seq2seq编码器encoder和解码器decoder详解
编码器
在序列到序列模型中,编码器将输入序列(如一个句子)转换为一个隐藏状态序列,供解码器生成输出。编码层通常由嵌入层和RNN(如GRU/LSTM)等组成
- Token:是模型处理文本时的基本单元,可以是词,子词,字符等,每个token都有一个对应的ID。是由原始文本中的词或子词通过分词器(Tokenizer)处理后得到的最小单位,这些 token 会被映射为词汇表中的唯一索引 ID
- 输入:
- 原始输入序列:通常是一个句子的词汇ID序列。例如 [“Hello”, “world”] 可能会被映射为 [1, 2],假设“Hello”的ID是1,“world”的ID是2;
- 嵌入向量: token ID 列表 [1, 2] 会作为模型的输入,每一个token即1和2经过嵌入层(embedding layer)都会转换为’encoder_embed_dim’大小的向量,即两个嵌入向量。嵌入向量最初是由模型在训练过程中学到的,初始时通常是随机的。在训练的过程中,嵌入向量会调整,使得语义相似的词在向量空间中更接近。
- 编码层(通常是RNN,GRU,LSTM,Transformer):
- 作用: 处理输入序列的时间依赖性,并生成隐藏状态
- 输入:嵌入向量序列,形状为(seq_len, embed_dim)
- 输出: 编码器对每个时间步(即每个token)计算一个隐藏状态,这些隐藏状态组成了一个隐藏状态序列,捕捉了当前 token 以及它的上下文信息,每个时间步的隐藏状态不仅考虑当前词的嵌入向量,还结合了之前所有时间步的信息。对于长度为seq_len的输入序列,隐藏状态序列的形状为 (seq_len, hidden_dim)。对于 LSTM 或 GRU,编码器还会输出最后一个时间步的隐藏状态,供解码器初始化使用
- 输出:
- 隐藏状态序列:编码器处理整个输入序列后,输出的隐藏状态序列通常被称为 encoder_outputs。其中每个隐藏状态序列对应于输入序列中的一个 token,这个序列的形状是 (seq_len, batch_size, hidden_dim)
- 最终隐藏状态:编码器的最后一个时间步的隐藏状态通常被用作解码器的初始状态。这被称为 encoder_hiddens,形状为 (num_layers, batch_size, hidden_dim),在双向RNN中,这个向量可能会有两倍的维度,变为(num_layers, batch_size, 2*hidden_dim)
'''定义了一个用于自然语言处理的编码器类 RNNEncoder,该类继承自 FairseqEncoder,
并实现了一个双向 GRU(门控循环单元,Gated Recurrent Unit)来对输入的文本进行编码'''
class RNNEncoder(FairseqEncoder):def __init__(self, args, dictionary, embed_tokens):super().__init__(dictionary)self.embed_tokens = embed_tokens # 嵌入层,用于将 token 索引转换为嵌入向量。self.embed_dim = args.encoder_embed_dim # 嵌入维度self.hidden_dim = args.encoder_ffn_embed_dim # 隐藏层维度self.num_layers = args.encoder_layers # GRU层数self.dropout_in_module = nn.Dropout(args.dropout)# 双向GRU层,用于处理输入序列self.rnn = nn.GRU(self.embed_dim, self.hidden_dim, self.num_layers, dropout=args.dropout, batch_first=False, bidirectional=True)self.dropout_out_module = nn.Dropout(args.dropout)self.padding_idx = dictionary.pad() # 填充索引,用于处理可变长度的输入序列。def combine_bidir(self, outs, bsz: int): # outs: 双向RNN的输出,[seq_len, batch_size, hidden_dim * 2],序列长度、批次大小和双向 RNN 的隐藏状态维度(2 倍的 hidden_dim)# bsz: 当前batch的大小# view: [self.num_layers, 2, bsz, -1], 2表示RNN双向的两个方向,-1 表示自动计算的隐藏状态维度hidden_dim# transpose: [self.num_layers, bsz, 2, -1]# 调用 contiguous() 来确保张量在内存中的布局是连续的out = outs.view(self.num_layers, 2, bsz, -1).transpose(1, 2).contiguous()# 将 out 重新调整为形状 [self.num_layers, bsz, hidden_dim * 2],即将双向的两个隐藏状态拼接在一起,成为一个新的隐藏状态张量。# 这里 -1 表示自动计算合并后的隐藏状态维度,等于 hidden_dim * 2。return out.view(self.num_layers, bsz, -1)# 执行编码器的前向传播,处理输入的 token 序列并生成输出def forward(self, src_tokens, **unused):bsz, seqlen = src_tokens.size()# get embedding 获取输入token的嵌入向量,并进行dropout操作x = self.embed_tokens(src_tokens)x = self.dropout_in_module(x)# [batch_size, sequence_length, hidden_dim] -> [sequence_length,batch_size,hidden_dim]# B x T x C -> T x B x Cx = x.transpose(0, 1)# pass thru bidirectional RNN# 初始化GRU的隐藏状态h0[2*num_layers,batch_size,hidden_dim]h0 = x.new_zeros(2 * self.num_layers, bsz, self.hidden_dim)x, final_hiddens = self.rnn(x, h0)outputs = self.dropout_out_module(x)# outputs = [sequence len, batch size, hid dim * directions]# hidden = [num_layers * directions, batch size , hid dim]# Since Encoder is bidirectional, we need to concatenate the hidden states of two directionsfinal_hiddens = self.combine_bidir(final_hiddens, bsz)# hidden = [num_layers , batch , num_directions*hidden]encoder_padding_mask = src_tokens.eq(self.padding_idx).t()return tuple((outputs, # seq_len , batch , hiddenfinal_hiddens, # num_layers , batch , num_directions*hiddenencoder_padding_mask, # seq_len , batch))def reorder_encoder_out(self, encoder_out, new_order):# This is used by fairseq's beam search. How and why is not particularly important here.return tuple((encoder_out[0].index_select(1, new_order), # outputsencoder_out[1].index_select(1, new_order), # final_hiddensencoder_out[2].index_select(1, new_order), # encoder_padding_mask))
解码器
根据编码器的输出生成目标序列,分为训练阶段和推理阶段,略有不同
- 训练阶段(teaching forcing)
在训练阶段,解码器知道整个目标序列,它使用前一个正确的 token(即目标序列的上一个 token)作为当前时间步的输入。这种方式称为 Teacher Forcing
-
输入:
- 初始输入:在序列开始时,解码器通常会接收到一个特殊的开始标记(如 ,表示 “Beginning of Sequence”)作为输入,是目标序列中上一个时间步的实际token ID,形状是(target_seq_len, batch_size)。可以稳定训练,加速收敛,因为训练早期模型生成的token可能不准确,通过使用实际的目标 token 作为输入,可以让模型在训练时保持在正确的轨道上,学习更稳定。能更快地学会生成目标序列的模式,训练过程更快收敛。
-
嵌入层:
解码器的每个输入 token(包括 和前一个时间步的输出 token)都会通过嵌入层转换成嵌入向量(target_seq_len, batch_size, embed_dim)。embed_dim 是嵌入向量的维度。 -
序列模型:
在每个时间步接收嵌入向量和隐藏状态,生成当前时间步的输出和更新的隐藏状态。- 隐藏状态:解码器会在每个时间步更新它的隐藏状态,这个隐藏状态将在下一个时间步作为输入的一部分。解码器的初始隐藏状态通常是由编码器的最终隐藏状态传递过来的。在双向 RNN 结构中,这个隐藏状态可以是编码器的最后一层前向和后向隐藏状态的拼接。
- RNN、LSTM、GRU:
- 形状:(num_layers, batch_size, hidden_dim)
- num_layers 是 RNN 层的数量。
- hidden_dim 是隐藏状态的维度。
- Transformer:
- (seq_len, batch_size, embed_dim)
- RNN、LSTM、GRU:
- 隐藏状态:解码器会在每个时间步更新它的隐藏状态,这个隐藏状态将在下一个时间步作为输入的一部分。解码器的初始隐藏状态通常是由编码器的最终隐藏状态传递过来的。在双向 RNN 结构中,这个隐藏状态可以是编码器的最后一层前向和后向隐藏状态的拼接。
-
注意力机制(可选):如果使用注意力机制,解码器还会基于编码器的输出和当前的隐藏状态计算注意力权重,以对编码器的隐藏状态进行加权求和。这有助于生成时更好地关注输入序列的相关部分。
-
输出:
- 生成的token:
- 预测的token概率分布:解码器的最后一层通常是一个全连接层,用于将隐藏状态映射到词汇表中的每个词的概率分布,(target_seq_len, batch_size, vocab_size),vocab_size 是词汇表的大小
- 最终生成的 token: 是根据这个概率分布选取的。解码器会在每个时间步生成一个 token,直到生成一个结束标记(如 ,表示 “End of Sequence”)或者达到最大长度,这个输出与实际目标序列的 token 进行比较,以计算损失,在训练时,目标序列通常包括 ,以帮助模型学习生成结束标记
- 隐藏状态
- 生成的token:
-
步骤:
-
初始化:用编码器的最终隐藏状态初始化解码器的隐藏状态,并输入 作为第一个 token。
-
每个时间步:
- 输入目标序列的上一个 token 以及当前隐藏状态到解码器。
- 解码器输出当前时间步的预测 token。
- 计算损失:将解码器的输出与实际目标序列的当前 token 进行比较,并计算损失。
-
更新:使用损失反向传播更新模型参数。
-
- 推理阶段
在推理阶段,解码器并不知道目标序列。它使用自己上一步生成的 token 作为当前时间步的输入,逐步生成整个序列。解码器通常是一个 token 一个 token 地进行输入和输出的
-
步骤:
- 初始化:与训练阶段相同,解码器的隐藏状态用编码器的最终隐藏状态初始化,并输入 作为第一个 token。
- 每个时间步:
- 使用解码器在前一个时间步生成的 token 作为当前时间步的输入。
- 解码器输出当前时间步的预测 token。
- 将预测 token 作为下一个时间步的输入。
- 如果生成了 ,则终止解码;否则继续。
- 输出:最终解码器生成的 token 序列作为输出序列。
-
输入:
- 在推理的开始阶段,解码器的输入通常是一个特殊的起始标记(),表示序列的开始。
- 形状:(1, batch_size),其中 1 是时间步的数量(在初始阶段只有一个 token),batch_size 是批处理的大小。
-
嵌入向量:(1, batch_size, embed_dim)
-
生成token概率分布:
解码器生成一个 token 的概率分布,这个概率分布表示当前时间步每个词汇的概率。(1, batch_size, vocab_size) -
更新输入,将生成的token作为下一个时间步的输入,经过嵌入曾,再次生成token分布,一直充分生成token,直到生成 或达到最大长度
class RNNDecoder(FairseqIncrementalDecoder):def __init__(self, args, dictionary, embed_tokens):super().__init__(dictionary)self.embed_tokens = embed_tokens# 解码器和编码器的层数必须相同assert args.decoder_layers == args.encoder_layers, f"""seq2seq rnn requires that encoder and decoder have same layers of rnn. got: {args.encoder_layers, args.decoder_layers}"""# 解码器的隐藏层维度必须是编码器隐藏层维度的两倍,因为在许多的seq2seq模型中,编码器的输出可能是双向的(双向GRU或LSTM)assert args.decoder_ffn_embed_dim == args.encoder_ffn_embed_dim*2, f"""seq2seq-rnn requires that decoder hidden to be 2*encoder hidden dim. got: {args.decoder_ffn_embed_dim, args.encoder_ffn_embed_dim*2}"""self.embed_dim = args.decoder_embed_dim # 解码器的嵌入维度self.hidden_dim = args.decoder_ffn_embed_dim # 解码器RNN的hidden layers维度self.num_layers = args.decoder_layers # 解码器RNN的层数self.dropout_in_module = nn.Dropout(args.dropout)self.rnn = nn.GRU(self.embed_dim, self.hidden_dim, self.num_layers, dropout=args.dropout, batch_first=False, bidirectional=False)self.attention = AttentionLayer(self.embed_dim, self.hidden_dim, self.embed_dim, bias=False) # self.attention = Noneself.dropout_out_module = nn.Dropout(args.dropout)if self.hidden_dim != self.embed_dim:self.project_out_dim = nn.Linear(self.hidden_dim, self.embed_dim)else:self.project_out_dim = Noneif args.share_decoder_input_output_embed:self.output_projection = nn.Linear(self.embed_tokens.weight.shape[1],self.embed_tokens.weight.shape[0],bias=False,)self.output_projection.weight = self.embed_tokens.weightelse:self.output_projection = nn.Linear(self.output_embed_dim, len(dictionary), bias=False)nn.init.normal_(self.output_projection.weight, mean=0, std=self.output_embed_dim ** -0.5)def forward(self, prev_output_tokens, encoder_out, incremental_state=None, **unused):# extract the outputs from encoderencoder_outputs, encoder_hiddens, encoder_padding_mask = encoder_out# outputs: seq_len x batch x num_directions*hidden# encoder_hiddens: num_layers x batch x num_directions*encoder_hidden# padding_mask: seq_len x batchif incremental_state is not None and len(incremental_state) > 0:# if the information from last timestep is retained, we can continue from there instead of starting from bosprev_output_tokens = prev_output_tokens[:, -1:]cache_state = self.get_incremental_state(incremental_state, "cached_state")prev_hiddens = cache_state["prev_hiddens"]else:# incremental state does not exist, either this is training time, or the first timestep of test time# prepare for seq2seq: pass the encoder_hidden to the decoder hidden statesprev_hiddens = encoder_hiddensbsz, seqlen = prev_output_tokens.size()# embed tokensx = self.embed_tokens(prev_output_tokens)x = self.dropout_in_module(x)# B x T x C -> T x B x Cx = x.transpose(0, 1)# decoder-to-encoder attentionif self.attention is not None:x, attn = self.attention(x, encoder_outputs, encoder_padding_mask)# pass thru unidirectional RNNx, final_hiddens = self.rnn(x, prev_hiddens)# outputs = [sequence len, batch size, hid dim]# hidden = [num_layers * directions, batch size , hid dim]x = self.dropout_out_module(x)# project to embedding size (if hidden differs from embed size, and share_embedding is True, # we need to do an extra projection)if self.project_out_dim != None:x = self.project_out_dim(x)# project to vocab sizex = self.output_projection(x)# T x B x C -> B x T x Cx = x.transpose(1, 0)# if incremental, record the hidden states of current timestep, which will be restored in the next timestepcache_state = {"prev_hiddens": final_hiddens,}self.set_incremental_state(incremental_state, "cached_state", cache_state)return x, Nonedef reorder_incremental_state(self,incremental_state,new_order,):# This is used by fairseq's beam search. How and why is not particularly important here.cache_state = self.get_incremental_state(incremental_state, "cached_state")prev_hiddens = cache_state["prev_hiddens"]prev_hiddens = [p.index_select(0, new_order) for p in prev_hiddens]cache_state = {"prev_hiddens": torch.stack(prev_hiddens),}self.set_incremental_state(incremental_state, "cached_state", cache_state)return
相关文章:

seq2seq编码器encoder和解码器decoder详解
编码器 在序列到序列模型中,编码器将输入序列(如一个句子)转换为一个隐藏状态序列,供解码器生成输出。编码层通常由嵌入层和RNN(如GRU/LSTM)等组成 Token:是模型处理文本时的基本单元,可以是词,子词,字符…...

前端使用 Konva 实现可视化设计器(21)- 绘制图形(椭圆)
本章开始补充一些基础的图形绘制,比如绘制:直线、曲线、圆/椭形、矩形。这一章主要分享一下本示例是如何开始绘制一个图形的,并以绘制圆/椭形为实现目标。 请大家动动小手,给我一个免费的 Star 吧~ 大家如果发现了 Bug,…...

Python 将单词拆分为单个字母组成的列表对象
Python 将单词拆分为单个字母组成的列表对象 正文 正文 这里介绍一个简单算法,将英文单词拆分为其对应字母组成的列表。 str1 ACG lst1 [i for i in str1] lst2 list(str1)# Method 1 print(lst1) # Method 2 print(lst2) """ result: [A, C, G…...

欧洲 摩纳哥税务知识
摩纳哥是一个位于法国南部的城邦国家,以其豪华的生活环境和宽松的税收政策而闻名。自1869年以来,摩纳哥取消了个人所得税的征收,这使得它成为富裕人士和外籍人士的理想居住地。然而,这并不意味着摩纳哥的税收制度完全不存在。以下…...

域控制器的四大支柱分别是车载以太网、自适应Autosar
域控制器的四大支柱分别是车载以太网、自适应Autosar、高性能处理器和集中式E/E架构。 百度安全验证 。自适应Autosar采用Proxy/Skeleton的通信架构,同时采用中间件SOME/IP...

写给大数据开发:如何优化临时数据查询流程
你是否曾因为频繁的临时数据查询请求而感到烦恼?这些看似简单的任务是否正在蚕食你的宝贵时间,影响你的主要工作?如果是,那么这篇文章正是为你而写。 目录 引言:数据开发者的困境问题剖析:临时数据查询的…...
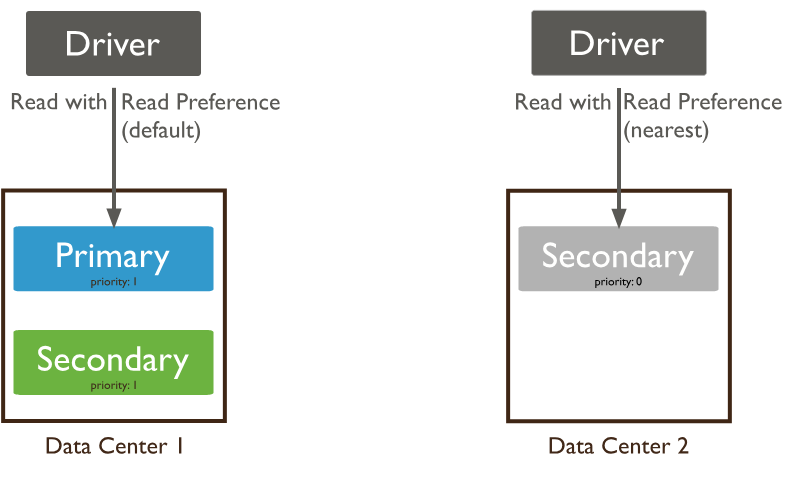
【MongoDB】Java连接MongoDB
连接URI 连接 URI提供驱动程序用于连接到 MongoDB 部署的指令集。该指令集指示驱动程序应如何连接到 MongoDB,以及在连接时应如何运行。下图解释了示例连接 URI 的各个部分: 连接的URI 主要分为 以下四个部分 第一部分 连接协议 示例中使用的 连接到具有…...

nginx支持的不同事件驱动模型
Nginx 支持的不同事件驱动模型 Nginx 是一款高性能的 Web 和反向代理服务器,它支持多种事件驱动模型来处理网络 I/O 操作。不同的操作系统及其版本支持不同的事件驱动模型,这些模型对于 Nginx 的并发处理能力和性能至关重要。下面详细介绍 Nginx 支持的…...

C++ TinyWebServer项目总结(7. Linux服务器程序规范)
进程 PID 进程的PID(Process ID)是操作系统中用于唯一标识一个进程的整数值。每个进程在创建时,操作系统都会分配一个唯一的PID,用来区分不同的进程。 PID的特点 唯一性: 在操作系统运行的某一时刻,每个…...

基于STM32单片机设计的秒表时钟计时器仿真系统——程序源码proteus仿真图设计文档演示视频等(文末工程资料下载)
基于STM32单片机设计的秒表时钟计时器仿真系统 演示视频 基于STM32单片机设计的秒表时钟计时器仿真系统 摘要 本设计基于STM32单片机,设计并实现了一个秒表时钟计时器仿真系统。系统通过显示器实时显示当前时间,并通过定时器实现秒表计时功能。显示小时…...

人才流失预测项目
在本项目中,通过数据科学和AI的方法,分析挖掘人力资源流失问题,并基于机器学习构建解决问题的方法,并且,我们通过对AI模型的反向解释,可以深入理解导致人员流失的主要因素,HR部门也可以根据分析…...

BUG——imx6u开发_结构体导致的死机问题(未解决)
简介: 最近在做imx6u的linux下裸机驱动开发,由于是学习的初级阶段,既没有现成的IDE可以使用,也没有GDB等在线调试工具,只能把代码烧写在SD卡上再反复插拔,仅靠卑微的亮灯来判断程序死在哪一步。 至于没有使…...

问答:什么是对称密钥、非对称密钥,http怎样变成https的?
文章目录 对称密钥 vs 非对称密钥HTTP 变成 HTTPS 的过程 对称密钥 vs 非对称密钥 1. 对称密钥加密 定义: 对称密钥加密是一种加密算法,其中加密和解密使用的是同一个密钥。特点: 速度快: 因为只使用一个密钥,所以加密和解密速度较快。密钥分发问题: 双…...

虚拟滚动列表组件ReVirtualList
虚拟滚动列表组件ReVirtualList 组件实现基于 Vue3 Element Plus Typescript,同时引用 vueUse lodash-es tailwindCss (不影响功能,可忽略) 在 ReList 的基础上,增加虚拟列表功能,在固定高度的基础上,可以优化大数…...

稳定、耐用、美观 一探究竟六角头螺钉螺栓如何选择
在机器与技术未被发现的过去,紧固件设计和品质并不稳定。但是,他们已成为当今许多行业无处不在的构成部分。六角头标准件或六角头标准件是紧固件中持续的头部设计之一,它有六个面,对广泛工业应用大有益处。六角头标准件或常分成六…...

数据库Mybatis基础操作
目录 基础操作 删除 预编译SQL 增、改、查 自动封装 基础操作 环境准备 删除 根据主键动态删除数据:使用了mybatis中的参数占位符#{ },里面是传进去的参数。 单元测试: 另外,这个方法是有返回值的,返回这次操作…...

人物形象设计:塑造独特角色的指南
引言 人物形象设计是一种创意过程,它利用强大的设计工具,通过视觉和叙述元素塑造角色的外在特征和内在性格。这种设计不仅赋予角色以生命,还帮助观众或读者在心理层面上与角色建立联系。人物形象设计的重要性在于它能够增强故事的吸引力和说…...

网络安全-安全策略初认识
文章目录 前言理论介绍1. 安全策略1.1 定义:1.2 关键术语: 2. 防火墙状态监测 实战步骤1:实验环境搭建步骤2:配置实现 总结1. 默认安全策略2. 自定义安全策略3. 防火墙状态会话表 前言 who:本文主要写给入门防火墙的技…...

python import相对导入与绝对导入
文章目录 相对导入与绝对导入绝对导入相对导入何时使用相对导入何时使用绝对导入示例 相对导入与绝对导入 在Python中,from .file_manager import SomeFunction 和 from file_manager import SomeFunction 两种导入方式看似相似,但在模块寻找机制上存在…...

深入理解 Go 语言原子内存操作
原子内存操作提供了实现其他同步原语所需的低级基础。一般来说,你可以用互斥体和通道替换并发算法的所有原子操作。然而,它们是有趣且有时令人困惑的结构,应该深入了解它们是如何工作的。如果你能够谨慎地使用它们,那么它们完全可以成为代码优化的好工具,而不会增加复杂性…...

css实现圆环展示百分比,根据值动态展示所占比例
代码如下 <view class""><view class"circle-chart"><view v-if"!!num" class"pie-item" :style"{background: conic-gradient(var(--one-color) 0%,#E9E6F1 ${num}%),}"></view><view v-else …...

中南大学无人机智能体的全面评估!BEDI:用于评估无人机上具身智能体的综合性基准测试
作者:Mingning Guo, Mengwei Wu, Jiarun He, Shaoxian Li, Haifeng Li, Chao Tao单位:中南大学地球科学与信息物理学院论文标题:BEDI: A Comprehensive Benchmark for Evaluating Embodied Agents on UAVs论文链接:https://arxiv.…...

Debian系统简介
目录 Debian系统介绍 Debian版本介绍 Debian软件源介绍 软件包管理工具dpkg dpkg核心指令详解 安装软件包 卸载软件包 查询软件包状态 验证软件包完整性 手动处理依赖关系 dpkg vs apt Debian系统介绍 Debian 和 Ubuntu 都是基于 Debian内核 的 Linux 发行版ÿ…...

Docker 运行 Kafka 带 SASL 认证教程
Docker 运行 Kafka 带 SASL 认证教程 Docker 运行 Kafka 带 SASL 认证教程一、说明二、环境准备三、编写 Docker Compose 和 jaas文件docker-compose.yml代码说明:server_jaas.conf 四、启动服务五、验证服务六、连接kafka服务七、总结 Docker 运行 Kafka 带 SASL 认…...

ESP32读取DHT11温湿度数据
芯片:ESP32 环境:Arduino 一、安装DHT11传感器库 红框的库,别安装错了 二、代码 注意,DATA口要连接在D15上 #include "DHT.h" // 包含DHT库#define DHTPIN 15 // 定义DHT11数据引脚连接到ESP32的GPIO15 #define D…...

Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility
Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility 1. 实验室环境1.1 实验室环境1.2 小测试 2. The Endor System2.1 部署应用2.2 检查现有策略 3. Cilium 策略实体3.1 创建 allow-all 网络策略3.2 在 Hubble CLI 中验证网络策略源3.3 …...

C# SqlSugar:依赖注入与仓储模式实践
C# SqlSugar:依赖注入与仓储模式实践 在 C# 的应用开发中,数据库操作是必不可少的环节。为了让数据访问层更加简洁、高效且易于维护,许多开发者会选择成熟的 ORM(对象关系映射)框架,SqlSugar 就是其中备受…...

前端开发面试题总结-JavaScript篇(一)
文章目录 JavaScript高频问答一、作用域与闭包1.什么是闭包(Closure)?闭包有什么应用场景和潜在问题?2.解释 JavaScript 的作用域链(Scope Chain) 二、原型与继承3.原型链是什么?如何实现继承&a…...

SpringCloudGateway 自定义局部过滤器
场景: 将所有请求转化为同一路径请求(方便穿网配置)在请求头内标识原来路径,然后在将请求分发给不同服务 AllToOneGatewayFilterFactory import lombok.Getter; import lombok.Setter; import lombok.extern.slf4j.Slf4j; impor…...

docker 部署发现spring.profiles.active 问题
报错: org.springframework.boot.context.config.InvalidConfigDataPropertyException: Property spring.profiles.active imported from location class path resource [application-test.yml] is invalid in a profile specific resource [origin: class path re…...