【Spark分布式内存计算框架——Spark Core】8. 共享变量
第七章 共享变量
在默认情况下,当Spark在集群的多个不同节点的多个任务上并行运行一个函数时,它会把函数中涉及到的每个变量,在每个任务上都生成一个副本。但是,有时候需要在多个任务之间共享变量,或者在任务(Task)和任务控制节点(Driver Program)之间共享变量。
为了满足这种需求,Spark提供了两种类型的变量:
1)、广播变量Broadcast Variables
- 广播变量用来把变量在所有节点的内存之间进行共享,在每个机器上缓存一个只读的变量,而不是为机器上的每个任务都生成一个副本;
2)、累加器Accumulators - 累加器支持在所有不同节点之间进行累加计算(比如计数或者求和);
官方文档:http://spark.apache.org/docs/2.4.5/rdd-programming-guide.html#shared-variables
7.1 广播变量
广播变量允许开发人员在每个节点(Worker or Executor)缓存只读变量,而不是在Task之间传递这些变量。使用广播变量能够高效地在集群每个节点创建大数据集的副本。同时Spark还使用高效的广播算法分发这些变量,从而减少通信的开销。
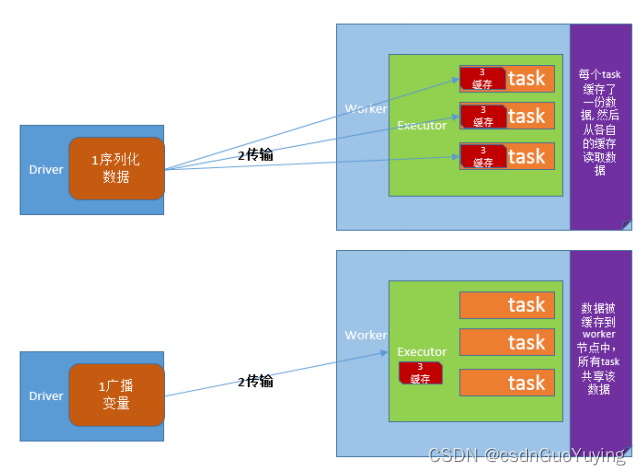
可以通过调用sc.broadcast(v)创建一个广播变量,该广播变量的值封装在v变量中,可使用获取
该变量value的方法进行访问。

7.2 累加器
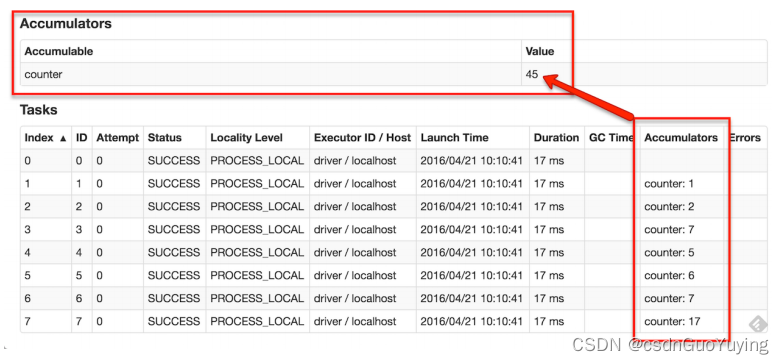
Spark提供的Accumulator,主要用于多个节点对一个变量进行共享性的操作。Accumulator只提供了累加的功能,即确提供了多个task对一个变量并行操作的功能。但是task只能对Accumulator进行累加操作,不能读取Accumulator的值,只有Driver程序可以读取Accumulator的值。创建的Accumulator变量的值能够在Spark Web UI上看到,在创建时应该尽量为其命名。
Spark内置了三种类型的Accumulator,分别是LongAccumulator用来累加整数型,DoubleAccumulator用来累加浮点型,CollectionAccumulator用来累加集合元素。
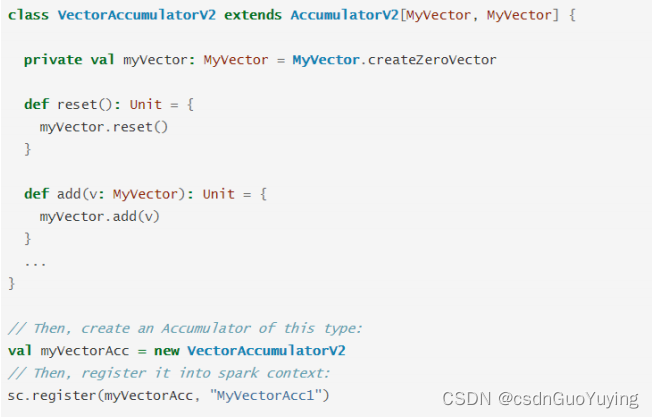
当内置的Accumulator无法满足要求时,可以继承AccumulatorV2实现自定义的累加器。实现自定义累加器的步骤:
- 第一步、继承AccumulatorV2,实现相关方法;
- 第二步、创建自定义Accumulator的实例,然后在SparkContext上注册它;
官方提供实例如下:
7.3 案例演示
以词频统计WordCount程序为例,假设处理的数据如下所示,包括非单词符合,统计数据词频时过滤非单词的符合并且统计总的格式。

实现功能:
第一、过滤非单词符合
- 非单词符合存储列表List中

- 使用广播变量广播列表

第二、累计统计非单词符号出现次数
- 定义一个LongAccumulator累加器,进行计数

范例演示完整代码如下
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
import org.apache.spark.util.LongAccumulator
import org.apache.spark.{SparkConf, SparkContext}
/**
* 基于Spark框架使用Scala语言编程实现词频统计WordCount程序,将符号数据过滤,并统计出现的次数
* -a. 过滤标点符号数据
* 使用广播变量
* -b. 统计出标点符号数据出现次数
* 使用累加器
*/
object SparkSharedVariableTest {
def main(args: Array[String]): Unit = {
// 创建应用程序入口SparkContext实例对象
val sc: SparkContext = {
// 1.a 创建SparkConf对象,设置应用的配置信息
val sparkConf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[2]")
// 1.b 传递SparkConf对象,构建Context实例
new SparkContext(sparkConf)
}
sc.setLogLevel("WARN")
// a. 读取文件数据
val datasRDD: RDD[String] = sc.textFile("datas/filter/datas.input", minPartitions = 2)
// TODO: 字典数据,只要有这些单词就过滤: 特殊字符存储列表List中
val list: List[String] = List(",", ".","!","#","$","%")
// TODO: 通过广播变量 将列表list广播到各个Executor内存中,便于多个Task使用
val listBroadcast: Broadcast[List[String]] = sc.broadcast(list)
// TODO: 定义累加器,记录单词为符号数据的个数
val accumulator: LongAccumulator = sc.longAccumulator("number_accum")
// b. 分割单词,过滤数据
val wordsRDD = datasRDD
// 1)、过滤数据,去除空行数据
.filter(line => null != line && line.trim.length > 0)
// 2)、分割单词
.flatMap(line => line.trim.split("\\s+"))
// 3)、过滤字典数据:符号数据
.filter{word =>
// 获取符合列表 TODO: 从广播变量中获取列表list的值
val listValue = listBroadcast.value
// 判断单词是否为符号数据,如果是就过滤掉
val isFlag = listValue.contains(word)
if(isFlag){
// TODO: 如果单词为符号数据,累加器加1
accumulator.add(1L)
}
!isFlag
}
val resultRDD: RDD[(String, Int)] = wordsRDD
// 转换为二元组
.mapPartitions{iter => iter.map(word => (word, 1))}
// 按照单词聚合统计
.reduceByKey((tmp, item) => tmp + item)
resultRDD.foreach(println)
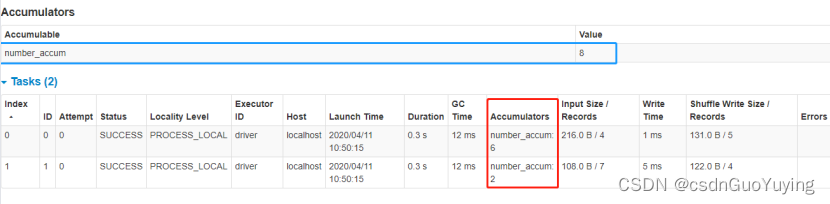
println(s"过滤符合数据的个数:${accumulator.value}")
// 应用程序运行结束,关闭资源
sc.stop()
}
}
运行应用,查看WEB UI监控,定义累加器的值:
相关文章:
【Spark分布式内存计算框架——Spark Core】8. 共享变量
第七章 共享变量 在默认情况下,当Spark在集群的多个不同节点的多个任务上并行运行一个函数时,它会把函数中涉及到的每个变量,在每个任务上都生成一个副本。但是,有时候需要在多个任务之间共享变量,或者在任务(Task)和…...

C++多态常见面试题
1.什么是多态 简单点说,就是多种形态,具体就是完成某个行为,当不同的对象去完成时产生的不同形态。多态分为静态多态和动态多态,静态多态一般指的是函数重载,在编译阶段通过函数名修饰规则,不同类型调用不同…...
字母板上的路径 题解,力扣官方出来挨打(小声)
字母板上的路径 我们从一块字母板上的位置 (0, 0) 出发,该坐标对应的字符为 board[0][0]。 在本题里,字母板为board [“abcde”, “fghij”, “klmno”, “pqrst”, “uvwxy”, “z”],如下所示。 我们可以按下面的指令规则行动:…...
代码随想录算法训练营第二十六天 | 39. 组合总和,40.组合总和II,131.分割回文串
一、参考资料组合总和题目链接/文章讲解:https://programmercarl.com/0039.%E7%BB%84%E5%90%88%E6%80%BB%E5%92%8C.html 视频讲解:https://www.bilibili.com/video/BV1KT4y1M7HJ 组合总和II题目链接/文章讲解:https://programmercarl.com/004…...

vueday01-脚手架安装详细
一、vue脚手架安装命令npm i -g vue/cli 或 yarn global add vue/cli安装上面的工具,安装后运行 vue --version ,如果看到版本号,说明安装成功或 vue -V工具安装好之后,就可以安装带有webpack配置的vue项目了。创建项目之前&#…...
)
初识cesium3d(一)
使用ViteVue3.2Cesium。Vite需要Node.js版本14.18及以上版本。Vite命令创建的工程会自动生成vite.config.js文件,来配置一些相关的参数。 1、使用Vite创建vue3项目 # npm npm init vitelatest cesium-app -- --template vue # yarn yarn create vite cesium-app…...

点云转3D网格【Python】
推荐:使用 NSDT场景设计器 快速搭建 3D场景。 在本文中,我将介绍我的 3D 表面重建过程,以便使用 Python 从点云快速创建网格。 你将能够导出、可视化结果并将结果集成到您最喜欢的 3D 软件中,而无需任何编码经验。 此外࿰…...
【OpenCV图像处理系列一】OpenCV开发环境的安装与搭建(Ubuntu + Window都适用)
🔗 运行环境:OpenCV,Ubuntu,Windows 🚩 撰写作者:左手の明天 🥇 精选专栏:《python》 🔥 推荐专栏:《算法研究》 #### 防伪水印——左手の明天 #### &#x…...

【代码随想录】-动态规划专题
文章目录理论基础斐波拉契数列爬楼梯使用最小花费爬楼梯不同路径不同路径 II整数拆分不同的二叉搜索树背包问题——理论基础01背包二维dp数组01背包一维数组(滚动数组)装满背包分割等和子集最后一块石头的重量 II目标和一和零完全背包零钱兑换 II组合总和…...

c++数据类型 输入输出
C++语法 //常用包: iostream:cin cout endl cstdio:scanf printf algorithm:max min reverse swap cstring:memset memcpymemset(a,-1,sizeof a) 填充数组memcpy(b,a,sizeof a) 将a数组复制到b数组,长度是a数组字节长度 cmath:sin sqrt pow abs fabs编程是一种控制计…...
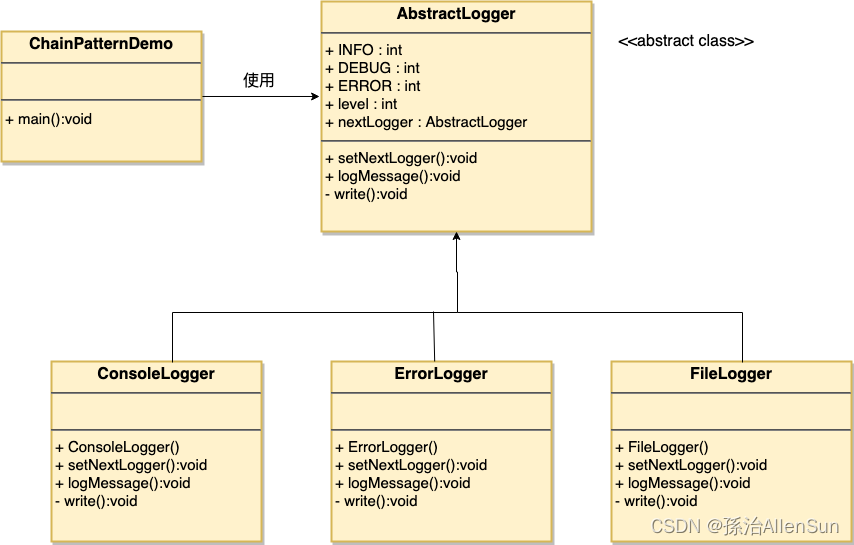
【设计模式-11】责任链模式
认识设计模式(十一)---责任链模式【一】责任链模式【二】介绍(1)意图(2)主要解决(3)何时使用(4)如何解决(5)关键代码(6&am…...
SpringBoot+Vue实现智能物流管理系统
文末获取源码 开发语言:Java 框架:springboot JDK版本:JDK1.8 服务器:tomcat7 数据库:mysql 5.7/8.0 数据库工具:Navicat11 开发软件:eclipse/myeclipse/idea Maven包:Maven3.3.9 浏…...

【MT7628】MT7628如何修改串口波特率、调试串口物理口、使用UART3口
环境说明 sdk版本:Mediatek_ApSoC_SDK_4320_20150414.tar.bz2 芯片方案:MT7628A Uboot修改串口波特率方法 修改rt2880.h文件 修改include/configs/rt2880.h文件CONFIG_BAUDRATE宏的值 - #define CONFIG_BAUDRATE 57600 +#define CONFIG_BAUDRATE 115200 Kernel中修改串口波特…...

css盒模型介绍
在使用CSS进行网页布局时,我们一定离不开的一个东西————盒子模型。盒子模型,顾名思义,盒子就是用来装东西的,它装的东西就是HTML元素的内容。或者说,每一个可见的 HTML 元素都是一个盒子,下面所说的盒子…...

onetab 谷歌插件历史数据清除
文章目录方法1:测试也可以步骤1:批量执行点击步骤2:python 脚本模拟点击确定操作方法2:成功【推荐】步骤1:修改confirm,类似于hook操作步骤2:批量点击删除操作:onetab 谷歌插件历史数…...

GRBL源码简单分析
结构体说明 GRBL里面的速度规划是带运动段前瞻的,所以有规划运动段数据和微小运动段的区分 这里的“规划运动段”对应的数据结构是plan_block_t,前瞻和加减速会使用到,也就是通过解析G代码后出来的直接直线数据或是圆弧插补出来的拟合直线数据…...
)
第一部分:简单句——第一章:简单句的核心——二、简单句的核心变化(谓语动词的情态)
二、简单句的核心变化 简单句的核心变化其实就是 一主一谓(n. v.) 表达一件事情,谓语动词是其中最重要的部分,谓语动词的变化主要有四种:三态加一否(时态、语态、情态、否定),其中…...

软考高级考试中有五大证书,其中哪个更值得考?
计算机软考属于专业技术人员职业资格水平评价类,是职业资格、专业技术资格(职称)和专业技术水平"三合一"的考试,是目前IT行业仅有的国家级考试。考试不受学历、专业、资历等条件限制。软考高级考试中有五大证书…...

FlexRay™ 协议控制器 (E-Ray)-04
网络管理 累积的网络管理 (NM) 向量位于网络管理寄存器 1 到网络管理寄存器 3 (NMVx (x = 1-3)) 中。【The accrued Network Management (NM) vector is located in the Network Management Register 1 to Network Management Register 3 (NMVx (x = 1-3)).】 网络管理向量 x…...

container_of 根据成员变量获得包含其的对象的地址!
写在前面 本系列文章的灵感出处均是各个技术书籍的读后感,详细书籍信息见文章最后的参考文献 CONTAINER_OF 在书中发现一个很有意思的宏,以此可以衍生出来其很多的用法,这个宏可以根据某个成员变量的地址得到包含这个成员变量地址的对象的…...

变量 varablie 声明- Rust 变量 let mut 声明与 C/C++ 变量声明对比分析
一、变量声明设计:let 与 mut 的哲学解析 Rust 采用 let 声明变量并通过 mut 显式标记可变性,这种设计体现了语言的核心哲学。以下是深度解析: 1.1 设计理念剖析 安全优先原则:默认不可变强制开发者明确声明意图 let x 5; …...

盘古信息PCB行业解决方案:以全域场景重构,激活智造新未来
一、破局:PCB行业的时代之问 在数字经济蓬勃发展的浪潮中,PCB(印制电路板)作为 “电子产品之母”,其重要性愈发凸显。随着 5G、人工智能等新兴技术的加速渗透,PCB行业面临着前所未有的挑战与机遇。产品迭代…...
【机器视觉】单目测距——运动结构恢复
ps:图是随便找的,为了凑个封面 前言 在前面对光流法进行进一步改进,希望将2D光流推广至3D场景流时,发现2D转3D过程中存在尺度歧义问题,需要补全摄像头拍摄图像中缺失的深度信息,否则解空间不收敛…...

最新SpringBoot+SpringCloud+Nacos微服务框架分享
文章目录 前言一、服务规划二、架构核心1.cloud的pom2.gateway的异常handler3.gateway的filter4、admin的pom5、admin的登录核心 三、code-helper分享总结 前言 最近有个活蛮赶的,根据Excel列的需求预估的工时直接打骨折,不要问我为什么,主要…...

基础测试工具使用经验
背景 vtune,perf, nsight system等基础测试工具,都是用过的,但是没有记录,都逐渐忘了。所以写这篇博客总结记录一下,只要以后发现新的用法,就记得来编辑补充一下 perf 比较基础的用法: 先改这…...

MODBUS TCP转CANopen 技术赋能高效协同作业
在现代工业自动化领域,MODBUS TCP和CANopen两种通讯协议因其稳定性和高效性被广泛应用于各种设备和系统中。而随着科技的不断进步,这两种通讯协议也正在被逐步融合,形成了一种新型的通讯方式——开疆智能MODBUS TCP转CANopen网关KJ-TCPC-CANP…...

OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别
OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别 直接训练提示词嵌入向量的核心区别 您提到的代码: prompt_embedding = initial_embedding.clone().requires_grad_(True) optimizer = torch.optim.Adam([prompt_embedding...

关键领域软件测试的突围之路:如何破解安全与效率的平衡难题
在数字化浪潮席卷全球的今天,软件系统已成为国家关键领域的核心战斗力。不同于普通商业软件,这些承载着国家安全使命的软件系统面临着前所未有的质量挑战——如何在确保绝对安全的前提下,实现高效测试与快速迭代?这一命题正考验着…...

Java线上CPU飙高问题排查全指南
一、引言 在Java应用的线上运行环境中,CPU飙高是一个常见且棘手的性能问题。当系统出现CPU飙高时,通常会导致应用响应缓慢,甚至服务不可用,严重影响用户体验和业务运行。因此,掌握一套科学有效的CPU飙高问题排查方法&…...

虚拟电厂发展三大趋势:市场化、技术主导、车网互联
市场化:从政策驱动到多元盈利 政策全面赋能 2025年4月,国家发改委、能源局发布《关于加快推进虚拟电厂发展的指导意见》,首次明确虚拟电厂为“独立市场主体”,提出硬性目标:2027年全国调节能力≥2000万千瓦࿰…...