指针进阶(中)
提示: 上集内容小复习🥰🥰
int my_strlen(const char* str) {return 1;
}
int main() {//指针数组char* arr[10];//数组指针int arr2[5] = { 0 };int(*p)[5] = &arr2; //p是一个指向数组的指针变量//函数指针int (*pf)(const char*)=&my_strlen; //pf是一个指向函数的函数指针变量//int (*pf)(const char*) = my_strlen;//调用函数(*pf)("abcdef"); //函数指针调用my_strlen("abcdef"); //函数名调用pf("abcdef"); //函数指针不加*调用//函数指针数组:存放函数指针的数组--->在函数指针变量后加[]int (* pfArr[10])(const char*) = &my_strlen;}
文章目录
- 前言
- 七、指向函数指针数组的指针
- 区分函数指针,函数指针数组,指向函数指针数组的指针
- 八、回调函数
- 1.举例说明:
- **(1)简化思路图解**:
- **(2)代码**:
- **(3)代码逻辑图**:
- **(4)对比上篇博客中主函数的简化代码与本篇中的主函数简化代码有什么区别?**
- 2.演示qsort函数
- (1)复习冒泡排序
- (2)qsort函数的好处
- I.认识一下qsort函数的形式参数
- II.qsort可以排序任意类型的数据
- III.注意qsort参数中void*的用法
- IV.qsort函数的头文件
- V.测试qsort排序整型数据(qsort默认是升序排序)
- 代码详解图:
- VI.测试qsort排序结构型数据
- (1)按照年龄来排序
- (2)按照名字来排序
- 3.模拟实现qsort功能
- 用冒泡排序模拟一下`qsort怎么用
- (1)排序整型数据
- 拆分各部分讲解
- 完整代码展示
- 运行结果
- 注意点:
- (2)排序结构体类型数据
- 测试按照年龄排序代码展示
- 按年龄排序前:
- 按年龄排序后:
- 测试按照名字排序代码展示
- 按名字排序前:
- 按名字排序后:
- (3)用flag优化
- 总结
前言
七、指向函数指针数组的指针
含义:🐇
指向函数指针数组的指针是一个指针
指针指向一个数组 ,数组的元素都是函数指针
区分函数指针,函数指针数组,指向函数指针数组的指针
int Add(int x, int y) {return x + y;
}
int Sub(int x, int y) {return x - y;
}
int main() {int (*pf)(int, int) = Add; //函数指针变量int (*pfArr[4])(int, int) = { Add ,Sub}; //函数指针数组//pfArr是数组名,&pfArr是取出数组的地址,数组的地址应该放到数组指针里int (*(*ppfArr)[4])(int,int)= &pfArr; //ppfArr是一个指向函数指针数组的指针变量,把指针和指向的四个元素(*ppfArr[4])去掉,剩下的是它的类型return 0;
}
图解:

八、回调函数
含义:🐇
回调函数就是一个通过函数指针调用的函数,如果你把函数的指针(地址)作为参数传递给另一个函数,当这个指针被用来调用其所指向的函数时,我们就说这是回调函数,回调函数不是该函数的实现方式直接调用,而是在特定的事件或条件发生时由另外的一方调用的,用于对该事件或条件进行响应.
通俗来讲:🐻❄️把一个函数指针(用于接收A函数的地址值)作为形式参数传递给B函数,在B函数内部通过函数指针来调用A函数.A就被称为回调函数.
图解

1.举例说明:
在上篇博客中最后的计算机题目中,我们发现有很多代码其实是冗余的,如何简化呢?
(1)简化思路图解:
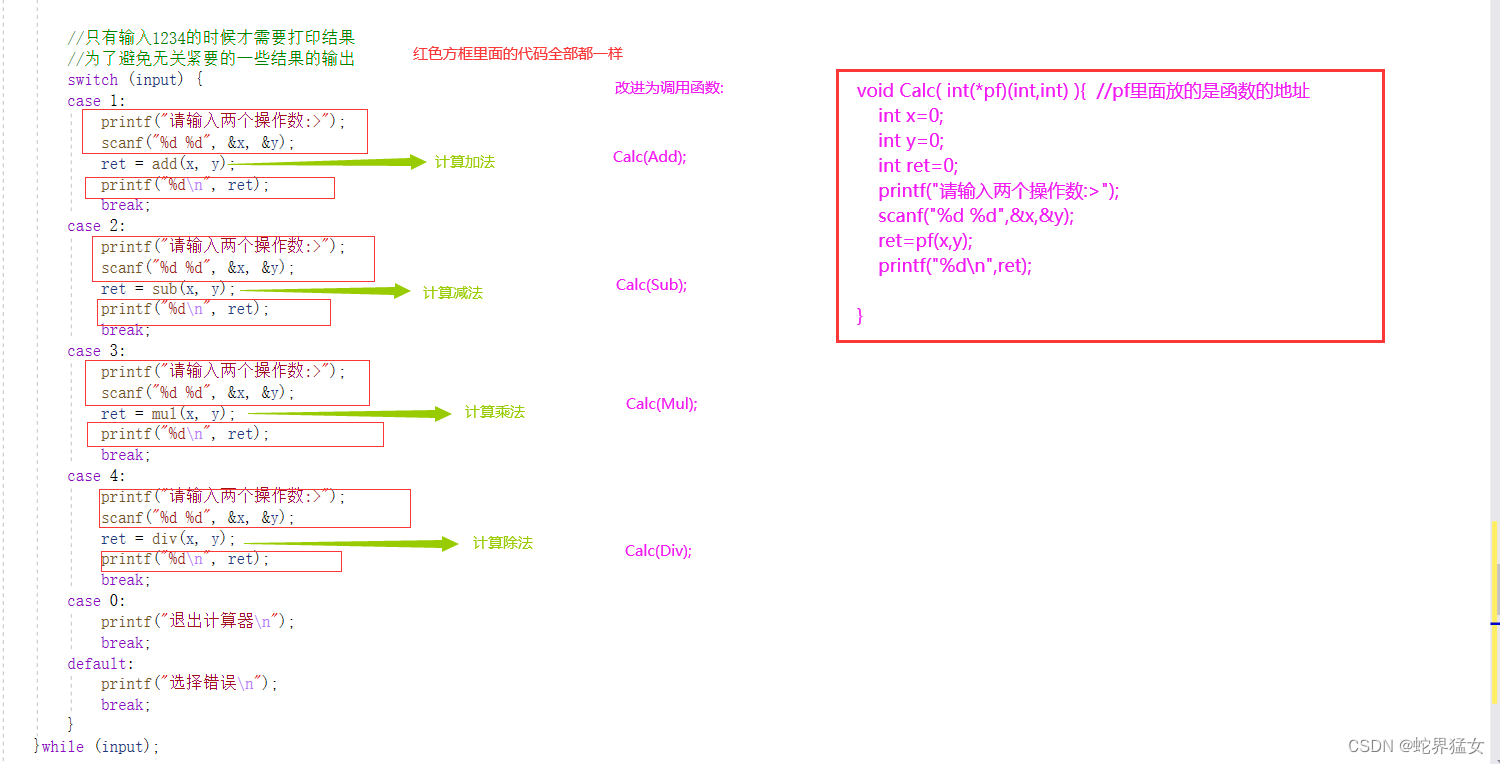
(2)代码:
void menu() {printf("***************************************\n");printf("******1.add 2.sub**********************\n");printf("******3.mul 4.div**********************\n");printf("******0.exit **********************\n");printf("***************************************\n");}
int Add(int x, int y) {return x + y;
}
int Sub(int x, int y) {return x - y;
}
int Mul(int x, int y) {return x * y;
}
int Div(int x, int y) {return x / y;
}void Calc(int (*pf)(int, int)) { //函数指针接收函数的地址int x = 0;int y = 0;int ret = 0;printf("请输入两个操作数:>");scanf("%d %d", &x, &y);ret = pf(x, y);printf("%d\n", ret);
}
int main() {int input = 0;do {menu();printf("请选择->");scanf("%d", &input);//只有输入1234的时候才需要打印结果//为了避免无关紧要的一些结果的输出switch (input) {case 1:Calc(Add);break;case 2:Calc(Sub);break;case 3:Calc(Mul);break;case 4:Calc(Div);break;case 0:printf("退出计算器\n");break;default:printf("选择错误\n");break;}} while (input);return 0;
}
(3)代码逻辑图:
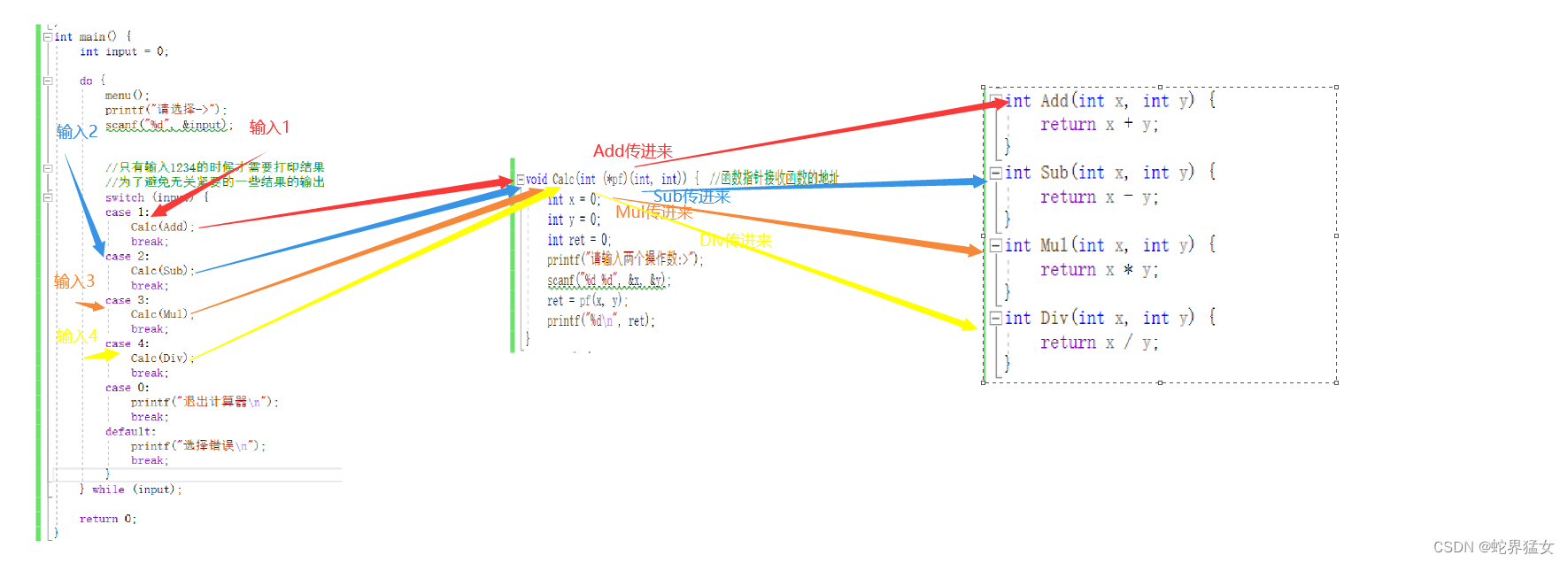
在这道题目中,没有直接调用加减乘除的函数,而是在特定的事件下去调用函数,用来响应这一事件.
(4)对比上篇博客中主函数的简化代码与本篇中的主函数简化代码有什么区别?
解决的问题不一样,没有哪个比哪个好的说法
上篇:当在计算机中不断增加运算的功能的时候,觉得swith…case语句中的case太多,用函数指针数组更好一些
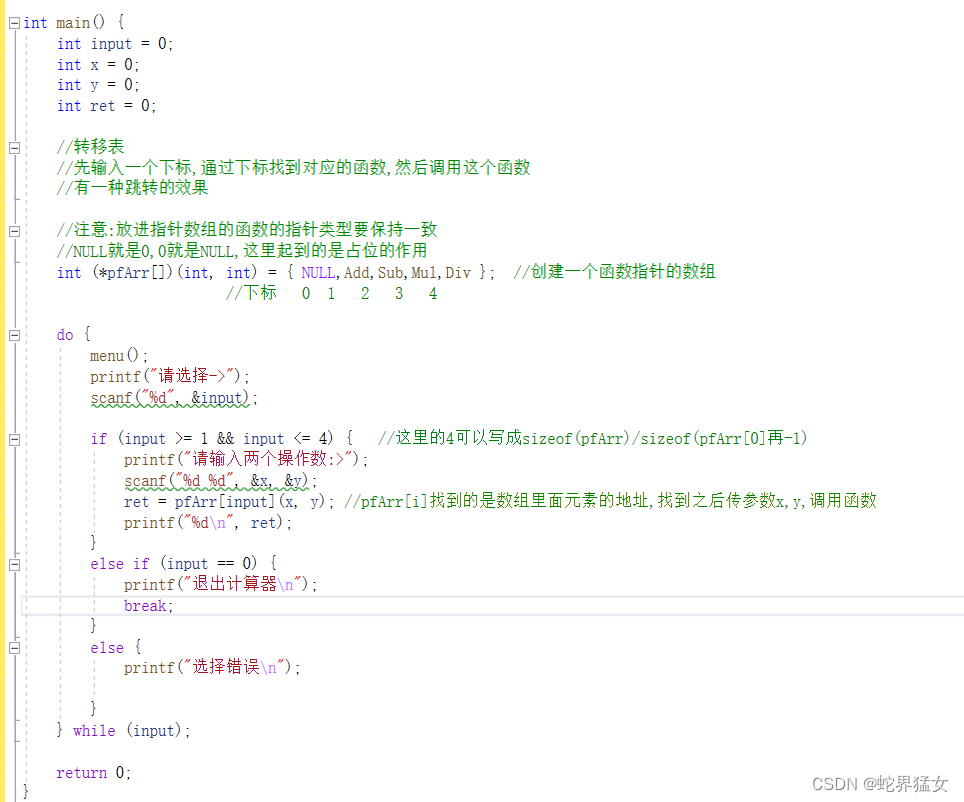
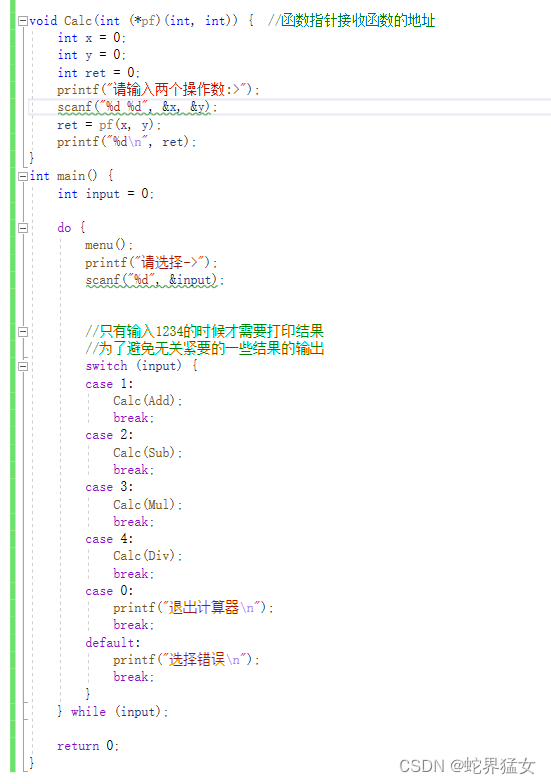
本篇:解决的问题是如果使用原来的代码有些代码是重复冗余的,原来的代码如下图所见:

本篇是为了解决代码的冗余,使用回调函数,当特定事件结果为不同值时调用函数,形参传入不同的函数地址.
2.演示qsort函数
qsort是一个库函数,用来排序的库函数
底层用的是快速排序的方法,不是冒泡排序
q:quick quicksort
为什么是快速排序的方法不是冒泡排序的方法呢?
接下来我们来体验一下冒泡排序有哪里不好的地方🥱🥱
(1)复习冒泡排序
冒泡排序的思想分析:🐇🐇
两两相邻的元素比较.
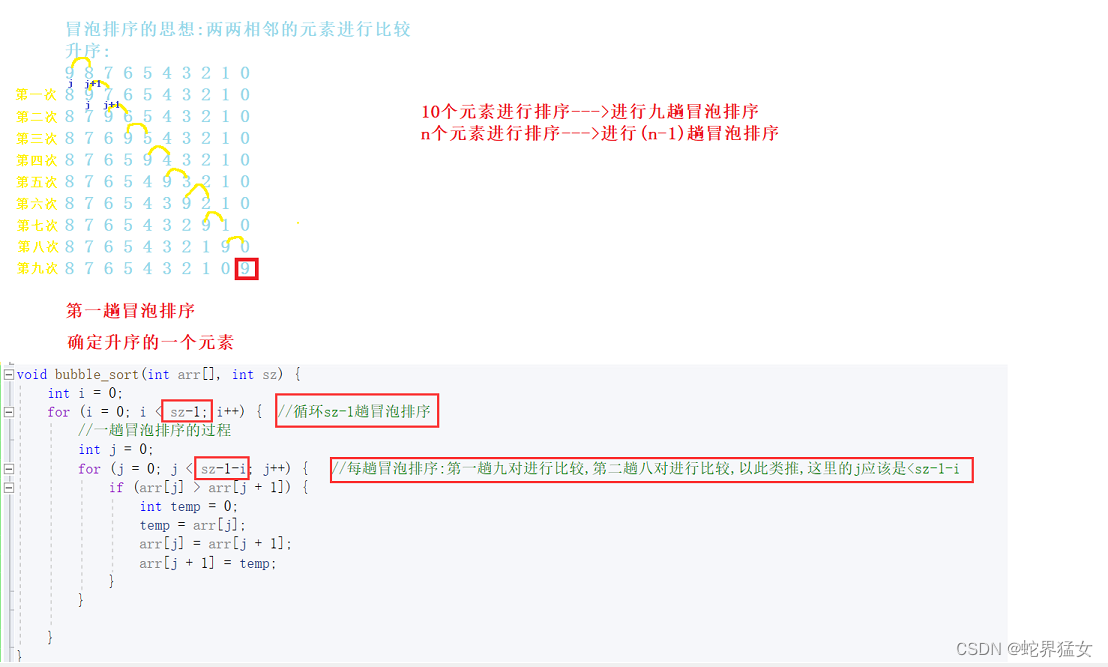
void bubble_sort(int arr[], int sz) {int i = 0;for (i = 0; i < sz-1; i++) { //循环sz-1趟冒泡排序//一趟冒泡排序的过程int j = 0;for (j = 0; j < sz-1-i; j++) { //每趟冒泡排序:第一趟九对进行比较,第二趟八对进行比较,以此类推,这里的j应该是<sz-1-iif (arr[j] > arr[j + 1]) {int temp = 0;temp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = temp;}}}
}
void print_arr(int arr[],int sz) {int i = 0;for (i = 0; i < sz; i++) {printf("%d ", arr[i]);}
}
int main() {int arr[] = { 9,8,7,6,5,4,3,2,1,0 };//排序//使用冒泡排序的方法//封装一个冒泡排序的方法(需要把数组和数组元素的个数传过去)int sz = sizeof(arr) / sizeof(arr[0]);bubble_sort(arr, sz);//打印print_arr(arr,sz);return 0;}

冒泡排序有哪里不好呢?🐇
:只能排固定类型的数据,不是想排什么类型的数据就排序什么类型的数据
因为函数void bubble_sort(int arr[], int sz)的形式参数固定写死的,未来想要排序一些浮点型数据,结构体类型的数据等等是不行的
(2)qsort函数的好处
qsort函数的好处:🤞
1.现成的
2.可以排序任意类型的数据
I.认识一下qsort函数的形式参数

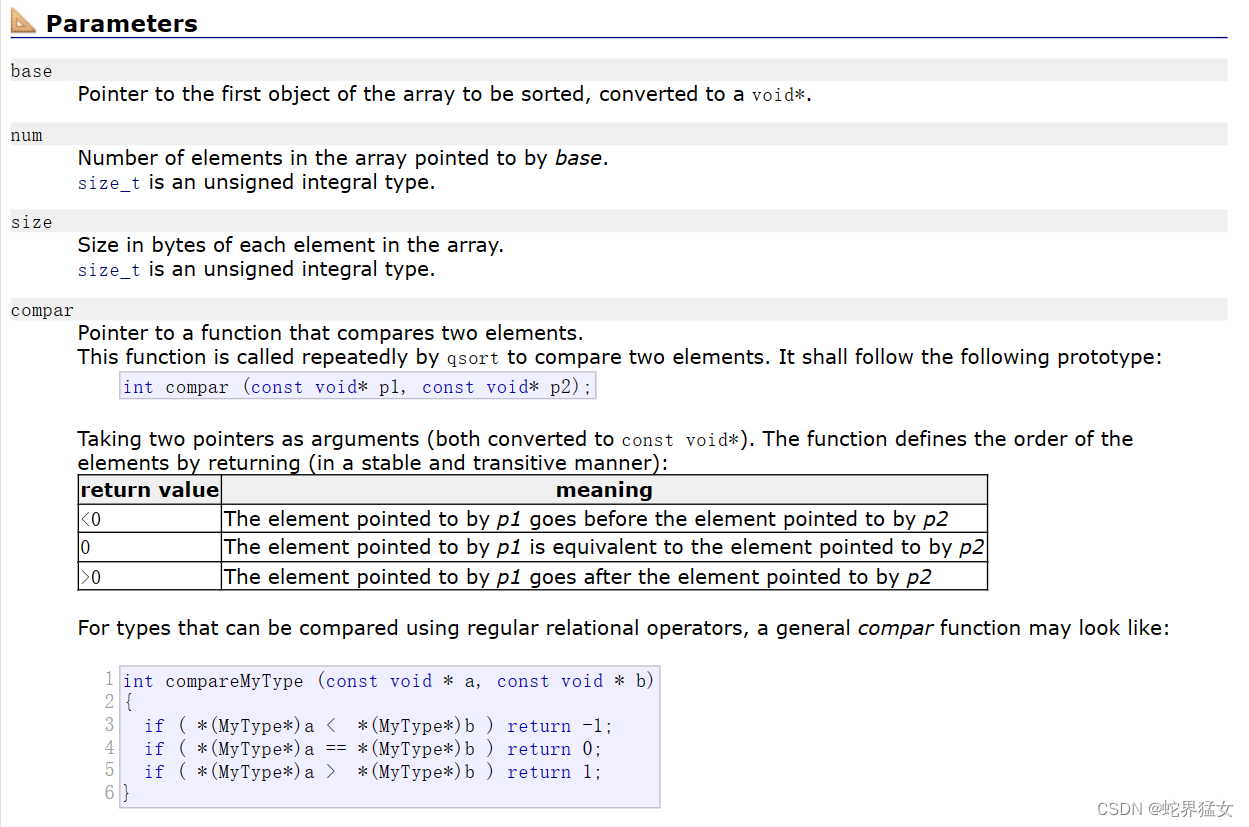
void qsort(void* base, //指向了待排序数组的第一个元素size_t num, //待排序的元素个数size_t size, //每个元素的大小,单位是字节int (*compar)(const void*, const void*) //指向一个函数,这个函数可以比较两个元素的大小.(这个形式参数是函数指针)//const void*, const void*是待比较的两个元素的地址
);

II.qsort可以排序任意类型的数据
1.比较2个整数的大小 > < ==
2.比较2个字符串,strcmp
3.比较2个结构体数据(学生,张三,李四) 指定比较的标准,拿什么比较
假如用冒泡排序,来排序整型数据,字符型数据,结构体数据
需要变的是比较方法和交换方式

III.注意qsort参数中void*的用法
(1)void* 就是无具体类型的指针,可以接收任意类型的指针.
(2)有时候不知道别人给传一个什么类型的地址的时候,我又要把它存起来,这时要创建一个void指针接收地址
(3)void的指针不能解引用操作
(4)void的指针不能进行++或者–,因为他不知道跳过几个字节
(5)可以将void类型的指针进行强制转换再解引用

IV.qsort函数的头文件
#include<stdlib.h>
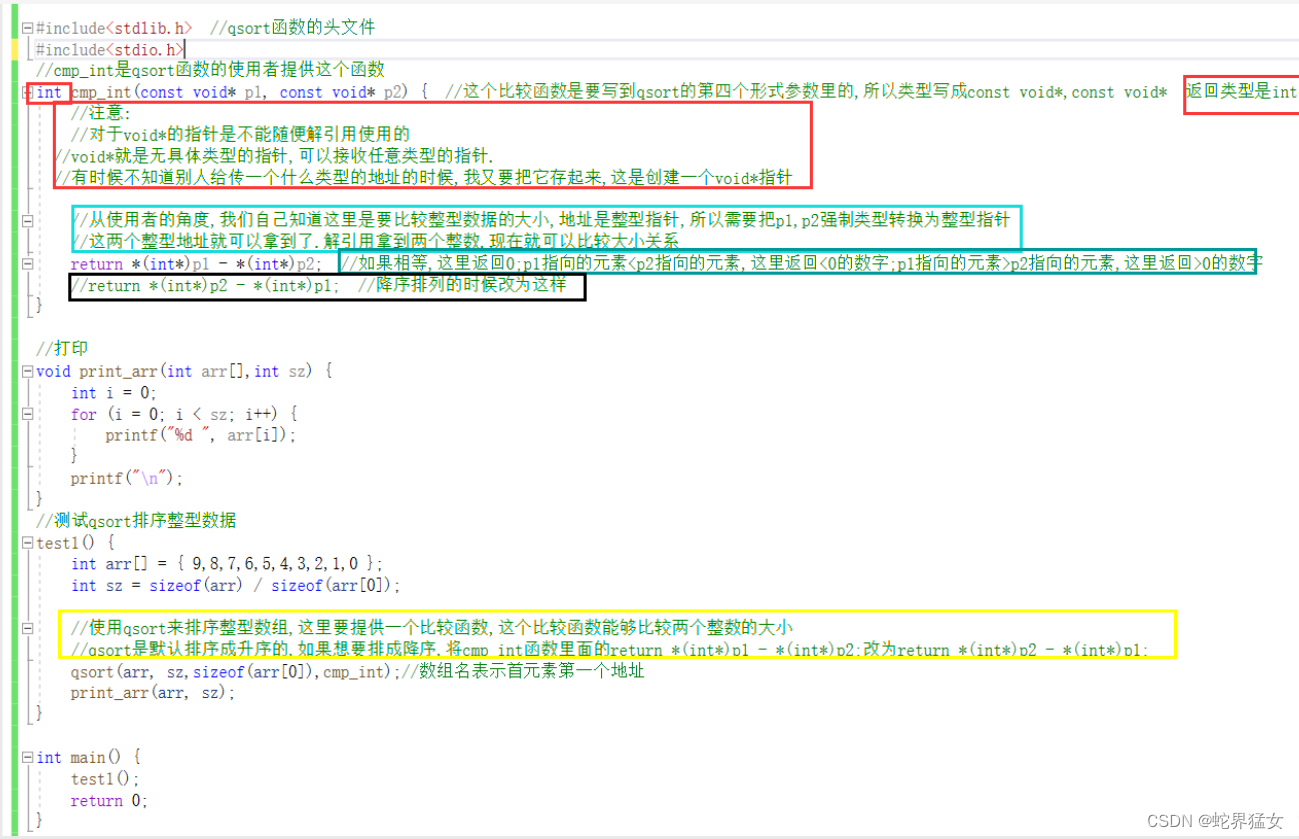
V.测试qsort排序整型数据(qsort默认是升序排序)
#include<stdlib.h> //qsort函数的头文件
#include<stdio.h>
//cmp_int是qsort函数的使用者提供这个函数
int cmp_int(const void* p1, const void* p2) {return *(int*)p1 - *(int*)p2;
}
//打印
void print_arr(int arr[],int sz) {int i = 0;for (i = 0; i < sz; i++) {printf("%d ", arr[i]);}printf("\n");
}
void test1() {int arr[] = { 9,8,7,6,5,4,3,2,1,0 };int sz = sizeof(arr) / sizeof(arr[0]);//使用qsort来排序整型数组,这里要提供一个比较函数,这个比较函数能够比较两个整数的大小//qsort是默认排序成升序的,如果想要排成降序,将cmp_int函数里面的return *(int*)p1 - *(int*)p2;改为return *(int*)p2 - *(int*)p1;qsort(arr, sz,sizeof(arr[0]),cmp_int);//数组名表示首元素第一个地址print_arr(arr, sz);
}int main() {test1();return 0;
}

代码详解图:
VI.测试qsort排序结构型数据
(1)按照年龄来排序
//打印
void print_arr(int arr[], int sz) {int i = 0;for (i = 0; i < sz; i++) {printf("%d ", arr[i]);}printf("\n");
}
struct Stu {char name[20];int age;
};
//按照年龄来比较
int cmp_stu_by_age(const void* p1, const void* p2) { //p1,p2分别指向结构体数据return ((struct Stu*)p1)->age - ((struct Stu*)p2)->age;//将void*类型的指针转换成结构体指针,但是是临时的,所以要加上()再->访问结构体成员//p1指向的元素等于p2指向的元素,返回0;p1指向的元素<p2指向的元素,这里返回<0的数字;p1指向的元素>p2指向的元素,这里返回>0的数字}
test2() {struct Stu s[] = { {"zhangsan",30},{"lisi",25},{"wangwu",50} };int sz = sizeof(s) / sizeof(s[0]);qsort(s, sz, sizeof(s[0]), cmp_stu_by_age);print_arr(s,sz);
}int main() {test2();return 0;
}
执行qsort函数前,结构体数组元素分别为:

执行qsort函数后,结构体数组元素分别为:

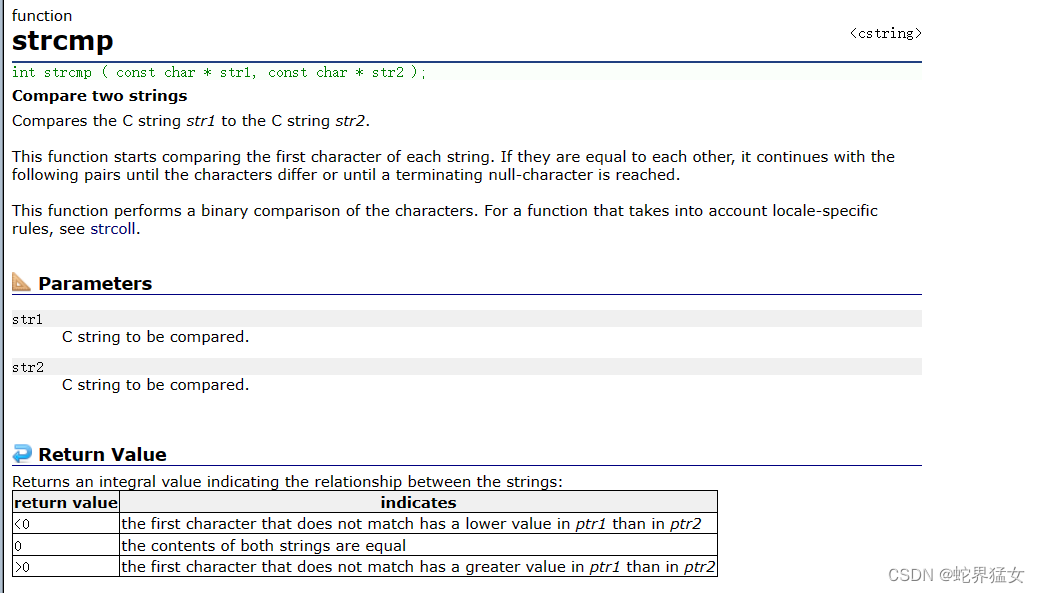
(2)按照名字来排序

strcmp的用法:👻👻
阅读可以发现:
当str1等于str2,返回0;当str1大于st2,返回大于0的数字;当str1小于str2,返回小于0的数字.
需要头文件#include<string.h>
在比较的时候,先比较首字母,一样的话比较下一个字母,直到比到不相等或者全部比完
代码展示:
#include<string.h> //strcmp头文件
#include<stdlib.h> //qsort函数的头文件
#include<stdio.h>
//打印
void print_arr(int arr[], int sz) {int i = 0;for (i = 0; i < sz; i++) {printf("%d ", arr[i]);}printf("\n");
}
//测试qsort排序结构体数据
struct Stu {char name[20];int age;
};
//按照名字来排序(注意两个名字不能相减,要用strcmp比较)
int cmp_stu_by_name(const void* p1, const void* p2) { //p1,p2分别指向结构体数据return strcmp(((struct Stu*)p1)->name ,((struct Stu*)p2)->name);//将void*类型的指针转换成结构体指针,但是是临时的,所以要加上()再->访问结构体成员test2() {struct Stu s[] = { {"zhangsan",30},{"lisi",25},{"wangwu",50} };int sz = sizeof(s) / sizeof(s[0]);//测试按照名字来排序qsort(s, sz, sizeof(s[0]), cmp_stu_by_name);print_arr(s,sz);
}int main() {test2();return 0;
}}
排序前:

排序后:

3.模拟实现qsort功能
用冒泡排序模拟一下`qsort怎么用
但是我们没有学快速排序的思想,所以我们使用冒泡排序的思想来实现一个类似于qsort这个功能的冒泡排序bubble_sort()
🐇🐇🐇注意qsort底层是快速排序,这里只是模拟一下这个函数的功能
(1)排序整型数据
拆分各部分讲解
test3:
I.首先准备一个数组
II.求元素个数
III.调用:用冒泡排序模拟qsort函数的bubble_sort(待排序数组的第一个元素,待排序数组的元素个数,每个元素的大小,使用者提供的比较大小的函数的地址)
IV.打印
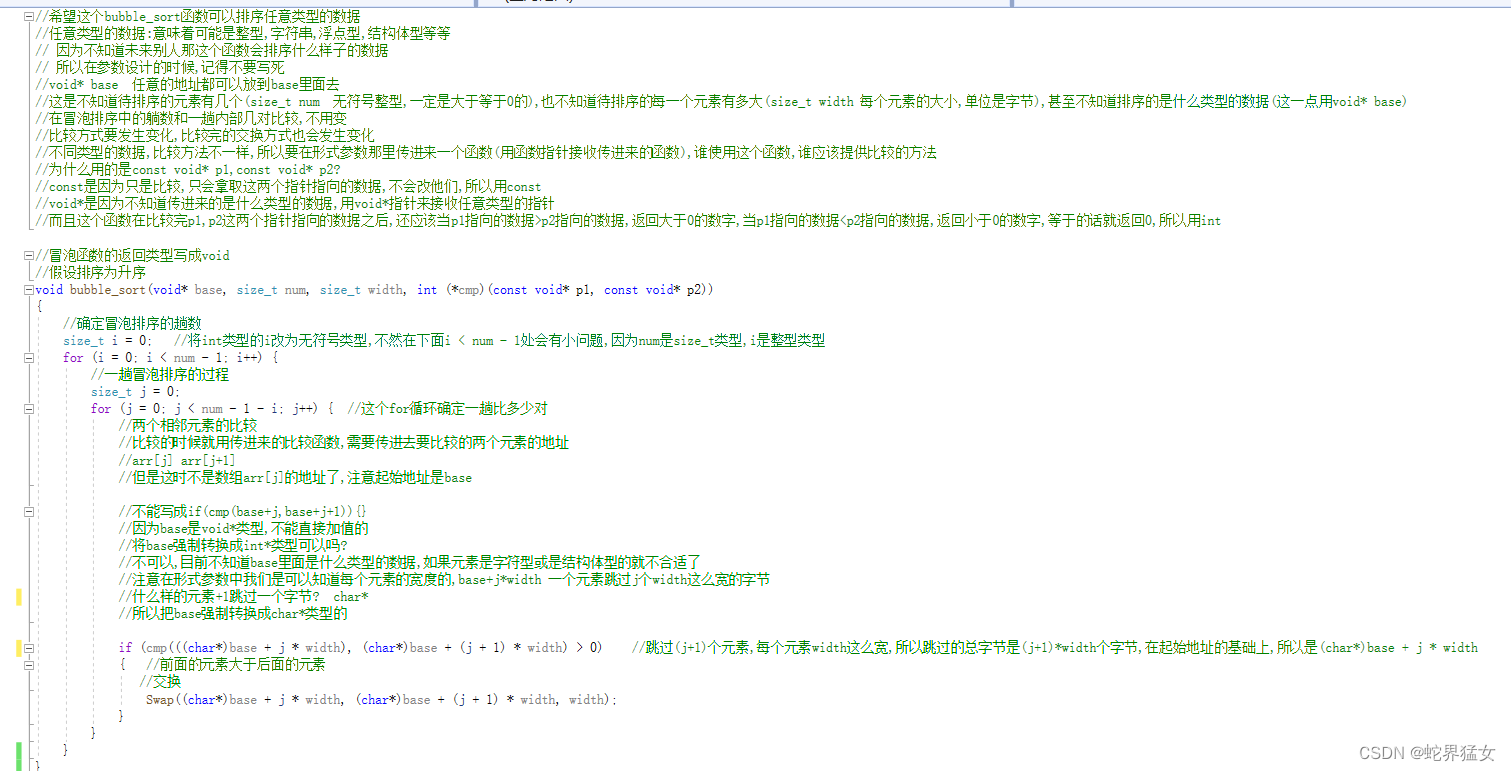
bubble_sort:
I.形式参数(voidbase指向起始位置,size_t num元素的个数,size_t width 宽度这里是4个字节,int (cmp)(const void p1, const void p2)用函数指针来接收使用者创建的比较函数)
用函数指针调用cmp,这里的cmp实质上是一个回调函数
II.内容:
✨确定冒泡排序的趟数
✨一趟内部进行多少对比较
✨比较的时候用使用者创建的比较函数比,将要比较的两个元素的地址传进来
元素的地址怎么表示?
(char*)base + j * width
什么样的元素+1跳过一个字节? char*
所以把base强制转换成char类型的
起始位置base转换为char 指针
跳过(j+1)个元素,每个元素width这么宽,所以跳过的总字节是(j+1)* width个字节,在起始地址的基础上,所以是(char*)base + j * width
✨交换:创建一个交换函数(将这两个元素的起始地址传进来)
参数:创建一个字符指针接收第一个元素的第一个字节char* buf1,创建一个字符指针接收第二个元素的第一个字节char* buf2,创建一个宽度变量来接收一个元素总共有多少个字节int width
交换的时候一个字节一个字节的交换
用width控制交换多少遍,在循环内部创建临时变量tmp作为中间变量与buf1,buf2进行交换
比较函数:(下图所示默认为升序)
如果是降序排列,将p1,p2互换

交换函数:

主函数:

完整代码展示
//打印
void print_arr(int arr[], int sz) {int i = 0;for (i = 0; i < sz; i++) {printf("%d ", arr[i]);}
}
//比较函数
int cmp_int(const void* p1, const void* p2){return *(int*)p1 - *(int*)p2;}
//交换
void Swap(char* buf1, char* buf2, int width) {int i = 0;for (i = 0; i < width; i++) {char tmp = *buf1;//先把buf1内指向的第一个字节放入到tmp里面,*buf1 = *buf2;*buf2 = tmp;buf1++; //找buf1的下一个字节buf2++; //找buf2的下一个字节}
}
//模拟qsort函数的bubble_sort
void bubble_sort(void* base, size_t num, size_t width, int (*cmp)(const void* p1, const void* p2)){size_t i = 0; //将int类型的i改为无符号类型,不然在下面i < num - 1处会有小问题,因为num是size_t类型,i是整型类型for (i = 0; i < num - 1; i++) {//一趟冒泡排序的过程size_t j = 0;for (j = 0; j < num - 1 - i; j++) { //这个for循环确定一趟比多少对if (cmp(((char*)base + j * width), (char*)base + (j + 1) * width) > 0) //跳过(j+1)个元素,每个元素width这么宽,所以跳过的总字节是(j+1)*width个字节,在起始地址的基础上,所以是(char*)base + j * width{ //前面的元素大于后面的元素//交换Swap((char*)base + j * width, (char*)base + (j + 1) * width, width);}}}
}
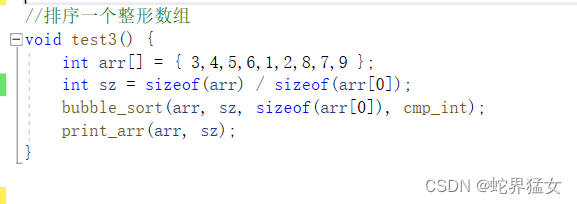
//排序一个整形数组
void test3() {int arr[] = { 3,4,5,6,1,2,8,7,9 };int sz = sizeof(arr) / sizeof(arr[0]);bubble_sort(arr, sz, sizeof(arr[0]), cmp_int);print_arr(arr, sz);
}int main() {test3();return 0;
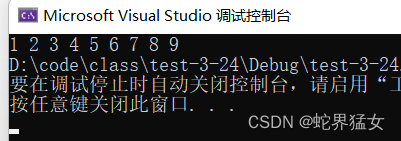
}运行结果
注意点:
注意各个函数在定义时候的先后顺序,只有在前面定义了,后面才可以使用
(2)排序结构体类型数据
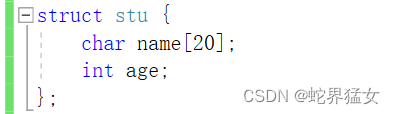
创建结构体:
测试按照年龄排序代码展示
//测试qsort排序结构体数据
struct stu {char name[20];int age;
};
//按照年龄来比较
int cmp_stu_by_age(const void* p1, const void* p2) { //p1,p2分别指向结构体数据return ((struct stu*)p1)->age - ((struct stu*)p2)->age;//将void*类型的指针转换成结构体指针,但是是临时的,所以要加上()再->访问结构体成员//p1指向的元素等于p2指向的元素,返回0;p1指向的元素<p2指向的元素,这里返回<0的数字;p1指向的元素>p2指向的元素,这里返回>0的数字}
//交换
void Swap(char* buf1, char* buf2, int width) {int i = 0;for (i = 0; i < width; i++) {char tmp = *buf1;//先把buf1内指向的第一个字节放入到tmp里面,*buf1 = *buf2;*buf2 = tmp;buf1++; //找buf1的下一个字节buf2++; //找buf2的下一个字节}
}
//模拟qsort函数的bubble_sort
void bubble_sort(void* base, size_t num, size_t width, int (*cmp)(const void* p1, const void* p2)){size_t i = 0; //将int类型的i改为无符号类型,不然在下面i < num - 1处会有小问题,因为num是size_t类型,i是整型类型for (i = 0; i < num - 1; i++) {//一趟冒泡排序的过程size_t j = 0;for (j = 0; j < num - 1 - i; j++) { //这个for循环确定一趟比多少对if (cmp(((char*)base + j * width), (char*)base + (j + 1) * width) > 0) //跳过(j+1)个元素,每个元素width这么宽,所以跳过的总字节是(j+1)*width个字节,在起始地址的基础上,所以是(char*)base + j * width{ //前面的元素大于后面的元素//交换Swap((char*)base + j * width, (char*)base + (j + 1) * width, width);}}}
}
//打印
void print_arr(int arr[], int sz) {int i = 0;for (i = 0; i < sz; i++) {printf("%d ", arr[i]);}
}int cmp_int(const void* p1, const void* p2){return *(int*)p1 - *(int*)p2;}void test4() {struct stu s[] = { {"zhangsan",30},{"lisi",25},{"wangwu",50} };int sz = sizeof(s) / sizeof(s[0]);//测试按照年龄来排序bubble_sort(s, sz, sizeof(s[0]), cmp_stu_by_age);print_arr(s, sz);
}int main() {test4();return 0;
}按年龄排序前:
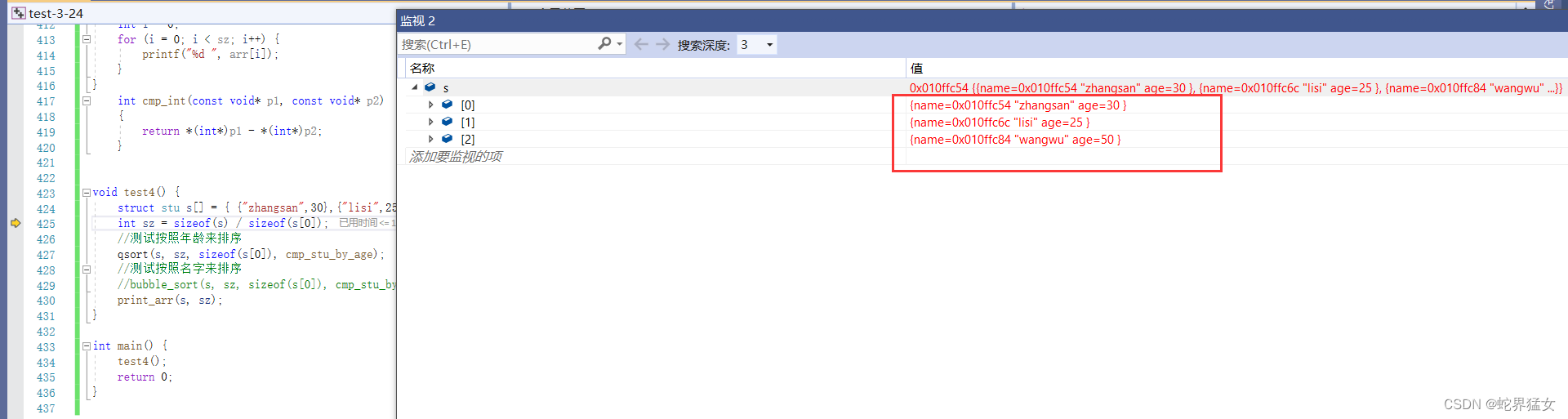
按年龄排序后:

测试按照名字排序代码展示
struct stu {char name[20];int age;
};
//按照名字来排序(注意两个名字不能相减,要用strcmp比较)
int cmp_stu_by_name(const void* p1, const void* p2) { //p1,p2分别指向结构体数据return strcmp(((struct stu*)p1)->name, ((struct stu*)p2)->name);//将void*类型的指针转换成结构体指针,但是是临时的,所以要加上()再->访问结构体成员//p1指向的元素等于p2指向的元素,返回0;p1指向的元素<p2指向的元素,这里返回<0的数字;p1指向的元素>p2指向的元素,这里返回>0的数字}
void Swap(char* buf1, char* buf2, int width) {int i = 0;for (i = 0; i < width; i++) {char tmp = *buf1;//先把buf1内指向的第一个字节放入到tmp里面,*buf1 = *buf2;*buf2 = tmp;buf1++; //找buf1的下一个字节buf2++; //找buf2的下一个字节}
}
//模拟qsort函数的bubble_sort
void bubble_sort(void* base, size_t num, size_t width, int (*cmp)(const void* p1, const void* p2)){size_t i = 0; //将int类型的i改为无符号类型,不然在下面i < num - 1处会有小问题,因为num是size_t类型,i是整型类型for (i = 0; i < num - 1; i++) {//一趟冒泡排序的过程size_t j = 0;for (j = 0; j < num - 1 - i; j++) { //这个for循环确定一趟比多少对if (cmp(((char*)base + j * width), (char*)base + (j + 1) * width) > 0) //跳过(j+1)个元素,每个元素width这么宽,所以跳过的总字节是(j+1)*width个字节,在起始地址的基础上,所以是(char*)base + j * width{ //前面的元素大于后面的元素//交换Swap((char*)base + j * width, (char*)base + (j + 1) * width, width);}}}
}
//打印
void print_arr(int arr[], int sz) {int i = 0;for (i = 0; i < sz; i++) {printf("%d ", arr[i]);}
}int cmp_int(const void* p1, const void* p2){return *(int*)p1 - *(int*)p2;}void test4() {struct stu s[] = { {"zhangsan",30},{"lisi",25},{"wangwu",50} };int sz = sizeof(s) / sizeof(s[0]);//测试按照年龄来排序//bubble_sort(s, sz, sizeof(s[0]), cmp_stu_by_age);//测试按照名字来排序bubble_sort(s, sz, sizeof(s[0]), cmp_stu_by_name);print_arr(s, sz);
}int main() {test4();return 0;
}按名字排序前:
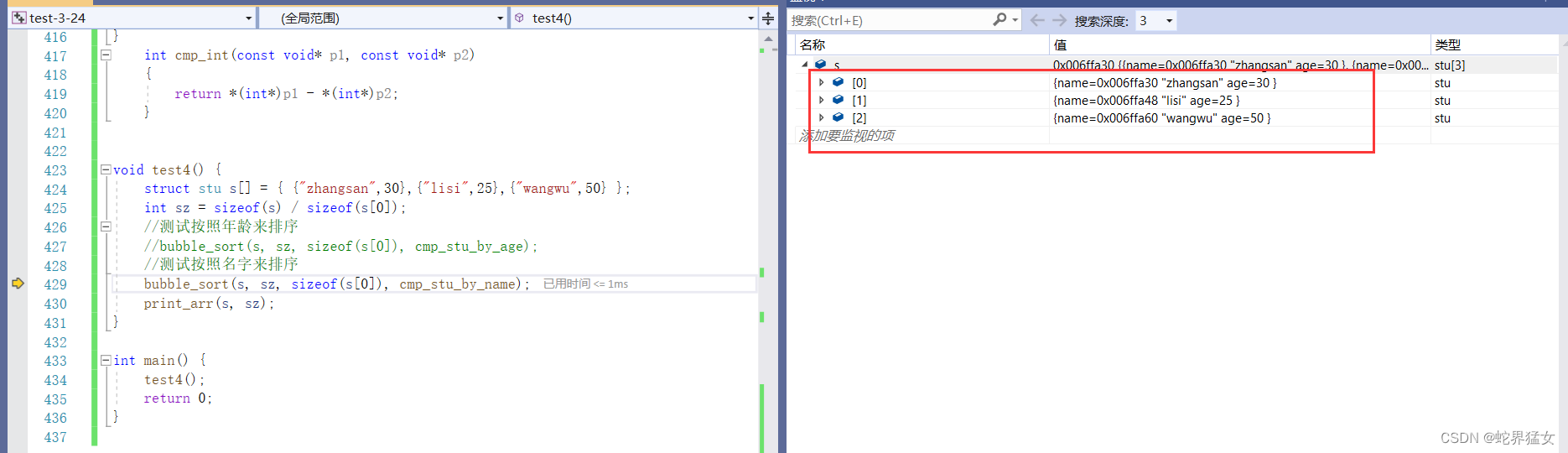
按名字排序后:

(3)用flag优化
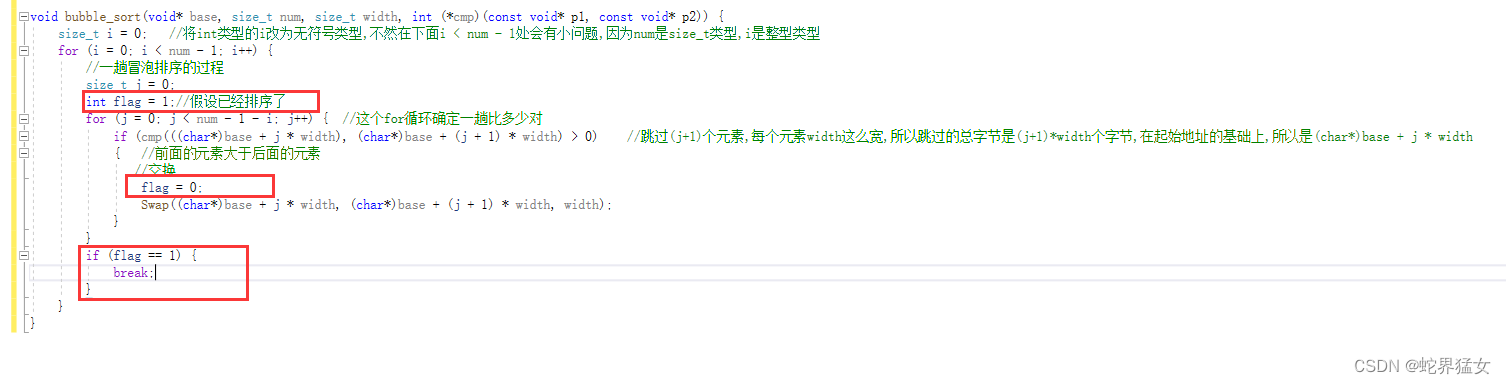
✨比如说在中间某个过程冒泡排序已经得到最终排序结果,剩下的排序过程就没有必要再进行
✨这时使用flag来优化
✨假设每一趟排序已经是有序的,flag置为1,要写在循环里面,每一趟都认为是有序的
✨只要进入交换函数进行交换,flag就会被更改为0,如果这一趟里面没有进行交换,flag不会被修改,说明已经是有序的了,不需要再排序
✨判断flag的值是多少,如果是1的话,跳出循环,结束排序
注意👻👻👻
(1)以上是用冒泡排序实现了一个通用的冒泡排序,只不过是这个通用的冒泡排序与qsort的使用是一模一样的
不要认为上面的代码是用冒泡排序模拟qsort,qsort底层用的是快速排序的思想
(2)正是由于回调函数的使用,才可以用函数指针去调用函数去完成不同的功能,使得冒泡排序能够适配更多的类型,这就是回调函数的好处
总结
指针进阶(中)的内容就到这里啦,创作不易如果对友友们有帮助的话,记得点赞收藏博客,关注后续的指针进阶下集内容哦~👻👻👻

相关文章:
指针进阶(中)
提示: 上集内容小复习🥰🥰 int my_strlen(const char* str) {return 1; } int main() {//指针数组char* arr[10];//数组指针int arr2[5] { 0 };int(*p)[5] &arr2; //p是一个指向数组的指针变量//函数指针int (*pf)(const char*)&m…...
,__BASE_FILE__))
C/C++获取文件名的方法(__FILE__,__builtin_FILE(),__BASE_FILE__)
目录标题C/C获取文件名的方法__FILE__宏避免__FILE__宏的错误慎用$(subst $(dir $<),,$<)\"")来重定义__BASE_FILE__宏__builtin_FILE()函数Windows API函数GetModuleFileName()getenv()使用cmake中的变量重定义__FILE__宏的CMake示例C/C获取文件名的方法 使用…...

线程池的讲解和实现
🚀🚀🚀🚀🚀🚀🚀大家好,今天为大家带来线程池相关知识的讲解,并且实现一个线程池 🌸🌸🌸🌸🌸🌸🌸🌸…...

linux编程──gcc和clang
实验链接 编译原理实验-GCC/Clang工具链在ARM架构上的使用 实验报告 第1关:理解程序的不同表示形式 ##问题1-1: 如果在命令行下执行 gcc -DNEG -E sample.c -o sample.i生成的sample.i 与之前的有何区别? 根据定义NEG,而选择了M定义为-4…...

字节跳动测试岗面试记:二面被按地上血虐,所幸Offer已到手...
在互联网做了几年之后,去大厂“镀镀金”是大部分人的首选。大厂不仅待遇高、福利好,更重要的是,它是对你专业能力的背书,大厂工作背景多少会给你的简历增加几分竞争力。 但说实话,想进大厂还真没那么容易。最近面试字…...

5.多线程学习
作者:爱塔居 专栏:JavaEE 作者简介:大三学生,喜欢总结与分享~ 文章目录 目录 文章目录 章节回顾 一、wait 和notify 二、设计模式 2.1 单例模式 章节回顾 线程安全 1.一个线程不安全的案例(两个线程各自自增5w次&…...

数据结构中的堆
一、树的重要知识点 节点的度:一个节点含有的子树的个数称为该节点的度(有几个孩子)叶节点或终端节点:度为0的节点称为叶节点;如上图:B、C、H、I...等节点为叶节点(0个孩子)非终端节点或分支节点…...

Linux内核设备信息集合
本文结合设备信息集合的详细讲解来认识一下设备和驱动是如何绑定的。所谓设备信息集合,就是根据不同的外设寻找各自的外设信息,我们知道一个完整的开发板有 CPU 和各种控制器(如 I2C 控制器、SPI 控制器、DMA 控制器等)࿰…...
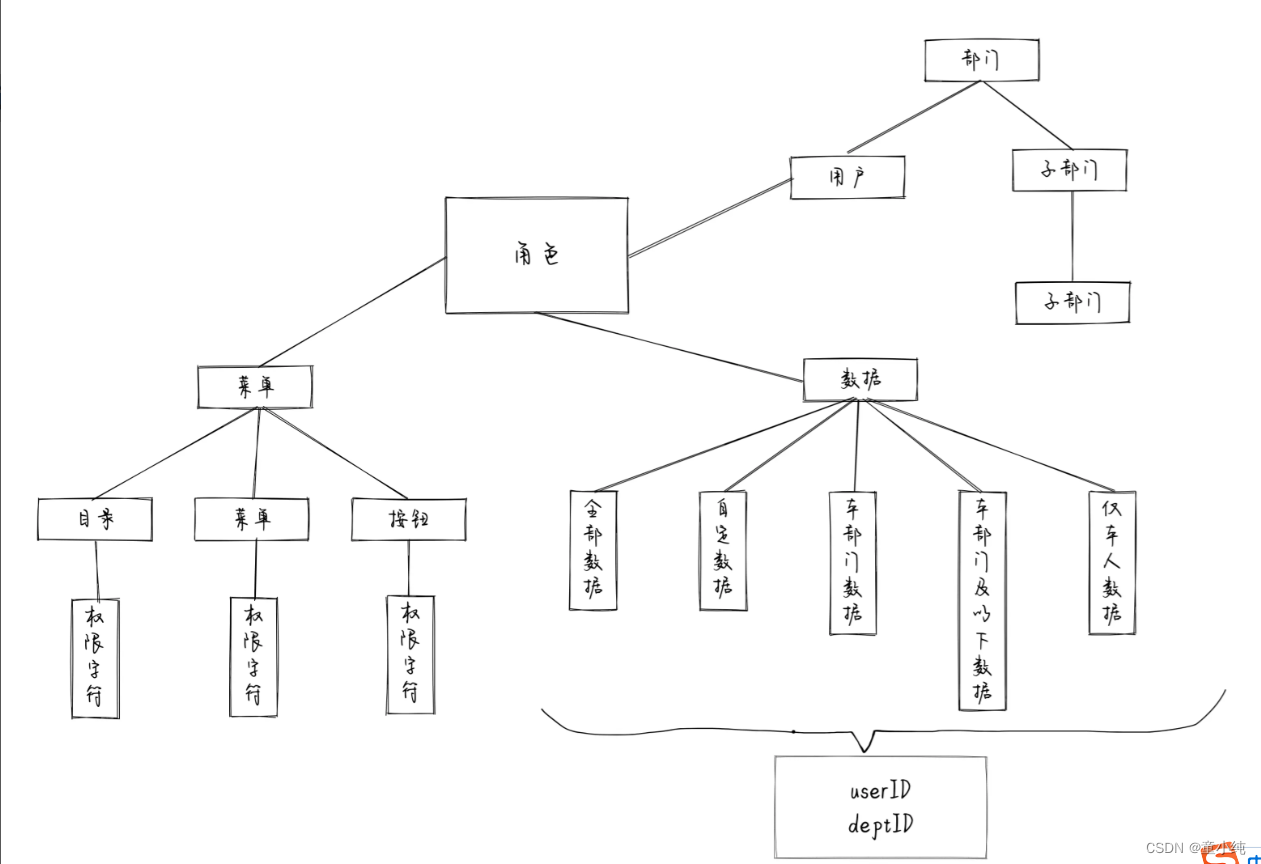
若依框架---权限管理设计
前言 若依权限管理包含两个部分:菜单权限 和 数据权限。菜单权限控制着我们可以执行哪些操作。数据权限控制着我们可以看到哪些数据。 菜单是一个概括性名称,可以细分为目录、菜单和按钮,以若依自身为例: 目录,就是页…...
——工厂模式)
Java设计模式(二)——工厂模式
当用户需要一个类的子类实例,且不希望与该类的子类形成耦合或者不知道该类有哪些子类可用时,可采用工厂模式;当用户需要系统提供多个对象,且希望和创建对象的类解耦时,可采用抽象工厂模式。 工厂模式一般分为简单工厂、…...
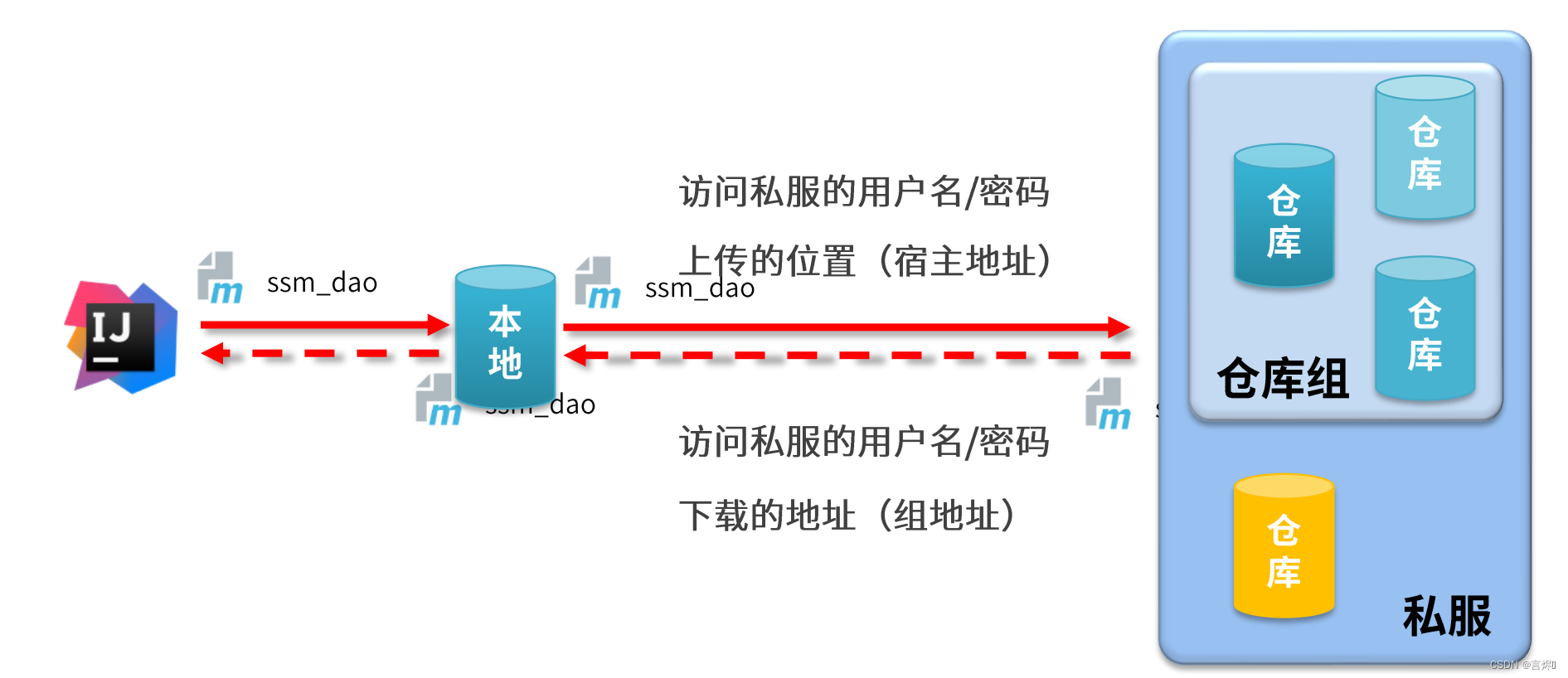
【Maven】
MavenMaven简介仓库坐标Maven项目构建依赖管理生命周期及插件插件模块拆分与开发聚合继承属性版本管理资源配置多环境开发配置跳过测试私服Maven简介 Maven的本质时一个项目管理工具,将项目开发和管理过程抽象成一个项目对象模型(POM) POM(Project Object Model)&a…...
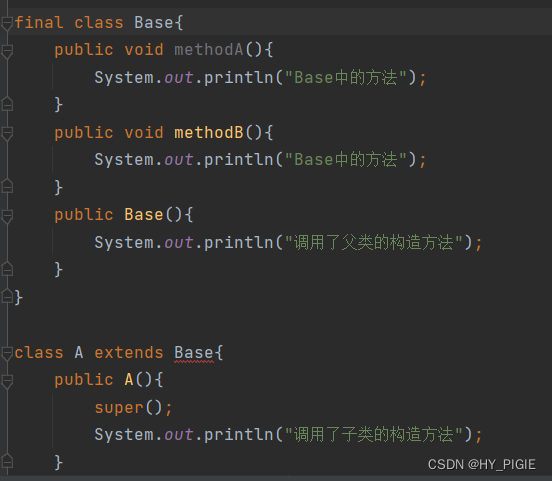
[JAVA]继承
目录 1.继承的概念 2.继承的语法 3.父类成员访问 3.1子类中访问父类成员变量 3.2子类中访问父类成员方法 4.super关键字 5.子类构造方法 6.继承方式 7.final关键字和类的关系 面向对象思想中提出了继承的概念,专门用来进行共性抽取,实现代码复…...
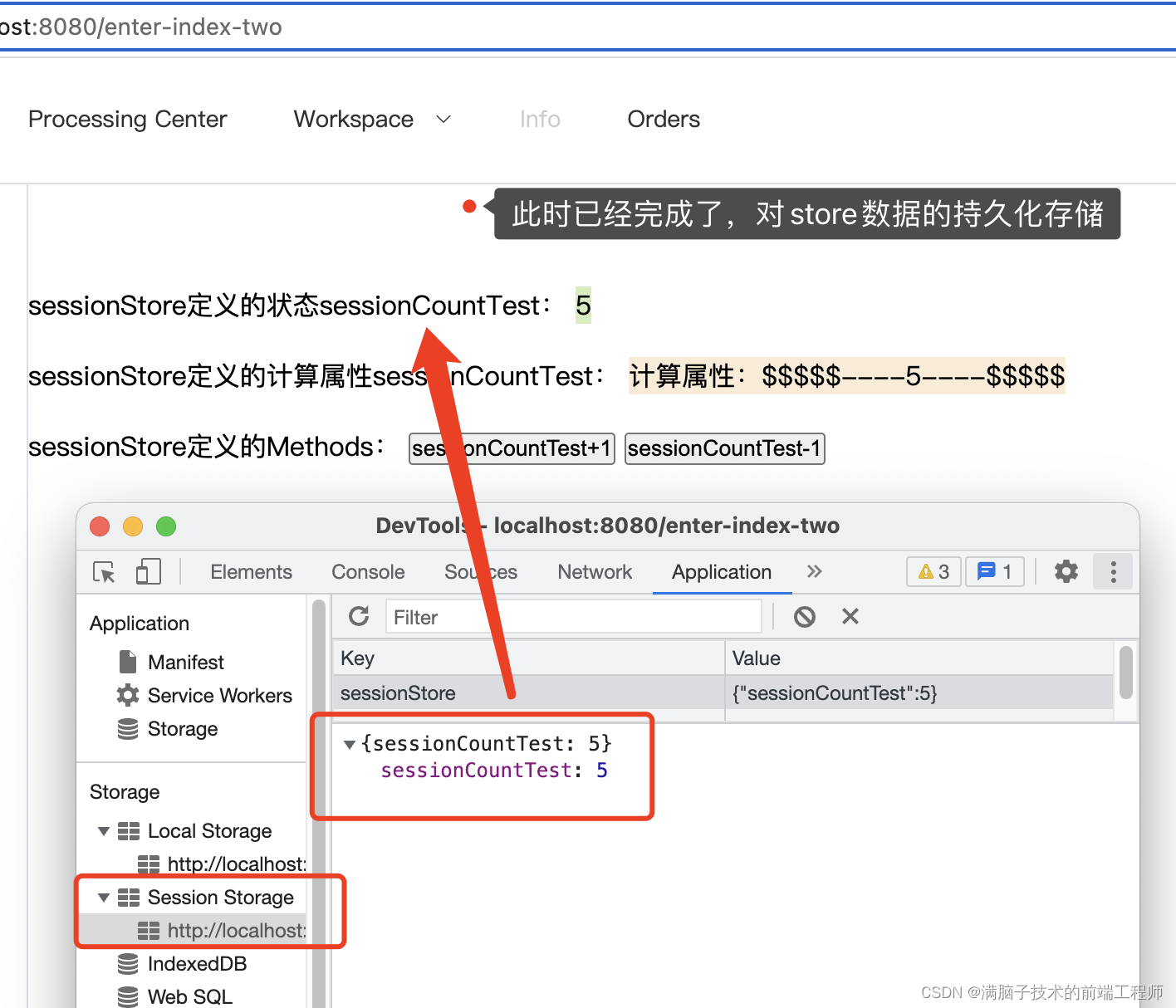
Vue3 pinia持久化存储(组合式Api案例演示)
pinia-plugin-persist( pinia持久化插件) 本文采用的是 组合式Api的方式来做Pinia的持久化存储演示 如果对pinia的持久化还是不是很了解的👨🎓|👩🎓,可以看一下笔者的上一篇文章…...

8个你一看就觉得很棒的Vue开发技巧
1.路由参数解耦 通常在组件中使用路由参数,大多数人会做以下事情。 export default {methods: {getParamsId() {return this.$route.params.id}} }在组件中使用 $route 会导致与其相应路由的高度耦合,通过将其限制为某些 URL 来限制组件的灵活性。 正…...
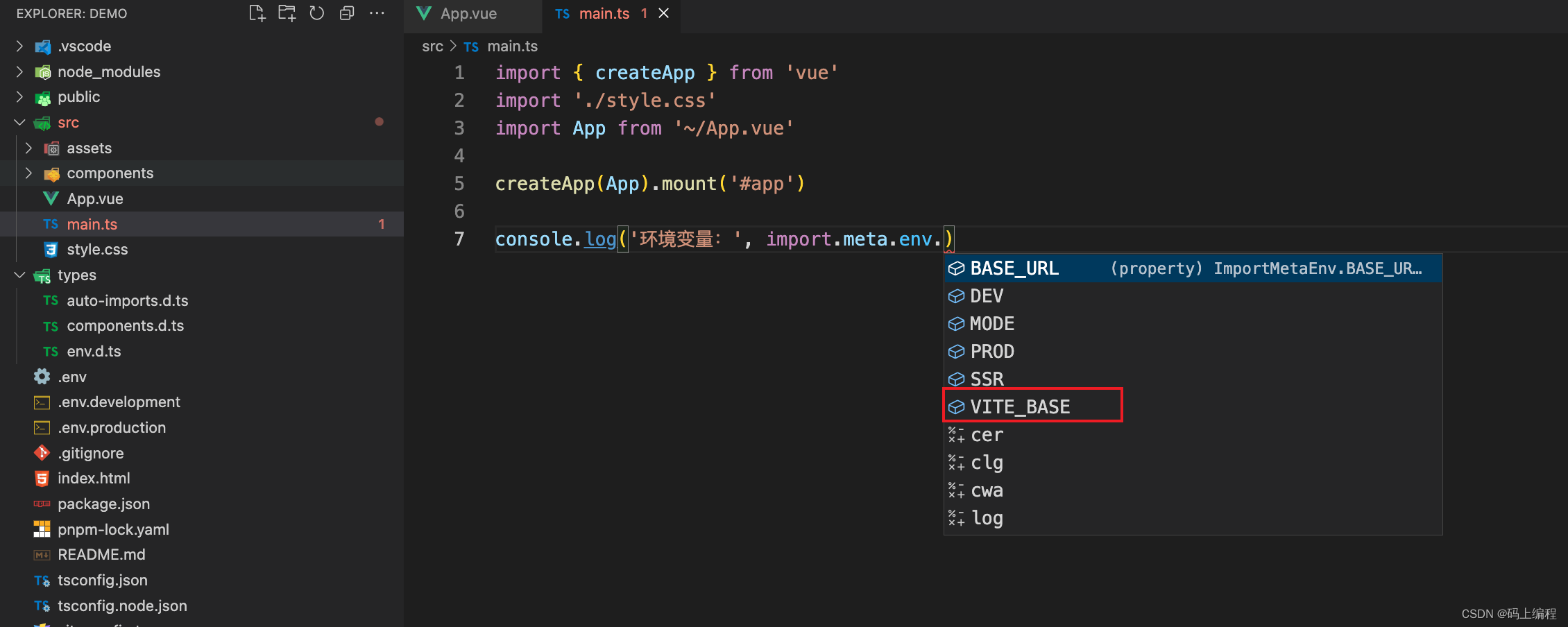
vue3+ts 开发效率提升
1、vite pnpm项目初始化 pnpm: 比npm或yarn快10倍 pnpm与其他包管理器(如npm和Yarn)的不同之处在于它使用一种称为“硬链接”的独特安装方法。当你使用PNPM安装一个包时,它并不会将包的文件复制到每个项目的node_modules目录中&a…...

【数据结构与算法】队列和栈的相互实现以及循环队列
目录🌔一.用队列实现栈🌙1.题目描述🌙2.思路分析🌙3.代码实现⛈二.用栈实现队列☔1.题目描述☔2.思路分析☔3.代码实现🌈三.实现循环队列🌔一.用队列实现栈 🌙1.题目描述 我们先看一下题目链接…...

mysql连接不上问题解决
公司新搭内网测试环境,mysql远程登录问题解决 远程登录: 1 修改host, mysql> select user,host,plugin from user; ---------------------------------------------------- | user | host | plugin | ------------------------…...

利用nginx实现动静分离的负载均衡集群实战
前言 大家好,我是沐风晓月,今天我们利用nginx来作为负载,实现两台apache服务器的动静分离集群实战; 本文收录于沐风晓月的专栏《linux基本功-系统服务实战》,更多内容可以关注我的博客: https://blog.csd…...

与chatGPT神聊,引领你深入浅出系统调用
在操作系统的教学中,系统调用的作用不言而喻,但是,对系统调用常常是雾里看花,似乎明白,又难以真正的触及,即使在代码中调用了系统调用,比如调用fork()创建进程࿰…...
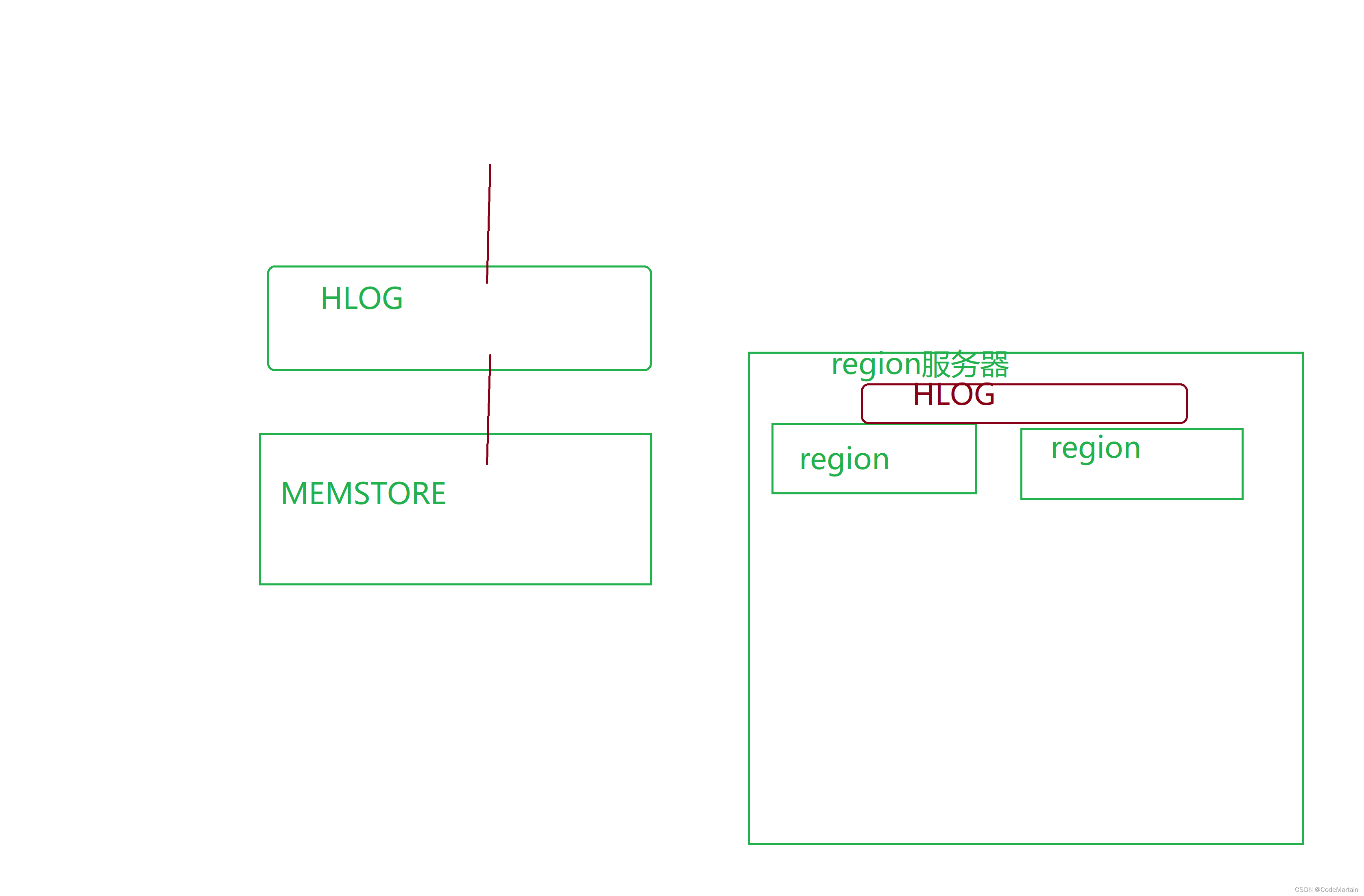
自学大数据第十天~Hbase
随着数据量的增多,数据的类型也不像原来那样都是结构化数据,还有非结构化数据; Hbase时google 的bigtable的开源实现, BigtableHbase文件存储系统GFSHDFS海量数据处理MRMR协同管理服务chubbyzookeeper虽然有了HDFS和MR,但是对于数据的实时处理是比较困难的,没有办法应对数据的…...

【Linux】shell脚本忽略错误继续执行
在 shell 脚本中,可以使用 set -e 命令来设置脚本在遇到错误时退出执行。如果你希望脚本忽略错误并继续执行,可以在脚本开头添加 set e 命令来取消该设置。 举例1 #!/bin/bash# 取消 set -e 的设置 set e# 执行命令,并忽略错误 rm somefile…...

Appium+python自动化(十六)- ADB命令
简介 Android 调试桥(adb)是多种用途的工具,该工具可以帮助你你管理设备或模拟器 的状态。 adb ( Android Debug Bridge)是一个通用命令行工具,其允许您与模拟器实例或连接的 Android 设备进行通信。它可为各种设备操作提供便利,如安装和调试…...

23-Oracle 23 ai 区块链表(Blockchain Table)
小伙伴有没有在金融强合规的领域中遇见,必须要保持数据不可变,管理员都无法修改和留痕的要求。比如医疗的电子病历中,影像检查检验结果不可篡改行的,药品追溯过程中数据只可插入无法删除的特性需求;登录日志、修改日志…...

Java如何权衡是使用无序的数组还是有序的数组
在 Java 中,选择有序数组还是无序数组取决于具体场景的性能需求与操作特点。以下是关键权衡因素及决策指南: ⚖️ 核心权衡维度 维度有序数组无序数组查询性能二分查找 O(log n) ✅线性扫描 O(n) ❌插入/删除需移位维护顺序 O(n) ❌直接操作尾部 O(1) ✅内存开销与无序数组相…...

【SpringBoot】100、SpringBoot中使用自定义注解+AOP实现参数自动解密
在实际项目中,用户注册、登录、修改密码等操作,都涉及到参数传输安全问题。所以我们需要在前端对账户、密码等敏感信息加密传输,在后端接收到数据后能自动解密。 1、引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId...

大数据零基础学习day1之环境准备和大数据初步理解
学习大数据会使用到多台Linux服务器。 一、环境准备 1、VMware 基于VMware构建Linux虚拟机 是大数据从业者或者IT从业者的必备技能之一也是成本低廉的方案 所以VMware虚拟机方案是必须要学习的。 (1)设置网关 打开VMware虚拟机,点击编辑…...

【SQL学习笔记1】增删改查+多表连接全解析(内附SQL免费在线练习工具)
可以使用Sqliteviz这个网站免费编写sql语句,它能够让用户直接在浏览器内练习SQL的语法,不需要安装任何软件。 链接如下: sqliteviz 注意: 在转写SQL语法时,关键字之间有一个特定的顺序,这个顺序会影响到…...

3403. 从盒子中找出字典序最大的字符串 I
3403. 从盒子中找出字典序最大的字符串 I 题目链接:3403. 从盒子中找出字典序最大的字符串 I 代码如下: class Solution { public:string answerString(string word, int numFriends) {if (numFriends 1) {return word;}string res;for (int i 0;i &…...

华为OD机考-机房布局
import java.util.*;public class DemoTest5 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseSystem.out.println(solve(in.nextLine()));}}priv…...

GO协程(Goroutine)问题总结
在使用Go语言来编写代码时,遇到的一些问题总结一下 [参考文档]:https://www.topgoer.com/%E5%B9%B6%E5%8F%91%E7%BC%96%E7%A8%8B/goroutine.html 1. main()函数默认的Goroutine 场景再现: 今天在看到这个教程的时候,在自己的电…...