从〇 搭建PO模式的Web UI自动化测试框架
Page Object模式简介
核心思想
将页面元素和操作行为封装在独立的类中,形成页面对象(Page Object)。每个页面对象代表应用程序中的一个特定页面或组件。
优点:
代码复用性高
页面对象可以在多个测试用例中复用。
易于维护
如果页面布局或元素发生变化,只需要修改对应的页面对象类,而不需要修改所有相关的测试用例。
项目结构介绍

allure-results/:
- 作用: 存放 Allure 生成的测试结果文件。Allure 从这里读取数据来生成报告。
内容示例: 包含测试结果的 JSON 文件、截图等附件。
pages/:
-
作用:存放Page Object类。Page Object类将页面元素及其操作封装起来,每个类对应一个页面或组件。这种封装使得测试代码更为简洁易读,并减少了页面变更时的修改量。
-
示例:
- base_page.py: 定义了一个基础的Page类,提供了页面操作的通用方法,如查找元素、点击、输入文本等。其他页面类都会继承这个类。
import allure from selenium.common import TimeoutException from selenium.webdriver.remote.webdriver import WebDriver from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as ECclass BasePage:def __init__(self, driver: WebDriver):self.driver = driverself.timeout = 5def find_element(self, locator):"""获取元素的手柄:param locator:指定元素的定位器:return:元素手柄"""# presence_of_element_located:等待某个元素出现在 DOM 中# visibility_of_element_located:等待某个元素不仅存在于 DOM 中,而且是可见的。try:# 尝试等待元素的可见性return WebDriverWait(self.driver, self.timeout).until(EC.visibility_of_element_located(locator))except TimeoutException:# 如果元素的可见性等待超时,继续等待元素的存在return WebDriverWait(self.driver, self.timeout).until(EC.presence_of_element_located(locator))def element_exists(self, locator):"""用显示等待判断指定元素是否存在:param locator:待判断元素的定位器:return:True/False"""try:self.find_element(locator)return Trueexcept TimeoutException:return Falsedef upload_file(self, file_path, locator):"""公共的上传文件函数:param file_path (str):要上传的文件的路径:param locator (tuple):上传元素的定位器:return: 无"""with allure.step(f"上传文件:{file_path}"):upload_element = self.find_element(locator)upload_element.send_keys(file_path)def get_text(self, locator):text_content = self.find_element(locator).textreturn text_contentdef click(self, locator):"""点击指定的元素:param locator: 指定元素的定位器:return:"""with allure.step(f"点击指定元素:{locator}"):self.find_element(locator).click()def double_click(self, locator):"""点击指定的元素:param locator: 指定元素的定位器:return:"""with allure.step(f"双击指定元素:{locator}"):self.find_element(locator).double_click()def context_click(self, locator):"""右键指定的元素:param locator: 指定元素的定位器:return:"""with allure.step(f"右键指定元素:{locator}"):self.find_element(locator).context_click()def send_keys(self, locator, text):"""收入数据:param locator: 指定元素的定位器:param text: 待输入的数据:return:"""with allure.step(f"在{locator}中输入:{text}"):self.find_element(locator).send_keys(text)def get_title(self):"""获取当前页面表头:return:"""return self.driver.title- baidu_page.py: 这个文件是一个具体的Page Object类的示例,封装了登录页面的操作。通常会包含元素定位和一些基本的操作方法,如输入输入、点击搜索按钮等。
import time import allure from selenium.webdriver.common.by import By from .base_page import BasePageclass LoginPage(BasePage):# 元素:element# 定位器:positionerep_INPUT = (By.XPATH, '//*[@id="kw"]')ep_SEARCH_BUTTON = (By.XPATH, '//*[@id="su"]')ep_ASSERT_TEXT = (By.XPATH, '//*[@id="1"]/div/section/div[1]/span')ep_INPUT_IMAGE = (By.XPATH, '//*[@id="form"]/span[1]/span[1]')ep_SELECT_FILE = (By.XPATH, '//*[@id="form"]/div/div[2]/div[2]/input')ep_IMAGE_PATH = 'D:\\UITestProject\\20240815175707543.jpg'ep_ASSERT_IMAGE = (By.XPATH, '//*[@id="app"]/div/div[1]/div/div[1]/div/div/div[2]/div[1]')# @allure.step("输入搜素text") # 用于记录测试用例中的具体步骤def input_value(self, value):"""输入搜索值:param value::return:"""self.send_keys(self.ep_INPUT, value)# @allure.step("点击搜索按钮") # 用于记录测试用例中的具体步骤def click_search(self):"""点击搜索按钮:return:"""self.click(self.ep_SEARCH_BUTTON)# @allure.step("获取判断元素的text")def get_assert_text_text(self):return self.get_text(self.ep_ASSERT_TEXT)# @allure.step("上传图片") # 用于记录测试用例中的具体步骤def upload_image(self):self.click(self.ep_INPUT_IMAGE)self.upload_file(self.ep_IMAGE_PATH, self.ep_SELECT_FILE)def get_assert_image_text(self):print(self.get_text(self.ep_ASSERT_IMAGE))return self.get_text(self.ep_ASSERT_IMAGE)
tests/:
- 作用: 存放所有的测试用例文件。每个测试文件通常以 test_ 开头,包含测试函数和测试类。
- 示例:
- test_baidu.py:包含针对百度功能的测试用例。
import allure import pytest from pages.baidu_page import LoginPage# @pytest.mark.usefixtures("setup") # 在测试用例之前和之后执行 @allure.feature("百度搜索功能") class TestLogin:# @pytest.mark.skip(reason="跳过该测试用例!") # 跳过该测试用例!# @pytest.mark.skipif(sys.platform == "win32", reason="Windows上不运行该用例") # 根据条件判断是否跳过该测试用例# @pytest.mark.run(order=1) # 控制运行顺序【优先级】,从小到大依次执行@allure.title("搜索文本功能") # 用于给测试用例设置一个自定义的标题,替代默认的函数名称。@pytest.mark.parametrize("value, text", [("猪猪", "其他人还搜"), ("狗子", "相关动物")]) # 参数化def test_search_text(self, value, text):login_page = LoginPage(self.driver)login_page.input_value(value)login_page.click_search()assert login_page.get_assert_text_text() == textassert login_page.get_title() == f"{value}_百度搜索"@allure.title("搜索图片功能") # 用于给测试用例设置一个自定义的标题,替代默认的函数名称。@allure.description("测试是否可以搜索出与上传图片有关的内容") # 为测试用例添加详细描述,帮助更好地理解测试的目的和背景。def test_search_image(self):login_page = LoginPage(self.driver)login_page.upload_image()assert login_page.get_assert_image_text() == "文字提取" - 示例:
utils/:
- 作用:作用: 存放工具类和辅助功能的脚本。通常包括 WebDriver 的工厂类、常用的功能函数等。
- 示例:
- driver_factory.py:创建和管理 WebDriver 实例的工厂类。
from selenium import webdriverdef get_driver(browser_name="chrome"):# 判断启动的浏览器,不区分大小写if browser_name.lower() == "chrome":options = webdriver.ChromeOptions()# 添加启动时最大化窗口的参数options.add_argument("--start-maximized")return webdriver.Chrome(options=options)elif browser_name.lower() == "firefox":options = webdriver.FirefoxOptions()options.add_argument("--start-maximized")return webdriver.Firefox(options=options)elif browser_name.lower() == "edge":options = webdriver.EdgeOptions()options.add_argument("--start-maximized")return webdriver.Edge(options=options)else:raise ValueError(f"不支持该浏览器: {browser_name}")conftest.py:
-
作用:用于设置和清理测试环境、初始化 WebDriver 实例等。
import allure import pytest from utils.driver_factory import get_driver# 在每个测试类之前执行一次,需要手动添加注解后才能生效 @pytest.fixture(scope="class") def setup(request):# 使用 get_driver 函数创建一个 WebDriver,可以根据需求修改浏览器类型# driver = get_driver(browser_name="chrome")driver = get_driver(browser_name="edge")# 将创建的 WebDriver 实例赋值给测试类,以便测试用例可以使用request.cls.driver = driver# yield 语句之前的代码是测试前置条件,yield 之后的代码是测试后置条件yielddriver.quit()# 在每个测试用例之前执行一次,不需要额外给测试用例添加注解 @pytest.fixture(autouse=True) def test_case_setup(request):# 将创建的 WebDriver 实例赋值给测试类,以便测试用例可以使用driver = get_driver(browser_name="chrome")request.cls.driver = driver# 打开指定链接driver.get("https://www.baidu.com")# yield 语句之前的代码是测试前置条件,yield 之后的代码是测试后置条件yield# 在测试用例执行完毕后,关闭浏览器并退出 WebDriverdriver.close()# 生成测试报告的钩子函数 @pytest.hookimpl(tryfirst=True, hookwrapper=True) def pytest_runtest_makereport(item, call):# 先执行测试outcome = yieldreport = outcome.get_result()# 如果测试失败并且是一个 "call" 状态(表示实际运行测试代码时出错)# if report.when == "call" and report.failed:# 测试通过或不通过都截图if report.when == "call":# 通过 request 对象获取 driver 实例driver = item.funcargs['request'].cls.driver# 截图并附加到 Allure 报告中try:allure.attach(driver.get_screenshot_as_png(),name="测试结果截图",attachment_type=allure.attachment_type.PNG)except Exception as e:# 将错误日志作为附件添加到 Allure 报告中allure.attach(f"截图失败: {e}",name="截图失败日志",attachment_type=allure.attachment_type.TEXT)
pytest.ini:
- 作用: 配置 pytest 的行为,包括指定测试目录、文件名模式、标记等。
[pytest]
# --continue-on-collection-errors 测试用例报错后,仍然继续运行
# --alluredir=./allure-results:指定生成的测试数据存储的位置
addopts = --continue-on-collection-errors --alluredir=./allure-results# 指定 pytest 搜索测试用例的根目录
# 所有测试文件和目录都会在 `tests` 目录下被自动发现和执行
testpaths = tests
# 指定测试文件的命名模式
# pytest 只会识别文件名以 `test_` 开头的 Python 文件作为测试文件
python_files = test_*.py# 指定测试类的命名模式
# pytest 只会识别以 `Test` 开头的类名作为测试类
python_classes = Test*# 指定测试函数的命名模式
# pytest 只会识别以 `test_` 开头的函数名作为测试函数
python_functions = test_*requirements.txt
-
作用:当前项目中所使用到的第三方库
allure-pytest==2.13.5 allure-python-commons==2.13.5 attrs==24.2.0 certifi==2024.7.4 cffi==1.17.0 colorama==0.4.6 exceptiongroup==1.2.2 h11==0.14.0 idna==3.7 iniconfig==2.0.0 outcome==1.3.0.post0 packaging==24.1 pluggy==1.5.0 pycparser==2.22 PySocks==1.7.1 pytest==8.3.2 selenium==4.23.1 sniffio==1.3.1 sortedcontainers==2.4.0 tomli==2.0.1 trio==0.26.2 trio-websocket==0.11.1 typing_extensions==4.12.2 urllib3==2.2.2 websocket-client==1.8.0 wsproto==1.2.0
运行
运行测试:
pytest
查看Allure测试报告
allure serve allure-results
测试报告示例

相关文章:
从〇 搭建PO模式的Web UI自动化测试框架
Page Object模式简介 核心思想 将页面元素和操作行为封装在独立的类中,形成页面对象(Page Object)。每个页面对象代表应用程序中的一个特定页面或组件。 优点: 代码复用性高 页面对象可以在多个测试用例中复用。 易于维护 …...

在Ubuntu中重装Vscode(没有Edit Configurations(JSON)以及有错误但不标红波浪线怎么办?)
在学习时需要将vscode删除重装,市面上很多方法都不能删干净,删除之后拓展都还在。因此下面的方法可以彻底删除。注意,我安装时使用的是snap方法。 如果你的VScode没有Edit Configurations(JSON),以及有错误但不标红波浪线的话&…...

Oracle 用户-表空间-表之间关系常用SQL
问题: 当某一个表数据量特别大,突然插入数据一直失败,可能是表空间不足,需要查看表的使用率 用户-表空间-表之间关系:用户可以有多个表空间,表空间可以有多个表,表只能拥有一个表空间和用户 1.…...
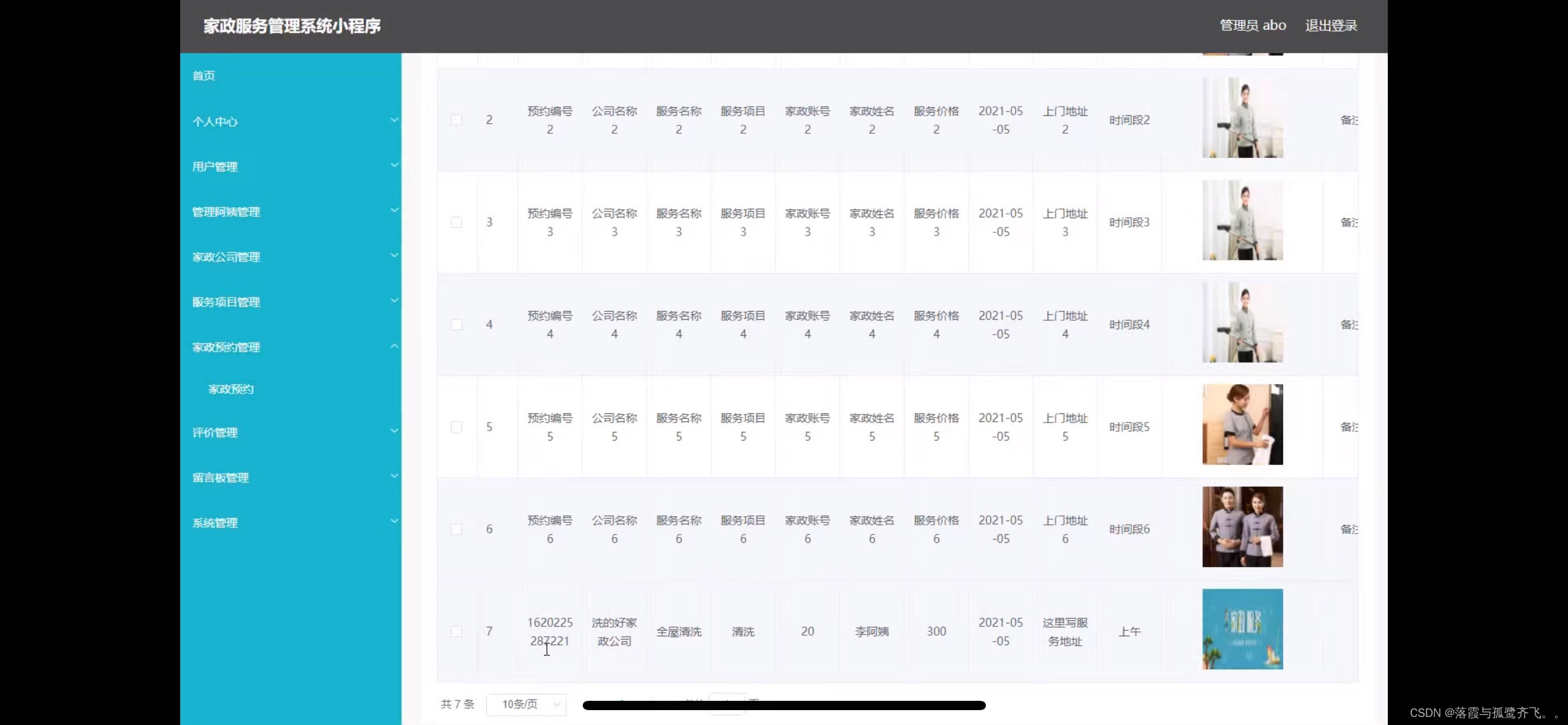
家政服务管理系统小程序的设计
管理员账户功能包括:系统首页,个人中心,用户管理,管理阿姨管理,家政公司管理,服务项目管理,家政预约管理,评价管理,留言板管理,系统管理 微信端账号功能包括…...

【算法】并查集的介绍与使用
1.并查集的概论 定义: 并查集是一种树型的数据结构,用于处理一些不相交集合的合并及查询问题(即所谓的并、查)。比如说,我们可以用并查集来判断一个森林中有几棵树、某个节点是否属于某棵树等。 主要构成: …...

Shell——运算符
在 Shell 编程中,运算符用于执行各种类型的操作,如算术运算、字符串比较、文件测试等。以下是 Shell 中常用的运算符分类和示例: 1. 算术运算符 Shell 中使用 expr 或 $(( ... )) 来进行算术运算。 : 加法-: 减法*: 乘法/: 除法%: 取余**:…...
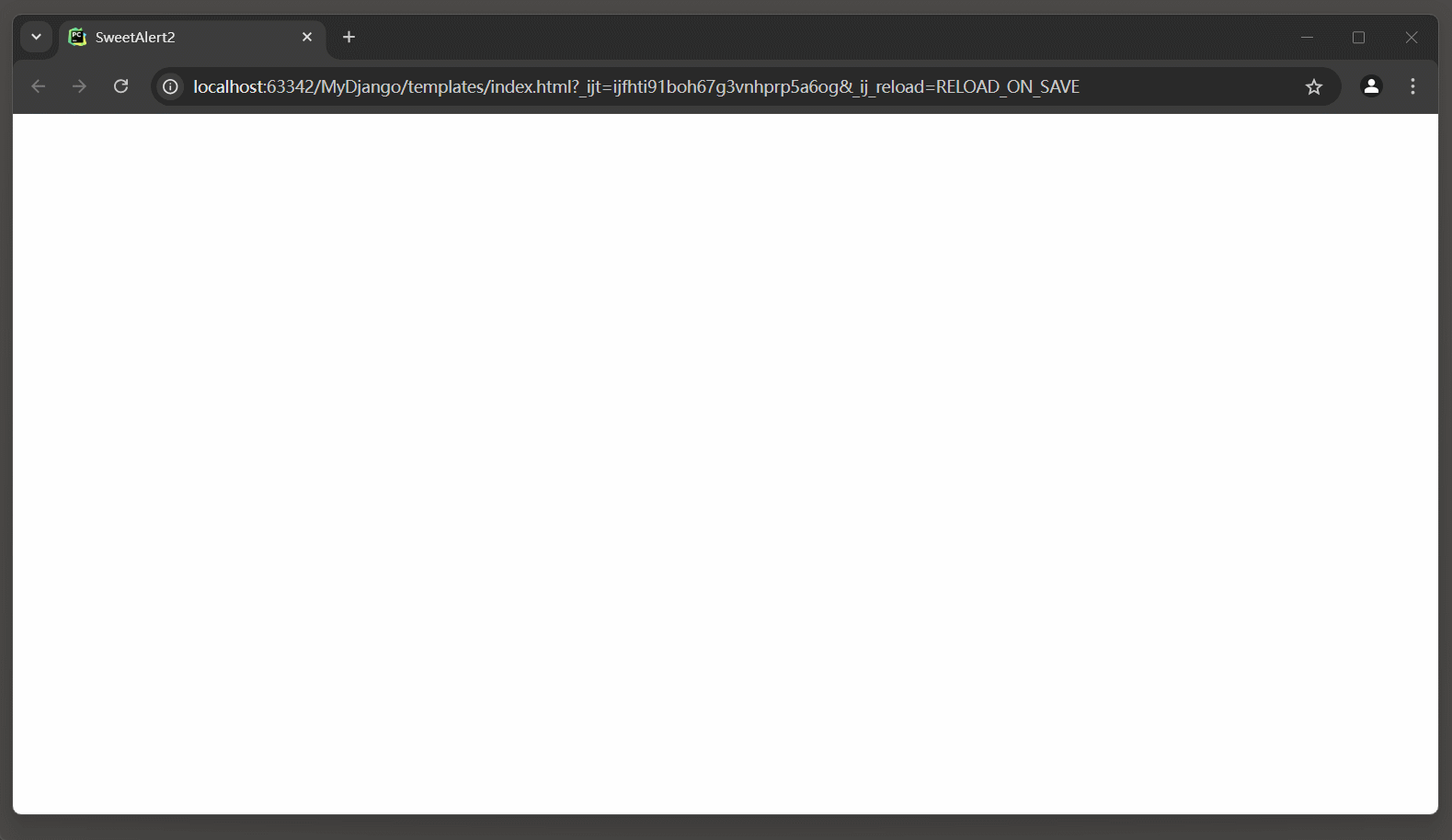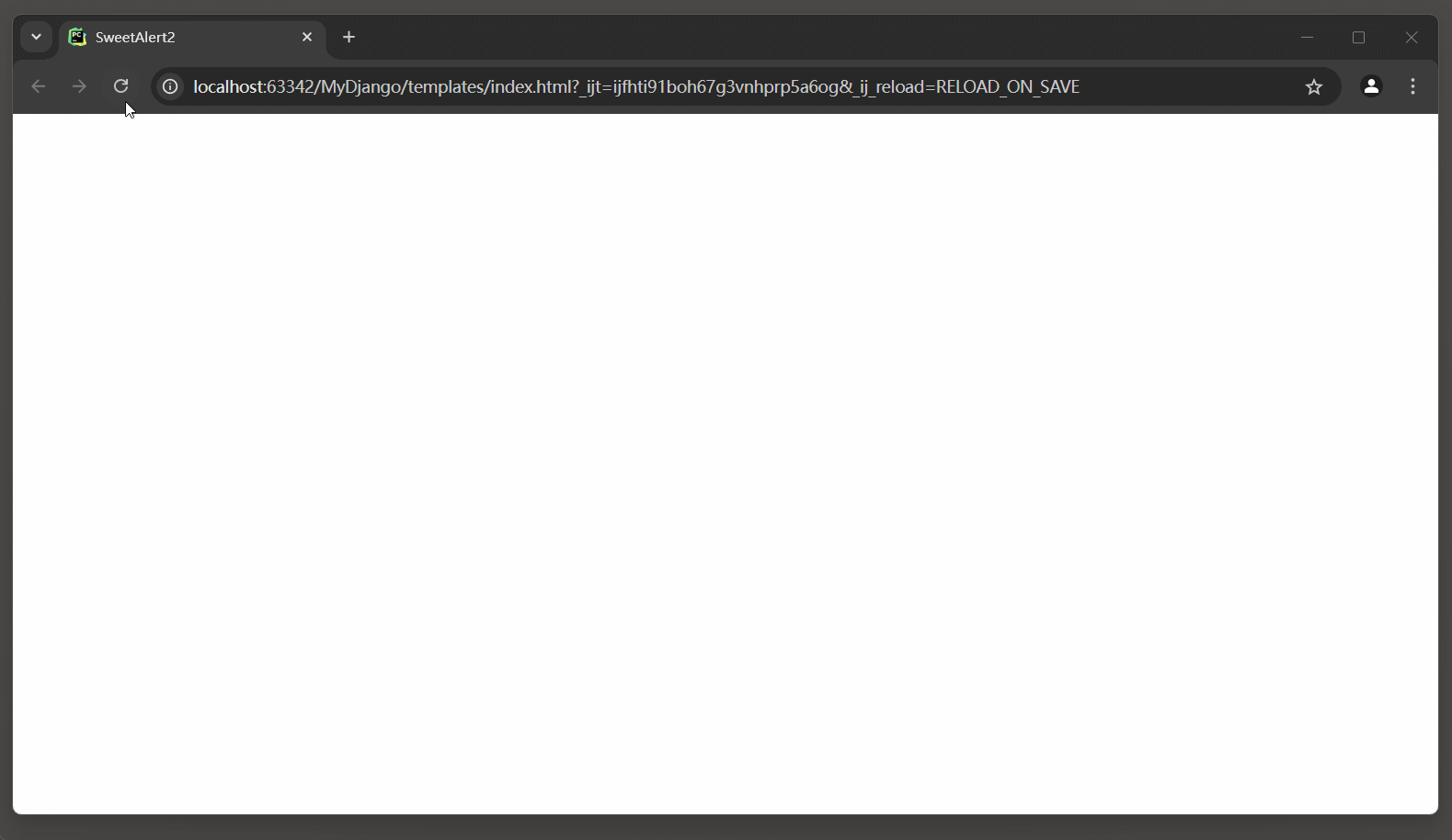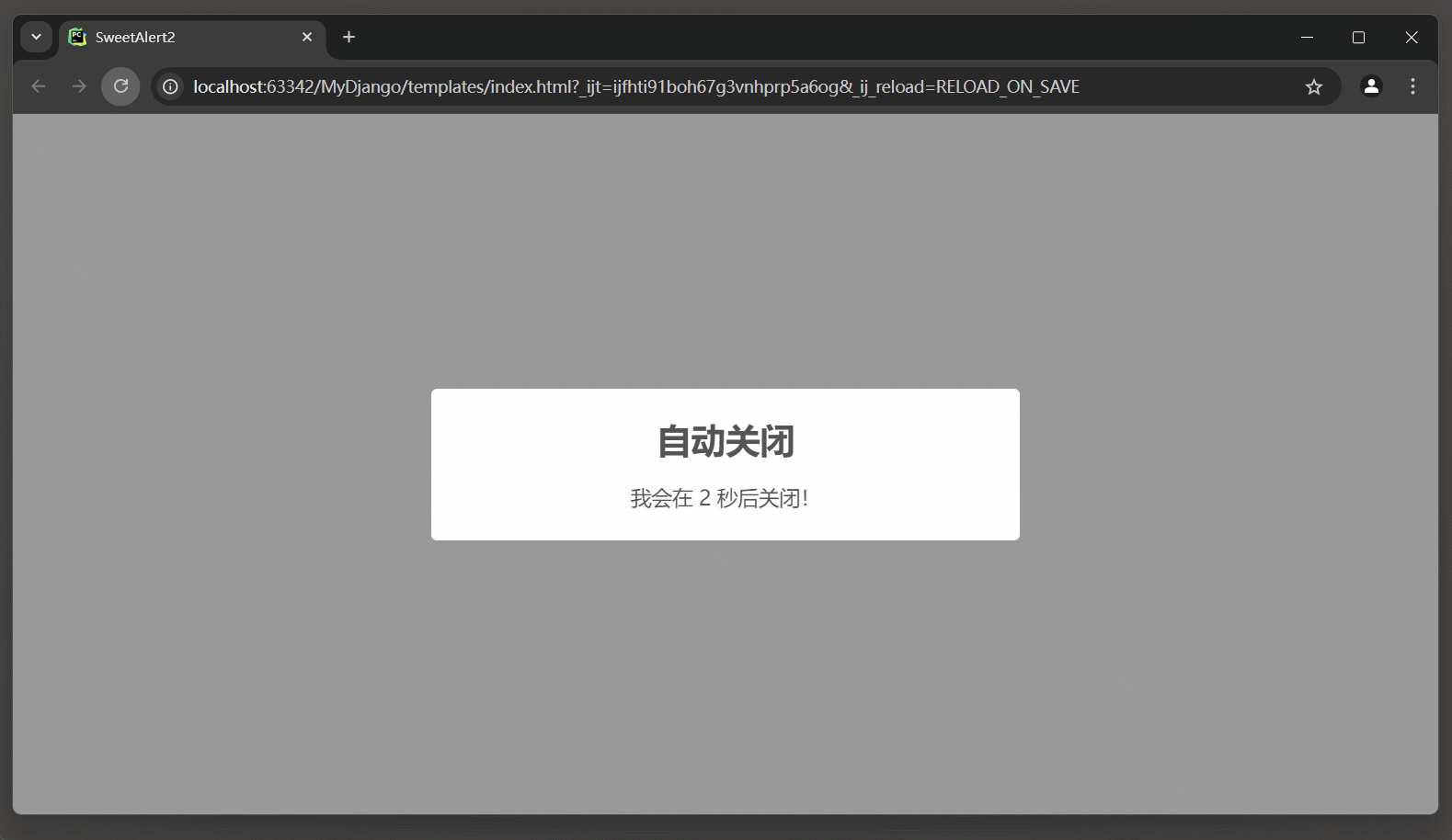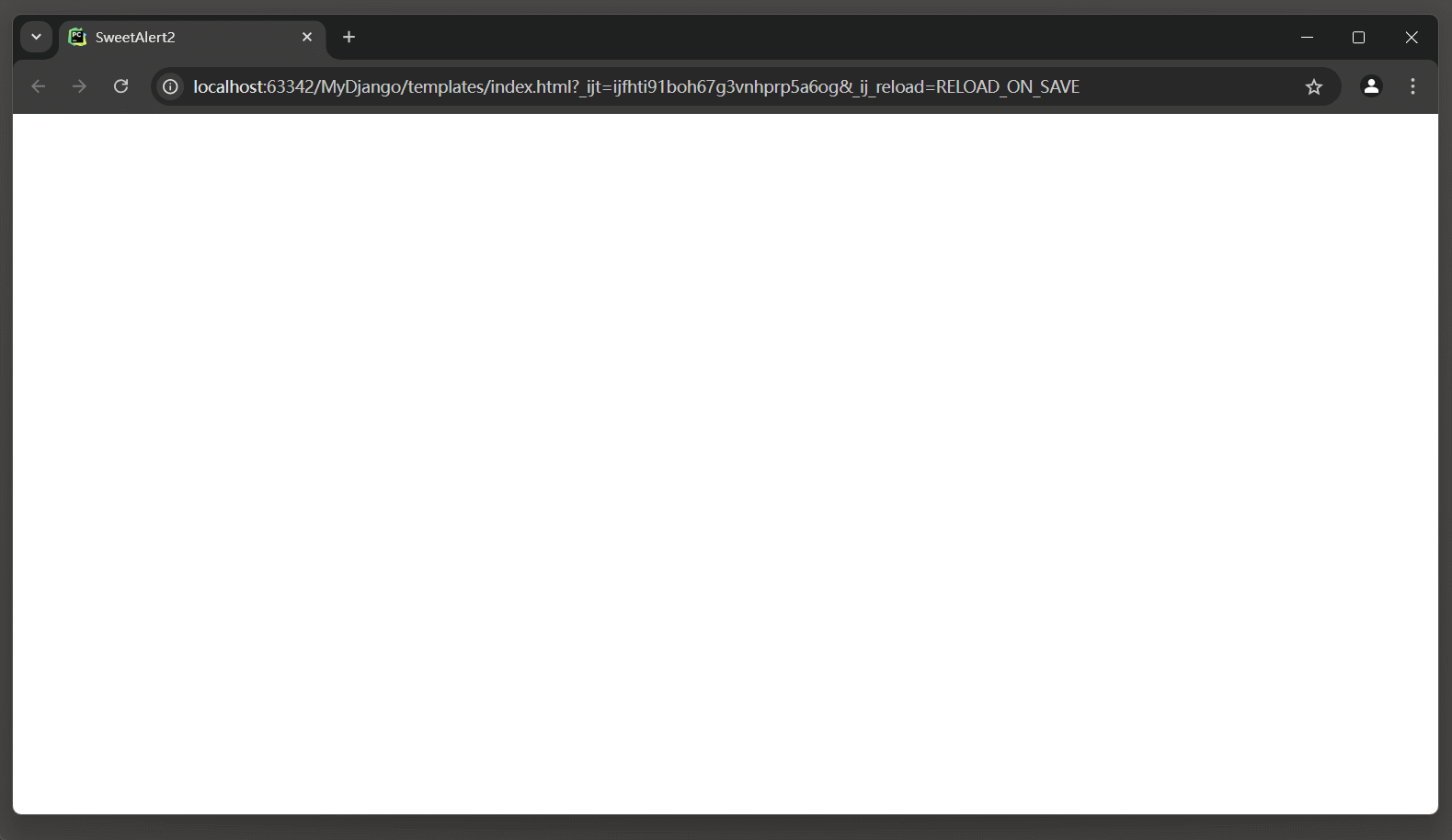
SweetAlert2
1. SweetAlert2 SweetAlert2是一个基于JavaScript的库, 用于在网页上替换标准的警告框(alert), 确认框(confirm)和提示框(prompt), 并提供更加美观和用户友好的界面.需要在项目中引入SweetAlert2, 可以通过CDN链接或者将库文件下载到你的项目中来实现这一点. 通过CDN引入:<…...

c语言中比较特殊的输入函数
目录 一.getchar()函数 1.基本功能 2.使用方法 (1).读取单个字符 (2).读取多个字符(直到遇到换行符) (3).处理输入中的空白字符 3.返回值 4.应用场景 5.注意事项 二.fgets()函数 1.函数原型 2.工作原理 3.使用示例 (1).从标准输入读取一行…...

Java版自动化测试之Selenium
1. 准备 编程语言:Java JDK版本:17 Maven版本:3.6.1 2. 开始 声明:本次只测试Java的Selenium自动化功能 本次示例过程:打开谷歌游览器,进入目标网址,找到网页的输入框元素,输入指…...

【计算机网络】——计算机网络的性能指标
速率(speed) 连接在计算机网络上的主机在数字信道上传送数据的速率。 影响条件: 带宽(band width) 指在固定的时间可传输的资料数量 单位:bps或HZ 吞吐量(throughtput) 指对网络、…...

MongoDB数据类型介绍
MongoDB作为一种高性能、开源、无模式的文档型数据库,支持丰富的数据类型,以满足各种复杂的数据存储需求。本文将详细介绍MongoDB支持的主要数据类型,包括数值类型、字符串类型、日期和时间类型、布尔类型、二进制类型、数组、对象以及其他扩…...

【SpringBoot】SpringBoot 中 Bean 管理和拦截器的使用
目录 1.Bean管理 1.1 自定义Bean对象 1.2 Bean的作用域和生命周期 2.拦截器的使用 1.Bean管理 默认情况下,Spring项目启动时,会把我们常用的Bean都创建好放在IOC容器中,但是有时候我们自定义的类需要手动配置bean,这里主要介绍…...

Spring IoCDI(中)--IoC的进步
通过上文的讲解和学习, 我们已经知道了Spring IoC 和DI的基本操作, 接下来我们来系统的学习Spring IoC和DI 的操作. 前⾯我们提到IoC控制反转,就是将对象的控制权交给Spring的IOC容器,由IOC容器创建及管理对 象,也就是bean的存储。 1. Bean的…...

读软件开发安全之道:概念、设计与实施02经典原则
1. CIA原则 1.1. 软件安全都构建在信息安全的三大基本原则之上,即机密性(confidentiality)、完整性(integrity)和可用性(availability) 1.2. 双方交换的数据 1.2.1. 从技术上看,端点之间的数据交换本身就会削弱交互的机密性 1.2.2. 隐藏通信数据量的一…...

MySQL中处理JSON数据:大数据分析的新方向,详解与示例
文章目录 1. MySQL中的JSON数据类型2. JSON函数和运算符3. 创建JSON列的表4. 插入JSON数据5. 查询JSON数据6. 复杂查询和聚合7. JSON 数据的索引8. 总结 在当今的大数据时代,JSON(JavaScript Object Notation)作为一种轻量级的数据交换格式&a…...

【图形学】TA之路-矩阵
在 Unity 中,矩阵广泛用于处理各种图形变换,例如平移、旋转、缩放等。矩阵的使用不仅限于三维空间,还可以应用于二维空间的操作。了解矩阵及其运算对于游戏开发和计算机图形学非常重要。Unity 中使用的是行向量不是列向量,这个要注…...

LAMM: Label Alignment for Multi-Modal Prompt Learning
系列论文研读目录 文章目录 系列论文研读目录文章题目含义AbstractIntroductionRelated WorkVision Language ModelsPrompt Learning MethodologyPreliminaries of CLIPLabel AlignmentHierarchical Loss 分层损失Parameter Space 参数空间Feature Space 特征空间Logits Space …...

mac编译opencv 通用架构库的记录
1,通用架构 (x86_64;arm64)要设置的配置项: CPU_BASELINE CPU_DISPATCH 上面这两个我设置成SSE_3,其他选项未尝试,比如不设置。 CMAKE_OSX_ARCHITECTURES:x86_64;arm64 WITH_IPP:不勾选 2,contrib库的添加: 第一次…...

Python 向IP地址发送字符串
Python 向IP地址发送字符串 在网络编程中,使得不同设备间能够进行数据传输是一项基本任务。Python提供了强大的库,帮助开发者轻松地实现这种通信。本文将介绍如何使用Python通过UDP协议向特定的IP地址发送字符串信息。 UDP协议简介 UDP(用…...

上升响应式Web设计:纯HTML和CSS的实现技巧-1
响应式Web设计(Responsive Web Design, RWD)是一种旨在确保网站在不同设备和屏幕尺寸下都能良好运行的网页设计策略。通过纯HTML和CSS实现响应式设计,主要依赖于媒体查询(Media Queries)、灵活的布局、可伸缩的图片和字…...

Driver Store Explorer:3步快速清理Windows驱动垃圾,释放数十GB磁盘空间终极指南
Driver Store Explorer:3步快速清理Windows驱动垃圾,释放数十GB磁盘空间终极指南 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你是否经常发现Windows系统盘空…...

基于OpenClaw/QClaw与LLM的Reddit智能摘要系统构建实战
1. 项目概述与核心价值如果你和我一样,每天泡在Reddit和各种技术社区里,试图从海量的帖子、评论和新闻中淘出真正有价值的信息,那你一定体会过那种“信息过载”的无力感。首页永远刷不完,热帖里夹杂着大量水贴和重复讨论ÿ…...

C语言完美演绎8-17
/* 范例:8-17 */#include <stdio.h>void func(char *i,int j){printf("%d 以%s方式来调用函数指针\n",j,i);}void main(void){void (*pfun)(char *a, int b); /* 定义pfun函数指针 */pfunfunc; /* 将函数func()的地址赋值给函数指针pfun */(*pf…...
)
RWKV7-1.5B-world一文详解:1.5B参数如何兼顾双语能力与3GB显存效率(附技术栈清单)
RWKV7-1.5B-world一文详解:1.5B参数如何兼顾双语能力与3GB显存效率(附技术栈清单) 1. 模型概述 RWKV7-1.5B-world是基于第7代RWKV架构的轻量级双语对话模型,拥有15亿参数。该模型采用创新的线性注意力机制替代传统Transformer的…...

AI数学自动评估技术解析与应用实践
1. 项目背景与核心价值数学自动评估技术正在彻底改变教育测评领域的工作方式。传统人工批改数学作业的方式存在效率低下、标准不统一等问题,而基于AI的自动评估系统能够实现秒级反馈,大幅提升教学效率。Omni-MATH-2作为当前最全面的开放数学评估数据集&a…...

用Matplotlib做数据分析报告?手把手教你定制带误差棒的分组柱状图
科研级数据可视化:用Matplotlib打造带误差棒的分组柱状图 实验室里堆积如山的实验数据,产品迭代时密密麻麻的A/B测试结果,学术论文中需要严谨呈现的统计指标——这些场景都需要一种既能清晰对比多组数据,又能直观展示数据可靠性的…...

Claude Max Proxy:突破OAuth限制,实现OpenAI API生态下的完整工具调用
1. 项目概述:Claude Max Proxy 是什么,以及它解决了什么问题如果你和我一样,订阅了 Claude Max,并且眼馋 OpenAI API 那种灵活、标准化的工具调用能力,那你肯定也踩过同样的坑。Claude Max 的 OAuth 令牌,虽…...

VSCode主题设计实战:从JetBrains Abyss到JD‘s Abyss的色彩迁移与深度定制
1. 项目概述:从JetBrains到VSCode的视觉迁徙如果你和我一样,长期在JetBrains家族的IDE(比如IntelliJ IDEA、PyCharm)里“搬砖”,大概率会对Gerry‘s Abyss这款深色主题印象深刻。它那种深邃的蓝紫色背景,配…...

使用CGAL构建完美球体网格
在计算机图形学和几何处理中,构建高质量的球体网格(sphere mesh)是许多应用的基础。CGAL(Computational Geometry Algorithms Library)提供了丰富的工具来处理几何问题。本文将详细介绍如何使用CGAL中的SurfaceMesh数据结构来生成一个规则的球体网格,并展示如何通过Loop细…...

6条Claude Code实践中的经验与思考
Claude Code系列回顾 目前在实践和应用Claude Code,顺便分享一些在实践过程中的经验,没想竟然写成一个系列了。如果你也对Claude Code感兴趣,可以先回顾一下之前的文章,然后开始今天的文章。 第1篇:《国内环境下的Cl…...