机器学习深度学习中的搜索算法浅谈

机器学习&深度学习中的搜索算法浅谈
搜索算法是计算机科学中的核心算法,用于在各种数据结构(如数组、列表、树、图等)中查找特定元素或信息。这些算法不仅在理论上具有重要意义,还在实际应用中扮演着关键角色。本文将详细探讨搜索算法的基本概念、常见分类及经典算法(如A*算法及其变种),并介绍这些算法在不同场景中的应用。
1. 什么是搜索算法?
搜索算法用于在给定的数据结构中查找特定元素或满足特定条件的信息。无论是查找一个数字、搜索路径,还是在复杂图结构中定位某个节点,搜索算法都能帮助我们有效地找到目标。
举个栗子:想象你在图书馆寻找一本书。你可以从头到尾检查每个书架上的每本书,直到找到它。这类似于线性搜索。如果书架按照书名的字母顺序排列,你可以使用更高效的方法,从中间开始寻找,逐步缩小搜索范围,这类似于二分搜索。如果你在城市中寻找某个地方,你可能会从一个地点开始,按照既定的路线进行探索,这类似于深度优先搜索(DFS)。而如果你选择从市中心开始,逐步扩展到周围的区域,这就像广度优先搜索(BFS)。
2. 常见的搜索算法分类
搜索算法可以按照应用方式和目标数据结构进行分类。以下是几种常见的搜索算法:
2.1 线性搜索(Linear Search)
线性搜索是最基本的搜索算法。它逐一检查数据结构中的每个元素,直到找到目标元素或遍历完所有元素为止。
数学意义:
- 给定一个包含 n n n 个元素的数组 A A A,线性搜索目标值 x x x 的过程可以描述为:
for i = 0 to n − 1 do \text{for } i = 0 \text{ to } n-1 \text{ do} for i=0 to n−1 do
if A [ i ] = x then return i \quad \text{if } A[i] = x \text{ then return } i if A[i]=x then return i
else continue \quad \text{else } \text{continue} else continue
如果找到目标值 x x x,返回其索引,否则返回 -1 表示未找到。
时间复杂度:O(n),其中n是数据结构中的元素个数。
空间复杂度:O(1),不需要额外的存储空间。
举个栗子:假设你在一组无序的电话号码列表中寻找一个特定的号码,你只能从头到尾逐个查看,直到找到它,这就是线性搜索的原理。
代码示例:
def linear_search(arr, target):for i in range(len(arr)):if arr[i] == target:return ireturn -1
2.2 二分搜索(Binary Search)
二分搜索是一种高效的搜索算法,适用于有序数据结构。它通过每次将搜索范围一分为二,不断缩小查找区间,直到找到目标元素或确定目标不存在。
数学意义:
- 二分搜索在数组 A A A 中查找目标值 x x x 的过程如下:
low = 0 \text{low} = 0 low=0
high = n − 1 \text{high} = n-1 high=n−1
while low ≤ high do \text{while } \text{low} \leq \text{high} \text{ do} while low≤high do
mid = ⌊ low + high 2 ⌋ \quad \text{mid} = \left\lfloor \frac{\text{low} + \text{high}}{2} \right\rfloor mid=⌊2low+high⌋
if A [ mid ] = x then return mid \quad \text{if } A[\text{mid}] = x \text{ then return } \text{mid} if A[mid]=x then return mid
else if A [ mid ] < x then low = mid + 1 \quad \text{else if } A[\text{mid}] < x \text{ then low} = \text{mid} + 1 else if A[mid]<x then low=mid+1
else high = mid − 1 \quad \text{else high} = \text{mid} - 1 else high=mid−1
最终,如果找到目标值 x x x,返回其索引,否则返回 -1。
时间复杂度:O(log n)。
空间复杂度:O(1),只需常量级的额外空间。
举个栗子:如果你在一本按字母顺序排列的电话簿中查找一个人的名字,你可以从中间开始,根据名字的字母顺序决定向前或向后查找,这就是二分搜索的思想。
代码示例:
def binary_search(arr, target):low, high = 0, len(arr) - 1while low <= high:mid = (low + high) // 2if arr[mid] == target:return midelif arr[mid] < target:low = mid + 1else:high = mid - 1return -1
2.3 深度优先搜索(Depth-First Search, DFS)
深度优先搜索(DFS)是一种用于图或树结构的搜索算法。它从一个节点出发,沿着一条路径深入搜索,直到找到目标或到达叶子节点(无子节点的节点),然后回溯并尝试其他路径。
数学意义:
- DFS的递归过程可以定义为:
DFS ( v ) = Mark v as visited \text{DFS}(v) = \text{Mark } v \text{ as visited} DFS(v)=Mark v as visited
for each u adjacent to v do \text{for each } u \text{ adjacent to } v \text{ do} for each u adjacent to v do
if u is not visited then DFS ( u ) \quad \text{if } u \text{ is not visited then } \text{DFS}(u) if u is not visited then DFS(u)
时间复杂度:O(V + E),其中V是节点数,E是边数。
空间复杂度:O(V),由于递归调用栈的深度可能达到节点总数。
举个栗子:假设你在一个迷宫中行走,你总是沿着一个方向走到尽头,然后再回头寻找其他未走过的路径,这就类似于DFS的策略。
代码示例(使用递归):
def dfs(graph, start, visited=None):if visited is None:visited = set()visited.add(start)for next_node in graph[start] - visited:dfs(graph, next_node, visited)return visited
2.4 广度优先搜索(Breadth-First Search, BFS)
广度优先搜索(BFS)也是一种用于图或树结构的搜索算法。它从一个节点开始,逐层向外扩展搜索,直到找到目标元素。
数学意义:
- BFS的非递归过程通常使用队列实现:
BFS ( v ) = Initialize queue with v \text{BFS}(v) = \text{Initialize queue with } v BFS(v)=Initialize queue with v
while queue is not empty do \text{while queue is not empty do} while queue is not empty do
u = Dequeue \quad u = \text{Dequeue} u=Dequeue
for each w adjacent to u do \quad \text{for each } w \text{ adjacent to } u \text{ do} for each w adjacent to u do
if w is not visited then \quad \quad \text{if } w \text{ is not visited then} if w is not visited then
Mark w as visited and enqueue w \quad \quad \quad \text{Mark } w \text{ as visited and enqueue } w Mark w as visited and enqueue w
时间复杂度:O(V + E)。
空间复杂度:O(V),用于存储队列和访问标记。
举个栗子:如果你从城市的中心开始,逐步向外扩展
搜索,直到找到某个特定地点,这就类似于BFS的策略。
代码示例(使用队列):
from collections import dequedef bfs(graph, start):visited = set()queue = deque([start])while queue:vertex = queue.popleft()if vertex not in visited:visited.add(vertex)queue.extend(graph[vertex] - visited)return visited
3. A*算法:启发式搜索的典范
A*算法是一种广泛应用于路径规划的启发式搜索算法。它结合了广度优先搜索和深度优先搜索的优点,通过启发式函数引导搜索过程,以找到从起点到终点的最优路径。
3.1 A*算法的核心思想
A*算法的核心思想是在搜索过程中,同时考虑从起点到当前节点的实际代价 g ( n ) g(n) g(n) 和从当前节点到目标节点的预估代价 h ( n ) h(n) h(n)(即启发式函数)。总代价为:
f ( n ) = g ( n ) + h ( n ) f(n) = g(n) + h(n) f(n)=g(n)+h(n)
算法每次扩展代价最小的节点,直至找到目标节点。
3.2 启发式函数的选择
启发式函数 h ( n ) h(n) h(n) 的选择对A*算法的效率有着至关重要的影响。一个好的启发式函数应当是可接受的,即不会高估从当前节点到目标节点的实际代价,从而保证A*算法找到的是最优解。
常见的启发式函数:
- 曼哈顿距离(用于网格地图):假设只能水平或垂直移动,启发式函数为:
h ( n ) = ∣ x goal − x n ∣ + ∣ y goal − y n ∣ h(n) = |x_{\text{goal}} - x_n| + |y_{\text{goal}} - y_n| h(n)=∣xgoal−xn∣+∣ygoal−yn∣ - 欧几里得距离:假设可以任意方向移动,启发式函数为:
h ( n ) = ( x goal − x n ) 2 + ( y goal − y n ) 2 h(n) = \sqrt{(x_{\text{goal}} - x_n)^2 + (y_{\text{goal}} - y_n)^2} h(n)=(xgoal−xn)2+(ygoal−yn)2
3.3 A*算法的应用场景
举个栗子:假设你驾驶一辆汽车在城市中导航。A*算法就像GPS导航系统,它不仅考虑你目前的位置(已走过的路),还会根据你距离目的地的直线距离来估算最优路径,从而引导你绕开交通拥堵,以最短时间到达目的地。
- 路径规划:在机器人导航、游戏AI中寻找从起点到目标的最短路径。
- 地图搜索:如Google Maps或GPS导航系统中的路径规划。
代码示例:
from queue import PriorityQueuedef a_star(graph, start, goal, h):open_set = PriorityQueue()open_set.put((0, start))came_from = {}g_score = {node: float('inf') for node in graph}g_score[start] = 0while not open_set.empty():current = open_set.get()[1]if current == goal:path = []while current in came_from:path.append(current)current = came_from[current]return path[::-1]for neighbor, cost in graph[current]:tentative_g_score = g_score[current] + costif tentative_g_score < g_score[neighbor]:came_from[neighbor] = currentg_score[neighbor] = tentative_g_scoref_score = tentative_g_score + h(neighbor, goal)open_set.put((f_score, neighbor))return None
4. 其他经典的搜索算法
除了A*算法,还有其他几种经典的搜索算法在不同场景中有着广泛的应用。
4.1 Dijkstra算法
Dijkstra算法是A*算法的前身,主要用于寻找加权图中从单个起点到所有其他节点的最短路径。它类似于A*,但不使用启发式函数,仅基于实际代价 g ( n ) g(n) g(n) 进行搜索。
数学意义:
- 初始化:将起点的代价设为0,其他节点代价为无穷大,将起点放入优先队列。
- 循环:
- 从优先队列中选取代价最小的节点进行扩展。
- 更新其邻居节点的代价,如果邻居节点的代价减少,将其放入优先队列。
- 重复以上过程,直到所有节点都被处理。
时间复杂度:O(V^2) 或 O((V + E) \log V)(使用优先队列优化)。
举个栗子:假设你要找到从你家到城市中所有商店的最短路径,你从家出发,计算到达每个商店的最短距离,并不断更新其他商店的最短路径,这就是Dijkstra算法的工作方式。
应用场景:最短路径搜索,如网络路由、城市交通规划。
代码示例:
from queue import PriorityQueuedef dijkstra(graph, start):queue = PriorityQueue()queue.put((0, start))distances = {vertex: float('infinity') for vertex in graph}distances[start] = 0while not queue.empty():current_distance, current_vertex = queue.get()if current_distance > distances[current_vertex]:continuefor neighbor, weight in graph[current_vertex]:distance = current_distance + weightif distance < distances[neighbor]:distances[neighbor] = distancequeue.put((distance, neighbor))return distances
4.2 Bellman-Ford算法
Bellman-Ford算法用于寻找含负权边的图中的最短路径。它通过反复放松边来更新路径的代价。
数学意义:
- 初始化:将起点的代价设为0,其他节点代价为无穷大。
- 循环 ∣ V ∣ − 1 |V|-1 ∣V∣−1 次(其中 ∣ V ∣ |V| ∣V∣ 是节点数):
- 对图中的每条边 ( u , v ) (u, v) (u,v) 执行松弛操作:
if g ( v ) > g ( u ) + w ( u , v ) then g ( v ) = g ( u ) + w ( u , v ) \text{if } g(v) > g(u) + w(u, v) \text{ then } g(v) = g(u) + w(u, v) if g(v)>g(u)+w(u,v) then g(v)=g(u)+w(u,v)
- 对图中的每条边 ( u , v ) (u, v) (u,v) 执行松弛操作:
时间复杂度:O(VE)。
举个栗子:假设你在城市中寻找最便宜的公交路线,你要不断更新不同路线的花费,直到找到最便宜的方案,这就是Bellman-Ford算法的思路。
应用场景:处理图中可能存在负权边的情况,如金融领域的套利检测。
代码示例:
def bellman_ford(graph, start):distance = {node: float('inf') for node in graph}distance[start] = 0for _ in range(len(graph) - 1):for node in graph:for neighbor, weight in graph[node]:if distance[node] + weight < distance[neighbor]:distance[neighbor] = distance[node] + weight# Check for negative-weight cyclesfor node in graph:for neighbor, weight in graph[node]:if distance[node] + weight < distance[neighbor]:return "Graph contains a negative-weight cycle"return distance
4.3 Floyd-Warshall算法
Floyd-Warshall算法用于计算加权图中所有节点对之间的最短路径。它是动态规划的一种形式。
数学意义:
- 设定初始状态:
if i = j then d [ i ] [ j ] = 0 \text{if } i = j \text{ then } d[i][j] = 0 if i=j then d[i][j]=0
else if ( i , j ) is an edge then d [ i ] [ j ] = w ( i , j ) \text{else if } (i, j) \text{ is an edge then } d[i][j] = w(i, j) else if (i,j) is an edge then d[i][j]=w(i,j)
else d [ i ] [ j ] = ∞ \text{else } d[i][j] = \infty else d[i][j]=∞ - 对每个中间节点 k k k 执行更新操作:
d [ i ] [ j ] = min ( d [ i ] [ j ] , d [ i ] [ k ] + d [ k ] [ j ] ) d[i][j] = \min(d[i][j], d[i][k] + d[k][j]) d[i][j]=min(d[i][j],d[i][k]+d[k][j])
时间复杂度:O(V^3)。
举个栗子:假设你要计算城市中任意两个地点之间的最短路径,你可以通过逐一考虑每个中间点来优化路径,这就是Floyd-Warshall算法的工作方式。
应用场景:适用于计算全图的最短路径矩阵,如网络分析、交通网络优化。
代码示例:
def floyd_warshall(graph):distance = {i: {j: float('inf') for j in graph} for i in graph}for node in graph:distance[node][node] = 0for neighbor, weight in graph[node]:distance[node][neighbor] = weightfor k in graph:for i in graph:for j in graph:distance[i][j] = min(distance[i][j], distance[i][k] + distance[k][j])return distance5. 算法比较与选择
在实际应用中,选择合适的搜索算法至关重要。下表对比了不同算法的优缺点及适用场景。
| 算法 | 时间复杂度 | 空间复杂度 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|---|
| 线性搜索 | O(n) | O(1) | 简单易实现 | 效率低,适用于小规模数据 | 无序数据的小规模查找 |
| 二分搜索 | O(log n) | O(1) | 高效 | 仅适用于有序数据 | 有序数组或列表查找 |
| 深度优先搜索 | O(V + E) | O(V) | 遍历完整图,内存占用少 | 可能陷入死循环或路径过长 | 树或图的深度遍历 |
| 广度优先搜索 | O(V + E) | O(V) | 找到最短路径 | 内存占用大,效率较低 | 树或图的广度遍历 |
| Dijkstra算法 | O(V^2) 或 O((V + E) \log V) | O(V) | 找到最短路径 | 不能处理负权边 | 图中最短路径搜索 |
| Bellman-Ford算法 | O(VE) | O(V) | 处理负权边 | 效率较低 | 含负权边的图中最短路径搜索 |
| A*算法 | O(E) | O(V) | 效率高,找到最优路径 | 启发式函数选择影响效果 | 路径规划,游戏AI |
| Floyd-Warshall算法 | O(V^3) | O(V^2) | 计算全图所有节点对的最短路径 | 内存占用大,适用规模有限 | 全图最短路径分析 |
相关文章:
机器学习深度学习中的搜索算法浅谈
机器学习&深度学习中的搜索算法浅谈 搜索算法是计算机科学中的核心算法,用于在各种数据结构(如数组、列表、树、图等)中查找特定元素或信息。这些算法不仅在理论上具有重要意义,还在实际应用中扮演着关键角色。本文将详细探讨…...

基于IMX8M_plus+FPGA+AI监护仪解决方案
监护仪是一种以测量和控制病人生理参数,并可与已知设定值进行比较,如果出现超标可发出警报的装置或系统。 (1)监护仪主要采集测量人体生理参数,心电、血压、血氧、体温等需要采集处理大量的数据,系统需要多…...
)
仿RabbitMq实现简易消息队列正式篇(路由匹配篇)
TOC 目录 路由匹配模块 代码展示 路由匹配模块 决定了一条消息是否能够发布到指定的队列 在每个队列根交换机的绑定信息中,都有一个binding_key(在虚拟机篇有说到)这是队列发布的匹配规则 在每条要发布的消息中,都有一个rout…...

一套完整的NVR网络硬盘录像机解决方案和NVR程序源码介绍
随着网络技术的发展,视频数据存储的需求激增,促使硬盘录像机(DVR)逐渐演变为具备网络功能的网络视频录像机(NVR)。NVR,即网络视频录像机,负责网络视音频信号的接入、存储、转发、解码…...

2024年人工智能固态硬盘采购容量预计超过45 EB
根据TrendForce发布的最新市场报告,人工智能(AI)服务器客户在过去两个季度显著增加了对企业级固态硬盘(SSD)的订单。为了满足AI应用中不断增长的SSD需求,上游供应商正在加速工艺升级,并计划在20…...

Java的反射原理
反射允许程序在运行时检查或修改其类、接口、字段和方法的行为。反射主要通过java.lang.reflect包中的类和接口实现,它主要用于以下目的: 在运行时分析类的能力:通过反射,可以在运行时检查类的结构,比如它的方法、构造…...

vue.config.js 配置
vue.config.js 文件是 Vue CLI 项目中的全局配置文件,它允许你以 JavaScript 的形式来配置构建选项,而不是通过命令行参数或者 .vue-clirc 的 JSON 格式。 官方文档: https://cli.vuejs.org/zh/config/#全局-cli-配置 基础配置 publicPath 设置构建好的…...

C ++ 也可以搭建Web?高性能的 C++ Web 开发框架 CPPCMS + MySQL 实现快速入门案例
什么是CPPCMS? CppCMS 是一个高性能的 C Web 开发框架,专为构建快速、动态的网页应用而设计,特别适合高并发和低延迟的场景。其设计理念类似于 Python 的 Django 或 Ruby on Rails,但针对 C 提供了更细粒度的控制和更高效的性能。…...

Taos 常用命令工作笔记(二)
最近测试创建一个涛思的数据库和一堆表进行测试,通过json配置文件配置字段的类型、名称等,程序通过解析json文件的配置,动态创建数据库的表。 其中表字段为驼峰结构的规则命名,创建表也是成功的,插入的测试数据也是成功…...

idea安装二进制文本阅读插件
引言 在软件开发过程中,有时需要查看二进制文件的内容以调试或分析问题。虽然有许多专用工具可以处理这类任务,但直接在 IDE 内集成这些功能无疑更加方便高效。本文将介绍如何在 IntelliJ IDEA 2023中安装和配置一个名为 BinEd的插件,以及如…...

MySQL 常用 SQL 语句大全
1. 基本查询 查询所有记录和字段 SELECT * FROM table_name; 查询特定字段 SELECT column1, column2 FROM table_name; 查询并限制结果 SELECT column1, column2 FROM table_name LIMIT 10; 条件查询 SELECT column1, column2 FROM table_name WHERE condition; 模糊匹…...

[Spring] Spring事务与事务的传播
🌸个人主页:https://blog.csdn.net/2301_80050796?spm1000.2115.3001.5343 🏵️热门专栏: 🧊 Java基本语法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12615970.html?spm1001.2014.3001.5482 🍕 Collection与…...

Java 网络编程练习
InternetExercise1 package InternetExercise20240815;public class InternetExercise1 {public static void main(String[] args) {// 网络编程// 在网络通信协议下,不同计算机上面运行的程序,可以实现不同计算机上的数据传输// 网络编程三要素// 1.IP…...

中国科技统计年鉴,数据覆盖1991-2022年多年份
基本信息. 数据名称: 中国科技统计年鉴 数据格式: excel 数据时间: 1991-2022年 数据几何类型: xlsx 数据坐标系: WGS84 数据来源:国家统计局 数据预览: 数据可视化....

大模型的训练过程
大模型的训练是一个复杂的过程,涉及多个步骤和技术。下面我将概述大模型训练的主要流程,包括预训练、微调等关键阶段,并解释一些常见的技术和策略。 1. 数据准备 数据收集:收集大量多样化的数据,包括文本、图像、音频…...

4款ai在线改写工具,帮你轻松一键智能改写文章
在当今数字化内容创作的浪潮中,ai技术的应用为我们带来了极大的便利,尤其是在文章改写方面。以下将为大家详细分享四款出色的ai在线改写工具,从而帮助大家提升创作效率和质量。 ai在线改写工具一:智媒ai伪原创工具 它是一款备受好…...

Maven Mirror - 仓库镜像的介绍和配置
Maven Mirror(Maven镜像)是Maven构建工具中用于优化依赖下载速度和提高构建效率的一种机制。 在使用 Maven 构建应用程序时,Maven 默认会从 Maven 官方的中央仓库中下载依赖包。但是,在该仓库受到网络限制或访问速度过慢等问题时&…...

DevEcoStudio对Gitee进行变基与合并
当尝试将本地分支的更改推送到远程仓库,但是远程仓库中的该分支已经有了您本地分支中没有的提交时,会出现这个提示。 具体来说,这个提示意味着: 推送被拒绝:不能直接将更改推送到远程仓库,因为远程仓库中…...

2024 NVIDIA Summer Camp Day1:构建RAG多模态AI Agent
下载材料和课件等 课程相关资料下载链接: https://pan.baidu.com/s/15Y-gmsfeYCgKF-M3TJZVgg?pwdfafe 提取码: fafe 1.课件 链接:https://pan.baidu.com/s/15JTy9CqnesXSlPiwwrUmjA?pwd1111 提取码:1111 2.phi3量化大模型 链接:http…...

微服务之间的通信?
微服务之间的通信是微服务架构中的关键部分,它决定了服务之间如何进行数据交换和协同工作。微服务架构通过将大型应用拆分成多个小型、独立的服务,每个服务专注于完成特定的业务功能,从而提高了系统的可伸缩性、可维护性和可靠性。以下是微服…...

Ubuntu系统下交叉编译openssl
一、参考资料 OpenSSL&&libcurl库的交叉编译 - hesetone - 博客园 二、准备工作 1. 编译环境 宿主机:Ubuntu 20.04.6 LTSHost:ARM32位交叉编译器:arm-linux-gnueabihf-gcc-11.1.0 2. 设置交叉编译工具链 在交叉编译之前&#x…...

【OSG学习笔记】Day 18: 碰撞检测与物理交互
物理引擎(Physics Engine) 物理引擎 是一种通过计算机模拟物理规律(如力学、碰撞、重力、流体动力学等)的软件工具或库。 它的核心目标是在虚拟环境中逼真地模拟物体的运动和交互,广泛应用于 游戏开发、动画制作、虚…...

PHP和Node.js哪个更爽?
先说结论,rust完胜。 php:laravel,swoole,webman,最开始在苏宁的时候写了几年php,当时觉得php真的是世界上最好的语言,因为当初活在舒适圈里,不愿意跳出来,就好比当初活在…...

ESP32读取DHT11温湿度数据
芯片:ESP32 环境:Arduino 一、安装DHT11传感器库 红框的库,别安装错了 二、代码 注意,DATA口要连接在D15上 #include "DHT.h" // 包含DHT库#define DHTPIN 15 // 定义DHT11数据引脚连接到ESP32的GPIO15 #define D…...

Nuxt.js 中的路由配置详解
Nuxt.js 通过其内置的路由系统简化了应用的路由配置,使得开发者可以轻松地管理页面导航和 URL 结构。路由配置主要涉及页面组件的组织、动态路由的设置以及路由元信息的配置。 自动路由生成 Nuxt.js 会根据 pages 目录下的文件结构自动生成路由配置。每个文件都会对…...

HashMap中的put方法执行流程(流程图)
1 put操作整体流程 HashMap 的 put 操作是其最核心的功能之一。在 JDK 1.8 及以后版本中,其主要逻辑封装在 putVal 这个内部方法中。整个过程大致如下: 初始判断与哈希计算: 首先,putVal 方法会检查当前的 table(也就…...

Mysql中select查询语句的执行过程
目录 1、介绍 1.1、组件介绍 1.2、Sql执行顺序 2、执行流程 2.1. 连接与认证 2.2. 查询缓存 2.3. 语法解析(Parser) 2.4、执行sql 1. 预处理(Preprocessor) 2. 查询优化器(Optimizer) 3. 执行器…...
在 Spring Boot 中使用 JSP
jsp? 好多年没用了。重新整一下 还费了点时间,记录一下。 项目结构: pom: <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://ww…...
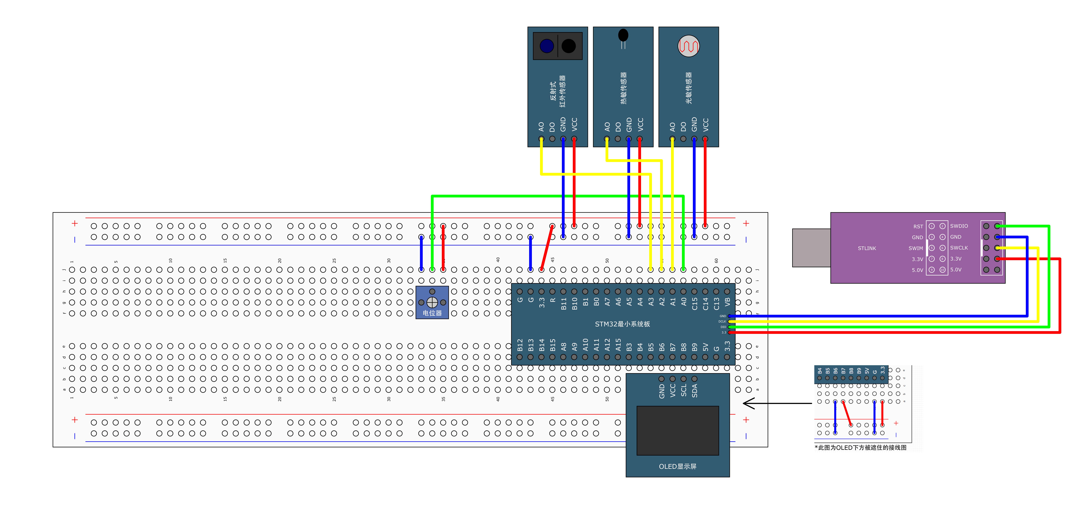
STM32标准库-ADC数模转换器
文章目录 一、ADC1.1简介1. 2逐次逼近型ADC1.3ADC框图1.4ADC基本结构1.4.1 信号 “上车点”:输入模块(GPIO、温度、V_REFINT)1.4.2 信号 “调度站”:多路开关1.4.3 信号 “加工厂”:ADC 转换器(规则组 注入…...
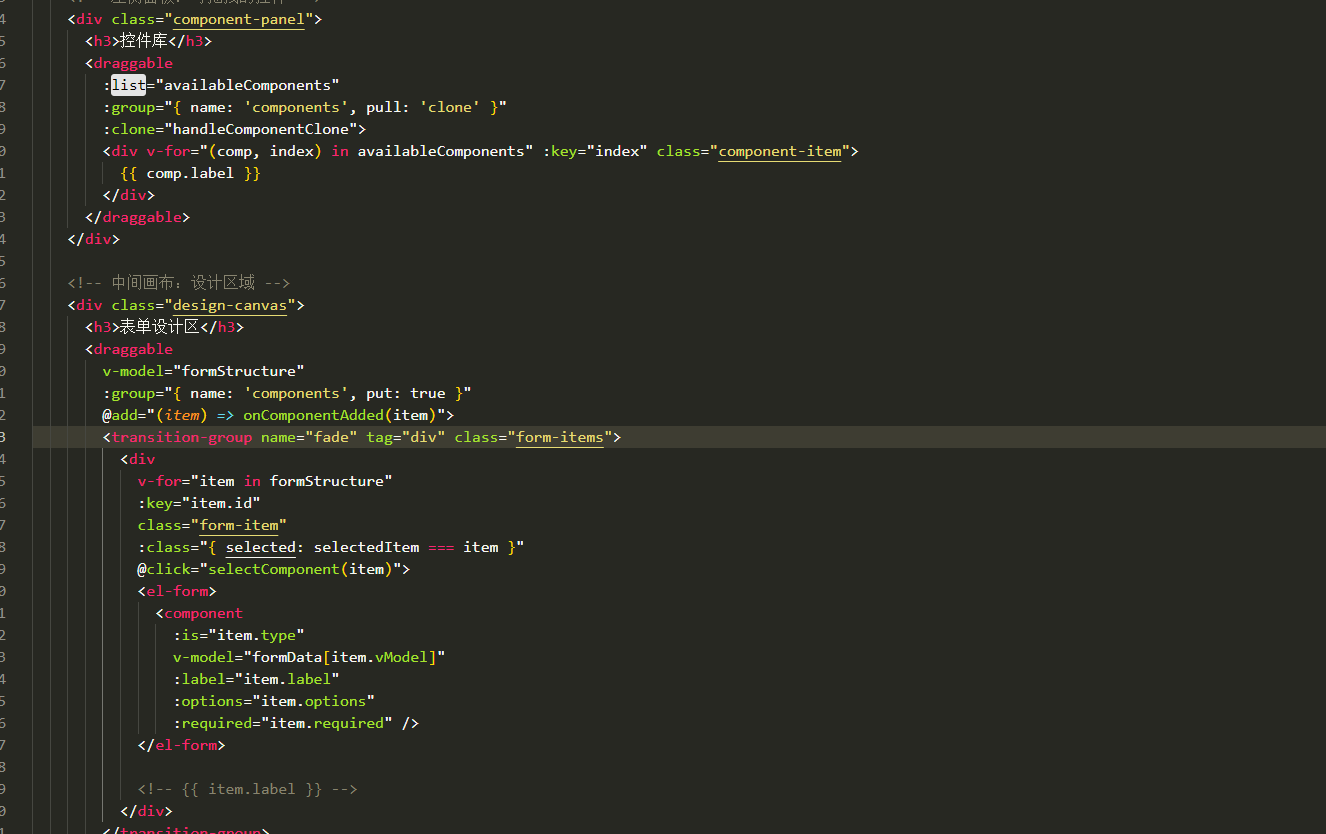
表单设计器拖拽对象时添加属性
背景:因为项目需要。自写设计器。遇到的坑在此记录 使用的拖拽组件时vuedraggable。下面放上局部示例截图。 坑1。draggable标签在拖拽时可以获取到被拖拽的对象属性定义 要使用 :clone, 而不是clone。我想应该是因为draggable标签比较特。另外在使用**:clone时要将…...