Kafka系统及其角色
Apache Kafka系统介绍
Apache Kafka 是由 LinkedIn 公司最初开发的一个高性能、分布式的消息传递系统。它被设计为一个可扩展、持久、分布式的流式处理平台,以满足 LinkedIn 在实时数据处理方面的需求 。Kafka 的诞生源于 LinkedIn 需要处理海量数据时现有消息队列系统(如 ActiveMQ 和 RabbitMQ)所遇到的性能瓶颈 。Kafka 的设计理念主要受到了分布式日志的启发,它采用了类似于分布式日志的存储方式,并提供了高吞吐量和容错性 。
在 2011 年,Kafka 项目得到开源并捐赠给 Apache 软件基金会,随后成为 Apache 的顶级项目 。Kafka 的架构师 Jay Kreps 选择了 Kafka 这个名字,因为他本人非常喜欢 Franz Kafka 并且认为这个名字听起来很酷,尽管这个名字与消息传递系统并无直接关联 。
Kafka 的设计目标包括使用推送和拉取模式实现生产者和消费者的解耦,提供数据持久化以支持多个消费者,能够随着数据流的增长进行横向扩展,并通过系统优化实现高吞吐量 。Kafka 支持多个生产者和消费者,可以进行 broker 的横向扩展,并通过副本集机制实现数据冗余以保障数据尽量不丢失 。
发布-订阅模式
发布-订阅模式(Publish-Subscribe Pattern)是一种消息传递范式,允许消息生产者(Producer)发送消息到一个主题,而无需知道哪些消费者(Consumer)会接收这些消息。同样,消费者订阅他们感兴趣的主题,只接收与这些主题相关的消息。

Kafka 通过主题(Topics)来组织消息,Producer将消息发布到这些主题而无需知道Consumer的身份,Consumer则订阅感兴趣的主题来接收消息,实现生产者和消费者之间的解耦。主题可以被分割为多个分区以提高并发处理能力,保持消息的有序性。
在 Kafka 的设计中,Consumer通常以组的形式存在,每个分区在Consumer组内只能被一个消费者实例消费,从而实现负载均衡。同时,Kafka会保证消息的持久化存储,支持高吞吐量和容错性,适合构建可扩展和高可靠性的实时数据流应用程序。
Kafka系统的角色与核心概念
在 Apache Kafka 系统中,"Producer"、"Consumer" 和 "Broker" 是三个核心概念,它们在 Kafka 的架构中扮演着重要的角色:
- Producer:负责产生消息并发送到 Kafka 集群。
- Consumer:订阅并主动请求,消费 Kafka 集群中的消息。
- Broker:作为 Kafka 集群的节点,负责存储消息并进行消息的分发。
Producer(生产者)
Producer 在 Apache Kafka 中的主要角色是向 Broker 发送消息。
Producer的关键特性包括:
-
消息发布:Producer创建消息并发布到特定的Topics,支持键值对(Key-Value)形式的消息,其中键可以用于分区。
-
分区策略:Producer根据Topic的分区策略,将消息分配到一个或多个Partition,以实现负载均衡和并行处理。
-
异步/同步发送:Producer支持异步消息发送,提高消息发送的性能和吞吐量,并通过回调函数处理消息确认。Producer也可以配置为同步发送消息,确保每条消息发送完成后再继续。
-
消息确认:Producer可以根据
acks配置来确定何时认为消息发送成功,提供不同级别的数据可靠性保证。
除此以外,Producer还负责了要发送给broker数据的压缩、批处理、重试机制、序列化与反序列化等工作。总之,Producer的设计使其能够高效、可靠地向Kafka集群发布消息,是实现实时数据流和事件驱动架构的关键组件。
Broker(代理)
Broker 是 Kafka 集群中的一个节点,负责维护数据,并处理来自生产者的数据推送和来自消费者的读取请求。
Broker 的关键特性:
-
消息存储:Broker以Topic为单位存储消息,每个Topic可以被分割为多个Partition,提高并发处理能力。
-
数据持久化:Broker将接收到的消息持久化到磁盘,确保数据的可靠性和系统的容错性。
-
分区管理:Broker管理Topic的分区,每个Partition在物理上对应一个日志文件,消息以追加的方式存储。
-
副本复制:Broker通过Replica机制为每个Partition创建副本,包括一个Leader和多个Follower,增强数据的冗余和可用性。
-
Leader选举:Broker负责在Leader失败时进行选举,确保Partition的高可用性。
-
负载均衡:Broker通过Partition的分散存储实现负载均衡,提高集群的整体吞吐量。
-
消息传递:Broker处理来自Producer的消息发送请求和来自Consumer的读取请求,实现消息的推送和拉取。
Broker的工作流程涵盖了消息的接收、存储、复制、以及根据Consumer的请求进行消息的检索和转发。Broker的设计使得Kafka能够高效地处理大量数据流,同时保持高性能和高可靠性。通过合理配置Broker,可以实现数据的稳定存储和快速访问,满足大规模分布式系统的实时消息交换需求。
Consumer(消费者)
Consumer扮演着接收和处理消息的角色。Consumer通过订阅一个或多个Topics来消费消息,并且通常属于一个Consumer Group(消费者组)。以下是Consumer的一些关键特性和工作流程:
Consumer的关键特性:
-
订阅Topics:Consumer订阅感兴趣的Topics以接收消息。一个Consumer可以订阅多个Topics,但一个Topic只能被同一个Consumer Group中的一个Consumer实例消费。
-
Consumer Group:为了实现可扩展性和容错性,Consumer通常以组的形式存在。每个Consumer Group中的Consumer共享同一个Group ID,并协调工作以消费订阅Topics的所有Partition。
-
消息消费:Consumer从Broker拉取(Pull)消息进行消费。与Producer的推送(Push)模式不同,Consumer主动请求消息。
-
Offset管理:Consumer需要维护自己读取数据的Offset(偏移量)。这是在Kafka中跟踪消息消费位置的机制。Consumer可以根据自己的需要提交或重置Offset。
-
消息顺序性:在同一个Partition内,消息是有序的。如果业务需要保证全局顺序性,可以通过设计确保所有消息发送到同一个Partition。
-
并发消费:一个Consumer Group可以有多个Consumer实例,分布在不同的进程或机器上,以实现并发消费。
-
消息处理:Consumer接收到消息后,会根据业务逻辑进行处理。处理完成后,可以选择提交Offset,表示已消费的消息可以被Kafka安全地删除。
Consumer的工作流程:
-
初始化:Consumer初始化并连接到Kafka集群,加入Consumer Group。
-
订阅Topics:Consumer订阅感兴趣的Topics,并等待接收消息。
-
拉取消息:Consumer定期从Broker拉取消息。这个过程可以是同步的,也可以是异步的。
-
处理消息:Consumer对拉取的消息进行业务逻辑处理。
-
提交Offset:处理完成后,Consumer可以选择提交Offset,告知Kafka已消费的消息可以被删除。
-
容错和恢复:如果Consumer实例失败,Consumer Group中的其他实例可以接管其Partition,继续消费消息。
-
消费者协调:Consumer Group中的Consumer通过Kafka的协调服务(如Zookeeper或Kafka自身的Raft协议)来管理Partition分配和消费者状态。
Consumer的配置选项:
- enable.auto.commit:是否自动提交Offset。
- auto.commit.interval:自动提交Offset的时间间隔。
- auto.offset.reset:如果没有找到初始Offset,Consumer应如何设置Offset。
- group.id:Consumer Group的ID。
Consumer的设计允许Kafka系统在处理大量数据时具有高吞吐量和良好的扩展性。通过合理配置和使用Consumer,可以实现高效的数据处理和系统稳定性。
ZooKeeper
ZooKeeper是Kafka生态系统中不可或缺的分布式协调服务。它提供了一种高效且可靠的机制,用于管理和协调分布式环境中的数据和状态。在Kafka中,ZooKeeper承担着多项关键职责:
-
集群管理:ZooKeeper监控Kafka集群中的所有Broker和副本的状态,确保Broker故障时能够重新平衡集群中的分区。
-
数据同步:通过ZooKeeper,Kafka能够确保所有副本之间的数据保持同步,当副本数据发生变化时,其他副本会收到通知并更新数据。
-
Leader选举:在Broker故障或其他需要重新选举领导者的场景中,ZooKeeper提供了领导者选举机制,保障了系统的可用性和稳定性。
-
客户端路由:ZooKeeper还负责客户端与Broker之间的路由,客户端可以通过ZooKeeper查询当前可用的Broker,并选择合适的Broker进行数据生产和消费。
ZooKeeper为Kafka提供了稳定可靠的运行环境,是Kafka实现其分布式特性和高可用性的关键依赖。在Kafka的架构中,ZooKeeper的使用减少了单点故障的风险,并提高了整个系统的弹性和可靠性。
Kafka系统的核心特性
性能优化与可扩展性
Apache Kafka 在设计上特别注重性能优化和系统的可扩展性。其分布式架构确保了消息处理能够跨越多个节点进行,显著提升了整体的处理能力。通过将数据持久化存储在磁盘上,Kafka 降低了成本,同时保持了高效的消息处理。此外,Kafka 特别优化了数据读写过程,实现了高吞吐量,即便在普通硬件上也能达到每秒数万条消息的传输速率。这些设计使得 Kafka 能够轻松应对大规模数据流的挑战,并通过在线水平扩展,增加更多的 Broker 节点来提升系统的处理能力。
数据一致性与可靠性
Kafka 采取了多种机制来确保数据的一致性和可靠性。消息分区允许 Kafka 将主题分割成多个分区,每个分区独立地存储和处理消息,提高了数据的完整性。数据复制通过在不同的 Broker 之间复制消息,提高了数据的容错性,确保了即使部分硬件故障,数据也不会丢失。消费者偏移量管理和消费者组的设计,使得 Kafka 能够在消费者发生故障时,重新分配消费任务,保证消息被可靠地消费。端到端的精确一次处理进一步确保了数据处理的准确性。
消息处理的灵活性与顺序性
Kafka 的发布-订阅模型提供了消息处理的灵活性,允许多个生产者和消费者通过主题进行通信,而无需直接耦合。消费者可以独立地扩展或修改处理逻辑。消息顺序性保证确保了在每个分区内部,消息将按照发送的顺序被消费,这对于需要保持事件顺序的应用程序至关重要。同时,消费者组支持消费者之间的消息消费任务共享,实现了负载均衡和提高了系统的吞吐量。
系统解耦与集成能力
Kafka 的设计允许生产者和消费者之间的解耦,它们通过主题进行通信,无需知道对方的存在,这提高了系统的灵活性和可维护性。作为一个轻量级的消息系统,Kafka 易于部署和维护,适合各种规模的应用。此外,Kafka 与大数据生态系统的集成使其成为日志聚合、实时监控数据、流处理等多种场景的理想选择。它可以与 Hadoop、Spark 等技术栈无缝集成,用于构建复杂的数据处理流程。
流处理能力
Kafka 不仅支持批量数据处理,还具备强大的流处理能力。通过引入 Kafka Streams 库,Kafka 可以处理实时数据流,为用户提供了从简单的消息传递到复杂的流处理应用的广泛支持。这使得 Kafka 不仅可以作为消息队列使用,还可以作为流处理平台,满足现代实时数据处理的需求。
相关文章:

Kafka系统及其角色
Apache Kafka系统介绍 Apache Kafka 是由 LinkedIn 公司最初开发的一个高性能、分布式的消息传递系统。它被设计为一个可扩展、持久、分布式的流式处理平台,以满足 LinkedIn 在实时数据处理方面的需求 。Kafka 的诞生源于 LinkedIn 需要处理海量数据时现有消息队列系…...

从零开始构建霸王餐返利APP的技术路线与挑战
从零开始构建霸王餐返利APP的技术路线与挑战 大家好,我是阿可,微赚淘客系统及省赚客APP创始人,是个冬天不穿秋裤,天冷也要风度的程序猿! 在电商领域,霸王餐返利APP作为一种新兴的商业模式,为用…...

安装Jmeter,配置jdk
注意点: java的jdk和jmeter的版本相匹配 ! ! ! 目前我使用的是1.8的的,jmeter使用的是5.6.3 JDK下载地址:https://www.oracle.com/cn/java/technologies/downloads 别管,直接傻瓜式安装点点就完了... 1.电脑-属性-高级系统设置-环境变量 2.系统变量-新建-变量…...

Aria2@RPC下载@Alist批量下载
文章目录 abstractAria2 RPC 概述RPC 的主要功能在线文档aria2的配置文件与启动选项使用配置文件设置aria2 rpc功能Aria2关于rpc的离线文档 Aria2 RPC 重要和常用选项1. enable-rpc2. rpc-listen-port3. rpc-secret4. rpc-listen-all5. rpc-allow-origin-all6. rpc-max-request…...

神经串联式语音转换:对基于串联的单次语音转换方法的再思考 论文笔记
NEURAL CONCATENATIVE SINGING VOICE CONVERSION: RETHINKING CONCATENATION-BASED APPROACH FOR ONE-SHOT SINGING VOICE CONVERSION 笔记 发现问题: 在any-to-any的转换中,由于内容和说话人音色的解耦不足,导致源说话人的音色部分仍保留在转换后的音频中&#x…...

机器学习(1)--数据可视化
文章目录 数据可视化作用可视化方法实现可视化 总结 数据可视化 数据可视化是将数据以图形、图像、动画等视觉形式表示出来,以便人们能够更直观地理解、分析和交流数据中的信息。 作用 一个整理的好好的数据,我们为什么要将其可视化呢?将它…...

docker部署Prometheus、Grafana
docker部署Prometheus 1、 拉取prometheus镜像 docler pull prom/prometheus 遇到问题:注意下科学上网。 2、将prometheus配置文件放在外面管理 prometheus.yml global:scrape_interval: 15sevaluation_interval: 15salerting:alertmanagers:- static_configs:-…...

5.mysql多表查询
MYSQL多表查询 MYSQL多表查询1.多表关系笛卡尔积 2. 多表查询概述2.1 内连接2.2 外连接2.3自连接联合查询union ,union all 2.4子查询2.4.1标量子查询2.4.2列子查询2.4.3行子查询2.4.4表子查询 MYSQL多表查询 create table student(id int auto_increment primary …...

【前端面试】挖掘做过的nextJS项目(上)
为什么使用nextJS 需求: 快速搭建宣传官网 1.适应pc、移动端 2.基本的路由跳转 3.页面渲染优化 4.宣传的图片、视频资源的加载优化 5.seo优化 全栈react web应用、 tailwind css原子工具的支持,方便书写响应式ui app router(React 服务器组件)支持服务器渲…...

【Unity-UGUI】UGUI知识汇总
目录 前言1 UGUI系统原理2 事件系统2.1 EventSystem2.2 InputModules2.3 Raycasters2.4 协作 3 UGUI系统的组件3.1 Image和RawImage3.2 Mask和RectMask2D 扩展UI穿透问题 前言 记录一些最近学到的有关UGUI的知识。 参考 知乎:6千字带你入门UGUI源码 书籍ÿ…...

JavaScript性能测试:策略、工具与实践
在Web开发中,性能测试是确保应用程序达到预期响应速度和处理能力的关键步骤。JavaScript作为构建交互式Web应用的核心语言,其性能直接影响用户体验。本文将详细介绍如何使用JavaScript进行性能测试,包括性能测试的基本概念、测试类型、工具、…...

嵌入式软件开发学习一:软件安装(保姆级教程)
资源下载: 江协科技提供: 资料下载 一、安装Keil5 MDK 1、双击.EXE文件,开始安装 2、 3、 4、此处尽量不要安装在C盘,安装路径选择纯英文,防止后续开发报错 5、 6、 7、弹出来的窗口全部关闭,进入下一步&a…...

SpringMVC学习中遇到的不懂注解记录
文章目录 Autowrite 和 ResourceQualifier 和 PrimaryPathVariableController、Service、Repository 和 Component Autowrite 和 Resource 我们先讲讲 Autowrite 注解 吧。 public class StudentService3 implements IStudentService {//Autowiredprivate IStudentDao studentD…...

Java面试题--分布式锁
分布式锁 你说一下什么是分布式锁 分布式锁是在分布式/集群环境中解决多线程并发造成的一系列数据安全问题.所用到的锁就是分布式锁,这种锁需要被多个应用共享才可以,通常使用Redis和zookeeper来实现。 分布式锁有哪些解决方案 常用的三种方案 基于…...

一文讲清数据平台与数据中台的关系与区别
前言 如果您是IT领域或者数据领域的从业者,一定对IT行业“创造”概念的能力深有体会,也一定经常被看起来名称相似,但又不同的各种概念绕的云里雾里,摸不着头脑。今天我们要讨论的是数据平台和数据中台两个概念,您是不…...

Android的Service和Thread的区别
Service 是一种可在后台执行长时间运行操作而不提供界面的应用组件。 Android Service是组件,既不能说它是单独的进程也不能说它是单独的线程。 如果非要从通俗的语言层面来理解的话,姑且将其理解为对象。这个Service对象本身作为应用程序的一部分与它的…...
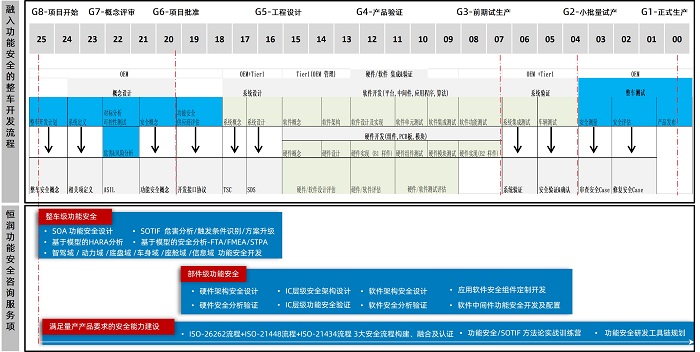
经纬恒润亮相第四届焉知汽车年会,功能安全赋能域控
8月初,第四届焉知汽车年会在上海举行。此次年会围绕当下智能电动汽车的热点和焦点,聚焦于智能汽车场景应用、车载通信、激光雷达、智能座舱、功能安全、电驱动系统等多个领域,汇聚了来自OEM、科技公司、零部件供应商、测试认证机构、政府院校…...

掌握JavaScript单元测试:最佳实践与技术指南
单元测试是软件开发过程中的关键环节,它帮助开发者确保代码的每个独立部分按预期工作。在JavaScript开发中,进行单元测试不仅可以提高代码质量,还可以加快开发速度,因为它们为代码更改提供了安全网。本文将详细介绍如何使用JavaSc…...

spring boot 古茶树管理系统---附源码19810
目 录 摘要 1 绪论 1.1 研究背景 1.2国内外研究现状 1.3论文结构与章节安排 2古茶树管理系统系统分析 2.1 可行性分析 2.1.1 技术可行性分析 2.1.2经济可行性分析 2.1.3操作可行性分析 2.2 系统流程分析 2.2.1 数据流程 3.3.2 业务流程 2.3 系统功能分析 2.3.1 …...

00067期 matlab中的asv文件
今天在编写代码的过程中,发现自动生成.m文件的同名文件.asv,特此发出疑问?下面是解答: 有时在存放m文件的文件夹中会出现*.asv asv 就是auto save的意思,*.asv文件的内容和相应的*.m文件内容一样,用记…...

Lombok 的 @Data 注解失效,未生成 getter/setter 方法引发的HTTP 406 错误
HTTP 状态码 406 (Not Acceptable) 和 500 (Internal Server Error) 是两类完全不同的错误,它们的含义、原因和解决方法都有显著区别。以下是详细对比: 1. HTTP 406 (Not Acceptable) 含义: 客户端请求的内容类型与服务器支持的内容类型不匹…...

从零实现富文本编辑器#5-编辑器选区模型的状态结构表达
先前我们总结了浏览器选区模型的交互策略,并且实现了基本的选区操作,还调研了自绘选区的实现。那么相对的,我们还需要设计编辑器的选区表达,也可以称为模型选区。编辑器中应用变更时的操作范围,就是以模型选区为基准来…...

在rocky linux 9.5上在线安装 docker
前面是指南,后面是日志 sudo dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo dnf install docker-ce docker-ce-cli containerd.io -y docker version sudo systemctl start docker sudo systemctl status docker …...

Python爬虫实战:研究feedparser库相关技术
1. 引言 1.1 研究背景与意义 在当今信息爆炸的时代,互联网上存在着海量的信息资源。RSS(Really Simple Syndication)作为一种标准化的信息聚合技术,被广泛用于网站内容的发布和订阅。通过 RSS,用户可以方便地获取网站更新的内容,而无需频繁访问各个网站。 然而,互联网…...

MVC 数据库
MVC 数据库 引言 在软件开发领域,Model-View-Controller(MVC)是一种流行的软件架构模式,它将应用程序分为三个核心组件:模型(Model)、视图(View)和控制器(Controller)。这种模式有助于提高代码的可维护性和可扩展性。本文将深入探讨MVC架构与数据库之间的关系,以…...
)
【RockeMQ】第2节|RocketMQ快速实战以及核⼼概念详解(二)
升级Dledger高可用集群 一、主从架构的不足与Dledger的定位 主从架构缺陷 数据备份依赖Slave节点,但无自动故障转移能力,Master宕机后需人工切换,期间消息可能无法读取。Slave仅存储数据,无法主动升级为Master响应请求ÿ…...

爬虫基础学习day2
# 爬虫设计领域 工商:企查查、天眼查短视频:抖音、快手、西瓜 ---> 飞瓜电商:京东、淘宝、聚美优品、亚马逊 ---> 分析店铺经营决策标题、排名航空:抓取所有航空公司价格 ---> 去哪儿自媒体:采集自媒体数据进…...

【Nginx】使用 Nginx+Lua 实现基于 IP 的访问频率限制
使用 NginxLua 实现基于 IP 的访问频率限制 在高并发场景下,限制某个 IP 的访问频率是非常重要的,可以有效防止恶意攻击或错误配置导致的服务宕机。以下是一个详细的实现方案,使用 Nginx 和 Lua 脚本结合 Redis 来实现基于 IP 的访问频率限制…...

Golang——6、指针和结构体
指针和结构体 1、指针1.1、指针地址和指针类型1.2、指针取值1.3、new和make 2、结构体2.1、type关键字的使用2.2、结构体的定义和初始化2.3、结构体方法和接收者2.4、给任意类型添加方法2.5、结构体的匿名字段2.6、嵌套结构体2.7、嵌套匿名结构体2.8、结构体的继承 3、结构体与…...
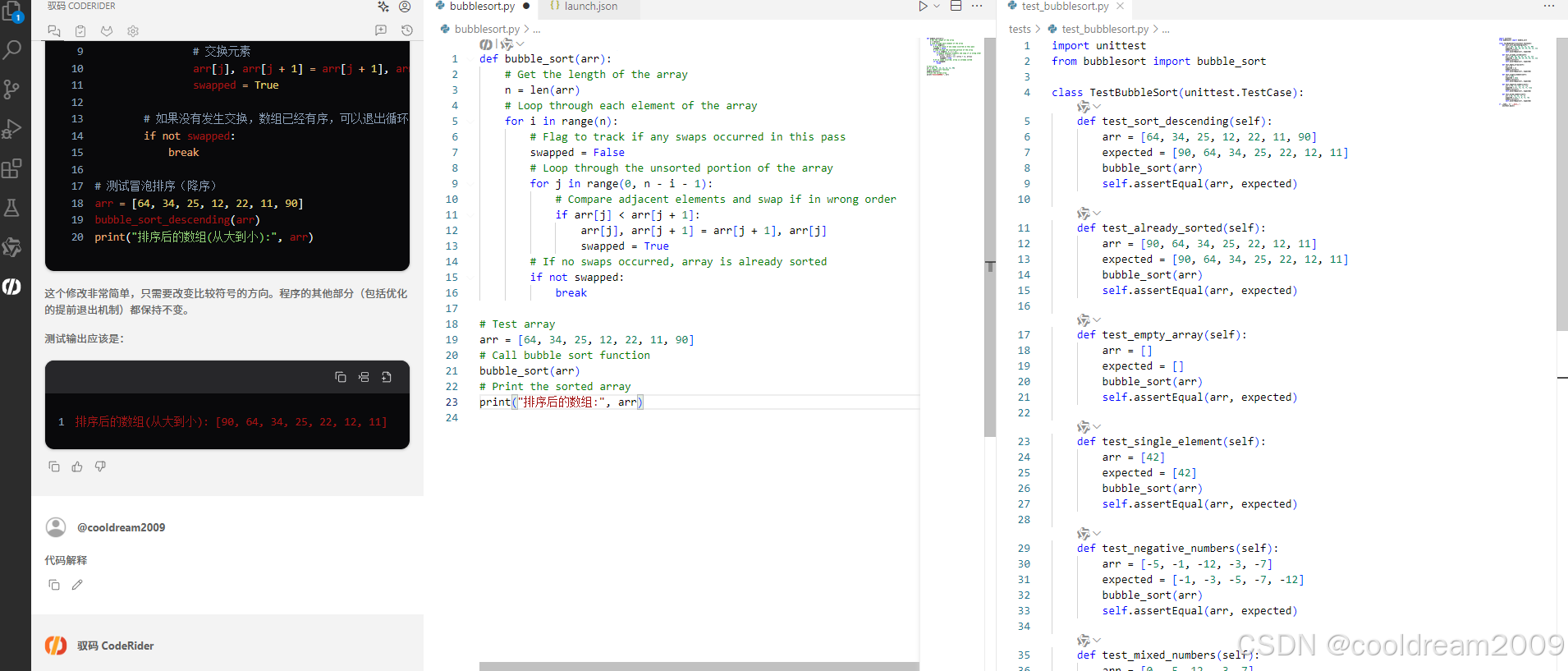
在 Visual Studio Code 中使用驭码 CodeRider 提升开发效率:以冒泡排序为例
目录 前言1 插件安装与配置1.1 安装驭码 CodeRider1.2 初始配置建议 2 示例代码:冒泡排序3 驭码 CodeRider 功能详解3.1 功能概览3.2 代码解释功能3.3 自动注释生成3.4 逻辑修改功能3.5 单元测试自动生成3.6 代码优化建议 4 驭码的实际应用建议5 常见问题与解决建议…...