一线大厂高并发Redis缓存架构
文章目录
- 高并发缓存架构设计
- 架构设计思路
- 完整代码
- 开发规范与优化建议
- 键值设计
- 命令使用
- 客户端的使用
- 扩展
- 布隆过滤器
- redis的过期键的清除策略
高并发缓存架构设计
架构设计思路
首先是一个基础的缓存架构,对于新增、修改操作set会对缓存更新,对于查询操作先去查询redis缓存,没有再去查询DB,然后把数据在Redis中也缓存一份
但如果数据量很大,redis中不能存储所有的数据,而且很大一部分数据都是冷门数据,可能就插入时用了一次。对于这种情况我们就可以在新增或修改时对缓存set时加过期时间,在查询时将查询到的数据在缓存中更新过期时间,保证热点数据不过期,这样就简单的实现了冷热分离
考虑解决缓存击穿的情况,大量的数据同时间过期导致大量请求直接落到了DB上。在业务上肯定会有一些批量操作,那么对于批量新增的场景,多个数据设置了同一时间过期,那么就可能会出现缓存击穿的情况,解决方法是再加个随机方法,在原有过期时间上再增加一段随机时间
考虑解决缓存穿透的情况,管理员误删热点数据或恶意攻击,一直访问缓存和数据库中都不存在的数据,进而拖垮数据库。
我们可以选择往缓存中存一个空值+过期时间;或者是布隆过滤器。
这里最好是要区分一下,写一个方法区查询缓存,如果查询缓存没有查询到数据返回null,如果查询到了数据但是这个数据是我们上一步存的空值那么这里返回什么,最好是和前一步返回的null区分开
考虑解决热点数据缓存重建问题,热点数据过期或者是冷门数据忽然变成热点数据,这时缓存中没数据,DB中有数据,一瞬间大量的请求要查询这条数据就都落到了DB上。
解决方案是加锁,对查询DB操作加锁,这里需要加分布式锁,锁的粒度要小,比如电商中使用锁前缀+商品id。之所以要使用分布式锁而不是synchronized也是因为锁的粒度,使用synchronized(this)方式那么查询其他商品的操作也会被阻塞住,使用synchronized(锁前缀 + product.getId()) 这种方式生成的锁对象又不是同一个对象。为了性能,同时还需要参考单例模式的双重检测机制,将DCL(Double-Checked-Locking)机制也加上。
伪代码如下:
// 查询缓存
Object o = queryCache(keyStr);
if(o != null){return o;
}// 热点数据缓存重建 缓存没有查询到就加锁
lock.lock();
try{// 再查一遍Object o = queryCache(keyStr);if(o != null){return o;}// 还没有查询到就查询DB并往Redis中写queryDatabase(...);}finally {lock.unlock();
}
考虑解决缓存与DB双写不一致问题
双写不一致问题
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8u46PsEk-1679751253793)(picture/Redis/103029)]](https://img-blog.csdnimg.cn/5806475bb7d04c05bbee7434936217f4.png)
读写不一致问题,假如更新操作时我不更新缓存,而是删除缓存嘞?如下所示也是有问题的。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zKHwgJ77-1679751253794)(picture/Redis/103137)]](https://img-blog.csdnimg.cn/da147d982c6643919e275e23f6022a90.png)
要解决上面这些问题的方法还是加锁,在查DB更新缓存、更新DB更新缓存这两个地方加同一把分布式锁。此时就会有人提问了:
-
这么写一个简单的增删改查逻辑代码会变得很复杂
如果并发不高或者能容忍这些问题的话,那么你可以不加这些校验代码,如果你想要解决这些小概率问题那么就必须要加相应的代码。 -
这么写都是串行执行,效率不会很低吗?
在上一步中我们对查询方法就加了DCL机制,绝大部分请求在两次校验时就从缓存中拿到数据返回了,根本不会进入到加锁的位置
Object o = queryCache(keyStr);
if(o != null){return o;
}// 解决热点数据缓存重建问题 缓存没有查询到就加锁
lock.lock();
try{Object o = queryCache(keyStr);if(o != null){return o;}// 这个方法中才是查询DB更新缓存,这里面才会加锁,但是大部分请求在上面两次查缓存中就已经拿到数据并返回了queryDatabase(...);}finally {lock.unlock();
}
接下来尝试对上面两种分布式锁做优化
首先是为了解决热点数据缓存重建问题而加的分布式锁,其实现在这种方式也能用了,因为只会有一个请求去查询DB然后写入缓存,其他阻塞的线程就会通过第二次验证从缓存中拿到数据返回。但是可能会有几万个请求都阻塞在了加锁的那一行中,我们可以使用trylock()方法来优化,指定一个最大等待时间,这样所有等待的线程一到时间就直接去执行第二个从缓存中取数据的代码了。
接下来是为了解决缓存与DB数据不一致问题而加的分布式锁,大部分的情况下我们业务都是读多写少,我们可以在这里使用读写锁来提高性能,更新DB更新缓存的地方使用写锁,缓存无数据 查询DB更新缓存的地方用读锁。
接下来考虑解决缓存雪崩的问题,我们都是请求–>web服务–>redis,如果并发量很大,多个web服务的请求到发到了一个redis节点上,redis处理不过来一秒十几万或更多的请求,那么redis就可能宕机或者是用户线程一直等待redis响应
如果redis宕机,那么业务代码try{}catch后一般就去查数据库了,大量的请求就会让数据库挂掉,接着再整个服务都不能访问了。
如果redis没宕机,用户线程一直等待redis数据返回,此时并发很高,web服务中线程得不到释放,又不断有新的请求进来,又导致微服务可能宕机,进而影响到整个系统宕机。
解决方法:
-
限流,但万一中间件部分限流没有拦住,我们在代码层面也要做相应的处理,使用下面这种解决方案
-
多级缓存,我们可以在JVM层面也加一层缓存,在访问Redis前先访问JVM层面的缓存。因为JVM是本机内存,并发访问可以达到每秒百万
我们还需要一个单独的系统去维护JVM层面的缓存。确定什么样的数据能放缓存中;某个微服务节点更新了数据,其他节点的JVM层面的缓存也要更新等等情况。
完整代码
package com.hs.distributlock.service;import com.alibaba.fastjson.JSON;
import com.hs.distributlock.entity.ProductEntity;
import com.hs.distributlock.mapper.ProductMapper;
import org.redisson.Redisson;
import org.redisson.api.RLock;
import org.redisson.api.RReadWriteLock;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Service;
import org.springframework.util.StringUtils;import java.util.Objects;
import java.util.Random;
import java.util.concurrent.TimeUnit;/*** @Description: 高并发缓存架构* @Author 胡尚* @Date: 2023/3/25 20:10*/
@Service
public class ProductService {@AutowiredStringRedisTemplate redisTemplate;@AutowiredRedisson redisson;@AutowiredProductMapper productMapper;/*** 缓存穿透默认值*/public static final String PRODUCT_PENETRATE_DEFAULT = "{}";/*** 突发性热点缓存重建时加的锁*/public static final String LOCK_PRODUCT_HOT_CACHE_CREATE_PREFIX = "lock:product:hot_cache_create:";/*** 突发性热点缓存重建时加的锁*/public static final String LOCK_CACHE_DB_UNLIKE_PREFIX = "lock:cache_db_unlike:";public void updateProduct(ProductEntity entity){// 解决缓存与数据库双写 数据不一致问题 而加写锁RReadWriteLock readWriteLock = redisson.getReadWriteLock(LOCK_CACHE_DB_UNLIKE_PREFIX + entity.getId());RLock wLock = readWriteLock.writeLock();wLock.lock();try {// 更新DB 更新缓存productMapper.update(entity);String json = JSON.toJSONString(entity);redisTemplate.opsForValue().set("product:id:" + entity.getId(), json, 12*60*60+getRandomTime(), TimeUnit.SECONDS);}finally {wLock.unlock();}}public void insertProduct(ProductEntity entity){// 解决缓存与数据库双写 数据不一致问题 而加写锁RReadWriteLock readWriteLock = redisson.getReadWriteLock(LOCK_CACHE_DB_UNLIKE_PREFIX + entity.getId());RLock wLock = readWriteLock.writeLock();wLock.lock();try {// 更新DB 更新缓存productMapper.insert(entity);String json = JSON.toJSONString(entity);redisTemplate.opsForValue().set("product:id:" + entity.getId(), json, 12*60*60+getRandomTime(), TimeUnit.SECONDS);}finally {wLock.unlock();}}/*** 重点方法,这其中使用了双重检测去查询缓存,还加了读锁去解决缓存和数据库双写导致的数据不一致问题*/public ProductEntity queryProduct(Long id) throws InterruptedException {String productKey = "product:id:" + id;// 从缓存取数据ProductEntity entity = queryCache(productKey);if (entity != null){return entity;}// 突发性热点缓存重建问题,避免大量请求直接去请求DB,进而加锁拦截RLock lock = redisson.getLock(LOCK_PRODUCT_HOT_CACHE_CREATE_PREFIX + id);lock.tryLock(3, 30, TimeUnit.SECONDS);try {// 第二次验证 从缓存取数据entity = queryCache(productKey);if (entity != null){return entity;}// 缓存与DB数据双写不一致问题 加锁RReadWriteLock readWriteLock = redisson.getReadWriteLock(LOCK_CACHE_DB_UNLIKE_PREFIX + id);RLock rLock = readWriteLock.readLock();rLock.lock();try {// 查询数据库 更新缓存entity = queryDatabase(productKey, id);}finally {rLock.unlock();}}finally {lock.unlock();}return entity;}/*** 从缓存中查询*/private ProductEntity queryCache(String key){ProductEntity entity = null;String json = redisTemplate.opsForValue().get(key);if (StringUtils.hasLength(json)){// 判断是否为解决缓存穿透而手动存储的值,如果是则直接返回一个新对象,并和前端约定好错误提示if (Objects.equals(PRODUCT_PENETRATE_DEFAULT, json)){return new ProductEntity();}entity = JSON.parseObject(json, ProductEntity.class);// 延期redisTemplate.expire(key, 12*60*60+getRandomTime(), TimeUnit.SECONDS);}return entity;}/*** 从数据库中查询,如果查询到了就将数据在缓存中保存一份,如果没有查询到则往缓存中存一个默认值来解决缓存击穿问题*/private ProductEntity queryDatabase(String productKey, long id){ProductEntity entity = productMapper.get(id);// 如果数据库中也没有查询到,那么就往缓存中存一个默认值,去解决缓存击穿问题if (entity == null){redisTemplate.opsForValue().set(productKey, PRODUCT_PENETRATE_DEFAULT, 60*1000, TimeUnit.SECONDS);} else {redisTemplate.opsForValue().set(productKey, JSON.toJSONString(entity), 12*60*60+getRandomTime(), TimeUnit.SECONDS);}return entity;}private Integer getRandomTime(){return new Random().nextInt(5) * 60 * 60;}
}开发规范与优化建议
键值设计
Key的设计
-
可读性和可管理性。以业务名为前缀,用冒号分割。避免直接使用id作为key导致数据覆盖的情况。
-
简洁性。保证语义的前提下,控制key的长度,不要太长
-
不要包含空格、换行、单双引号以及其他特殊字符
value的设计
-
避免bigkey
字符串类型,最大512MB,但是一般超过10KB就认为是bigkey
非字符串类型,hash、list、set、zset,一般它们的元素超过5000就任务是bigkey
bigkey的危害:导致redis阻塞、网络拥堵
一般产生bigkey的原因:按天统计某些功能或用户集合、将数据库查询到的数据序列化后存入缓存,我们要判断是否是所有字段都需要缓存
优化bigkey:将一个bigkey拆分为多个数据、如果不可拆分则不要每次取所有的数据,比如
hmget key field [field ...]只读取其中某些元素 -
选择合适的数据类型
反例:
set user:1:name tom set user:1:age 19 set user:1:favor football正例:
hmset user:1 name tom age 19 favor football -
控制key的生命周期,添加过期时间
命令使用
-
O(N)命令关注N的数量
例如hgeall、lrange、smembers、zrange等并非不能用,但需要关注N的数量。
有遍历的需求可以使用hscan、sscan、zscan代替。
-
禁用命令:keys * 、flushall 、flushdb等
-
使用批量操作提高效率,比如pipeline管道等
-
redis的事务不要过多使用,可以使用lua脚本来代替
客户端的使用
-
避免所有业务使用同一个redis实例
可以搭建多个redis集群,不同的微服务调用不同的redis集群,不相干的业务拆分,公共数据做服务化。
-
使用带有连接池,有效控制连接提高效率
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig(); jedisPoolConfig.setMaxTotal(5); jedisPoolConfig.setMaxIdle(2); jedisPoolConfig.setTestOnBorrow(true);JedisPool jedisPool = new JedisPool(jedisPoolConfig, "127.0.0.1", 6379, 3000, null);Jedis jedis = null; try {jedis = jedisPool.getResource();//具体的命令jedis.executeCommand() } catch (Exception e) {logger.error("op key {} error: " + e.getMessage(), key, e); } finally {//注意这里不是关闭连接,在JedisPool模式下,Jedis会被归还给资源池。if (jedis != null) jedis.close(); }连接池参数含义:
序号 参数名 含义 默认值 使用建议 1 maxTotal 资源池中最大连接数 8 设置建议见下面 2 maxIdle 资源池允许最大空闲的连接数 8 设置建议见下面 3 minIdle 资源池确保最少空闲的连接数 0 设置建议见下面 4 blockWhenExhausted 当资源池用尽后,调用者是否要等待。只有当为true时,下面的maxWaitMillis才会生效 true 建议使用默认值 5 maxWaitMillis 当资源池连接用尽后,调用者的最大等待时间(单位为毫秒) -1:表示永不超时 不建议使用默认值 6 testOnBorrow 向资源池借用连接时是否做连接有效性检测(ping),无效连接会被移除 false 业务量很大时候建议设置为false(多一次ping的开销)。 7 testOnReturn 向资源池归还连接时是否做连接有效性检测(ping),无效连接会被移除 false 业务量很大时候建议设置为false(多一次ping的开销)。 8 jmxEnabled 是否开启jmx监控,可用于监控 true 建议开启,但应用本身也要开启 一般我们控制最大连接数和资源池允许的最大空闲连接数这两个配置就行了
Redis连接池的连接对象是懒加载的,连接池对象刚创建时不会初始化创建连接对象,是真正使用时才会去创建,我们可以做连接池预热
// 先将创建的连接对象保存起来,然后再统一调用close()方法放回连接池中 List<Jedis> minIdleJedisList = new ArrayList<Jedis>(jedisPoolConfig.getMinIdle());for (int i = 0; i < jedisPoolConfig.getMinIdle(); i++) {Jedis jedis = null;try {jedis = pool.getResource();minIdleJedisList.add(jedis);jedis.ping();} catch (Exception e) {logger.error(e.getMessage(), e);} finally {//注意,这里不能马上close将连接还回连接池,否则最后连接池里只会建立1个连接//jedis.close();} } //统一将预热的连接还回连接池 for (int i = 0; i < jedisPoolConfig.getMinIdle(); i++) {Jedis jedis = null;try {jedis = minIdleJedisList.get(i);//将连接归还回连接池jedis.close();} catch (Exception e) {logger.error(e.getMessage(), e);} finally {} }
扩展
布隆过滤器
当布隆过滤器说某个值存在时,这个值可能不存在;当它说不存在时,那就肯定不存在。
布隆过滤器不能删除数据,如果要删除得重新初始化数据。
底层原理如下图所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TMs6tLvs-1679807400908)(picture/Redis/81509)]](https://img-blog.csdnimg.cn/2a3cf08fe0b744eea4cefe0c73461f74.png)
使用Redisson实现一个简单的案例
package com.redisson;import org.redisson.Redisson;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;public class RedissonBloomFilter {public static void main(String[] args) {// 构建一个redisson对象Config config = new Config();config.useSingleServer().setAddress("redis://localhost:6379");RedissonClient redisson = Redisson.create(config);RBloomFilter<String> bloomFilter = redisson.getBloomFilter("nameList");//初始化布隆过滤器:预计元素为100000000L,误差率为3%,根据这两个参数会计算出底层的bit数组大小bloomFilter.tryInit(100000000L,0.03);//将zhuge插入到布隆过滤器中bloomFilter.add("hushang");//判断下面号码是否在布隆过滤器中System.out.println(bloomFilter.contains("aabbcc"));//falseSystem.out.println(bloomFilter.contains("eeeee"));//falseSystem.out.println(bloomFilter.contains("hushang"));//true}
}
实际开发中的伪代码如下
//初始化布隆过滤器
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("nameList");
//初始化布隆过滤器:预计元素为100000000L,误差率为3%
bloomFilter.tryInit(100000000L,0.03);//把所有数据存入布隆过滤器
void init(){for (String key: keys) {bloomFilter.add(key);}
}String get(String key) {// 从布隆过滤器这一级缓存判断下key是否存在Boolean exist = bloomFilter.contains(key);if(!exist){return "";}// 从缓存中获取数据String cacheValue = cache.get(key);// 缓存为空if (StringUtils.isBlank(cacheValue)) {// 从存储中获取String storageValue = storage.get(key);cache.set(key, storageValue);// 如果存储数据为空,往缓存中存一个空对象 需要设置一个过期时间(300秒)if (storageValue == null) {cache.expire(key, 60 * 5);}return storageValue;} else {// 缓存非空return cacheValue;}
}
redis的过期键的清除策略
-
被动删除
当调用get命令时去查询key是否过期,如果过期再删除
-
主动删除
Redis会定期(默认每100ms)主动淘汰一批已过期的key
-
主动清理策略
我们在redis.conf配置文件中配置
maxmemory指定redis的最大使用内存,如果当前使用内存超过了这里配置的值则触发主动清理策略
主动清理策略共有8种,一般默认是不处理。
- 对于设置了过期时间的key
- volatile-ttl:根据过期时间的先后进行删除,越早过期的越先被删除。
- volatile-random:在设置了过期时间的键值对中,进行随机删除。
- volatile-lru:会使用 LRU 算法筛选设置了过期时间的键值对删除。
- volatile-lfu:会使用 LFU 算法筛选设置了过期时间的键值对删除。
- 对于所有的key
- allkeys-random:从所有键值对中随机选择并删除数据。
- allkeys-lru:使用 LRU 算法在所有数据中进行筛选删除。
- allkeys-lfu:使用 LFU 算法在所有数据中进行筛选删除。
- 不处理
- noeviction:不会剔除任何数据,拒绝所有写入操作并返回客户端错误信息"(error) OOM command not allowed when used memory",此时Redis只响应读操作。
LRU 算法(Least Recently Used,最近最少使用)
淘汰很久没被访问过的数据,以最近一次访问时间作为参考。
LFU 算法(Least Frequently Used,最不经常使用)
淘汰最近一段时间被访问次数最少的数据,以次数作为参考。
一般对于存在热点数据的访问场景下,选择LFU算法,这样避免了短时间新增了一批冷数据进而删除热点数据,但是LRU的效率要高
根据自身业务类型,配置好maxmemory-policy(默认是noeviction),推荐使用volatile-lru。
如果不设置maxmemory最大使用内存的话,redis将服务器的所有内存用完后,那么就会开始频繁的和磁盘进行交互了,会很慢。
对于主从模式,主节点删除过期的key后,会把del key命令同步到从节点执行
相关文章:
一线大厂高并发Redis缓存架构
文章目录高并发缓存架构设计架构设计思路完整代码开发规范与优化建议键值设计命令使用客户端的使用扩展布隆过滤器redis的过期键的清除策略高并发缓存架构设计 架构设计思路 首先是一个基础的缓存架构,对于新增、修改操作set会对缓存更新,对于查询操作…...
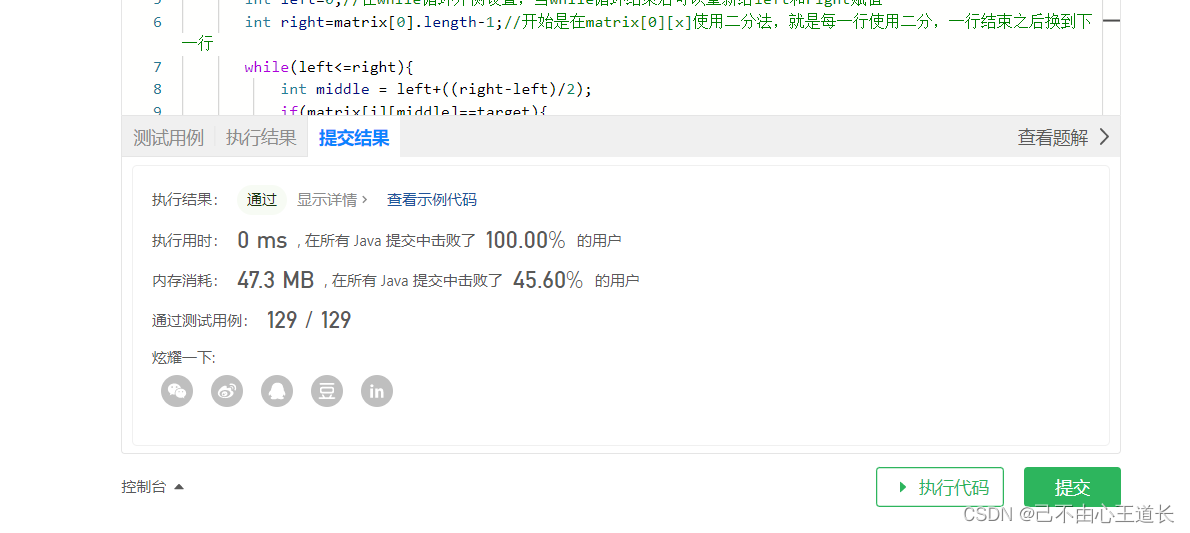
剑指offer-二维数组中的查找
文章目录题目描述题解一 无脑暴力循环题解二 初始二分法🌕博客x主页:己不由心王道长🌕! 🌎文章说明:剑指offer-二维数组中的查找🌎 ✅系列专栏:剑指offer 🌴本篇内容:对剑…...
怎么设计一个秒杀系统
1、系统部署 秒杀系统部署要单独区别开其他系统单独部署,这个系统的流量肯定很大,单独部署。数据库也要单独用一个部署的数据库或者集群,防止高并发导致整个网站不可用。 2、防止超卖 100个库存,1000个人买,要保证不…...

程序参数解析C/C++库 The Lean Mean C++ Option Parser
开发中我们经常使用程序参数,根据参数的不同来实现不同的功能。POSIX和GNU组织对此都制定了一些标准,为了我们程序更为通用标准,建议遵循这些行业内的规范,本文介绍的开源库The Lean Mean C Option Parser就可以很好满足我们的需求…...
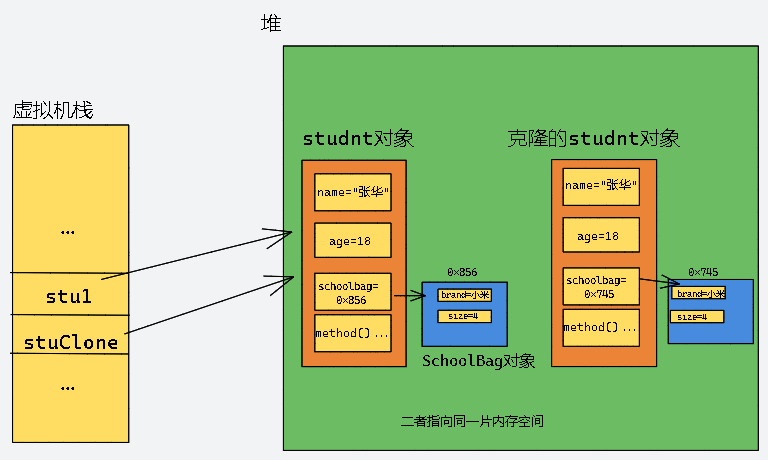
Java中的深拷贝和浅拷贝
目录 🍎引出拷贝 🍎浅拷贝 🍎深拷贝 🍎总结 引出拷贝 现在有一个学生类和书包类,在学生类中有引用类型的书包变量: class SchoolBag {private String brand; //书包的品牌private int size; //书…...

大文件上传
上图就是大致的流程一、标题图片上传课程的标题图片Ajax发送请求到后端后端接收到图片使用IO流去保存图片,返回图片的信息对象JS回调函数接收对象通过$("元素id").val(值),方式给页面form表达img标签src属性值,达到上传图片并回显二…...

Python每日一练(20230327)
目录 1. 最大矩形 🌟🌟🌟 2. 反转链表 II 🌟🌟 3. 单词接龙 II 🌟🌟🌟 🌟 每日一练刷题专栏 🌟 Golang每日一练 专栏 Python每日一练 专栏 C/C每日…...

Centos7 升级内核到5.10mellanox 编译安装
升级5.10内核 #uname -r 重启后 进入新的内核 进入新的内核信息 直接查看是看不到gcc版本 5.10需要高版本gcc 才可以进行编译...

冯诺依曼,操作系统以及进程概念
文章目录一.冯诺依曼体系结构二.操作系统(operator system)三.系统调用和库函数四.进程1.进程控制块(PCB)2.查看进程3.系统相关的调用4.fork介绍(并发引入)五.总结一.冯诺依曼体系结构 计算机大体可以说是…...

7.网络爬虫—正则表达式详讲
7.网络爬虫—正则表达式详讲与实战Python 正则表达式re.match() 函数re.search方法re.match与re.search的区别re.compile 函数检索和替换检索:替换:findallre.finditerre.split正则表达式模式常见的字符类正则模式正则表达式模式量词正则表达式举例前言&…...

关于位运算的巧妙性:小乖,你真的明白吗?
一.位运算的概念什么是位运算?程序中的所有数在计算机内存中都是以二进制的形式储存的。位运算就是直接对整数在内存中的二进制位进行操作。位运算就是直接操作二进制数,那么有哪些种类的位运算呢?常见的运算符有与(&)、或(|)、异或(^)、…...

【Android车载系列】第5章 AOSP开发环境配置
1 硬件支持 建议空闲内存16G以上,同时硬盘400G以上 内存不够可以使用 Linux 的交换分区2 VMware Workstation安装 https://download3.vmware.com/software/wkst/file/VMware-workstation-full-16.1.1-17801498.exe2.1 Ubuntu镜像 http://mirrors.aliyun.com/ubun…...
个人时间管理网站—Git项目管理
🌟所属专栏:献给榕榕🐔作者简介:rchjr——五带信管菜只因一枚😮前言:该专栏系为女友准备的,里面会不定时发一些讨好她的技术作品,感兴趣的小伙伴可以关注一下~👉文章简介…...

2023最新ChatGPT整理的40道Java高级面试题
2023 年最火的就是 ChatGPT 了,很多同事使用他完成一些代码上的智能提示,也有人使用它发了财《「用ChatGPT年入百万!」各博主发布生财之道,网友:答辩搬运工》、《“躺着就能赚大钱”?ChatGPT火了,有人早就动起坏脑筋》等。 最近我也使用 ChatGPT 写技术文章了,比如:《…...
单机分布式一体化是什么?真的是数据库的未来吗,OceanBase或将开启新的里程碑
一. 数据 我们先说说数据这个东西,这段时间的ChatGPT在全世界的爆火说明了一件事,数据是有用的,并且大量的数据如果有一个合适的LLM大规模语言模型训练之后,可以很高程度的完成很多意想不到的事情。 我们大多数的时候的注意力只…...

100天精通Python丨基础知识篇 —— 03、Python基础知识扫盲(第一个Python程序,13个小知识点)
文章目录🐜 1、Python 初体验Pycharm 第一个程序交互式编程第一个程序🐞 2、Python 引号🐔 3、Python 注释🦅 4、Python 保留字符🐯 5、Python 行和缩进🐨 6、Python 空行🐹 7、Python 输出&…...
springboot逍遥大药房管理系统
084-springboot逍遥大药房管理系统演示录像开发语言:Java 框架:springboot JDK版本:JDK1.8 服务器:tomcat7 数据库:mysql 5.7 数据库工具:Navicat11 开发软件:eclipse/myeclipse/idea Maven包&a…...

ZYNQ中的GPIO与AXI GPIO
GPIO GPIO—一种外设,对器件进行观测和控制MIO—将来自PS外设和静态存储器接口的访问多路复用到PS引脚上处理器控制外设的方法—通过一组寄存器包括状态寄存器和控制寄存器,这些寄存器都是有地址的,通过这些寄存器的读写进行外设的控制sessi…...

接口导入功能
1.接口api export function import(param) { return fetch({ url: XXX.import, method: POST, headers: { Content-Type: multipart/form-data; }, data: param }) } 2.页面vue 和 js逻辑 <el-button :loading"disable&qu…...

网络安全知识点总结 期末总结
1、信息安全从总体上可以分成5个层次,密码技术 是信息安全中研究的关键点。 2、握手协议 用于客户机与服务器建立起安全连接之前交换一系列信息的安全信道。 3、仅设立防火墙系统,而没有 安全策略 ,防火墙就形同虚设。 4、应用代理防火墙 …...

挑战杯推荐项目
“人工智能”创意赛 - 智能艺术创作助手:借助大模型技术,开发能根据用户输入的主题、风格等要求,生成绘画、音乐、文学作品等多种形式艺术创作灵感或初稿的应用,帮助艺术家和创意爱好者激发创意、提高创作效率。 - 个性化梦境…...

FFmpeg 低延迟同屏方案
引言 在实时互动需求激增的当下,无论是在线教育中的师生同屏演示、远程办公的屏幕共享协作,还是游戏直播的画面实时传输,低延迟同屏已成为保障用户体验的核心指标。FFmpeg 作为一款功能强大的多媒体框架,凭借其灵活的编解码、数据…...
【机器视觉】单目测距——运动结构恢复
ps:图是随便找的,为了凑个封面 前言 在前面对光流法进行进一步改进,希望将2D光流推广至3D场景流时,发现2D转3D过程中存在尺度歧义问题,需要补全摄像头拍摄图像中缺失的深度信息,否则解空间不收敛…...

【磁盘】每天掌握一个Linux命令 - iostat
目录 【磁盘】每天掌握一个Linux命令 - iostat工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景 注意事项 【磁盘】每天掌握一个Linux命令 - iostat 工具概述 iostat(I/O Statistics)是Linux系统下用于监视系统输入输出设备和CPU使…...

2.Vue编写一个app
1.src中重要的组成 1.1main.ts // 引入createApp用于创建应用 import { createApp } from "vue"; // 引用App根组件 import App from ./App.vue;createApp(App).mount(#app)1.2 App.vue 其中要写三种标签 <template> <!--html--> </template>…...

STM32标准库-DMA直接存储器存取
文章目录 一、DMA1.1简介1.2存储器映像1.3DMA框图1.4DMA基本结构1.5DMA请求1.6数据宽度与对齐1.7数据转运DMA1.8ADC扫描模式DMA 二、数据转运DMA2.1接线图2.2代码2.3相关API 一、DMA 1.1简介 DMA(Direct Memory Access)直接存储器存取 DMA可以提供外设…...

如何将联系人从 iPhone 转移到 Android
从 iPhone 换到 Android 手机时,你可能需要保留重要的数据,例如通讯录。好在,将通讯录从 iPhone 转移到 Android 手机非常简单,你可以从本文中学习 6 种可靠的方法,确保随时保持连接,不错过任何信息。 第 1…...

2025 后端自学UNIAPP【项目实战:旅游项目】6、我的收藏页面
代码框架视图 1、先添加一个获取收藏景点的列表请求 【在文件my_api.js文件中添加】 // 引入公共的请求封装 import http from ./my_http.js// 登录接口(适配服务端返回 Token) export const login async (code, avatar) > {const res await http…...

第一篇:Agent2Agent (A2A) 协议——协作式人工智能的黎明
AI 领域的快速发展正在催生一个新时代,智能代理(agents)不再是孤立的个体,而是能够像一个数字团队一样协作。然而,当前 AI 生态系统的碎片化阻碍了这一愿景的实现,导致了“AI 巴别塔问题”——不同代理之间…...

使用SSE解决获取状态不一致问题
使用SSE解决获取状态不一致问题 1. 问题描述2. SSE介绍2.1 SSE 的工作原理2.2 SSE 的事件格式规范2.3 SSE与其他技术对比2.4 SSE 的优缺点 3. 实战代码 1. 问题描述 目前做的一个功能是上传多个文件,这个上传文件是整体功能的一部分,文件在上传的过程中…...