python学习——多线程
python学习——多线程
- 概念
- python中线程的开发
- 线程的启动
- 线程的退出和传参
- threading的属性和方法
- threading实例的属性和方法
- 多线程
- daemon线程和non-demone线程
- daemon线程的应用场景
- 线程的join
- threading.local类
- 线程的延迟执行:Timer
- 线程同步
- Event 事件
- Lock ——锁
- 加锁和解锁
- 锁的应用场景
- 非阻塞锁
- 可重入的锁Rlock
- Condition
- Barrier ——栅栏/屏障
- Barrier的应用
- Semaphone信号量
概念
- 并行(parallel):同时做某些事情,可以互不干扰的同一时刻做几件事,
-
- 例如:跑在道路上,不同车道上的汽车(一条车道一辆车)
- 并行(concurrenty):同事做某些事情,但是强调同一个时段做几件事情
-
- 例如:十字路口的红绿灯,每个方向有10min的通行时间,不同方向的车辆交替行驶,实现不同方向的通行
- 如果要处理的任务过多,处理机器较少,就需要将各个任务排成一个队列,按照一定的顺序解决(例如:先进先出)
- 缓冲区:就是排成的队列,可以认为他是一个缓冲地带
- 优先队列:如果有紧急任务,可以将紧急任务排在特殊的队列中,优先解决特殊队列中的任务,这个特殊队列就是优先队列
- 争抢:只有一个处理机,他一次也只能处理一个任务,一个任务占据处理机,就视为锁定窗口,多个任务挤着去占用处理机,就是争抢的过程
- 在任务未处理完之前不能处理其他任务,这就是锁
- 任务抢到处理机,就上锁,锁有排他性,其他任务只能等待
- 预处理:一种提前加载用户需要的数据的思路,这种方式缓存常用
-
- 例如,食堂打饭,80%的人喜欢的菜品提前做,打完即走,缩短窗口的锁定时间,20%的人先做,这样解决任务的速度就会块很多
- 水平扩展:日常通过购买更多的服务器,或者多开进程,进程实现并行处理,开解决并发问题的思想
-
- 计算机中,单核CPU同事处理多个任务,这不是并行,是并发
- 垂直扩展:提高任务的执行速度,或者提高单个性能CPU的性能,或者单个服务器安装更多的CPU的思想
- 消息中间件,常见的有RabbitMQ、ActiveMQ(Apache提供)、RecketMQ(阿里提供)、kafka(分布式服务,Apache提供)等,系统之外缓存消息队列的地方,用于存放系统接受不了的消息,提升消息的存储能力
- 进程和线程之间的关系:
-
- 线程是操作熊能够进行运算调度的最小单位
-
- 线程被包含在进程中,是进程中实际运作的单位
-
- 一个程序执行的实例,就是一个进程
-
- 进程是计算机中程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统的基础
-
- 程序被操作系统加载到内存中,就是进程,进程存放的指令和数据资源,他是线程的容器
-
- 线程是轻量级的进程,是程序执行的最小单元
-
- 一个进程可以对应多个线程,线程可以认为是进程的父类,线程可以共享进程的资源
- python中,进程会启动一个解释器进程,里面至少有一个线程,这个线程就是主线程。不同进程之间是不可以随便交互数据的
python中线程的开发
- python中,线程开发使用标准库:
threading - 线程的区分是靠线程id的,不是靠名字的
- 其原始代码中有如下部分:
def __init__(self, group=None, target=None, name=None,args=(), kwargs=None, *, daemon=None):
- 以上代码中
-
- target,表示线程调用的对象,也就是目标函数
-
- name,为线程起的名字
-
- args,为目标函数传递的实参,类型是元祖
-
- kwargs,为目标函数传递的关键词参数,目标是字典、
线程的启动
import threading # 加载线程库
import timedef worker():# 自定义线程函数,启动线程后要调用的方法for i in range(0,9):time.sleep(1)print("welcome to study python!")def worker_1():# 自定义线程函数,启动线程后要调用的方法for i in range(0,9):time.sleep(1)print("welcome to study threading……!")t = threading.Thread(target=worker)
# 对线程库中的类进行实例化,指定线程调用的函数
t.start()
#启动线程,线程启动之后,不杀死线程的情况下
# 要将目标函数执行完才能结束t = threading.Thread(target=worker_1)
t.start()
# 并发运行,有两个函数,启动两个线程
- 代码解析:
-
- 通过
threading.Thread创建一个线程对象,target是目标函数
- 通过
-
- 线程启动调用start方法
-
- 并发调用多个函数,就需要启动两个线程,分别对应不同的函数,已达到并发的效果
线程的退出和传参
- python中,没有提供线程退出的方法,线程会在下面情况下退出
-
- 线程函数内语句执行完毕
-
- 线程函数中抛出未处理的异常
- python中的线程没有优先级,没有线程组的概念,也不能被销毁,停止,挂起,因此也就没有恢复和中断
- 线程的传参和函数的传参没有区别,其本质上就是函数传参,实参传元祖,关键字参数传字典
threading的属性和方法
current_thread:返回当前线程的对象main_thread:返回主线程的对象active_count:当前处于alive状态的线程个数enumerate:返回所有或者的线程列表-
- 包括已经终止的线程和未开始的线程
get_ident:返回当前线程的ID,非0 整数
import threading # 加载线程库
import timedef worker():# 自定义线程函数,启动线程后要调用的方法for i in range(0,3):time.sleep(1)print("welcome to study python!")print(threading.current_thread())
print(threading.active_count())
print(threading.enumerate())
print(threading.get_ident())
t = threading.Thread(target=worker)
t.start()
# 并发运行,有两个函数,启动两个线程
threading实例的属性和方法
- 线程的name只是一个名称,可以重复,但是ID必须唯一,不过ID可以在退出线程之后再利用
name:只是线程的一个名字,或者可以理解为一个标识ident:线程ID,是一个非0 整数-
- 线程启动之后才会有ID,否则为None
-
- 线程退出之后,ID依旧可以访问
-
- ID可以重复利用
is_alive:返回线程是否活着,是一个布尔值start:启动线程,每一个线程必须且只能执行该方法一次run:运行线程函数- 使用start方法启动线程,是启动了一个新的线程
- 但是使用run方法,并没有启动新的线程,就是在主线程中调用了一个普通的函数
- 因此,启动线程需要使用start方法,可以启动多个线程
import threading # 加载线程库
import timedef worker():# 自定义线程函数,启动线程后要调用的方法for i in range(0,3):time.sleep(1)print("welcome to study python!")t = threading.Thread(target=worker)
t.start()
# 并发运行,有两个函数,启动两个线程print(t.name)
print(t.ident)
print(t.is_alive())print(time.sleep(10))print(t.name)
print(t.ident)
print(t.is_alive())**********************run_result*******************
Thread-1
14664
True
welcome to study python!
welcome to study python!
welcome to study python!
None
Thread-1
14664
False
多线程
- 多线程,就是一个进程中有多个线程,实现一种并发
- 没有开新的线程,就是一个普通的函数调用,执行完t2.run(),就执行t1.run(),这里不是多线程
- 当使用start方法启动线程之后,进程内有多个线程并行的工作,这就是多线程
- 一个进程中至少有一个线程,并作为程序的入口,这个就是主线程
- 一个进程至少有一个主进程,其他线程成为工作线程
import threading # 加载线程库
import timedef worker():count =0# 自定义线程函数,启动线程后要调用的方法while True:if count > 5:breaktime.sleep(0.5)count+=1print("worker running")print(threading.current_thread().name,threading.get_ident())class MyThread(threading.Thread):def start(self):print("~~~~~~~~~~~~~~")super().start()def running(self) :print("***************")super().run()t1 = MyThread(name="worker1",target=worker)
t2 = MyThread(name="worker2",target=worker)t2.start() # 使用这种方法,t1和t2返回的进程id是不一样的,有两个进程
t1.start()
#t2.run() # 使用这种方法,t1和t2返回的进程id是一样的,有一个进程
#t1.run()
daemon线程和non-demone线程
- 主线程就是第一个启动的线程
- 如果进程A中,启动了一个进程B,A就是B的父线程;B就是A的子线程
- python中,构建县城的时候,可以设置daemon属性
- 主线程是non-daemon线程,即daemon=false,不写daemon属性,不代表线程是主线程
- 线程具有一个daemin属性,可以设置为True或者False,也可以不设置,不设置时取值为None
-
- 如果daemin属性为False,主线程执行完成之后,会等待工作线程结束
-
- 但是daemon属性为True,主线程执行完成之后,就立即结束了,不会等待工作线程
- 如果不设置daemin,就取当前的daemin来设置
- 从主线程创建的所有线程不设置daemin属性,则默认daemon=False,也就是non-daemon线程
- 再重复一遍:python程序在没有活着的non-daemin线程运行时退出,也就是剩下的只能是daemon县城,主线程才能退出,否则主线程只能等待
import threading # 加载线程库
import timedef fod():time.sleep(0.5)for i in range(10):print(i)
# 主线程是non-daemon线程
t= threading.Thread(target=fod,daemon=False)
# 当daemon为False时,下面的print语句打印完毕之后,即可结束
t.start()print("ending")***********************two********************
def fod(n):for i in range(n):print(i)time.sleep(0.5)
# 主线程是non-daemon线程
t= threading.Thread(target=fod,args=(3,),daemon=True)
t.start()t= threading.Thread(target=fod,args=(5,),daemon=False)
t.start()time.sleep(2)
print("ending")
daemon线程的应用场景
- 后台任务,例如发送心跳包,监控,这种场景最多
- 主线程工作才有用的线程,例如,主线程中维护公共资源,主线程已经清理了,准备退出,工作线程再使用这些资源就没有意义了,一起退出最合适
- 随时可以被终止的进程
- 如果主线程退出,需要其他工作线程一起退出,就是用daemon=True
- 如果需要等待工作线程,就需要daemon=False或者下面的join方法
线程的join
- 可以理解为等待,谁调用join,谁等待
join(timeout=value),是线程的标准方法之一- 一个线程A(下例子中的主线程)中调用另一个线程B(下面例子中的darmon线程)的join方法,调用者(A,主线程)将被阻塞,直到被调用线程(B,daemon线程)终止
- 一个线程可以被join多次
- timeout参数指定调用者等待多久,没有设置超时,就一直等到被调用线程结束
import threading # 加载线程库
import timedef fod(n):for i in range(n):print(i)time.sleep(0.5)
# 主线程是non-daemon线程
t= threading.Thread(target=fod,args=(3,),daemon=True)
t.start()
t.join()
#使用join方法之后,只有daemon线程执行完毕,主线程才能退出
# 不添加join的效果,只有0和ending,添加join之后,可以全部打印print("ending")
threading.local类
- 在Python中,使用全局对象global,虽然实现了全局作用域,但是线程之间会相互干扰,导致错误的结果
- python提供threading.local类,将这个类的实例化得到一个全局对象,但是不同的线程使用这个对象存储的数据,其他线程看不到
import threading # 加载线程库
import timeglobal_data = threading.local()
# 创建实例,实现线程之间的全局作用域,线程之间互不影响def worker():global_data.x = 0 # 给实例创建一个x的属性for i in range(100):time.sleep(0.0001)global_data.x +=1print(threading.current_thread(),global_data.x)for i in range(5):threading.Thread(target=worker).start()
***************************使用global实现,会相互影响******************
x = 0
def worker():global xfor i in range(100):time.sleep(0.0001)x +=1print(threading.current_thread(),x)for i in range(5):threading.Thread(target=worker).start()
线程的延迟执行:Timer
- 作用:定时器,或者延迟执行
threading.Timer继承自Thread,这个类用来定义多久执行一个函数threading.Timer(interval, function, args)),其中interval为等待时间,function为执行函数,args为方法传入的参数,元组形式- start方法执行之后,Timer对象会处于等待状态,等interval之后,开始执行function的函数
- 如果再执行函数之前的等待阶段,使用了cancel方法,就会跳过执行函数结束
- 如果线程中的函数开始执行,cancel就没有任何效果了
- 总结:Timer是Thread的子类,是线程类,具有线程的能力和特征(例如join方法,可调用)
- 他的实例水能够延时执行目标函数的线程,在真正执行目标函数之前,都可以cancel它
- 再start之前调用cancel函数,就是提前取消线程的启动
import threading
import timedef add(x,y):print(x+y)t = threading.Timer(interval=3, function=add, args=(2,4))
#等待3s后执行
t.start()time.sleep(0.5)
t.cancel()#cancel是timer的新增方法,非线程方法
# cancel放在start之前,线程提前取消
# 继承,线程终结,存在这句话且等待时间小于timer等待时间,add方法不执行
线程同步
- 线程同步:线程之间协同,通过某种技术,让一个线程访问这些数据时,其他线程不能访问这些数据,直到该线程完成对数据的操作
- 解决多个线程/进程争抢同一个共享资源的问题
- 线程同步存在临界区(Critical Section)、互斥量(Mutex)——这个可以理解为锁、信号量(Semaphore)和事件(Event)
Event 事件
- Event事件,是指线程之间通信中最简单的实现,使用一个内部的标记flag,通过flag的True或者False的变化来进行操作
- 其方法有:
-
set():设置标记为True
-
clear():设置标记为Flase
-
is_set():标记是否为True,询问当前状态
-
wait(timeout=None):设置等待标记为True的时长,None为无限等待,等到返回True,未等到超时就返回Flase
- 等待有wait,也有sleep,他们两者之间的关系是:
-
- wait优于sleep,在多线程的时候,wait会让出时间片,其他线程也可以被调度;但是sleep会一直占用时间片,不会被让出
# 老板让员工生产10个杯子之后,停止,说good job
from threading import Event,Thread
import logging
import timeFORMAT = "%(asctime)s-%(threadName)s-%(thread)d-%(message)s"
logging.basicConfig(format=FORMAT,level=logging.INFO)def boss(event:Event):logging.info("i am boss waittinng for you")event.wait() # 等待,标识变为True执行下面的代码print("标识1:", event.is_set()) # 判断当前线程的状态logging.info("Good Job")def Worker(event:Event,count = 10):logging.info("i am working for you")cups = []while 1:logging.info("make 1")time.sleep(0.5)cups.append(1)if len(cups) >=10:print("标识2:",event.is_set())# 判断当前线程的状态event.set()# 通知,更改标识breaklogging.info("I finished my job,cups={}".format(cups))event = Event()
w = Thread(target=Worker,args=(event,))
b = Thread(target=boss,args=(event,))
w.start()
b.start()
**************run_result************
2023-03-23 10:30:08,597-Thread-1-14700-i am working for you
2023-03-23 10:30:08,597-Thread-1-14700-make 1
2023-03-23 10:30:08,597-Thread-2-11076-i am boss waittinng for you
2023-03-23 10:30:09,120-Thread-1-14700-make 1
2023-03-23 10:30:09,630-Thread-1-14700-make 1
2023-03-23 10:30:10,143-Thread-1-14700-make 1
2023-03-23 10:30:10,648-Thread-1-14700-make 1
2023-03-23 10:30:11,160-Thread-1-14700-make 1
2023-03-23 10:30:11,666-Thread-1-14700-make 1
2023-03-23 10:30:12,172-Thread-1-14700-make 1
2023-03-23 10:30:12,679-Thread-1-14700-make 1
2023-03-23 10:30:13,192-Thread-1-14700-make 1
标识2: False
标识1: True
2023-03-23 10:30:13,706-Thread-1-14700-I finished my job,cups=[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
2023-03-23 10:30:13,706-Thread-2-11076-Good Job
- 使用同一个Event对象标记Flag
- 谁wait就是等到flag 变为True,或者等到超时返回False,不限制等待的个数
Lock ——锁
- 锁,凡是存在共享资源争抢的地方,都可以使用锁,从而保证只有一个使用者可以完全使用这个资源
- 原理:一个线程再使用共享资源的时候,要加锁,防止别的线程使用;使用完归还之后,解锁,让别的线程使用
lock.acquire(),默认阻塞-
- 阻塞可以设置超时时间
-
- 非阻塞时,timeout禁止设置
-
- 成功获取锁,返回True,否则就返回False
lock.release():释放锁,可以从任何线程调用释放-
- 已上锁的锁,会被重置为unlocked
-
- 未上锁的锁,调用时抛出RuntimeError的异常
#老板等10个员工生产100个杯子
import logging
import threadingFORMAT = "%(asctime)s-%(threadName)s-%(thread)d-%(message)s"
logging.basicConfig(format=FORMAT,level=logging.INFO)cups = [] # 公共资源,杯子的容器def worker(lock:threading.Lock,task=100): #task, 杯子的个数while True:lock.acquire()#线程开始拿锁,拿到锁就独占共享资源# 这个时候,别人要使用共享的资源,就只能等待count = len(cups)# 每次计算杯子的个数logging.info(str(count))if count >=task:lock.release()# 如果这里直接退出,其他的线程还在等待解锁# 会陷入死锁,因此需要在退出之前解锁# 如果没有这句话,run的时候就不会结束breakcups.append(1)# 没有进入循环,说明自核条件,添加元素lock.release()#解锁,释放共享资源logging.info("{} make 1".format(threading.current_thread().name))# 日志打印哪个线程添加的元素logging.info("cups:{}".format(len(cups)))lock = threading.Lock()
for i in range(10):threading.Thread(target=worker,args=(lock,100)).start()
加锁和解锁
- 一般来说,加锁之后还要一些代码实现,在释放之前还有可能抛出异常
- 但是一旦出现异常,锁是无法释放的,但当前线程可能因为这个异常被终止,这就产生了死锁
- 加锁和解锁的常用语句:
-
- try……finally,使用这种方式保证,出现异常时锁的释放
-
- with上下文管理器,锁对象支持上下文管理
- 例如:(以下代码逻辑上可能有问题,但是语法没有问题)
import threading
from threading import Thread,Lock
import timeclass Counter:def __init__(self):self._val = 0self._lock = Lock()def inc(self):# 方式一:异常处理try:self._lock.acquire()#加锁self._val+=1finally:self._lock.release()#解锁def dec(self):try:self._lock.acquire() # 加锁self._val -= 1finally:self._lock.release() # 解锁@propertydef value(self):#方式二:上下文管理器with self._lock:return self._valdef run_d(c:Counter,count=100):for _ in range(count):for i in range(-50,50):if i<0:c.dec()else:c.inc()c=Counter()
c1=10
c2=10000
for i in range(c1):threading.Thread(target=run_d,args=(c,c2)).start()# print(threading.current_thread().name)while 1:time.sleep(0.3)if threading.active_count() ==1:print(threading.enumerate())print(c.value)else:print(threading.enumerate())break
锁的应用场景
- 适用于访问和修改同一个共享资源的时候,即读写同一个资源的时候
- 如果全部都是读取同一个资源,就不需要锁,因为可以认为共享资源是不可变的,每一次读取都是同一个值,因此不需要加锁
- 使用锁的注意事项:
-
- 少用锁,必要时用锁,因为用了所,多线程访问被锁的资源时,就成了串行,要么排队执行,要么争抢执行,例如告诉公路上的收费通道只有一个,过这个路口必须排队,但是过了这个路口可以并行通行
- 加锁的时间越短越好,不需要应该立即释放
- 一定要避免死锁
非阻塞锁
- 这种形式的锁,在上锁之后不会阻止后面的进程再去拿这把锁
- 也就是是说线程A拿到锁之后,访问共享资源;线程B在线程A没有执行完释放锁的情况下,仍可以去访问共享资源
- 因此可以结合if语句使用,因为锁的返回值是布尔值
import logging
import threading
import timeFORMAT = "%(asctime)s-%(threadName)s-%(thread)d-%(message)s"
logging.basicConfig(format=FORMAT,level=logging.INFO)def worker(tasks):for task in tasks:time.sleep(0.2)if task.lock.acquire(False):# 获取到锁,则返回True,没有则是Falselogging.info("{} {} begin to start".format(threading.current_thread(),task.name))time.sleep(3)task.lock.release()# 选取适当的时机释放锁else:logging.info("{} {} begin to working".format(threading.current_thread(), task.name))class Task:def __init__(self,name):self.name = nameself.lock = threading.Lock()# 构造10个任务,构造10个对象,即10把锁
tasks = [Task("task={}".format(x)) for x in range(10)]# 启动5个线程,即启动5把锁,一个线程已经拿到锁,另外一个线程就拿不到了
# 就走worker中的else
for i in range(5):threading.Thread(target=worker,name="worker={}".format(i),args=(tasks,)).start()
可重入的锁Rlock
- 可重入锁,是线程相关的锁(threading.local 和线程相关,全局域)
- 线程S可以获得可重复锁,并可以多次成功获取,不会阻塞
- 但是,最后要在线程A中做和acquire次数相同的release
- 使用可重入的锁,不能跨线程
import threading
def sub(l):l.release() # 报错,不能跨线程lock = threading.RLock()
print(lock.acquire())
print("***************")
print(lock.acquire(blocking=False))
print(lock.acquire())
print(lock.acquire(timeout=3.55))
print(lock.acquire(blocking=False))
# print(lock.acquire(blocking=False,timeout=10)) # 会报异常
lock.release()
lock.release()
lock.release()
lock.release()
lock.release()
# lock.release() # 对应异常的那个,多了一次
print("*******************")
print(lock.acquire()) # 主线程中的锁,必须在主线程结束
threading.Thread(target=sub,args=(lock,)).start()# 报错,不能跨县城
Condition
- 构造方法Condition(lock=None),可以传入一个lock或者Rlock的对象(锁对象),默认Rlock
- acquire() 和release(),获得锁和取消锁
- wait(self,timeout=None):等待或者超时
- notify(n=1):唤醒之多执行数目个数的等待的线程,没有等待的线程就不会任何操作
- notify_all();唤醒所有等待的线程
- Condition用于生产者或者消费者模型,为了解决生产者和消费者速度不匹配的问题
- 使用condition,必须先acquire,用完了要release
- 因为内部使用了锁,弄人使用Rliock锁,最好的方式是使用上下文管理器
- 消费者wait等待通知
- 生产者生产信息,对消费者发通知,可以使用notify或者notify_all方法
import logging
import time
import randomFORMAT = "%(asctime)s-%(threadName)s-%(thread)d-%(message)s"
logging.basicConfig(format=FORMAT,level=logging.INFO)#暂时不来考虑线程安全,只是为了演示contition的用法class DispatcherOne:def __init__(self,x=0):self.data = xself.event = threading.Event()self.cond = threading.Condition()def produce(self):# 生产者for i in range(10):data = random.randint(1,100)with self.cond:self.data = data # 随机生成的数据放置早初始化公共区域self.cond.notify_all() # 条件通知消费者,生产好了,唤醒线程logging.info("produce:{} {}".format(threading.current_thread().name, self.data))self.event.wait(1)self.event.set()def custom(self):#消费者#消费者先等待(wait),等生产者生产数据后通知,等待就是线程阻塞while True:# 不断的接受生产者的数据,就需要用到循环with self.cond:#上下文管理器#self.cond是构造方法,本身就是锁,出上下文之后就关闭self.cond.wait(3)# 线程等待,阻止线程再次生产数据logging.info("custom:{} {}".format(threading.current_thread().name, self.data))#消费者消费数据
d = DispatcherOne(1)
p = threading.Thread(target=d.produce)
c = threading.Thread(target=d.custom,daemon=False)
c.start()
p.start()
Barrier ——栅栏/屏障
- 此功能为python3.2之后引入的功能
Barrier(parties, action=None, timeout=None),构建Barrier对象,置顶参与方的数目-
- tiimeout是weait方法未指定超时的默认值
Barrier.n_waiting,当前在屏障中等待的线程数Barrier.parties,各方数,就是需要多少个等待Barrier.wait(timeout=None),等待通过屏障-
- 返回0到线程数-1的整数,每个线程返回不同
-
- 如果wait方法设置了超时,并超时发送,屏障将处于broken状态(打破状态)
-
- 从运行下面的代码可以得到:所有的线程都在
barrier.wait前等待,直到达到参与者的数目,屏障才会打开;此时所有的线程停止等待,继续执行
- 从运行下面的代码可以得到:所有的线程都在
- 如果再有线程来,还需要达到参与方的数目才能放行,因此,线程数是参与方的倍数
import logging
import threadingFORMAT = "%(asctime)s-%(threadName)s-%(thread)d-%(message)s"
logging.basicConfig(format=FORMAT,level=logging.INFO)def worker(barrier:threading.Barrier):logging.info("wait for {} thread".format(barrier.n_waiting))# 屏障前输出当前有几个等待数try:barrier_id = barrier.wait()#返回分配的每个线程的id,每个线程都相同# 运行的时候可以看到,在3个线程没有全部等待之前,所有的线程都阻塞到这一块儿# 达到某种条件不等待之后(全部的参与者参与进来之后),下面的打印,是线程抢着进行logging.info("after barrier {}".format(barrier_id))except threading.BrokenBarrierError:# 如果打破屏障,就打印下面的信息logging.info("Broken Barrier")barrier = threading.Barrier(3)#3为三个参与方for x in range(5):# 这里起大于参与者的线程,如果起的线程个数非参与方的倍数,线程会一直等待,不会结束# 例如,参与方3,起了5个线程,日志打印一轮后,会在 barrier.wait()的地方阻塞两个线程threading.Event().wait(timeout=2)threading.Thread(target=worker,name="worker-{}".format(x),args=(barrier,)).start()
Barrier.broken,如果屏障处于打破状态,返回TrueBarrier.abort(),将屏障处于broken的状态-
- 等待中的线程或者调用等待方法的线程中都会抛出BrokenBarrierError的异常
-
- 直到reset方法来回复屏障
Barrier.reset(),恢复屏障,重新开始拦截- Barrier中的wait方法如果超时,屏障将处于broken状态,就像执行了abort方法,直到再次reset恢复屏障
import logging
import threadingFORMAT = "%(asctime)s-%(threadName)s-%(thread)d-%(message)s"
logging.basicConfig(format=FORMAT,level=logging.INFO)def worker(barrier:threading.Barrier):logging.info("wait for {} thread".format(barrier.n_waiting))try:barrier_id = barrier.wait()#barrier_id = barrier.wait(timeout=0.5)#barrier的wait方法超时logging.info("after barrier {}".format(barrier_id))except threading.BrokenBarrierError:# 如果打破屏障,就打印下面的信息logging.info("Broken Barrier")barrier = threading.Barrier(3)#3为三个参与方for x in range(1,8):threading.Event().wait(timeout=2)threading.Thread(target=worker,name="worker-{}".format(x),args=(barrier,)).start()if x==2:barrier.abort()# 手动打破异常,会返回异常处理中的Broken Barrierlogging.info("当前线程状态:{}" .format(barrier.broken))# 打印屏障状态elif x==4:barrier.reset()# 屏障恢复logging.info("当前线程状态:{}".format(barrier.broken))
Barrier的应用
- 并发初始化
- 所有的线程都必须初始化之后才能继续工作,例如运行前加载数据,检查,如果这些工作没有完成,活着开始运行,就不能正常工作
- 或者:一个功能需要10个线程完成10个步骤(1个线程1个步骤)才嫩个继续向下进行,就需要先完成的等待其他线程完成步骤
Semaphone信号量
- 和lock很像,信号量对象内部维护一个倒计数器
- 每一次acquire都会-1,当acquire方法发现技术为0时,就阻塞请求线程,直到其他的线程release后,计数器大于0才会恢复阻塞的线程
Semaphore(value=1),构造方法,value小鱼0,就会抛出ValueError的异常Semaphore(value=1).acquire(),获取信号量,计数器减1,获取成功则返回TrueSemaphore(value=1).release(),释放信号量,计数器加1- 计数器永远不会低于0,因为acquire的时候,发现等于0就会阻塞
- 使用Semaphone,没有acquire直接release超过了约束值,不会报错,为了约束这种情况,需要使用构造方法:
BoundedSemaphore -
- BoundedSemaphore,有界的信号量,不允许使用release超出初始值的范围,否则就会抛出ValueError的异常
# 可以跨线程
import logging
import threadingFORMAT = "%(asctime)s-%(threadName)s-%(thread)d-%(message)s"
logging.basicConfig(format=FORMAT,level=logging.INFO)
def worker(s:threading.Semaphore):logging.info("in sub thread")logging.info(s.release())logging.info("sub thread over")#信号量
s= threading.Semaphore(3)
logging.info(s.acquire())
logging.info(s.acquire())
logging.info(s.acquire())
threading.Thread(target=worker,args=(s,)).start()# 例子二
import logging
import threadingFORMAT = "%(asctime)s-%(threadName)s-%(thread)d-%(message)s"
logging.basicConfig(format=FORMAT,level=logging.INFO)
def worker(s:threading.Semaphore):logging.info("in sub thread")logging.info(s.acquire())logging.info("sub thread over")#信号量
s= threading.Semaphore(3)
logging.info(s.acquire())
logging.info(s.acquire())
logging.info(s.acquire())
threading.Thread(target=worker,args=(s,)).start()print("…………………………")
logging.info(s.acquire(False))
logging.info(s.acquire(timeout=3))s.release()#释放信号量
print("end")
相关文章:

python学习——多线程
python学习——多线程概念python中线程的开发线程的启动线程的退出和传参threading的属性和方法threading实例的属性和方法多线程daemon线程和non-demone线程daemon线程的应用场景线程的jointhreading.local类线程的延迟执行:Timer线程同步Event 事件Lock ——锁加锁…...
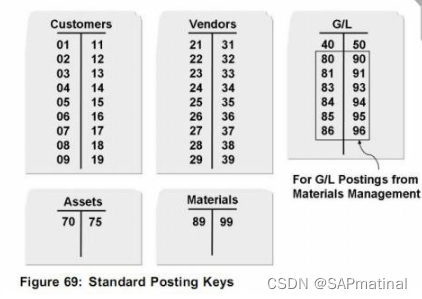
SAP 系统中过账码or记账码
SAP中过账码和记账码是指同一个事物。 在实际业务中,记账码就是只有“借”和“贷”, 而SAP中Posting Code肩负着更多的任务: 1)界定科目类型, 2)借贷方向, 3)凭证输入时画面上的字…...

【FreeRTOS(一)】FreeRTOS新手入门——初识FreeRTOS
初识FreeRTOS一、实时操作系统概述1、概念2、RTOS的必要性3、RTOS与裸机的区别4、FreeRTOS的特点二、FreeRTOS的架构三、FreeRTOS的代码架构一、实时操作系统概述 1、概念 RTOS:根据各个任务的要求,进行资源(包括存储器、外设等)…...

Python中 __init__的通俗解释是什么?
__init__是Python中的一个特殊方法,用于在创建对象时初始化对象的属性。通俗来讲,它就像是一个构造函数,当我们创建一个类的实例时,__init__方法会被自动调用,用于初始化对象的属性。 举个例子,如果我们定义…...

网友真实面试总结出的自动化测试面试题库
目录 常规问题 手工测试部 自动化测试 自动化测试面试题2:selenium篇 常规问题 1、如何快速深入的了解移动互联网领域的应用 (答案:看http协议 restful api知识 json加1分) 2、对xx应用自己会花多久可以在业务上从入门到精通&…...

2023 年最佳 C++ IDE
文章目录前言1. Visual Studio2. Code::Blocks3. CLion4. Eclipse CDT(C/C 开发工具)5. CodeLite6. Apache NetBeans7. Qt Creator8. Dev C9. C Builder10. Xcode11. GNAT Programming Studio12. Kite总结前言 要跟踪极佳 IDE(集成开发环境&…...

在Ubuntu上使用VSCode编译MySQL Connector/C连接库
首先下载并解压MySQL Connector/C源码,然后执行以下步骤: 1、安装MySQL Connector/C依赖:在终端中输入以下命令来安装MySQL Connector/C的依赖项: sudo apt-get install build-essential cmake 2、下载并解压MySQL Connector/C源…...
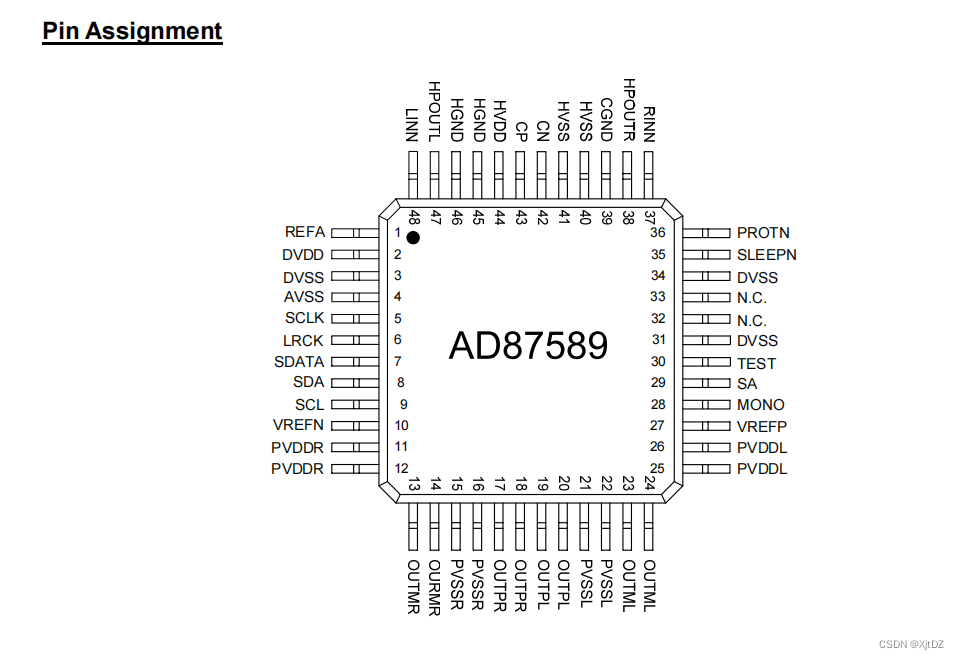
单声道数字音频放大器AD87589
AD87589是一种集成音频系统解决方案,嵌入数字音频处理、功率级放大器和立体声2Vrms线路驱动器。 AD87589具有可编程转换速率控制的输出缓冲器,可直接驱动一个(单声道)或两个(立体声)扬声器。此外࿰…...

网络的UDP协议和TCP协议
协议:数据在网络中的传输规则,常见的协议有 UDP协议和TCP协议 协议:计算机网络中,连接和通信的规则被称为网络通信协议 UDP协议:用户数据报协议,是面向无连接通信协议,速度快,有大小…...

【JaveEE】多线程之阻塞队列(BlockingQueue)
目录 1.了解阻塞队列 2.生产者消费者模型又是什么? 2.1生产者消费者模型的优点 2.1.1降低服务器与服务器之间耦合度 2.1.2“削峰填谷”平衡消费者和生产的处理能力 3.标准库中的阻塞队列(BlockingQueue) 3.1基于标准库(Bloc…...
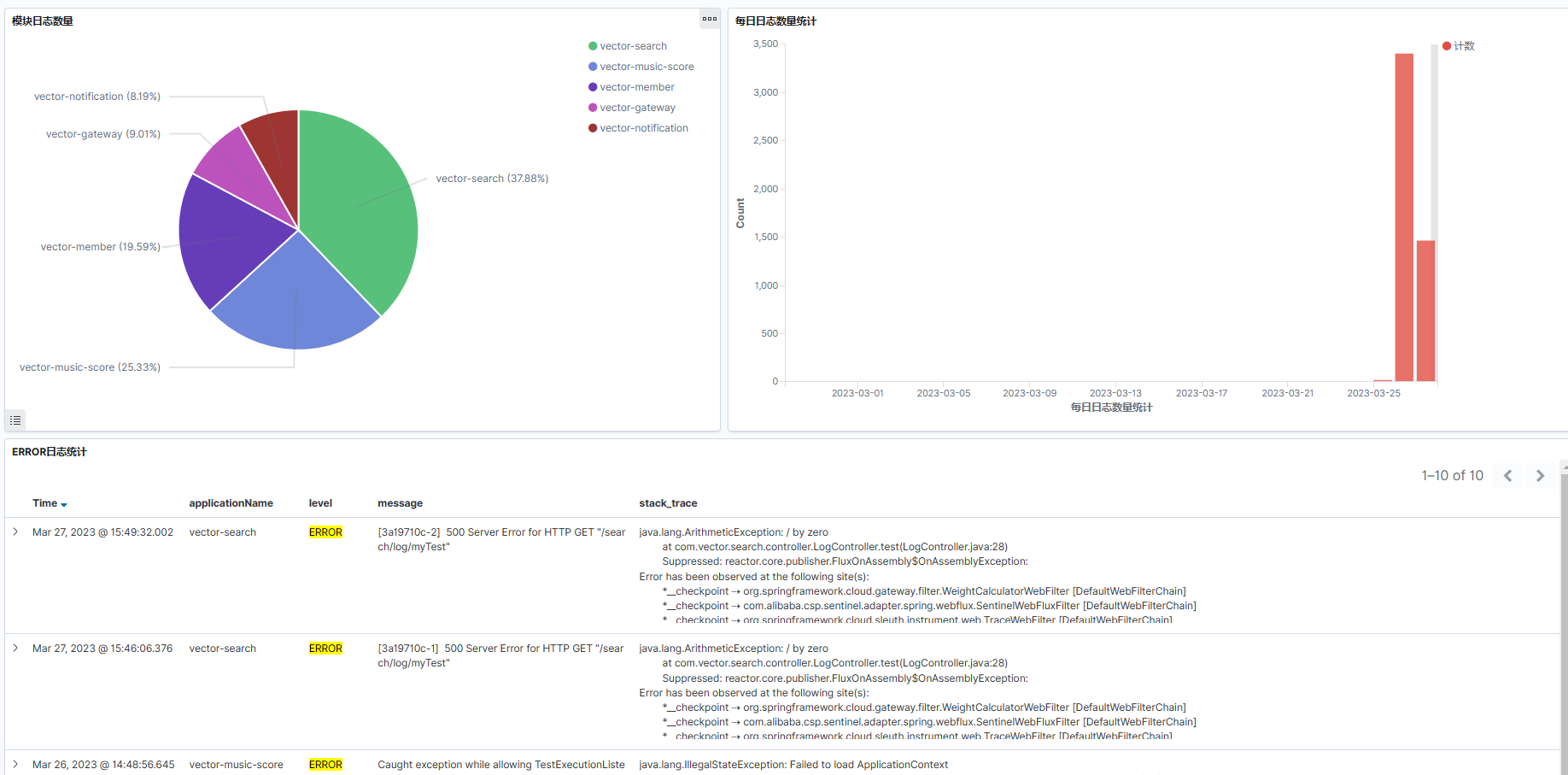
分布式ELK日志监控系统环境搭建
文章目录1.1为什么需要监控项目日志1.2ELK日志监控系统介绍1.3ELK的工作流程1.4ELK环境搭建1.4.1Elasticsearch的安装1.4.2Kibana的安装1.4.3Logstash的安装1.4.4数据源配置1.4.5日志监测测试1.4.6日志数据可视化展示1.1为什么需要监控项目日志 项目日志是记录项目运行过程中产…...
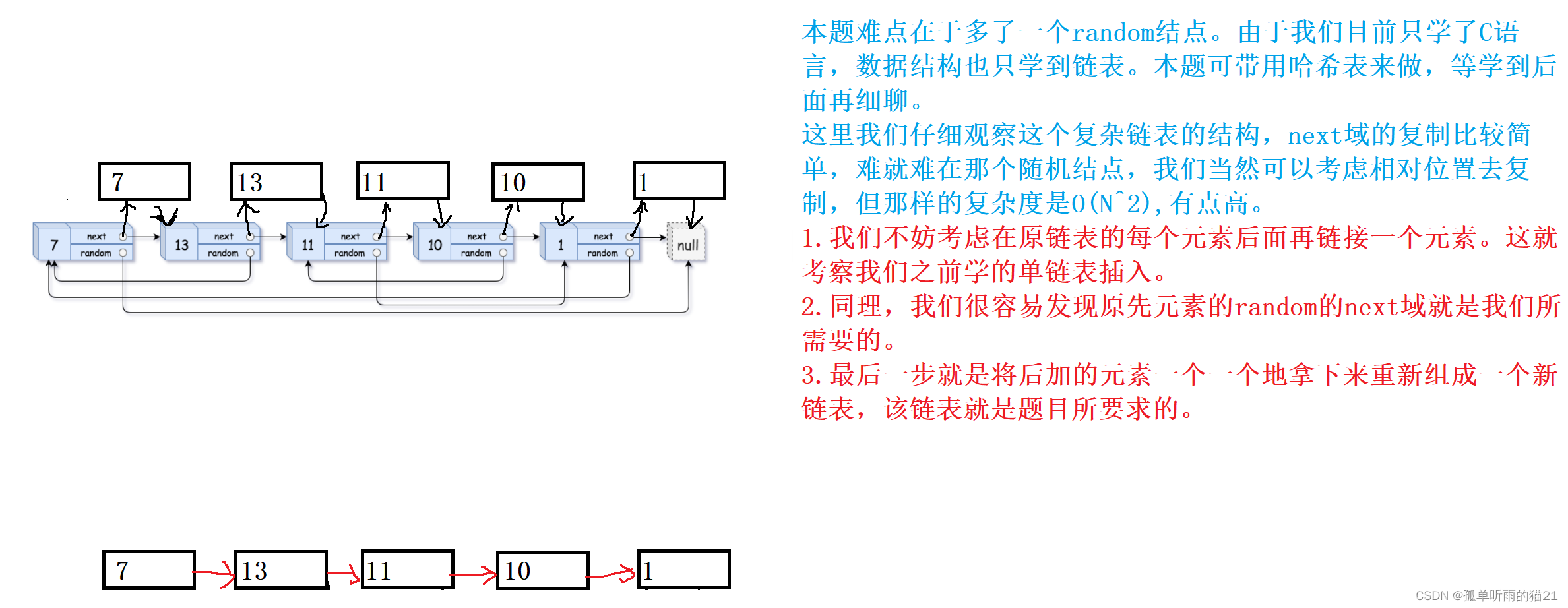
【数据结构刷题集】链表经典习题
😽PREFACE🎁欢迎各位→点赞👍 收藏⭐ 评论📝📢系列专栏:数据结构刷题集🔊本专栏涉及到题目是数据结构专栏的补充与应用,只更新相关题目,旨在帮助提高代码熟练度&#x…...

JavaSE(3.27) 异常
学习不要眼高手低,学习是一点点积累的。即使你现在很菜,坚持学一个学期不会差的!只要花时间学习,每天都是进步的,这些进步可能你现在看不到,但是不要小瞧了积累效应,30天,60天&#…...

【看门狗】我说的是定时器不是狗啊
单片机在运行中死机了,你或许只能按2下电源键(重启)或1下复位键。 这里简单说一下重启和复位: 从RESET引脚复位,只有MCU复位。而外设看情况,有的可能会有MCU同步复位或者重新初始化。也有可能一些保持复位…...
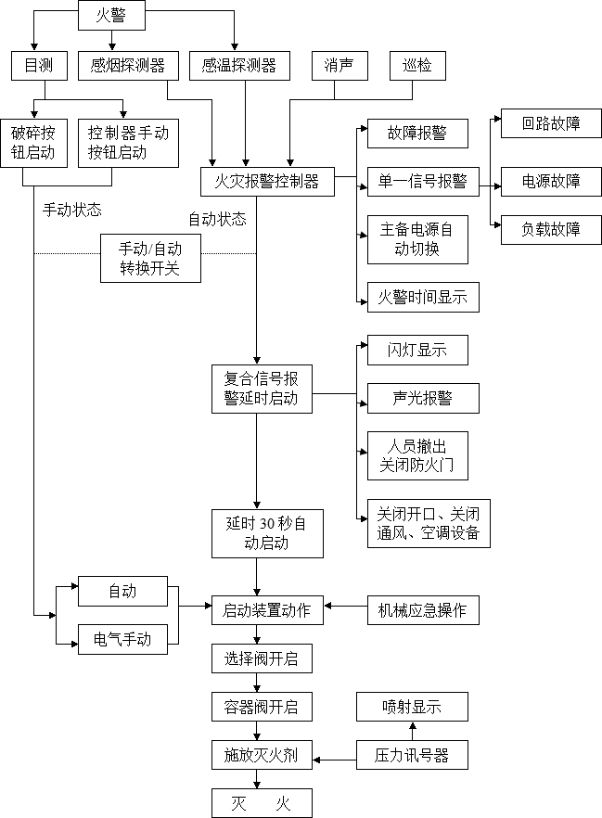
24万字智慧城市顶层设计及智慧应用解决方案
本资料来源公开网络,仅供个人学习,请勿商用,如有侵权请联系删除。部分资料内容: 4.8 机房消防系统 4.8.1消防系统概况 根据本工程机房消防系统的特殊要求,整个消防系统由火灾报警系统、消防联动系统和气体灭火系统三部…...

跨境电商卖家工具——跨境卫士内容介绍
一、简介 跨境卫士是一款集合多种跨境电商工具的综合软件,由知名跨境电商服务商跨境通开发。跨境卫士可以帮助卖家完成海外物流管理、订单处理、报关报税、市场营销等多项任务,同时还提供数据分析、客户服务、运营管理等一系列支持功能,方便卖…...

Redis 常用基本命令
关于 redis 的常用基本命令 目录 关于 redis 的常用基本命令 1. 关于 key 的操作 2. HyperLogLog 求近似基数 3. 排序相关命令 4. Limit 限制查询 1. 关于 key 的操作 判断某个 key 是否存在 # 格式: exists key exists name# 存在name 返回1 # 不存在name 返回0 查找或…...
【Leetcode】队列的性质与应用
文章目录225. 用队列实现栈示例:提示:分析:题解:622. 设计循环队列示例:提示:分析:题解:225. 用队列实现栈 请你仅使用两个队列实现一个后入先出(LIFO)的栈&…...
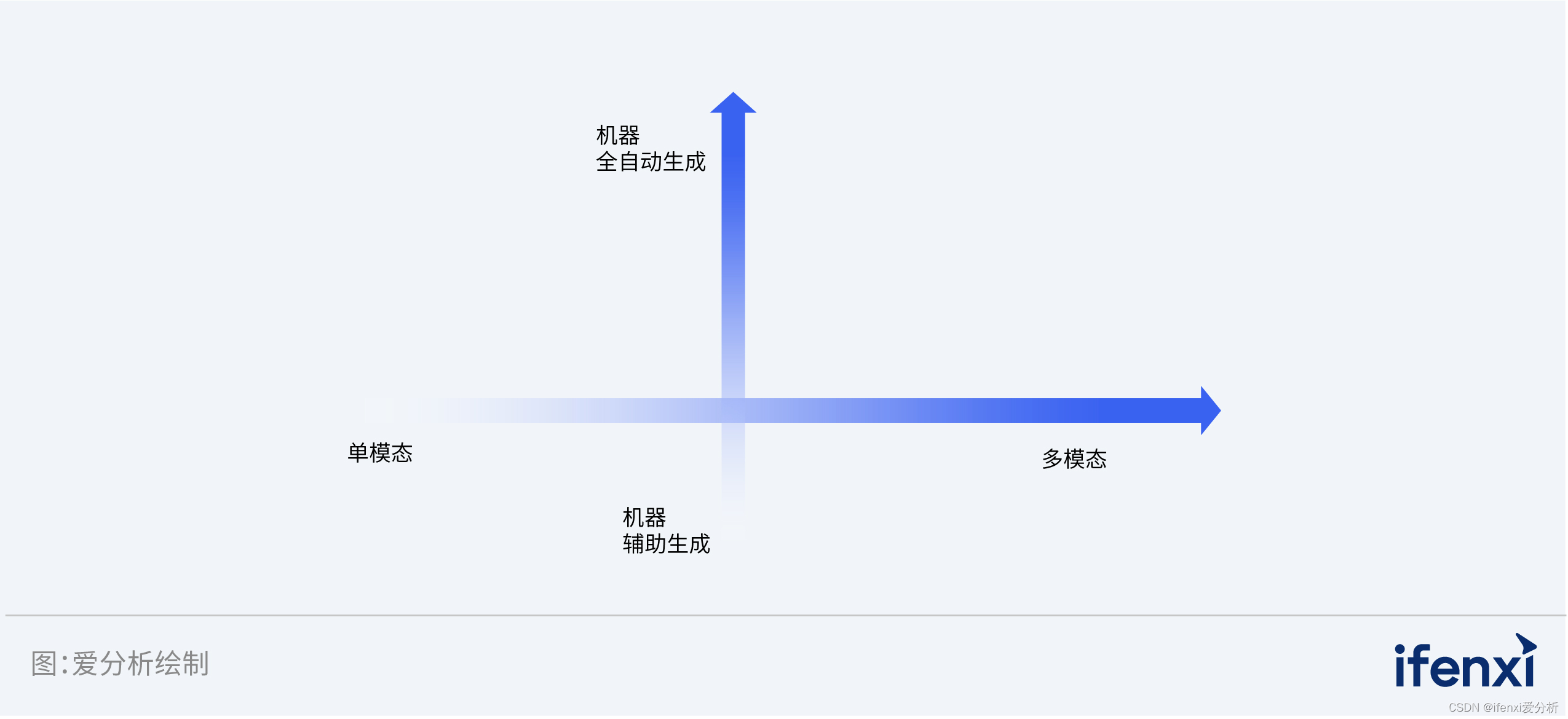
开启新航路,拓尔思发力AIGC市场 | 爱分析调研
2022年,随着AI聊天机器人GhatGPT在世界范围内持续火爆,极具创意、表现力、个性化且能快速迭代的AIGC技术成功破圈,成为全民讨论热点。 AIGC是指在确定主题下,由算法模型自动生成内容,包括单模态内容如文本、图像、音频…...

RK3568平台开发系列讲解(调试篇)Linux 内核的日志打印
🚀返回专栏总目录 文章目录 一、dmseg 命令二、查看 kmsg 文件三、调整内核打印等级沉淀、分享、成长,让自己和他人都能有所收获!😄 📢本篇将 Linux 内核的日志打印进行梳理。 一、dmseg 命令 在终端使用 dmseg 命令可以获取内核打印信息,该命令的具体使用方法如下所…...

测试微信模版消息推送
进入“开发接口管理”--“公众平台测试账号”,无需申请公众账号、可在测试账号中体验并测试微信公众平台所有高级接口。 获取access_token: 自定义模版消息: 关注测试号:扫二维码关注测试号。 发送模版消息: import requests da…...

利用ngx_stream_return_module构建简易 TCP/UDP 响应网关
一、模块概述 ngx_stream_return_module 提供了一个极简的指令: return <value>;在收到客户端连接后,立即将 <value> 写回并关闭连接。<value> 支持内嵌文本和内置变量(如 $time_iso8601、$remote_addr 等)&a…...

LeetCode - 394. 字符串解码
题目 394. 字符串解码 - 力扣(LeetCode) 思路 使用两个栈:一个存储重复次数,一个存储字符串 遍历输入字符串: 数字处理:遇到数字时,累积计算重复次数左括号处理:保存当前状态&a…...

转转集团旗下首家二手多品类循环仓店“超级转转”开业
6月9日,国内领先的循环经济企业转转集团旗下首家二手多品类循环仓店“超级转转”正式开业。 转转集团创始人兼CEO黄炜、转转循环时尚发起人朱珠、转转集团COO兼红布林CEO胡伟琨、王府井集团副总裁祝捷等出席了开业剪彩仪式。 据「TMT星球」了解,“超级…...

HarmonyOS运动开发:如何用mpchart绘制运动配速图表
##鸿蒙核心技术##运动开发##Sensor Service Kit(传感器服务)# 前言 在运动类应用中,运动数据的可视化是提升用户体验的重要环节。通过直观的图表展示运动过程中的关键数据,如配速、距离、卡路里消耗等,用户可以更清晰…...

uniapp手机号一键登录保姆级教程(包含前端和后端)
目录 前置条件创建uniapp项目并关联uniClound云空间开启一键登录模块并开通一键登录服务编写云函数并上传部署获取手机号流程(第一种) 前端直接调用云函数获取手机号(第三种)后台调用云函数获取手机号 错误码常见问题 前置条件 手机安装有sim卡手机开启…...

比较数据迁移后MySQL数据库和OceanBase数据仓库中的表
设计一个MySQL数据库和OceanBase数据仓库的表数据比较的详细程序流程,两张表是相同的结构,都有整型主键id字段,需要每次从数据库分批取得2000条数据,用于比较,比较操作的同时可以再取2000条数据,等上一次比较完成之后,开始比较,直到比较完所有的数据。比较操作需要比较…...

Rust 开发环境搭建
环境搭建 1、开发工具RustRover 或者vs code 2、Cygwin64 安装 https://cygwin.com/install.html 在工具终端执行: rustup toolchain install stable-x86_64-pc-windows-gnu rustup default stable-x86_64-pc-windows-gnu 2、Hello World fn main() { println…...

Python网页自动化Selenium中文文档
1. 安装 1.1. 安装 Selenium Python bindings 提供了一个简单的API,让你使用Selenium WebDriver来编写功能/校验测试。 通过Selenium Python的API,你可以非常直观的使用Selenium WebDriver的所有功能。 Selenium Python bindings 使用非常简洁方便的A…...

comfyui 工作流中 图生视频 如何增加视频的长度到5秒
comfyUI 工作流怎么可以生成更长的视频。除了硬件显存要求之外还有别的方法吗? 在ComfyUI中实现图生视频并延长到5秒,需要结合多个扩展和技巧。以下是完整解决方案: 核心工作流配置(24fps下5秒120帧) #mermaid-svg-yP…...