Selenium自动化防爬技巧:从入门到精通,保障爬虫稳定运行,通过多种方式和add_argument参数设置来达到破解防爬的目的
在Web自动化测试和爬虫开发中,Selenium作为一种强大的自动化工具,被广泛用于模拟用户行为、数据抓取等场景。然而,随着网站反爬虫技术的日益增强,直接使用Selenium很容易被目标网站识别并阻止。因此,掌握Selenium的防爬策略与参数设置变得尤为重要。本文将详细介绍几种常见的Selenium防爬方法,并列出关键的防爬参数,同时提供详细的代码案例。
关于Selenium防止被检测到实战可以参考这几篇文章:
selenium实战指南:如何防止被浏览器检测?_selenium防止被检测-CSDN博客
Selenium自动化爬取BOSS招聘数据:一个完整的指南(实测有效)_selenium爬取并存储boss网站招聘数据过程-CSDN博客
Selenium实战:深度解析Python中嵌套Frame与iFrame的定位与切换技巧,解决Selenium定位不到的问题-CSDN博客
一、Selenium防爬方法概述
1. 修改User-Agent
User-Agent是浏览器向服务器发送请求时携带的一种标识,通过修改它可以使Selenium的请求看起来更像是来自真实用户的浏览器。
2. 设置浏览器窗口大小
一些网站会通过检测浏览器窗口大小来判断是否为自动化脚本。设置合理的窗口大小可以使请求更加自然。
3. 禁用图片加载
加载图片会增加请求次数和响应时间,同时也可能暴露自动化脚本的特征。禁用图片加载可以加快请求速度并减少被识别的风险。
4. 使用代理IP
频繁使用同一IP地址进行请求容易被目标网站封禁。使用代理IP可以隐藏真实IP地址,增加请求的匿名性。
5. 模拟用户行为
通过模拟真实的用户行为(如点击、滚动、等待等)来减少被识别的风险。
6. 增加请求间隔
合理的请求间隔可以减少对目标网站服务器的压力,并降低被识别为爬虫的风险。
二、Selenium防爬设置
1. 修改User-Agent
在Selenium中,可以通过设置ChromeOptions或FirefoxOptions来修改User-Agent。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options# Chrome浏览器
chrome_options = Options()
chrome_options.add_argument('user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36')
driver = webdriver.Chrome(options=chrome_options)# Firefox浏览器(类似设置)
# from selenium.webdriver.firefox.options import Options
# firefox_options = Options()
# firefox_options.add_argument('--user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36')
# driver = webdriver.Firefox(options=firefox_options)2. 设置浏览器窗口大小
driver.set_window_size(1280, 1024) # 设置浏览器窗口大小为1280x10243. 禁用图片加载(Chrome为例)
chrome_prefs = {}
chrome_options.add_experimental_option("prefs", chrome_prefs)
chrome_prefs["profile.default_content_settings.images"] = 2 # 2代表禁用图片注意:Chrome的最新版本可能不支持通过这种方法直接禁用图片加载,需要寻找其他方法或使用浏览器插件。
4. 使用代理IP(需额外库支持,如selenium-wire)
由于Selenium本身不直接支持代理设置,可以使用第三方库如selenium-wire来实现。
from seleniumwire import webdriverdriver = webdriver.Chrome()
driver.options.add_argument('--proxy-server=http://your-proxy-server:port')
# 注意:selenium-wire的使用方式可能与原生Selenium有所不同,具体请参考其文档5. 模拟用户行为(示例:模拟点击)
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC# 假设已经定位到一个可点击的元素
element = driver.find_element(By.ID, "clickable-element")
element.click()# 等待页面加载完成(示例)
wait = WebDriverWait(driver, 10)
wait.until(EC.visibility_of_element_located((By.ID, "some-other-element")))6. 增加请求间隔
增加请求间隔是防止因过于频繁地发送请求而被目标网站识别为爬虫的有效手段。在Selenium脚本中,你可以使用Python的time模块中的sleep()函数来实现这一点。然而,过度依赖sleep()可能会导致脚本运行效率低下,因为无论目标网站是否已准备好响应,脚本都会等待指定的时间。
一个更优化的做法是使用Selenium的显式等待(Explicit Wait)功能,它允许你等待某个条件成立后再继续执行脚本,而不是简单地等待一段时间。显式等待通过WebDriverWait类和一系列预定义的等待条件(如元素可见性、可点击性等)来实现。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import timedriver = webdriver.Chrome()
driver.get("你的网页URL")# 使用显式等待等待某个元素可见
try:element = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.ID, "someElementId")))# 对元素进行操作...element.click()
except Exception as e:print(e)# 在需要的时候使用time.sleep()增加额外的延迟
# 例如,在两次请求之间等待
time.sleep(2) # 等待2秒# 继续执行其他操作...# 脚本结束前关闭浏览器
driver.quit()7. 伪装浏览器指纹
浏览器指纹是指浏览器在访问网站时展现的一系列特征,如操作系统、浏览器类型、分辨率、字体列表、插件列表等。这些特征可以被网站用来识别用户或区分爬虫与真实用户。为了伪装浏览器指纹,可以使用一些高级技术,如使用Selenium WebDriver的模拟浏览器指纹插件或自行修改WebDriver的源代码。
然而,这些方法通常比较复杂且需要较高的技术门槛,且随着网站反爬虫技术的升级,伪装浏览器指纹的有效性也会逐渐降低。
8. 遵守robots.txt协议
虽然Selenium主要用于自动化测试和爬虫开发,但如果你正在使用Selenium来抓取网站数据,那么遵守该网站的robots.txt协议是非常重要的。robots.txt文件是一个文本文件,它告诉搜索引擎哪些页面可以抓取,哪些不可以。虽然robots.txt协议主要针对搜索引擎,但遵守它也是对网站所有者权益的尊重,并有助于避免法律纠纷。
9. 监控与调试
在开发Selenium脚本时,监控和调试是必不可少的环节。你可以使用Selenium的日志功能来记录脚本运行过程中的详细信息,或者使用浏览器的开发者工具来调试页面和脚本。此外,还可以使用一些第三方工具来监控网络请求和响应,以便及时发现和解决问题。
三、Selenium自动化防爬参数配置
为了避免Chrome浏览器在自动化测试时显示被控制的提示,可以通过配置add_argument来实现。
1、禁用自动化检测功能:
import time
from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.chrome.options import Optionschrome_options = Options()
# 禁用浏览器自动化检测功能,使浏览器无法检测到它是被自动化工具控制的。
chrome_options.add_argument("--disable-blink-features=AutomationControlled")
# 启动Chrome浏览器
driver = webdriver.Chrome(options=chrome_options)
#打开网站
driver.get('https://www.baidu.com/')
#等待10秒(非必须,只是为了演示)
time.sleep(10)
# 关闭浏览器
driver.quit()"--disable-blink-features=AutomationControlled" 是一个传递给Chrome浏览器的命令行参数,其目的是为了绕过或禁用Chrome浏览器内置的一种自动化检测机制。
Chrome浏览器(及其底层的Blink渲染引擎)包含一些用于检测浏览器是否被自动化工具(如Selenium WebDriver)控制的特性。这些特性可以帮助网站区分真正的用户访问和自动化脚本的访问。当检测到自动化工具时,网站可能会采取一些措施,如限制访问、增加验证码等,来防止自动化脚本的滥用。
"--disable-blink-features=AutomationControlled" 参数的作用就是尝试禁用这种自动化检测特性。通过禁用这个特性,你的Selenium自动化脚本可能能够更顺利地模拟用户行为,而不被网站的反爬机制轻易识别出来。
然而,需要注意的是,这种方法的有效性可能会随着Chrome浏览器版本的更新而变化。Chrome浏览器的开发者可能会修复或改进这些特性,以更好地检测和阻止自动化脚本。因此,如果你发现这个参数不再有效,可能需要寻找其他方法或等待Selenium的更新来支持新的反检测策略。
2、禁用Chrome的自动化扩展:
import time
from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
# 禁用Chrome的自动化扩展,这有助于减少被检测到的风险。
chrome_options.add_experimental_option('useAutomationExtension', False)
# 启动Chrome浏览器
driver = webdriver.Chrome(options=chrome_options)
#打开网站
driver.get('https://www.baidu.com/')
#等待10秒(非必须,只是为了演示)
time.sleep(10)
# 关闭浏览器
driver.quit()useAutomationExtension的作用是尝试禁用或绕过浏览器内部与自动化工具检测相关的某种机制或扩展。通过将 useAutomationExtension 设置为 False,代码试图告诉浏览器不要使用或加载与自动化控制相关的特定扩展或功能。
3、关闭浏览器显示正受到自动化的控制
使用参数之前

使用参数之后
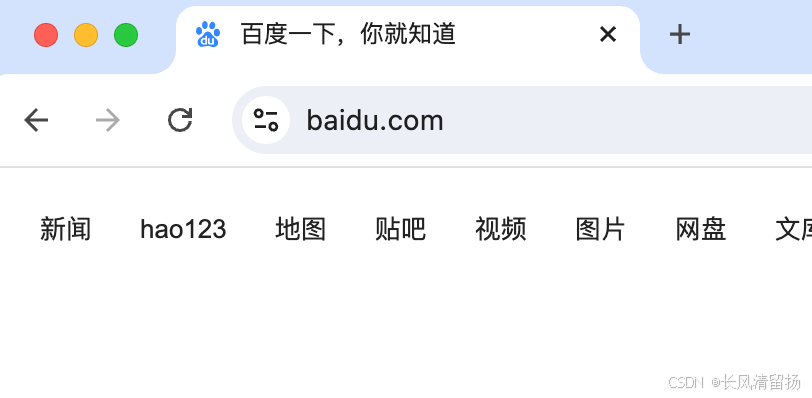
浏览器不再显示正受到自动测试软件的控制
import time
from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
# 从Chrome的启动参数中排除enable-automation开关,进一步防止浏览器显示被控制的提示。
chrome_options.add_experimental_option('excludeSwitches', ['enable-automation'])
# 启动Chrome浏览器
driver = webdriver.Chrome(options=chrome_options)
#打开网站
driver.get('https://www.baidu.com/')
#等待10秒(非必须,只是为了演示)
time.sleep(10)
# 关闭浏览器
driver.quit()enable-automation是Chrome的一个内部标志,当ChromeDriver启动Chrome浏览器时,它通常会被自动启用。这个标志的存在可能会告诉网站或网页上的脚本,浏览器正在被自动化工具控制。一些网站会使用这种检测机制来阻止自动化脚本的执行,或者提供与正常用户不同的体验。
通过excludeSwitches选项排除enable-automation,你试图让浏览器在启动时表现得更加“正常”,即不向网站透露它正在被自动化工具控制。这有助于绕过一些基于enable-automation标志存在的自动化检测机制。
然而,需要注意的是,这种方法的有效性可能会随着Chrome和ChromeDriver的更新而发生变化。浏览器开发者可能会不断改进其自动化检测机制,使得基于排除特定开关的方法来绕过检测变得不再有效。
4、启用无头模式:
import time
from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
# 启用无头模式,使Chrome在后台运行,没有可视化窗口。这不仅可以避免被检测,还可以提高测试效率,因为不需要加载和渲染UI界面。
chrome_options.add_argument("--headless")
# 启动Chrome浏览器
driver = webdriver.Chrome(options=chrome_options)
#打开网站
driver.get('https://www.baidu.com/')
#等待10秒(非必须,只是为了演示)
time.sleep(10)
# 关闭浏览器
driver.quit()"--headless" 是一个命令行参数,用于指示浏览器在无头(headless)模式下运行。在无头模式下,浏览器不会显示图形用户界面(GUI),即它不会在屏幕上显示窗口。这意味着浏览器可以在没有物理显示的情况下运行,这对于自动化测试、服务器端渲染、爬虫等场景非常有用,因为它们不需要图形界面来执行任务。
使用 options.add_argument("--headless") 配置浏览器后,当你启动浏览器时,它将在无头模式下运行,执行你指定的任务,但不会显示任何窗口或界面。这对于自动化脚本来说非常有用,因为它可以减少对系统资源的需求(如屏幕和图形处理),并且可以在没有图形界面的服务器或容器中运行。
5、禁用GPU加速:
import time
from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
# 在某些情况下,特别是Linux系统上,可能需要禁用GPU加速,以确保无头模式能正常工作。
chrome_options.add_argument("--disable-gpu")
# 启动Chrome浏览器
driver = webdriver.Chrome(options=chrome_options)
#打开网站
driver.get('https://www.baidu.com/')
#等待10秒(非必须,只是为了演示)
time.sleep(10)
# 关闭浏览器
driver.quit()"--disable-gpu" 是一个命令行参数,用于指示Chrome浏览器在启动时禁用GPU加速。GPU加速是浏览器利用计算机的图形处理单元(GPU)来加速页面渲染和图形密集型任务的过程。然而,在某些情况下,GPU加速可能会导致问题,如性能下降、崩溃或渲染错误。
通过在ChromeOptions中添加"--disable-gpu"参数,你告诉浏览器在启动时不要使用GPU加速。这通常用于解决与GPU相关的兼容性问题或性能问题,特别是在自动化测试、远程桌面会话、虚拟机或某些特定的硬件配置上。
四、结尾
通过这篇文章给大家分享我在学习过程中的一些经验和心得,希望能够对大家有所帮助,同时也接受大家的建议和意见,共同进步、共同学习。
如果你觉得我的文章对你有所帮助,我诚挚地邀请你关注、点赞和分享。
相关文章:
Selenium自动化防爬技巧:从入门到精通,保障爬虫稳定运行,通过多种方式和add_argument参数设置来达到破解防爬的目的
在Web自动化测试和爬虫开发中,Selenium作为一种强大的自动化工具,被广泛用于模拟用户行为、数据抓取等场景。然而,随着网站反爬虫技术的日益增强,直接使用Selenium很容易被目标网站识别并阻止。因此,掌握Selenium的防爬…...
从数据类型到变量、作用域、执行上下文
从数据类型到变量、作用域、执行上下文 JS数据类型 分类 1》基本类型:字符串String、数字Number、布尔值Boolean、undefined、null、symbol、bigint 2》引用类型:Object (Object、Array、Function、Date、RegExp、Error、Arguments) Symbol是ES6新出…...

一文读懂:AI时代到底需要什么样的网络?
各位小伙伴们大家好哈,我是老猫。 今天跟大家来聊聊数据中心网络。 提到网络,通常把网络比作高速公路,网卡相当于上下高速公路的闸口,数据包就相当于运送数据的汽车,交通法规就是“传输协议”。 如高速公路也会堵车一…...

基于HarmonyOS的宠物收养系统的设计与实现(一)
基于HarmonyOS的宠物收养系统的设计与实现(一) 本系统是简易的宠物收养系统,为了更加熟练地掌握HarmonyOS相关技术的使用。 项目创建 创建一个空项目取名为PetApp 首页实现(组件导航使用) 官方文档:组…...

严格模式报错
部分参考: Android内存泄露分析之StrictMode - 星辰之力 - 博客园 (cnblogs.com)...

nginx: [emerg] the “ssl“ parameter requires ngx_http_ssl_module in nginx.conf
nginx: [emerg] the "ssl" parameter requires ngx_http_ssl_module in /usr/local/nginx/conf/nginx.conf:42 查看/usr/local/nginx/conf/nginx.conf文件第42行数据: listen 443 ssl; # server中的配置 原因是:nginx缺少 http_ssl_modul…...

Docker 部署loki日志 用于微服务
因为每次去查看日志都去登录服务器去查询相关日志文件,还有不同的微服务,不同日期的文件夹,超级麻烦,因为之前用过ELK,原本打算用ELK,在做技术调研的时候发现了一个轻量级的日志系统Loki,果断采…...

[Day 57] 區塊鏈與人工智能的聯動應用:理論、技術與實踐
區塊鏈的零知識證明技術 一、引言 隨著區塊鏈技術的不斷發展,如何在保護用戶隱私的同時確保數據的完整性和可信度成為了研究的焦點。零知識證明(Zero-Knowledge Proof,ZKP)技術就是其中的一項關鍵技術,它允許一方在不…...

06结构型设计模式——代理模式
一、代理模式简介 代理模式(Proxy Pattern)是一种结构型设计模式(GoF书中解释结构型设计模式:一种用来处理类或对象、模块的组合关系的模式),代理模式是其中的一种,它可以为其他对象提供一种代…...

《深入浅出多模态》(九)多模态经典模型:MiniGPT-v2、MiniGPT5
🎉AI学习星球推荐: GoAI的学习社区 知识星球是一个致力于提供《机器学习 | 深度学习 | CV | NLP | 大模型 | 多模态 | AIGC 》各个最新AI方向综述、论文等成体系的学习资料,配有全面而有深度的专栏内容,包括不限于 前沿论文解读、资料共享、行业最新动态以、实践教程、求职…...

调试和优化大型深度学习模型 - 0 技术介绍
调试和优化大型深度学习模型 - 0 技术介绍 flyfish LLaMA Factory LLaMA Factory 是一个简单易用且高效的大型语言模型(Large Language Model)训练与微调平台。通过 LLaMA Factory,可以在无需编写任何代码的前提下,在本地完成上…...

华为S3700交换机配置VLAN的方法
1.VLAN的详细介绍 VLAN(Virtual Local Area Network)即虚拟局域网,是一种将一个物理的局域网在逻辑上划分成多个广播域的技术。 1.1基本概念 1)作用: 隔离广播域:通过将网络划分为不同的 VLAN,广播帧只会在同一 VLAN 内传播,而不会扩散到其他 VLAN 中,从而有效…...
:深入详解C++网络编程:套接字(Socket)开发技术)
学懂C++(三十八):深入详解C++网络编程:套接字(Socket)开发技术
目录 一、概述与基础概念 1.1 套接字(Socket)概念 1.2 底层原理与网络协议 1.2.1 网络协议 1.2.2 套接字工作原理 二、C套接字编程核心技术 2.1 套接字编程的基本步骤 2.2 套接字编程详细实现 2.2.1 创建套接字 2.2.2 绑定地址 2.2.3 监听和接…...

SpringBoot-配置加载顺序
目录 前言 样例 内部配置加载顺序 样例 小结 前言 我之前写的配置文件,都是放在resources文件夹,根据当前目录下,优先级的高低,判断谁先被加载。但实际开发中,我们写的配置文件并不是,都放…...

第八周:机器学习笔记
第八周机器学习笔记 摘要Abstract机器学习1. 鱼和熊掌和可兼得的机器学习1.1 Deep network v.s. Fat network 2. 为什么用来验证集结果还是不好? Pytorch学习1. 卷积层代码实战2. 最大池化层代码实战3. 非线性激活层代码实战 总结 摘要 本周学习对李宏毅机器学习视…...

音乐怎么剪切掉一部分?5个方法,轻松学会音频分割!(2024全新)
音乐怎么剪切掉一部分?音频文件是娱乐和创作的重要基础。音频在我们日常生活中发挥着重要作用,从音乐播放列表到有趣的视频,它无处不在。无论是音乐爱好者还是内容创作者,我们常常需要对音频文件进行剪切和编辑。想象一下…...

洛谷 CF295D Greg and Caves
题目来源于:洛谷 题目本质:动态规划dp,枚举 解题思路:将整个洞分成两半,一半递增,一半递减。我们分别 DP 求值,最后合并。状态转移方程为:dpi,jk2∑j(j−k1)dpi−1,k1。枚举极…...

【图像处理】在图像处理算法开发中,有哪些常见的主观评价指标和客观评价指标?
主观评价指标 在图像处理算法开发中,主观评价指标依赖于观察者的个人感受和判断,通常用于评估图像的视觉质量。以下是一些常见的主观评价指标: 平均意见分数 (Mean Opinion Score, MOS):通过收集多个评价者的评分并计算平均值来评…...

从零开始学cv-6:图像的灰度变换
文章目录 一,简介:二、图像的线性变换三、分段线性变换四,非线性变换4.1 对数变换4.2 Gamma变换 五,效果: 一,简介: 图像灰度变换涉及对图像中每个像素的灰度值执行数学运算,进而调整图像的视觉…...
使用Apache POI和POI-OOXML实现word模板文档自动填充功能
最近接到一个新的需求,用户创建好模板文件保存到模板库,然后使用在线文档编辑器打开模板时,将系统数据填充到模板文件并生成新的word文件,然后在线编辑,研究使用Apache POI和POI-OOXML实现了这个功能。 Maven依赖 <…...

SkyWalking 10.2.0 SWCK 配置过程
SkyWalking 10.2.0 & SWCK 配置过程 skywalking oap-server & ui 使用Docker安装在K8S集群以外,K8S集群中的微服务使用initContainer按命名空间将skywalking-java-agent注入到业务容器中。 SWCK有整套的解决方案,全安装在K8S群集中。 具体可参…...

VB.net复制Ntag213卡写入UID
本示例使用的发卡器:https://item.taobao.com/item.htm?ftt&id615391857885 一、读取旧Ntag卡的UID和数据 Private Sub Button15_Click(sender As Object, e As EventArgs) Handles Button15.Click轻松读卡技术支持:网站:Dim i, j As IntegerDim cardidhex, …...

8k长序列建模,蛋白质语言模型Prot42仅利用目标蛋白序列即可生成高亲和力结合剂
蛋白质结合剂(如抗体、抑制肽)在疾病诊断、成像分析及靶向药物递送等关键场景中发挥着不可替代的作用。传统上,高特异性蛋白质结合剂的开发高度依赖噬菌体展示、定向进化等实验技术,但这类方法普遍面临资源消耗巨大、研发周期冗长…...

【解密LSTM、GRU如何解决传统RNN梯度消失问题】
解密LSTM与GRU:如何让RNN变得更聪明? 在深度学习的世界里,循环神经网络(RNN)以其卓越的序列数据处理能力广泛应用于自然语言处理、时间序列预测等领域。然而,传统RNN存在的一个严重问题——梯度消失&#…...

图表类系列各种样式PPT模版分享
图标图表系列PPT模版,柱状图PPT模版,线状图PPT模版,折线图PPT模版,饼状图PPT模版,雷达图PPT模版,树状图PPT模版 图表类系列各种样式PPT模版分享:图表系列PPT模板https://pan.quark.cn/s/20d40aa…...

LLMs 系列实操科普(1)
写在前面: 本期内容我们继续 Andrej Karpathy 的《How I use LLMs》讲座内容,原视频时长 ~130 分钟,以实操演示主流的一些 LLMs 的使用,由于涉及到实操,实际上并不适合以文字整理,但还是决定尽量整理一份笔…...

xmind转换为markdown
文章目录 解锁思维导图新姿势:将XMind转为结构化Markdown 一、认识Xmind结构二、核心转换流程详解1.解压XMind文件(ZIP处理)2.解析JSON数据结构3:递归转换树形结构4:Markdown层级生成逻辑 三、完整代码 解锁思维导图新…...
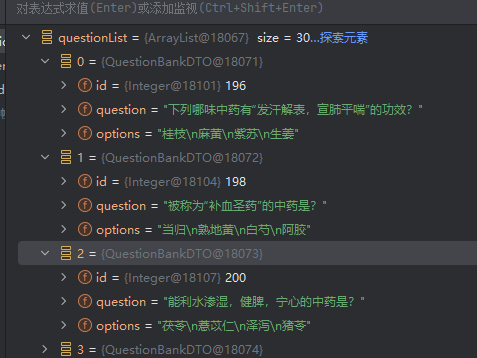
jdbc查询mysql数据库时,出现id顺序错误的情况
我在repository中的查询语句如下所示,即传入一个List<intager>的数据,返回这些id的问题列表。但是由于数据库查询时ID列表的顺序与预期不一致,会导致返回的id是从小到大排列的,但我不希望这样。 Query("SELECT NEW com…...

Java 与 MySQL 性能优化:MySQL 慢 SQL 诊断与分析方法详解
文章目录 一、开启慢查询日志,定位耗时SQL1.1 查看慢查询日志是否开启1.2 临时开启慢查询日志1.3 永久开启慢查询日志1.4 分析慢查询日志 二、使用EXPLAIN分析SQL执行计划2.1 EXPLAIN的基本使用2.2 EXPLAIN分析案例2.3 根据EXPLAIN结果优化SQL 三、使用SHOW PROFILE…...

WinUI3开发_使用mica效果
简介 Mica(云母)是Windows10/11上的一种现代化效果,是Windows10/11上所使用的Fluent Design(设计语言)里的一个效果,Windows10/11上所使用的Fluent Design皆旨在于打造一个人类、通用和真正感觉与 Windows 一样的设计。 WinUI3就是Windows10/11上的一个…...