PyTorch 之 基于经典网络架构训练图像分类模型
文章目录
- 一、 模块简单介绍
- 1. 数据预处理部分
- 2. 网络模块设置
- 3. 网络模型保存与测试
- 二、数据读取与预处理操作
- 1. 制作数据源
- 2. 读取标签对应的实际名字
- 3. 展示数据
- 三、模型构建与实现
- 1. 加载 models 中提供的模型,并且直接用训练的好权重当做初始化参数
- 2. 参考 pytorch 官网例子
- 3. 设置哪些层需要训练
- 4. 优化器设置
- 5. 训练模块
- 6. 测试模型效果
本文参加新星计划人工智能(Pytorch)赛道:https://bbs.csdn.net/topics/613989052

一、 模块简单介绍
- 我们可以进入 pytorch 的官方网站,对模型的基本架构和训练好的参数进行直接调用,具体链接如下 https://pytorch.org/。
1. 数据预处理部分
- (1) 数据增强通过 torchvision 中 transforms 模块的自带功能实现,比较实用。
- (2) 数据预处理通过 torchvision 中 transforms 也帮我们实现好了,直接调用即可。
- (3) DataLoader 模块可以直接读取 batch 数据。
2. 网络模块设置
- (1) 加载预训练模型,torchvision 中有很多经典网络架构,调用起来十分方便,并且可以用人家训练好的权重参数来继续训练,也就是所谓的迁移学习。
- (2) 需要注意的是别人训练好的任务跟咱们的可不是完全一样,需要把最后的 head 层改一改,一般也就是最后的全连接层,改成咱们自己的任务。
- (3) 训练时可以全部重头训练,也可以只训练最后咱们任务的层,因为前几层都是做特征提取的,本质任务目标是一致的。
3. 网络模型保存与测试
- (1) 模型保存的时候可以带有选择性,例如在验证集中如果当前效果好则保存。
- (2) 读取模型进行实际测试。

import os
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import torch
from torch import nn
import torch.optim as optim
import torchvision
#pip install torchvision
from torchvision import transforms, models, datasets
#https://pytorch.org/docs/stable/torchvision/index.html
import imageio
import time
import warnings
import random
import sys
import copy
import json
from PIL import Image
二、数据读取与预处理操作
- 在最开始,我们先进行训练集和测试集的数据读取。
data_dir = './flower_data/'
train_dir = data_dir + '/train'
valid_dir = data_dir + '/valid'
1. 制作数据源
- 由于整体数据集较少,因此,我们通过 data_transforms 进行数据增强,指定所有图像预处理操作,包括旋转,裁剪,水平翻转、垂直翻转等等。
- 需要注意的是,这里分为训练集和数据集两部分。
data_transforms = {'train': transforms.Compose([transforms.RandomRotation(45),#随机旋转,-45到45度之间随机选transforms.CenterCrop(224),#从中心开始裁剪transforms.RandomHorizontalFlip(p=0.5),#随机水平翻转 选择一个概率概率transforms.RandomVerticalFlip(p=0.5),#随机垂直翻转transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1),#参数1为亮度,参数2为对比度,参数3为饱和度,参数4为色相transforms.RandomGrayscale(p=0.025),#概率转换成灰度率,3通道就是R=G=Btransforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])#均值,标准差]),'valid': transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
}
- 在数据加强完后,我们将单次传递给程序用以训练的数据也就是样本的个数设置为 8。
- 在传入数据集的时候,第一个参数是我们原始数据的路径,第二个参数是我们的数据增强方法。
batch_size = 8
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in ['train', 'valid']}
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=batch_size, shuffle=True) for x in ['train', 'valid']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'valid']}
class_names = image_datasets['train'].classes
- 接下来,我们读取数据集的基本信息,包括训练集中的数据个数,存储路径等等信息,测试集也是相同的。
image_datasets
#{'train': Dataset ImageFolder
# Number of datapoints: 6552
# Root location: ./flower_data/train
# StandardTransform
# Transform: Compose(
# RandomRotation(degrees=(-45, 45), resample=False, expand=False)
# CenterCrop(size=(224, 224))
# RandomHorizontalFlip(p=0.5)
# RandomVerticalFlip(p=0.5)
# ColorJitter(brightness=[0.8, 1.2], contrast=[0.9, 1.1], saturation=[0.9, 1.1], #hue=[-0.1, 0.1])
# RandomGrayscale(p=0.025)
# ToTensor()
# Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
# ), 'valid': Dataset ImageFolder
# Number of datapoints: 818
# Root location: ./flower_data/valid
# StandardTransform
# Transform: Compose(
# Resize(size=256, interpolation=PIL.Image.BILINEAR)
# CenterCrop(size=(224, 224))
# ToTensor()
# Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
# )}
- 我们也可以打印 dataloaders 中的信息,包含训练集和测试集两个。
dataloaders
#{'train': <torch.utils.data.dataloader.DataLoader at 0x21c5388b2b0>,
# 'valid': <torch.utils.data.dataloader.DataLoader at 0x21c539a80b8>}
- 查看 dataset 中的数据数量,其中训练集包含 6552 个样本,测试集中包含 818 个样本。
dataset_sizes
#{'train': 6552, 'valid': 818}
2. 读取标签对应的实际名字
- 在我们的文件当中,包含一个 json 文件,这中间包含了基本的标签信息,每个数字对应一种花的种类,在此,我们对这些信息进行读取。
with open('cat_to_name.json', 'r') as f:cat_to_name = json.load(f)
cat_to_name

3. 展示数据
- 在展示数据时,需要注意 tensor 的数据需要转换成 numpy 的格式,而且还需要还原回标准化的结果。
- 由于现在的数据都是已经处理完成后的数据,因此,如果我们想要展示的话需要对这些数据进行还原。
def im_convert(tensor):""" 展示数据"""image = tensor.to("cpu").clone().detach()image = image.numpy().squeeze()image = image.transpose(1,2,0)image = image * np.array((0.229, 0.224, 0.225)) + np.array((0.485, 0.456, 0.406))image = image.clip(0, 1)
return image
- 在还原完成后,我们只需要对其中的数据进行读取即可,这里展示 8 个数据为例。
fig=plt.figure(figsize=(20, 12))
columns = 4
rows = 2
dataiter = iter(dataloaders['valid'])
inputs, classes = dataiter.next()
for idx in range (columns*rows):ax = fig.add_subplot(rows, columns, idx+1, xticks=[], yticks=[])ax.set_title(cat_to_name[str(int(class_names[classes[idx]]))])plt.imshow(im_convert(inputs[idx]))
plt.show()

三、模型构建与实现
1. 加载 models 中提供的模型,并且直接用训练的好权重当做初始化参数
- 第一次执行需要下载,可能会比较慢,大家不必担心。
model_name = 'resnet' #可选的比较多 ['resnet', 'alexnet', 'vgg', 'squeezenet', 'densenet', 'inception']
- 在下载完成后,通过设置 feature_extract 为 True 或 False,决定是否用人家训练好的特征来做,这里直接使用人家训练好的特征,也就是设置为 True。
feature_extract = True
- 之后,我们决定是否用 GPU 进行训练。
train_on_gpu = torch.cuda.is_available()
if not train_on_gpu:print('CUDA is not available. Training on CPU ...')
else:print('CUDA is available! Training on GPU ...')device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
#CUDA is available! Training on GPU ...
- 进行模型架构的打印。
def set_parameter_requires_grad(model, feature_extracting):if feature_extracting:for param in model.parameters():param.requires_grad = Falsemodel_ft = models.resnet152()
model_ft

2. 参考 pytorch 官网例子
- 选择合适的模型,不同模型的初始化方法稍微有点区别,具体的代码如下所示。
def initialize_model(model_name, num_classes, feature_extract, use_pretrained=True):model_ft = Noneinput_size = 0
if model_name == "resnet":""" Resnet152"""model_ft = models.resnet152(pretrained=use_pretrained)set_parameter_requires_grad(model_ft, feature_extract)num_ftrs = model_ft.fc.in_featuresmodel_ft.fc = nn.Sequential(nn.Linear(num_ftrs, 102),nn.LogSoftmax(dim=1))input_size = 224
elif model_name == "alexnet":""" Alexnet"""model_ft = models.alexnet(pretrained=use_pretrained)set_parameter_requires_grad(model_ft, feature_extract)num_ftrs = model_ft.classifier[6].in_featuresmodel_ft.classifier[6] = nn.Linear(num_ftrs,num_classes)input_size = 224
elif model_name == "vgg":""" VGG11_bn"""model_ft = models.vgg16(pretrained=use_pretrained)set_parameter_requires_grad(model_ft, feature_extract)num_ftrs = model_ft.classifier[6].in_featuresmodel_ft.classifier[6] = nn.Linear(num_ftrs,num_classes)input_size = 224
elif model_name == "squeezenet":""" Squeezenet"""model_ft = models.squeezenet1_0(pretrained=use_pretrained)set_parameter_requires_grad(model_ft, feature_extract)model_ft.classifier[1] = nn.Conv2d(512, num_classes, kernel_size=(1,1), stride=(1,1))model_ft.num_classes = num_classesinput_size = 224
elif model_name == "densenet":""" Densenet"""model_ft = models.densenet121(pretrained=use_pretrained)set_parameter_requires_grad(model_ft, feature_extract)num_ftrs = model_ft.classifier.in_featuresmodel_ft.classifier = nn.Linear(num_ftrs, num_classes)input_size = 224
elif model_name == "inception":""" Inception v3Be careful, expects (299,299) sized images and has auxiliary output"""model_ft = models.inception_v3(pretrained=use_pretrained)set_parameter_requires_grad(model_ft, feature_extract)# Handle the auxilary netnum_ftrs = model_ft.AuxLogits.fc.in_featuresmodel_ft.AuxLogits.fc = nn.Linear(num_ftrs, num_classes)# Handle the primary netnum_ftrs = model_ft.fc.in_featuresmodel_ft.fc = nn.Linear(num_ftrs,num_classes)input_size = 299
else:print("Invalid model name, exiting...")exit()
return model_ft, input_size
3. 设置哪些层需要训练
- 在关于哪些层需要训练,首先导入模型的名字,把最终的输出结果 102 导入进去,然后选择是否动那些层,是否使用人家的模型参数。
model_ft, input_size = initialize_model(model_name, 102, feature_extract, use_pretrained=True)
- 使用 GPU 进行计算。
model_ft = model_ft.to(device)
- 将我们训练完成后的模型保存到指定路径之下。
filename='checkpoint.pth'
- 是否训练所有层。
params_to_update = model_ft.parameters()
print("Params to learn:")
if feature_extract:params_to_update = []for name,param in model_ft.named_parameters():if param.requires_grad == True:params_to_update.append(param)print("\t",name)
else:for name,param in model_ft.named_parameters():if param.requires_grad == True:print("\t",name)
#Params to learn:
# fc.0.weight
# fc.0.bias
#model_ft

4. 优化器设置
- 进行学习率衰减。
optimizer_ft = optim.Adam(params_to_update, lr=1e-2)
scheduler = optim.lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)#学习率每7个epoch衰减成原来的1/10
#最后一层已经LogSoftmax()了,所以不能nn.CrossEntropyLoss()来计算了,nn.CrossEntropyLoss()相当于logSoftmax()和nn.NLLLoss()整合
criterion = nn.NLLLoss()
5. 训练模块
def train_model(model, dataloaders, criterion, optimizer, num_epochs=25, is_inception=False,filename=filename):since = time.time()best_acc = 0"""checkpoint = torch.load(filename)best_acc = checkpoint['best_acc']model.load_state_dict(checkpoint['state_dict'])optimizer.load_state_dict(checkpoint['optimizer'])model.class_to_idx = checkpoint['mapping']"""model.to(device)
val_acc_history = []train_acc_history = []train_losses = []valid_losses = []LRs = [optimizer.param_groups[0]['lr']]
best_model_wts = copy.deepcopy(model.state_dict())
for epoch in range(num_epochs):print('Epoch {}/{}'.format(epoch, num_epochs - 1))print('-' * 10)
# 训练和验证for phase in ['train', 'valid']:if phase == 'train':model.train() # 训练else:model.eval() # 验证
running_loss = 0.0running_corrects = 0
# 把数据都取个遍for inputs, labels in dataloaders[phase]:inputs = inputs.to(device)labels = labels.to(device)
# 清零optimizer.zero_grad()# 只有训练的时候计算和更新梯度with torch.set_grad_enabled(phase == 'train'):if is_inception and phase == 'train':outputs, aux_outputs = model(inputs)loss1 = criterion(outputs, labels)loss2 = criterion(aux_outputs, labels)loss = loss1 + 0.4*loss2else:#resnet执行的是这里outputs = model(inputs)loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
# 训练阶段更新权重if phase == 'train':loss.backward()optimizer.step()
# 计算损失running_loss += loss.item() * inputs.size(0)running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(dataloaders[phase].dataset)epoch_acc = running_corrects.double() / len(dataloaders[phase].dataset)time_elapsed = time.time() - sinceprint('Time elapsed {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))# 得到最好那次的模型if phase == 'valid' and epoch_acc > best_acc:best_acc = epoch_accbest_model_wts = copy.deepcopy(model.state_dict())state = {'state_dict': model.state_dict(),'best_acc': best_acc,'optimizer' : optimizer.state_dict(),}torch.save(state, filename)if phase == 'valid':val_acc_history.append(epoch_acc)valid_losses.append(epoch_loss)scheduler.step(epoch_loss)if phase == 'train':train_acc_history.append(epoch_acc)train_losses.append(epoch_loss)print('Optimizer learning rate : {:.7f}'.format(optimizer.param_groups[0]['lr']))LRs.append(optimizer.param_groups[0]['lr'])print()
time_elapsed = time.time() - sinceprint('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))print('Best val Acc: {:4f}'.format(best_acc))
# 训练完后用最好的一次当做模型最终的结果model.load_state_dict(best_model_wts)return model, val_acc_history, train_acc_history, valid_losses, train_losses, LRs model_ft, val_acc_history, train_acc_history, valid_losses, train_losses, LRs = train_model(model_ft, dataloaders, criterion, optimizer_ft, num_epochs=20, is_inception=(model_name=="inception"))

- 再次继续训练所有层。
for param in model_ft.parameters():param.requires_grad = True
#再继续训练所有的参数,学习率调小一点
optimizer = optim.Adam(params_to_update, lr=1e-4)
scheduler = optim.lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
#损失函数
criterion = nn.NLLLoss()#Load the checkpoint
checkpoint = torch.load(filename)
best_acc = checkpoint['best_acc']
model_ft.load_state_dict(checkpoint['state_dict'])
optimizer.load_state_dict(checkpoint['optimizer'])
#model_ft.class_to_idx = checkpoint['mapping']model_ft, val_acc_history, train_acc_history, valid_losses, train_losses, LRs = train_model(model_ft, dataloaders, criterion, optimizer, num_epochs=10, is_inception=(model_name=="inception"))

6. 测试模型效果
- 输入一张测试图像,看看网络的返回结果:
probs, classes = predict(image_path, model)
print(probs)
print(classes)
#[ 0.01558163 0.01541934 0.01452626 0.01443549 0.01407339]
#['70', '3', '45', '62', '55']
- 这里需要注意的是,预处理方法需相同。
- 然后,我们加载训练好的模型。
model_ft, input_size = initialize_model(model_name, 102, feature_extract, use_pretrained=True)
#GPU模式
model_ft = model_ft.to(device)
#保存文件的名字
filename='seriouscheckpoint.pth'
#加载模型
checkpoint = torch.load(filename)
best_acc = checkpoint['best_acc']
model_ft.load_state_dict(checkpoint['state_dict'])
- 测试数据处理方法需要跟训练时一直才可以。
- crop 操作的目的是保证输入的大小是一致的。
- 标准化操作也是必须的,用跟训练数据相同的 mean 和 std,但是需要注意一点训练数据是在 0-1 上进行标准化,所以测试数据也需要先归一化。
- PyTorch 中颜色通道是第一个维度,跟很多工具包都不一样,需要转换。
def process_image(image_path):# 读取测试数据img = Image.open(image_path)# Resize,thumbnail方法只能进行缩小,所以进行了判断if img.size[0] > img.size[1]:img.thumbnail((10000, 256))else:img.thumbnail((256, 10000))# Crop操作left_margin = (img.width-224)/2bottom_margin = (img.height-224)/2right_margin = left_margin + 224top_margin = bottom_margin + 224img = img.crop((left_margin, bottom_margin, right_margin, top_margin))# 相同的预处理方法img = np.array(img)/255mean = np.array([0.485, 0.456, 0.406]) #provided meanstd = np.array([0.229, 0.224, 0.225]) #provided stdimg = (img - mean)/std# 注意颜色通道应该放在第一个位置img = img.transpose((2, 0, 1))return img
- 在数据测试完成后,我们需要对测试数据进行展示,也就是需要进行还原操作。
def imshow(image, ax=None, title=None):"""展示数据"""if ax is None:fig, ax = plt.subplots()# 颜色通道还原image = np.array(image).transpose((1, 2, 0))# 预处理还原mean = np.array([0.485, 0.456, 0.406])std = np.array([0.229, 0.224, 0.225])image = std * image + meanimage = np.clip(image, 0, 1)ax.imshow(image)ax.set_title(title)return ax
image_path = 'image_06621.jpg'
img = process_image(image_path)
imshow(img)

- 之后进行预测结果的展示。
fig=plt.figure(figsize=(20, 20))
columns =4
rows = 2
for idx in range (columns*rows):ax = fig.add_subplot(rows, columns, idx+1, xticks=[], yticks=[])plt.imshow(im_convert(images[idx]))ax.set_title("{} ({})".format(cat_to_name[str(preds[idx])], cat_to_name[str(labels[idx].item())]),color=("green" if cat_to_name[str(preds[idx])]==cat_to_name[str(labels[idx].item())] else "red"))
plt.show()

相关文章:
PyTorch 之 基于经典网络架构训练图像分类模型
文章目录一、 模块简单介绍1. 数据预处理部分2. 网络模块设置3. 网络模型保存与测试二、数据读取与预处理操作1. 制作数据源2. 读取标签对应的实际名字3. 展示数据三、模型构建与实现1. 加载 models 中提供的模型,并且直接用训练的好权重当做初始化参数2. 参考 pyto…...

Scrapy的callback进入不了回调方法
一、前言 有的时候,Scrapy的callback方法直接被略过了,不去执行其中的回调方法,可能排查好久都排查不出来,我来教大家集中解决方法。 yield Request(urlurl, callbackself.parse_detail, cb_kwargs{item: item})二、解决方法 1…...

第二十一天 数据库开发-MySQL
目录 数据库开发-MySQL 前言 1. MySQL概述 1.1 安装 1.2 数据模型 1.3 SQL介绍 1.4 项目开发流程 2. 数据库设计-DDL 2.1 数据库操作 2.2 图形化工具 2.3 表操作 3. 数据库操作-DML 3.1 增加(insert) 3.2 修改(update) 3.3 删除(delete) 数据库开发-MySQL 前言 …...

蓝桥杯每日一真题—— [蓝桥杯 2021 省 AB2] 完全平方数(数论,质因数分解)
文章目录[蓝桥杯 2021 省 AB2] 完全平方数题目描述输入格式输出格式样例 #1样例输入 #1样例输出 #1样例 #2样例输入 #2样例输出 #2提示思路:理论补充:完全平方数的一个性质:完全平方数的质因子的指数一定为偶数最终思路:小插曲&am…...
Linux编辑器-vim
一、vim简述1)vi/vim2)检查vim是否安装2)如何用vim打开文件3)vim的几种模式命令模式插入模式末行模式可视化模式二、vim的基本操作1)进入vim(命令行模式)2)[命令行模式]切换至[插入模式]3)[插入模式]切换至[命令行模式]4)[命令行模…...
5G将在五方面彻底改变制造业
想象一下这样一个未来,智能机器人通过在工厂车间重新配置自己,从多条生产线上组装产品。安全无人机处理着从监视入侵者到确认员工停车等繁琐的任务。自动驾驶汽车不仅可以在建筑物之间运输零部件,还可以在全国各地运输。工厂检查可以在千里之…...

http和https的区别?
http和https的区别?HTTPHTTPSHTTP与HTTPS区别HTTPS相比于HTTP协议的优点和缺点HTTP http是超文本传输协议 HTTP协议是基于传输层的TCP协议进行通信,通用无状态的协议。80端口 HTTPS https—安全的超文本传输协议 是以安全为目标的HTTP通道,…...
【Spring Cloud Alibaba】4.创建服务消费者
文章目录简介开始搭建创建项目修改POM文件添加启动类添加配置项添加Controller添加配置文件启动项目测试访问Nacos访问接口查看端点检查简介 接下来我们创建一个服务消费者,本操作先要完成之前的步骤,详情请参照【Spring Cloud Alibaba】Spring Cloud A…...
C语言——动态内存管理 malloc、calloc、realloc、free的使用
目录 一、为什么存在动态内存分配 二、动态内存函数的介绍 2.1malloc和free 2.2calloc 2.3realloc 三、常见的动态内存错误 3.1对NULL指针的解引用操作 3.2对动态开辟空间的越界访问 3.3对非动态开辟的内存使用free释放 3.4使用free释放一块动态开辟内存的一部分 3.5…...

技术分享——Java8新特性
技术分享——Java8新特性1.背景2. 新特性主要内容3. Lambda表达式4. 四大内置核心函数式接口4.1 Consumer<T>消费型接口4.2 Supplier<T>供给型接口4.3 Function<T,R>函数型接口4.4 Predicate<T> 断定型接口5. Stream流操作5.1 什么是流以及流的类型5.2…...

vue基础知识大全
1,指令作用 以v-开头,由vue提供的attribute,为渲染DOM应用提供特殊的响应式行为,也即是在表达式的值发生变化的时候响应式的更新DOM。其内容为可以被求值的js代码,可以写在return后面被返回的表达式。 指令的简写指令简…...
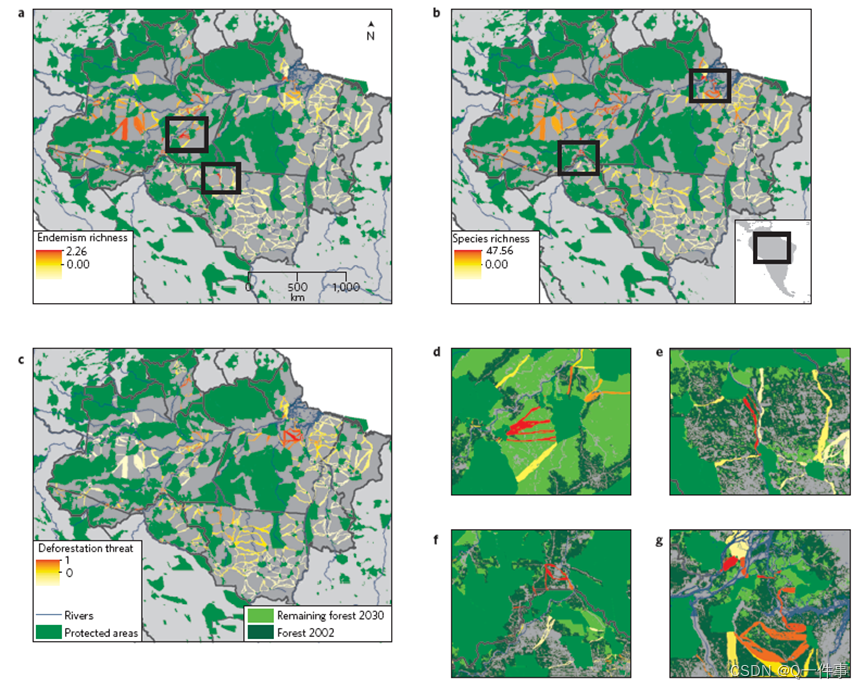
第2篇|文献研读|nature climate change|减缓气候变化和促进热带生物多样性的碳储量走廊
研究背景 从 2000 年到 2012 年,潮湿和干燥热带地区的森林总损失超过 90,000 平方公里 yr-1,这主要是由农业扩张驱动的。热带森林砍伐向大气中排放 0:95 Pg C yr-1 并导致广泛的生物多样性丧失。保护区的生物多样性取决于与保护区所在的更广泛景观的生态…...

从暴力递归到动态规划(2)小乖,你也在为转移方程而烦恼吗?
前引:继上篇我们讲到暴力递归的过程,这一篇blog我们将继续对从暴力递归到动态规划的实现过程,与上篇类似,我们依然采用题目的方式对其转化过程进行论述。上篇博客:https://blog.csdn.net/m0_65431718/article/details/…...

Leetcode.1638 统计只差一个字符的子串数目
题目链接 Leetcode.1638 统计只差一个字符的子串数目 Rating : 1745 题目描述 给你两个字符串 s和 t,请你找出 s中的非空子串的数目,这些子串满足替换 一个不同字符 以后,是 t串的子串。换言之,请你找到 s和 t串中 恰…...
KoTime:v2.3.9新增线程管理(线程统计、状态查询等)
功能概览 KoTime的开源版本已经迭代到了V2.3.9,目前功能如下: 实时监听方法,统计运行时长web展示方法调用链路,瓶颈可视化追踪追踪系统异常,精确定位到方法接口超时邮件通知,无需实时查看线上热更新&…...

直面风口,未来不仅是中文版ChatGPT,还有AGI大时代在等着我们
说到标题的AI2.0这个概念的研究早在2015年就研究起步了,其实大家早已知道,人工智能技术必然是未来科技发展战略中的重要一环,今天我们就从AI2.0入手,以GPT-4及文心一言的发布为切入角度,来谈一谈即将降临的AGI时代。 关…...
若依微服务(ruoyi-cloud)保姆版容器编排运行
一、简介 项目gitee地址:https://gitee.com/y_project/RuoYi-Cloud 由于该项目运行有很多坑,大家可以在git克隆拷贝到本地后,执行下面的命令使master版本回退到本篇博客的版本: git reset --hard 05ca78e82fb4e074760156359d09a…...
vue2图片预览插件
学习:vue插件开发实例-图片预览插件 vue2-pre-img-plugin的gitee代码 准备工作 准备图片与基础的样式 将iconfont下载的字体图标资源放在src/assets/iconfont目录下将准备预览的图片放到src/static/images目录下 PrevImg.vue 在plugins/PrevImg目录下ÿ…...

手写Promise源码的实现思路
Promise的使用: let promise new Promise((resolve, reject) > {resolve("OK");// reject("Error"); });console.log(promise);promise.then(value > {console.log("success"); }, error > {console.log("fail"…...

【数据结构】-关于树的概念和性质你了解多少??
作者:小树苗渴望变成参天大树 作者宣言:认真写好每一篇博客 作者gitee:gitee 如 果 你 喜 欢 作 者 的 文 章 ,就 给 作 者 点 点 关 注 吧! 树前言一、树概念及结构1.1树的概念1.2 树的相关概念1.3 树的表示1.4树在实际中的运用…...

Vue记事本应用实现教程
文章目录 1. 项目介绍2. 开发环境准备3. 设计应用界面4. 创建Vue实例和数据模型5. 实现记事本功能5.1 添加新记事项5.2 删除记事项5.3 清空所有记事 6. 添加样式7. 功能扩展:显示创建时间8. 功能扩展:记事项搜索9. 完整代码10. Vue知识点解析10.1 数据绑…...

从WWDC看苹果产品发展的规律
WWDC 是苹果公司一年一度面向全球开发者的盛会,其主题演讲展现了苹果在产品设计、技术路线、用户体验和生态系统构建上的核心理念与演进脉络。我们借助 ChatGPT Deep Research 工具,对过去十年 WWDC 主题演讲内容进行了系统化分析,形成了这份…...

MySQL 隔离级别:脏读、幻读及不可重复读的原理与示例
一、MySQL 隔离级别 MySQL 提供了四种隔离级别,用于控制事务之间的并发访问以及数据的可见性,不同隔离级别对脏读、幻读、不可重复读这几种并发数据问题有着不同的处理方式,具体如下: 隔离级别脏读不可重复读幻读性能特点及锁机制读未提交(READ UNCOMMITTED)允许出现允许…...

理解 MCP 工作流:使用 Ollama 和 LangChain 构建本地 MCP 客户端
🌟 什么是 MCP? 模型控制协议 (MCP) 是一种创新的协议,旨在无缝连接 AI 模型与应用程序。 MCP 是一个开源协议,它标准化了我们的 LLM 应用程序连接所需工具和数据源并与之协作的方式。 可以把它想象成你的 AI 模型 和想要使用它…...

Mac软件卸载指南,简单易懂!
刚和Adobe分手,它却总在Library里给你写"回忆录"?卸载的Final Cut Pro像电子幽灵般阴魂不散?总是会有残留文件,别慌!这份Mac软件卸载指南,将用最硬核的方式教你"数字分手术"࿰…...

leetcodeSQL解题:3564. 季节性销售分析
leetcodeSQL解题:3564. 季节性销售分析 题目: 表:sales ---------------------- | Column Name | Type | ---------------------- | sale_id | int | | product_id | int | | sale_date | date | | quantity | int | | price | decimal | -…...

Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决
Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决 问题背景 在一个基于 Spring Cloud Gateway WebFlux 构建的微服务项目中,新增了一个本地验证码接口 /code,使用函数式路由(RouterFunction)和 Hutool 的 Circle…...

Vite中定义@软链接
在webpack中可以直接通过符号表示src路径,但是vite中默认不可以。 如何实现: vite中提供了resolve.alias:通过别名在指向一个具体的路径 在vite.config.js中 import { join } from pathexport default defineConfig({plugins: [vue()],//…...

什么是VR全景技术
VR全景技术,全称为虚拟现实全景技术,是通过计算机图像模拟生成三维空间中的虚拟世界,使用户能够在该虚拟世界中进行全方位、无死角的观察和交互的技术。VR全景技术模拟人在真实空间中的视觉体验,结合图文、3D、音视频等多媒体元素…...

ubuntu22.04 安装docker 和docker-compose
首先你要确保没有docker环境或者使用命令删掉docker sudo apt-get remove docker docker-engine docker.io containerd runc安装docker 更新软件环境 sudo apt update sudo apt upgrade下载docker依赖和GPG 密钥 # 依赖 apt-get install ca-certificates curl gnupg lsb-rel…...