9.5. 机器翻译与数据集
笔记
9.5. 机器翻译与数据集 — 动手学深度学习 2.0.0 documentation
1.下载文件 读文件
2.处理数据 在所有标点符号前面加空格 后面用于分割 因为法语英语可能有半角全角的字符区分用utf编码的方式统一成半角字符的空格
3.因为分隔用的是空格split 所有vocab是没有空格的
4.分割之后 分别是词源和翻译两个list
![]()
分别都是一个大list装着不同的小list,小list对应的是原本的词语加字符,用空格split之后分开装了
5.后续用vocab处理, 提前加入reserved_tokens=['<pad>', '<bos>', '<eos>'] 这三个 pad是后续padding用的就是填充的缩写,填充标识符,bos是开始标识符,eos是结束标识符 因为固定'unknown'排第一,下标0,所有这三个正好是下标1,2,3的位置
min_freq=2出现次数少于2次的生僻词过滤,处理后得到词源和翻译字典 每一个下标对应一个word而不是字符
#此处用字典是为了之后将word和字符转成字典中按频率排的数字list,减少内存和方便操作
6.之后将词源内容src每一句转成数字list,但同时还要加上eos标识符标志结束,因为没有其他办法标志句子的结束,
标识符在vocab下标是3
![]()
7.之后将所有lines中的文本每一行line填充为num_steps长度,当num_steps为8的时候
以str的角度来看go.这个文本转换成vocab的数字序列之后只有2的长度,加上eos标志符也只有3.所以需要填充为go.<eos><pad><pad><pad><pad><pad> 这样的话就是长度为8了
以数字序列来看就是[9, 4, 3, 1, 1, 1, 1, 1] 9是go,.是4, eos是3 注意是在eos后面加
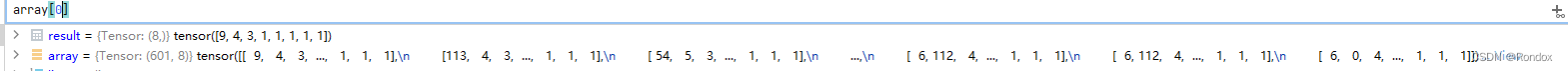
因为要方便后面算valid有效长度
8.算有效长度:
valid_len = (array != vocab['<pad>']).type(torch.int32).sum(1)
用下标0组实例分解
(array != vocab['<pad>']).type(torch.int32) 布尔转int

最后以全组再用sum在1维处减少维数

得到有效长度list
9.最后就是构成传数据的函数load_data_nmt返回数据 返回四个成员组成的tuple
import os
import torch
from d2l import torch as d2l#@save
d2l.DATA_HUB['fra-eng'] = (d2l.DATA_URL + 'fra-eng.zip','94646ad1522d915e7b0f9296181140edcf86a4f5')#@save
def read_data_nmt():"""载入“英语-法语”数据集"""data_dir = d2l.download_extract('fra-eng')with open(os.path.join(data_dir, 'fra.txt'), 'r',encoding='utf-8') as f:return f.read()raw_text = read_data_nmt()
print(raw_text[:75])#@save
def preprocess_nmt(text):"""预处理“英语-法语”数据集"""def no_space(char, prev_char):return char in set(',.!?') and prev_char != ' '# 使用空格替换不间断空格# 使用小写字母替换大写字母text = text.replace('\u202f', ' ').replace('\xa0', ' ').lower()# 在单词和标点符号之间插入空格out = [' ' + char if i > 0 and no_space(char, text[i - 1]) else charfor i, char in enumerate(text)]return ''.join(out)text = preprocess_nmt(raw_text)
print(text[:80])#@save
def tokenize_nmt(text, num_examples=None):"""词元化“英语-法语”数据数据集"""source, target = [], []for i, line in enumerate(text.split('\n')):if num_examples and i > num_examples:breakparts = line.split('\t')if len(parts) == 2:source.append(parts[0].split(' '))target.append(parts[1].split(' '))return source, targetsource, target = tokenize_nmt(text)
source[:6], target[:6]#@save
def show_list_len_pair_hist(legend, xlabel, ylabel, xlist, ylist):"""绘制列表长度对的直方图"""d2l.set_figsize()_, _, patches = d2l.plt.hist([[len(l) for l in xlist], [len(l) for l in ylist]])d2l.plt.xlabel(xlabel)d2l.plt.ylabel(ylabel)for patch in patches[1].patches:patch.set_hatch('/')d2l.plt.legend(legend)show_list_len_pair_hist(['source', 'target'], '# tokens per sequence','count', source, target);src_vocab = d2l.Vocab(source, min_freq=2,reserved_tokens=['<pad>', '<bos>', '<eos>'])#空格只做分割 vocab是没有空格的 src_vocab[' ']
len(src_vocab)#@save
def truncate_pad(line, num_steps, padding_token):#padding_token指用哪个token用于填充padding 传进去的是vocab的下标"""截断或填充文本序列 truncate翻译是截断"""if len(line) > num_steps:return line[:num_steps] # 截断return line + [padding_token] * (num_steps - len(line)) # 填充#line是[47, 4] 这里意思是往里面一直加元素这样一个[1]truncate_pad(src_vocab[source[0]], 10, src_vocab['<pad>'])#@save
def build_array_nmt(lines, vocab, num_steps):"""将机器翻译的文本序列转换成小批量"""lines = [vocab[l] for l in lines]lines = [l + [vocab['<eos>']] for l in lines]#数字list加上一个eos标识符的下标 所以加了一个结束的标志下标 比如[9,4]->[9,4,3]array = torch.tensor([truncate_pad(l, num_steps, vocab['<pad>']) for l in lines])valid_len = (array != vocab['<pad>']).type(torch.int32).sum(1)return array, valid_len#@save
def load_data_nmt(batch_size, num_steps, num_examples=600):"""返回翻译数据集的迭代器和词表"""text = preprocess_nmt(read_data_nmt())source, target = tokenize_nmt(text, num_examples)src_vocab = d2l.Vocab(source, min_freq=2,reserved_tokens=['<pad>', '<bos>', '<eos>'])tgt_vocab = d2l.Vocab(target, min_freq=2,reserved_tokens=['<pad>', '<bos>', '<eos>'])src_array, src_valid_len = build_array_nmt(source, src_vocab, num_steps)tgt_array, tgt_valid_len = build_array_nmt(target, tgt_vocab, num_steps)data_arrays = (src_array, src_valid_len, tgt_array, tgt_valid_len)data_iter = d2l.load_array(data_arrays, batch_size)return data_iter, src_vocab, tgt_vocabtrain_iter, src_vocab, tgt_vocab = load_data_nmt(batch_size=2, num_steps=8)
for X, X_valid_len, Y, Y_valid_len in train_iter:print('X:', X.type(torch.int32))print('X的有效长度:', X_valid_len)print('Y:', Y.type(torch.int32))print('Y的有效长度:', Y_valid_len)break相关文章:
9.5. 机器翻译与数据集
笔记 9.5. 机器翻译与数据集 — 动手学深度学习 2.0.0 documentation 1.下载文件 读文件 2.处理数据 在所有标点符号前面加空格 后面用于分割 因为法语英语可能有半角全角的字符区分用utf编码的方式统一成半角字符的空格 3.因为分隔用的是空格split 所有vocab是没有空格的 …...

跟着凯新生物2 Arm PEG Biotin,2-Branched PEG Biotin,生物素-聚乙二醇-二臂/支,学试剂知识
中英文名:2 Arm/Branched PEG Biotin,2 ArmPEG Biotin,二臂/支 PEG 生物素一、Product specifications: 1.CAS No:N/A 2.Packaging specification:10mg,25mg,50mg, flexible packagi…...

react组件进阶(四)
文章目录1. 组件通讯介绍2. 组件的 props3. 组件通讯的三种方式3.1 父组件传递数据给子组件3.2 子组件传递数据给父组件3.3 兄弟组件4. Context5. props 深入5.1 children 属性5.2 props 校验5.3 props 的默认值6. 组件的生命周期6.1 组件的生命周期概述6.2 生命周期的三个阶段…...

阿维塔城区NCA智驾导航辅助,复杂路口,全面胜任
阿维塔11城区NCA智驾导航辅助将于3月在上海、深圳等城市分阶段开启体验,以看得清、判得准、控得稳的“智驾”,进一步巩固业界智能天花板的地位。智能驾驶里程碑,拨杆两下开启都市安适旅程作为AVATRANS智能领航系统的重要组成部分,…...

[Pandas] div()函数
div()方法将DataFrame中的每个值除以指定的值,并返回一个计算处理后的Dataframe结果 DataFrame.div()函数其实是除法运算,表格中的每个数据都是被除数 导入数据 import pandas as pd df pd.DataFrame({"col1":[5, 3, None, 4], "col2…...

c++并发与多线程
c并发与多线程 子线程结束,主线程不能结束,否则会出错,和java不一样。 可以用join的方式让主线程等待子线程执行结束。 quickStart 线程相关头文件 #include <thread> 使用全局函数构造一个线程对象 #include <iostream> #…...

Vinylsulfone PEG Biotin,Biotin-PEG-VS,生物素聚乙二醇乙烯砜,VS基团容易与游离巯基发生反应
●中文名:乙烯砜PEG生物素,生物素聚乙二醇乙烯砜 ●英文名:Vinylsulfone PEG Biotin, VS-PEG-Biotin,Vinyl sulfone-PEG-Biotin,Biotins-PEG-sulfone Vinyl●产品理化指标: CAS号:N/A 分子量&am…...
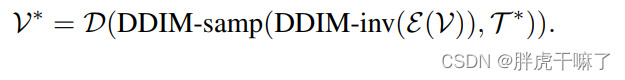
论文学习——Tune-A-Video
Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation Abstract 本文提出了一种方法,站在巨人的肩膀上——在大规模图像数据集上pretrain并表现良好的 text to image 生成模型——加入新结构并进行微调,训练出一套 …...

C++类与对象part1
目录 1.类的6个默认函数 2.构造函数(相当于init) 3.析构函数 (相当于destroy) 4.拷贝构造函数 赋值运算符重载 运算符重载 赋值运算符重载 引入: 你知道为什么cout可以自动识别类型吗? 其实cout是一…...

记一次抓取网页内容
已打码 // UserScript // name --------- // namespace http://tampermonkey.net/ // version 0.1 // description https://---------oups/{id}/topics?scopeall&count20&begin_time2022-09-01T00%3A00%3A00.000%2B0800&end_time2022-10-01T00%…...
parasoft帮助史密斯医疗通过测试驱动开发提供安全、高质量的医疗设备
parasoft是一家专门提供软件测试解决方案的公司,Parasoft通过其经过市场验证的自动化软件测试工具集成套件,帮助企业持续交付高质量的软件。Parasoft的技术支持嵌入式、企业和物联网市场,通过将静态代码分析和单元测试、Web UI和API测试等所有…...

SpringBoot整合Oauth2开放平台接口授权案例
<!-- SpringBoot整合Web组件 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.projectlombok</groupId>&l…...

Linux_创建用户
创建一个名为hello的用户,并指定/home/hello为根目录useradd -d /home/hello -m hello 设置密码 ,密码会输入两次,一次设置密码,一次确认密码,两次密码要输入的一样passwd hellouseradd的常用参数含义-d指定用户登入时的主目录&am…...

RDD(弹性分布式数据集)总结
文章目录一、设计背景二、RDD概念三、RDD特性四、RDD之间的依赖关系五、阶段的划分六、RDD运行过程七、RDD的实现一、设计背景 1.某些应用场景中,不同计算阶段之间会重用中间结果,即一个阶段的输出结果会作为下一个阶段的输入。如:迭代式算法…...

服务器版RstudioServer安装与配置详细教程
Docker部署Rstudio server 背景:如果您想在服务器上运行RstudioServer,可以按照如下方法进行操作,笔者测试时使用腾讯云服务器(系统centos7),需要在管理员权限下运行 Rstudio 官方提供了使用不同 R 版本的 …...

如何在Java中将一个列表拆分为多个较小的列表
在Java中,有多种方法可以将一个列表拆分为多个较小的列表。在本文中,我们将介绍三种不同的方法来实现这一目标。 方法一:使用List.subList()方法 List接口提供了一个subList()方法,它可以用来获取列表中的一部分元素。我们可以使…...

TryHackMe-Inferno(boot2root)
Inferno 现实生活中的机器CTF。该机器被设计为现实生活(也许不是?),非常适合刚开始渗透测试的新手 “在我们人生旅程的中途,我发现自己身处一片黑暗的森林中,因为直截了当的道路已经迷失了。我啊…...

微信原生开发中 JSON配置文件的作用 小程序中有几种JSON配制文件
关于json json是一种数据格式,在实际开发中,JSON总是以配制文件的形式出现,小程序与不例外,可对项目进行不同级别的配制。Q:小程序中有几种配制文件A:小程序中有四种配制文件分别是:project.config.json si…...

【python】为什么使用python Django开发网站这么火?
关注“测试开发自动化” 弓中皓,获取更多学习内容) Django 是一个基于 Python 的 Web 开发框架,它提供了许多工具和功能,使开发者可以更快地构建 Web 应用程序。以下是 Django 开发中的一些重要知识点: MTV 模式&#…...

Java设计模式(五)—— 责任链模式
责任链模式定义如下:使多个对象都有机会处理请求,从而避免请求的发送者与接收者之间的耦合关系。将这些对象连成一条链,并沿着这条链传递该请求,知道有一个对象处理它为止。 适合使用责任链模式的情景如下: 有许多对…...

网络六边形受到攻击
大家读完觉得有帮助记得关注和点赞!!! 抽象 现代智能交通系统 (ITS) 的一个关键要求是能够以安全、可靠和匿名的方式从互联车辆和移动设备收集地理参考数据。Nexagon 协议建立在 IETF 定位器/ID 分离协议 (…...

基于大模型的 UI 自动化系统
基于大模型的 UI 自动化系统 下面是一个完整的 Python 系统,利用大模型实现智能 UI 自动化,结合计算机视觉和自然语言处理技术,实现"看屏操作"的能力。 系统架构设计 #mermaid-svg-2gn2GRvh5WCP2ktF {font-family:"trebuchet ms",verdana,arial,sans-…...

利用ngx_stream_return_module构建简易 TCP/UDP 响应网关
一、模块概述 ngx_stream_return_module 提供了一个极简的指令: return <value>;在收到客户端连接后,立即将 <value> 写回并关闭连接。<value> 支持内嵌文本和内置变量(如 $time_iso8601、$remote_addr 等)&a…...

uni-app学习笔记二十二---使用vite.config.js全局导入常用依赖
在前面的练习中,每个页面需要使用ref,onShow等生命周期钩子函数时都需要像下面这样导入 import {onMounted, ref} from "vue" 如果不想每个页面都导入,需要使用node.js命令npm安装unplugin-auto-import npm install unplugin-au…...

解决Ubuntu22.04 VMware失败的问题 ubuntu入门之二十八
现象1 打开VMware失败 Ubuntu升级之后打开VMware上报需要安装vmmon和vmnet,点击确认后如下提示 最终上报fail 解决方法 内核升级导致,需要在新内核下重新下载编译安装 查看版本 $ vmware -v VMware Workstation 17.5.1 build-23298084$ lsb_release…...

关于iview组件中使用 table , 绑定序号分页后序号从1开始的解决方案
问题描述:iview使用table 中type: "index",分页之后 ,索引还是从1开始,试过绑定后台返回数据的id, 这种方法可行,就是后台返回数据的每个页面id都不完全是按照从1开始的升序,因此百度了下,找到了…...

Objective-C常用命名规范总结
【OC】常用命名规范总结 文章目录 【OC】常用命名规范总结1.类名(Class Name)2.协议名(Protocol Name)3.方法名(Method Name)4.属性名(Property Name)5.局部变量/实例变量(Local / Instance Variables&…...

Python实现prophet 理论及参数优化
文章目录 Prophet理论及模型参数介绍Python代码完整实现prophet 添加外部数据进行模型优化 之前初步学习prophet的时候,写过一篇简单实现,后期随着对该模型的深入研究,本次记录涉及到prophet 的公式以及参数调优,从公式可以更直观…...

Spring数据访问模块设计
前面我们已经完成了IoC和web模块的设计,聪明的码友立马就知道了,该到数据访问模块了,要不就这俩玩个6啊,查库势在必行,至此,它来了。 一、核心设计理念 1、痛点在哪 应用离不开数据(数据库、No…...

【Java学习笔记】BigInteger 和 BigDecimal 类
BigInteger 和 BigDecimal 类 二者共有的常见方法 方法功能add加subtract减multiply乘divide除 注意点:传参类型必须是类对象 一、BigInteger 1. 作用:适合保存比较大的整型数 2. 使用说明 创建BigInteger对象 传入字符串 3. 代码示例 import j…...