pytorch项目实战之实时人脸属性检测系统
简介
本项目采用CelebA人脸属性数据集训练人脸属性分类模型,使用mediapipe进行人脸检测,使用onnxruntime进行模型的推理,最终在intel的奔腾cpu上实现30-100帧完整的实时人脸属性识别系统。
ps:本来是打算写成付费专栏的,毕竟这是个只要稍微修改就可以商业化的系统,不是那些玩具例子,但考虑到阅读量马上破十万了,就作为纪念作发出来吧。
python包环境
训练环境:
python 3.9.12
torch 1.12.0+cu116
torchvision 0.13.0+cu116
导出模型相关:
onnx 1.12.0
onnxruntime 1.14.0
部署模型环境:
onnxruntime 1.14.0
cv2(opencv-python) 4.7.0
mediapipe 0.9.0.1
python3.10.6
注:版本没有特定要求,写出来只是方便查bug,一般拥有以上的包即可完成本项目,没有包请自行pip安装。
数据集准备
手动下载CelebA数据集

输入截图上面这个网址(不直接放网址是因为外链会被识别为低质量文章的奇葩规定),然后点击图上baidu drive,输入提取码后:
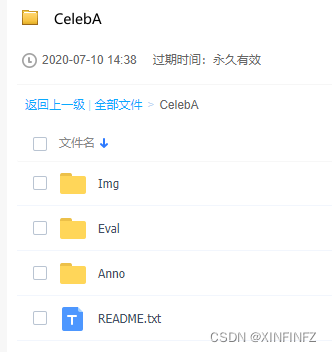
把以上文件夹下的每一个东西都下载下来放到一起,比如我这边下载完后构造如下图所示,一个都不能少和多:
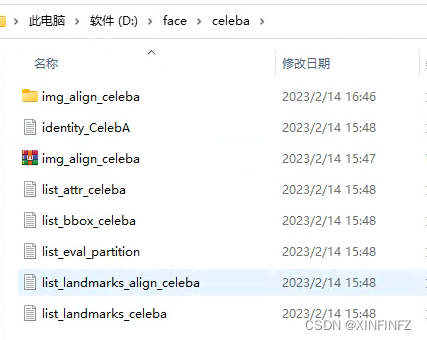
img_align_celeba文件夹是压缩包解压完后的,下面直接就是人脸的图片,没有次级目录:
装载数据集
首先使用torchvision直接加载数据集,划分训练集,测试集。这里download设为False表示你已经手动下载好了,不需要自动下载(速度很慢)。此外root路径为数据集的根路径,我这里所有东西是放在D:/face/celeba下,那么根路径就是写D:/face。
from torchvision import datasets
import torchvision.transforms as transforms
train_dataset = datasets.CelebA(root="D:/face",split='train',transform = transforms.Compose([transforms.CenterCrop(128),transforms.ToTensor(),transforms.Normalize(mean=[0.5, 0.5, 0.5],std=[0.5, 0.5, 0.5])]),download=False)
test_dataset = datasets.CelebA(root="D:/face",split='test',transform = transforms.Compose([transforms.CenterCrop(128),transforms.ToTensor(),transforms.Normalize(mean=[0.5, 0.5, 0.5],std=[0.5, 0.5, 0.5])]),download=False)
这里对数据集进行了三个预处理,因为涉及到后面推理环节摆脱torch进行相同的处理所以需要详细解释:
| 语句 | 意义 |
|---|---|
| transforms.CenterCrop(128) | 中心裁剪128x128图片 |
| transforms.ToTensor() | 把0-255的像素值除以255转为0-1 |
| transforms.Normalize(mean=[0.5, 0.5, 0.5],std=[0.5, 0.5, 0.5])]) | 对三个通道减去0.5平均值并除以0.5标准差 |
然后我们使用torch的dataloader类来把数据集正式装入可供读取:
import torch
train_dataloader = torch.utils.data.DataLoader(dataset=train_dataset, shuffle=True, batch_size=128,num_workers=4)
test_dataloader = torch.utils.data.DataLoader(dataset=test_dataset, shuffle=False, batch_size=128,num_workers=4)
batch_size我这里调了128,num_workers调了4,这两个指标是影响训练速度的,如果电脑配置不行请适当调小,配置很行请调大加速训练,数据量本身还是很大的,一次epoch大概2分钟。
定义模型类
模型采用2017年的slimnet架构,是一个非常轻量的网络,对slimnet感兴趣的请自行搜索相关论文,这里直接放代码了:
import torch
import torch.nn as nn
import torch.nn.functional as Fclass ConvBNReLU(nn.Sequential):def __init__(self, in_planes, out_planes, kernel_size=3, stride=1, groups=1):padding = (kernel_size - 1) // 2super(ConvBNReLU, self).__init__(nn.Conv2d(in_planes, out_planes, kernel_size, stride, padding, groups=groups, bias=False),nn.BatchNorm2d(out_planes),nn.ReLU(inplace=True))class DWSeparableConv(nn.Module):def __init__(self, inp, oup):super().__init__()self.dwc = ConvBNReLU(inp, inp, kernel_size=3, groups=inp)self.pwc = ConvBNReLU(inp, oup, kernel_size=1)def forward(self, x):x = self.dwc(x)x = self.pwc(x)return xclass SSEBlock(nn.Module):def __init__(self, inp, oup):super().__init__()out_channel = oup * 4self.pwc1 = ConvBNReLU(inp, oup, kernel_size=1)self.pwc2 = ConvBNReLU(oup, out_channel, kernel_size=1)self.dwc = DWSeparableConv(oup, out_channel)def forward(self, x):x = self.pwc1(x)out1 = self.pwc2(x)out2 = self.dwc(x)return torch.cat((out1, out2), 1)class SlimModule(nn.Module):def __init__(self, inp, oup):super().__init__()hidden_dim = oup * 4out_channel = oup * 3self.sse1 = SSEBlock(inp, oup)self.sse2 = SSEBlock(hidden_dim * 2, oup)self.dwc = DWSeparableConv(hidden_dim * 2, out_channel)self.conv = ConvBNReLU(inp, hidden_dim * 2, kernel_size=1)def forward(self, x):out = self.sse1(x)out += self.conv(x)out = self.sse2(out)out = self.dwc(out)return outclass SlimNet(nn.Module):def __init__(self, num_classes):super().__init__()self.conv = ConvBNReLU(3, 96, kernel_size=7, stride=2)self.max_pool0 = nn.MaxPool2d(kernel_size=3, stride=2)self.module1 = SlimModule(96, 16)self.module2 = SlimModule(48, 32)self.module3 = SlimModule(96, 48)self.module4 = SlimModule(144, 64)self.max_pool1 = nn.MaxPool2d(kernel_size=3, stride=2)self.max_pool2 = nn.MaxPool2d(kernel_size=3, stride=2)self.max_pool3 = nn.MaxPool2d(kernel_size=3, stride=2)self.max_pool4 = nn.MaxPool2d(kernel_size=3, stride=2)self.gap = nn.AdaptiveAvgPool2d((1, 1))self.fc = nn.Linear(192, num_classes)def forward(self, x):x = self.max_pool0(self.conv(x))x = self.max_pool1(self.module1(x))x = self.max_pool2(self.module2(x))x = self.max_pool3(self.module3(x))x = self.max_pool4(self.module4(x))x = self.gap(x)x = torch.flatten(x, 1)x = self.fc(x)return x
device = torch.device('cuda')
model = SlimNet(num_classes=40).to(device=device)
device这里我用了cuda训练,如果你没有英伟达显卡请写cpu,num_classes=40表示最后输出有40个人脸属性特征,以下是我翻译过后的特征,方便理解:

可以看到我们最后是个多分类任务,但这里网络输出的不是0,1的分类,也不是0-1的概率值,需要在预测时先用sigmoid函数转换到0-1的可能性,再以0.5分类。
训练网络
中间的训练过程就不细讲了,都是pytorch的八股文,需要注意的是选取损失函数时要明白它的数据类型,这里target是整数型,需要转为double型才能和score计算loss。本次训练手动设定了一个best_acc表示最好的准确度,一旦在训练中对测试集评估时发现准确度比它更好,就会自动保存当前模型。
loss_criterion = nn.BCEWithLogitsLoss() #定义损失函数
optimizer = torch.optim.Adam(model.parameters(), lr = 0.001) #定义优化器
best_acc = 0.90325 #最好的在测试集上的准确度,可手动修改
seed = 18203861252700 #固定起始种子
for epoch in range(50): #训练五十轮torch.manual_seed(seed)torch.cuda.manual_seed(seed)torch.backends.cudnn.benchmark = Falsetorch.backends.cudnn.deterministic = True#以上这些都是企图固定种子,但经过测试只能固定起始种子,可删掉total_train = 0 #总共的训练图片数量,用来计算准确率correct_train = 0 #模型分类对的训练图片running_loss = 0 #训练集上的lossrunning_test_loss = 0 #测试集上的losstotal_test = 0 #测试的图片总数correct_test = 0 #分类对的测试图片数model.train() #训练模式for data, target in train_dataloader:data = data.to(device=device)target = target.type(torch.DoubleTensor).to(device=device)score = model(data)loss = loss_criterion(score, target)running_loss += loss.item()optimizer.zero_grad()loss.backward()optimizer.step()sigmoid_logits = torch.sigmoid(score)predictions = sigmoid_logits > 0.5 #使结果变为true,false的数组total_train += target.size(0) * target.size(1)correct_train += (target.type(predictions.type()) == predictions).sum().item()model.eval() #测试模式with torch.no_grad():for batch_idx, (images,labels) in enumerate(test_dataloader):images, labels = images.to(device), labels.type(torch.DoubleTensor).to(device)logits = model.forward(images)test_loss = loss_criterion(logits, labels)running_test_loss += test_loss.item()sigmoid_logits = torch.sigmoid(logits)predictions = sigmoid_logits > 0.5total_test += labels.size(0) * labels.size(1)correct_test += (labels.int() == predictions.int()).sum().item()test_acc = correct_test/total_testif test_acc > best_acc:best_acc = test_acctorch.save(model,f"model_{test_acc*100}.pt")print(f"For epoch : {epoch} training loss: {running_loss/len(train_dataloader)}")print(f'train accruacy is {correct_train*100/total_train}%')print(f"For epoch : {epoch} test loss: {running_test_loss/len(test_dataloader)}")print(f'test accruacy is {test_acc*100}%')
训练结束后可以在目录下找到以下文件,就是我们训练过程中发现的好模型,用来后续导出:

模型导出onnx
这里最好接着上面在同一个notebook里写,如果另外保存的话,需要把上面定义网络的部分复制粘贴进去,不然会找不到网络的定义。
torch_model = torch.load("model_90.56845506462278.pt", map_location='cpu')
torch_model.eval()
x = torch.randn(1, 3, 128, 128, requires_grad=True) #随机128x128输入
torch_out = torch_model(x)
print(torch_out)
# 导出模型
torch.onnx.export(torch_model, # 需要导出的模型x, # 模型输入"cpu.onnx", # 保存模型位置export_params=True, # 保存训练参数opset_version=10, # onnx的opset版本do_constant_folding=True, # 是否进行常量折叠优化,这里开关都一样input_names = ['input'], # 输入名字output_names = ['output'], # 输出名字)
ort_session = onnxruntime.InferenceSession("cpu.onnx",providers=['CPUExecutionProvider'])
#尝试进行推理看是否报错
def to_numpy(tensor):return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy()ort_inputs = {ort_session.get_inputs()[0].name: to_numpy(x)}
ort_outs = ort_session.run(None, ort_inputs)
print(ort_outs[0])
# 比较onnx模型推理的结果和torch推理的结果误差是否在可容忍范围内
np.testing.assert_allclose(to_numpy(torch_out), ort_outs[0], rtol=1e-03, atol=1e-05)print("Exported model has been tested with ONNXRuntime, and the result looks good!")
一切没问题的话会在目录下找到cpu.onnx文件:

图片最小推理示例
我们直接把数据集中的第一张图片复制过来并重名为test_face.jpg,

进行推理:
from PIL import Image
import torchvision.transforms as transforms
import onnxruntime
import torch
import numpy as np
img = Image.open("test_face.jpg")
comp = transforms.Compose([transforms.CenterCrop(128),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),]) #torch的预处理
img = comp(img)
img.unsqueeze_(0)
def to_numpy(tensor):return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy()
x = to_numpy(img)
ort_session = onnxruntime.InferenceSession("cpu.onnx")
ort_inputs = {ort_session.get_inputs()[0].name: x}
ort_outs = ort_session.run(None, ort_inputs)
def sigmoid_array(x): #使用sigmoid转换概率值return 1 / (1 + np.exp(-x))
result = sigmoid_array(ort_outs[0]) > 0.5
list_attr_cn = np.array(["早上刚刮下午长出来的一点胡子","拱形眉毛","有吸引力的","眼袋","秃头","刘海","大嘴唇"
,"大鼻子","黑发","金发","模糊的","棕发","浓眉","圆胖","双下巴","眼镜","山羊胡子","灰白发","浓妆","高高的颧骨",
"男性","嘴微微张开","胡子","眯眯眼","没有胡子","鹅蛋脸","苍白皮肤","尖鼻子","后退的发际线","红润脸颊",
"鬓角","微笑","直发","卷发","耳环","帽子","口红","项链","领带","年轻"])
print(list_attr_cn[result[0]])
结果如下:
[‘拱形眉毛’ ‘有吸引力的’ ‘棕发’ ‘浓妆’ ‘高高的颧骨’ ‘嘴微微张开’ ‘没有胡子’ ‘尖鼻子’ ‘微笑’ ‘口红’ ‘年轻’]
有了玩具例子,只要再加上亿点点细节,就可以完成整个系统了。
视频实时人脸检测
直接放代码,如果要细细解释得讲很多,不如直接代码注释看起来方便,总之就是用opencv来读取视频并画文字,使用Mediapipe来进行快速人脸识别。
import onnxruntime
import time
import numpy as np
import cv2
import mediapipe as mp
mp_face_detection = mp.solutions.face_detection
mp_drawing = mp.solutions.drawing_utils
cap = cv2.VideoCapture("test_face3.mp4") #视频输入,如果需要摄像头,请改成数字0,并修改下面的break为continue
ort_session = onnxruntime.InferenceSession("cpu.onnx")
list_attr_en = np.array(["5_o_Clock_Shadow","Arched_Eyebrows","Attractive","Bags_Under_Eyes","Bald",
"Bangs","Big_Lips","Big_Nose","Black_Hair","Blond_Hair","Blurry","Brown_Hair",
"Bushy_Eyebrows","Chubby","Double_Chin","Eyeglasses","Goatee","Gray_Hair",
"Heavy_Makeup","High_Cheekbones","Male","Mouth_Slightly_Open","Mustache","Narrow_Eyes",
"No_Beard","Oval_Face","Pale_Skin","Pointy_Nose","Receding_Hairline","Rosy_Cheeks",
"Sideburns","Smiling","Straight_Hair","Wavy_Hair","Wearing_Earrings","Wearing_Hat",
"Wearing_Lipstick","Wearing_Necklace","Wearing_Necktie","Young"]) #英文原版属性
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)) #获取视频宽度
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) #获取视频高度
fps = cap.get(cv2.CAP_PROP_FPS) #获取视频FPS,如果是实时摄像头请手动设定帧数
out = cv2.VideoWriter('output3.avi', cv2.VideoWriter_fourcc(*"MJPG"), fps, (width,height)) #保存视频,没需求可去掉
def cv2_preprocess(img): #numpy预处理和torch处理一样img = cv2.resize(img, (128, 128), interpolation=cv2.INTER_NEAREST)img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)mean = [0.5,0.5,0.5] #一定要是3个通道,不能直接减0.5std = [0.5,0.5,0.5]img = ((img / 255.0 - mean) / std)img = img.transpose((2,0,1)) #hwc变为chwimg = np.expand_dims(img, axis=0) #3维到4维img = np.ascontiguousarray(img, dtype=np.float32) #转换浮点型return img
def sigmoid_array(x): #sigmoid函数手动设定return 1 / (1 + np.exp(-x))
def result_inference(input_array): #推理环节ort_inputs = {ort_session.get_inputs()[0].name: input_array}ort_outs = ort_session.run(None, ort_inputs)possibility = sigmoid_array(ort_outs[0]) > 0.5result = list_attr_en[possibility[0]]return result
with mp_face_detection.FaceDetection(model_selection=1, min_detection_confidence=0.5) as face_detection:#人脸识别,1为通用模型,0为近距离模型while cap.isOpened():a1 = time.time()success, image = cap.read()if not success:print("Ignoring empty camera frame.")breakimage.flags.writeable = False #据说这样写可以加速人脸识别推理image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)results = face_detection.process(image)image.flags.writeable = Trueimage = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)image2 = image.copy() #copy复制,因为cv2会直接覆盖原有数组if results.detections:for detection in results.detections:mp_drawing.draw_detection(image, detection)image_rows, image_cols, _ = image.shapelocation = detection.location_data.relative_bounding_box #获取人脸位置start_point = mp_drawing._normalized_to_pixel_coordinates(location.xmin, location.ymin,image_cols,image_rows) #获取人脸左上角的点end_point = mp_drawing._normalized_to_pixel_coordinates(location.xmin + location.width, location.ymin + location.height,image_cols,image_rows) #获取右下角的点x1,y1 = start_point #左上点坐标x2,y2 = end_point #右下点坐标img_infer = image2[y1-70:y2,x1-50:x2+50].copy() #为了营造相似环境,把左上角和右上角的点连线囊括的区域扩大提高准确度img_infer = cv2_preprocess(img_infer)result = result_inference(img_infer)# # cv2.imshow('test',img_infer)# if cv2.waitKey(5) & 0xFF == 27:# breakfor i in range(0,len(result)):image = cv2.putText(image, result[i],(x1,y1+i*40), cv2.FONT_HERSHEY_SIMPLEX, 1, (255,255,255), 1, cv2.LINE_AA) #画文字,一行一行画,如果想要中文请自行编译安装freetype版opencv,不推荐用别的库包裹转换中文,速度慢a2 = time.time()out.write(image)print(f'one pic time is {a2 - a1} s')
此外,mediapipe本身提供的功能是自带画人脸关键点的,如果不想要关键点可以和我一样把它注释掉:
最终成果
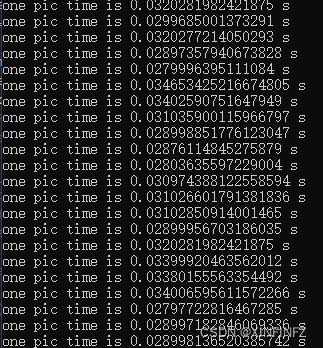
推理时间测试了多个视频,一帧完整的从读取到检测画图画完的时间大约在0.01-0.035之间,换算下来每秒可以达到30-100帧。
从下图可以看到识别出来的属性还是挺准的,图上是一位棕色头发没有胡子的有吸引力的年轻女性。属性条有变化是因为人脸识别捕捉的区域不同,也没有加上人脸跟踪的算法。

相关文章:
pytorch项目实战之实时人脸属性检测系统
简介 本项目采用CelebA人脸属性数据集训练人脸属性分类模型,使用mediapipe进行人脸检测,使用onnxruntime进行模型的推理,最终在intel的奔腾cpu上实现30-100帧完整的实时人脸属性识别系统。 ps:本来是打算写成付费专栏的,毕竟这是…...

JS和Jquery
js函数 function 方法名(参数){ 方法体 return 返回值; } js事件 事件介绍 事件指的就是当某些组件执行了某些操作后,会触发某些代码的执行 onload 某个页面或图像被完成加载 onsubmit 当表单提交时触发事件 onclick 鼠标单击事件…...

Linux设置固定IP
vi /etc/sysconfig/network-scripts/ifcfg-ens33 第一个修改是开启网络 修改完成后重启网络服务 sudo service network restart 然后就可以看到ip 地址了 然后我们开始修改固定IP 主要是下图中的两部分 BOOTPROTO从dhcp改为static HWADD好像改不改都行,我改了&…...

面试准备啊
fail fast 是把数组原来的更改次数记住 每次都去比较 变了 就抛异常 如果数组容量没到64 会先扩容 再树化 缺点:全是偶数 hash分布不均匀 质数比较好(二次哈希也不需要) 效率好 2的n次幂 使用内存屏障解决指令重排序 第一次扩容和之后的不…...
机器人工程专业师生的第二张名片
课堂上多次提及第二张名片。什么是CatGPT-使用效果如何-专业感性非理性总结如下:机器人工程的工作与考研之困惑→汇总篇←其中包括:☞ 机器人工程的工作与考研之困惑“卷”☞ 机器人工程的工作与考研之困惑“歧视”☞ 机器人工程的工作与考研之困惑“取舍…...

【云原生之企业级容器技术 Docker实战一】Docker 介绍
目录一、Docker 介绍1.1 容器历史1.2 Docker 是什么1.3 Docker 和虚拟机,物理主机1.4 Docker 的组成1.5 Namespace1.6 Control groups1.7 容器管理工具1.8 Docker 的优势1.9 Docker 的缺点1.10 容器的相关技术1.10.1 容器规范1.10.2 容器 runtime1.10.3 容器管理工具…...
【Microsoft】与 Bing AI 进行 ⌈狂飙⌋
🎊 今天是3月8号,❤️农历二月十七,💕祝广大女同胞们👩女神节快乐🎉!——以创作之名致敬女性开发者文章目录序言Ⅰ、Bing AI初体验Ⅱ、代码生成Ⅲ、生成图像Ⅳ、使用次数Ⅴ、总结序言 近期&…...

PyDolphinScheduler发布4.0.2版本,修复无法提交工作流到DolphinScheduler 3.1.4的问题
点击蓝字 关注我们PyDolphinScheduler 正式发布 4.0.2 版本,主要修复了 4.0.1 版本无法提交工作流到 Apache DolphinScheduler 3.1.4 的问题。除此之外,PyDolphinScheduler 4.0.2 较大的优化还包括:PyDolphinScheduler 校验 Apache DolphinSc…...

go-cqhttp安装使用
2023-03-28 时效性强 go-cqhttp qq机器人 qq bot 安装 本地虚拟机 centos7安装使用 浏览官方文档go-cqhttp 帮助中心 下载:Releases Mrs4s/go-cqhttp GitHub 当前最新版本v1.0.0-rc5 下载go-cqhttp_1.0.0-rc5_linux_amd64.rpm 传到服务器,新…...

论文阅读和分析:Hybrid Mathematical Symbol Recognition using Support Vector Machines
HMER论文系列 1、论文阅读和分析:When Counting Meets HMER Counting-Aware Network for HMER_KPer_Yang的博客-CSDN博客 2、论文阅读和分析:Syntax-Aware Network for Handwritten Mathematical Expression Recognition_KPer_Yang的博客-CSDN博客 3、论…...

05期:面向业务的消息服务落地实践
这里记录的是学习分享内容,文章维护在 Github:studeyang/leanrning-share。 我们在上次分享中聊到了领域驱动设计和微服务,在 DDD 中有一个术语叫做领域事件,例如订单模型中的订单已创建、商品已发货。领域事件会触发下一步的业务…...
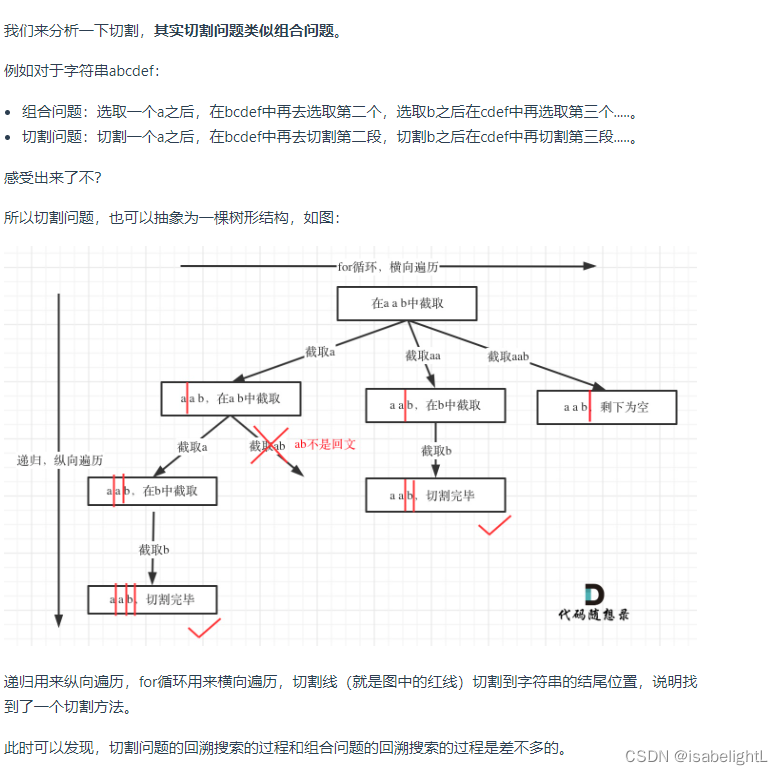
代码随想录|day26|回溯算法part03● 39. 组合总和● 40.组合总和II● 131.分割回文串
今天的练习基本就是回溯法组合问题,这一节只要看labuladong即可。 组合问题: 39. 组合总和---------------------形式三,元素无重可复选 链接:代码随想录 一次对,同样在进入下次循环时,注意startindex是从j…...

linux-文件切割-splitcsplit
目录 按大小切割-split 按行数切割-split 按内容切割-csplit 按大小切割-split split -b 10k example.conf -d -a 3 output.file example.conf 被切割的文件 -b 指定切割大小 -d 数字后缀 -a 后缀长度,默认2 output.file …...
)
USB键盘实现——设备限定描述符(五)
文章目录设备限定描述符仓库地址设备限定描述符介绍设备限定描述符结构体定义获取设备限定描述符的请求标准设备请求USB 控制端点收到的数据设备限定描述符返回附 STM32 枚举日志设备限定描述符 设备限定描述符内容解析和 HID鼠标 一致。 仓库地址 仓库地址 设备限定描述符…...
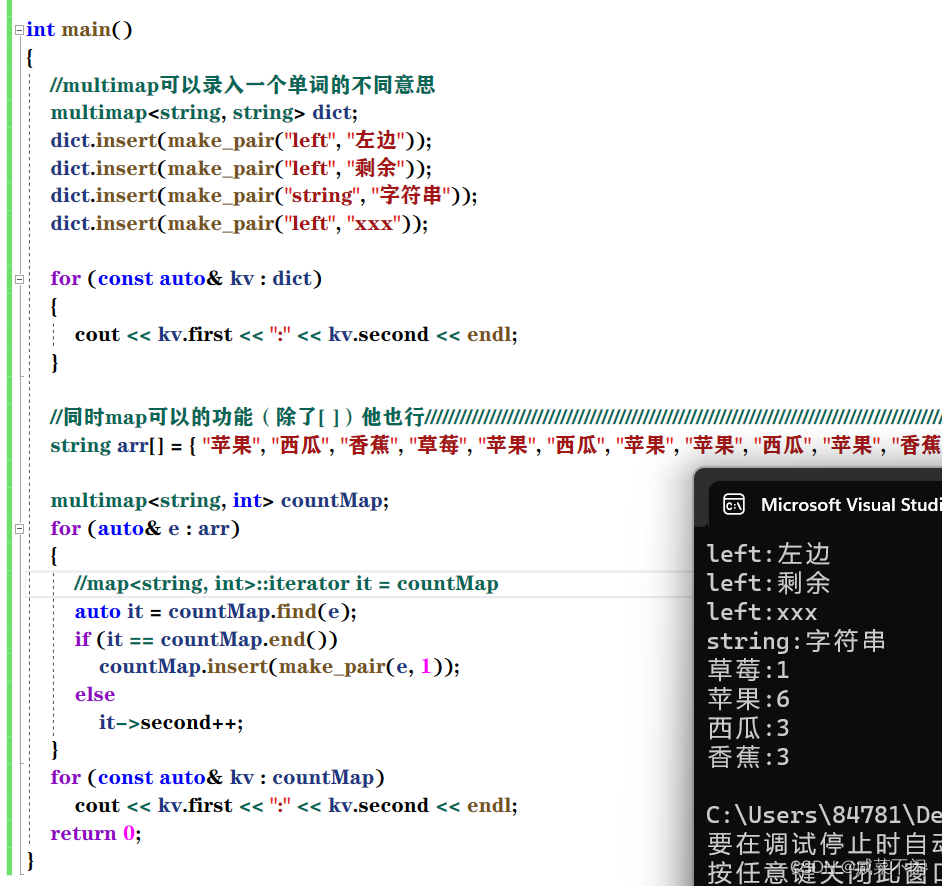
【C++】map和set(一文拿捏,包教包会)
目录 1.关联式容器和序列式容器 2.键值对 3.树型结构的关联式容器 4.set 5.multiset 6.map 7.multimap 1.关联式容器和序列式容器 set:关联式容器——数据之间关联紧密 线性表(vector,list,deque):序…...

爬虫Day2 正则表达式
爬虫Day2 正则表达式 一、正则表达式 1. 正则的作用 正则表达式是一种可以让复杂的字符串变得简单的工具。 写正则表达式就是用正则符号来描述字符串规则 # 案例1:判断一个字符串是否是一个合法的手机号码 tel 23297293329# 方法1:不用正则 if len…...

LeetCode-0324~28
leetCode1032 思路:想的是维护一个后缀数组,然后用Set去判断一下,结果超时了,去看题解,好家伙AC自动机,没办法,开始学。 正确题解: class ACNode{public ACNode[] children;publi…...
Vue2自己封装的基础组件库或基于Element-ui再次封装的基础组件库,如何发布到npm并使用(支持全局或按需引入使用),超详细
最终效果如下 一、先创建vue2项目 1、 可以用vue-cli自己来创建;也可以直接使用我开源常规的vue2后台管理系统模板 以下我以 wocwin-admin-vue2 项目为例 修改目录结构,最终如下 2、修改vue.config.js文件 module.exports { // 修改 src 目录 为 exam…...

【开发】中间件——MongoDB
MongoDB是一个基于分布式(海量数据存储)文件存储的数据库。 MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的,它支持的数据结构非常松散,是类似json…...
C++进阶 — 【C++11】
目录 一、 C11简介 二、 统一的列表初始化 1.{}初始化 2. initializer_list 三、声明 1. auto 2. decltype 3. nullptr 四、范围for循环 五、STL中一些变化 1. 提供了一些新容器 2.容器中增加了一些新方法 六、右值引用和移动语义 1. 左值引用和右…...

利用ngx_stream_return_module构建简易 TCP/UDP 响应网关
一、模块概述 ngx_stream_return_module 提供了一个极简的指令: return <value>;在收到客户端连接后,立即将 <value> 写回并关闭连接。<value> 支持内嵌文本和内置变量(如 $time_iso8601、$remote_addr 等)&a…...

反向工程与模型迁移:打造未来商品详情API的可持续创新体系
在电商行业蓬勃发展的当下,商品详情API作为连接电商平台与开发者、商家及用户的关键纽带,其重要性日益凸显。传统商品详情API主要聚焦于商品基本信息(如名称、价格、库存等)的获取与展示,已难以满足市场对个性化、智能…...

AI Agent与Agentic AI:原理、应用、挑战与未来展望
文章目录 一、引言二、AI Agent与Agentic AI的兴起2.1 技术契机与生态成熟2.2 Agent的定义与特征2.3 Agent的发展历程 三、AI Agent的核心技术栈解密3.1 感知模块代码示例:使用Python和OpenCV进行图像识别 3.2 认知与决策模块代码示例:使用OpenAI GPT-3进…...

FastAPI 教程:从入门到实践
FastAPI 是一个现代、快速(高性能)的 Web 框架,用于构建 API,支持 Python 3.6。它基于标准 Python 类型提示,易于学习且功能强大。以下是一个完整的 FastAPI 入门教程,涵盖从环境搭建到创建并运行一个简单的…...

Psychopy音频的使用
Psychopy音频的使用 本文主要解决以下问题: 指定音频引擎与设备;播放音频文件 本文所使用的环境: Python3.10 numpy2.2.6 psychopy2025.1.1 psychtoolbox3.0.19.14 一、音频配置 Psychopy文档链接为Sound - for audio playback — Psy…...

聊一聊接口测试的意义有哪些?
目录 一、隔离性 & 早期测试 二、保障系统集成质量 三、验证业务逻辑的核心层 四、提升测试效率与覆盖度 五、系统稳定性的守护者 六、驱动团队协作与契约管理 七、性能与扩展性的前置评估 八、持续交付的核心支撑 接口测试的意义可以从四个维度展开,首…...

基于matlab策略迭代和值迭代法的动态规划
经典的基于策略迭代和值迭代法的动态规划matlab代码,实现机器人的最优运输 Dynamic-Programming-master/Environment.pdf , 104724 Dynamic-Programming-master/README.md , 506 Dynamic-Programming-master/generalizedPolicyIteration.m , 1970 Dynamic-Programm…...

docker 部署发现spring.profiles.active 问题
报错: org.springframework.boot.context.config.InvalidConfigDataPropertyException: Property spring.profiles.active imported from location class path resource [application-test.yml] is invalid in a profile specific resource [origin: class path re…...

LangFlow技术架构分析
🔧 LangFlow 的可视化技术栈 前端节点编辑器 底层框架:基于 (一个现代化的 React 节点绘图库) 功能: 拖拽式构建 LangGraph 状态机 实时连线定义节点依赖关系 可视化调试循环和分支逻辑 与 LangGraph 的深…...

GAN模式奔溃的探讨论文综述(一)
简介 简介:今天带来一篇关于GAN的,对于模式奔溃的一个探讨的一个问题,帮助大家更好的解决训练中遇到的一个难题。 论文题目:An in-depth review and analysis of mode collapse in GAN 期刊:Machine Learning 链接:...