数据结构与算法 - 贪心算法
一、贪心例子
贪心算法或贪婪算法的核心思想是:
1. 将寻找最优解的问题分为若干个步骤
2. 每一步骤都采用贪心原则,选取当前最优解
3. 因为没有考虑所有可能,局部最优的堆叠不一定让最终解最优
贪心算法是一种在每一步选择中都采取在当前状态下最好或最优(即最有利)的选择,从而希望导致结果是最好或最优的算法。这种算法通常用于求解优化问题,如最小生成树、背包问题等。
贪心算法的应用:
1. 背包问题:给定一组物品和一个背包,每个物品有一定的重量和价值,要求在不超过背包容量的情况下,尽可能多地装入物品。
2. 活动选择问题:在一个活动集合中,每次只能参加一个活动,问如何安排时间以最大化所有活动的收益。
3. 编辑距离问题:给定两个字符串,求它们之间的最小编辑距离(即将一个字符串转换为另一个字符串所需的最少操作次数)。
4. 网络流问题:给定一张有向图和一些起点和终点,求最大流量。
5. 找零问题:给定一定数量的硬币和需要找零的金额,求使用最少的硬币数。
常见问题及解答:
1. 贪心算法一定会找到最优解吗?
答:不一定。贪心算法只保证在每一步选择中都是最优的,但并不能保证整个问题的最优解。例如,背包问题中的贪心算法可能会导致最后一个物品没有被装入背包。
2. 如何判断一个问题是否适合用贪心算法解决?
答:一个问题如果可以用递归的方式分解为若干个子问题,且每个子问题都有明确的最优解(即局部最优),那么这个问题就可以用贪心算法解决。
3. 贪心算法的时间复杂度是多少?
答:贪心算法的时间复杂度取决于问题的规模和具体实现。一般来说,对于规模较小的问题,贪心算法的时间复杂度可以达到O(nlogn)或O(n^2);对于规模较大的问题,可能需要(O^3)或更高。
几个贪心的例子
Dijkstra
// ...
while (!list.isEmpty()) {// 选取当前【距离最小】的顶点Vertex curr = chooseMinDistVertex(list);// 更新当前顶点邻居距离updateNeighboursDist(curr);// 移除当前顶点list.remove(curr);// 标记当前顶点已经处理过curr.visited = true;
}-

- 没找到最短路径的例子:负边存在时,可能得不到正确解
- 问题出在贪心的原则会认为本次已经找到了该顶点的最短路径,下次不会再处理它(curr.visited = true)
- 与之对比,Bellman-Ford并没有考虑局部距离最小的顶点,而是每次都处理所有边,所以不会出错,当然效率不如Dijkstra
Prim
// ...
while (!list.isEmpty()) {// 选取当前【距离最小】的顶点Vertex curr = chooseMinDistVertex(list);// 更新当前顶点邻居距离updateNeighboursDist(curr);// 移除当前顶点list.remove(curr);// 标记当前顶点已经处理过curr.visited = true;
}Kruskal
// ...
while (list.size() < size - 1) {// 选取当前【距离最短】的边Edge poll = queue.poll();// 判断两个集合是否相交int i = set.find(poll.start);int j = set.find(poll.end);if (i != j) { // 未相交list.add(poll);set.union(i, j); // 相交}
}其它贪心的例子
-
选择排序、堆排序
-
拓扑排序(入度最小)
-
并查集合中的 union by size 和 union by height
-
哈夫曼编码
-
钱币找零,英文搜索关键字
-
change-making problem
-
find Minimum number of Coins
-
-
任务编排
-
求复杂问题的近似解
二、零钱兑换问题
1. 零钱兑换
给你一个整数数组 coins ,表示不同面额的硬币;以及一个整数 amount ,表示总金额。
计算并返回可以凑成总金额所需的 最少的硬币个数 。如果没有任何一种硬币组合能组成总金额,返回 -1 。
你可以认为每种硬币的数量是无限的。
示例 1:
输入:coins = [1, 2, 5], amount = 11输出:3解释:11 = 5 + 5 + 1
示例 2:
输入:coins = [2], amount = 3输出:-1
示例 3:
输入:coins = [1], amount = 0 输出:0
提示:
1 <= coins.length <= 121 <= coins[i] <= 2^31 - 10 <= amount <= 10^4
解法一:穷举法。超出时间限制
private int min = -1;public int coinChange(int[] coins, int amount) {rec(0, coins, amount, new AtomicInteger(-1));return min;}// count代表某一组合,钱币的总数private void rec(int index, int[] coins, int remainder, AtomicInteger count) {count.incrementAndGet();if (remainder == 0) {if (min == -1) {min = count.get();} else {min = Integer.min(min, count.get());}} else if (remainder > 0) {for (int i = index; i < coins.length; i++) {rec(i, coins, remainder - coins[i], count);}}count.decrementAndGet();}解法二:动态规划
class Solution {public int coinChange(int[] coins, int amount) {int[] dp = new int[amount + 1];Arrays.fill(dp, amount + 1);// 0元所需的硬币数为0dp[0] = 0;// 遍历每一个硬币for (int coin : coins) {// 从coin到amount更新dp数组for (int i = coin; i <= amount; i++) {// dp[i]为凑成金额i所需的最少硬币个数dp[i] = Math.min(dp[i], dp[i - coin] + 1);}}return dp[amount] == amount + 1 ? -1 : dp[amount];}
}解法三:贪心算法。只能通过部分测试用例
(贪心算法得到的解不一定是全局最优解)
// 贪心算法 可能得到错误的解public int coinChange(int[] coins, int amount) {Arrays.sort(coins);reverseArray(coins);int remainder = amount;int count = 0;for (int coin : coins) {// 从大面额的金币开始凑while (remainder > coin) {remainder -= coin;count++;}if (remainder == coin) {remainder = 0;count++;break;}}if (remainder > 0) {return -1;} else {return count;}}private void reverseArray(int[] coins) {int left = 0;int right = coins.length - 1;while (left < right) {// 交换元素int temp = coins[left];coins[left] = coins[right];coins[right] = temp;left++;right--;}}2. 零钱兑换Ⅱ
给你一个整数数组 coins 表示不同面额的硬币,另给一个整数 amount 表示总金额。
请你计算并返回可以凑成总金额的硬币组合数。如果任何硬币组合都无法凑出总金额,返回 0 。
假设每一种面额的硬币有无限个。
题目数据保证结果符合 32 位带符号整数。
示例 1:
输入:amount = 5, coins = [1, 2, 5] 输出:4 解释:有四种方式可以凑成总金额: 5=5 5=2+2+1 5=2+1+1+1 5=1+1+1+1+1
示例 2:
输入:amount = 3, coins = [2] 输出:0 解释:只用面额 2 的硬币不能凑成总金额 3 。
示例 3:
输入:amount = 10, coins = [10] 输出:1
提示:
1 <= coins.length <= 3001 <= coins[i] <= 5000coins中的所有值 互不相同0 <= amount <= 5000
解法一:每次都会重复计算相同的子问题,导致时间复杂度较高。超出时间限制
class Solution {public int change(int amount, int[] coins) {return rec(0, coins, amount, new LinkedList<>(), true);}/*** 求凑成剩余金额的解的个数* @param index 当前硬币索引* @param coins 硬币面值数组* @param remainder 剩余金额* @param stack* @param first* @return*/private int rec(int index, int[] coins, int remainder, LinkedList<Integer> stack, boolean first) {if(!first) {stack.push(coins[index]);}int count = 0;// 情况1:剩余金额 < 0 -> 无解if(remainder < 0) {print("无解:", stack);}// 情况2:剩余金额 == 0 -> 找到解else if(remainder == 0) {print("有解:", stack);count = 1;}// 情况3:剩余金额 > 0 -> 继续递归else {for (int i = index; i < coins.length; i++) {count += rec(i, coins, remainder - coins[i], stack, false);}}// 回溯backtrackif(!stack.isEmpty()) {stack.pop();}return count;}private static void print(String prompt, LinkedList<Integer> stack) {ArrayList<Integer> print = new ArrayList<>();ListIterator<Integer> iterator = stack.listIterator(stack.size());while(iterator.hasPrevious()) {print.add(iterator.previous());}System.out.println(prompt + print);}
}解法二:动态规划。执行耗时2ms
使用一个一维数组dp来保存到达每个金额所需的不同硬币组合的数量
public int change(int amount, int[] coins) { int[] dp = new int[amount + 1]; dp[0] = 1; // 只有一种方式凑成0元,即不使用任何硬币 // 动态规划:通过循环每一个硬币来计算不同金额的组合数 for (int coin : coins) { for (int i = coin; i <= amount; i++) { dp[i] += dp[i - coin]; } } return dp[amount];
}三、Huffman编码问题
1. 问题引入
(1)什么是编码?
答:简单来说就是建立【字符】到【数字】的对应关系,如下面大家熟知的ASCⅡ编码表,例如,可以查表得知字符【a】对应的数字是十六进制数【0x61】
| \ | 00 | 01 | 02 | 03 | 04 | 05 | 06 | 07 | 08 | 09 | 0a | 0b | 0c | 0d | 0e | 0f |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0000 | 00 | 01 | 02 | 03 | 04 | 05 | 06 | 07 | 08 | 09 | 0a | 0b | 0c | 0d | 0e | 0f |
| 0010 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 1a | 1b | 1c | 1d | 1e | 1f |
| 0020 | 20 | ! | " | # | $ | % | & | ' | ( | ) | * | + | , | - | . | / |
| 0030 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? |
| 0040 | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 0050 | P | Q | R | S | T | U | V | W | X | Y | Z | [ | \ | ] | ^ | _ |
| 0060 | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 0070 | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | 7f |
注:一些直接以十六进制数字标识的是那些不可打印字符
(2)传输时的编码
java中每个char对应的数字会占用固定长度2个字节
如果在传输中仍采用上述规则,传递abbccccccc这10个字符
- 实际的字节为 0061006200620063006300630063006300630063(16进制表示)
- 总共20个字节,不经济
现在希望找到一种最节省字节的传输方式,怎么办?
假设传输的字符中只包含a,b,c这3个字符,有同学重新设计一张二进制编码表,见下图
- 0表示a
- 1表示b
- 10表示c
现在还是传递abbccccccc这10个字符
- 实际的字节为 01110101010101010 (二进制表示)
- 总共需要17bits,也就是2字节多一点,行不行?
不行,因为解码会出现问题,因为10会被错误的解码成为ba,而不是c
- 解码后的结果为 abbbababababababa,是错误的。
怎么解决?必须保证编码后的二进制数字,要能区分它们的前缀(prefix-free),用满二叉树结构编码,可以确保前缀不重复

- 向左走为0,向右走为1
- 走到叶子字符,累计起来的0和1就是该字符的二进制编码
- a的编码为0;b的编码为10;c的编码为11
现在还是传递 abbccccccc 这 10 个字符
- 实际的字节为 0101011111111111111(二进制表示)
- 总共需要 19 bits,也是 2 个字节多一点,并且解码没有问题了,行不行?
这次解码没有问题了,但是并非最少字节,因为c的出现频率高(7次),a的出现频率低(1次),因此出现频率高的字符编码成短数字更经济。
考察下面的树

00表示a;01表示b;1表示c
现在还是传递image-20230616095129461
-
实际的字节为 000101 1111111 (二进制表示)
-
总共需要 13 bits,这棵树就称之为 Huffman 树
-
根据 Huffman 树对字符和数字进行编解码,就是 Huffman 编解码
2. Huffman树及Huffman编解码
注:为了简单,期间编码解码都用字符串演示,实际应该按bits编解码
package com.itheima.algorithms.greedy;import java.util.Comparator;
import java.util.HashMap;
import java.util.Map;
import java.util.PriorityQueue;/*** Huffman树及编解码*/
public class HuffmanTree {/*** Huffman树的构建过程* 1. 将统计了出现频率的字符,放入到优先级队列* 2. 每次出队两个频次最低的元素,给他俩找个爹* 3. 把爹重新放入队列,重复 2~3* 4. 当队列中只剩一个元素时,Huffman树构建完成*/static class Node {Character ch; // 字符int freq; // 频次Node left; // 左孩子Node right; // 右孩子String code; // 编码public Node(Character ch) {this.ch = ch;}public Node(int freq, Node left, Node right) {this.freq = freq;this.left = left;this.right = right;}public int getFreq() {return freq;}public boolean isLeaf() {return left == null;}@Overridepublic String toString() {return "Node{" + "ch = " + ch + ", freq = " + freq + "}";}}String str;Node root;Map<Character, Node> map = new HashMap<>();public HuffmanTree(String str) {this.str = str;// 1. 统计频率char[] chars = str.toCharArray();for (char ch : chars) {/*if(!map.containsKey(ch)) {map.put(ch, new Node(ch));}Node node = map.get(ch);node.freq++;*/Node node = map.computeIfAbsent(ch, Node::new);node.freq++;}// 2. 构造树PriorityQueue<Node> queue = new PriorityQueue<>(Comparator.comparingInt(Node::getFreq));queue.addAll(map.values());while (queue.size() >= 2) {// 每次出队两个频次最低的元素,给他俩找个爹Node x = queue.poll();Node y = queue.poll();int freq = x.freq + y.freq;// 把爹重新放入队列queue.offer(new Node(freq, x, y));}root = queue.poll();// 3. 计算每个字符的编码int bit = dfs(root, new StringBuilder());for (Node node : map.values()) {System.out.println(node + ", " + "code:" + node.code);}System.out.println("字符串 " + str + " 编码总共占用了 " + bit + " bit");}private int dfs(Node node, StringBuilder code) {int sum = 0;if (node.isLeaf()) {// 叶子节点node.code = code.toString();// 4. 统计字符串编码后占用多少bitsum += node.freq * node.code.length();} else {sum += dfs(node.left, code.append("0"));sum += dfs(node.right, code.append("1"));}// 回溯if (code.length() > 0) {code.deleteCharAt(code.length() - 1);}return sum;}// 编码public String encode() {char[] chars = str.toCharArray();StringBuilder sb = new StringBuilder();for (char ch : chars) {sb.append(map.get(ch).code);}return sb.toString();}/*** 解码* 从根节点开始,寻找数字对应的字符* 数字是0,向左走* 数字是1,向右走* 如果没走到头,每走一步数字的索引 i++* 走到头就可以找到解码字符,再将node重置为根节点* @param str -> code* @return*/public String decode(String str) {char[] chars = str.toCharArray();int i = 0;StringBuilder sb = new StringBuilder();Node node = root;while(i < chars.length) {if(!node.isLeaf()) { // 非叶子if(chars[i] == '0') {// 向左走node = node.left;} else if(chars[i] == '1'){// 向右走node = node.right;}i++;}if(node.isLeaf()) {sb.append(node.ch);node = root;}}return sb.toString();}public static void main(String[] args) {HuffmanTree tree = new HuffmanTree("abbccccccc");String encode = tree.encode();System.out.println(encode);System.out.println(tree.decode(encode));}
}
3. 连接木棍的最低费用
为了装修新房,你需要加工一些长度为正整数的棒材 sticks。
如果要将长度分别为 X 和 Y 的两根棒材连接在一起,你需要支付 X + Y 的费用。 由于施工需要,你必须将所有棒材连接成一根。
返回你把所有棒材 sticks 连成一根所需要的最低费用。注意你可以任意选择棒材连接的顺序。
示例 1:
输入:sticks = [2,4,3]
输出:14
解释:先将 2 和 3 连接成 5,花费 5;再将 5 和 4 连接成 9;总花费为 14。
示例 2:
输入:sticks = [1,8,3,5]
输出:30
提示:
1 <= sticks.length <= 10^4
1 <= sticks[i] <= 10^4
解法一:哈夫曼树(建树)
class Solution {public int connectSticks(int[] sticks) {// 1. 将元素放入优先队列PriorityQueue<Integer> queue = new PriorityQueue<>();for (int stick : sticks) {queue.offer(stick);}int sum = 0;while(queue.size() >= 2) {// 每次取最小的两个Integer x = queue.poll();Integer y = queue.poll();int c = x + y;sum += c;// 将父节点入队queue.offer(c);}return sum;}
}四、活动选择问题
1. 举办最多的活动
要在应该会议室举办n个活动
- - 每个活动有它们各自的起始和结束时间
- - 找出时间上互不冲突的活动组合,能够充分利用会议室(举办的活动次数最多)
package com.itheima.algorithms.greedy;import java.util.ArrayList;
import java.util.Arrays;
import java.util.Comparator;
import java.util.List;/*** 活动区间选择 - 贪心算法* 无重叠区间本质就是活动选择问题*/
public class ActivitySelectionProblem {/*** 要在应该会议室举办n个活动* - 每个活动有它们各自的起始和结束时间* - 找出时间上互不冲突的活动组合,能够充分利用会议室(举办的活动次数最多)** 例1* 0 1 2 3 4 5 6 7 8 9* |-------)* |-------)* |-------)* 例2* 0 1 2 3 4 5 6 7 8 9* |---)* |---)* |-----------------------)* |-------)* |---)* |---------------)** 几种贪心策略* 1. 优先选择持续时间最短的活动 (×)* 0 1 2 3 4 5 6 7 8 9* 1 |---------------) 选中* 2 |-------)* 3 |---------------) 选中** 2. 优先选择冲突最少的活动 (×)* 编号 0 1 2 3 4 5 6 7 8 9 冲突次数 实际解* 1 |-------) 3 选中* 2 |-------) 4* 3 |-------) 4* 4 |-------) 4* 5 |-------) 4 选中* 6 |-------) 2* 7 |-----------) 4 选中* 8 |-------) 4* 9 |-------) 4* 10 |-------) 4* 11 |-------) 3 选中** 3. 优先选择最先开始的活动 (×)* 0 1 2 3 4 5 6 7 8 9* 2 |---) 选中* 3 |---) 选中* 4 |---) 选中* 1 |-----------------------------------)** 4. 优先选择最先结束的活动 (√)*/// 活动类static class Activity {int index;int start;int finish;public Activity(int index, int start, int finish) {this.index = index;this.start = start;this.finish = finish;}public int getFinish() {return finish;}@Overridepublic String toString() {return "Activity(" + index + ")";}}public static void main(String[] args) {Activity[] activities = new Activity[] {new Activity(1, 2, 4),new Activity(0, 1, 3),new Activity(2, 3, 5)};Arrays.sort(activities, Comparator.comparingInt(Activity::getFinish));System.out.println(Arrays.toString(activities));select(activities, activities.length);}private static void select(Activity[] activities, int n) {List<Activity> result = new ArrayList<>();Activity prev = activities[0]; // 上次被选中的活动result.add(prev);for (int i = 1; i < n; i++) {Activity curr = activities[i]; // 正在处理的活动if(curr.start >= prev.finish) {result.add(curr);prev = curr;}}for (Activity activity : result) {System.out.println(activity);}}
}
2. 无重叠区间
给定一个区间的集合 intervals ,其中 intervals[i] = [starti, endi] 。返回 需要移除区间的最小数量,使剩余区间互不重叠 。
示例 1:
输入: intervals = [[1,2],[2,3],[3,4],[1,3]] 输出: 1 解释: 移除 [1,3] 后,剩下的区间没有重叠。
示例 2:
输入: intervals = [ [1,2], [1,2], [1,2] ] 输出: 2 解释: 你需要移除两个 [1,2] 来使剩下的区间没有重叠。
示例 3:
输入: intervals = [ [1,2], [2,3] ] 输出: 0 解释: 你不需要移除任何区间,因为它们已经是无重叠的了。
提示:
1 <= intervals.length <= 10^5intervals[i].length == 2-5 * 10^4 <= starti < endi <= 5 * 10^4
解法一:贪心算法
class Solution {/*** 找到不重叠的最多的活动数(count),即活动选择问题原始需求* 在此基础之上,活动总数 - count,就是题目要的排除数量* * @param intervals* @return*/public int eraseOverlapIntervals(int[][] intervals) {// 1. 将集合元素按照结束时间升序排序Arrays.sort(intervals, Comparator.comparingInt(a -> a[1]));int count = 1; // 默认选择第一个int i = 0; // 前一个for (int j = 0; j < intervals.length; j++) {// 后一个的开始时间 >= 前一个的结束时间if (intervals[j][0] >= intervals[i][1]) {i = j;count++;}}return intervals.length - count;}
}解法二:动态规划
class Solution {public int eraseOverlapIntervals(int[][] intervals) {if (intervals.length == 0)return 0;// 按结束时间排序Arrays.sort(intervals, (a, b) -> Integer.compare(a[1], b[1]));// 创建一个数组保存结束时间int n = intervals.length;int[] ends = new int[n];ends[0] = intervals[0][1];int count = 1; // 至少包括第一个区间for (int i = 1; i < n; i++) {// 检查重叠if (intervals[i][0] >= ends[count - 1]) {ends[count++] = intervals[i][1]; // 添加到不重叠区间}}return n - count; // 总数减去不重叠的数量}
}五、分数背包问题
package com.itheima.algorithms.greedy;import java.util.Arrays;
import java.util.Comparator;public class FractionalKnapsackProblem {/*1. n个物品都是液体,有重量和价值2. 现在你要取走 10升 的液体3. 每次可以不拿,全拿,或拿一部分,问最高价值是多少编号 重量(升) 价值0 4 24 水1 8 160 牛奶 选中 7/82 2 4000 五粮液 选中3 6 108 可乐4 1 4000 茅台 选中8140简化起见,给出的数据都是【价值/重量】能够整除,避免计算结果中出现小数,增加心算难度*/static class Item {int index;int weight;int value;public Item(int index, int weight, int value) {this.index = index;this.weight = weight;this.value = value;}// 单位价值public int unitValue() {return value / weight;}@Overridepublic String toString() {return "Item{" + index + "}";}}public static void main(String[] args) {Item[] items = new Item[] {new Item(0, 4, 24),new Item(1, 8, 160),new Item(2, 2, 4000),new Item(3, 6, 108),new Item(4, 1, 4000)};System.out.println(select(items, 10));}private static int select(Item[] items, int total) {// 1. 按单位价值降序排序Arrays.sort(items, Comparator.comparingInt(Item::unitValue).reversed());int max = 0;for (Item item : items) {if(total >= item.weight) {// 可以拿完total -= item.weight;max += item.value;} else {// 拿不完max += item.unitValue() * total;break;}}return max;}
}
六、0-1背包问题
对于此问题,贪心算法可能无法得到最优解
package com.itheima.algorithms.greedy;import java.util.Arrays;
import java.util.Comparator;public class KnapsackProblem {/*1. n个物品都是固体,有重量和价值2. 现在你要取走不超过 10克 的物品3. 每次可以 不拿 或 全拿,问最高价值是多少编号 重量(g) 价值(元)0 1 1_000_000 钻戒一枚1 4 1600 黄金一块2 8 2400 红宝石戒指一枚3 5 30 白银一块*/static class Item {int index;int weight;int value;public Item(int index, int weight, int value) {this.index = index;this.weight = weight;this.value = value;}public int unitValue() {return value / weight;}@Overridepublic String toString() {return "Item(" + index + ")";}}public static void main(String[] args) {Item[] items = new Item[]{new Item(0, 1, 1000000),new Item(1, 4, 1600),new Item(2, 8, 2400),new Item(3, 5, 30)};select(items, 10);}private static void select(Item[] items, int total) {Arrays.sort(items, Comparator.comparingInt(Item::unitValue).reversed());int max = 0; // 最大价值for (Item item : items) {System.out.println(item);if (total >= item.weight) { // 可以拿完total -= item.weight;max += item.value;}}System.out.println("最大价值是:" + max);}
}贪心算法的局限
| 问题名称 | 是否能用贪心得到最优解 | 替换解法 |
|---|---|---|
| Dijkstra(不存在负边) | ✔️ | |
| Dijkstra(存在负边) | ❌ | Bellman-Ford |
| Prim | ✔️ | |
| Kruskal | ✔️ | |
| 零钱兑换 | ❌ | 动态规划 |
| Huffman 树 | ✔️ | |
| 活动选择问题 | ✔️ | |
| 分数背包问题 | ✔️ | |
| 0-1 背包问题 | ❌ | 动态规划 |
相关文章:
数据结构与算法 - 贪心算法
一、贪心例子 贪心算法或贪婪算法的核心思想是: 1. 将寻找最优解的问题分为若干个步骤 2. 每一步骤都采用贪心原则,选取当前最优解 3. 因为没有考虑所有可能,局部最优的堆叠不一定让最终解最优 贪心算法是一种在每一步选择中都采取在当前…...

sed 一点点记忆
sed用法实例1(我用的最多,超级无敌的用法) 格式:/ # b 可以换成你想要的字符 sed -i //s/// 文本文件 sed -i ##s### 文本文件 sed -i bbsbbb 文本文件描述 通过正则表达式过滤你想要的行,替换该行的内容 1、s前面用…...

PyTorch--卷积神经网络(CNN)模型实现手写数字识别
文章目录 前言完整代码代码解析1. 导入必要的库2. 设备配置3. 超参数设置4. 加载MNIST数据集5. 创建数据加载器6. 定义卷积神经网络模型7. 实例化模型并移动到设备8. 定义损失函数和优化器9. 训练模型10. 测试模型11. 保存模型 常用函数解析小改进数据集部分可视化训练过程可视…...

前端程序员回忆工作第1年的记录总结(一)
更多详情:爱米的前端小笔记(csdn~xitujuejin~zhiHu~Baidu~小红shu)同步更新,等你来看!都是利用下班时间整理的,整理不易,大家多多👍💛➕🤔哦!你们…...

SQL Server端口设置完整详细步骤
大家好,我是程序员小羊! 前言: 前面是对SQLserver服务器一些介绍,不想了解的可直接点击目录跳入正题,谢谢!!! SQL Server 是由微软公司开发的关系数据库管理系统 (RDBMS)。它主要…...

【2024】k8s集群 图文详细 部署安装使用(两万字)
目录💻 一、前言二、下载依赖配置环境1、配置系统环境1.1、配置桥接网络1.1.1、parallels desktop配置1.1.2、VMware配置 1.2、配置root用户登陆 2、环境配置安装下载2.1、安装ipset和ipvsadm2.2、关闭SWAP分区 3、配置Containerd容器3.1、下载安装Containerd3.2、创…...

CSS 伪类和伪元素
也是选择器的一种,被称为伪类和伪元素。这一类选择器的数量众多,通常用于很明确的目的。 伪类 什么是伪类 伪类是选择器的一种,它用于选择处于特定状态的元素。 比如当它们是这一类型的第一个元素时(:first-child)&…...

某动一面——算法题
function restoreIpAddresses(s) {const result = [];function backtrack(start, path) {// 如果剩余的字符数不符合IP地址的要求,则剪枝if (s.length - start > (4 - path.length) * 3) return;if (s.length - start < (4 - path.length)) return;// 当找到了四段IP地址…...

kubernetes中共享内存和内存区别
计算机科学中的内存与共享内存 在计算机科学中,“内存”和“共享内存”是两个不同的概念,但它们之间有着密切的关系。为了更好地理解这两个概念及其相互关系,我们可以分别解释一下: 内存 (Memory) 内存通常指的是计算机系统的主…...

JavaWeb04-MyBatis与Spring结合
目录 前言 一、MyBatis入门(MyBatis官网) 1.1 创建mybatis项目(使用spring项目整合式方法) 1.2 JDBC 1.3 数据库连接池 1.4 实用工具:Lombok 二、MyBatis基础操作 2.1 准备工作 2.2 导入项目并实现操作 2.3 具…...
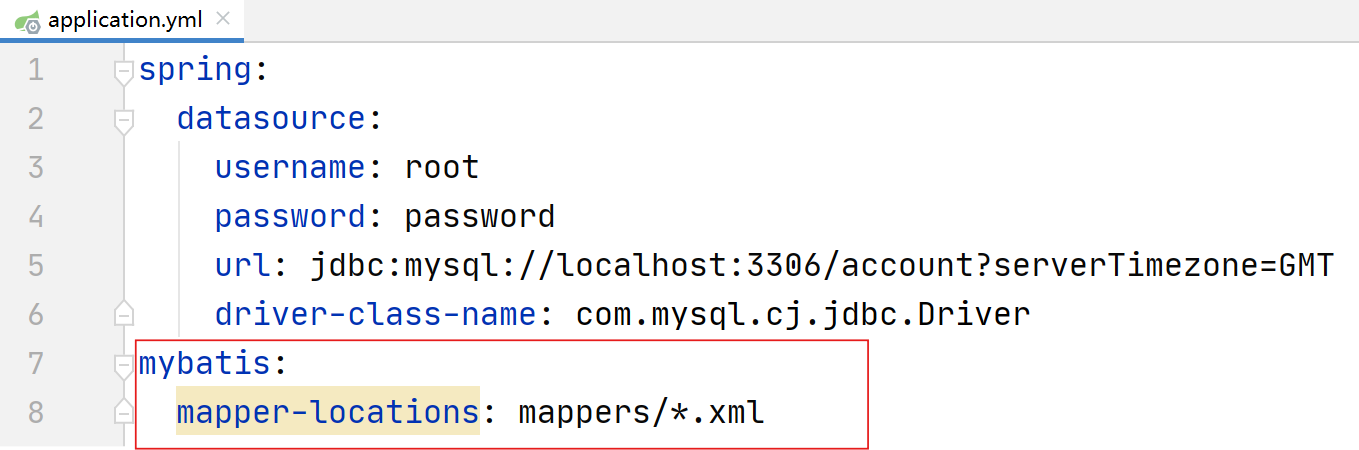
Mybatis-springBoot
MyBatis 是一个流行的 Java 持久层框架,它简化了与关系型数据库的交互。通过将 SQL 语句与 Java 代码进行映射,MyBatis 提供了一种方便、灵活的方式来执行数据库操作。它支持动态SQL、缓存机制和插件扩展,使得开发人员能够更高效地编写和管理…...

【中国数据库前世今生】数据存储管理的起源与现代数据库发展启蒙
记录开启本篇的目的: 作为1名练习时长2年半的DBA,工作大部分时间都在和数据库打交道,包括Oracle,Mysql,Postgresql,Opengauss等国内外数据库。但是对数据库的发展史却知之甚少。 正好腾讯云开发者社区正在热播:【纪录片】中国数据库前世今生,借此机会了解…...

拉卡拉上半年营收29.82亿元 外卡、数字化服务提升业绩增长空间
8月9日晚,拉卡拉(300773.SZ)发布2024年半年业绩报告。在国内经济延续恢复向好态势、国内消费市场规模持续增长的背景下,拉卡拉积极推进“推广数字支付、共享数字科技、兑现数据价值”的经营战略,上半年公司实现营业收入29.82亿元,…...

数学建模——启发式算法(蚁群算法)
算法原理 蚁群算法来自于蚂蚁寻找食物过程中发现路径的行为。蚂蚁并没有视觉却可以寻找到食物,这得益于蚂蚁分泌的信息素,蚂蚁之间相互独立,彼此之间通过信息素进行交流, 从而实现群体行为。 蚁群算法的基本原理就是蚂蚁觅食的过程…...
详解)
【Pytorch实用教程】在做模型融合时非常关键的代码:nn.Identity()详解
文章目录 nn.Identity()基础介绍主要用途示例代码以ResNet为例介绍 self.resnet.fc = nn.Identity() 的作用1. **背景:ResNet 模型结构**2. **代码 `self.resnet.fc = nn.Identity()` 的作用**3. **为什么使用 `nn.Identity()`**4. **示例代码**nn.Identity()基础介绍 nn.Ide…...

【开源力荐】一款基于web的可视化视频剪辑工具
嗨, 大家好, 我是徐小夕. 之前一直在社区分享零代码&低代码的技术实践,也陆陆续续设计并开发了多款可视化搭建产品,比如: H5-Dooring(页面可视化搭建平台)V6.Dooring(可视化大屏搭建平台)橙…...

鸿萌数据恢复服务: 如何修复 SQL Server 数据库错误 829?
天津鸿萌科贸发展有限公司从事数据安全服务二十余年,致力于为各领域客户提供专业的数据恢复、数据备份、网络及终端数据安全等解决方案与服务。 同时,鸿萌是众多国际主流数据恢复软件(Stellar、UFS、R-Studio、ReclaiMe Pro 等)的授权代理商,…...

OpenCV图像处理——按最小外接矩形剪切图像
引言 在图像处理过程中,提取感兴趣区域(ROI)并在其上进行处理后,往往需要将处理后的结果映射回原图像。这一步通常涉及以下几个步骤: 找到最小外接矩形:使用 cv::boundingRect 或 cv::minAreaRect 提取感兴…...

《熬夜整理》保姆级系列教程-玩转Wireshark抓包神器教程(4)-再识Wireshark
1.简介 按照以前的讲解和分享路数,宏哥今天就应该从外观上来讲解WireShark的界面功能了。 2.软件界面 由上到下依次是标题栏、主菜单栏、主菜单工具栏、显示过滤文本框、打开区、最近捕获并保存的文件、捕获区、捕获过滤文本框、本机所有网络接口、学习区及用户指…...

调用yolov3模型进行目标检测
要调用已经训练好的YOLOv3模型对图片进行检测,需要完成以下几个步骤: 加载预训练模型:从预训练的权重文件中加载模型。准备输入图片:将图片转换为模型所需的格式。进行推理:使用模型对图片进行推理,得到检…...
)
Python实战:用最小二乘法预测房价走势(附完整代码)
Python实战:用最小二乘法预测房价走势(附完整代码) 房价预测一直是数据分析领域的热门话题。无论是房产投资者、开发商还是普通购房者,都希望能从历史数据中洞察未来趋势。本文将带你用Python实现一个完整的房价预测模型ÿ…...

OpenBMC系统服务开发避坑指南:如何正确配置systemd单元文件与日志输出
OpenBMC系统服务开发避坑指南:如何正确配置systemd单元文件与日志输出 在OpenBMC开发中,systemd服务配置是每个开发者必须掌握的技能。不同于常规Linux发行版,OpenBMC对systemd的使用有其特殊性,尤其是在日志输出、权限控制和自启…...

双馈永磁风电机组并网仿真短路故障模型:探索风电世界的奥秘
双馈永磁风电机组并网仿真短路故障模型,kw级别永磁同步机PMSG并网仿真模型,机端由6台1.5MW双馈风机构成9MW风电场,风电场容量可调,出口电压690v,经升压变压器及线路阻抗连接至120kv交流电网。 该模型还包括风速模块&am…...

all-MiniLM-L6-v2多场景实践:构建跨平台内容索引引擎
all-MiniLM-L6-v2多场景实践:构建跨平台内容索引引擎 1. 认识all-MiniLM-L6-v2:轻量高效的语义理解利器 all-MiniLM-L6-v2是一个专门为语义理解设计的轻量级模型,它能够将文本转换为具有语义含义的数字向量。简单来说,它就像是一…...

Ubuntu 22.04外接NVIDIA显卡驱动安装
我的NUC缺一个强大的图形处理硬件, 于是把之前吃灰的显卡坞翻了出来, 发挥点余热, 但是在此之前, 因为开源驱动 nouveau 驱动只能提供基础显示功能,无法调用GPU的加速能力。所以我还需要 彻底禁用nouveau驱动 nouveau是Ubuntu默认的开源驱动,必须禁用&am…...

SpringBoot 3.3 整合 AI 接口:5 分钟快速实现智能应用
为什么要做 SpringBoot 3.3 AI 整合? SpringBoot 3.3 作为最新稳定版,不仅强化了原生虚拟线程、AOT 编译等性能特性,还对 HTTP 客户端、配置体系做了轻量化优化。而当前 AI 应用的核心痛点之一就是快速落地——大多数开发者不需要从零搭建 …...

一条SQL拖垮系统!教你用Explain光速排查性能瓶颈
一条SQL拖垮系统!资深DBA教你用Explain光速排查性能瓶颈 在凌晨三点的生产环境中,报警群里突然弹出的“数据库CPU使用率达到99%”的消息足以让任何一位后端开发或DBA心惊肉跳。很多时候,罪魁祸首并非流量洪峰,而是一条不起眼的慢查…...

为什么你的浮点数计算总是不准?揭秘Float类型的7位有效数字陷阱
为什么你的浮点数计算总是不准?揭秘Float类型的7位有效数字陷阱 1. 浮点数精度问题的真实案例 想象一下这样的场景:你在开发一个电商平台的购物车功能,用户将三件单价为3.33元的商品加入购物车,系统显示总价为9.99元。但当用户使用…...

LP4069充电管理IC在蓝牙耳机中的实战应用:从原理图到引脚配置全解析
LP4069充电管理IC在蓝牙耳机中的实战应用:从原理图到引脚配置全解析 在蓝牙耳机设计中,电池充电管理是决定产品续航和用户体验的关键环节。LP4069作为一款专为便携设备优化的充电管理IC,凭借其紧凑封装、高效充电和多重保护机制,正…...
:为什么你的FD帧总在500kbps以上丢包?)
CAN FD协议栈调试失效全记录(附可复现源码+Wireshark自定义解码器):为什么你的FD帧总在500kbps以上丢包?
第一章:CAN FD协议栈调试失效全记录(附可复现源码Wireshark自定义解码器):为什么你的FD帧总在500kbps以上丢包?CAN FD在高速段(>500 kbps)频繁丢包,往往并非物理层故障࿰…...