提供严格的全序,所有线程在同一个序列中看到操作。
例如:
std::atomic<int> flag(0); // 设置值
flag.store(1, std::memory_order_release); // 读取值
if (flag.load(std::memory_order_acquire) == 1) { // 处理逻辑
}
- 使用原子的注意事项
- 性能:尽管std::atomic提供了无锁操作,但使用时仍需考虑性能开销,特别是不断进行原子操作可能会影响性能。
- 设计:在设计多线程程序时,尽量用最简单的同步机制,只有在必要时才使用更复杂的原子操作。
- 平台兼容性:std::atomic是跨平台的,但在不同的架构和编译器下可能会有不同的性能特点。
总结
std::atomic提供了一种简明且高效的方式来在多线程环境中进行线程安全的操作,避免了传统锁的复杂性和开销。正确理解原子操作及其内存顺序,能够帮助你更好地进行并发编程,从而提高程序的性能和稳定性。
7.C++锁的底层原理是什么?
在C++中,锁是一种用于实现线程同步的机制,确保数据的一致性和避免数据竞争。锁的底层原理可以从以下几个方面来理解:
- 锁的基本概念
锁是一种用于控制对共享资源(如变量、数据结构等)的访问的机制。在多线程环境中,当一个线程获得了锁,其他线程需要等到锁被释放后才能访问该资源。
- 锁的种类
- 互斥锁(Mutex):确保同一时间内只有一个线程能够访问共享资源。
- 读写锁(Read-Write Lock):允许多个线程同时读,但在写入时会排斥其他读写操作。
- 条件变量(Condition Variables):允许线程在某个条件不满足时睡眠,并在条件满足时被唤醒。
- 底层原理
3.1 原子操作
锁的实现通常依赖于原子操作(例如,使用std::atomic)。通过原子操作,可以在不需要复杂锁机制的情况下,安全地更新状态或计数值,避免数据竞争。
3.2 自旋锁与阻塞锁
-
自旋锁:线程在尝试获取锁时,如果锁已被其他线程持有,它会循环(自旋)等待,直到锁释放。这种方式适合短时间等待的场景,但如果锁被长时间保持,会浪费CPU资源。
-
阻塞锁:如果线程无法获取锁,它会被挂起(阻塞),直到锁可用。这通常使用操作系统的线程调度机制来实现,能够更有效地利用资源,尤其是在长时间等待的场合。
3.3 操作系统支持
大多数操作系统提供了对线程和同步机制的底层支持,包括:
-
线程管理:多线程库封装了底层操作系统的线程管理功能,通常会使用操作系统的API(如POSIX Threads(pthread))来实现锁。
-
原子性保障:平台级代码会确保对锁的操作是原子的,不可被中断,这通常依赖于CPU的指令集。
- 锁的实现
以下是mutex的一个简单实现原理:
#include <atomic> class SimpleMutex {
private: std::atomic_flag flag = ATOMIC_FLAG_INIT; // 原子标志 public: void lock() { while (flag.test_and_set(std::memory_order_acquire)) { // 自旋等待锁释放 } } void unlock() { flag.clear(std::memory_order_release); // 释放锁 }
};
- 性能考虑
-
锁竞争:多个线程尝试同时获取同一个锁会导致竞争,这可能导致性能下降。合理设计锁的粒度和策略是必要的。
-
死锁与解决:死锁是指多个线程因等待对方释放锁而无法继续执行。避免死锁的方式包括锁的顺序、超时、检测机制等。
- C++标准库中的锁
C++11引入了库,提供了多种锁的实现,包括:
- std::mutex:基本的互斥锁。
- std::recursive_mutex:允许同一线程多次获取同一锁。
- std::timed_mutex:带有超时功能的互斥锁。
- std::shared_mutex:实现读写锁的类。
总结
C++的锁机制是通过利用原子操作、操作系统支持和线程管理实现的。合理选择和使用锁可以提高程序的性能和可维护性,同时也要注意避免死锁和锁竞争带来的问题。
8.请介绍C++的6种内存序列?
在C++中,内存序列(Memory Order)主要与多线程编程中的原子操作和内存模型相关。C++标准定义了多种内存序列,用于控制线程之间的访问顺序。这些内存序列主要有以下几种:
- memory_order_relaxed:
该序列不对内存操作的顺序进行任何限制。它仅保证该操作是原子的,但不保证在该操作前后的其它读写操作的顺序。因此,使用这种序列时,可能会看到乱序执行的结果,但它仍然可以保证数据的一致性。
- memory_order_consume:
这个内存序列保证在该操作之后的所有依赖于该操作的读操作都在该操作之后执行。它通常用于实现从一个原子变量获取值并使用这个值的情况。实际应用中,这种序列的使用可能比较复杂,编译器对该序列的支持也常常有限。
- memory_order_acquire:
该序列用于获取锁或同步操作,保证在此操作前的所有读写操作都已经完成。换句话说,执行获取操作后,线程能看到所有在获取操作之前发生的写入。
- memory_order_release:
这个序列用于释放锁或数据结构,保证在此操作后的所有读写操作都不会在此之前的操作之后执行。这意味着在释放操作前的所有写入都会对其他线程可见。
- memory_order_acq_rel:
该序列结合了memory_order_acquire和memory_order_release的特性,既保证所有在该操作之前的写入在该操作之后可见,又保证该操作之后的所有读写操作在该操作之前完成。这通常用于实现同时需要获取和释放资源的操作。
- memory_order_seq_cst:
这是最严格的内存序列,保证全局的顺序性。所有执行在这个内存序列下的操作都必须遵循一个全局的顺序。这确保了所有线程都以相同的顺序观察到操作的结果,使得程序的行为更加可预测且容易理解。
这些内存序列对于多线程程序的正确性和性能有着重要影响,开发者需要根据具体需求选择合适的内存序列。
9.C++的条件变量为什么要配合着锁使用?
条件变量在C++中的使用通常需要与锁(例如互斥锁)配合,这主要是出于以下几个原因:
- 线程安全:
条件变量是用来在不同线程之间进行同步的工具,它允许一个线程在条件满足之前进入等待状态。为了确保对共享资源的访问是安全的,必须使用锁来防止多个线程同时访问共享数据从而引发数据竞争。
- 保持数据一致性:
当一个线程在等待条件变量时,它会释放所持有的锁。这使得其他线程能够在此期间修改共享资源,并可能确定何时满足条件。一旦条件满足,等待的线程会被唤醒并重新获得锁。这样可以确保在继续操作之前,线程获取的数据是一致且最新的。
- 避免虚假唤醒:
由于条件变量的特性,一个线程可能会在不满足条件的情况下被唤醒(比如操作系统的调度等原因)。因此,使用锁的方式可以确保在被唤醒后,线程重新检查条件是否确实满足,这一检查是在持有锁的状态下进行的,从而避免潜在的数据一致性问题。
- 实现复杂的线程交互:
许多多线程应用需要复杂的协调和交流,条件变量能够在一些特定的条件下控制线程的执行。使用锁可以有效地防止在检查和等待条件的期间发生数据竞争,确保多线程交互时的数据安全。
在C++中,标准库的条件变量(std::condition_variable)与互斥锁(std::mutex)通常一起使用,代码模式如下:
std::mutex mtx;
std::condition_variable cv;
bool ready = false; void worker() { std::unique_lock<std::mutex> lock(mtx); // 等待条件变量,释放锁,直到被唤醒 cv.wait(lock, [] { return ready; }); // 被唤醒后,继续工作 // ...
} void notify() { { std::lock_guard<std::mutex> lock(mtx); ready = true; // 修改条件 } cv.notify_one(); // 通知等待的线程
} 在上述例子中,std::unique_lock和std::lock_guard确保了在访问共享数据时的线程安全。同时条件变量的使用使得线程能有效地等待与通知,从而实现协调和同步。
C++条件变量,展示了如何使用条件变量来实现生产者-消费者模式。在这个例子中,生产者线程生成数据并将其放入缓冲区,而消费者线程从缓冲区中取出数据进行处理。
#include <iostream>
#include <thread>
#include <mutex>
#include <condition_variable>
#include <queue>
#include <chrono> std::queue<int> buffer; // 缓冲区
const unsigned int maxBufferSize = 5; // 最大缓冲区大小
std::mutex mtx; // 互斥锁
std::condition_variable cv; // 条件变量 // 生产者函数
void producer() { for (int i = 0; i < 10; ++i) { std::this_thread::sleep_for(std::chrono::milliseconds(100)); // 模拟生产延迟 std::unique_lock<std::mutex> lock(mtx); // 等待直到缓冲区未满 cv.wait(lock, [] { return buffer.size() < maxBufferSize; }); // 生产数据 buffer.push(i); std::cout << "生产者: 生产数据 " << i << '\n'; // 通知消费者 cv.notify_all(); }
} // 消费者函数
void consumer() { for (int i = 0; i < 10; ++i) { std::this_thread::sleep_for(std::chrono::milliseconds(150)); // 模拟消费延迟 std::unique_lock<std::mutex> lock(mtx); // 等待直到缓冲区有数据 cv.wait(lock, [] { return !buffer.empty(); }); // 消费数据 int data = buffer.front(); buffer.pop(); std::cout << "消费者: 消费数据 " << data << '\n'; // 通知生产者 cv.notify_all(); }
} int main() { std::thread producerThread(producer); std::thread consumerThread(consumer); producerThread.join(); consumerThread.join(); return 0;
}
代码解释:
- 缓冲区:
- 使用 std::queue 来作为共享缓冲区,和一个长度限制 maxBufferSize。
- 互斥锁和条件变量:
- 使用 std::mutex 来保护对缓冲区的访问,使用 std::condition_variable 来实现线程间的协调。
- 生产者线程:
- 生产者每次生成一个数据,首先检查缓冲区是否已满。如果缓冲区满,则使用 cv.wait(lock, condition) 等待,并在条件满足后继续。这是通过 notify_all() 通知被唤醒线程来实现的。
- 消费者线程:
- 消费者从缓冲区中取出数据,首先检查缓冲区是否为空。如果为空,则使用 cv.wait(lock, condition) 进行等待,直到有数据可用。
- 主函数:
- 创建生产者和消费者线程并等待它们结束。
运行结果:
在控制台中,你会看到生产者和消费者交替工作,输出生成和消费的数据。通过条件变量的使用,程序能够有效地协调生产和消费的过程。
10.对C++中cv.wait(lock,condition)的理解?
cv.wait(lock, condition) 的行为:它会在 condition 为 false 时使线程等待,直到 condition 变为 true。
具体解释
lock:
- 这是一个持有的互斥锁,确保在等待期间对共享资源的安全访问。
condition:
- 这是一个用于判断的条件,通常是一个 lambda 表达式或者函数,其返回值为布尔值。其目的是判断某个条件是否满足。
工作流程
- 初始状态: 当调用 cv.wait(lock, condition) 时,它会检查 condition 的返回值。
- 如果 condition 返回 false,线程将被挂起,并释放 lock,这样其他线程可以获取互斥锁并对共享资源进行修改。
- 如果 condition 返回 true(这种情况不会挂起线程),则线程继续执行后面的代码。
- 唤醒机制:
- 当其他线程(如生产者线程)改变了共享资源的状态并通知 cv(使用 notify_one() 或 notify_all()),等待的线程将被唤醒。
- 唤醒后,再次检查 condition。如果 condition 仍旧为 false,线程会再次进入等待状态。
示例
以下是一个示例,展示了消费者线程如何使用这一机制:
void consumer() { while (true) { std::unique_lock<std::mutex> lock(mtx); // 等待条件满足(缓冲区不为空) cv.wait(lock, [] { return !buffer.empty(); }); // 如果我们到达这里,条件为真,消费数据 int data = buffer.front(); buffer.pop(); std::cout << "消费者: 消费数据 " << data << '\n'; // 通知生产者可以添加数据 cv.notify_all(); }
}
总结
cv.wait(lock, condition) 在 condition 为 false 时使线程等待;一旦 condition 为 true,线程将继续执行。
这种机制在生产者-消费者模式中非常有效,可以确保消费者在没有可用数据时不会消耗 CPU 资源。
11.如何解决C++中条件变量的丢失和虚假唤醒的问题?
在 C++ 中,使用条件变量时,丢失唤醒(lost wakeup)和虚假唤醒(spurious wakeup)是常见的问题。下面分别介绍这两个问题及其解决方法。
虚假唤醒
定义: 虚假唤醒是指线程在未被实际通知的情况下被唤醒,导致它可能在不满足条件的情况下继续执行。
解决方法: 在调用 wait 后,用一个循环来检查条件,以确保线程只在条件满足时继续执行。
代码示例:
void consumer() { while (true) { std::unique_lock<std::mutex> lock(mtx); // 使用循环来处理虚假唤醒 cv.wait(lock, [] { return !buffer.empty(); }); int data = buffer.front(); buffer.pop(); std::cout << "消费者: 消费数据 " << data << '\n'; cv.notify_all(); }
}
丢失唤醒
定义: 丢失唤醒是指当线程正在等待时,由于某种原因(如程序错误或逻辑错误),它可能会错过一个有效的唤醒信号。
解决方法: 确保在 notify_one() 或 notify_all() 之前和之后正确管理条件,确保所有的条件检查和状态更新都在持有锁的情况下进行。避免在唤醒后立即移除数据,尤其是在复杂的条件或状态管理中。
示例代码:
以下是一个改进的生产者-消费者示例,确保了适当的条件检查和状态管理:
std::queue<int> buffer;
std::mutex mtx;
std::condition_variable cv; void producer() { for (int i = 0; i < 10; ++i) { { std::lock_guard<std::mutex> lock(mtx); buffer.push(i); std::cout << "生产者: 生产数据 " << i << '\n'; } cv.notify_one(); // 生产后通知消费者 }
} void consumer() { while (true) { int data; { std::unique_lock<std::mutex> lock(mtx); cv.wait(lock, [] { return !buffer.empty(); }); // 循环等待条件满足 // 消费数据 data = buffer.front(); buffer.pop(); } std::cout << "消费者: 消费数据 " << data << '\n'; }
}
关键要点
- 使用循环: 通过在条件变量的 wait 中使用一个 lambda 表达式,确保每次唤醒时都检查条件。
- 管理锁的粒度: 尽量缩小锁的持有范围,以提升并发性能,同时确保在关键段中始终正确管理条件。
- 适当通知: 只在条件改变之后调用 notify_one() 或 notify_all(),确保不会漏掉有效的唤醒信号。
通过以上方法,可以有效地处理虚假唤醒和丢失唤醒的问题,确保多线程环境中的条件变量使用正确且安全。
相关文章:

c++并发编程面试题
1. C中lock_guard和unique_lock的区别? 在C中,lock_guard和unique_lock都是用于管理互斥锁的类,它们提供了一种 RAII(Resource Acquisition Is Initialization)机制来确保锁在作用域结束时自动释放。尽管它们的目的相…...
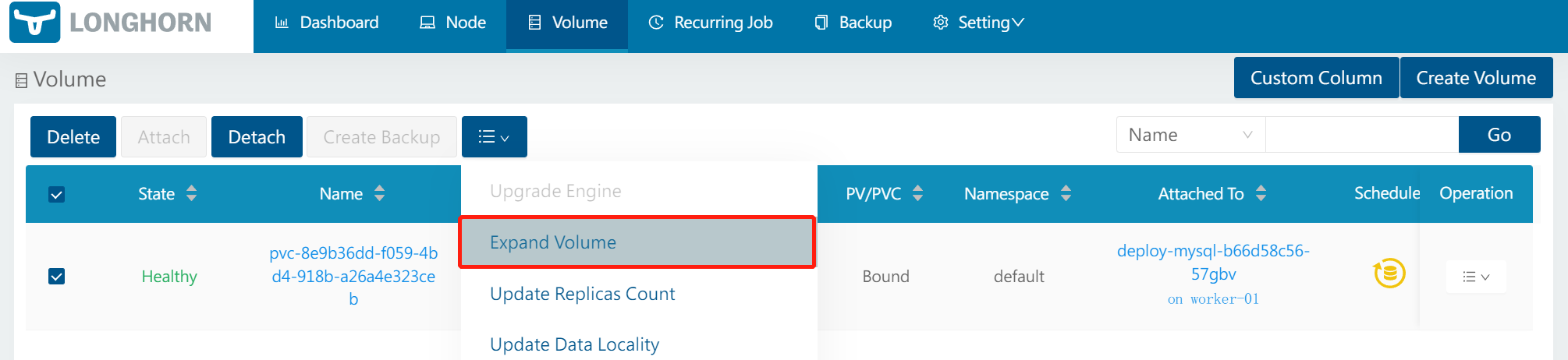
K8S上安装LongHorn(分布式块存储) --use
要在 Kubernetes上安装 LongHorn,您可以按照以下步骤进行操作: 准备工作 参考 官网教程将LongHorn只部署在k8s-worker5节点上。https://github.com/longhorn/longhorn 安装要求 Each node in the Kubernetes cluster where Longhorn is installed must f…...

2024年前端技术发展趋势分析
2024年的前端技术发展趋势继续受到快速变化的技术环境和不断增长的用户期望的影响。以下是2024年前端技术发展的几个关键趋势: 1. Web 组件和自定义元素 Web 组件技术(包括 Shadow DOM、HTML Templates 和 Custom Elements)正在成为构建可重…...

spring boot 笔记大杂烩
一,springboot项目创建 springboot创建时idea会打开start.spring.io失败报错 可以手动打开这个页面,然后选择maven项目,然后修改group和name名然后添加依赖web,然后生成项目包,解压缩后用idea打开就能用了 运行后报错…...

如何在香港云服务器上优化网站性能?
在香港云服务器上优化网站性能可以通过以下几种方式进行,确保用户从全球各地访问时获得快速、稳定的体验: 1. 使用内容分发网络 (CDN) 优势:CDN可以将静态内容(如图像、视频、CSS、JavaScript文件)缓存到全球多个节点…...

STM32低功耗与备用备份区域
STM的备份备用区域其实就是两个区块:BKP和RTC。低功耗则其实是STM32四种模式中的三种耗能很低的模式。 目录 一:备用区域 1.BKP 2.RTC 二:低功耗模式 1.睡眠模式: 2.停机模式: 3.待机模式: 一&…...

武汉某汽配公司携手三品软件 共绘PLM项目新蓝图
近日,三品软件与武汉某汽配公司达成战略合作,双方将共同启动PLM项目,以助力该公司在汽车制造业的研发管理领域实现全面升级。 客户简介 该公司自2008年成立以来,一直专注于为汽车制造业提供自动化输送系统、车辆装配的合装技术和…...

uniapp多图上传uni.chooseImage上传照片uni.uploadFile,默认上传9张图
uniapp多图上传uni.chooseImage上传照片uni.uploadFile 代码示例: /**上传照片 多图*/getImage() {uni.chooseImage({count: 9, //默认9sizeType: [original, compressed], //可以指定是原图还是压缩图,默认二者都有sourceType: [album], //从相册选择/…...

MySQL——内置函数
时间函数 select * from msg where date_add(sendtime, interval 2 minute) > now(); 理解: ------------------------------|-----------|-------------|------------------ 初始时间 now() 初始时间2min 字符串 length函数返回字符串长度,以字节为…...

2024年最新版小程序云开发数据模型的开通步骤,支持可视化数据库管理,支持Mysql和NoSql数据库,可以在vue3前端web里调用操作
小程序官方又改版了,搞得石头哥不得不紧急的再新出一版,教大家开通最新版的数据模型。官方既然主推数据模型,那我们就先看看看新版的数据模型到底是什么。 一,什么是数据模型 数据模型是什么 数据模型是一个用于组织和管理数据的…...

智慧水库大坝安全监测预警系统解决方案
前言 水库大坝作为重要的水利设施,承载着防洪涝、灌溉、发电等功能,关系着无数人的生命财产安全,一旦发生意外事故,后果将不堪设想,因此需要建立一套水库大坝安全监测预警系统解决方案。 系统概述 水库大坝安全监测…...

基于SpringBoot+VUE的社区团购系统(源码+文档+部署)
主要内容:Java项目、Python项目、前端项目、PHP、ASP.NET、人工智能与大数据、单片机开发、物联网设计与开发设计、简历模板、学习资料、面试题库、技术互助、就业指导等 业务范围:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写…...

LeetCode 3151. 特殊数组 I【数组】简单【Py3,C++,Java,GO,Rust】
本文属于「征服LeetCode」系列文章之一,这一系列正式开始于2021/08/12。由于LeetCode上部分题目有锁,本系列将至少持续到刷完所有无锁题之日为止;由于LeetCode还在不断地创建新题,本系列的终止日期可能是永远。在这一系列刷题文章…...

超级字符串技能:提升你的编码游戏
嘿嘿,uu们,今天咱们来详解字符函数与字符串函数,好啦,废话不多讲,开干! 1.:字符分类函数 C语言中又一系列的函数是专门做字符分类的,也就是一个字符属于什么类型的字符的,这些函数的使用需要包含头文件ctype.h 这些函数的使用方法都十分类似,博主在这里就举两到三个…...

米联客-FPGA程序设计Verilog语法入门篇连载-16 Verilog语法_时钟分频设计
软件版本:无 操作系统:WIN10 64bit 硬件平台:适用所有系列FPGA 板卡获取平台:https://milianke.tmall.com/ 登录“米联客”FPGA社区 http://www.uisrc.com 视频课程、答疑解惑! 1概述 本小节讲解Verilog语法的时钟…...

【Echarts】custom自定义图表实现甘特图
效果图 主要注意点: 1、右上角图例visualMap实现 2、visualMap增加formatter 3、series使用custom自定义图表,encode解析四维数组。核心是renderItem方法,必填项,且需要注意要全部定义在options里面!!&…...
)
【高等代数笔记】003线性方程组的解法(一)
1. 线性方程组的解法 1.1 解线性方程组的矩阵消元法 【例1】解线性方程组 { x 1 3 x 2 x 3 2 3 x 1 4 x 2 2 x 3 9 − x 1 − 5 x 2 4 x 3 10 2 x 1 7 x 2 x 3 1 \left\{\begin{array}{ll} x_{1}3x_{2}x_{3}2 \\ 3x_{1}4x_{2}2x_{3}9 \\ -x_{1}-5x_{2}4x_{3}10 \\…...

Scrapy入门教程
Scrapy入门教程:打造高效爬虫的第一步 1. 引言 在当今的网络世界中,信息是无价的资源。而爬虫工具则是获取这些资源的有力武器。Scrapy 是 Python 生态系统中最强大的爬虫框架之一,它不仅功能强大,而且易于扩展,适用…...

Microsoft VBA Excel VBA学习笔记——双重筛选+复制数值1.0
问题场景 CountryProductCLASS 1CLASS 2CLASS 3CLASS 4CLASS 5CLASS 6…USApple0.3641416030.8918210610.0591451990.7320110290.0509636560.222464259…USBanana0.2300833330.4027262180.1548836670.2988904860.7802326210.028592635…CNApple0.7762370470.5075548320.481978…...

谷歌反垄断官司败诉后,或又面临被拆分风险?
KlipC报道:上周8月5日,美国法院裁定谷歌的搜索业务违反了美国反垄断法,非法垄断在线搜索和搜索文本广告市场。据悉,胜诉的美国司法部正在考虑拆分谷歌。其他选项包括强制谷歌与竞争对手分享更多数据,以及防止其在人工智…...

从零起步探索SEO,让网站访客源源不断流入
在探索SEO的过程中,理解每个模块的内涵和相互关系至关重要。内容优化是连接关键词研究与外部链接建设的枢纽。通过优质的内容,不仅可以吸引目标用户,还能提升他们在网站上的体验和互动。在撰写内容时,需关注用户需求,确…...

JetBrains IDE试用期管理工具:跨平台高效解决方案
JetBrains IDE试用期管理工具:跨平台高效解决方案 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter ide-eval-resetter是一款专注于JetBrains系列IDE试用期管理的开源工具,通过安全可靠的技术…...

【立创开发板】GameStation-YunQy:基于梁山派打造NES掌机的硬件设计与模拟器移植实战
基于梁山派打造NES掌机:硬件设计与模拟器移植实战 最近有不少朋友问我,能不能用国产的GD32单片机做个好玩的东西?正好,立创EDA的梁山派开发板(GD32F470)性能强劲,价格也合适,我就用它…...

3分钟上手的高性能Markdown解决方案:轻量级编辑器的跨环境部署指南
3分钟上手的高性能Markdown解决方案:轻量级编辑器的跨环境部署指南 【免费下载链接】cherry-markdown ✨ A Markdown Editor 项目地址: https://gitcode.com/GitHub_Trending/ch/cherry-markdown 在信息爆炸的时代,选择一款既能提升写作效率又不占…...

效率提升秘籍:用快马AI一键生成专业级谷歌账号注册教程页面
最近在做一个教学类的小项目,需要制作一个谷歌账号注册的教程页面。这种页面结构其实挺典型的:有概述、有材料清单、有分步指导、还有FAQ。如果从头开始写HTML、CSS和JavaScript,光是调整样式和实现交互就得花上大半天。这次我尝试了一个新方…...

热键侦探:Windows系统热键冲突的全方位解决方案
热键侦探:Windows系统热键冲突的全方位解决方案 【免费下载链接】hotkey-detective A small program for investigating stolen hotkeys under Windows 8 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 一、热键冲突:被忽视的系…...

程序员考AI证:一般学习周期为3-6个月,备考经验全解析
在AI技术快速渗透职场的当下,AI证书已成为程序员职业进阶的核心背书,而CAIE注册人工智能工程师认证(全称Certificated Artificial Intelligence Engineer,中文简称“赛一”),凭借与程序员技术基础高度适配、…...

ComfyUI-VideoHelperSuite:AI视频工作流的效率革命与实践指南
ComfyUI-VideoHelperSuite:AI视频工作流的效率革命与实践指南 【免费下载链接】ComfyUI-VideoHelperSuite Nodes related to video workflows 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-VideoHelperSuite 内容导航图 核心价值 ├── 用户痛点解…...

第十章 微积分:贯穿多领域的统一思维与落地价值
第十章 微积分:贯穿多领域的统一思维与落地价值 专栏「微积分入门与行业展开」收官篇|承接第九章《微积分与数据分析:趋势预测和最优决策的工具》 一、系列回顾:从公式到思维的九层跃迁 过去九章,我们共同走完了一条从数学公式→行业工具→认知范式的完整路径。微积分不…...

U8g2常见问题解答:解决OLED/LCD显示开发中的痛点难题
U8g2常见问题解答:解决OLED/LCD显示开发中的痛点难题 【免费下载链接】u8g2 U8glib library for monochrome displays, version 2 项目地址: https://gitcode.com/gh_mirrors/u8/u8g2 U8g2是一款功能强大的单色显示器库,广泛应用于OLED和LCD显示…...