windows C++-并行编程-并行算法(五) -选择排序算法
并行模式库 (PPL) 提供了对数据集合并行地执行工作的算法。这些算法类似于 C++ 标准库提供的算法。并行算法由并发运行时中的现有功能组成。
在许多情况下,parallel_sort 会提供速度和内存性能的最佳平衡。 但是,当您增加数据集的大小、可用处理器的数量或比较函数的复杂性时,parallel_buffered_sort 或 parallel_radixsort 性能更佳。 确定在任何给定方案中使用哪种排序算法的最佳方式是:体验并度量在有代表性计算机配置下对典型数据排序需要多长时间。 在选择排序策略时请遵循以下准则。
- 数据集的大小。 在本文档中,小型数据集包含的元素少于 1,000 个,中型数据集包含的元素介于 10,000 和 100,000 个之间,而大型数据集包含的元素多于 100,000 个;
- 您的比较函数或哈希函数所执行的工作量;
- 可用计算资源的量;
- 数据集的特征。 例如,一种算法对已完成近似排序的数据可能执行效果很好,但对完全未排序的数据执行效果就不那么好了;
- 区块的大小。 可选的 _Chunk_size 参数将指定算法在将整体排序细分成较小工作单元时何时从并行排序实现切换为串行排序实现。 例如,如果提供的是 512,算法会在工作单元包含 512 个或更少元素时切换到串行实现。 串行实现可以提高整体性能,因为它消除了并行处理数据所需的开销;
以并行方式对小型数据集排序可能不值得,即使是在您拥有大量的可用计算资源或您的比较函数或哈希函数执行相对大量的工作时。 可以使用 std::sort 函数对小型数据集排序。 (当你指定的区块大小大于数据集时,parallel_sort 和 parallel_buffered_sort 会调用 sort;但是,parallel_buffered_sort 将必须分配 O(N) 空间,这样会因锁争用或内存分配而花费更多时间。)
如果您必须节省内存或您的内存分配器容易出现锁争用问题,请使用 parallel_sort 对中型数据集排序。 parallel_sort 不需要额外的空间;其他算法需要 O(N) 空间。
当你的应用程序能够满足额外的 O(N) 空间需求时,使用 parallel_buffered_sort 对中型数据集排序。 当您拥有大量的计算资源或高开销的比较函数或哈希函数时,parallel_buffered_sort 尤其有用。
当你的应用程序能够满足额外的 O(N) 空间需求时,使用 parallel_radixsort 对大型数据集排序。 当等效的比较操作开销较大或两种操作开销都很大时,parallel_radixsort 尤其有用。
好的哈希函数的实现要求你知道数据集范围以及数据集中的每个元素如何转换为对应的无符号值。 由于哈希操作会处理无符号值,如果无法生成无符号哈希值,请考虑使用另外的排序策略。
下面的示例针对相同大小的随机数据集对 sort、parallel_sort、parallel_buffered_sort 和 parallel_radixsort 的性能进行比较。
// choosing-parallel-sort.cpp
// compile with: /EHsc
#include <ppl.h>
#include <random>
#include <iostream>
#include <windows.h>using namespace concurrency;
using namespace std;// Calls the provided work function and returns the number of milliseconds
// that it takes to call that function.
template <class Function>
__int64 time_call(Function&& f)
{__int64 begin = GetTickCount();f();return GetTickCount() - begin;
}const size_t DATASET_SIZE = 10000000;// Create
// Creates the dataset for this example. Each call
// produces the same predefined sequence of random data.
vector<size_t> GetData()
{vector<size_t> data(DATASET_SIZE);generate(begin(data), end(data), mt19937(42));return data;
}int wmain()
{// Use std::sort to sort the data.auto data = GetData();wcout << L"Testing std::sort...";auto elapsed = time_call([&data] { sort(begin(data), end(data)); });wcout << L" took " << elapsed << L" ms." <<endl;// Use concurrency::parallel_sort to sort the data.data = GetData();wcout << L"Testing concurrency::parallel_sort...";elapsed = time_call([&data] { parallel_sort(begin(data), end(data)); });wcout << L" took " << elapsed << L" ms." <<endl;// Use concurrency::parallel_buffered_sort to sort the data.data = GetData();wcout << L"Testing concurrency::parallel_buffered_sort...";elapsed = time_call([&data] { parallel_buffered_sort(begin(data), end(data)); });wcout << L" took " << elapsed << L" ms." <<endl;// Use concurrency::parallel_radixsort to sort the data.data = GetData();wcout << L"Testing concurrency::parallel_radixsort...";elapsed = time_call([&data] { parallel_radixsort(begin(data), end(data)); });wcout << L" took " << elapsed << L" ms." <<endl;
}
/* Sample output (on a computer that has four cores):Testing std::sort... took 2906 ms.Testing concurrency::parallel_sort... took 2234 ms.Testing concurrency::parallel_buffered_sort... took 1782 ms.Testing concurrency::parallel_radixsort... took 907 ms.
*/本示例中假设在排序期间分配 O(N) 空间是可以接受的,parallel_radixsort 在此计算机配置下对这个数据集表现得最好。
相关文章:
 -选择排序算法)
windows C++-并行编程-并行算法(五) -选择排序算法
并行模式库 (PPL) 提供了对数据集合并行地执行工作的算法。这些算法类似于 C 标准库提供的算法。并行算法由并发运行时中的现有功能组成。 在许多情况下,parallel_sort 会提供速度和内存性能的最佳平衡。 但是,当您增加数据集的大小、可用处理器的数量或…...

【系统架构设计师-2014年真题】案例分析-答案及详解
更多内容请见: 备考系统架构设计师-核心总结索引 文章目录 【材料1】问题1问题2【材料2】问题1问题2问题3【材料3】问题1问题2问题3【材料4】问题1问题2【材料5】问题1问题2问题3【材料1】 请详细阅读以下关于网络设备管理系统架构设计的说明,在答题纸上回答问题1和问题2。 …...
-分区工作)
windows C++-并行编程-并行算法(三)-分区工作
并行模式库 (PPL) 提供了对数据集合并行地执行工作的算法。这些算法类似于 C 标准库提供的算法。并行算法由并发运行时中的现有功能组成。 若要对数据源操作进行并行化,一个必要步骤是将源分区为可由多个线程同时访问的多个部分。 分区程序将指定并行算法应如何在线…...

下载 llama2-7b-hf 全流程【小白踩坑记录】
1、文件转换 在官网 https://ai.meta.com/llama/ 申请一个账号,选择要下载的模型,会收到一个邮件,邮件中介绍了下载方法 执行命令 git clone https://github.com/meta-llama/llama.git ,然后执行 llama/download.sh,…...

Codeforces practice C++ 2024/9/11 - 2024/9/13
D. Mathematical Problem Codeforces Round 954 (Div. 3) 原题链接:https://codeforces.com/contest/1986/problem/D 题目标签分类:brute force,dp,greedy,implementation,math,two pointers…...

RabbitMQ创建交换机和队列——配置类 注解
交换机的类型 Fanout:广播,将消息交给所有绑定到交换机的队列。 Direct:订阅,基于RoutingKey(路由key)发送给订阅了消息的队列。 Topic:通配符订阅,与Direct类似,只不…...

proteus+51单片机+AD/DA学习5
目录 1.DA转换原理 1.1基本概念 1.1.1DA的简介 1.1.2DA0832芯片 1.1.3PCF8591芯片 1.2代码 1.2.1DAC8053的代码 1.2.2PCF8951的代码 1.3仿真 1.3.1DAC0832的仿真 1.3.2PFC8951的仿真 2.AD转换原理 2.1AD的基本概念 2.1.1AD的简介 2.1.2ADC0809的介绍 2.1.3XPT2…...

【Python机器学习】长短期记忆网络(LSTM)
目录 随时间反向传播 实践 模型的使用 脏数据 “未知”词条的处理 字符级建模(英文) 生成聊天文章 进一步生成文本 文本生成的问题:内容不受控 其他记忆机制 更深的网络 尽管在序列数据中,循环神经网络为对各种语言关系…...

【Go】使用Goland创建第一个Go项目
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,…...

STM32学习笔记(一、使用DAP仿真器下载程序)
我们想要使用32单片机,总共包含四个步骤: 1、硬件连接 2、仿真器配置 3、编写程序 4、下载程序 一、第一个问题(硬件连接):如何进行硬件连接,才能够启动32板子并能够下载程序呢? 答&#…...
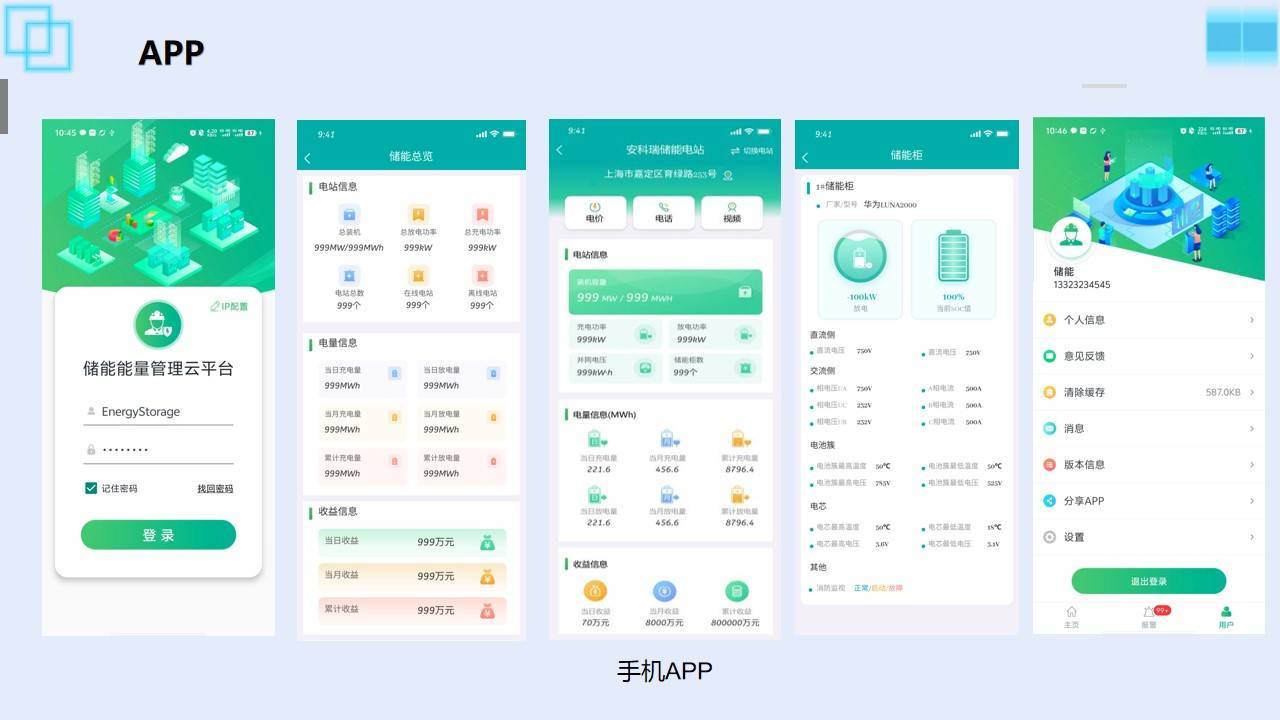
储能运维管理云平台解决方案EMS能量管理系统
在储能行业蓬勃发展的今天,储能运维管理的重要性日益凸显。而储能运维管理云平台的出现,正为储能系统的稳定运行和高效管理注入了新的活力。 一、储能运维管理面临的挑战 传统的储能运维管理方式往往依赖人工巡检和现场操作,存在诸多问题。比…...

网络药理学:16、速通流程版
一、筛选疾病靶点 GeneCards 下载数据得到GeneCards-SearchResult.csv通过Relevance score≥1.0得到GeneCards.csv步骤2只保留Gene Symbol,即基因名这一列得到GeneCards_gene_names.csv OMIM 下载数据得到OMIM-Gene-Map-Retrieval.xlsx只保留Gene/Locus…...

P2515 [HAOI2010] 软件安装
~~~~~ P2515 [HAOI2010] 软件安装 ~~~~~ 总题单链接 思路 ~~~~~ 发现构成的图是一个森林和一些环。 ~~~~~ 对于森林,建一个虚点然后树形 D P DP DP 即可。 ~~~~~ 对于环,发现要么把这个环上的每一个点都选了,要么每一个都不选。所以可以先缩…...

51单片机快速入门之定时器和计数器
51单片机快速入门之定时器 断开外部输入 晶振振荡 假设为 12MHz 12分频之后,为1MHz 当其从0-65536 时,需要65536μs 微秒 也就是65.536ms 毫秒 溢出(值>65536 时)>中断>执行中断操作 假设需要1ms后产生溢出,则需要设置初始值为64536 此时定时器会从 64536 开始计…...

【计算机网络 - 基础问题】每日 3 题(一)
✍个人博客:Pandaconda-CSDN博客 📣专栏地址:http://t.csdnimg.cn/fYaBd 📚专栏简介:在这个专栏中,我将会分享 C 面试中常见的面试题给大家~ ❤️如果有收获的话,欢迎点赞👍收藏&…...

Unity全面取消Runtime费用 安装游戏不再收版费
Unity宣布他们已经废除了争议性的Runtime费用,该费用于2023年9月引入,定于1月1日开始收取。Runtime费用起初是打算根据使用Unity引擎安装游戏的次数收取版权费。2023年9月晚些时候,该公司部分收回了计划,称Runtime费用只适用于订阅…...

IDEA测试类启动报 “java: 常量字符串过长” 解决办法
目录标题 问题描述问题分析解决办法其他办法 问题描述 问题分析 字符串长度过长,导致 idea 默认使用的 javac 编译器编译不了。 查询资料发现,原因是javac在编译期间,常量字符串最大长度为65534。 解决办法 Javac 编译器改为 Eclipse 编译…...

计算机科学基础 -- 访存单元
访存单元(Memory Access Unit)的概念 访存单元(Memory Access Unit) 是处理器中的一个关键模块,负责处理指令中的内存访问操作,包括从内存中读取数据和将数据写入内存。由于内存访问速度通常比处理器执行速…...
)
Linux压缩、解压缩、查看压缩内容详解使用(tar、gzip、bzip2、xz、jar、war、aar)
在Linux环境中,你可以使用各种命令来压缩、解压缩和查看不同类型的压缩包。以下是常用的命令和操作说明,包括tar、gzip、bzip2、xz、jar、war、aar等类型的包文件。 1. tar命令:压缩、解压、查看tar包 压缩: tar -cvf archive.…...

StreamReader 和 StreamWriter提供自动处理字符编码的功能
FileStream、StreamReader 和 StreamWriter 都用于文件操作,但它们的设计目标和使用方式有所不同。下面是它们之间的主要差异以及如何结合使用的说明: 1. FileStream 用途:提供对文件的字节流访问,用于读写二进制数据。特点&…...

浅谈 React Hooks
React Hooks 是 React 16.8 引入的一组 API,用于在函数组件中使用 state 和其他 React 特性(例如生命周期方法、context 等)。Hooks 通过简洁的函数接口,解决了状态与 UI 的高度解耦,通过函数式编程范式实现更灵活 Rea…...

突破不可导策略的训练难题:零阶优化与强化学习的深度嵌合
强化学习(Reinforcement Learning, RL)是工业领域智能控制的重要方法。它的基本原理是将最优控制问题建模为马尔可夫决策过程,然后使用强化学习的Actor-Critic机制(中文译作“知行互动”机制),逐步迭代求解…...

服务器硬防的应用场景都有哪些?
服务器硬防是指一种通过硬件设备层面的安全措施来防御服务器系统受到网络攻击的方式,避免服务器受到各种恶意攻击和网络威胁,那么,服务器硬防通常都会应用在哪些场景当中呢? 硬防服务器中一般会配备入侵检测系统和预防系统&#x…...

C++ 求圆面积的程序(Program to find area of a circle)
给定半径r,求圆的面积。圆的面积应精确到小数点后5位。 例子: 输入:r 5 输出:78.53982 解释:由于面积 PI * r * r 3.14159265358979323846 * 5 * 5 78.53982,因为我们只保留小数点后 5 位数字。 输…...

【python异步多线程】异步多线程爬虫代码示例
claude生成的python多线程、异步代码示例,模拟20个网页的爬取,每个网页假设要0.5-2秒完成。 代码 Python多线程爬虫教程 核心概念 多线程:允许程序同时执行多个任务,提高IO密集型任务(如网络请求)的效率…...

LeetCode - 199. 二叉树的右视图
题目 199. 二叉树的右视图 - 力扣(LeetCode) 思路 右视图是指从树的右侧看,对于每一层,只能看到该层最右边的节点。实现思路是: 使用深度优先搜索(DFS)按照"根-右-左"的顺序遍历树记录每个节点的深度对于…...

2025年低延迟业务DDoS防护全攻略:高可用架构与实战方案
一、延迟敏感行业面临的DDoS攻击新挑战 2025年,金融交易、实时竞技游戏、工业物联网等低延迟业务成为DDoS攻击的首要目标。攻击呈现三大特征: AI驱动的自适应攻击:攻击流量模拟真实用户行为,差异率低至0.5%,传统规则引…...

2.2.2 ASPICE的需求分析
ASPICE的需求分析是汽车软件开发过程中至关重要的一环,它涉及到对需求进行详细分析、验证和确认,以确保软件产品能够满足客户和用户的需求。在ASPICE中,需求分析的关键步骤包括: 需求细化:将从需求收集阶段获得的高层需…...

LUA+Reids实现库存秒杀预扣减 记录流水 以及自己的思考
目录 lua脚本 记录流水 记录流水的作用 流水什么时候删除 我们在做库存扣减的时候,显示基于Lua脚本和Redis实现的预扣减 这样可以在秒杀扣减的时候保证操作的原子性和高效性 lua脚本 // ... 已有代码 ...Overridepublic InventoryResponse decrease(Inventor…...

Pandas 可视化集成:数据科学家的高效绘图指南
为什么选择 Pandas 进行数据可视化? 在数据科学和分析领域,可视化是理解数据、发现模式和传达见解的关键步骤。Python 生态系统提供了多种可视化工具,如 Matplotlib、Seaborn、Plotly 等,但 Pandas 内置的可视化功能因其与数据结…...