基于集成学习的用户流失预测并利用shap进行特征解释
基于集成学习的用户流失预测并利用shap进行特征解释
小P:小H,如果我只想尽可能的提高准确率,有什么好的办法吗?
小H:优化数据、调参侠、集成学习都可以啊
小P:什么是集成学习啊,听起来就很厉害的样子
小H:集成学习就类似于【三个臭皮匠顶个诸葛亮】,将一些基础模型组合起来使用,以期得到更好的结果
集成学习实战
数据准备
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
import warnings
warnings.filterwarnings('ignore')from scipy import stats
from sklearn.preprocessing import StandardScaler
from imblearn.over_sampling import SMOTE
from sklearn.model_selection import train_test_split, cross_val_score, GridSearchCV, KFold
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier, VotingClassifier, ExtraTreesClassifier
import xgboost as xgb
from sklearn.metrics import accuracy_score, auc, confusion_matrix, f1_score, \precision_score, recall_score, roc_curve # 导入指标库
import prettytable
import sweetviz as sv # 自动eda
import toad
from sklearn.model_selection import StratifiedKFold, cross_val_score # 导入交叉检验算法# 绘图初始化
%matplotlib inline
pd.set_option('display.max_columns', None) # 显示所有列
sns.set(style="ticks")
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号# 导入自定义模块
import sys
sys.path.append("/Users/heinrich/Desktop/Heinrich-blog/数据分析使用手册")
from keyIndicatorMapping import *
上述自定义模块
keyIndicatorMapping如果有需要的同学可关注公众号HsuHeinrich,回复【数据挖掘-自定义函数】自动获取~
以下数据如果有需要的同学可关注公众号HsuHeinrich,回复【数据挖掘-集成学习】自动获取~
# 读取数据
raw_data = pd.read_csv('classification.csv')
raw_data.head()

# 缺失值填充,SMOTE方法限制非空
raw_data=raw_data.fillna(raw_data.mean())
# 数据集分割
X = raw_data[raw_data.columns.drop('churn')]
y = raw_data['churn']
# 标准化
scaler = StandardScaler()
scale_data = scaler.fit_transform(X)
X = pd.DataFrame(scale_data, columns = X.columns)
# 划分训练测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.3, random_state=0)
# 过采样
model_smote = SMOTE(random_state=0) # 建立SMOTE模型对象
X_train, y_train = model_smote.fit_resample(X_train, y_train)
模型对比
%%time
# 初选分类模型
model_names = ['LR', 'SVC', 'RFC', 'XGBC'] # 不同模型的名称列表
model_lr = LogisticRegression(random_state=10) # 建立逻辑回归对象
model_svc = SVC(random_state=0, probability=True) # 建立支持向量机分类对象
model_rfc = RandomForestClassifier(random_state=10) # 建立随机森林分类对象
model_xgbc = xgb.XGBClassifier(use_label_encoder=False, eval_metric='auc', random_state=10) # 建立XGBC对象# 模型拟合结果
model_list = [model_lr, model_svc, model_rfc, model_xgbc] # 不同分类模型对象的集合
pre_y_list = [model.fit(X_train, y_train).predict(X_test) for model in model_list] # 各个回归模型预测的y值列表
CPU times: user 2.49 s, sys: 125 ms, total: 2.62 s
Wall time: 843 ms
# 核心评估指标
metrics_dic = {'model_names':[],'auc':[],'ks':[],'accuracy':[],'precision':[],'recall':[],'f1':[]}
for model_name, model, pre_y in zip(model_names, model_list, pre_y_list):y_prob = model.predict_proba(X_test) # 获得决策树的预测概率,返回各标签(即0,1)的概率fpr, tpr, thres = roc_curve(y_test, y_prob[:, 1]) # ROC y_score[:, 1]取标签为1的概率,这样画出来的roc曲线为正metrics_dic['model_names'].append(model_name)metrics_dic['auc'].append(auc(fpr, tpr)) # AUCmetrics_dic['ks'].append(max(tpr - fpr)) # KS值metrics_dic['accuracy'].append(accuracy_score(y_test, pre_y))metrics_dic['precision'].append(precision_score(y_test, pre_y))metrics_dic['recall'].append(recall_score(y_test, pre_y))metrics_dic['f1'].append(f1_score(y_test, pre_y))
pd.DataFrame(metrics_dic)

集成学习
%%time
# 建立组合评估器列表 均衡稳定性和准确性 这里只是演示,就将所有模型都纳入了
estimators = [('SVC', model_svc), ('RFC', model_rfc), ('XGBC', model_xgbc), ('LR', model_lr)]
model_vot = VotingClassifier(estimators=estimators, voting='soft', weights=[1.1, 1.1, 0.9, 1.2],n_jobs=-1) # 建立组合评估模型
cv = StratifiedKFold(5) # 设置交叉检验方法 分类算法常用交叉检验方法
cv_score = cross_val_score(model_vot, X_train, y_train, cv=cv, scoring='accuracy') # 交叉检验
print('{:*^60}'.format('Cross val scores:'),'\n',cv_score) # 打印每次交叉检验得分
print('Mean scores is: %.2f' % cv_score.mean()) # 打印平均交叉检验得分
*********************Cross val scores:********************** [0.73529412 0.7745098 0.85294118 0.85294118 0.87745098]
Mean scores is: 0.82
CPU times: user 2.38 s, sys: 432 ms, total: 2.81 s
Wall time: 5 s
# 模型训练
model_vot.fit(X_train, y_train) # 模型训练
VotingClassifier(estimators=[('SVC', SVC(probability=True, random_state=0)),('RFC', RandomForestClassifier(random_state=10)),('XGBC',XGBClassifier(base_score=0.5, booster='gbtree',colsample_bylevel=1,colsample_bynode=1,colsample_bytree=1,eval_metric='rmse', gamma=0,gpu_id=-1, importance_type='gain',interaction_constraints='',learning_rate=0.300000012,max...min_child_weight=1, missing=nan,monotone_constraints='()',n_estimators=100, n_jobs=8,num_parallel_tree=1,random_state=10, reg_alpha=0,reg_lambda=1, scale_pos_weight=1,subsample=1, tree_method='exact',use_label_encoder=False,validate_parameters=1,verbosity=None)),('LR', LogisticRegression(random_state=10))],n_jobs=-1, voting='soft', weights=[1.1, 1.1, 0.9, 1.2])
model_confusion_metrics(model_vot, X_test, y_test, 'test')
model_core_metrics(model_vot, X_test, y_test, 'test')
confusion matrix for test+----------+--------------+--------------+
| | prediction-0 | prediction-1 |
+----------+--------------+--------------+
| actual-0 | 53 | 31 |
| actual-1 | 37 | 179 |
+----------+--------------+--------------+
core metrics for test+-------+----------+-----------+--------+-------+-------+
| auc | accuracy | precision | recall | f1 | ks |
+-------+----------+-----------+--------+-------+-------+
| 0.805 | 0.773 | 0.589 | 0.631 | 0.609 | 0.504 |
+-------+----------+-----------+--------+-------+-------+
可以看到集成学习的各项指标表现均优异,只有召回率低于LR
利用shap进行模型解释
shap作为一种经典的事后解释框架,可以对每一个样本中的每一个特征变量,计算出其重要性值,达到解释的效果。该值在shap中被专门称为Shapley Value。
该系列以应用为主,对于具体的理论只会简单的介绍它的用途和使用场景。这里的shap相关知识 可以参考黑盒模型事后归因解析:SHAP方法、SHAP知识点全汇总
学无止境,且学且珍惜~
# pip install shap
import shap
# 初始化
shap.initjs()
# 通过采样提高计算效率,但会导致准确率降低。表现在base_value与mean(model.predict_proba(X))存在差异,不建议K太小
# X_test_summary = shap.sample(X_test, 200)
# X_test_summary = shap.kmeans(X_test, 150)
explainer = shap.KernelExplainer(model_vot.predict_proba, X_test)
shap_values = explainer.shap_values(X_test, nsamples = 10)
Using 300 background data samples could cause slower run times. Consider using shap.sample(data, K) or shap.kmeans(data, K) to summarize the background as K samples.
- 单样本查看
# 单样本查看-1概率较高的样本 # 208
shap.force_plot(base_value=explainer.expected_value[1],shap_values=shap_values[1][208],features = X_test.iloc[208,:])
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AxXaXK0k-1679902455430)(null)]
base_value:所有样本预测值的均值,即
base_value=model_vot.predict_proba(X_test)[:,1].mean()⚠️注意:当进行采样或者kmean加速计算时,会损失一定准确度。即explainer带入的是X_test_summary
f(x):预测的实际值
model_vot.predict_proba(X_test)[:,1]data:样本特征值
shap_values:f(x)-base_value;shap值越大越红,越小越蓝
# 验证base_value print('所有样本预测标签1的概率均值:',model_vot.predict_proba(X_test)[:,1].mean()) print('base_value:',explainer.expected_value[1])所有样本预测标签1的概率均值: 0.3519852365700774 base_value: 0.35198523657007774经验证,base_value计算逻辑正确
# 验证单一样本 i=208 fx=model_vot.predict_proba(X_test)[:,1][i] da=X_test.iloc[i,:] sv=fx-explainer.expected_value[1] sv_val=shap_values[1][i].sum() print('f(x):',fx) print('shap_values:',sv,sv_val)f(x): 0.9264517406651224 shap_values: 0.5744665040950446 0.5744665040950446经验证,shap_values计算逻辑正确
- 特征重要性
# 特征重要程度
shap.summary_plot(shap_values[1],X_test,max_display=10,plot_type="bar")

- 蜂窝图体现特征重要性
# 特征与样本蜂窝图
shap.summary_plot(shap_values[1],X_test,max_display=10)

retention_days越大,蓝色的样本越多,表明较高的retention_days有助于缓减流失
- 特征的shap值
# 单特征预测结果
shap.dependence_plot("retention_days", shap_values[1], X_test, interaction_index=None)

retention_days低的shape值较大,上面讲到shap越大越红,对于y起到提高作用。即retention_days与流失负相关
# 双特征交叉影响
shap.dependence_plot("retention_days", shap_values[1], X_test, interaction_index='level')
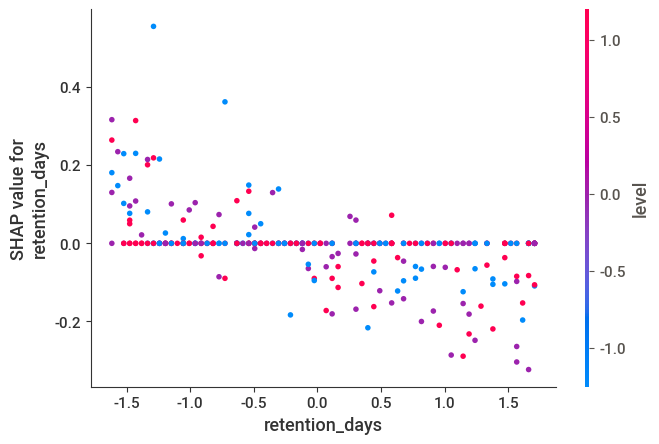
- 在较低的retention_days(如-1.5),高level(level=1.0)的shepae值较高(红色点),在0.2附近
- 在较高的retention_days(如1.5),高level(level=1.0)的shepae值较低(红色点),在-0.2附近
总结
集成学习能有效地提高模型的预测性能,但是使得模型内部结构更为复杂,无法直观理解。好在可以借助shap进行常见的特征重要性解释等。
共勉~
相关文章:
基于集成学习的用户流失预测并利用shap进行特征解释
基于集成学习的用户流失预测并利用shap进行特征解释 小P:小H,如果我只想尽可能的提高准确率,有什么好的办法吗? 小H:优化数据、调参侠、集成学习都可以啊 小P:什么是集成学习啊,听起来就很厉害的…...

【Java版oj 】 day17杨辉三角形的变形、计算某字符出现次数
目录 一、杨辉三角形的变形 (1)原题再现 (2)问题分析 (3)完整代码 二、计算某字符出现次数 (1)原题再现 (2)问题分析 (3)完整代…...

智能驾驶芯片赛道混战:如何看待5类玩家的竞争格局?
智能驾驶芯片赛道,一直是业内关注的焦点。 高工智能汽车注意到,针对L0-L2,业内基本采用智能前视一体机(IFC)方案;要实现高速NOA、城市NOA等更为高阶的智驾功能等,则基本采用域控制器方案。从IF…...

vue antd table表格的增删改查(三)input输入框根据关键字模糊查询【后台管理系统 使用filter与indexOf嵌套】
vue antd table表格的增删改查(三)input输入框根据关键字查询【后台管理系统filter与indexOf嵌套】知识回调场景复现利用filter和indexOf方法实现模糊查询1.查询对象为单层的数组元素2.查询对象为多层的数组元素(两层为例)3.查询对…...

【计组】性能指标——速度
衡量计算机性能的指标之一——速度,是指计算机执行完所有指令所耗费时间的长短。 一、概念: 引出了如下概念:机器字长:指计算机一次能处理的二进制位数,也就是我们通常说的32位64位计算机中的位。 机器字长决定了计算…...

【PC自动化测试-4】inspect.exe 详解
1,inspect.exe图解" 检查 "窗口有几个主要部分:● 标题栏。 显示" 检查 HWND (窗口句柄) 。● 菜单栏。 提供对 检查功能 的访问权限。● 工具 栏。 提供对 检查功能 的访问权限。● 树视图。 将 UI 元素的层次结构呈现为树视图控件&…...

比肩ChatGPT的国产AI:文心一言——有话说
🔗 运行环境:chatGPT,文心一言 🚩 撰写作者:左手の明天 🥇 精选专栏:《python》 🔥 推荐专栏:《算法研究》 #### 防伪水印——左手の明天 #### 💗 大家好&am…...

【第13届蓝桥杯】C/C++组B组省赛题目+详解
A.九进制转十进制 题目描述 九进制正整数(2022)9转换成十进制等于多少? 解: 2*9^02*9^12*9^321814581478; B.顺子日期 题目描述 小明特别喜欢顺子。顺子指的就是连续的三个数字:123、456等。顺子日期指的就是在日期的yyyymmdd表示法中&a…...
STM32 KEI 调试新手注意事项
记录一下解决问题的经过:1,用STM32 cubeMX 生成的MKD工程,默认的代码优化级别是level3 , 这个级别 会把一些代码给优化掉,造成一些意想不到的结果,最直观的就是 被优化的语句不能打断点调试,当你打了断点 ,…...

Windows权限提升—令牌窃取、UAC提权、进程注入等提权
Windows权限提升—令牌窃取、UNC提权、进程注入等提权1. 前言2. at本地命令提权2.1. 适用范围2.2. 命令使用2.3. 操作步骤2.3.1. 模拟提权2.3.2. at配合msf提权2.3.2.1. 生成木马文件2.3.2.2. 设置监听2.3.2.3. 设置反弹2.3.2.4. 查看反弹效果3. sc本地命令提权3.1. 适用范围3.…...

不做孔乙己也不做骆驼祥子
对教书育人的探讨前言一、为什么要“育人”1.育人为先2.育人是快乐的二、怎么“育人”前言 借着本次师德师风建设的主题,跟各位老师谈一谈对于“育人”的一些观点,和教育的一些看法。本文仅代表自己的观点,有不到位的地方,大家可以…...
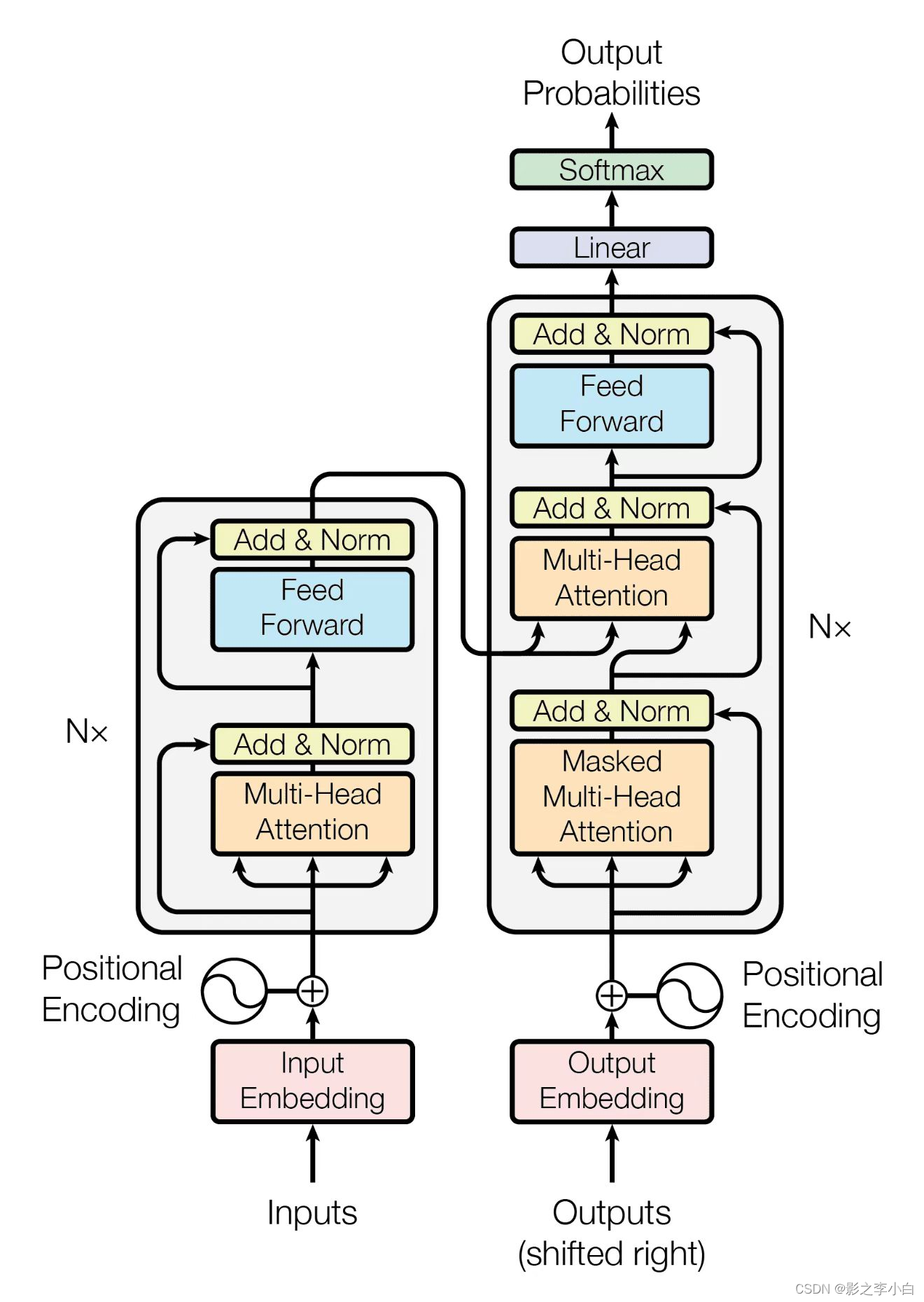
ChatGPT原理解析
文章目录Transformer模型结构构成组件整体流程GPT预训练微调模型GPT2GPT3局限性GPT4相关论文Transformer Transformer,这是一种仅依赖于注意力机制而不使用循环或卷积的简单模型,它简单而有效,并且在性能方面表现出色。 在时序模型中&#…...

常用算法实现【必会】:sort/bfs/dfs
文章目录常用排序算法实现(Go版本)BFS 广度优先遍历,利用queueDFS 深度优先遍历,利用stack前序遍历(根 左 右)中序遍历(左根右)后序遍历(左 右 根)BFS/DFS 总…...
瑟瑟发抖吧——用了这款软件,我的开发效率提升了50%
一、前言 开发中,一直听到有人讨论是否需要重复造轮子,我觉得有能力的人,轮子得造。但是往往开发周期短,用轮子所节省的时间去更好的理解业务,应用到业务中,也能清晰发现轮子的利弊,一定意义上…...

笔记本只使用Linux是什么体验?
个人主页:董哥聊技术我是董哥,嵌入式领域新星创作者创作理念:专注分享高质量嵌入式文章,让大家读有所得!近期,也有朋友问我,笔记本只安装Linux怎么样,刚好我也借此来表达一下我的感受…...

pipeline业务发布
业务环境介绍公司当前业务上线流程首先是通过nginx灰度,dubbo-admin操作禁用,然后发布上线主机,发布成功后,dubbo-admin启用,nginx启用主机;之前是通过手动操作,很不方便,本次优化为…...

【巨人的肩膀】JAVA面试总结(七)
💪MyBatis 1、谈谈你对MyBatis的理解 Mybatis是一个半ORM(对象关系映射)框架,它内部封装了JDBC,加载驱动、创建连接、创建statement等繁杂的过程,开发者开发时只需要关注如何编写SQL语句,可以…...

Python满屏表白代码
目录 前言 爱心界面 无限弹窗 前言 人生苦短,我用Python!又是新的一周啦,本期博主给大家带来了一个全新的作品:满屏表白代码,无限弹窗版!快快收藏起来送给她吧~ 爱心界面 def Heart(): roottk.Tk…...
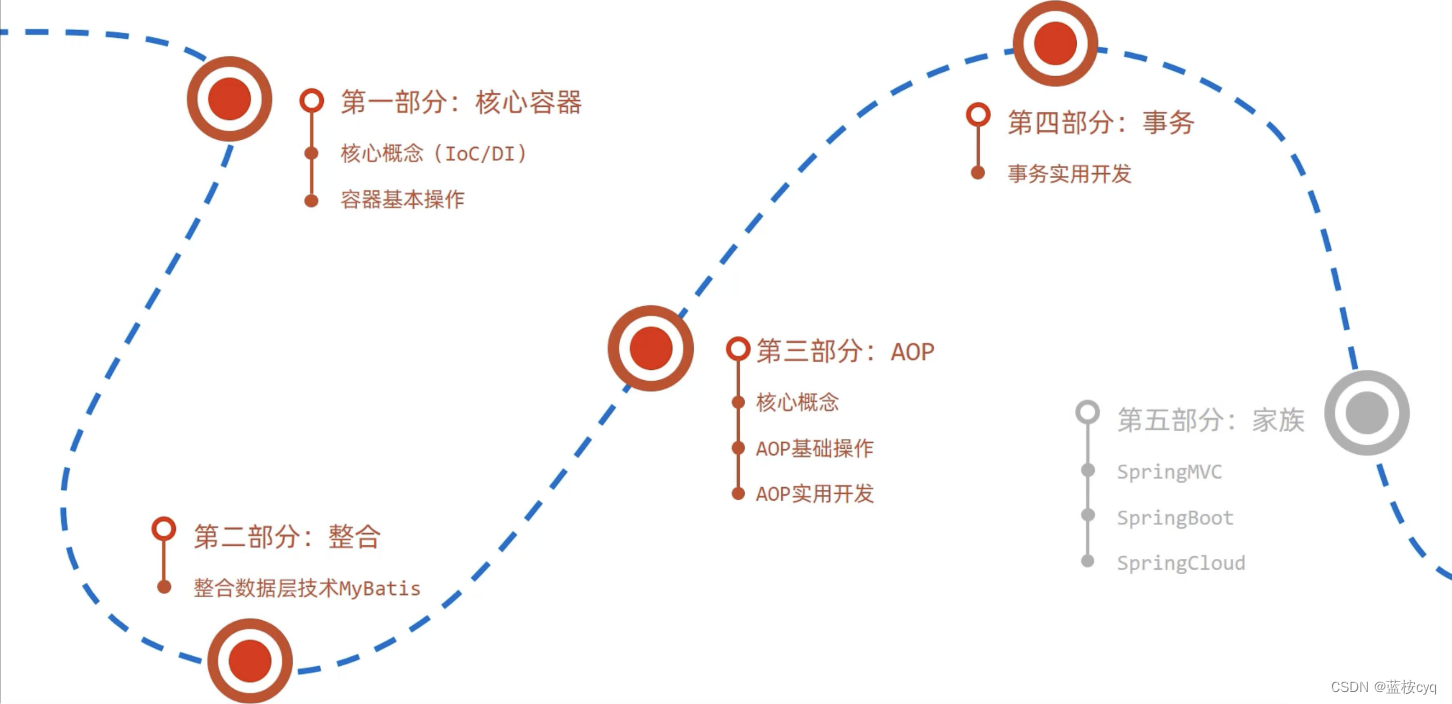
Spring学习流程介绍
Spring学习流程介绍 Spring技术是JavaEE开发必备技能,企业开发技术选型命中率>90%; Spring有下面两大优势: 简化开发: 降低企业级开发的复杂性 框架整合: 高效整合其他技术,提高企业级应用开发与运行效率 Spring官网: https://spring.io/ Spring发展…...
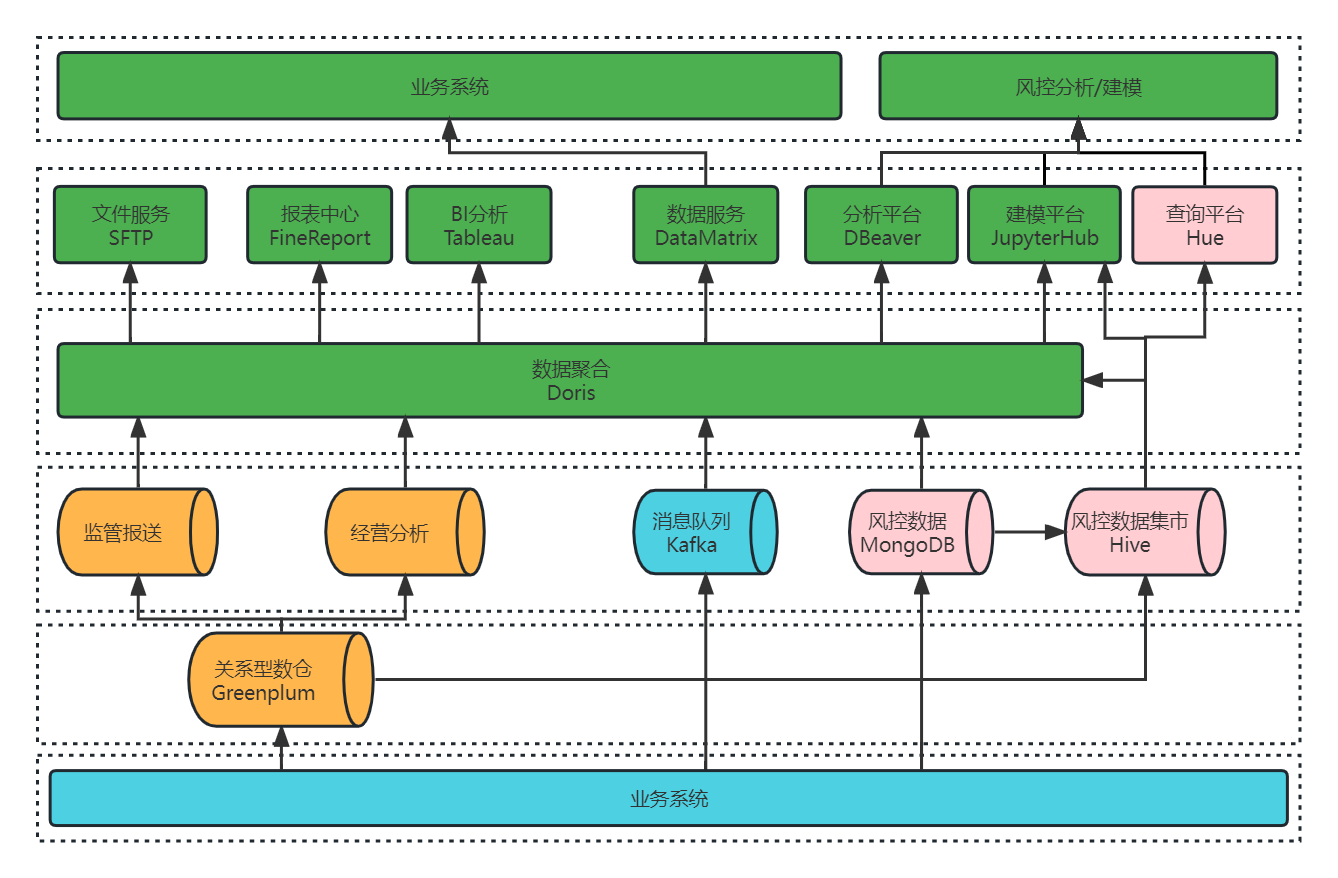
杭银消金基于 Apache Doris 的统一数据查询网关改造
导读: 随着业务量快速增长,数据规模的不断扩大,杭银消金早期的大数据平台在应对实时性更强、复杂度更高的的业务需求时存在瓶颈。为了更好的应对未来的数据规模增长,杭银消金于 2022 年 10 月正式引入 Apache Doris 1.2 对现有的风…...
: K8s 核心概念白话解读(上):Pod 和 Deployment 究竟是什么?)
云原生核心技术 (7/12): K8s 核心概念白话解读(上):Pod 和 Deployment 究竟是什么?
大家好,欢迎来到《云原生核心技术》系列的第七篇! 在上一篇,我们成功地使用 Minikube 或 kind 在自己的电脑上搭建起了一个迷你但功能完备的 Kubernetes 集群。现在,我们就像一个拥有了一块崭新数字土地的农场主,是时…...

Lombok 的 @Data 注解失效,未生成 getter/setter 方法引发的HTTP 406 错误
HTTP 状态码 406 (Not Acceptable) 和 500 (Internal Server Error) 是两类完全不同的错误,它们的含义、原因和解决方法都有显著区别。以下是详细对比: 1. HTTP 406 (Not Acceptable) 含义: 客户端请求的内容类型与服务器支持的内容类型不匹…...

java_网络服务相关_gateway_nacos_feign区别联系
1. spring-cloud-starter-gateway 作用:作为微服务架构的网关,统一入口,处理所有外部请求。 核心能力: 路由转发(基于路径、服务名等)过滤器(鉴权、限流、日志、Header 处理)支持负…...

376. Wiggle Subsequence
376. Wiggle Subsequence 代码 class Solution { public:int wiggleMaxLength(vector<int>& nums) {int n nums.size();int res 1;int prediff 0;int curdiff 0;for(int i 0;i < n-1;i){curdiff nums[i1] - nums[i];if( (prediff > 0 && curdif…...

算法岗面试经验分享-大模型篇
文章目录 A 基础语言模型A.1 TransformerA.2 Bert B 大语言模型结构B.1 GPTB.2 LLamaB.3 ChatGLMB.4 Qwen C 大语言模型微调C.1 Fine-tuningC.2 Adapter-tuningC.3 Prefix-tuningC.4 P-tuningC.5 LoRA A 基础语言模型 A.1 Transformer (1)资源 论文&a…...

站群服务器的应用场景都有哪些?
站群服务器主要是为了多个网站的托管和管理所设计的,可以通过集中管理和高效资源的分配,来支持多个独立的网站同时运行,让每一个网站都可以分配到独立的IP地址,避免出现IP关联的风险,用户还可以通过控制面板进行管理功…...

FFmpeg:Windows系统小白安装及其使用
一、安装 1.访问官网 Download FFmpeg 2.点击版本目录 3.选择版本点击安装 注意这里选择的是【release buids】,注意左上角标题 例如我安装在目录 F:\FFmpeg 4.解压 5.添加环境变量 把你解压后的bin目录(即exe所在文件夹)加入系统变量…...

OD 算法题 B卷【正整数到Excel编号之间的转换】
文章目录 正整数到Excel编号之间的转换 正整数到Excel编号之间的转换 excel的列编号是这样的:a b c … z aa ab ac… az ba bb bc…yz za zb zc …zz aaa aab aac…; 分别代表以下的编号1 2 3 … 26 27 28 29… 52 53 54 55… 676 677 678 679 … 702 703 704 705;…...

「全栈技术解析」推客小程序系统开发:从架构设计到裂变增长的完整解决方案
在移动互联网营销竞争白热化的当下,推客小程序系统凭借其裂变传播、精准营销等特性,成为企业抢占市场的利器。本文将深度解析推客小程序系统开发的核心技术与实现路径,助力开发者打造具有市场竞争力的营销工具。 一、系统核心功能架构&…...
 Module Federation:Webpack.config.js文件中每个属性的含义解释)
MFE(微前端) Module Federation:Webpack.config.js文件中每个属性的含义解释
以Module Federation 插件详为例,Webpack.config.js它可能的配置和含义如下: 前言 Module Federation 的Webpack.config.js核心配置包括: name filename(定义应用标识) remotes(引用远程模块࿰…...