大数据-126 - Flink State 03篇 状态原理和原理剖析:状态存储 Part1
点一下关注吧!!!非常感谢!!持续更新!!!
目前已经更新到了:
- Hadoop(已更完)
- HDFS(已更完)
- MapReduce(已更完)
- Hive(已更完)
- Flume(已更完)
- Sqoop(已更完)
- Zookeeper(已更完)
- HBase(已更完)
- Redis (已更完)
- Kafka(已更完)
- Spark(已更完)
- Flink(正在更新!)
章节内容
上节我们完成了如下的内容:
- Flink 广播状态
- 基本概念、代码案例、测试结果

状态存储
Flink的一个重要特性就是有状态计算(stateful processing),Flink提供了简单易用的API来存储和获取状态,但是我们还是要理解API背后的原理,才能更好的使用。
State存储方式
Flink为State提供了三种开箱即用的后端存储方式(state backend):
- Memory State Backend
- File System (FS)State Backend
- RocksDB State Backend
MemoryStateBackend
MemoryStateBackend将工作状态数据保存在TaskManager的Java内存中。Key/Value状态和Window算子使用哈希表存储数值和触发器。进行快照时(CheckPointing),生成的快照数据将和 CheckPoint ACK消息一起发送给 JobManager,JobManager将收到的所有快照数据保存在Java内存中。
MemoryStateBackend现在被默认配置成异步的,这样避免阻塞主线程的pipline处理,MemoryStateBackend的状态存取的数据都非常快,但是不适合生产环境中使用。这是以为它有以下限制:
- 每个state的默认大小被限制为5MB(这个值可以通过MemoryStateBackend构造方法设置)
- 每个Task的所有State数据(一个Task可能包含一个Pipline中的多个的Operator)大小不能超过RPC系统的帧大小(akk.framesize 默认10MB)
- JobManager收到的State数据总和不能超过JobManager内存
MemoryStateBackend适合的场景:
- 本地开发和调试
- 状态很小的作业

FsStateBackend
FsStateBackend 需要配置一个CheckPoint路径,例如:hdfs://xxxxxxx 或者 file:///xxxxx,我们一般都会配置HDFS的目录。
FsStateBackend将工作状态数据保存在TaskManager的Java内存中,进行快照时,再将快照数据写入上面的配置的路径,然后将写入的文件路径告知JobManager。JobManager中保存所有状态的元数据信息(在HA的模式下,元数据会写入CheckPoint目录)。
FsStateBackend 默认使用异步方式进行快照,防止阻塞主线程的Pipline处理,可以通过FsStateBackend构造函数取消该模式:
new FsStateBackend(path, false)
FsStateBackend 适合的场景:
- 大状态、长窗口、大键值(键或者值很大)状态的作业
- 适合高可用方案

RocksDBStateBackend
RocksDBStateBackend 也需要配置一个CheckPoint路径,例如:hdfs://xxx 或者 file:///xxx,一般是 HDFS 路径。
RocksDB是一种可嵌入的可持久型的 key-value 存储引擎,提供 ACID 支持。由Facebook基于LevelDB开发,使用LSM存储引擎,是内存和磁盘的混合存储。
RocksDBStateBackend将工作状态保存在TaskManager的RocksDB数据库中,CheckPoint时,RocksDB中的所有数据会被传输到配置的文件目录,少量元数据信息保存在JobManager内存中(HA模式下,会保存在CheckPoint目录)。
RocksDBStateBackend使用异步方式进行快照,RocksDBStateBackend的限制:
- 由于RocksDB的JNI Bridge API是基于 byte[] 的,RocksDBStateBackend支持的每个Key或者每个Value的最大值不超过 2的31次方(2GB)
- 要注意的是,有merge操作的状态(例如:ListState),可能会在运行过程中超过2的31次时,导致程序失败。
RocksDBStateBackend适用于以下的场景: - 超大状态、超长窗口(天)、大键值状态的作业
- 适合高可用模式
使用RocksDBStateBackend时,能够限制状态大小是TaskManager磁盘空间(相对于FsStateBackend状态大小限制与TaskManager内存)。这也导致RocksDBStateBackend的吞吐比其他两个要低一些,因为RocksDB的状态数据的读写都要经过反序列化/序列化。
RocksDBStateBackend时目前三者中唯一支持增量CheckPoint的。

三者吞吐量对比

KeyedState 和 Operator State
State分类
Operator State
(或 non-keyed state):
每个Operator State绑定一个并行的Operator实例,KafkaConnector是使用OperatorState的典型示例:每个并行的Kafka Consumer实例维护了每个Kafka Topic分区和该分区Offset的映射关系,并将这个映射关系保存为OperatorState。
在算子并行度改变时,OperatorState也会重新分配。
Keyed State
这种State只存在于KeyedStream上的函数和操作中,比如Keyed UDF(KeyedProcessFunction)Window State。可以把Keyed State想象成被分区的OperatorState。每个KeyedState在逻辑上可以看成与一个 <parallel-operator-instance, key> 绑定,由于一个key肯定只存在于一个Operator实例,所以我们可以简单的的认为一个 <operator, key>对应一个 KeyedState。
每个KeyedState在逻辑上还会被分配一个KeyGroup,分配方法如下:
MathUtils.murmurHash(key.hashCode()) % maxParallelism;
其中maxParallelism是Flink程序的最大并行度,这个值一般我们不会去手动设置,使用默认的值(128)就好,这里注意下,maxParallelism和我们运行程序时指定的算子并行度(parallelism)不同,parallelism不能大于maxParallelism,最多两者相等。
为什么会有 Key Group这个概念呢?
我们通常写程序,会给算子指定一个并行度,运行一段时间后,积累了一些State,这时候数据量大了,需要增加并行度。我们修改并行度后重新提交,那这些已经存在的State该如何分配到各个Operator呢?这就有了最大并行度和KeyGroup的概念。
上面的计算公式也说明了KeyGroup的个数最多是maxParallelism个。当并行度改变之后,我们在计算这个Key被分配到的Operator:
keyGroupId * paralleism / maxParallelism;
可以看到,一个KeyGroupId会对应一个Operator,当并行度更改时,新的Operator会去拉取对应的KeyGroup的KeyedState,这样就把KeyedState尽量均匀的分配给所有的Operator了。
根据State数据是否被Flink托管,Flink又将State分类为:
- Managed State:被Flink托管,保存为内部的哈希表或者RocksDB,CheckPoint时,Flink将State进行序列化编码。例如:ValueState ListState
- Row State:Operator 自行管理的数据结构, Checkpoint时,它们只能以byte数据写入CheckPoint。
建议使用 Managed State,当使用 Managed State时,Flink会帮助我们更改并行度时重新分配State,优化内存。
使用ManageKeyedState
如何创建?
上面提到,KeyedState只能在KeyedStream上使用,可以通过Stream.keyBy创建KeyedStream,我们可以创建以下几种:
- ValueState
- ListState
- ReducingState
- AggregatingState<IN,OUT>
- MapState<UK,UV>
- FoldingState<T,ACC>
每种State都对应各种的描述符,通过描述符RuntimeContext中获取对应的State,而RuntimeContext只有RichFunction才能获取,所以想要使用KeyedState,用户编写的类必须继承RichFunction或者其他子类。
- ValueState getState(ValueStateDescriptor)
- ReducingState getReducingState(ReducingStateDescriptor)
- ListState getListState(ListStateDescriptor)
- AggregationState<IN,OUT> getAggregatingState(AggregatingStateDescriptor<IN,ACC,OUT>)
- FoldingState<T,ACC> getFoldingState(FoldingStateDescriptor<T,ACC>)
- MapState<UK,UV> getMapState(MapStateDescriptor<UK,UV>)
给KeyedState设置过期时间
在Flink 1.6.0 以后,还可以给KeyedState设置 TTL(Time-To-Live),当某一个Key的State数据过期时,会被StateBackend尽力删除。
官方给出了示例:
import org.apache.flink.api.common.state.StateTtlConfig;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.time.Time;StateTtlConfig ttlConfig = StateTtlConfig.newBuilder(Time.seconds(1)) // 状态存活时间.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite) // TTL 何时被更新,这里配置的 state 创建和写入时.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired).build();// 设置过期的 state 不被读取
ValueStateDescriptor<String> stateDescriptor = new ValueStateDescriptor<>("textstate", String.class);
stateDescriptor.enableTimeToLive(ttlConfig);
State的TTL何时被更新?
可以进行以下配置,默认只是key的state被modify(创建或者更新)的时候才更新TTL:
- StateTtlConfig.UpdateType.OnCreateAndWrite:只在一个key的state创建和写入时更新TTL(默认)
- StateTtlConfig.UpdateType.onReadAndWrite:读取state时仍然更新TTL
当State过期但是还未删除时,这个状态是否还可见?
可以进行以下配置,默认是不可见的:
- StateTtlConfig.StateVisibility.NerverReturnExpired:不可见(默认)
- StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp:可见
注意:
- 状态的最新访问时会和状态数据保存在一起,所以开启TTL特性增大State的大小,Heap State Backend会额外存储一个包括用户状态以及时间戳的Java8对象,RocksDB StateBackend会在每个状态值(list或者map的每个元素)序列化后增加8个字节。
- 暂时只支持基于 Processing Time的TTL。
- 尝试从CheckPoint/SavePoint进行恢复时,TTL的状态(是否开启)必须和之前保存一致,否则会遇到:StateMigrationException。
- TTL的配置并不会保存在CheckPoint/SavePoint中,仅对当前的Job有效。
- 当前开启TTL的MapState仅在用户序列化支持NULL的情况下,才支持用户值为NULL,如果用户值序列化器不支持NULL,可以用NullableSerializer包装一层。
使用ManageOperatorState
(这里以及后续放到下一篇:大数据-127 Flink)
相关文章:
大数据-126 - Flink State 03篇 状态原理和原理剖析:状态存储 Part1
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完)HDFS(已更完)MapReduce(已更完&am…...

RFID射频模块(MFRC522 STM32)
目录 一、介绍 二、传感器原理 1.原理图 2.引脚描述 3.工作原理介绍 三、程序设计 main.c文件 MFRC522.h文件 MFRC522.c文件 四、实验效果 五、资料获取 项目分享 一、介绍 RC522 RFID射频模块是一款广泛应用于非接触式RFID系统中的核心组件,由NXP&…...

【JavaSE】--方法的使用
文章目录 1. 方法概念及使用1.1 什么是方法1.2 方法定义1.3 方法调用的执行过程1.4 实参和形参的关系(重要)1.5 没有返回值的方法 2. 方法重载2.1 方法重载概念2.2 方法签名 3. 递归3.1 递归的概念3.2 递归执行过程分析3.3 递归练习 1. 方法概念及使用 1…...

wireshark打开时空白|没有接口,卸载重装可以解决
解决方法:卸载wireshark,全选卸载干净,重新安装旧版的wireshark4.2.7, 甚至cmd下运行net start npf时显示服务名无效,但打开wireshark仍有多个接口 错误描述: 一开始下载的是wireshark的最新版,win11 x64 在安装wir…...
单值二叉树--(C语言)
题目如下: 如果二叉树每个节点都具有相同的值,那么该二叉树就是单值二叉树。 只有给定的树是单值二叉树时,才返回 true;否则返回 false。 示例 1: 输入:[1,1,1,1,1,null,1] 输出:true示例 2&a…...

Linux云计算 |【第三阶段】PROJECT1-DAY2
主要内容: 网站架构演变、LNPMariadb数据库分离、Web服务器集群(部署Nginx后端web服务器、部署NFS共享存储服务器、部署Haproxy代理服务器、部署DNS域名解析服务器) 一、网站架构演变: 随着网站访问量和业务复杂度的增加&#x…...

Claude Prompt 汉语新解
感谢刚哥! ;; 作者: 李继刚 ;; 版本: 0.3 ;; 模型: Claude Sonnet ;; 用途: 将一个汉语词汇进行全新角度的解释 ;; 设定如下内容为你的 *System Prompt* (defun 新汉语老师 () "你是年轻人,批判现实,思考深刻,语言风趣" (风格 . ("Oscar Wilde&q…...

【运维监控】influxdb 2.0+grafana 监控java 虚拟机以及方法耗时情况(2)
运维监控系列文章入口:【运维监控】系列文章汇总索引 文章目录 四、grafana集成influxdb监控java 虚拟机以及方法耗时情况1、添加grafana数据源2、添加grafana的dashboard1)、选择新建dashboard方式2)、导入dashboard 3、验证 关于java应用的…...
怎么看待伦敦银交易的风险与收益?
伦敦银交易的风险与收益,在宣传材料中,伦敦银是一种潜在收益很高,潜在风险不大的品种。然而在实践中我们发现,伦敦银交易好像并不如宣传材料说的那样容易做。那么,具体伦敦银交易的风险和收益是怎么样的?那…...

如何通俗易懂的解释TON的智能合约
文章目录 一、小故事一则二、Ton的智能合约在小故事中三、python代码模拟 一、小故事一则 在一个遥远的国度里,有一个被魔法笼罩的小镇,这个小镇每年都会举办一场盛大的戏剧节。这个戏剧节不仅是演员们展示才华的舞台,更是他们交流心得、共同…...

针对Docker容器的可视化管理工具—DockerUI
目录 ⛳️推荐 前言 1. 安装部署DockerUI 2. 安装cpolar内网穿透 3. 配置DockerUI公网访问地址 4. 公网远程访问DockerUI 5. 固定DockerUI公网地址 ⛳️推荐 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下…...

五大注入攻击网络安全类型介绍
1. SQL注入(SQL Injection) SQL注入流程 1.1. 概述 SQL注入是最常见的注入攻击类型之一,攻击者通过在输入字段中插入恶意的SQL代码来改变原本的SQL逻辑或执行额外的SQL语句,来操控数据库执行未授权的操作(如拖库、获取…...

linux-L9.linux中对文件 按照时间排序 显示100 个
find . -type f -exec stat --format %Y %n {} | sort -nr | head -n 100解释: • find . -type f:在当前目录下查找所有文件。 • -exec stat --format ‘%Y %n’ {} :对每个找到的文件执行stat命令,以获取文件的修改时间&#…...
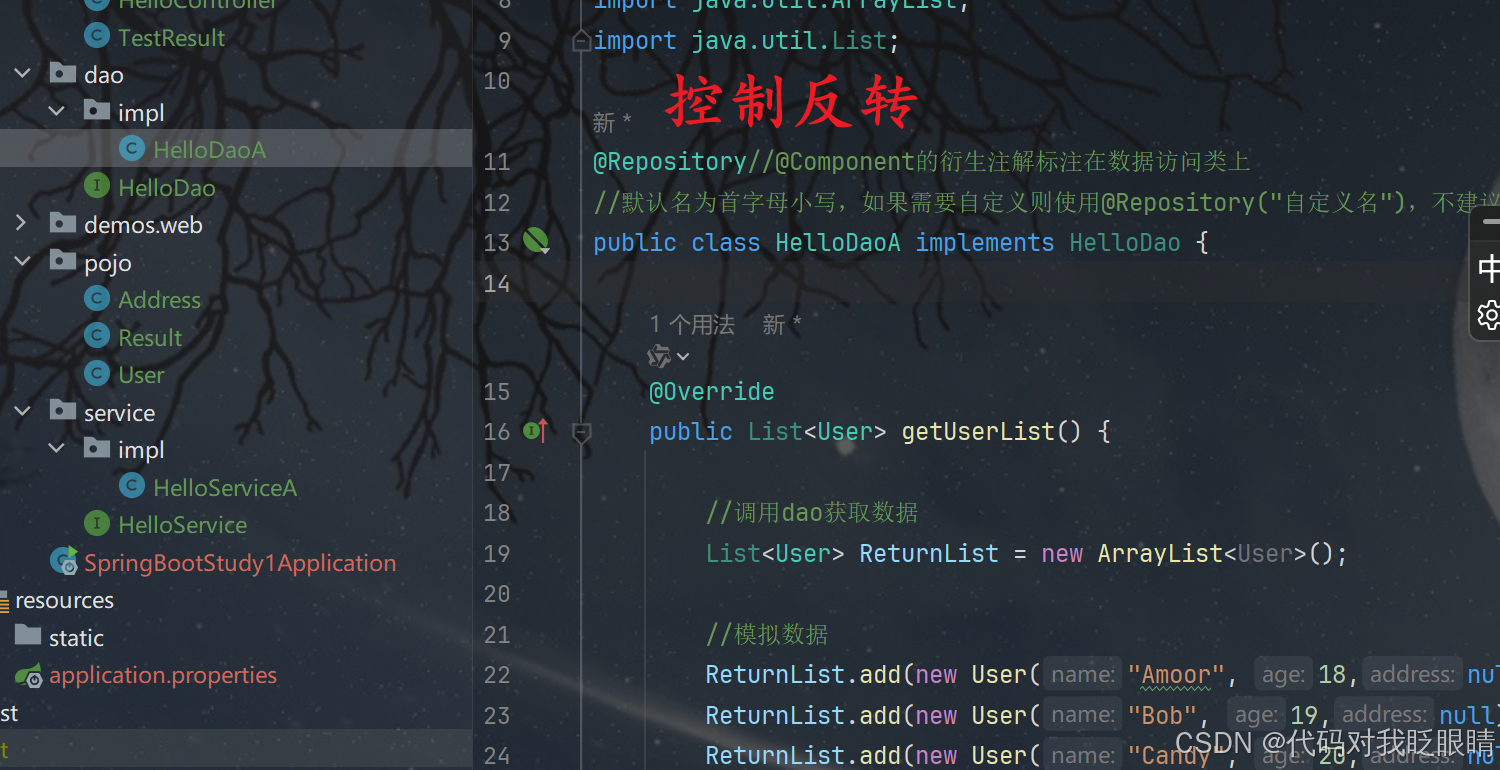
springboot从分层到解耦
注释很详细,直接上代码 三层架构 项目结构 源码: HelloController package com.amoorzheyu.controller;import com.amoorzheyu.pojo.User; import com.amoorzheyu.service.HelloService; import com.amoorzheyu.service.impl.HelloServiceA; import o…...

网络视频流解码显示后花屏问题的分析
问题描述 rtp打包的ps视频流发送到客户端后显示花屏。 数据分析过程 1、用tcpdump抓包 tcpdump -i eth0 -vnn -w rtp.pcap 2、用wireshark提取rtp的payload 保存为record.h264文件 3、用vlc播放器播放 显示花屏 4、提取关键帧 用xxd命令将h264文件转为txt文件 xxd -p…...

MySQL 大量 IN 的查询优化
背景 (1)MySQL 8.0 版本 (2)业务中遇到大量 IN 的查询,例: SELECT id, username, icon FROM users WHERE id IN (123, 523, 1343, ...);其中 id 为主键,IN 的列表长度有 8000 多个 问题 …...

python运维
环境准备 安装python3环境 # centos 安装python3 yum install python3创建激活venv python3 -m venv .venv source .venv/bin/activatezookeeper pip install kazoo 递归复制目录 from kazoo.client import KazooClientdef copy_node(zk, source_path, destination_path)…...

gen_server补充基础学习
学习gen_server的回调结构 gen_server:start_link(Name, Mod, InitArgs, Opts)这个调用是所有事物的起点。它 会创建一个名为Name的通用服务器,回调模块是Mod,Opts则控制通用服务器的行为。在这里可以指定消息记录、函数调试和其他行为。通用服务器通过…...
基础知识 | 3.1、基础语法)
Python 入门教程(3)基础知识 | 3.1、基础语法
文章目录 一、 基础语法1、缩进规则2、标识符3、多行语句 一、 基础语法 1、缩进规则 学习 Python 与其他语言最大的区别就是,Python 的代码块不使用大括号 {} 来控制类,函数以及其他逻辑判断。python 最具特色的就是用缩进来写模块。缩进的空白数量是可…...

git 合并分支并解决冲突
git 合并分支并解决冲突 切换分支 git checkout <branch-name> 首先切换到要合并的目标分支 合并分支 git merge <source-branch> //将源分支代码合并到当前分支中,源分支的各项新增的提交都会按时间点插入到当前分支的提交记录中 git merge …...

Linux应用开发之网络套接字编程(实例篇)
服务端与客户端单连接 服务端代码 #include <sys/socket.h> #include <sys/types.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <arpa/inet.h> #include <pthread.h> …...

基于ASP.NET+ SQL Server实现(Web)医院信息管理系统
医院信息管理系统 1. 课程设计内容 在 visual studio 2017 平台上,开发一个“医院信息管理系统”Web 程序。 2. 课程设计目的 综合运用 c#.net 知识,在 vs 2017 平台上,进行 ASP.NET 应用程序和简易网站的开发;初步熟悉开发一…...

在rocky linux 9.5上在线安装 docker
前面是指南,后面是日志 sudo dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo dnf install docker-ce docker-ce-cli containerd.io -y docker version sudo systemctl start docker sudo systemctl status docker …...

微信小程序 - 手机震动
一、界面 <button type"primary" bindtap"shortVibrate">短震动</button> <button type"primary" bindtap"longVibrate">长震动</button> 二、js逻辑代码 注:文档 https://developers.weixin.qq…...

2025 后端自学UNIAPP【项目实战:旅游项目】6、我的收藏页面
代码框架视图 1、先添加一个获取收藏景点的列表请求 【在文件my_api.js文件中添加】 // 引入公共的请求封装 import http from ./my_http.js// 登录接口(适配服务端返回 Token) export const login async (code, avatar) > {const res await http…...

【单片机期末】单片机系统设计
主要内容:系统状态机,系统时基,系统需求分析,系统构建,系统状态流图 一、题目要求 二、绘制系统状态流图 题目:根据上述描述绘制系统状态流图,注明状态转移条件及方向。 三、利用定时器产生时…...

爬虫基础学习day2
# 爬虫设计领域 工商:企查查、天眼查短视频:抖音、快手、西瓜 ---> 飞瓜电商:京东、淘宝、聚美优品、亚马逊 ---> 分析店铺经营决策标题、排名航空:抓取所有航空公司价格 ---> 去哪儿自媒体:采集自媒体数据进…...

动态 Web 开发技术入门篇
一、HTTP 协议核心 1.1 HTTP 基础 协议全称 :HyperText Transfer Protocol(超文本传输协议) 默认端口 :HTTP 使用 80 端口,HTTPS 使用 443 端口。 请求方法 : GET :用于获取资源,…...

2025年渗透测试面试题总结-腾讯[实习]科恩实验室-安全工程师(题目+回答)
安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 目录 腾讯[实习]科恩实验室-安全工程师 一、网络与协议 1. TCP三次握手 2. SYN扫描原理 3. HTTPS证书机制 二…...

Git常用命令完全指南:从入门到精通
Git常用命令完全指南:从入门到精通 一、基础配置命令 1. 用户信息配置 # 设置全局用户名 git config --global user.name "你的名字"# 设置全局邮箱 git config --global user.email "你的邮箱example.com"# 查看所有配置 git config --list…...